






第一章:Introduction to Machine Learning
🔑 第一章核心考点
- ML定义 + AI/ML/DL关系
- 三类问题(Engineering/ML/Human)
- ⭐ 三种学习范式(监督/无监督/强化)
- ML = 函数近似 h:X→Y
- ML历史发展时间线(1950s→GenAI)
- ⭐⭐ ML生命周期 L→M→O→P(四阶段核心任务)
- ⭐ 归纳偏置(定义+必要性+来源)
- 课程工具链 + 评分
机器学习:机器学习是让系统通过数据改进(学习)性能的技术
基本配方的两步:
- 训练(Training):用数据(examples)来教(fit)一个模型 → 学习模型参数
- 推理(Inference):用训练好的模型对新输入做预测/决策
三类问题 ⭐
| 问题类型 | 定义 | 解决方式 |
|---|---|---|
| 工程问题(Engineering) | 可以用直接的、可指定的算法或规则解决 | 写代码/规则 |
| ML问题 | 容易演示/评估解决方案但难以直接实现 | 从数据中学习 |
| 人类问题(Human) | 无法精确定义,需要人类判断 | 工程+ML+人类 |
三种学习范式
| 范式 | 输入 | 目标 |
|---|---|---|
| 监督学习(Supervised) | {(X, Y)} 观测对 | 学习输入到输出的映射关系 |
| 无监督学习(Unsupervised) | {X} 仅有数据 | 发现数据内在模式 |
| 强化学习(RL) | X, reward(·) | 从奖励信号中学习策略 |
监督学习两大任务
| 任务 | 输出类型 | 例子 |
|---|---|---|
| 分类(Classification) | 离散标签 | 图像标签{Hot Dog, …} |
| 回归(Regression) | 连续值 | 股票预测、下一词预测 |
无监督学习两大任务
| 任务 | 说明 | 例子 |
|---|---|---|
| 聚类与密度估计 | 发现数据中的自然分组 | 图像压缩的近似表示 |
| 降维 | 将高维数据映射到低维 | 可视化、作为其他ML任务的预处理 |
ML生命周期(Lifecycle)⭐
L → P → M → O → P
| 阶段 | 英文 | 核心问题 |
|---|---|---|
| L | Learning Problem(定义问题) | 预测什么?用什么数据?如何评判成功? |
| M | Model Design(模型设计) | 选什么模型族/架构?特征工程?归纳偏置? |
| O | Optimization(优化) | 定义损失函数?选优化方法(GD等)?正则化? |
| P | Predict & Evaluate(预测与评估) | 基于评估指标测试模型性能 |
各阶段详解
L - Learning Problem:
- Target:我想预测什么?(ML任务类型)
- Objective:如何评估成功?(用什么损失函数)
- Data:有什么数据?数据表示?训练/测试划分?
M - Model Design:
- Feature Engineering(特征工程):选择特征、编码特征
- Model family/Architecture(模型族):选择假设空间
- Hypothesis space(假设空间)
- Inductive biases / Assumptions(归纳偏置)
O - Optimization:
- Define a loss(定义损失)
- Choose optimization method(选优化方法:GD/SGD/Adam等)
- Manage regularization & overfitting(正则化+防过拟合)
P - Predict & Evaluate:
- 基于evaluation metrics评估预测结果
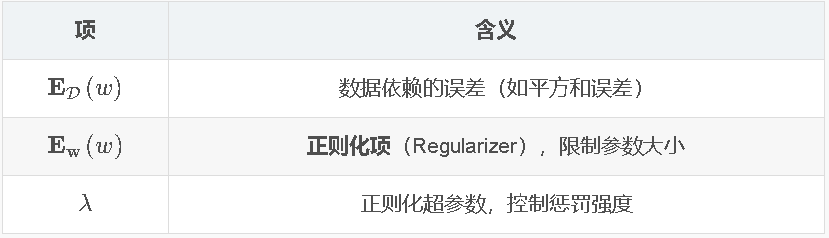
归纳偏置(Inductive Bias)
定义
学习算法在面对有限训练数据时,为了能对未见过的输入做出合理预测而引入的一组先验假设或偏好。
核心理解
- 给定有限训练样本→存在无限多个函数能完美拟合→但泛化性能不同
- 归纳偏置从无限可能中**"挑选"出更合理的解→实现泛化**
归纳偏置的来源
| 来源 | 例子 |
|---|---|
| 模型结构 | 选线性模型→假设数据线性可分 |
| 特征工程 | 用词袋模型→假设词序无关 |
| 正则化 | L2正则→偏好小权重 |
| 架构设计 | CNN→平移不变性 |
第二章
🔑 第二章核心考点
- L阶段三核心问题 + 数据理解
- ML分类体系(监督/无监督/强化→分类/回归/聚类/降维)
- ⭐⭐ 泛化 + Train-Val-Test三划分(考试类比)
- ⭐ 特征工程:One-Hot、标准化(公式+训练集μσ)、BoW、Embeddings
- 模型族:线性/逻辑回归、参数化vs非参数化
- ⭐ 归纳偏置 + No Free Lunch Theorem
- ⭐⭐ 欠拟合/Sweet Spot/过拟合 + 正则化调节
- 超参数+网格搜索 + 混淆矩阵+准确率
2.1 L - Learning Problem(定义学习问题)
L - Learning Problem:
- Target:我想预测什么?(ML任务类型)
- Objective:如何评估成功?(用什么损失函数)
- Data:有什么数据?数据表示?训练/测试划分?
2.1.1 ML任务类型
监督学习两大任务
| 任务 | 输出类型 | 例子 |
|---|---|---|
| 分类(Classification) | 离散标签 | 图像标签{Hot Dog, …} |
| 回归(Regression) | 连续值 | 股票预测、下一词预测 |
无监督学习两大任务
| 任务 | 说明 | 例子 |
|---|---|---|
| 聚类与密度估计 | 发现数据中的自然分组 | 图像压缩的近似表示 |
| 降维 | 将高维数据映射到低维 | 可视化、作为其他ML任务的预处理 |
2.1.2 理解数据 ⭐
| 检查项 | 问题 |
|---|---|
| 数据量 | N = ? 有多少样本? |
| 特征(Features) | D = ? 多少维度?分布如何?是否全是数值?是否有缺失? |
| 标签(Labels) | 是否有标签?离散还是连续?分布如何?是否有错误? |
泛化(Generalization)
模型在未见过的新数据上表现良好的能力。
Train-Test Split(训练-测试划分)
- 打乱(Shuffle)数据
- 按比例划分:训练集~80% + 测试集~20%
- 训练集:训练模型
- 测试集:仅使用一次评估泛化性能
Validation Split(验证集划分)
| 划分 | 类比 | 用途 |
|---|---|---|
| Train(训练集) | 练习题+答案 | 拟合/训练模型 |
| Validation(验证集) | 模拟考试 | 调模型设计、选超参数 |
| Test(测试集) | 正式考试 | 最终一次评估泛化能力 |
2.2 M - Model Design(模型设计)
2.2.1 Feature Engineering(特征工程)⭐
定义:从原始特征中选择和编码输入特征的过程。
数值特征编码
| 方法 | 适用场景 | 操作 |
|---|---|---|
| One-Hot Encoding | 类别特征(颜色、邮编等) | 每类别→一个二进制列 |
| Log变换 | 严重偏斜的特征(点击量、价格) | 取对数压缩尺度 |
| 标准化(Standardization) | 不同量级/方差的特征 |
文本特征编码 ⭐
| 方法 | 原理 | 特点 |
|---|---|---|
| One-Hot | 类别字符串→二进制列 | 适合短类别文本 |
| Bag-of-Words (BoW) | 词汇表中每词一列→计数 | 忽略词序、高维稀疏 |
| Learned Embeddings | LLM将文本→固定向量 | 语义丰富、现代主流 |
图像特征编码
| 方法 | 说明 |
|---|---|
| Flatten | 展平为向量,适合小尺寸单色图 |
| 变换(颜色空间/归一化) | 预处理 |
| 手工特征(边缘检测/纹理) | 传统CV方法 |
| 深度学习表示 | 用NN学习Embedding→现代主流 |
2.2.2 模型族(Model Family)
模型族:一类具有相同数学骨架,但参数不同的模型集合。
假设空间: 所有 w 生成的表达式,共同组成了这个模型族的假设空间。
线性回归模型族
- 输出连续的数值(如预测房价)
逻辑回归模型族(预览)
- 输出概率(如预测是猫还是狗,输出 0~1 之间的概率)。它在线性回归外面套了一层 Sigmoid 函数 σ(t)。
参数化 vs 非参数化模型
| 类型 | 参数量 | 例子 |
|---|---|---|
| 参数化(Parametric) | 固定(不依赖数据量) | 线性回归 |
| 非参数化(Non-Parametric) | 随数据增长 | K近邻(KNN)→"参数"=全部训练数据 |
2.2.3 归纳偏置与复杂度 ⭐
归纳偏置的来源
- 模型选择:选线性模型→假设线性关系
- 特征工程:BoW→假设词序无关
复杂度:欠拟合 vs 过拟合 ⭐
| 状态 | 表现 | 原因 |
|---|---|---|
| 欠拟合(Underfitting) | 训练和验证误差都高 | 模型太简单 |
| Sweet Spot | 训练和验证误差都低 | 最佳复杂度 |
| 过拟合(Overfitting) | 训练误差低、验证误差高 | 模型太复杂 |
正则化(Regularization)
- 在“模型族”的假设空间里,通过添加惩罚,把模型限制在一个“更简单”的子区域内
2.3 O - Optimization (优化)⭐
超参数(Hyperparameters)⭐
- 定义:优化过程中保持不变的参数(如λ)
- 通过验证集性能来选择
- 常用方法:网格搜索(Grid Search) → 遍历所有组合→选验证误差最小的
2.4 P - Predict (预测)
预测(Inference)两种形式
| 形式 | 输出 | sklearn方法 |
|---|---|---|
| 标签预测 | 最可能的类别/值 | model.predict() |
| 分布预测 | 类别概率 / 回归均值+方差(含不确定性) | model.predict_proba() |
评估指标:混淆矩阵
X/Y:X——预测是否正确 Y——预测的结果是什么
比如TP:预测正确T,预测结果是Positive;
比如FP:预测错误F,预测结果是Positive;
| 实际Spam | 实际Not Spam | |
|---|---|---|
| 预测Spam | TP | FP |
| 预测Not Spam | FN | TN |
第三章 Clustering and Probability 聚类与贝叶斯
🔑 第三章核心考点
- ⭐ K-means聚类:Lloyd算法(分配+更新交替)、目标函数、收敛性
- 肘部法则选K + 硬聚类 vs 软聚类
- Epistemic vs Aleatoric不确定性
- ⭐ 概率基础:联合/边缘/条件概率、乘法法则、独立性、IID
- ⭐⭐⭐ 贝叶斯定理:先验+似然→后验
- ⭐⭐ Wake Word基础率效应(99%检测率→仅9%阳性预测值)
- 疾病检测贝叶斯计算(类似Wake Word但换场景)
3.1 K-means硬聚类 ⭐
问题定义

目标函数(L2范数,欧氏距离平方)最小化每个点到其簇心距离之和
核心思想:每个数据点应尽可能靠近其被分配的聚类中心。
Lloyd’s Algorithm(交替最小化)
- 初始化:随机选择K个点作为初始中心μk
- Update Assignments(分配步):每个点分配给最近的中心
- Update Centers(更新步):重新计算每个簇的均值,更新簇心位置
- 重复1-2直到分配不再变化(收敛)
收敛性
- ✅ 保证收敛:交替最小化每一步都减少目标函数值
- ❌ 不一定是最优解:可能陷入局部最小值
如何选择初始化的K簇数量呢?
肘部法则(Elbow Method)⭐
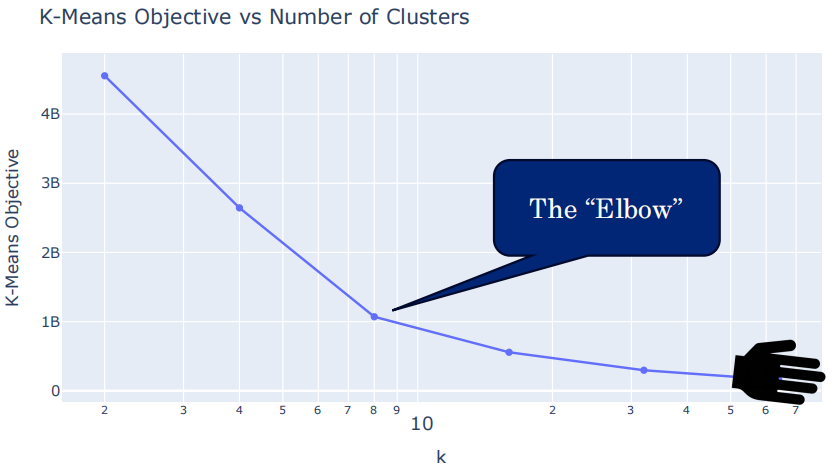
- 绘制 K-Means目标函数值 vs K 的曲线
- “肘部”= 增加K后目标函数改善递减最显著的位置
- 选择肘部对应的K值
聚类解释注意事项
- K-means输出簇标签→但不知道簇代表什么,可能对应类别,也可能对应其他因素
- 硬分配:每个点恰好属于一个簇
Pixel K-Means色数压缩
- 图像像素→RGB三维向量
- K-means聚类→用少数K种颜色渲染图像
3.2 不确定性 ⭐
| 类型 | 英文 | 含义 | 可消除? |
|---|---|---|---|
| 认知不确定性 | Epistemic | 有限训练数据和建模过程的系统不确定性 | ✅ 可约(更多数据/更好模型) |
| 偶然不确定性 | Aleatoric | 观测噪声带来的随机不确定性 | ❌ 不可约 |
3.3 概率论复习 ⭐⭐

你带着“夏天不常下雨(20%)”的老观念(先验=今天下雨的概率),看到了“乌云”这个新事实(观测=下雨时有乌云的概率),最终算出了一个更靠谱的“今天极可能下雨(75%)”的新观念(后验=有乌云今天下雨的概率)。用新证据修正旧观点。
Wake Word检测器示例

第四章 概率论与软聚类
4.1 期望与方差

4.2 概率密度函数
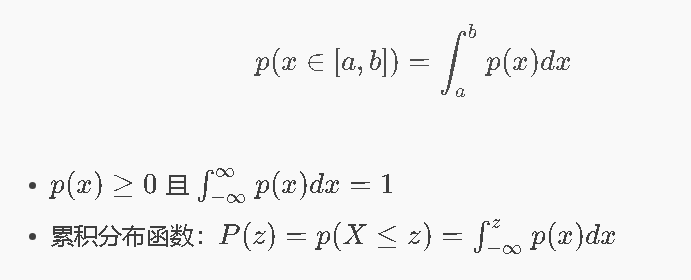
4.3 密度估计与MLE
充分统计量:参数完全描述了对μ估计所需的所有信息
两种估计方法
| 方法 | 目标 | 学派 |
|---|---|---|
| MLE(最大似然估计) | 频率学派 | |
| MAP(最大后验估计) | 贝叶斯学派 |
MLE的思想是发生的都是大概率事件,因此求这个概率的最大值,对所有样本D的发生概率连乘,然后对其求导,找到最大值点,此刻的参数就是最有可能的参数
建模(写对数似然)+ 优化(求导→临界点→验证)
为什么取对数:连乘变加和,防下溢且易于求导;单调性不变;



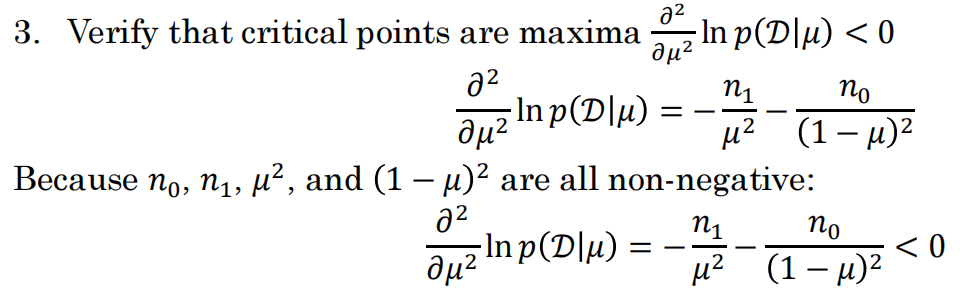
由概率函数连乘,然后先取对数后求导,令导数为0,得到极值点时的参数μ,然后对求导函数求二阶导,验证是否是极大值点,弱为负则结束。
怎么取对数?
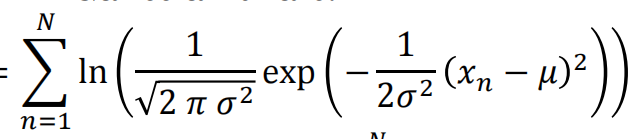
注意求和符号的化简,只有含xn的非常数项不可以化简,其他常数项可以乘以N计科。


偏差分析 ⭐
偏差

有偏的(偏小),真正的无偏估计分母为N-1
4.6 高斯分布
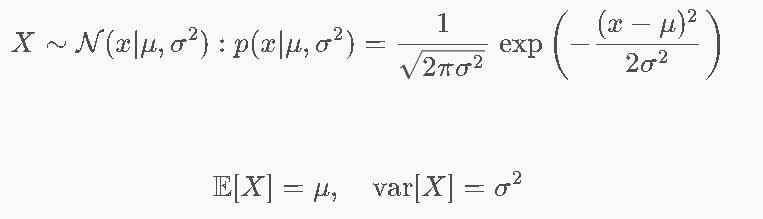
无偏的
有偏的(偏小),真正的无偏估计分母为N-1
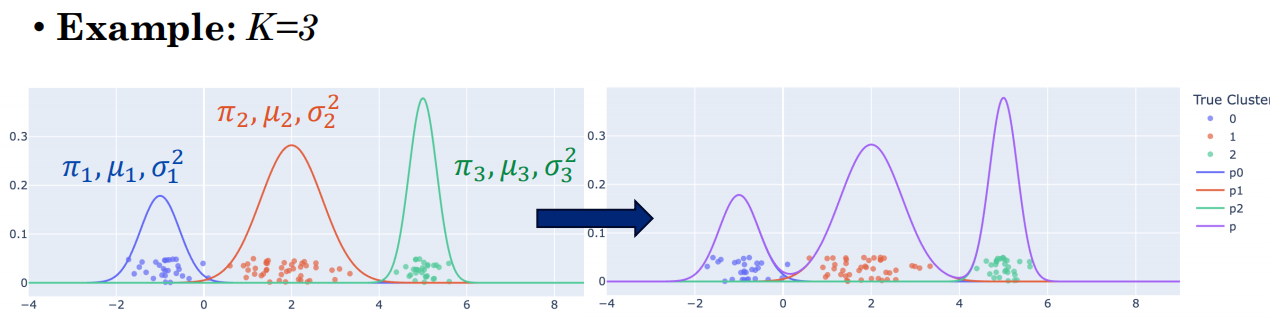
4.7 高斯混合模型(GMM)⭐⭐——软聚类问题

这个世界上的数据太复杂了,一个简单的圆球(一个高斯分布)根本包不住。那我就搞 K 个圆球(比如 3 个),把这堆数据盖住。
这样一个数据点就有不同的概率属于不同的簇类了。
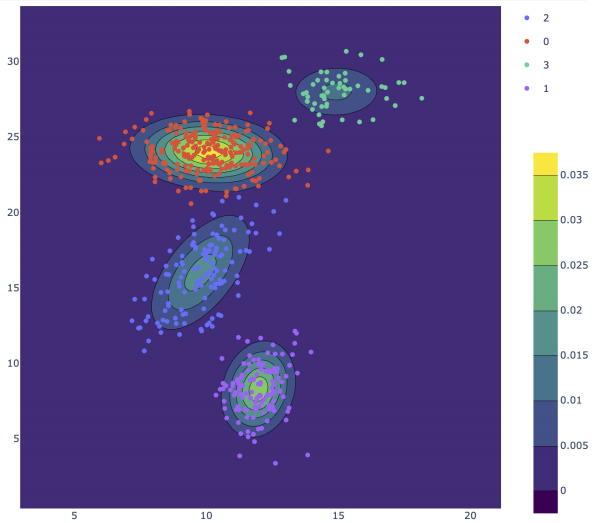
GMM vs K-Means ⭐
| 特性 | K-Means | GMM |
|---|---|---|
| 聚类类型 | 硬聚类 | 软聚类(概率归属) |
| 簇形状 | 球形 | 任意椭圆(可拉伸、旋转) |
| 输出 | 标签 | 标签 + 归属概率 |
| 优化 | Lloyd’s | EM算法 |
| 数学本质 | 距离最小化 | 概率密度最大化 |
-
K-Means(硬分类): 有一个数据点来了,它必须属于 1 号簇,或者必须属于 2 号簇,非黑即白。它把簇看成完美的圆(距离中心一样远)。
-
GMM(软分类): 有一个数据点来了,它可以“有 80% 的概率属于 1 号簇,20% 的概率属于 2 号簇”。并且,它的簇是可以拉伸、旋转成任意椭圆的。
-
-
结论: GMM 比 K-Means 更细腻、更灵活。
4.8 EM算法 ⭐⭐
GMM (EM) 的本质是“概率生成”:它不仅在找簇中心,更是在重新构造这 K 个“椭圆”的大小、方向、以及混合比例。


1.初始化
利用先验知识(K-Means 的结果)初始化模型参数 θ(包括均值μ 协方差Σk 混合权重Πk)
2.交替执行E步和M步,直到收敛
Expec步:
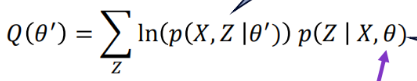
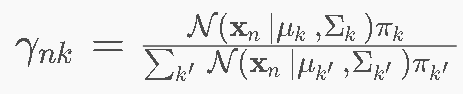
目标:利用当前(上一轮M步算出的θ)参数 θ,计算隐变量 Z 的后验分布(即各点属于各簇的软归属概率)
Max步:
![]()
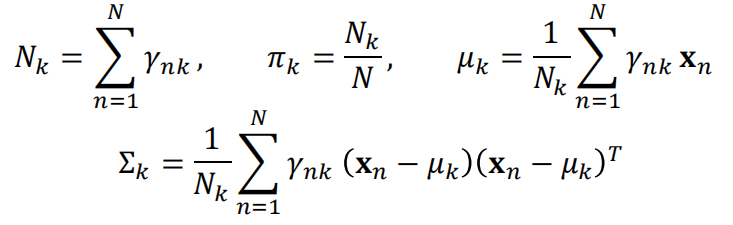
利用在 E步 中算出的隐变量后验概率(软分配),最大化 E-Step 中构造的期望对数似然函数 Q(θ′)。
求解出使期望对数似然最大的新参数 θ。
3. 终止判断
当参数θ的变化量小于预设值或达到迭代步数时终止。
第五章 线性回归
🔑 第五章核心考点
- 线性模型 = 对参数w线性(
也是线性模型)
- ⭐ 基函数(多项式/RBF/Sigmoid/正弦)= 不同归纳偏置
- 增广输入→ 向量化
- ⭐⭐ 误差函数(二次凸函数)
- ⭐⭐⭐ 正规方程+ 闭式解推导
- ⭐⭐ 几何正交投影解释()
- 评估指标:MSE/RMSE/R²/MAE/MAPE + 残差图
5.2 基函数(Basis Functions)⭐

"线性"的含义->权重是一次的 ⭐
线性模型 = 对参数w线性,而非对特征x线性!
引入非线性基函数 →y=w0+w_1x^2+w_2x^3
-
基函数 ϕ(x)=x^2,x^3 是非线性的(曲线)。
-
但是,对参数 w 来说,它依然是线性的!(因为 w1 没有平方,没有互相乘,只是单纯乘在 x2 上面再加起来)。
如何用数学方法,找到一条最完美的直线(或者高维的超平面),去拟合我们手里的数据。
第一模块:把“写方程”变成“算矩阵”
通过引入x0=1将截距项w0统一纳入向量化计算
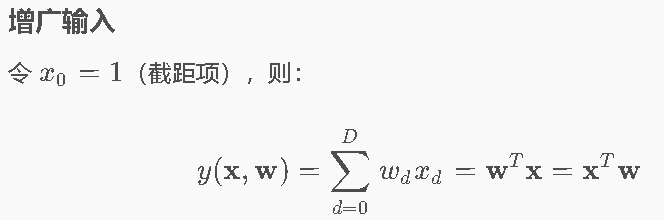
第二模块:怎么算模型的“分数”?
5.4 误差函数 ⭐
平方和误差(Sum of Squares)
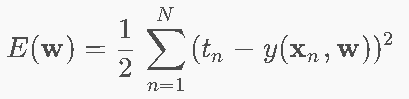
5.5 误差最小化:正规方程 ⭐⭐⭐
E(w)是关于w的非负二次函数,求导一定可以得到极大值点时的w。
求导后令导数为0的方程就是正规方程
正规方程(Normal Equations)
![]()
在等号两边同时乘以XTX的逆矩阵,得到闭式解:
闭式解(Closed-Form Solution)
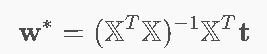
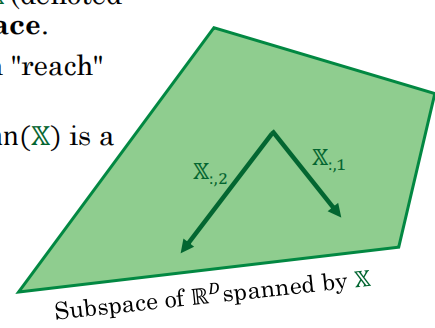
5.6 几何解释 ⭐⭐
两种视角
视角1(行视角):每行=一个数据点的预测
视角2(列视角):预测Y = X各列的线性组合
张成空间:基向量通过拉伸缩短后组成的向量,所有能到达位置的集合,即一个空间。
假设特征维度D=2,那么张成空间就是平面。
而真实值是带有噪声的,因此肯定会偏离这个平面,那么目标就转化为,如何在这个平面内找到一个与t最接近的向量。
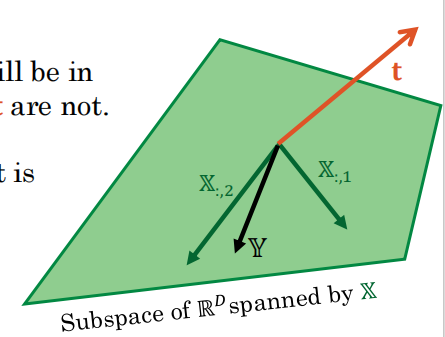
那显然是投影的时候是最近的:这个残差向量就是e=(t-Xw) Xw就是要找到向量。这个w就是要找的权重。所以说,Y是t在张成空间内“正交投影”。
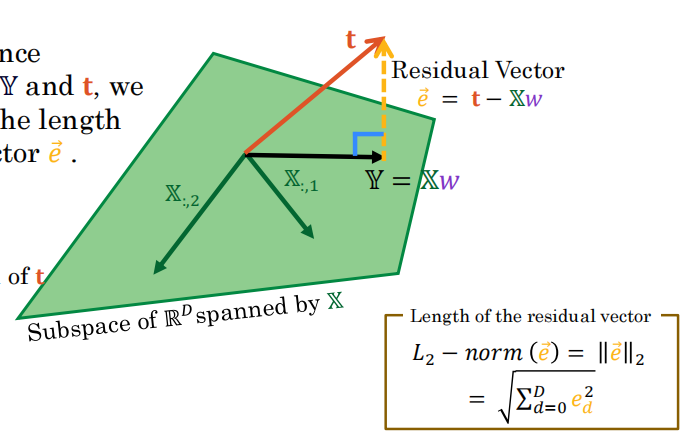
如何求这个投影呢,正交就说明e要与整个平面是垂直的,因此与X的所有列正交
那么我们可以解出

这就是正规方程了。
5.7 评估指标 ⭐
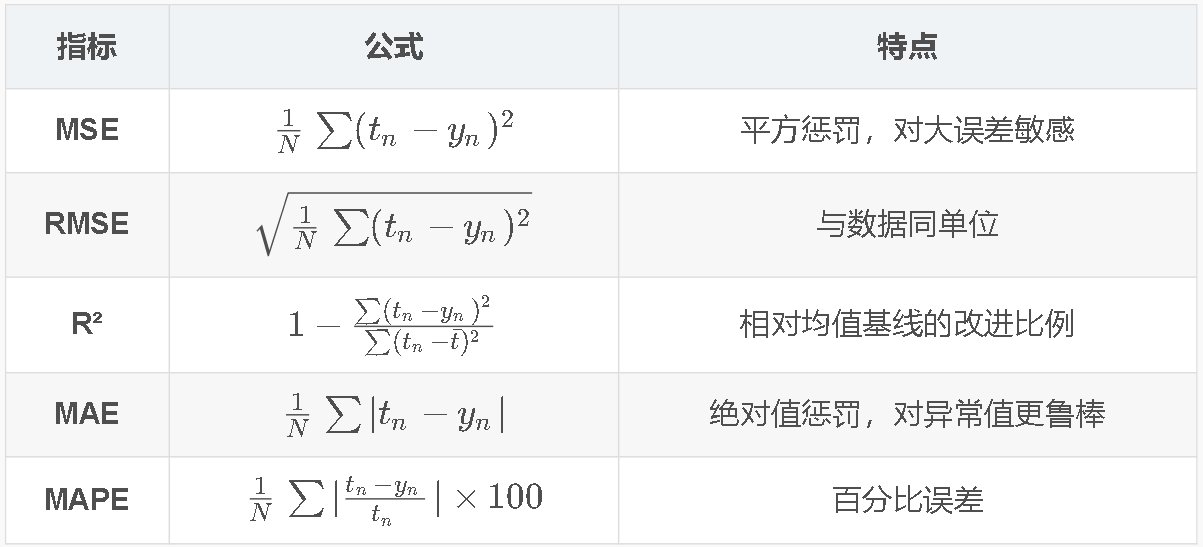
R越大越好,=1时MSE=0,说明无偏。=0时说明和均值一样。<0时说明MSE>预测MSE,拉爆了

第六章 线性回归2——正则化
6.1 正则化概述 ⭐
过拟合回顾
- 模型太复杂→过拟合→需要正则化
- 正则化 = 在学习过程中添加约束或惩罚→改善泛化
正则化框架
![]()
拉格朗日松弛
我们可以证明,上式等价于下面的式子,即:在找最低点时,要求Reg(w)<C
- 原约束:
- 松弛后:
- 约束→惩罚项(拉格朗日乘子法思想)
而这个Reg正则化函数就会引申出下面两种正则化方法:
6.2 范数(Norms)
范数三性质
- 正定性:
- 正齐次性:
- 三角不等式:
常见范数
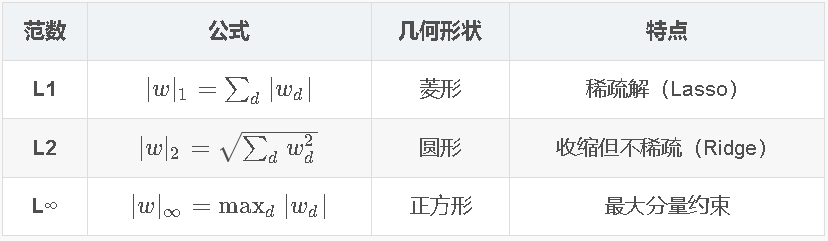
6.3 L1正则化(Lasso回归)
目标函数
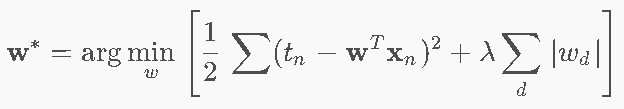
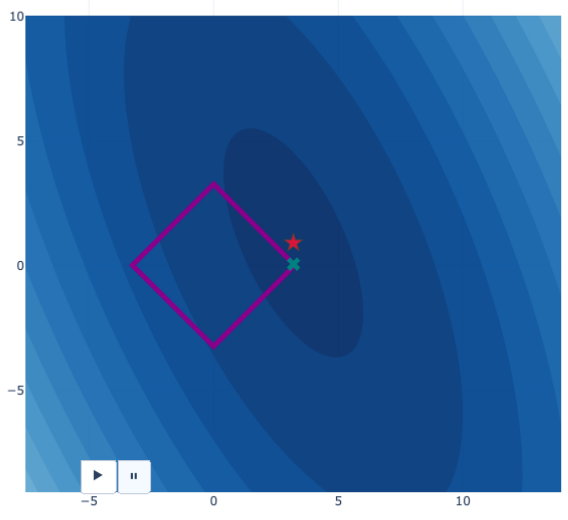
深色代表误差越小,显然★是最小点,但是Lasso回归要求取值在菱形范围内,因此取到了右尖角这个靠近★的点
这里强制令w1=0 w2=λ了,解是[0,λ]。在高维空间,也很容易取到棱角点,导致一堆0出现,比如w=[0,0,5.2,0]
L1正则化因此容易出现稀疏解。
此外,L1正则化也没有闭式解,必须迭代优化。
6.4 L2正则化(Ridge回归)⭐⭐⭐
目标函数
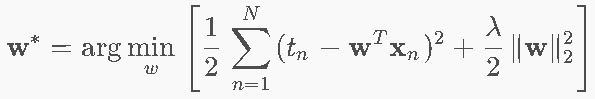
闭式解(Ridge正规方程)⭐
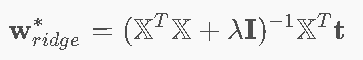
普通正规方程:![]()
多了一个λI项,就是其主对角线变得有值了,确保整体是可逆的,有闭式解。
而且各个列都会有一定的值,可以保证是稠密解,比如w=[1.2,−0.5,3.8,0.1]
λ的作用
- λ=0:退化为普通最小二乘
- λ→∞:所有权重→0(仅剩截距)
- λ适中:收缩权重→降低复杂度→防过拟合
L1 vs L2对比
| L2 (Ridge) | L1 (Lasso) | |
|---|---|---|
| 惩罚项 | ||
| 解的特点 | 权重收缩但不为0 | 稀疏(部分权重=0) |
| 几何 | 圆形约束区域 | 菱形约束区域 |
| 有闭式解 | ✅ | ❌(需迭代优化) |
| 特征选择 | ❌ | ✅ 自动 |
6.5 正规方程的问题与修复 ⭐

条件数,就是用来衡量这个矩阵 A 有多“容易求逆”、有多“敏感”的指标。指的是椭圆两个方向的拉伸程度。靠近1越好。
修复1:Ridge Trick ⭐
![]()

强行在矩阵里加上一个 λI,直接保证 (XTX+λI) 一定满秩、可逆。在每个特征值上加λ→缩小条件数→稳定求逆
修复2:Moore-Penrose伪逆
Σ是对角矩阵。对于小值归零,非零奇异值直接翻转。

修复3:随机梯度下降(SGD)

放弃“一步算完(闭式解)”,改用“一次看一个样本,逐个更新参数”的方式。
SGD每次使用一部分训练数据计算梯度。BGD用全部训练数据计算。
第七章 最小二乘(MSE 最小化损失函数)=最大似然(MLE 猜测参数)
🔑 第七章核心考点(虽然短但极其重要)
- ⭐⭐⭐ 最小二乘⇔MLE:高斯噪声假设下完整推导
-→ 最大化似然=最小化误差
- ⭐⭐ 噪声模型↔误差函数:高斯→MSE,拉普拉斯→MAE
- 误差函数=对数据噪声分布的隐含假设
-不影响
(常数缩放因子)
- MLE正规方程=最小二乘正规方程
7.1 最小二乘 = 最大似然 ⭐⭐⭐
猜测最优参数的目标=最大化这种可能发生的概率=使得这个拟合函数的误差最小
加性高斯噪声假设

这是我们要拟合的数据,是由某一个函数y叠加上一层高斯噪声形成的。
似然函数
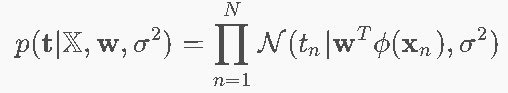
对数似然
我们的目的是找到一个w,使得这种情况发生的概率最大:因此使用MLE找到这个w
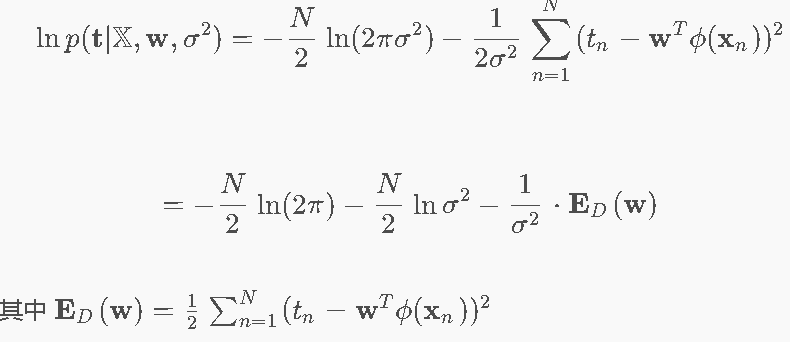
我们意外发现,最大化这个函数,就是最小化最后的ED。
而ED恰好是MSE误差函数的表达式。
同样的,不仅仅是在高斯噪声假设下有这样的结论。
在拉普拉斯噪声下也存在:
7.2 噪声模型 ↔ MLE对应不同的误差函数 ⭐⭐
这意味着,求叠加了高斯噪声的数据下,最可能的w值=最小化MSE;
求叠加了拉普拉斯噪声的数据下,最可能的w值=最小化MAE。

- 使用MSE → 隐含假设噪声是高斯分布(对大误差惩罚重,误差平方增长,会去拟合异常值)
- 使用MAE → 隐含假设噪声是拉普拉斯分布(对异常值更鲁棒,误差线性增长,对异常值不敏感)
那么,其实,只要我们知道这个数据叠加了高斯噪声,那么求取MLE,就是求取MSE,而求取MSE最小值可以直接用闭式解解答(5.4章)。无需再用MLE那一套(建模(写对数似然)+ 优化(求导→临界点→验证)4.3章)

基函数变化

第八章 先验与正则化的关系 方差与偏差的取舍
🔑 第八章核心考点
- ⭐⭐ MAP估计 = MLE + 先验信念
- ⭐⭐⭐ 偏差-方差分解:Error = Noise + Bias² + Variance(完整推导过程)
- ⭐⭐ $\lambda$的偏差-方差效应:$\lambda$↑→Bias↑+Variance↓
- 偏差-方差权衡U型曲线 + 最优$\lambda$通过验证集选择
- MLE vs MAP:频率学派 vs 贝叶斯学派
-
MLE(频率学派):只看数据。哪个参数能让“当前观测到的数据”出现概率最大,我就选谁。它认为数据代表一切。问题:数据少,或者数据里有噪音,它就会死记硬背,导致过拟合。
-
MAP(贝叶斯学派):数据 + 经验。它不仅看数据,还会考虑到“在这个数据发生之前,我主观上觉得参数大概率是什么样的(先验)”。
 ‘取负对数→最大化→最小化:
‘取负对数→最大化→最小化:
![]()
也就是说,要最大化WMAP,就是要最小化这个式子。
巧合的是,如果w满足高斯分布
高斯先验 → Ridge
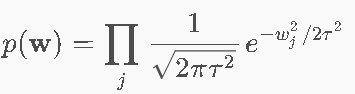
那么对其取ln,就会得到这一个带w方的项,类似于权重约束项:
带入后,会发现,正好可以凑成岭回归L2的式子:
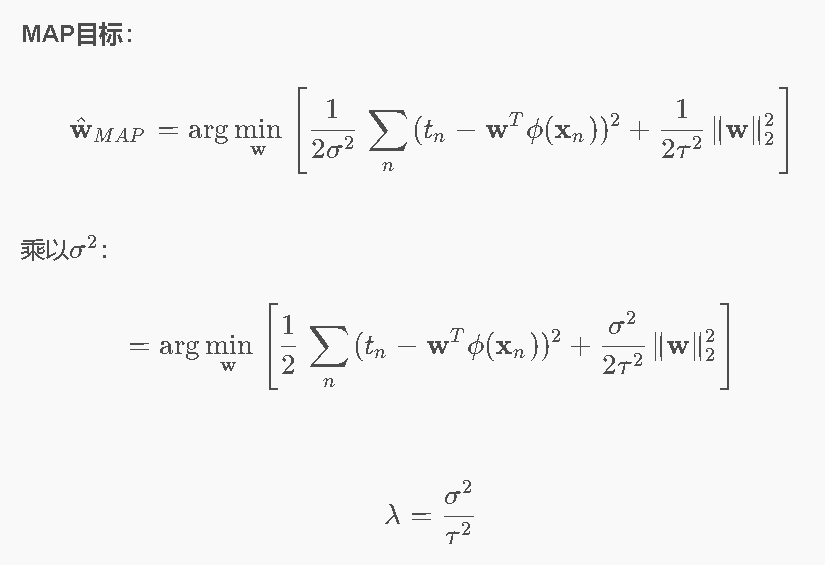
最终结论:MAP(高斯先验)= 岭回归(L2 正则化)!
L2正则化 = 假设权重服从高斯先验分布
λ=σ2/τ2:数据噪声大→λ大,约束越强;先验强(τ2小)→λ大,先验越确定,约束越强。
同理,我们可以得到:
拉普拉斯先验 → MAP ⇔ L1 正则化 (Lasso)
注意和上一章区分,上一章的结论是,
叠加高斯噪声的MLE = MSE(可以联想记忆,L2是平方约束,MSE是平方误差)
叠加拉普拉斯噪声的MLE=MAE
13. 在硬币例子中,先验h0=t0=5,观测到HH两次正面后,MAP后验均值约为?
A. 1.0(仅看数据)
B. 0.5(仅看先验)
C. 0.58(先验+数据折中)
D. 0(无信息)



8.2 偏差-方差分解 ⭐⭐⭐
学习的基本挑战
- 拟合数据:解释已观测到的
- 泛化到世界:预测未来、解释未观测到的
三个误差来源
| 来源 | 定义 | 可控? |
|---|---|---|
| 噪声(Noise) | 数据固有随机波动 | ❌ 不可控(通常) |
| 偏差(Bias) | 单一数据集期望预测值与真实值之间的偏差 | ✅ 模型选择 |
| 方差(Variance) | 在不同数据集上得出的结果 | ✅ 模型复杂度 |
假设 ,
,



偏差-方差权衡图
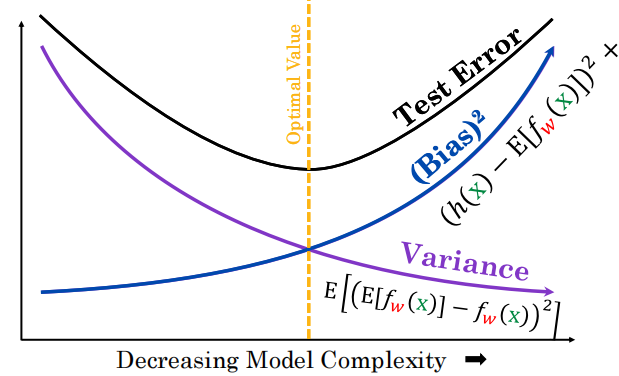
复杂度越高,在训练集上拟合越好,因此偏差低。但在测试集上拟合拉爆,因此方差高。
方差衡量多个数据集的,偏差衡量单个数据集的。
λ的偏差-方差效应
- λ小→模型复杂→低偏差+高方差(过拟合)
- λ大→模型简单→高偏差+低方差(欠拟合)
如何控制模型复杂度
| 方法 | 效果 |
|---|---|
| 特征数量 | 减少→更简单→更高偏差+更低方差 |
| 特征选择 | 选不同基函数→不同偏置 |
| 正则化λ | λ↑→更简单→更高偏差+更低方差 |
第九章 逻辑回归1 从回归走向分类问题
🔑 第九章核心考点
- ⭐ 分类任务类型(二分类/多分类/结构化)+ 为什么不能用MSE
- ⭐ Sigmoid函数性质(值域/对称/导数)
- ⭐⭐ 逻辑回归模型(广义线性模型)
- ⭐⭐⭐ 交叉熵损失:MLE推导+MSE对比(非凸有界 vs 凸无界)
- 线性可分→$w$→∞→正则化必需
- 梯度(无闭式解)
- 决策=后验+损失→阈值/拒绝选项
这一章教了你两件大事:
-
怎么把之前学的线性回归,改造成能预测“概率”的分类器(逻辑回归模型)。
-
为什么分类问题不能用传统的“平方误差(MSE)”,必须用“交叉熵误差(Cross-Entropy)”
9.1 分类任务
三种分类问题
| 类型 | 输出 | 例子 |
|---|---|---|
| 二分类(Binary) | y∈{0,1} | 垃圾邮件检测、疾病诊断 |
| 多分类(Multi-class) | y∈{1,…,K} | 图像标注、情感分析 |
| 结构化预测 | 结构化对象 | 翻译、ChatGPT |
基函数扩展
![]()
- 基函数可将非线性可分数据映射到线性可分空间
为什么不能直接用最小二乘 MSE?⭐⭐
| 问题 | 说明 |
|---|---|
| 输出范围不匹配 | 线性回归输出(−∞,∞),但分类需要[0,1] → 截断不自然 |
| MSE非凸 | 在逻辑回归参数空间中MSE有多个局部最小值 |
| MSE惩罚有界 | 最大误差被封顶在1(预测值限于[0,1],标签0/1 → MSE≤1) |
| 高斯噪声假设不成立 | 最小二乘隐含高斯噪声→不适用于{0,1}二值数据 |
结论:分类需要新的模型+新的误差函数!
9.2 Sigmoid函数 ⭐
定义
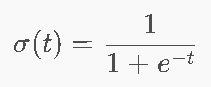
性质

9.3 逻辑回归模型 ⭐⭐
模型形式
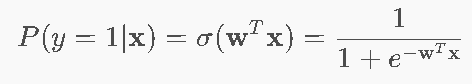
![]() (关于0,0.5对称)
(关于0,0.5对称)
19. 逻辑回归中,权重w的大小决定了什么?
A. 决策边界的方向和Sigmoid曲线的陡峭程度
B. 仅决策边界的方向
C. 仅数据量
D. 不决定任何东西
9.4 交叉熵损失函数 ⭐⭐⭐
MLE推导
似然函数(伯努利分布):最大化:(当标签tn=1时,输出sigmoid=1的概率;当标签tn=0时,输出(1-sigmoid=1)的概率)
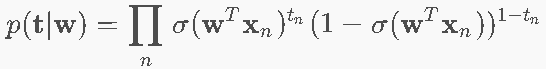

负对数似然 = 交叉熵(Cross-Entropy):
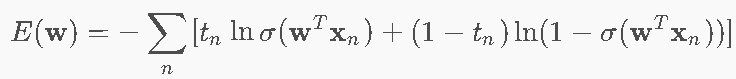
交叉熵的直观理解

32. 交叉熵损失对所有错误同等惩罚,不管错得有多离谱。( )
MSE vs 交叉熵对比 ⭐⭐
| MSE | 交叉熵 | |
|---|---|---|
| 凸性 | ❌ 非凸(多局部最小值) | ✅ 凸函数(保证全局最优) |
| 惩罚 | ❌ 有界(最大=1) | ✅ 无界:错得离谱→损失→∞ |
| 优化 | 可能陷入局部最小值 | 梯度下降→全局最优 |
9.5 正则化与优化
痛点 1:为什么没有直接的公式?
-
症状:之前学线性回归,有“正规方程”一步出答案(闭式解)。
-
原因:逻辑回归的损失函数(交叉熵)里包含了非线性函数 Sigmoid。你对它求导等于 0 后,发现这个方程解不出来,是一个非线性方程。
-
解法:没有闭式解,就只能一步步去逼近。
痛点 2:数据是“线性可分”时,权重会疯狂变大(过拟合)
-
发生了什么? 如果你的两类数据(红点和蓝点)完全被一条直线完美分开了,逻辑回归为了让预测概率无限逼近 1 和 0(更有自信),它的权重 w 会被推得越来越大(趋向于无穷大)。曲线会变成直上直下的阶跃函数。
-
后果:这种“迷之自信”会导致严重的过拟合。如果测试集里出现一个极其微小的异常点,模型就会被瞬间带偏。
-
解法:必须加正则化!
梯度(用于优化)
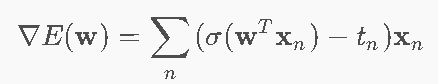
误差(pn−tn)乘输入xn → 与线性回归梯度类似。
9.6 决策 = 后验 + 损失
决策方式
- 默认:P(y=1∣x)>0.5 → 预测类别1
- 可调整阈值(考虑不等代价)
- 拒绝选项:当概率在[1−θ,θ]之间时拒绝决策
22. 逻辑回归直接输出类别标签(0或1)。( )
第十章 逻辑回归2 从二分类到多分类 以及 P评价指标
🔑 第十章核心考点
- ⭐ 多分类:OvR/OvO + ⭐⭐ Softmax函数(推导+计算)
- ⭐ 混淆矩阵(TP/TN/FP/FN → 依赖阈值)
- ⭐⭐ Accuracy陷阱(不均衡时失效)+ Precision/Recall/F1
- ⭐ Precision-Recall权衡(阈值调节)
- ⭐ ROC曲线与AUC(FPR-TPR空间→整体排序能力)
- 阈值选择:遍历法+期望损失最小化
10.1 多分类 ⭐
两种朴素方法
| 方法 | 策略 | 分类器数量 |
|---|---|---|
| One-vs-Rest (OvR) | K 个类别。我们每次只训练 K 个独立的二分类器
| K个 |
| One-vs-One (OvO) |
每对类一个二分类器
| K(K-1)/2个 |
以及,softmax函数,能输出概率分布!
Softmax函数 ⭐⭐
问题:将K个分数(logits) a1,…,aK 转为概率分布
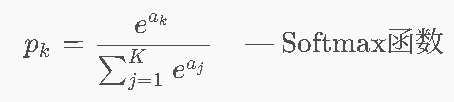
-
特点:它能输出一个概率分布。比如输入一张图,它输出:猫 0.1,狗 0.2,鸟 0.7。最关键的是,这三个概率加起来等于 1。只有 Softmax 能真正做到“兼顾所有类别的概率”。
-
Soft(软化/平滑):如果你几个分数差不多,指数函数放大的效果没有那么绝对,就会分到比较平滑的概率,而不是非黑即白的 0 或 1。
-
Max(最大值化):指数函数 e^ak 有“放大效应”。如果你有一个分数很高,e^ak 就会极其巨大,算出来的概率就会无限逼近 1,别的类别概率接近 0。
19. Softmax函数中,若所有ak同时加一个常数c,输出概率是否改变?
A. 改变
B. 不改变(分子分母的e^c抵消)
C. 取决于c的大小
D. 只有c=0时不改变
10.2 混淆矩阵 ⭐
| 预测0 | 预测1 | |
|---|---|---|
| 实际0 | TN(真阴性) | FP(假阳性) |
| 实际1 | FN(假阴性) | TP(真阳性) |
- 混淆矩阵依赖于:分类器 + 数据集 + 概率阈值
10.3 评估指标 ⭐⭐
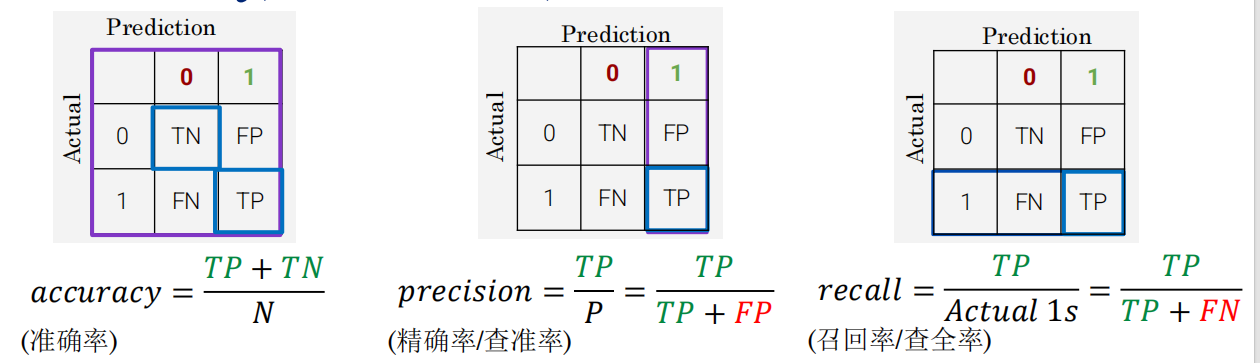
猜对的/猜测的——减低FP(precision) 以假乱真
猜对的/全部为正的——降低FN(recall) 漏选的
Accuracy(准确率)
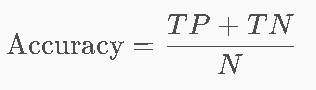
陷阱:类别极度不均衡时无效!
- 100封邮件5封垃圾→全预测"非垃圾"→准确率95%→但垃圾全漏!
Precision(精确率/查准率)⭐——认为的 有多少是真的->防止以假乱真

所有预测为正(认为都是真的P)的样本中,真正为正的比例。惩罚FP(把假的当作真的)。
Recall(召回率/查全率)⭐——实际上 有多少正确的被检测出来了->防止漏查真的
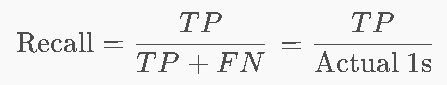
所有真正为正(分对的真和分错的假)的样本中,被正确检出的比例。惩罚FN(把真的当作假的)。
Precision vs Recall 权衡
| 阈值 | Precision | Recall | TP | FP |
|---|---|---|---|---|
| 升高 | ↑ | ↓ | 不变或↓ | ↓ |
| 降低 | ↓ | ↑ | ↑ | ↑ |
阈值降低,更多人能以假乱真的FP,Precision降低了。同样的,漏查的人就少了FN,Recall上升了。(以假乱真的人少了,漏选的人就多了)
TPFP和阈值反着变。
- Precision和Recall通常负相关→需权衡
- FP和FN可能有不同的代价→需根据业务调整
8. 提高分类的概率阈值会导致?
A. TP增加
B. TP不变或减少
C. FP增加
D. FN减少
F1 Score ⭐
-
为了综合考量这俩指标,引入 F1。它是 Precision 和 Recall 的调和平均数。
-
为什么不用简单的算术平均?因为如果一个是 1,一个是 0,算术平均是 0.5,而调和平均是 0。F1 对“偏科”非常严厉。只有在两者都高的时候,F1 才会高。

- Precision和Recall的调和平均数
- 适用于类别不均衡场景
- 选择使F1最大的阈值
10.4 ROC曲线与AUC ⭐——通过遍历阈值绘制
FPR和TPR

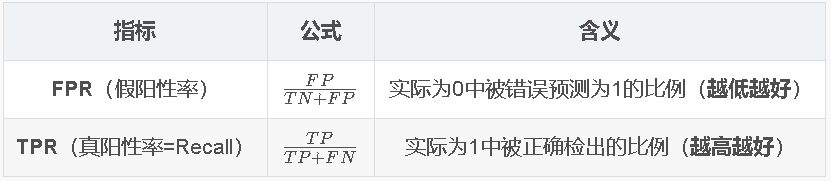
ROC曲线
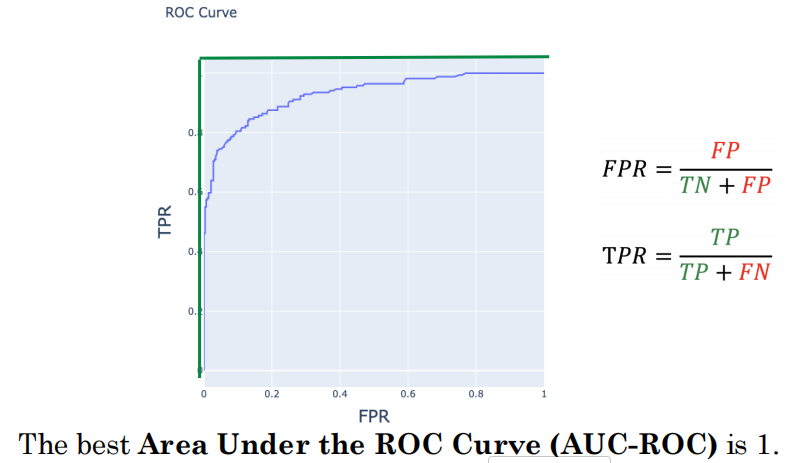
- 横轴:FPR(假阳性率) | 纵轴:TPR(真阳性率)
- 不同阈值→不同(FPR, TPR)点→连成ROC曲线
- 阈值低→FPR高+TPR高 | 阈值高→FPR低+TPR低
- 左上角(0,1)→完美分类器
AUC(Area Under Curve)
- AUC=1:完美分类器
- AUC=0.5:随机猜测
- 真实分类器:AUC在0.5~1之间
- AUC不依赖具体阈值→衡量分类器的整体排序能力
10.5 阈值选择策略
遍历阈值法
- 训练模型→对验证集预测概率
- 对T=0.01, 0.02, …, 0.99:
- 概率转0/1预测→计算指标
- 选使目标指标最优的T
选择标准
- 一般任务→最大化F1或Accuracy
- 不等代价→最小化期望损失(结合损失矩阵)
第十章总结
-
一看到多分类:想到 Softmax(输出和为 1 的概率)和 OvR/OvO。
-
一看到“类别极度不平衡”:立刻反应出 Accuracy 无效,必须用 Precision 和 Recall。
-
一看到问“如何兼顾 Precision 和 Recall”:立刻答 F1 Score(调和平均数)。
-
一看到 ROC:想到 横轴 FPR,纵轴 TPR。
-
一看到 AUC:想到 0.5 是瞎猜,1 是完美。AUC 用来衡量模型在不依赖特定阈值时的整体排序能力。
-
一看到“如何选阈值”:如果误报和漏报代价不同,就用损失矩阵(代价敏感学习)来算;否则最大化 F1 或 Accuracy。
1. 阈值和 TPR、FPR 是什么关系?(一对多)
-
阈值:是你人为定的一个切分点(比如 0.5、0.7 等)。
-
动态变化:当你每调整一次这个阈值(比如从 0.1 调到 0.9),模型对正负样本的划分就会改变,从而算出一组全新的 (FPR, TPR)。
-
一个阈值,对应一对 (FPR, TPR)。
2. 那 ROC 曲线是怎么画出来的?
-
ROC 曲线:就是你把“无数个不同的阈值”带来的【无数对 (FPR, TPR)】,全部作为点标在坐标系里,然后把它们连成一条线。
-
ROC 曲线。你根本不知道那上面的具体某一个点是用的什么阈值,但那条完整的线,代表了这个模型在所有阈值下的整体性能。
3. 那 AUC 到底刻画了什么?
-
AUC(曲线下面积):就是算一下 ROC 那条曲线正下方覆盖的面积。
-
AUC 刻画的核心含义(极其重要,必须背下来):
AUC 等价于:随机抽取一个正样本和一个负样本,模型将正样本排在负样本前面的概率。
-
为什么不直接看 TPR 和 FPR?
因为 TPR 和 FPR 都是一对一的,你选 0.5 阈值时 TPR 是 0.8,选 0.2 阈值时 TPR 可能变成 0.95。单看某一个点的指标,无法代表模型的“全局实力”。 -
AUC 的作用:
AUC 把那条线压缩成了一个 0 到 1 之间的具体数字。它告诉你:抛开我们选什么阈值不谈,这个模型本身的“区分能力”到底有多强。-
AUC = 0.5:代表模型的排布能力等于瞎猜(扔硬币)。 -
AUC = 1:代表无论怎么调阈值,模型都能完美地把正样本排在负样本前面(完美模型)。
-
也就是说,一个模型的每个阈值会输出一对TPR FPR,有可能0.1在左下,0.2在右上,0.3在中间,由曲线是无法得知具体其的对应阈值的。他只能衡量模型的全局水平。如果有两个模型,M1的AUC>M2的AUC,由于曲线和点不是一一对应的,因此无法得知其Accuracy水平如何。
第十一章 O优化与梯度下降
🔑 第十一章核心考点
- 优化问题形式 + 凸函数定义
- ⭐ 梯度(最陡上升方向)+ Hessian(曲率+临界点类型判断)
- ⭐⭐ GD算法:+ 收敛条件
- 条件数(小=良态=快)
- ⭐ 动量:平坦方向加速() + 震荡方向减速(
)
11.1 优化问题
一般形式
![]()

凸函数 ⭐ 两点间的函数值 ≤ 割线上的值
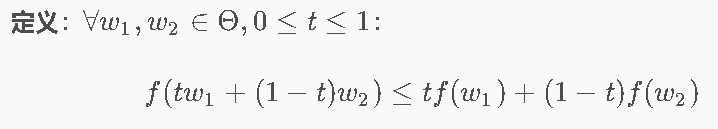
凸集:集合中任意两点连线仍在集合中。
- 凸函数+凸约束→可高效求解
- 最小二乘、逻辑回归→凸
- 深度学习→非凸(但仍用凸优化技术)
11.2 梯度与Hessian ⭐
梯度 一阶导 定方向
- 梯度指向最陡上升方向
- 梯度=0 → 驻点(最小值/最大值/鞍点)
- 梯度在定义域中(不在函数曲面上)
18. 梯度位于何处?
A. 在函数曲面上
B. 在参数空间(定义域)中
C. 在数据空间中
D. 在输出空间中
Hessian矩阵 二阶导 定最值点
- 特征值决定临界点类型:
| 特征值 | 驻点类型 |
|---|---|
| 全部>0 | 局部最小值 |
| 全部<0 | 局部最大值 |
| 混合 | 鞍点 |
19. Hessian矩阵的大小是?
A. D×1D×1
B. 1×D1×D
C. D×DD×D
D. N×NN×N
11.3 梯度下降算法 ⭐⭐
核心公式
![]()
超参数:

停止条件:权重变化 < 阈值ϵϵ
为什么叫"Batch" GD
每次更新使用全部训练数据计算梯度
损失曲线
- 训练误差:持续下降
- 验证误差:先降后升→过拟合→选验证误差最低点
11.4 二次近似与收敛性 ⭐⭐ 我觉得大概率不会这么细
二阶泰勒展开

GD收敛条件
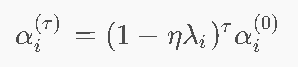
收敛要求: 对所有i

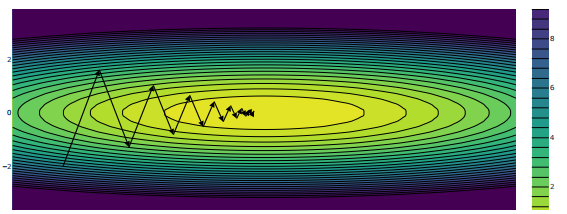
11.5 条件数与收敛速度 ⭐
条件数
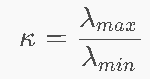
-
λ 是什么? 是Hessian矩阵(海森矩阵)的特征值。在数学上,它代表了误差曲面在某个方向上的“坡度(弯曲程度)”。
-
λmax:最陡峭的那个方向的坡度。
-
λmin:最平缓的那个方向的坡度。
-
-
条件数 κ 的物理意义:它衡量了你的误差曲面“有多畸形”(即最陡峭的方向和平缓方向的差距有多大)。
-
κ 小(接近 1):说明各个方向的坡度差不多。比如一个完美的碗。在这种地形上,无论从哪个方向走,步伐都会很均匀,梯度下降收敛特别快(良态)。
-
κ 大(极大):说明地形严重畸形。你可以想象一个极度拉长的、极其狭长的峡谷(或者一根细长的面条)。在这种地形上,有一个方向极陡(λmax 巨大),另一个方向极平(λmin 趋近于0)。这就是“病态(Ill-conditioned)”,梯度下降收敛极慢!
-
条件数,就是用来衡量这个矩阵 A 有多“容易求逆”、有多“敏感”的指标。指的是椭圆两个方向的拉伸程度。靠近1越好。(参考6.2 L2正则化的病态问题)
11.6 动量(Momentum)⭐
公式
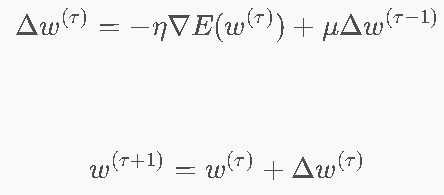

μ∈[0,1):动量超参数
动量如何帮助
| 场景 | 效果 | 有效学习率 |
|---|---|---|
| 平坦方向(梯度≈恒定) | 加速 | |
| 震荡方向(梯度交替变号) | 减速 |
动量=历史梯度的指数加权移动平均→加速平坦方向+平滑震荡方向!
第十二章
🔑 第十二章核心考点
- 学习率调度(幂律最常用,余弦→LLM)
- AdaGrad→RMSProp(EMA替代累积和)
- ⭐⭐⭐ Adam = Momentum + RMSProp + 偏差校正(最广泛使用)
- ⭐⭐ Batch GD() → SGD(
) → Mini-batch(
)对比
- Epoch/Shuffling/Batch Size选择
- 训练误差=测试误差的经验估计(SGD的理论基础)
在第十一章我们知道,学习率 η 定死了不好。太小走不动,太大来回跳。
纯动量的死穴: 它不会区分哪个参数需要大一点步子,哪个参数需要小一点步子。它只能给所有参数用同一个步子。
这一章引入了“参数级别的自适应学习率”:
-
对于梯度经常很大的参数(如 w1):
RMSProp 会把它的学习率“除以一个很大的数”。结果就是:哪怕它原来的梯度很大,最终更新步伐也变得很小,从而彻底压制了震荡。 -
对于梯度经常很小的参数(如 w2):
RMSProp 会把它的学习率“除以一个很小的数”。结果就是:哪怕它原来的梯度很小,最终更新步伐也变得很大,从而加速学习。
学习率调度(Schedules)就是告诉你:随着训练进程,我们要主动去改变 η 的大小。
12.1 学习率调度(Learning Rate Schedules)-随时间/批次变化

12.2 自适应学习率 ⭐⭐-参数级改变
AdaGrad
Ada 对每个参数都维护一个r作为学习率,如果r比较大,说明梯度更新的幅度很大,那么就在这个方向去减小学习率。如果r比较小,说明梯度更新的幅度很小,那么就在这个方向去增加学习率。
- 累积梯度平方和→梯度大的维度学习率减小
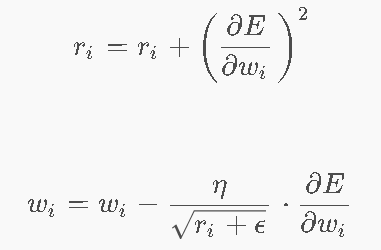

问题:r单调增长→学习率过度减小→早期大梯度导致后期停滞
于是我们考虑:不对分母r进行累计,而是对历史进行衰减
越近的历史说明最近的调节很大,那么就减小调节,很远的历史就没那么大的影响。
RMSProp
- 用指数加权移动平均替代AdaGrad的累积和→关注近期梯度
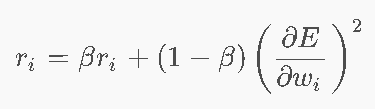
β≈0.9:越近的梯度权重越大

12.3 Adam ⭐⭐⭐
Adam = RMSProp + Momentum
第一步:第一行公式 —— 保留“动量”(走出直线 减少震荡)
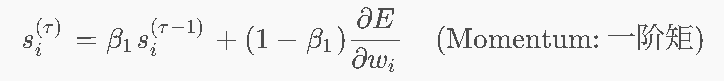
-
β1 的作用: 也就是保留了历史梯度的方向,用于抑制震荡,加速穿越平原。
第二步:第二行公式 —— 保留“自适应步长”(多减少补)
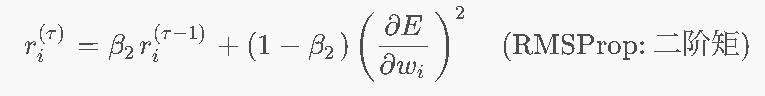
-
β2 的作用: 记录“这个参数最近跳得有多猛”,用于在分母里动态调整每个参数的学习率。
第三步:最关键的“偏差校正”
-
遇到什么问题了?
在第 1 步的时候,动量 si 和 ri 初始都是 0。
假如你把新数据加进来(比如公式里的 (1−β1) 是 0.1)。第一轮更新时,si 就只等于 0.1×梯度。这直接把步伐压缩了 10 倍! 导致 Adam 在训练刚开始的时候,跑得特别特别慢。 -
怎么解决的?(偏差校正)
-
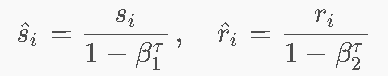
-

第四步:最终更新公式
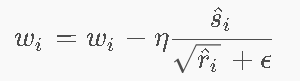

对比第十一章和第十二章的任务
一个是控制往哪里走(走直线下降最好),一个是控制走多远(多减少补最好)。

![]()
12.4 下降批次大小 Batch GD → SGD → Mini-batch ⭐⭐
Batch GD的代价
- 每步计算N个数据点的梯度→O(ND)
- 大数据集→每步都极昂贵
SGD(随机梯度下降)
- 每步随机选1个数据点→O(D)
- 梯度有噪声→但便宜+快
- 噪声可能帮助逃离局部最小值!
Mini-batch SGD
- 每步随机选B个数据点→O(BD)
- 在噪声和精度之间取得平衡
三种方法对比
| 方法 | 每步梯度 | 代价 | 特点 |
|---|---|---|---|
| Batch GD | 全部N点 | O(ND) | 精确但昂贵 |
| SGD | 1个点 | O(D) | 噪声大但便宜+快 |
| Mini-batch SGD | B个点 | O(BD) | 最优折中 |
训练误差=测试误差的经验估计
- 大N→训练误差≈期望测试误差(大数定律)
12.5 Epoch与Shuffling
Epoch
- 1 Epoch = 完整遍历全部N个数据点一次
Shuffling
- 每个Epoch开始前随机打乱数据顺序
- Mini-batch按序取B个→自然随机
每Epoch步数
- Batch size B → 每Epoch ⌈N/B⌉ 步
选择Batch Size
| 大B | 小B |
|---|---|
| 梯度估计更准 | 计算便宜→更多步 |
| GPU并行更好 | 随机性帮助逃离局部最优 |
| →先增大B填满GPU | →η可随B成比例增大 |
第十三章 从简单网络到神经网络
🔑 第十三章核心考点
- 线性模型局限(固定基函数)→ N(数据依赖基函数)
- ⭐ 人工神经元+ 生物对应
- ⭐⭐ 激活函数对比(Sigmoid/Tanh→梯度饱和 vs ReLU→不饱和)
- XOR → 隐藏层必要性
- ⭐ 网络架构:+ 万能逼近 + 深>宽
- ⭐ PyTorch训练循环四步:zero_grad→forward→backward→step
- 核心API:nn.Module, nn.Linear, Autograd, DataLoader, Optimizer
之前的章节(线性回归、逻辑回归、GMM)我们称之为“浅层模型”。它们虽然厉害,但都有个致命弱点:表达能力有限(比如逻辑回归只能画一条直线做决策边界)。
而这一章,就是告诉你怎么把若干个“简单的线性模型”像搭乐高一样堆叠起来,变成能够“拟合万物”的神奇网络——神经网络(Neural Networks)。
13.1 从线性模型到神经网络
线性模型的局限
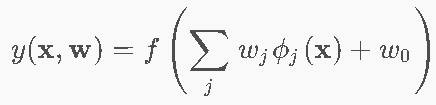
- ϕj(x):固定基函数(与训练数据无关)
- 即使基函数很丰富→大多数情况下不能近似任意函数
高维:诅咒与祝福
| 诅咒 | 祝福 |
|---|---|
| 需要指数级增长的数据 | 更多分离方式 |
| 点稀疏→"相似性"不可靠 | 升维+解耦→非线性可分→线性可分 |
| 容易过拟合 | 额外好特征可"解开"类别 |
4. 神经网络与传统线性模型(固定基函数)的核心区别是?
A. 神经网络不需要训练
B. 神经网络学习数据依赖的基函数(非人工设计)
C. 神经网络没有激活函数
D. 神经网络只能做分类
数据流形 → 神经网络 ⭐
真实高维数据(图像/音频/文本)通常生活在低维流形上
13.2 人工神经元 ⭐
数学模型
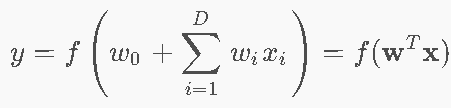
- 线性组合 + 激活函数ff(引入非线性)
阶跃函数 → 逻辑门
- AND门:可以用一个神经元实现
- XOR门:单个神经元不能实现(线性不可分)→需要隐藏层!
13.3 激活函数 ⭐⭐
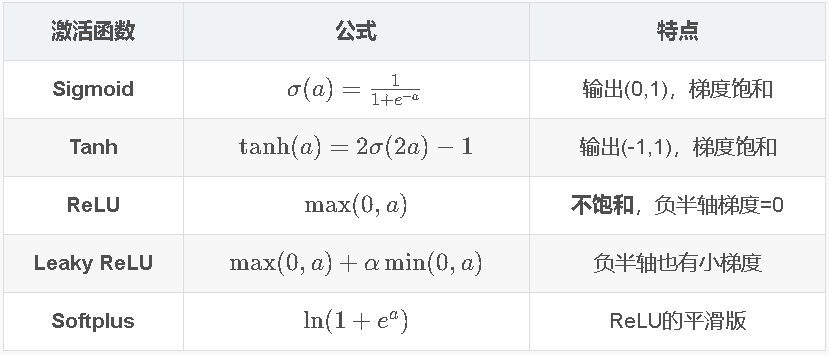
Sigmoid
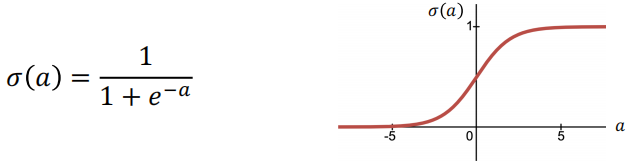
Tanh
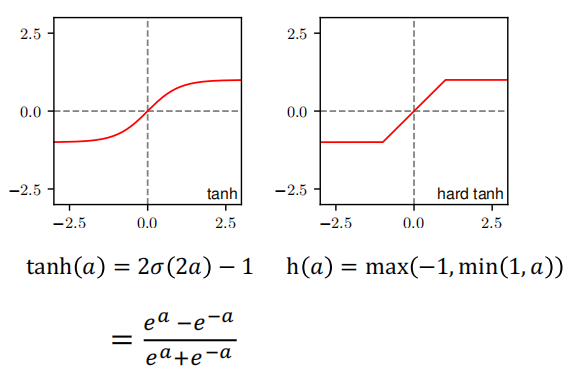
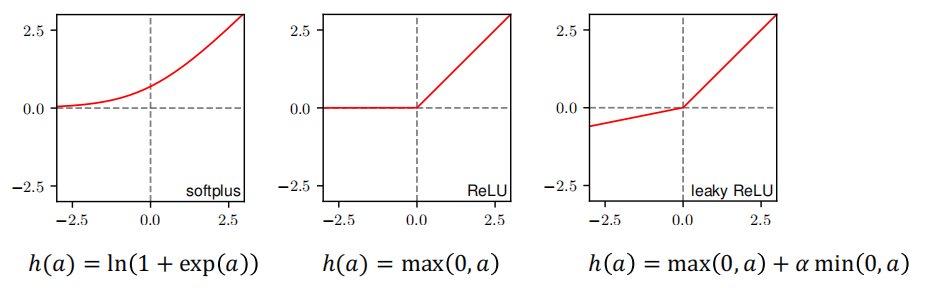
为什么ReLU更好?
- Sigmoid/Tanh在∣a∣大时→梯度→0(饱和)→梯度消失
- ReLU在a>0时梯度=1→不饱和→缓解梯度消失
- Leaky ReLU在a<0也有小梯度→避免"死神经元"
单隐藏层网络

深度网络
为什么"深"而非"宽"?
- 万能逼近定理:一个隐藏层+足够多神经元→可逼近任何连续函数
- 但→深网络更高效:用更少参数表示同样复杂度函数
第十四章 反向传播(如何调整第十三章提到的深度网络的权重)
🔑 第十四章核心考点
- 三种梯度方法对比(数值/符号/Autodiff)
- ⭐⭐ Forward Mode vs Backward Mode Autodiff
- ⭐⭐⭐ 反向传播核心:伴随变量+ 递归公式
- 计算图+拓扑逆序遍历
- Backward比Forward快~D倍(DL核心优势)
- PyTorch Autograd:.backward()触发
14.1 梯度计算:三种方法对比 ⭐
(1) 数值微分(Numerical Differentiation)
-
做法:用极限的近似定义去算。给 w 增加一个极小的扰动 ϵ,看看误差 E 变化了多少,以此估算斜率。
-
优点:实现极其简单,随便什么复杂函数都能套。
-
致命缺点:极慢! 如果你有 100 万个参数,每次更新都要算 100 万次扰动,训练一次要上万年。(所以在实际训练中完全不用,只用来做代码“正确性检验”)。
| 优点 | 缺点 |
|---|---|
| 适用于任何函数 | 近似(非精确) |
| 易于实现 | 极贵:需2D次误差计算→O(ND^2)总代价 |

(2) 符号微分(Symbolic Differentiation)
- 用求导规则推导解析梯度表达式
- 优点:精确 | 缺点:“表达式膨胀”(Expression Swell)。如果你有一百层网络,推导出来的导数公式可能会写满几张 A4 纸,计算机存都存不下。
21. 数值微分是计算梯度最精确的方法。( )![]()
(3) 自动微分(Autodiff)⭐
| 特点 | 说明 |
|---|---|
| 自动 | 追踪前向计算图→自动生成导数程序 |
| 精确 | 机器精度(非近似) |
| 高效 | 重用冗余计算 |
两种模式

14.2 前向追踪:计算图 ⭐
将计算分解为基本操作的序列:
v1 = x1 v4 = exp(v3)
v2 = x2 v5 = sin(v2)
v3 = v1 * v2 v6 = v4 + v3
v7 = v6 - v5 (= f)
-
作用:把复杂的计算变成一张“流程图”。比如
y = sin(v2) + v3,它会被拆成v2=...,v4=...,v5=...等若干个小节点(Node)。 -
前向追踪(Forward Mode):按照图的正向顺序,根据输入计算预测值,并缓存中间结果。
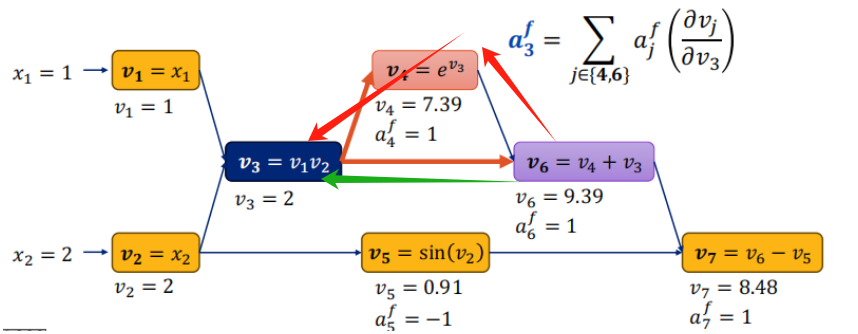
14.3 反向传播:与伴随变量 ⭐⭐⭐
核心递归公式
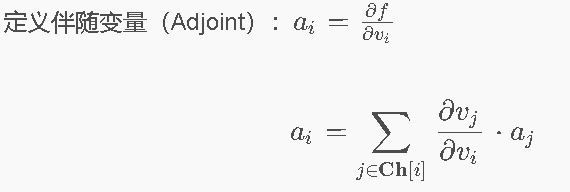
“当前节点 vi 拥有的总误差梯度(ai),等于【所有直接下游节点传回来的误差(aj)】乘以【它们之间连接局部的偏导数】,然后再加起来。”
-
这是核心! 误差 E 就是终点 ffinal。我们想知道 E 对最早的那个权重 v1 的导数怎么办?
-
从最后一步开始,算输出误差的导数(afinal=1)。
-
然后反向逆行,去算它“父节点”的导数。
-
拿到父节点的导数后,顺着反向图继续往上(往回)推,根据局部导数相乘(链式法则),一步步算出前面每个变量的导数。
-

-
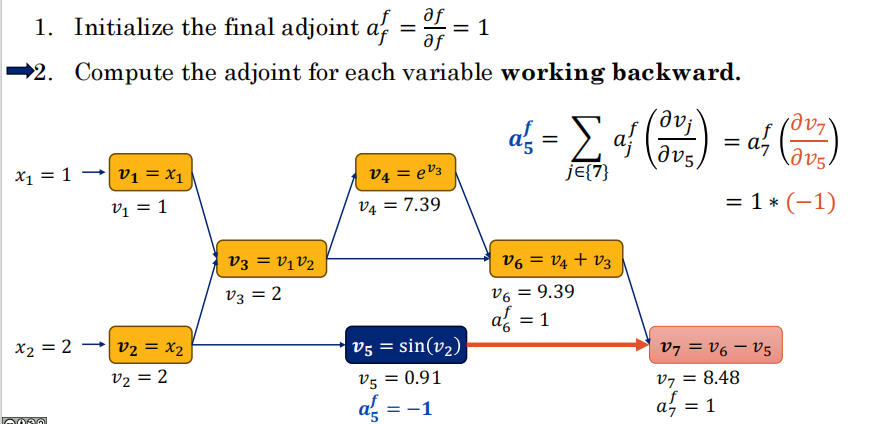
-
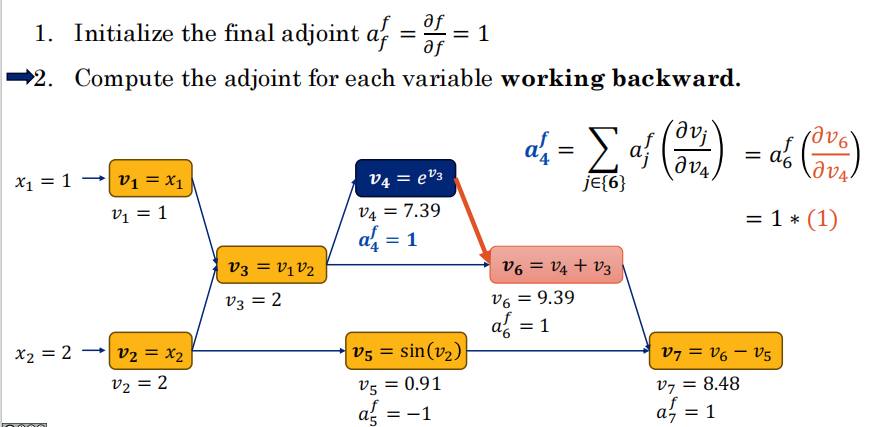
-
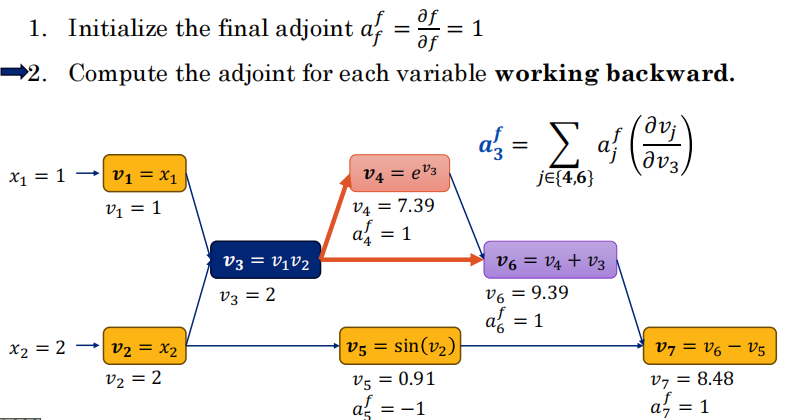
为什么反向模式高效
-
深度学习的特点:参数极多(百万、千万级),但最后输出只有一个(误差是一个标量)。
-
正向模式:想算 100 万个参数的梯度,你得正向传播 100 万次。(耗时 O(N))
-
反向模式:只需要正向算 1 次求出误差,然后反向走 1 次,就能同时算出所有 100 万个参数的梯度!(耗时 O(1))
-
结论:这就是为什么深度学习能跑起来的根本原因之一,反向传播具有“一次遍历计算所有梯度”的变态效率。

第十五章 训练技巧:网络优化策略:初始化 正则化 与 集成学习
🔑 第十五章核心考点
- ⭐ 初始化:零权重陷阱→He(K=2)/Xavier
- ⭐⭐ BN vs LN:统计维度/并行性/应用场景
- Weight Decay/Early Stopping/Dropout三大正则化
- ⭐ Dropout=瘦身网络隐式集成+测试时
缩放
- Bagging/MoE集成学习
- Double Descent(过参数化可改善泛化)
- ⭐⭐ 残差连接:→缓解梯度消失+集成视角
15.1 参数初始化 ⭐⭐
零权重陷阱
- 所有权重初始化为0→所有隐藏单元产生相同激活+相同梯度→对称性不打破→无法学习
- ReLU/Tanh下梯度为0→完全不学习!
- 必须随机初始化来打破对称性
- 指定一个均值(通常是0),限定一个标准差/范围(方差),在这个范围内随机取值。
He初始化(ReLU)⭐

Xavier初始化(Tanh)
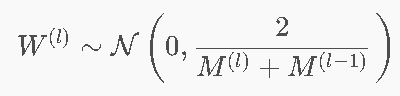
- 同时考虑fan-in和fan-out→适合Tanh/Sigmoid

15.2 归一化 ⭐⭐
输入数据量级差别太大(比如一个是 0.1,另一个是 1000),会导致梯度下降非常艰难(如同狭长的峡谷)。
数据归一化
BN 看“一排(所有样本的某一个特征)”,LN 看“一列(单样本的所有特征)”
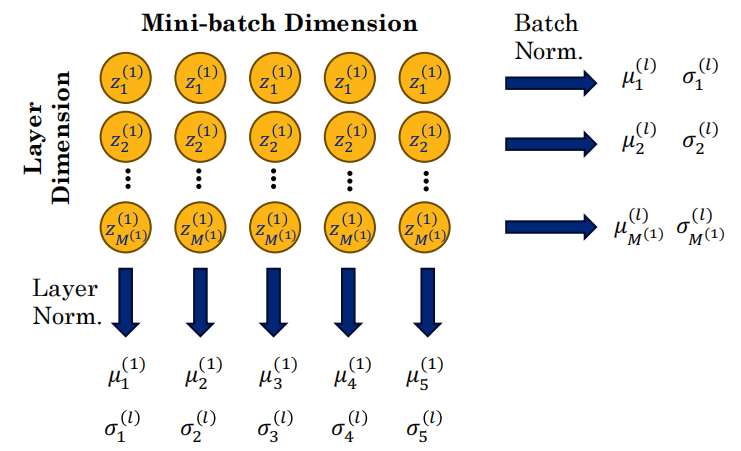
Batch Normalization(BN)
- 在Mini-batch维度计算均值和方差
- 每层每个神经元独立标准化
- 测试时:用训练中EMA(指数移动平均)的μ和σ
- 问题:跨GPU难以并行(需共享batch统计量)
Layer Normalization(LN)
- 在层(特征)维度计算均值和方差
- 每个样本独立→无需训练EMA→测试时直接使用
- 优势:天然支持并行→Transformer/LLM标准配置
BN vs LN 对比 ⭐
| Batch Norm | Layer Norm | |
|---|---|---|
| 统计维度 | Batch维度(同特征不同样本) | Layer维度(同样本不同特征) |
| 并行性 | ❌ 跨GPU困难(统计量需要共享) | ✅ 天然并行 |
| 测试时 | 需训练EMA | 直接计算 |
| 应用 | CNN/经典网络 | Transformer/LLM(样本间差异大) |
可学习的缩放和平移 “γ,β 通过 SGD 学习 → 恢复归一化可能限制的表达能力”
归一化时,核心动作是:“把数据强行拉回到均值为0、方差为1的标准状态。”
但所有数据都被强行压到0附近,会不会把原本数据中重要的“特征尺度”给弄丢了?
不直接把归一化后的数据传给下一层,而是把拉伸平移后的“归一化值”传下去:

所有的数据会经历:原始尺度->压缩为N(0,1)->拉伸为合适的尺度z=αz+β->给下一层
为什么不直接在原始特征上拉伸呢?第一步不知道参数应该设多少,只有N(0,1)才能保证第一次更新是安全的。
15.3 正则化技术 ⭐⭐
Weight Decay(=L2正则化)
![]()
之前讲过了
Early Stopping
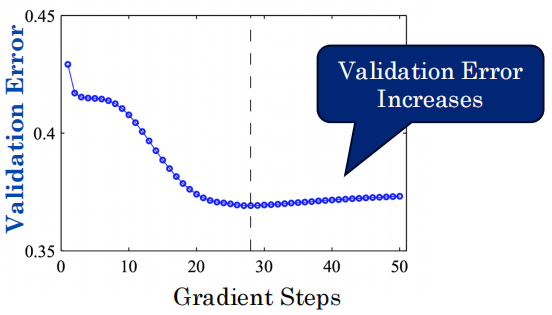
-
它是做什么的? 训练过程中,实时盯着验证集(Validation Set)的误差。一旦发现验证集误差开始上升,立刻中止训练。
-
为什么会有效? 它本质上是“隐式的正则化”(隐式的 Weight Decay)。因为停止得早,权重的数值还没来得及变得特别大,正好起到了防止过拟合的作用。
- 本质=隐式Weight Decay:从小权重开始→提前停止→权重没机会变大
Dropout ⭐
归纳偏置:模型不应依赖任何单一神经元→学习鲁棒特征
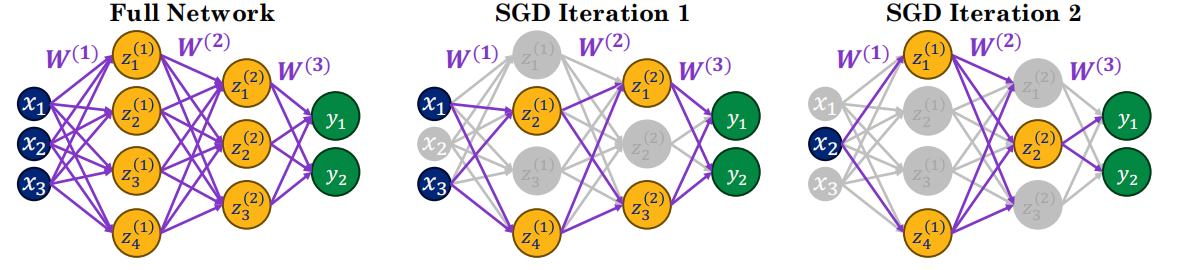
- 训练时:每次SGD迭代随机丢弃神经元(概率ρ,通常≤0.5)
,
- 测试时:
(缩放补偿)
Dropout = 模型平均
- M个神经元→2^M种可能的"瘦身"子网络
- 每次SGD步训练一个子网络→隐式集成
- 测试时=所有子网络预测的平均
15.4 集成学习与Bagging
模型集成
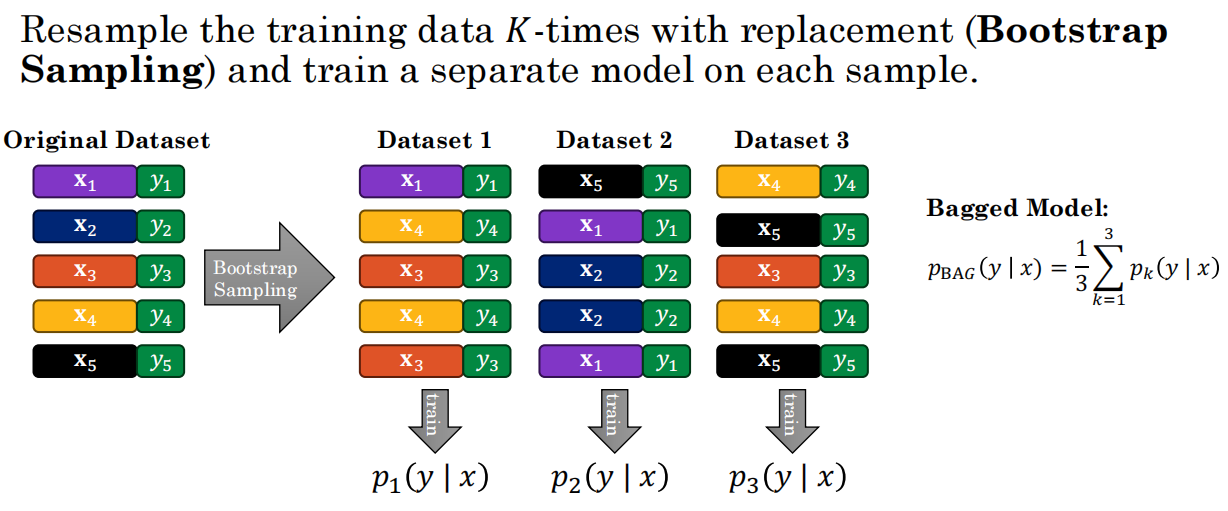
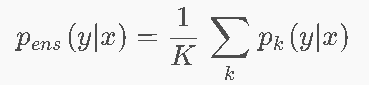
Bagging(Bootstrap Aggregation) —— 投票表决
- 有放回重采样K个训练集→训K个模型→平均预测
- 每个模型用不同的数据子集→多样性
Mixture of Experts(MoE)(混合专家模型)—— 专业人干专业事
-
做法:引入一个“路由(Router)”网络,它会根据输入的内容,动态决定把任务交给哪个“专家子网络”来处理。
-
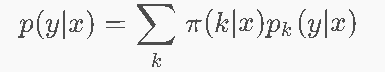
14. 模型集成减小的是什么?
A. 偏差
B. 方差
C. 噪声
D. 参数数量
15.5 双重下降(Double Descent)⭐
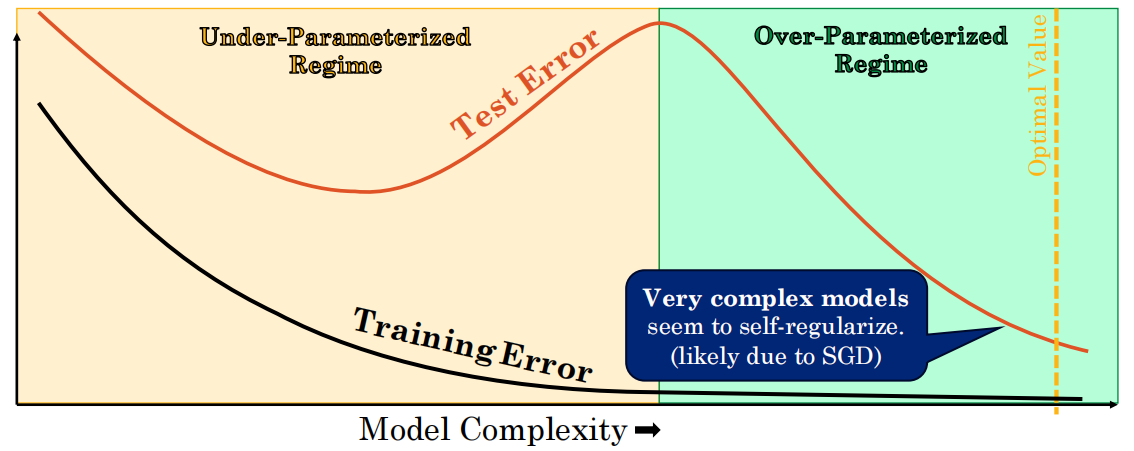
- 传统U型→模型越过插值阈值后→测试误差再次下降
- 当模型复杂度继续增加,跨越过“插值阈值”(Interpolation Threshold,即模型刚好能完美拟合训练数据)后,测试误差并没有继续上升。
- 反直觉:对足够大的模型→早停可能降低泛化能力
15.6 残差连接(Residual Connections)⭐⭐
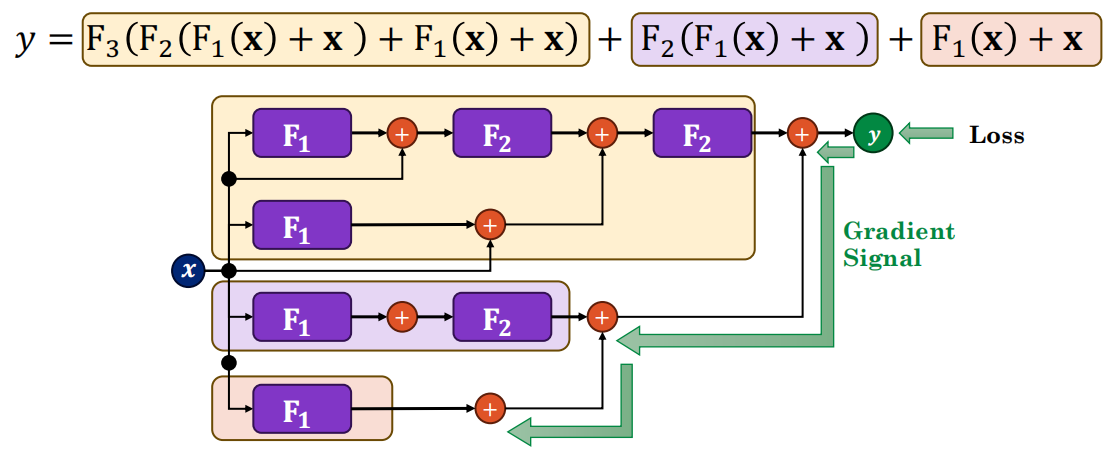
残差块
![]()
- Fl学习的是残差而非完整变换
- Skip connection→梯度可直接流过低层
为什么有效
- 解决梯度消失:梯度可沿残差连接直接回传
- 集成视角:ResNet展开后=不同深度网络的集成
- 使训练数百层深度网络成为可能
第十六章 Attention & Transformers
🔑 第十六章核心考点
- MLP→CNN→Attention演进逻辑
- ⭐⭐⭐ QKV机制+Scaled Dot-Product Attention完整公式
- 除以的原因 + KQ分离的原因
- ⭐⭐ MHA/GQA/MQA三种多头变体
- ⭐ Transformer层结构:MHA→残差→LN→MLP→残差→LN
- ⭐⭐ 位置编码:为什么需要 + Learned vs Sinusoidal + 加法插入
16.1 从MLP到CNN到Attention
MLP的局限
- 每像素独立参数→P^2参数量→参数爆炸
- 固定输入大小→稍大图像需全新模型
CNN的贡献与局限
| 优势 | 局限 |
|---|---|
| 权重共享→参数高效 | 局部感受野→高层才有全局上下文 |
| 平移不变性归纳偏置 | 卷积核感受野逐层增长→需很深 |
| 支持可变输入尺寸 |
-
MLP(全连接层)的局限:每个神经元独立,参数多,只能处理固定大小的输入(比如图片固定是 224×224224×224,变大了就处理不了)。
-
CNN(卷积)的局限:虽然能处理任意大小,但它是“局部视野”。你看图片时只能看到附近的一小块,离得远的信息就看不清了。
-
而让LLM理解一句话,显然是需要有token之间关系,知道上下文才行。
-
Attention(注意力机制)的降维打击:它允许模型“一眼看全”。在预测某个词(或像素)时,它可以直接关注到序列中任意位置的任意一个词,不再受距离的限制。这是整个 Transformer 的灵魂。
16.2 Attention机制 ⭐⭐⭐
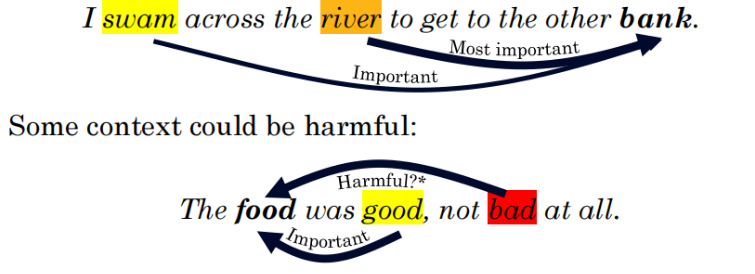
“如何把多个信息,压缩成一条信息”
平均池化
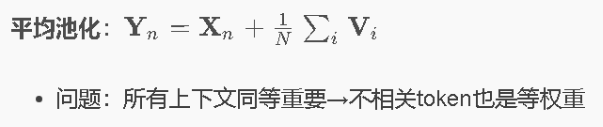
极简定义: 把所有值加在一起,除以个数(算个简单的平均数)。
-
例子:假设我们要把 A、B、C 三个人的思想总结成一句话。
-
A 说“红色”,B 说“蓝色”,C 说“绿色”。
-
平均池化操作:
(红 + 蓝 + 绿) / 3,结果变成了一种浑浊的灰色。
-
-
特点:
-
公平,但没个性。它忽略了每个词/特征的重要性差异,把所有的成分视为同等重要。
-
计算成本极低(只需要简单的加法和除法)。
-
-
在深度学习中的场景:
-
在 CNN(卷积神经网络) 的最后阶段使用。比如把一个 3×3 的特征图,平均成一个数字,用于告诉下一层“这个区域大概的明亮程度”。
-
问题:在 NLP(句子处理)中,如果机械地平均,good和bad的表意是相等的,不知道谁更重要。而注意力机制正是为了解决这个问题而生的。
-
-
加权平均

16.3 QKV与自注意力 ⭐⭐⭐
三个投影矩阵

1. 图中意思
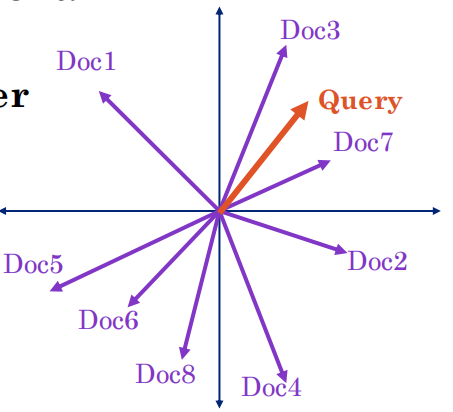
-
每个文档(Doc1~Doc7)的含义被表示成一个向量,叫 key。
-
用户的查询含义也被表示成一个向量,叫 query(图中的“Query”向量)。
-
计算 query 与每个文档 key 的内积(点积),内积越大表示相关性越高。
-
按内积从大到小排序返回文档(比如例子里 Doc3 最相关,然后是 Doc7…)。
这就完成了一次“内积搜索”,本质是用向量相似度来排序。
2. QKV 关系是什么?
在 Transformer 的 自注意力 或 交叉注意力 里:
-
Q(Query):当前要查询的向量(图中就是 Query)
-
K(Key):被比较的向量(图中每个文档的 key)
-
V(Value):与 K 配对的、真正要提取或加权的内容向量
具体流程:
-
根据X和权重矩阵计算QKV向量
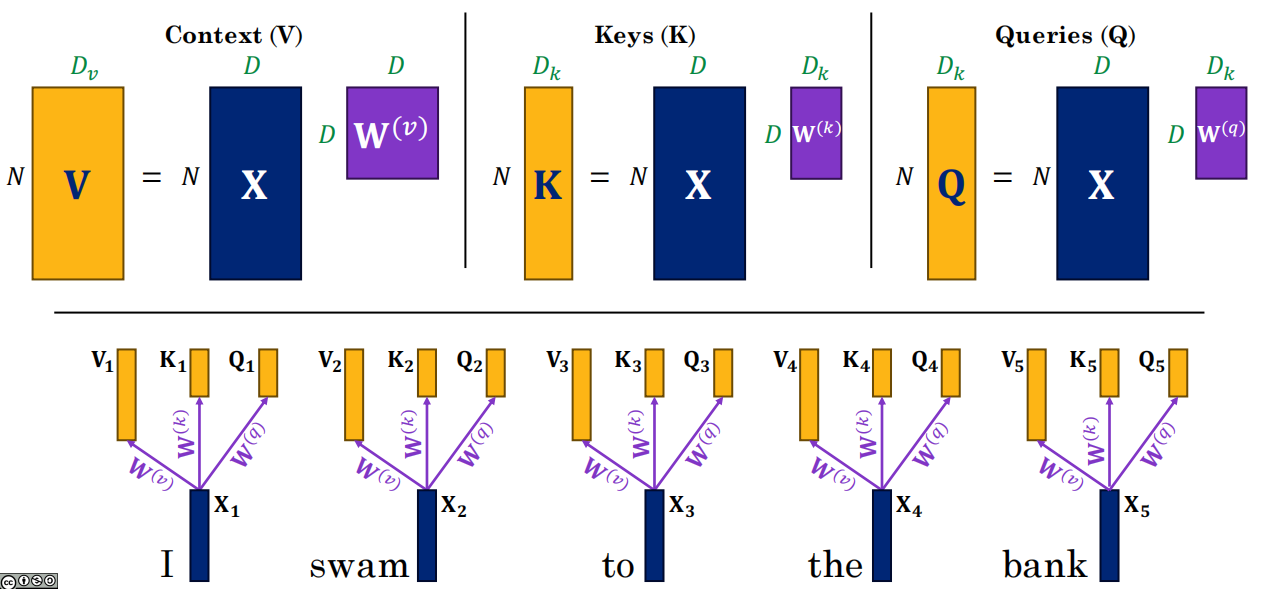
-
计算 Q 与每个 K 的内积(或缩放点积) → 得到一个分数。
z5,1即Q5查询K1的值,即bank和I的相关性。
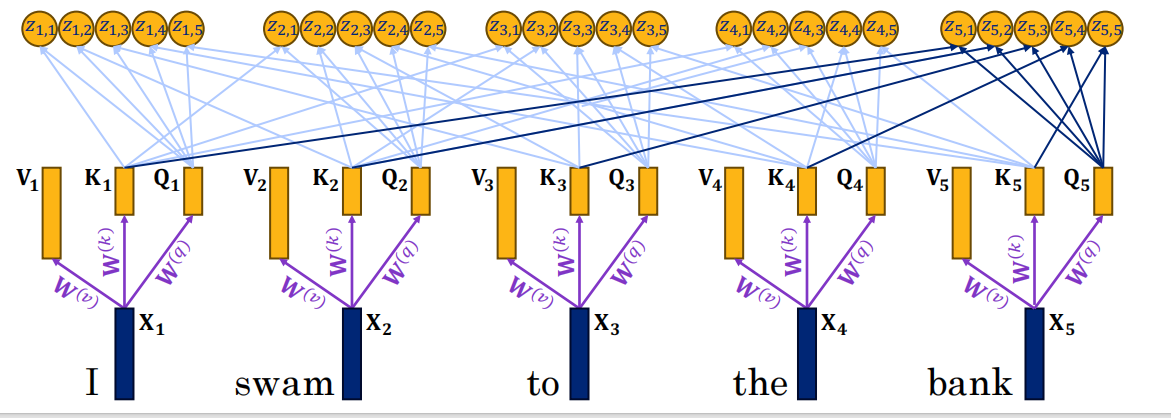
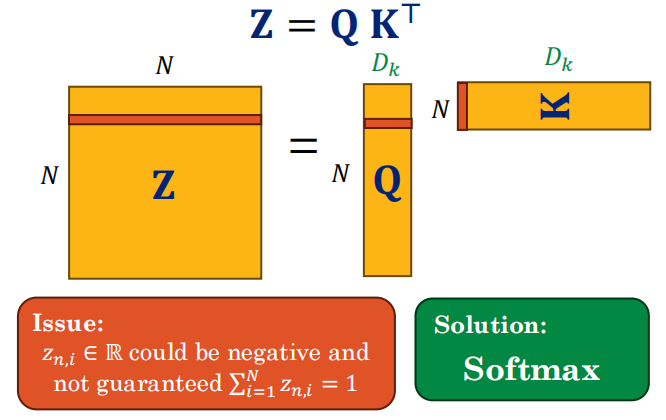
-
这些分数通常经过 softmax → 变成权重。
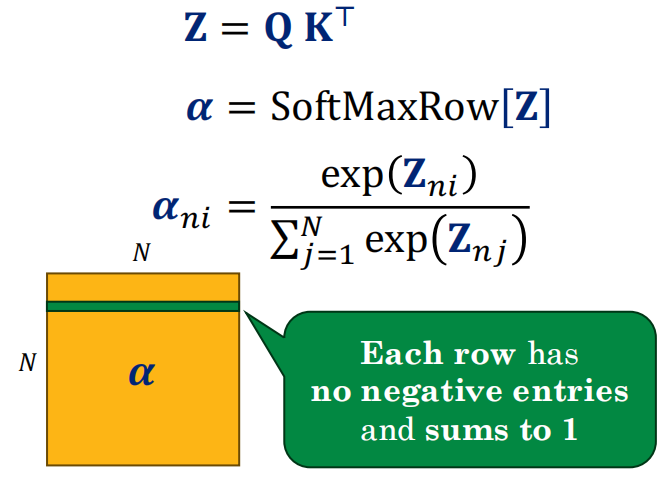
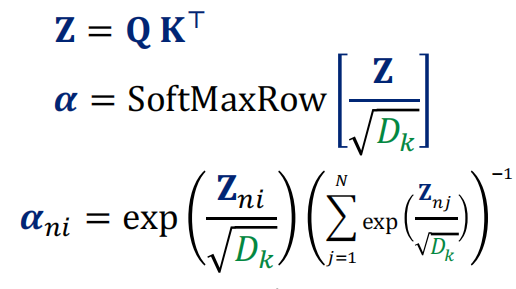
Scaling因子:防止内积方差过大→Softmax梯度消失
-
用这些权重去加权求和 V,得到最终的输出。
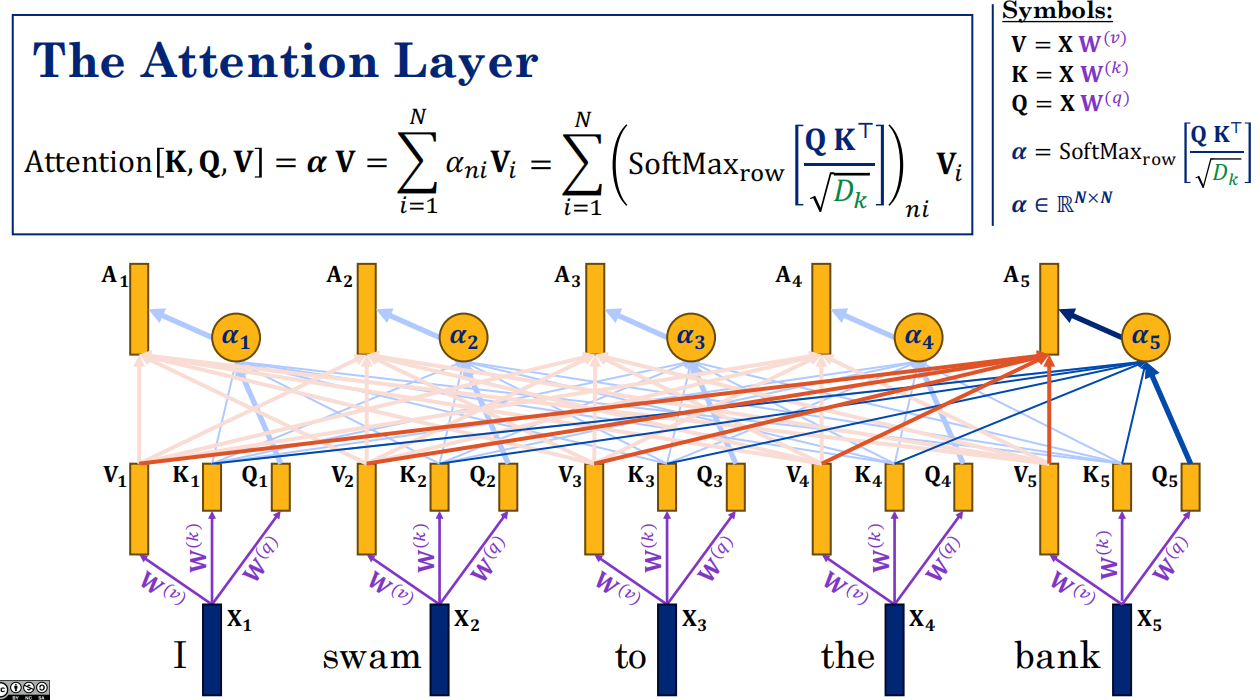
自注意力特性
- Attention层无参数(仅依赖K,Q,V)
- 等变性:置换输入token→输出同样置换
复杂度(N=token数)
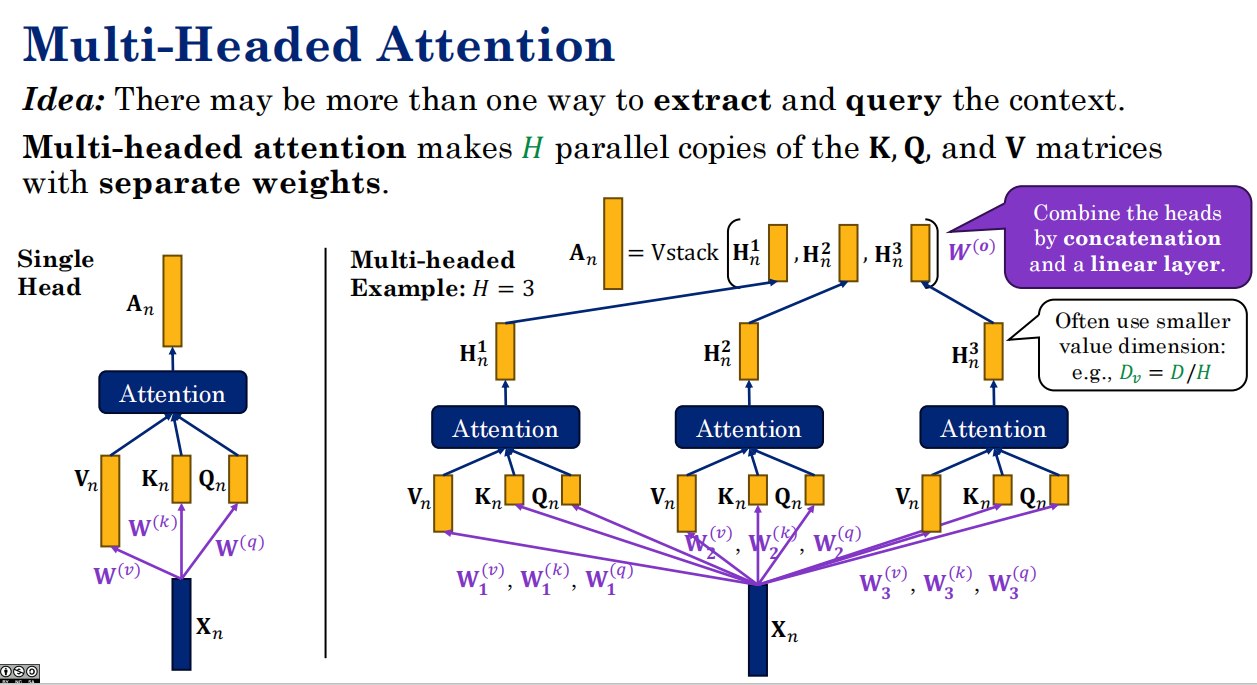
16.4 多头注意力 ⭐⭐
Multi-Head Attention(MHA)
“提取和查询上下文的方式可能不止一种。”
-
头 1 负责看语法。
-
头 2 负责看长距离依赖。
-
头 3 负责看情感。
-
结果:把这些头算出来的结果拼在一起(Concat),再经过一个输出层。
-
PPT 提到的 Dv=D/H:意思是,如果总维度是 512,分了 8 个头,那么每个头只需要算 64 维。这保证了虽然分了这么多头,但总的参数量和计算量并没有爆炸式增长。
变体
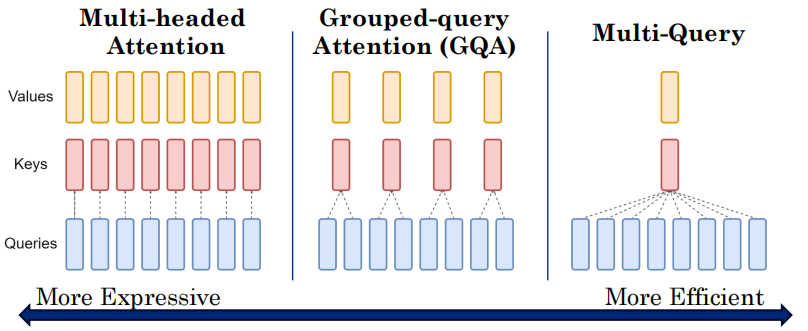
| 类型 | K,V | Q | 效率 |
|---|---|---|---|
| MHA | 每头独立 | 每头独立 | 最低 |
| GQA(分组查询) | 每头组共享 | 每头独立 | 中等 |
| MQA(多查询) | 全部共享 | 每头独立 | 最高 |
大多数现代模型使用GQA(效率与表达力的折中)
Q:为什么GQA比MQA好?理论上KV是公开的,共享应该没有问题啊?
“不同的头(Head)为了捕获不同的语义特征,需要在不同的‘语义几何空间’中建立高维索引。KV 独立,意味着每个空间都有自己专用的、精细化的稠密索引结构(Key)和内容库(Value)。共享 KV,就等于强制所有不同的查询(Q)去检索同一个‘粗糙的通用索引’,导致索引无法特化,从而丧失了捕捉复杂、多元化特征的能力。”
16.5 Transformer层 ⭐
表达了Transformer模型的基本构建单元(Transformer Layer)的架构原理和设计动机。
1. 基础结构:自注意力 + MLP
一个Transformer层由两部分组成:多头自注意力机制和逐词(Token-level)的前馈神经网络(通常是2层的MLP)。
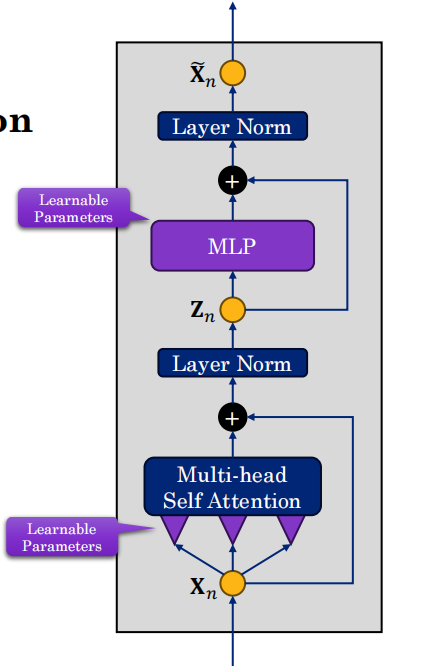
2. 核心疑问:为什么需要 MLP?
-
原因:自注意力层的输出本质上是输入 X 的线性组合。
-
MLP的作用:在自注意力处理后加入MLP,相当于引入了非线性激活函数(如ReLU、GELU等),能够让模型学习到更复杂、更抽象的特征,赋予模型更强的表达能力,且每个token都可以单独进行处理。
3. 训练优化:残差连接和层归一化(Layer Norm)
为了防止模型过深导致训练困难和梯度消失,必须使用这两个技巧。
-
残差连接(图中黄色的“+”号):将输入直接与输出相加,保留原始信息。
-
层归一化:在每一层处理后对数据进行归一化,让训练更稳定。
4. 深层构造:层级堆叠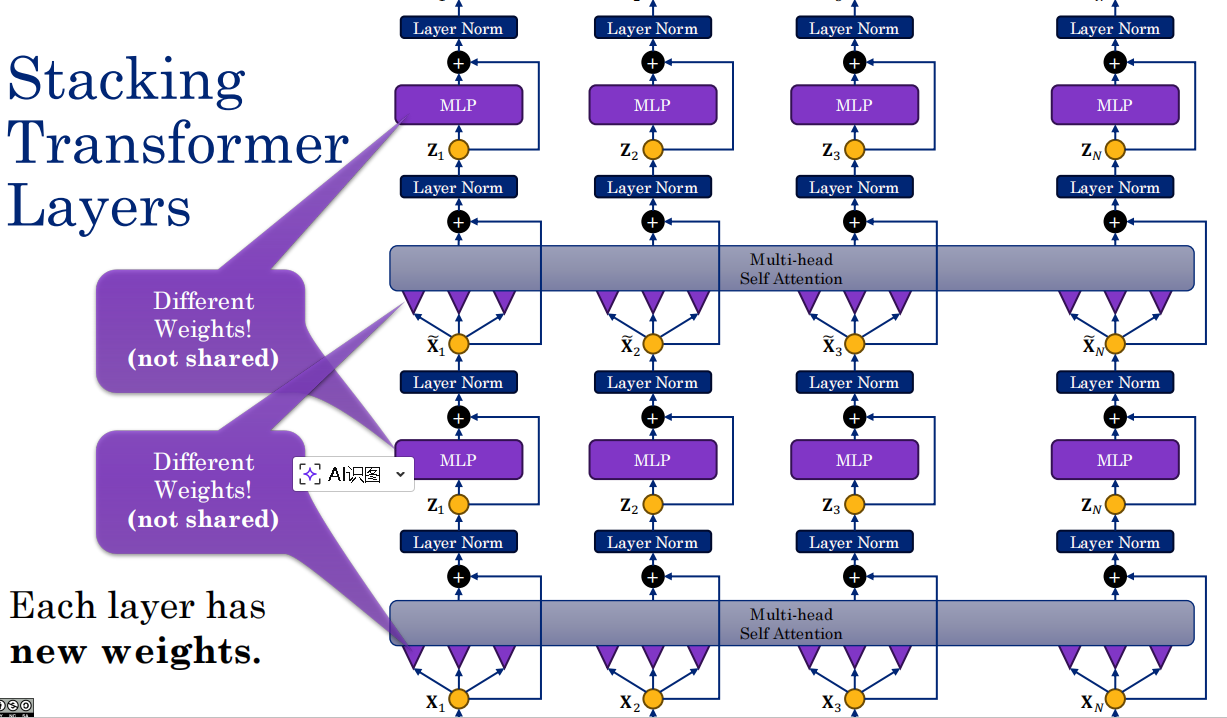
一个完整的Transformer模型(如BERT、GPT)就是由许多个这种“自注意力+MLP+残差+归一化”的模块串联堆叠而成的。层数越深,模型能建模的语义复杂度和抽象程度就越高。
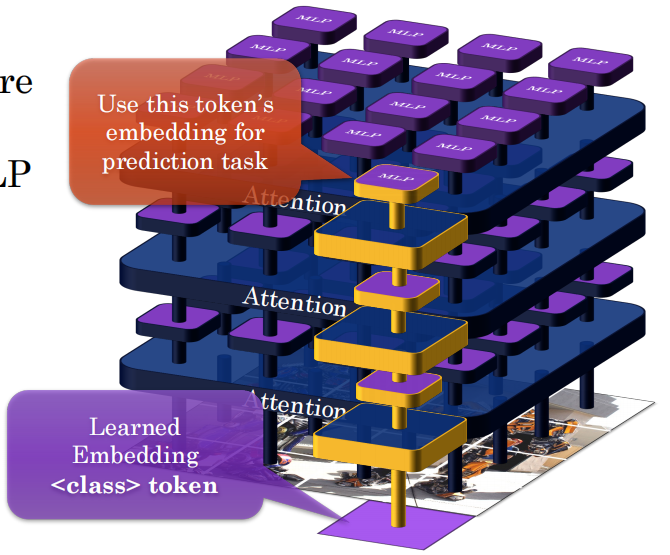
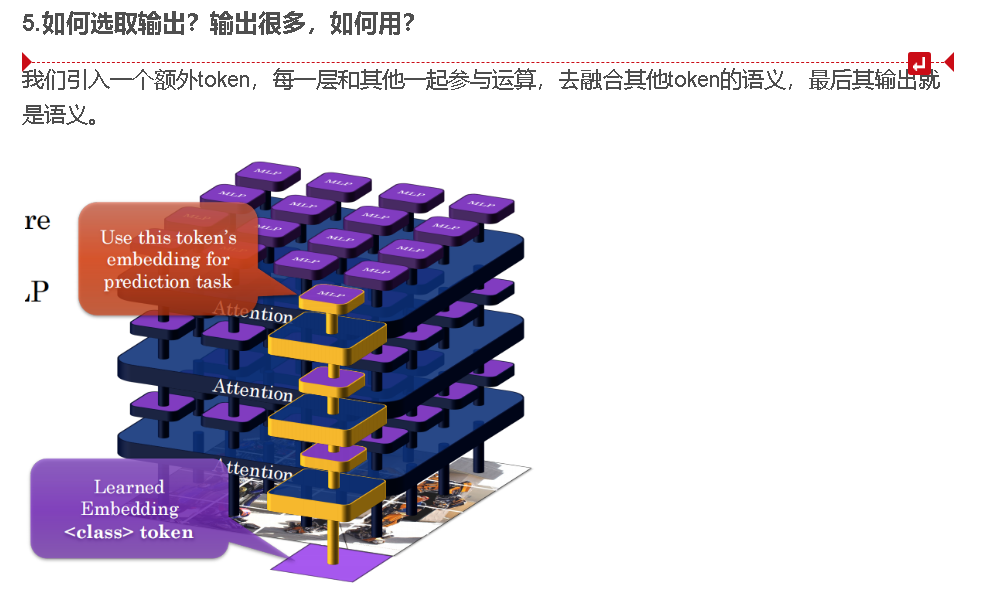
5.如何选取输出?输出很多,如何用?
我们引入一个额外token,每一层和其他一起参与运算,去融合其他token的语义,最后其输出就是语义。
16.6 位置编码 ⭐⭐
由于QK是组合排列的,是没有顺序之分的。导致无法区分词的位置,表达语义有误

| 方法 | 原理 | 优/缺点 |
|---|---|---|
| Learned | 每个位置学一个ri(GPT-1) | 表达力强;需预设最大N;相对距离难表达 |
| Sinusoidal | sin/cos波组合编码 | 任意长度;可查询相对位置(旋转矩阵特性) |
如何去构建rn 构建位置编码
唯一性 位置不能一致
有界性 和原有xn尺度相似,不能1+10000
能表达相对距离
支持任何长度 不管输入多少都能理解
Learned Position Embedding
GPT将rn变成一个可学习的参数,在训练中优化。
-
缺点:如果你训练时只能处理最长为 512 个词的句子,那么你只学到了 1~512 号座位。如果测试时给你一个 600 个词的长文本,模型就不知道 600 号座位该用哪个数字了,泛化能力受限。
Sinusoidal编码
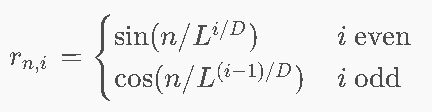
-
做法:不学了,直接用一组固定的、基于三角函数的公式生成数字。
-
为什么很聪明? 结合 PPT 写的“旋转矩阵属性”和“相对距离衰减”:
虽然 1 号座位和 100 号座位的数字完全不一样,但数学上可以证明,【100号座位的编码】可以看作【1号座位的编码】绕着某个中心旋转了一定角度得到的。 -
优点:无论是 512 个词还是 10000 个词,公式都能算出对应的数字,天然支持“任意长度”的输入,且天然包含相对位置信息。【可表达相对位置(旋转矩阵特性)+支持任意序列长度】
-
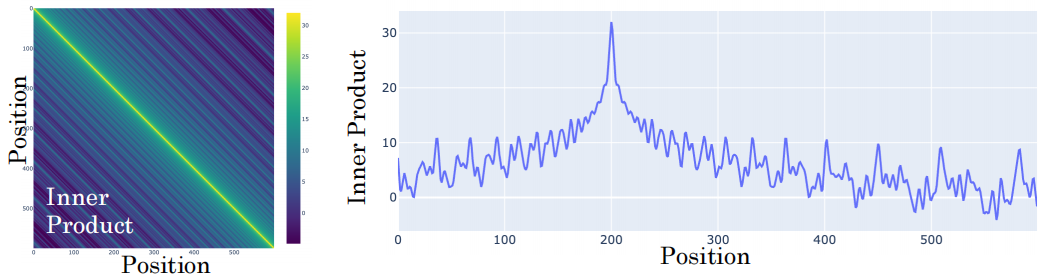
-
左图(热力图):对角线最亮(黄色)。对角线代表同一个位置,内积最大。颜色越往两边越暗,说明内积越小。
-
右图(折线图):中间有个高峰(代表当前位置),越往两边走,曲线越低。
-
白化翻译:当模型计算两个词的注意力(内积)时,距离越近的词,它们的内积越大;距离越远的词,内积越小。
位置编码的使用
![]()
我们直接在xn上加一个位置编码rn。
为什么不把V改为两维的?计算复杂
加不会有问题吗?是正交的,可以解耦。
30. Sinusoidal PE可以通过旋转矩阵查询相对位置。( )
31. Learned PE的一个局限是需要预设最大序列长度N。( )
32. 位置编码采用拼接(concatenation)而非加法加入token embedding。( )
16.7 经典文本骨干 —— Encoder Transformer的输出
还记得这里吗:
1. 标准架构流程
-
输入:把词变成数字(Token Embedding),然后加上上面讲的“位置编码”。
-
核心:重复堆叠 LL 层的 Transformer Block(也就是多头注意力 + 前馈网络 + 残差连接 + 层归一化)。每一层都在进行深层的信息交互。
-
输出:进行 Pooling(池化),或者利用特殊 Token 提取最终表示。
2. 神奇武器:特殊 Token([CLS])
-
这是什么? 在处理句子时,模型会在最前面强行塞进去一个虚拟的字符,通常叫
[CLS]。 -
怎么工作的? 当整个句子经过层层 Transformer 块时,
[CLS]会通过自注意力机制,从其他词里吸收整句话的所有信息和关系。 -
结果:当所有层计算完毕,输出层里
[CLS]对应的那个向量,就被看作是“整句话/整张图的浓缩语义特征”。 -
应用:做情感分类时,直接拿这个
[CLS]向量扔进一个简单的全连接层(线性分类器)就能预测了。它替代了传统的复杂人工特征工程。
【补充说明:注意力机制的参数】

25. Self-Attention层本身没有任何可学习参数。( )
26. Multi-Head Attention的总参数量与单头Attention相同(假设总维度不变)。( )
第十七章 Transformers & LLMs
🔑 第十七章核心考点
- LLM定义 + Tokenization/BPE原理
- ⭐ 因果语言模型+ 自回归解码
- ⭐⭐ Masked Attention:Encoder问题→上三角掩码→Decoder方案
- ⭐ Llama-3架构:RMSNorm+GQA(SwiGLU)+RoPE+残差
- KV Cache加速原理 + GQA节省KV存储
- Encoder-Only/Encoder-Decoder/Decoder-Only架构演进
17.1 LLM概述
什么是LLM
- Large:参数量巨大(数十亿→万亿级)
- Language Model:预测语言(下一词)
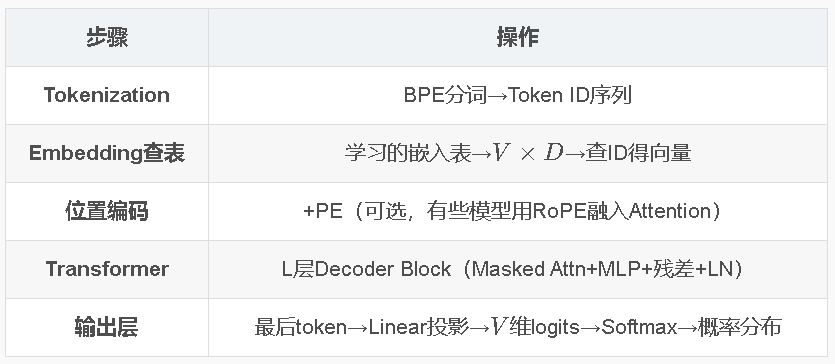
17.2 Tokenization ⭐
Token vs Word
- Token = 词、词缀、标点、特殊字符
- “The smallest tokenizer!” → [“The”, " small", “est”, " token", “izer”, “!”]
- 优势:允许处理新词/拼写错误/数字
BPE(Byte Pair Encoding)⭐
- 初始token集=所有字符+数字+特殊字符
- 统计语料中最高频的token对→合并为新token
- 重复→直到达到目标词汇量
17.3 因果语言建模 ⭐⭐
Causal Language Modeling
![]()
基于前文,下一个词token最可能是?
自回归解码(Auto-Regressive Decoding)
- 计算下一token的概率分布
- 选择下一token(最大概率/采样top-k)
- 将选中token追加到上下文
- 重复→直到
<stop>token
17.4 Decoder Transformer ⭐⭐
Encoder的问题
- 标准Self-Attention→所有token互相可见→生成时"偷看"答案
- 不适合因果(自回归)生成
Masked Attention(因果掩码)
- 只允许关注当前及之前的token(不能看到未来)
- 上三角掩码−∞→Softmax后权重为0
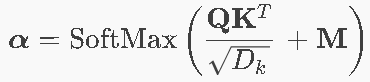

Decoder展开
- 每次新token加入→整个序列重新计算
- 但可缓存之前的K,V→KV Cache加速
- 最后一个token计算量最大(需attend所有历史)
“我今天要吃饭”
-
第一步(生成“我”):输入
[开始],计算[开始]的 Attention,生成我。 -
第二步(生成“今”):注意这里! 为了生成“今”,模型不知道后面会是什么,它必须把输入变长,变成
[开始], 我,重新从头到尾算一遍这两个词的 Attention。 -
生成“天”时就要重新计算“我”和“今”,复杂度是
KV Cache-“每次只算新加进来的那一个词(线性复杂度O(N))”
-
第一步:算完了
[开始]的 K 和 V,把它存到内存里(缓存)。 -
第二步:要生成新词时,只算新词自己的 K 和 V,然后直接从内存里把之前存好的 K 和 V 拿出来拼在一起,做矩阵乘法。
-
后续:每生成一个新词,就把它的 K 和 V 追加到内存数组的末尾。
无论如何,“饭”最终要attend前面所有字符,因此计算量最大。
17.6 翻译问题 Encoder-Decoder
在标准的 Encoder-Decoder 架构(如机器翻译模型,源语言→目标语言)中,数据是这样流动的:
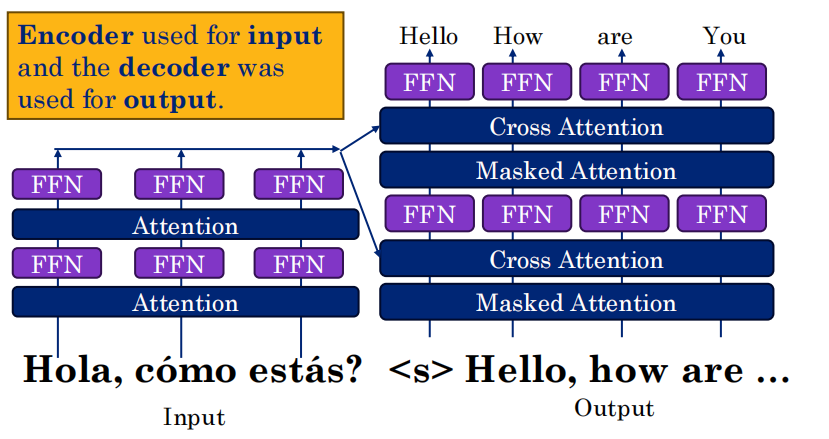
1. 记住它的“角色分工”:
-
Encoder(编码器):负责“读懂”输入。比如你输入一句英文 "I love AI",Encoder 把它变成了一堆包含语义信息的向量(这些向量就是 K 和 V)。
-
Decoder(解码器):负责“写出”输出。它正在一个词一个词地生成中文。当它准备生成第 3 个词时,它手里有一个搜索的申请单(Q)。
2. 交叉注意力(Cross-Attention)是在哪里发生的?
在 Decoder 的每一层中,中间有一层专门叫 Cross-Attention。
-
它的 Q(查询):来自于 Decoder 自己的上一步状态(代表“目前我已经写了什么,接下来我想找什么信息”)。
-
它的 K 和 V(键和值):来自于 Encoder 输出的最终结果(代表“整个输入源句子的信息”)。
3. 它的具体作用(桥接):
-
这两个东西一结合,就达成了“桥接输入和输出”的作用。
-
例子:Decoder 用当前的 Q 去匹配 Encoder 传来的 K。如果它发现 K 中的某个词(比如“AI”)和当前的 Q 最匹配,它就会提取出那个词对应的 V 信息。
-
最终效果:模型在翻译时,能随时“回头看”源句子的对应部分,从而做出准确的翻译。
13. Encoder-Decoder架构中,Cross-Attention实现什么?
A. 输入自身的注意力
B. Decoder的Q关注Encoder输出的K,V→桥接输入和输出
C. 随机注意力
D. 没有实际作用
31. Cross-Attention中Decoder的Query关注Encoder的Key和Value。( )
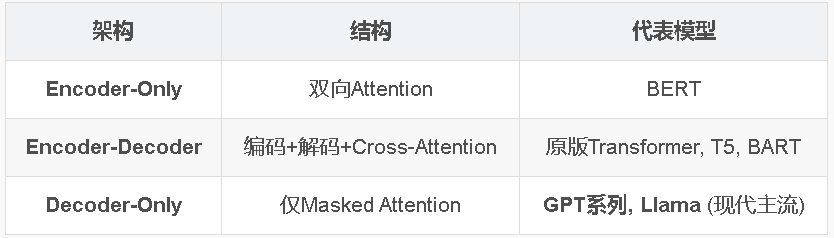
18. 现代LLM的主流架构是?
A. Encoder-Only
B. Encoder-Decoder
C. Decoder-Only
D. MLP
19. BERT属于什么架构?
A. Decoder-Only
B. Encoder-Only
C. Encoder-Decoder
D. MLP
第十八章 LLM的训练与应用
18.1 LLM完整推理流程
第一步:分词 模型的任务设定
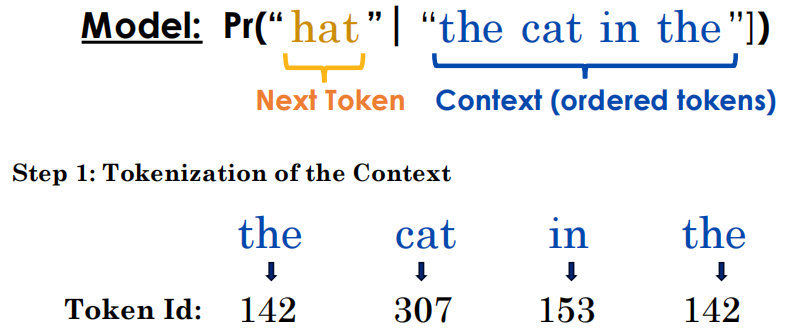
-
核心任务:Next Token Prediction(预测下一个词)。
-
具体目标:模型的任务是计算 P(“hat”∣“the cat in the”)。意思是:“已知前面的词是 'the cat in the',请问下一个词是 'hat'(帽子)的概率是多少?”(这里 'hat' 是正确答案)。
-
Tokenizer(分词):先把这句英文拆成独立的 Token(单词)。因为计算机不认单词,只认数字。
第二步:词嵌入 查表转化为向量
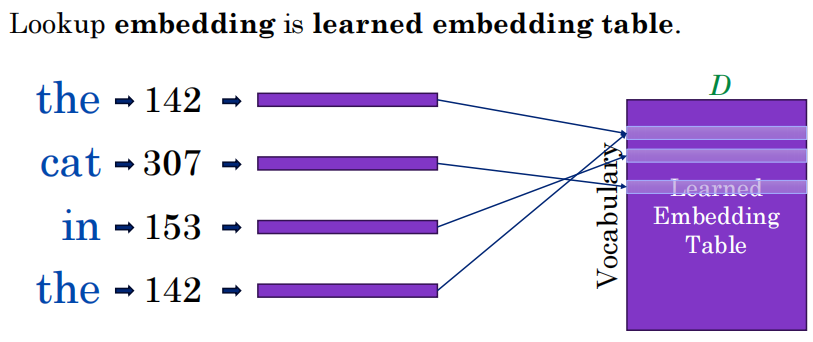
-
Token ID:把单词转换成机器能看懂的数字(比如
the变成142,cat变成307)。 -
Embedding(词嵌入):用这些数字去查一张预训练好的巨大的“表”(Embedding Table)。
-
这张表里,每个 Token ID 都对应着一个非常长的一维数字数组(向量,长度通常为几百或几千,图里标注为 D)。
-
图中的紫色长条就是词向量。在数学上,方向接近的向量,意味着它们在语义上是相似的。
-
第三步:PE位置编码
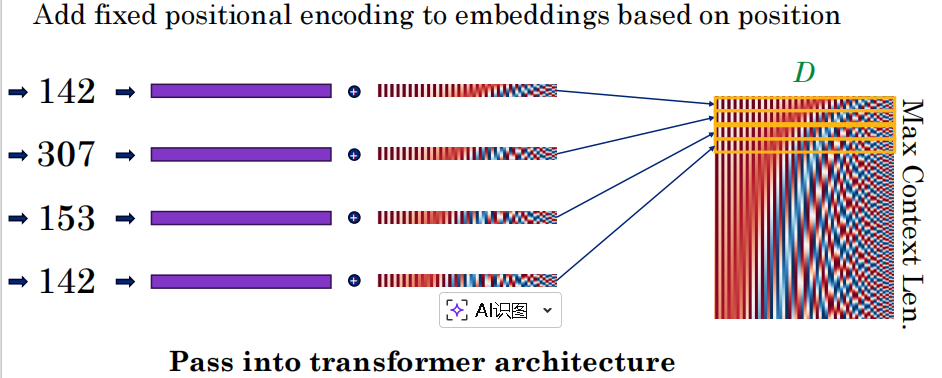
-
为什么要做这一步?
-
你在上一步查表时,如果句子是 “the cat in the” 和 “the in cat the”,查出来的词向量数字是一模一样的。模型完全不知道它们的先后顺序。
-
-
怎么加? 使用了正弦波(Sinusoidal)编码。
第四步:进入真正的 AI 大脑
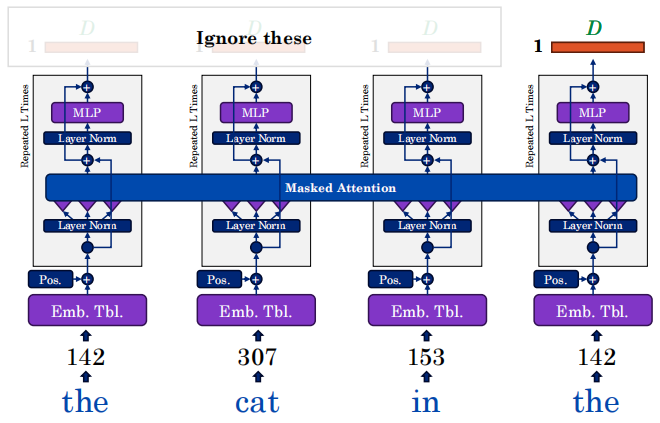
-
多头注意力(Multi-Head Attention):图里那个蓝色的长条
Multi-Head Attention。这个阶段,每个词会向其他词“发问”(Q),寻找相关性(K),并提取信息(V)。比如“猫”和“帽子”可能发生强烈的注意力关联。
第五步:挑出概率最高的那个词
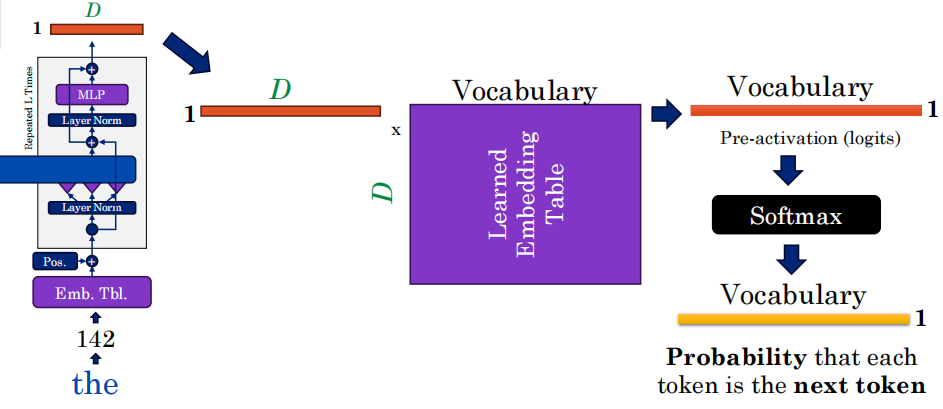
经过层层 Transformer 计算后,我们需要把它变回人类能读懂的文字。
-
输出层(Un-embedding / Logits):经过计算,模型输出了一条长度为D的向量。
-
用这条向量与词汇表叉积,得到各个词的分数(未归一化)
-
Softmax 归一化:把这些密密麻麻的分数扔进 Softmax 函数。函数会把分数变成 0 到 1 之间的概率,并且所有词的概率加起来一定等于 1。
-
结果:模型输出最高概率
hat。
20. LLM输出层Softmax的维度是?
A. D(模型维度)
B. N(序列长度)
C. V(词汇量大小)
D. L(层数)
18.2 GPT = 生成式预训练Transformer ⭐
| 字母 | 含义 |
|---|---|
| G (Generative) | 生成式—建模文本的创建 |
| P (Pretrained) | 预训练—在海量自然数据上训练 |
| T (Transformer) | 神经网络架构 |
预训练(Pre-training)
- 单段文本→每个token都是训练样本
- 最大化下一token的似然(MLE)→交叉熵损失
- 每个位置的输出预测下一个token
- 数据混合(Data Mix):多源数据→学习通用模式
2. LLM预训练的目标是?
A. 分类准确率
B. 最大化下一token的似然(MLE/交叉熵)
C. 最小化参数量
D. 最大化推理速度
15. 预训练中每句话有多少个训练样本?
A. 1个
B. 每个token都作为一个训练样本(预测下一token)
C. 整个句子算一个
D. 随机数量
18.3 后训练(Post-training)⭐
GPT alone can’t chat! — 预训练只能补全文本,不会对话
三种后训练方法
| 方法 | 核心 | 数据 |
|---|---|---|
| SFT(监督微调) | 给定 “指令-回答” 对,让模型学会“按人类方式回答问题” | 高质量对话数据 |
| RLHF(人类反馈强化学习) | 让模型给同一个问题生成几个不同的答案,人类打分,PPO训练 | 人类偏好对比 |
| DPO(直接偏好优化) | 同样使用人类偏好数据,但抛弃了复杂的强化学习(PPO)。它直接把这些“偏好对比”转化为标准的最大似然估计(MLE/交叉熵)问题。 | 人类偏好对比 |
18.4 LoRA(低秩适应)⭐
在微调大模型时,如果直接修改 GPT 的全部几千亿参数,显存根本装不下,且极易让模型“丢失”原有的通用能力。
核心思想
-
原理:冻结原来的大模型权重(W),只在旁边并联加入两个极小的低秩矩阵(A 和 B)。训练时只更新这两个小矩阵。

18.5 关键应用技术 ⭐
RAG(检索增强生成)
-
痛点:大模型的知识截止到训练那一天
-
做法:用户问问题 → 系统先去外部数据库/搜索引擎检索相关文档 → 把找到的文档加上用户问题,一起喂给大模型 → 大模型基于新资料回答问题。
-
优势:无需重新训练模型,低成本实现“知识库更新”和“防幻觉”。
Chain-of-Thought(思维链)
- 提示模型"一步步思考"→生成长推理链
- 行为:规划+反思+自我修正+回溯
Agentic Systems(智能体系统)
用户目标 → LLM(推理+工具调用) → 工具执行 → 观察结果 → LLM再次推理 → ...
- ReAct Agent:Reasoning + Acting循环
- 工具:搜索、计算器、邮件等→LLM主动调用
In-Context Learning(上下文学习)
- Zero-shot:直接提问(依赖已有知识)
- Few-shot:给几个例子→模型模仿
视觉语言模型(VLM)
第二步:充当“同声传译” (Learned Adapter → 投影到 LLM 空间)
这是最核心、也是技巧性最强的一步!
第三步:拉平认知,多模态推理 (统一表示)
-
第一步:像切西瓜一样,把图片“切开” (Vision Encoder → Image Patch)
-
问题:大语言模型(LLM)只能处理一串数字(Token)。一张高分辨率的高清照片,包含几百万个像素点,LLM 根本塞不进去。
-
VLM 的做法(计算机视觉的标准动作):不把整张图扔进去,而是把一张图切分成很多个小的正方形块(Patch)。比如切成 14×14 大小的网格(类似切西瓜)。
-
视觉编码器(Vision Encoder):用专门的图像模型(如 CLIP 或 SigLIP 的视觉侧)去处理这些“小方块(Patch)”,把它们转换成一串连续的数字向量(Token Embeddings)。这样,一张图片就被“翻译”成了几百个像文字一样的tokens。
-
问题:虽然图片变成了数字向量,但图像模型生成数字向量的“语言”,和大语言模型读懂数字向量的“语言”,是两种完全不同的数学语言。如果把图像向量直接粗暴地塞进 LLM,LLM 完全看不懂(就像给一个只会英语的人直接塞俄语字母)。
-
适配器(Learned Adapter):在这里就是一个“翻译器”(在代码中通常是一个或者几个简单的线性层/MLP 层)。它通过训练,学会了一套规则:
-
将图像模型输出的向量,“投影(映射)”到 LLM 能够读懂的数字分布区间里。
-
让本来代表“图像中的某个边缘、某个物体”的向量,变成 LLM 能理解的代表“形状、颜色、物体名称”的概念。
-
-
做法:经过上面两步,图像变成了和文字一模一样的“Token 序列”。
-
统一表示:现在,LLM 拿到了一大串输入:
[文本Token] [图像Patch Token] [文本Token]。因为格式已经完全打通了,LLM 就可以像读一段长文章一样,同时处理图像信息和文本信息。 -
结果:LLM 算着算着,就能推理出“图片里有一只猫在沙发上,请问这个沙发的颜色是什么?”这种跨模态的答案。
结束
模拟卷与基础笔记提示词
请帮我整理第一单元的知识点和笔记,参考Lecture 01 -- Introduction.pdf,之后这门课的所有PPT都在这个路径下:“E:\作业\大二\大二下\认知科学类脑计算\PPT\机器学习与模式识别\PPT”我的课堂笔记(严重不全,一开始和最后几节课我才记了笔记)链接:【第一部分】【第二部分】
(你需要提取文字和图片)。请你调用合适的skill阅读图片和文字,除了笔记之外,需要你模拟一套这个单元的习题,包含选择(20道),判断(15),简答(5-8)如果有重要计算也请出(3-5个),然后需要再写另一个md是答案。 此外,你需要持续维护一个文档,叫A4_final.docs,用于记录每一章的核心要点,因为我们允许带一张手写稿进入考场,要尽可能压缩用语。可以有图片,如果你无法从我的课堂笔记中抓取到图片并插入这个文档,请你在需要插入图片的地方标注【图片内容/描述+位置】。中途有任何不明确的需求请你咨询我。遇到问题请看看有没有合适的skill可以使用。在我审核第一单元的所有内容符合期望后,会逐步让你生成后续章节的笔记和试题的。
单选,判断,简答,计算


















 1255
1255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










