

Idea版本:专业版IntelliJ IDEA 2023.3.4 (Ultimate Edition)
一、创建Maven项目
1.新建项目
- 打开 IDEA → 「File」→「New」→「Project」;
- 左侧选New Project
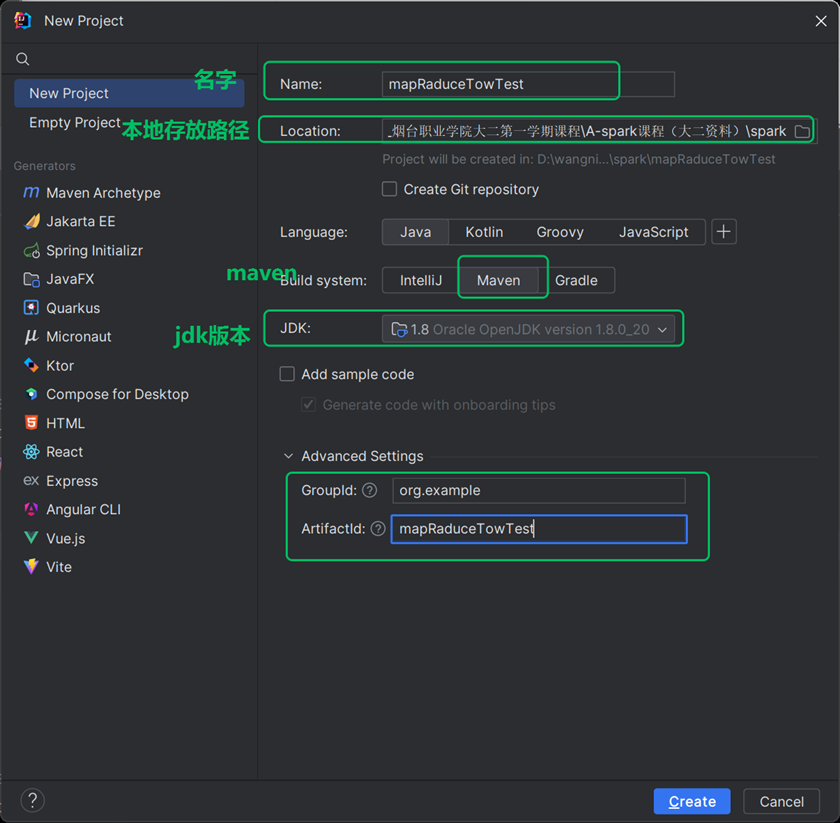
- 填写项目信息:
- Name:项目名(如mapRaduceTowTest);
- Location:本地项目路径(如E:\IDEAProjects\hadoopWordCount);
- GroupId:自定义(如com.hadoop);
- ArtifactId:项目名(如mapRaduceTowTest);
- 点击「Create」完成项目创建。
2.配置 Maven 环境
(确保依赖能下载)
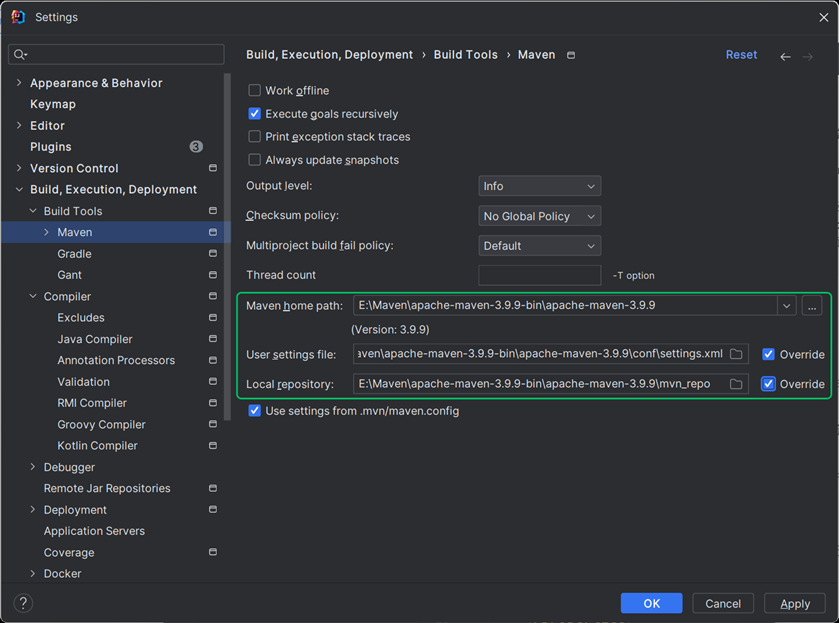
- 「File」→「Settings」→「Build, Execution, Deployment」→「Build Tools」→「Maven」;
- 配置:
- Maven home path:本地 Maven 安装路径(如E:\Maven\apache-maven-3.9.9);
- User settings file:Maven 的settings.xml路径(需配置阿里云镜像,加速 Hadoop 依赖下载);
- Local repository:Maven 本地仓库路径(如E:\Maven\apache-maven-3.9.9\mvn_repo);
- 点击「Apply」→「OK」。
maven的扩展介绍
1. 先回答:Maven 项目是什么?
Maven 项目,就是用 Maven 工具管理的 Java 项目—— 它不是 “独立的项目类型”,而是给普通 Java 项目套了个 “自动化管理外壳”,让项目开发更省心。
2. Maven 到底是干啥的?(解决 3 个核心痛点)
你之前手动写 Java 项目可能遇到过这些麻烦:
- 痛点 1:手动找依赖包太麻烦比如你要写 Hadoop 程序,得自己下载hadoop-common.jar、hadoop-hdfs.jar等十几个包,还要手动复制到项目里,少一个包就报错。→ Maven 的解决办法:你在pom.xml里写一行依赖(比如<dependency>hadoop-common</dependency>),Maven 会自动从网上下载所有需要的包,还能自动下这些包依赖的其他包(比如 hadoop-common 依赖的 guava 包)。
- 痛点 2:项目结构混乱,换电脑就崩不同人写 Java 项目,文件夹结构五花八门(比如有人把代码放src,有人放code),换个电脑打开项目,要么找不到代码,要么依赖包全丢了。→ Maven 的解决办法:强制规定项目结构(比如代码必须放src/main/java,测试代码放src/test/java,依赖包统一存在本地仓库),不管谁接手、换什么电脑,只要用 Maven 打开项目,结构和依赖都能自动恢复。
- 痛点 3:手动编译、打包太繁琐写好代码后,要手动用javac编译,手动打 JAR 包,还要自己处理依赖包的打包问题(比如把 Hadoop 的包一起打进 JAR 里)。→ Maven 的解决办法:只需要执行mvn compile(自动编译代码)、mvn package(自动打包成 JAR/WAR),甚至能一键把项目部署到服务器,全程自动化。
3. 总结:Maven 的核心定位
Maven 不是 “编程语言”,也不是 “项目类型”,而是Java 项目的 “自动化管理工具”,核心功能是:
- 自动下载 / 管理依赖包(不用手动找 JAR);
- 统一项目结构(所有人的项目长得都一样);
- 自动化编译、打包、部署(少写重复操作)。
简洁明了:
“Maven 是 Java 项目的管理工具,主要帮我们自动下依赖包、统一项目结构,还能一键编译打包,不用手动找 JAR 包、写编译命令,省了很多麻烦~”
3.添加 Hadoop 依赖(pom.xml)
打开项目根目录的pom.xml,在<dependencies>标签内添加 Hadoop 核心依赖(适配集群 Hadoop 版本,如 2.7.1):
配置的内容
<groupId>com.example</groupId> <!-- 项目包名前缀(自定义) -->
<artifactId>HadoopWordCount</artifactId> <!-- 项目名(唯一标识) -->
<version>1.0-SNAPSHOT</version> <!-- 项目版本(SNAPSHOT表示开发版) -->
<modelVersion>4.0.0</modelVersion> <!-- Maven POM版本(固定值) -->
正确的配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>HadoopWordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- Hadoop Common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.1</version>
</dependency>
<!-- Hadoop HDFS -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.1</version>
</dependency>
<!-- MapReduce 核心 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.1</version>
</dependency>
<!-- MapReduce 客户端 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.7.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 编译插件(指定Java版本) -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
配置了 4 个 Hadoop 核心依赖,都是 MapReduce 操作 HDFS 的必备包
| 依赖名称 | 作用 |
| hadoop-common | Hadoop 通用工具包(配置、日志、基础 IO 等) |
| hadoop-hdfs | HDFS 文件系统操作包(读写 HDFS 文件) |
| hadoop-mapreduce-client-core | MapReduce 核心包(Mapper/Reducer/Job 配置) |
| hadoop-mapreduce-client-jobclient | MapReduce 客户端包(提交 Job 到集群、运行任务) |
| ✅ 版本统一为2.7.1:必须和你的 HDFS 集群版本一致,否则会出现兼容性问题(你之前运行成功,说明版本匹配)。 |
4.再resource文件中添加hdfs的文件
src/main/resources
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--指定hdfs的nameservice的名称为ns -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!--指定zookeeper地址,主要在zookeeper文件的conf的clientPort这个值 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<!--指定hadoop临时文件存放 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop2.7/hadoop2.7.1/metadata</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--1. 副本数配置 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--2. 命名服务(Nameservice)配置 -->
<!--指定 hdfs 的 nameservice 为 ns,需要和 core-site.xml 中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- 3. NameNode 节点列表配置-->
<!-- ns 下面有两个 NameNode,分别是 nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- 4.NameNode 通信地址配置(nn1)-->
<!-- nn1 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>master:8020</value>
</property>
<!-- nn1 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>master:50070</value>
</property>
<!--5. NameNode 通信地址配置(nn2) -->
<!-- nn2 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>slave1:8020</value>
</property>
<!-- nn2 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>slave1:50070</value>
</property>
<!--6. JournalNode 共享编辑日志配置 -->
<!-- 指定 NameNode 的元数据在 JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/ns</value><!-- 节点间用;隔开 -->
</property>
<!-- 新增:JournalNode 本地数据存储路径(必须是本地路径) -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/src/hadoop2.7/hadoop2.7.1/data/journalnode</value>
</property>
<!-- 新增:NameNode 本地元数据存储路径(必须是本地路径) -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/src/hadoop2.7/hadoop2.7.1/data/namenode</value>
</property>
<!-- 可选补充:DataNode 本地数据存储路径(避免默认路径冲突) -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/src/hadoop2.7/hadoop2.7.1/data/datanode</value>
</property>
<!-- 故障转移代理 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- SSH fencing配置 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/master/.ssh/id_rsa</value>
</property>
<!-- 启用 HDFS 自动故障转移(ZKFC 必须依赖这个配置,之前漏了!) -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>supergroup</value> <!-- 超级用户组名称(默认是 supergroup) -->
</property>
<property>
<name>hadoop.security.group.mapping</name>
<value>org.apache.hadoop.security.JniBasedUnixGroupsMappingWithFallback</value>
</property>
<!-- 关闭严格权限检查 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 允许不同用户运行DataNode -->
<property>
<name>dfs.datanode.require.same.user</name>
<value>false</value>
</property>
<!-- 跳过权限检查 -->
<property>
<name>dfs.namenode.acls.enabled</name>
<value>false</value>
</property>
</configuration>
log4j.properties
核心作用是控制 Hadoop/MapReduce 程序运行时的日志输出规则
# ???????????
log4j.rootLogger=INFO, console
# ???????
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.Target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
# ??Hadoop????????
log4j.logger.org.apache.hadoop=WARN
log4j.logger.org.apache.hadoop.hdfs=WARN
5.创建文件存放运行项目
src/main/java/example
创建WordCount类
package example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
// 1. 解决 Windows 下 winutils 路径问题
System.setProperty("hadoop.home.dir", "E:\\soft\\hadoop2.7.2winutils");
System.setProperty("java.library.path", "/dev/null");
// 2. 核心配置:连接 active 的 slave1(nn2)IP + 8020 端口
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.183.131:8020"); // slave1 实际 IP
conf.set("dfs.permissions.enabled", "false");
// 3. 初始化 Job
Job job = Job.getInstance(conf, "wordcount-active-nn");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 替换原来的路径处理逻辑,改成纯硬编码(删除 args 相关逻辑)
// 4. 处理输入/输出路径(纯硬编码,和 fs.defaultFS 一致)
Path inputPath = new Path("/input/test.txt"); // 相对路径,自动拼接 fs.defaultFS
Path outputPath = new Path("/output/wordcount_result");
// 删除已存在的输出目录
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// 设置输入/输出路径
FileInputFormat.addInputPath(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
}
}
总结目录
 二、
二、
二、Maven 项目与后续远程运行的衔接
(一)、本地项目目录与集群目录的映射
编写完代码后,通过「Deployment」配置本地项目目录与集群目录的映射(如本地E:\IDEAProjects\hadoopWordCount ↔ 集群/usr/local/src/hadoopIdea),确保代码自动同步;
第一步
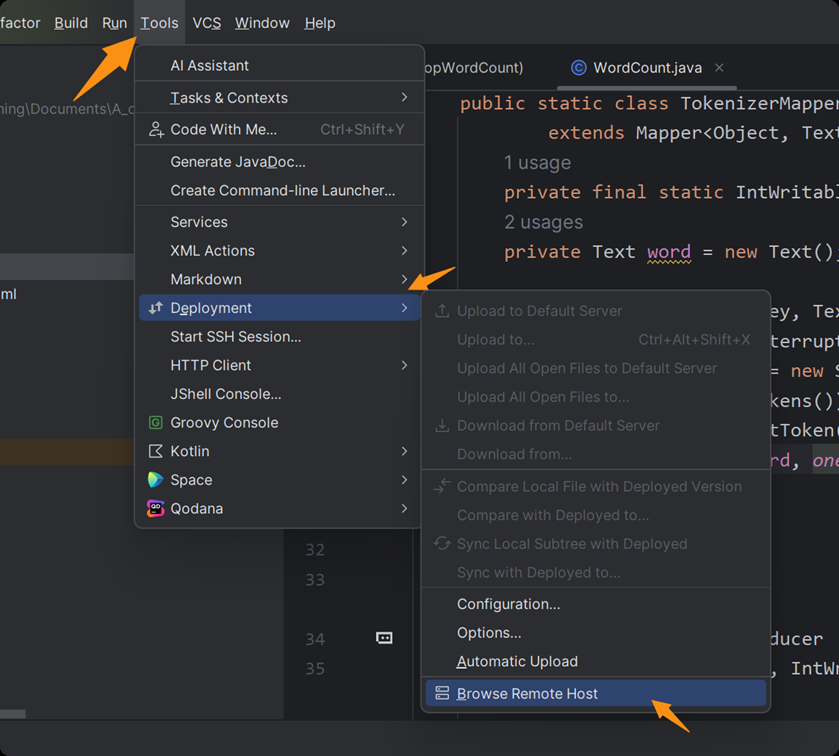
第二步
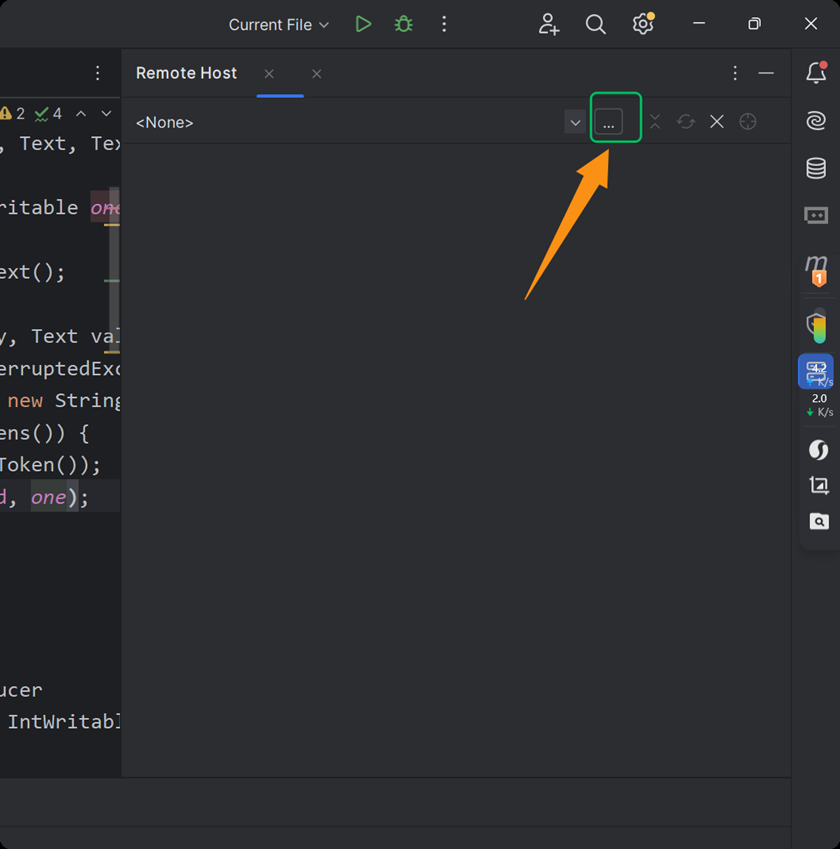
第三步
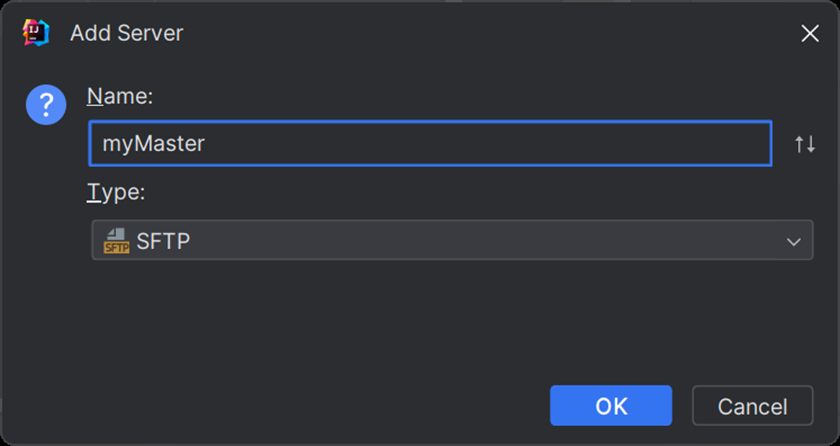
第四步
第一次配置的情况,如果不是,直接下拉菜单选择远程虚拟机
4.1
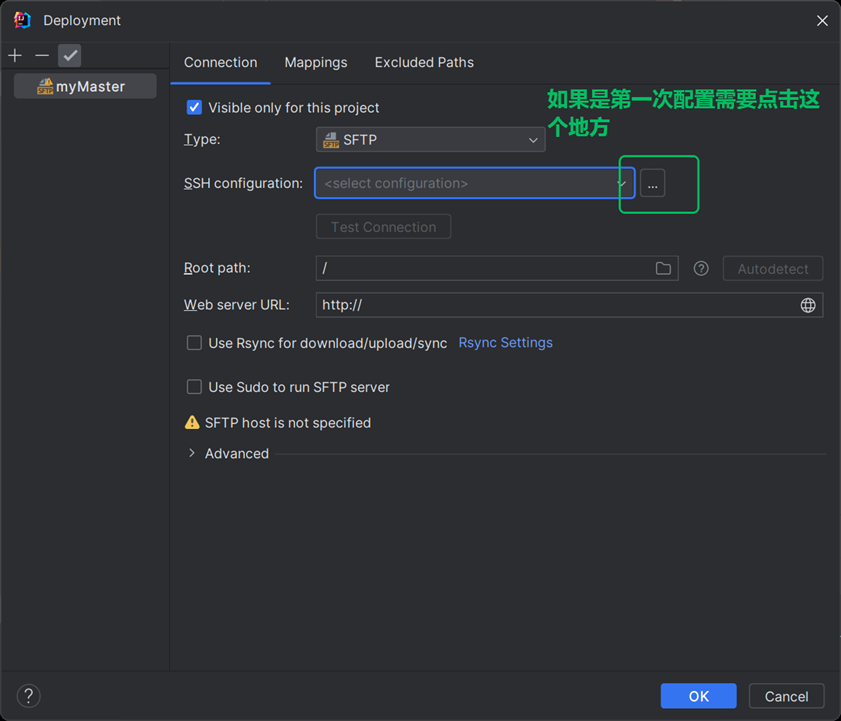
4.2
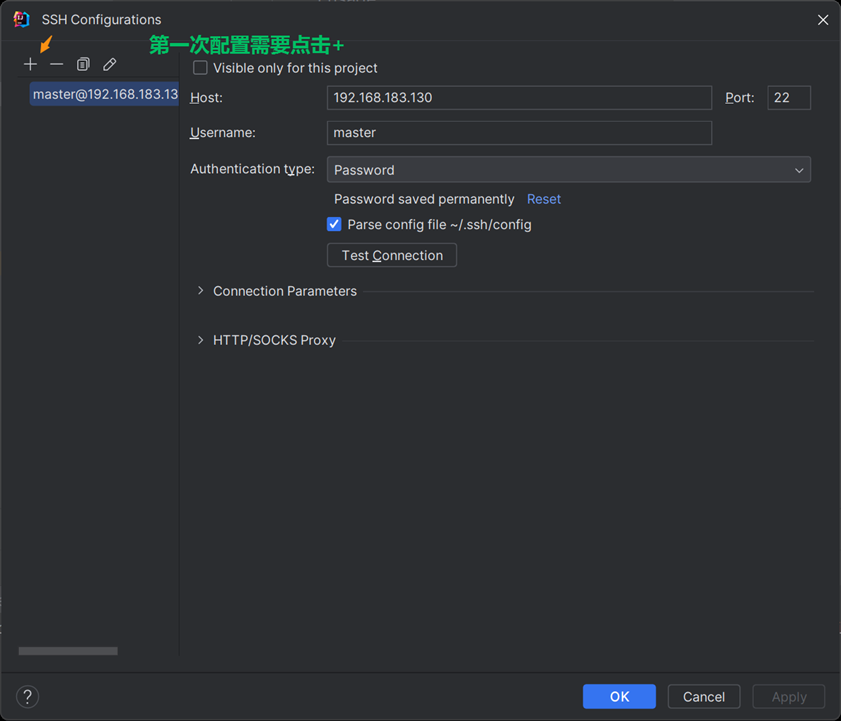
4.3
然后填写这些信息(按照自己的填写)
填写完毕之后点击apply+ok
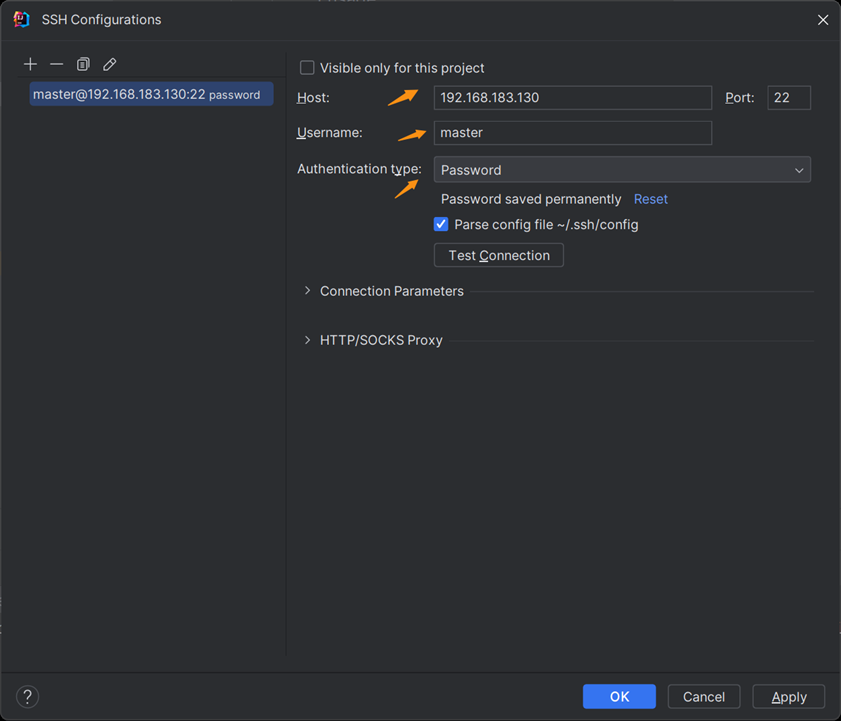
第五步
再点击(其他的不管)
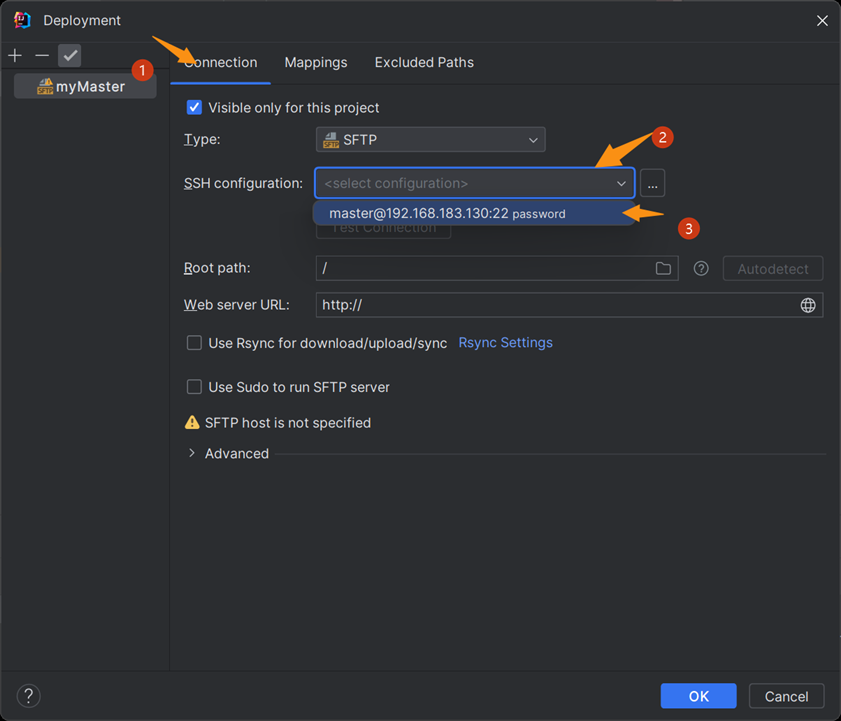
第六步
弄完这个之后点击ok
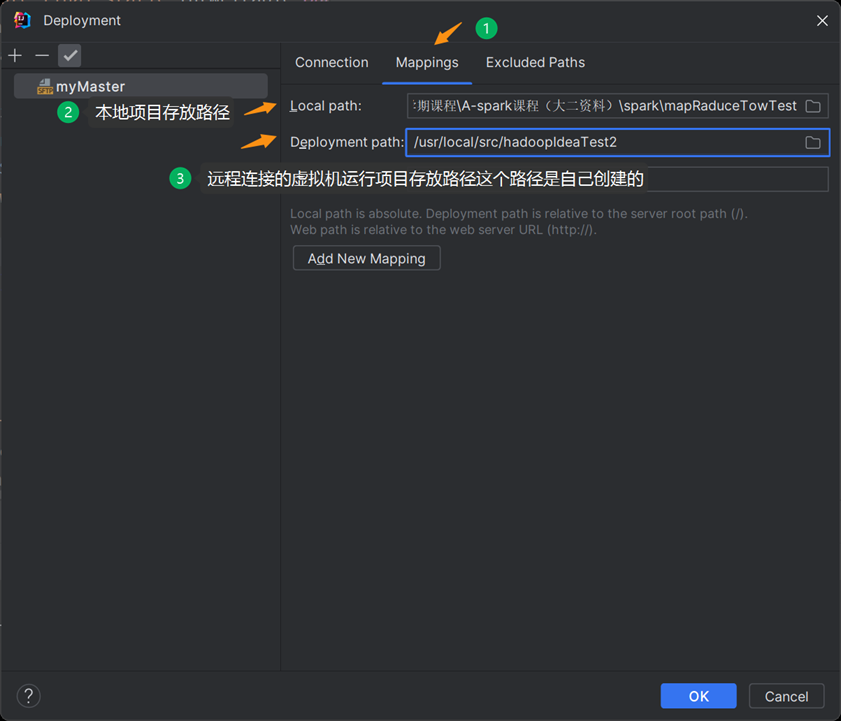
第七步,查看
此时就能连接
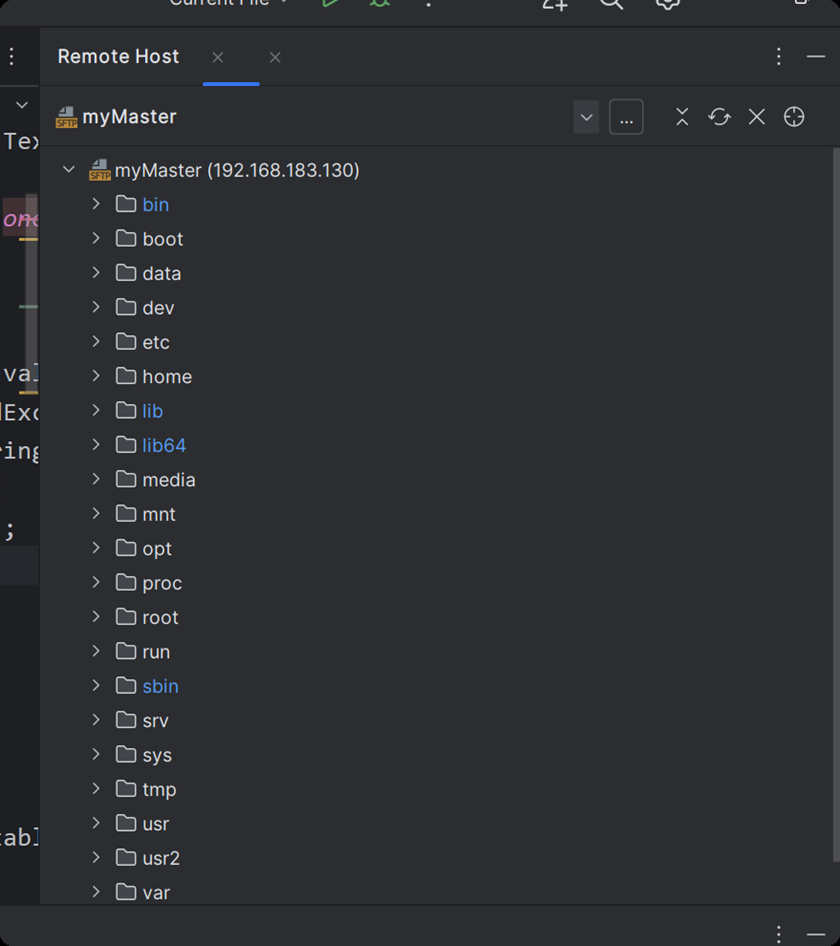
(二)、实现一键远程运行
配置远程运行模板实现 Maven 项目一键远程运行。
第一步
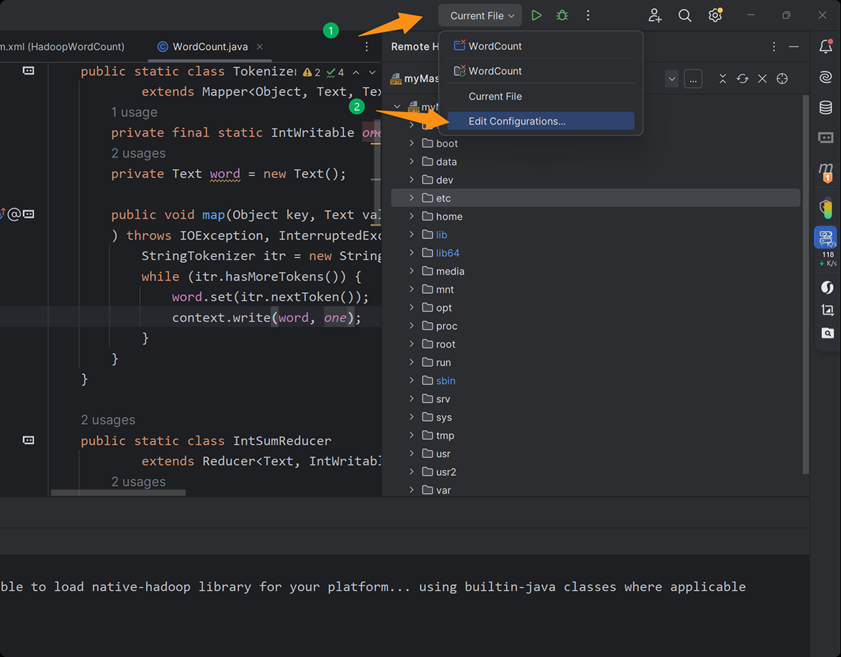
第二步
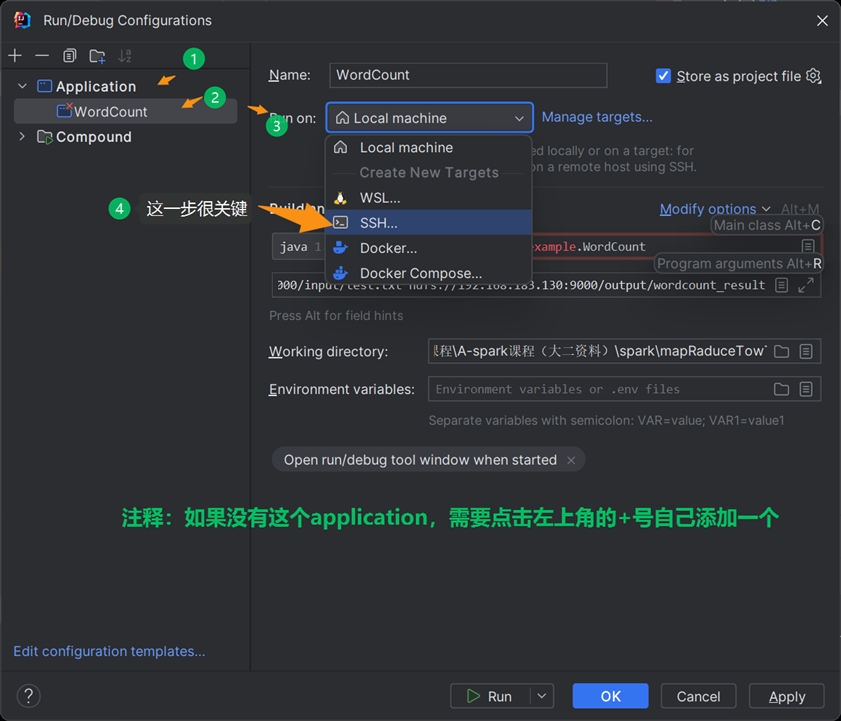
第三步
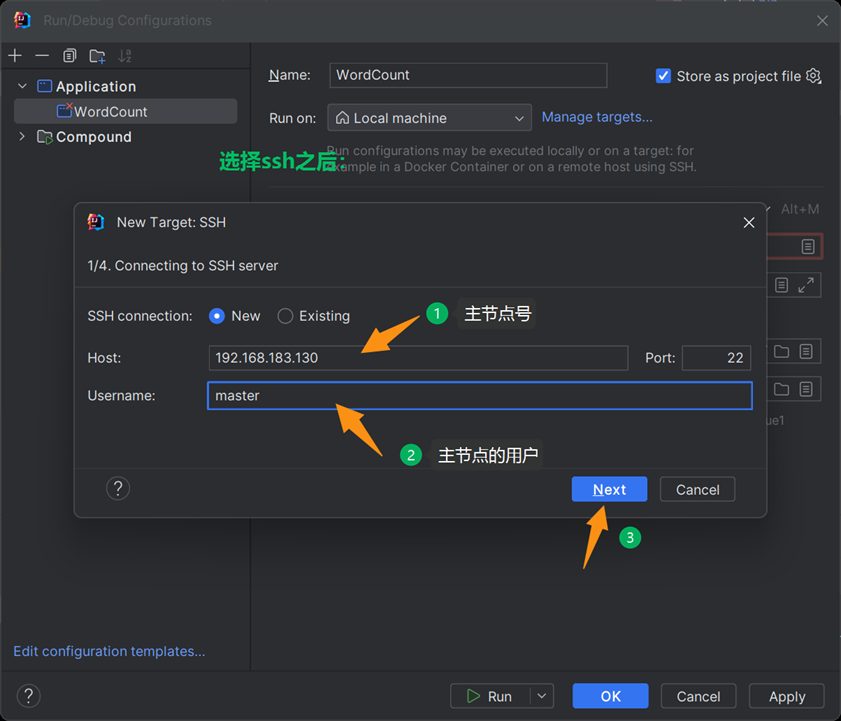
第四步
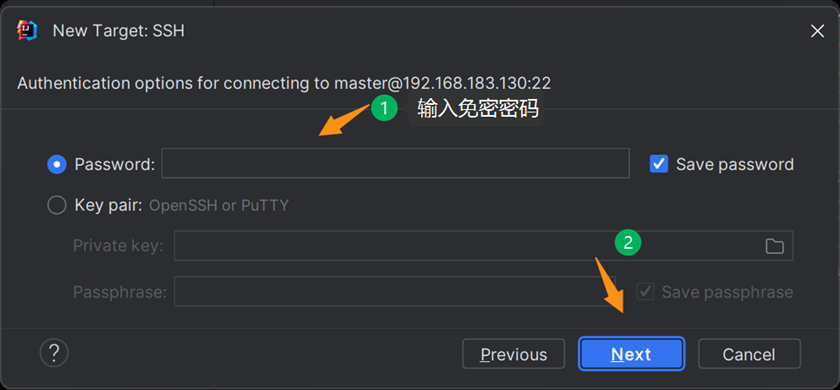
第五步
等待一会,
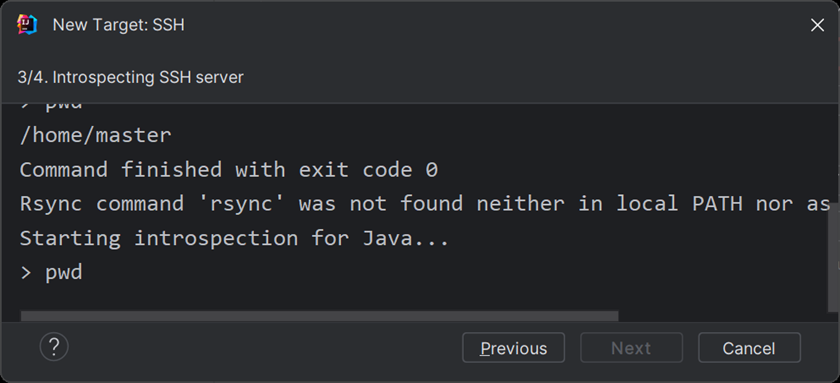
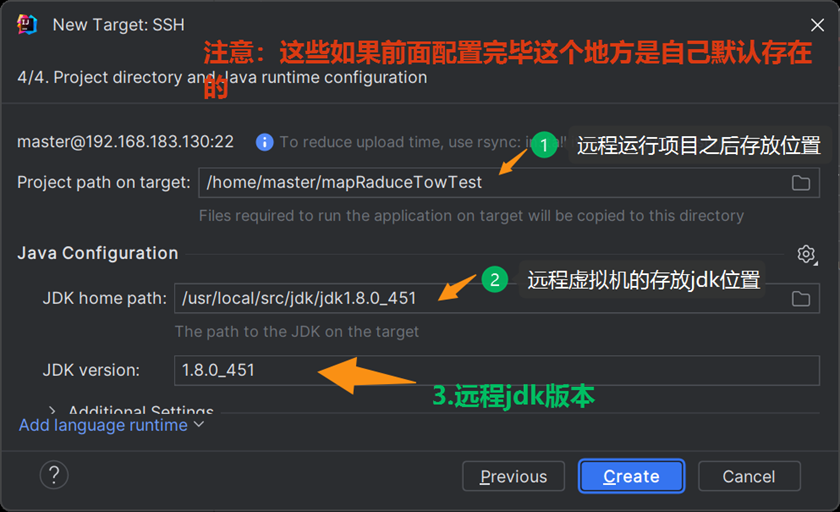
等待完毕点击next显示,之后点击creat就可以
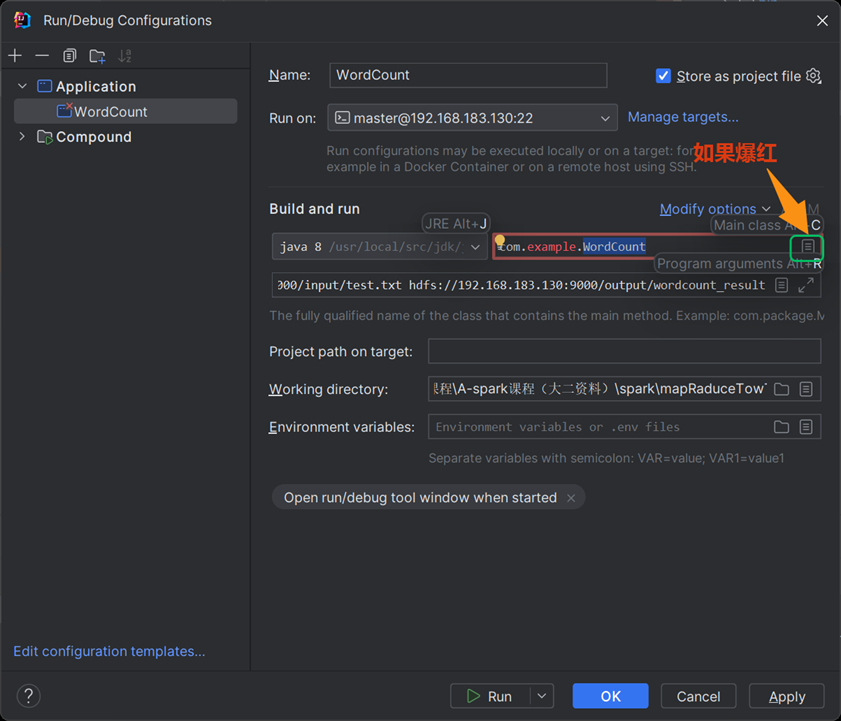
第六步
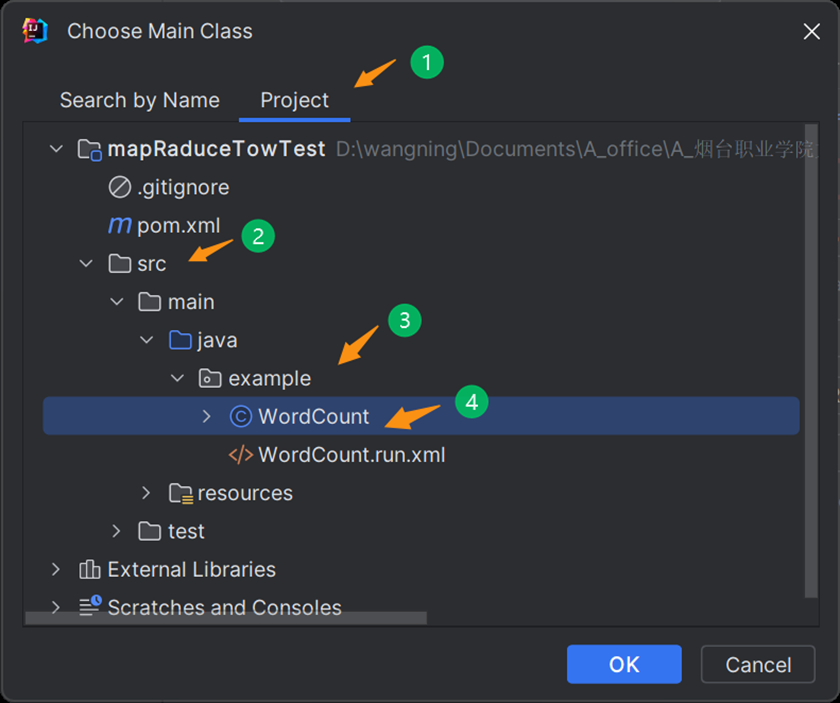
第七步
之后点击ok
第八步
HDFS 输入文件或输出目录
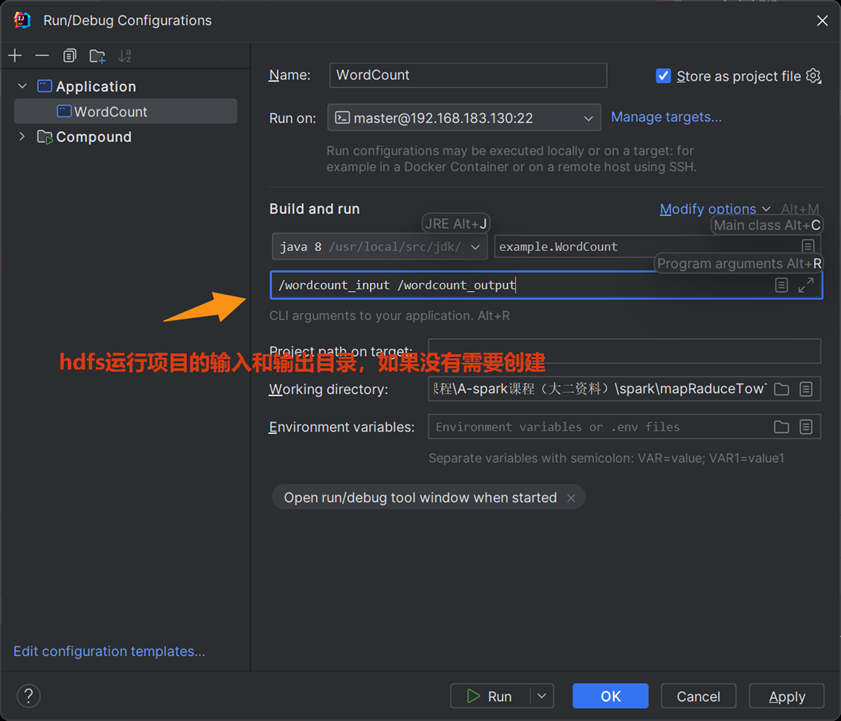
远程运行时 HDFS 没有输入文件或输出目录
如果远程运行时 HDFS 没有输入文件或输出目录,按以下步骤处理(分两种情况):
情况 1:HDFS 没有输入文件 / 目录(如/wordcount_input不存在)
会直接报错FileNotFoundException(找不到输入路径),解决方法:
- 打开 IDEA 的 SSH 终端(Tools→Start SSH Session→选master@192.168.183.130);
- 执行命令
- + 上传文件
- 1. 创建HDFS输入目录(和你Program arguments里的输入路径一致)
hdfs dfs -mkdir /wordcount_input
2. 上传集群本地文件到输入目录(比如传系统文件当测试数据)
hdfs dfs -put /etc/hosts /wordcount_input/ - 2:HDFS 没有输出目录(如/wordcount_output不存在)
不需要手动创建!Hadoop 的 MapReduce 程序会自动检测:
- 如果输出目录不存在,程序会自动创建该目录,并写入结果;
- 只有当输出目录已经存在时,才会报错(避免覆盖旧数据)。
关键注意点
- 输入目录 / 文件:必须手动创建 + 上传(因为程序要读取数据);
- 输出目录:禁止提前创建(Hadoop 会自动生成,提前创建会报错)。
第九步
最后一步,做完点击apply+ok
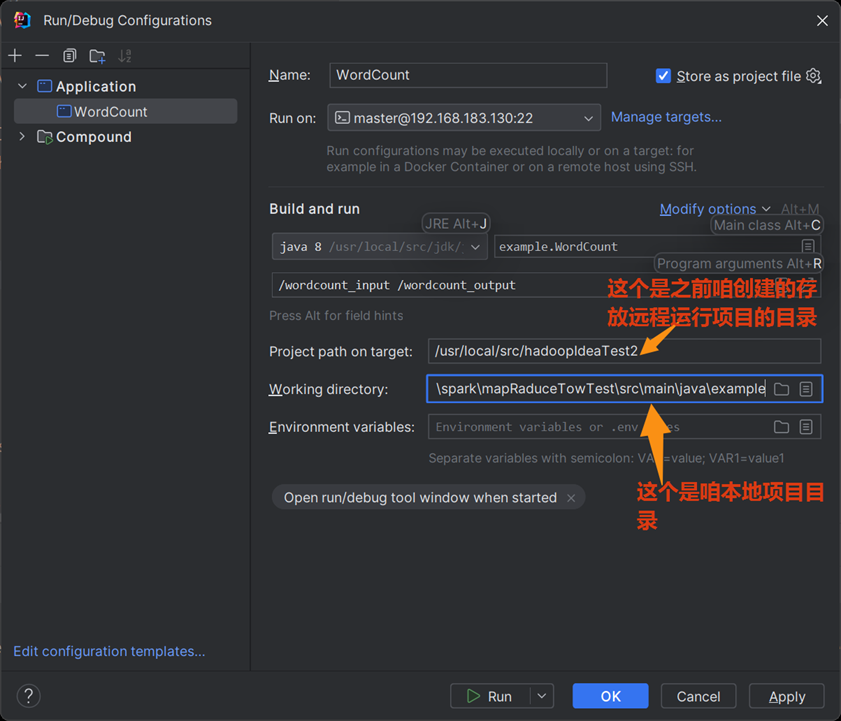
最终查看
完整的样子
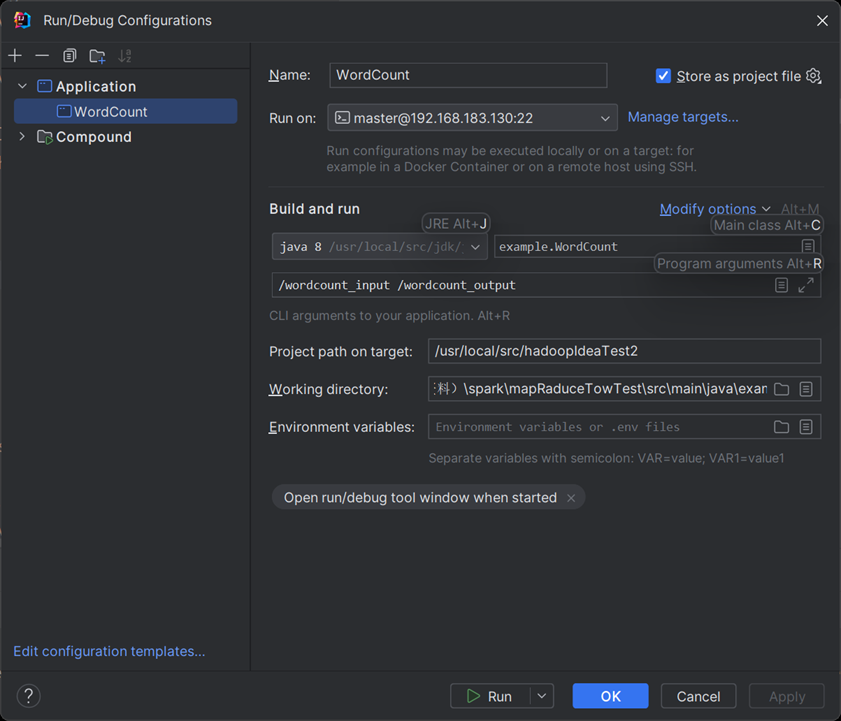
(三)、查看效果
点击运行查看
刚开始出现这些不用担心,以后就不会出现了
这些日志是 IDEA 帮你 “搬代码 / 依赖到集群” 的过程,等上传完成,程序就会在集群上执行
等待一会就行
这些日志是IDEA 远程运行 Hadoop 项目时的正常文件上传过程:
一、核心原因:远程运行需要 “把本地依赖 / 代码传到集群”
你是在 Windows 本地的 IDEA 写代码,但要在 Linux 集群(192.168.183.130)上运行程序 —— 集群里没有你本地 Maven 仓库的 Hadoop 依赖包、也没有你写的代码,所以 IDEA 会自动做两件事:
- 把你本地 Maven 仓库里的 Hadoop 依赖包(比如hadoop-common-2.7.jar、hadoop-hdfs-2.7.jar)上传到集群的临时目录(比如/home/master/mapRaduceTowTest/GCRzt2Z4Zt);
- 把你项目里的源码 / 编译后的 class 文件(比如src/main/java/example、target/classes)上传到集群指定目录(比如/usr/local/src/hadoopIdeaTest2)。
最后的结果













&spm=1001.2101.3001.5002&articleId=156092311&d=1&t=3&u=5b65461c6dcb42bf9d81cefffa79876e)

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










