



文章目录
- 前言🚀
- 九、Maven
- 十、SpringBootWeb
- 十一、SpringBootWeb请求响应
- 十二、数据库开发-MySQL
- 十三、Mybatis
- 十四、SpringBootWeb案例
- 十五、事务&AOP
前言🚀
本人是一个大三的计算机科学与技术专业的学生,目前还处于学习阶段,已经跟随bilibili黑马的课程学完了很多java后端的内容(javase、javaweb、git、linux、mysql、redis、springcloud等等),平时学习会做一些笔记,笔记毫不废话,开门见山,这也是我做笔记的个人习惯吧,这里分享一下我做的JavaWeb部分的学习笔记,笔记内容跟随黑马程序员的javaweb教程,课程地址如下:
https://www.bilibili.com/video/BV1m84y1w7Tb?t=1.6
笔记内容有点多,但是可以根据目录自动导航到特定章节进行复习或学习。
说明:这篇笔记只是一个初步的第一版笔记哦,相应的配套资料可以下载黑马的资料,我也准备了一个飞书版本的文章,平时博主复习也是使用的飞书知识库进行复习,所以另一个版本的文章会更加完善,而且,另一个版本也有一些资料的提供(不是全部哦),如果你想要,点击链接https://mcnerzykwkel.feishu.cn/wiki/KIfZw5wKAi0rXjkKRDkcPc2onyf就可以了,如果你有更好的建议,直接在飞书内评论说明就可以咯,但是博主还是很自信不会有几个建议的😊。
九、Maven
1.Maven概述
Maven是Apache旗下的一个开源项目,是一款用于管理和构建java项目的工具。
1.1 Maven的作用
- 方便的依赖管理:方便快捷的管理项目依赖的资源(jar包),避免版本冲突问题
在maven项目的pom.xml文件中,添加一段如下图所示的配置即可实现
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.2.13.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.4</version>
</dependency>
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>com.github.oshi</groupId>
<artifactId>oshi-core</artifactId>
<version>5.6.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
- 统一的项目结构:提供标准、统一的项目结构,解决不同开发工具的项目结构不一致问题。
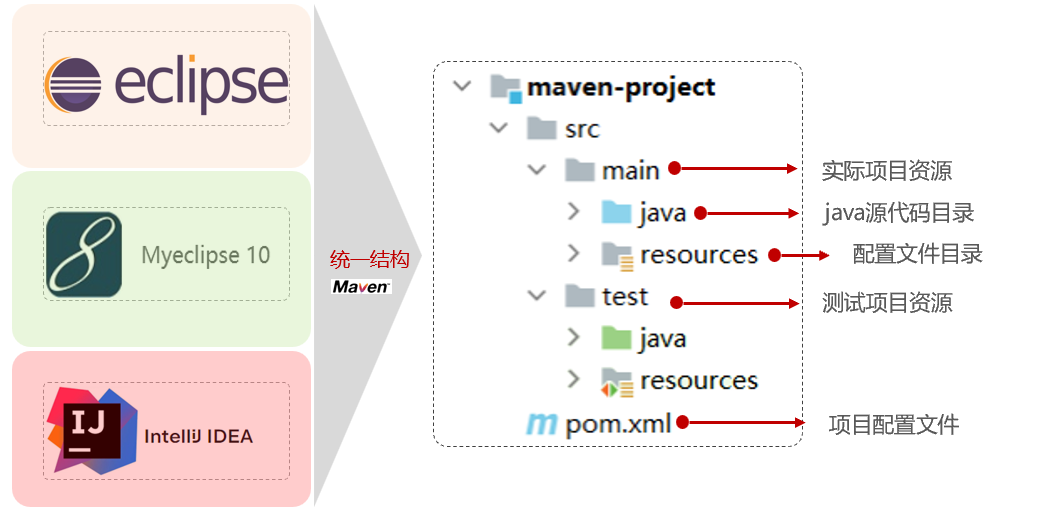
- 标准的项目构建流程:标准跨平台(Linux、Windows、MacOS)的自动化项目构建方式。我们开发一套系统需要进行编译、测试、打包、发布,这些操作如果需要反复进行就显得特别麻烦,Maven提供了一套简单的命令来完成项目构建。
1.2 Maven模型
-
项目对象模型 (Project Object Model):将我们自己的项目抽象成一个对象模型,有自己专属的坐标,通过坐标可以定位到所需资源(jar包)位置
-
依赖管理模型(Dependency):使用坐标来描述当前项目依赖哪些第三方jar包,通过在pom.xml文件中自定义的坐标自动从本地仓库下载导入相关的jar包
-
构建生命周期/阶段(Build lifecycle & phases):当我们需要编译,Maven提供了一个编译插件供我们使用;当我们需要打包,Maven就提供了一个打包插件供我们使用等
1.3 Maven仓库
仓库:用于存储资源,管理各种jar包。
Maven仓库分为:
- 本地仓库:自己计算机上的一个目录(用来存储jar包)
- 中央仓库:由Maven团队维护的全球唯一的。仓库地址:https://repo1.maven.org/maven2/
- 远程仓库(私服):一般由公司团队搭建的私有仓库
当项目中使用坐标引入对应依赖jar包后,首先会查找本地仓库中是否有对应的jar包
-
如果有,则在项目直接引用
-
如果没有,则去中央仓库中下载对应的jar包到本地仓库
如果还可以搭建远程仓库(私服),将来jar包的查找顺序则变为: 本地仓库 --> 远程仓库–> 中央仓库
1.4 Maven安装
参考资料中的安装文档安装即可
2.IDEA集成Maven
2.1 配置Maven环境
参考资料中的安装文档安装即可,创建maven项目和导入maven项目也参考资料中的安装文档安装。
2.2 POM配置详解
POM (Project Object Model) :指的是项目对象模型,用来描述当前的maven项目。
- 使用pom.xml文件来实现
pom.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<!-- POM模型版本 -->
<modelVersion>4.0.0</modelVersion>
<!-- 当前项目坐标 -->
<groupId>com.itheima</groupId>
<artifactId>maven_project1</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 打包方式 -->
<packaging>jar</packaging>
</project>
pom文件详解:
<project>:pom文件的根标签,表示当前maven项目<modelVersion>:声明项目描述遵循哪一个POM模型版本- 虽然模型本身的版本很少改变,但它仍然是必不可少的。目前POM模型版本是4.0.0
- 坐标 :
<groupId>、<artifactId>、<version>- 定位项目在本地仓库中的位置,由以上三个标签组成一个坐标
<packaging>:maven项目的打包方式,通常设置为jar或war(默认值:jar)
2.3 Maven坐标详解
什么是坐标?
- Maven中的坐标是资源的唯一标识 , 通过该坐标可以唯一定位资源位置
- 使用坐标来定义项目或引入项目中需要的依赖
Maven坐标主要组成
- groupId:定义当前Maven项目隶属组织名称(通常是域名反写,例如:com.itheima)
- artifactId:定义当前Maven项目名称(通常是模块名称,例如 order-service、goods-service)
- version:定义当前项目版本号
如下图就是使用坐标表示一个项目:

注意:
- 上面所说的资源可以是插件、依赖、当前项目。
- 我们的项目如果被其他的项目依赖时,也是需要坐标来引入的。
3.依赖管理
3.1 依赖配置
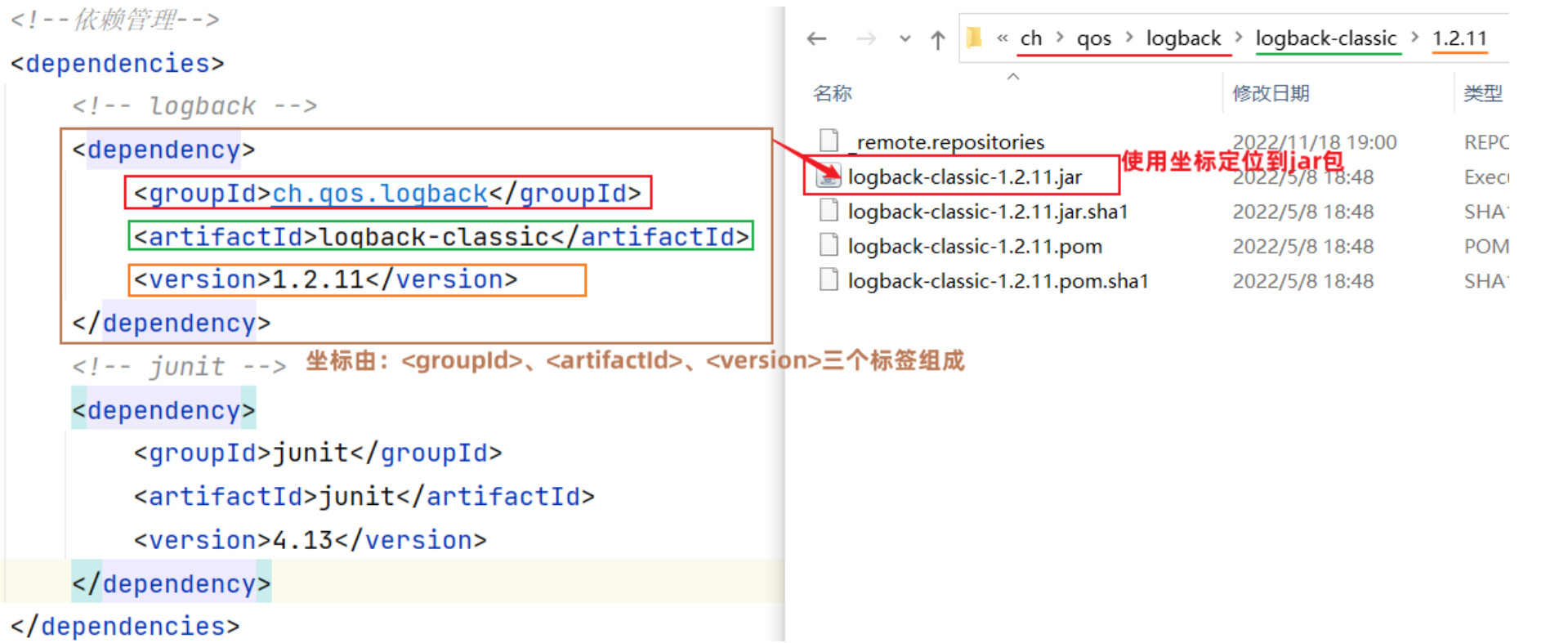
依赖指当前项目运行所需要的jar包,例如,在当前工程中,我们需要用到logback来记录日志,此时就可以在maven工程的pom.xml文件中,引入logback的依赖:
-
在pom.xml中编写
<dependencies>标签 -
在
<dependencies>标签中使用<dependency>引入坐标 -
定义坐标的 groupId、artifactId、version
<dependencies>
<!-- 第1个依赖 : logback -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.11</version>
</dependency>
<!-- 第2个依赖 : junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
- 注:如果不知道依赖的坐标信息,可以到mvn的中央仓库(https://mvnrepository.com/)中搜索
- 点击刷新按钮,引入最新加入的坐标
3.2 依赖传递
由于logback-classic依赖logback-core和slf4j,在添加logback-classic依赖时,会自动把所依赖的其他jar包logback-core和slf4j也一起导,故只需要在pom.xml配置文件中,添加logback-classic的依赖坐标即可。
依赖传递可以分为:
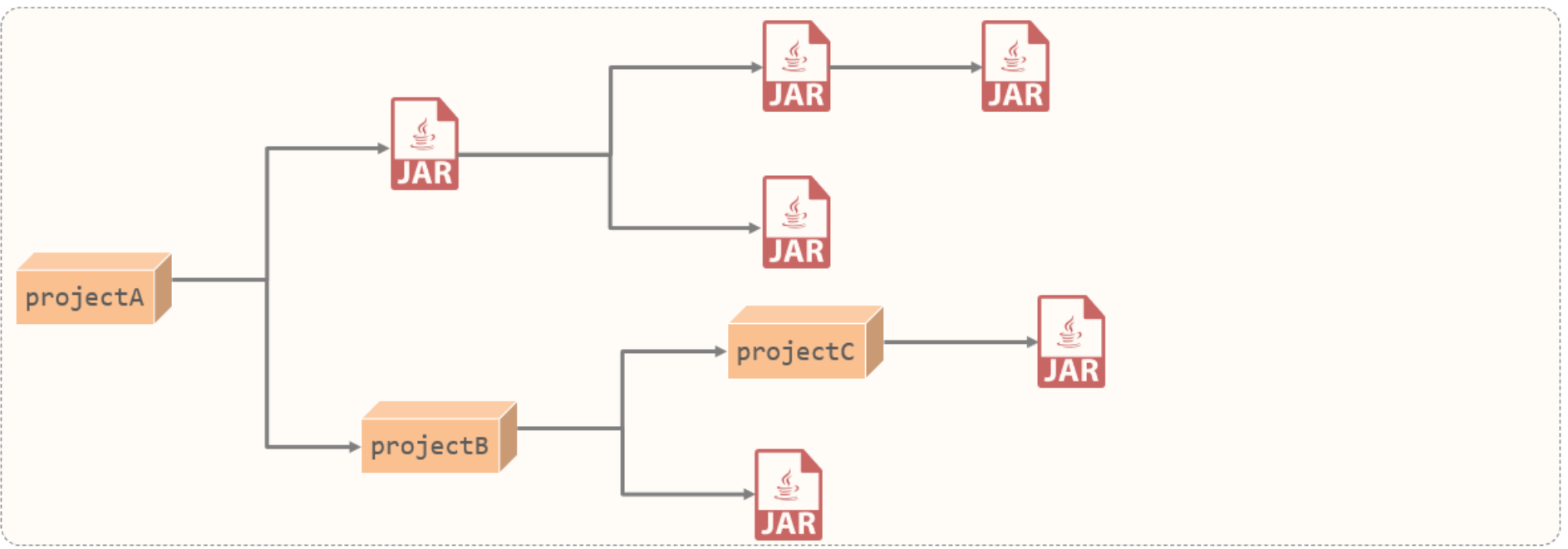
-
直接依赖:在当前项目中通过依赖配置建立的依赖关系
-
间接依赖:被依赖的资源如果依赖其他资源,当前项目间接依赖其他资源
例如对于projectA 来说,projectB 就是直接依赖,projectC就是间接依赖:
排除依赖
主动断开依赖的资源(被排除的资源无需指定版本)。
<dependency>
<groupId>com.itheima</groupId>
<artifactId>maven-projectB</artifactId>
<version>1.0-SNAPSHOT</version>
<!--排除依赖, 主动断开依赖的资源-->
<exclusions>
<exclusion>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</exclusion>
</exclusions>
</dependency>
3.3 依赖范围
限制依赖的使用范围,可以通过<scope>标签设置其作用范围。
作用范围:
-
主程序范围有效(main文件夹范围内)
-
测试程序范围有效(test文件夹范围内)
-
是否参与打包运行(package指令范围内)
scope标签的取值范围:
| scope值 | 主程序 | 测试程序 | 打包(运行) | 范例 |
|---|---|---|---|---|
| compile(默认) | Y | Y | Y | log4j |
| test | - | Y | - | junit |
| provided | Y | Y | - | servlet-api |
| runtime | - | Y | Y | jdbc驱动 |
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.1</version>
<scope>test</scope>
</dependency>
3.4 生命周期
Maven的生命周期描述了一次项目构建经历哪些阶段,在Maven出现之前,项目构建的生命周期就已经存在
Maven对项目构建的生命周期划分为3套(相互独立):
-
clean:清理工作。
-
default:核心工作。如:编译、测试、打包、安装、部署等。
-
site:生成报告、发布站点等。

常使用的5个阶段含义:
• clean:移除上一次构建生成的文件
• compile:编译项目源代码
• test:使用合适的单元测试框架运行测试(junit)
• package:将编译后的文件打包,如:jar、war等
• install:安装项目到本地仓库
在同一套生命周期中,我们在执行后面的生命周期时,前面的生命周期都会执行,例如执行package阶段,compile和test都会执行,但是clean不会执行,因为package和clean不在同一套生命周期。
执行某一阶段生命周期
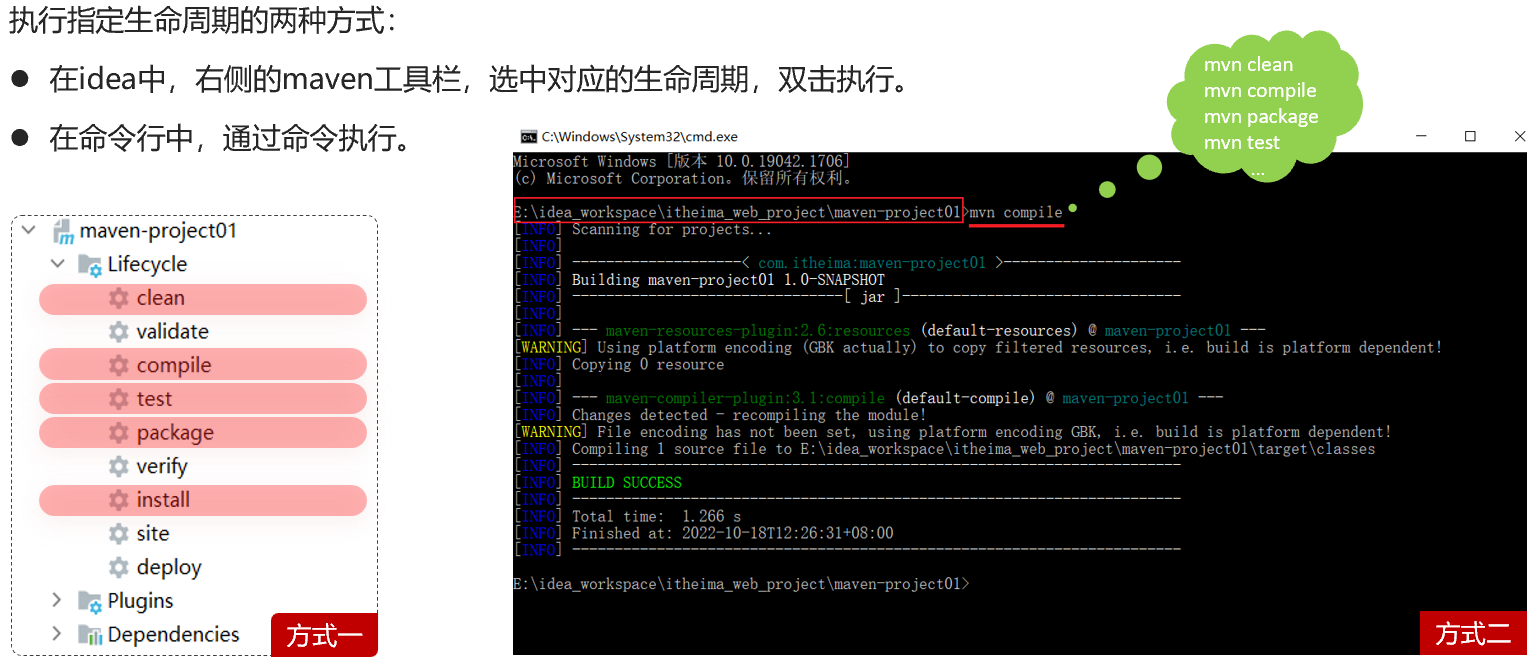
执行指定的生命周期时,有两种执行方式:
- 在idea工具右侧的maven工具栏中,选择对应的生命周期,双击执行
- 在DOS命令行中,通过maven命令执行
- 进入到maven项目的命令行中
- 运行命令
mvn 阶段名
3.5 清理maven仓库
从私服下载jar包时,可能由于网络的原因,jar包下载不完全,这些不完整的jar包都是以lastUpdated结尾,maven不会再重新下载,需要手动删除这些以lastUpdated结尾的文件,然后maven才会再次自动下载这些jar包。
可以定义一个批处理文件,在其中编写如下脚本来删除:
set REPOSITORY_PATH=E:\develop\apache-maven-3.6.1\mvn_repo
rem 正在搜索...
del /s /q %REPOSITORY_PATH%\*.lastUpdated
rem 搜索完毕
pause
1). 定义批处理文件del_lastUpdated.bat (直接创建一个文本文件,命名为del_lastUpdated,后缀名直接改为bat即可 )

2). 在上面的bat文件上右键—》编辑 。修改文件:

修改完毕后,运行即可删除maven仓库中的残留文件
十、SpringBootWeb
通过springboot可以快速的帮我们构建应用程序,简化开发、提高效率。
springboot最大的特点有两个:简化配置和快速开发
1.SpringBootWeb快速入门
基于SpringBoot的方式开发一个web应用,浏览器发起请求/hello后,给浏览器返回字符串 “Hello World ~”:

1.1 创建SpringBoot工程(需要联网)
基于Spring官方骨架,创建SpringBoot工程。
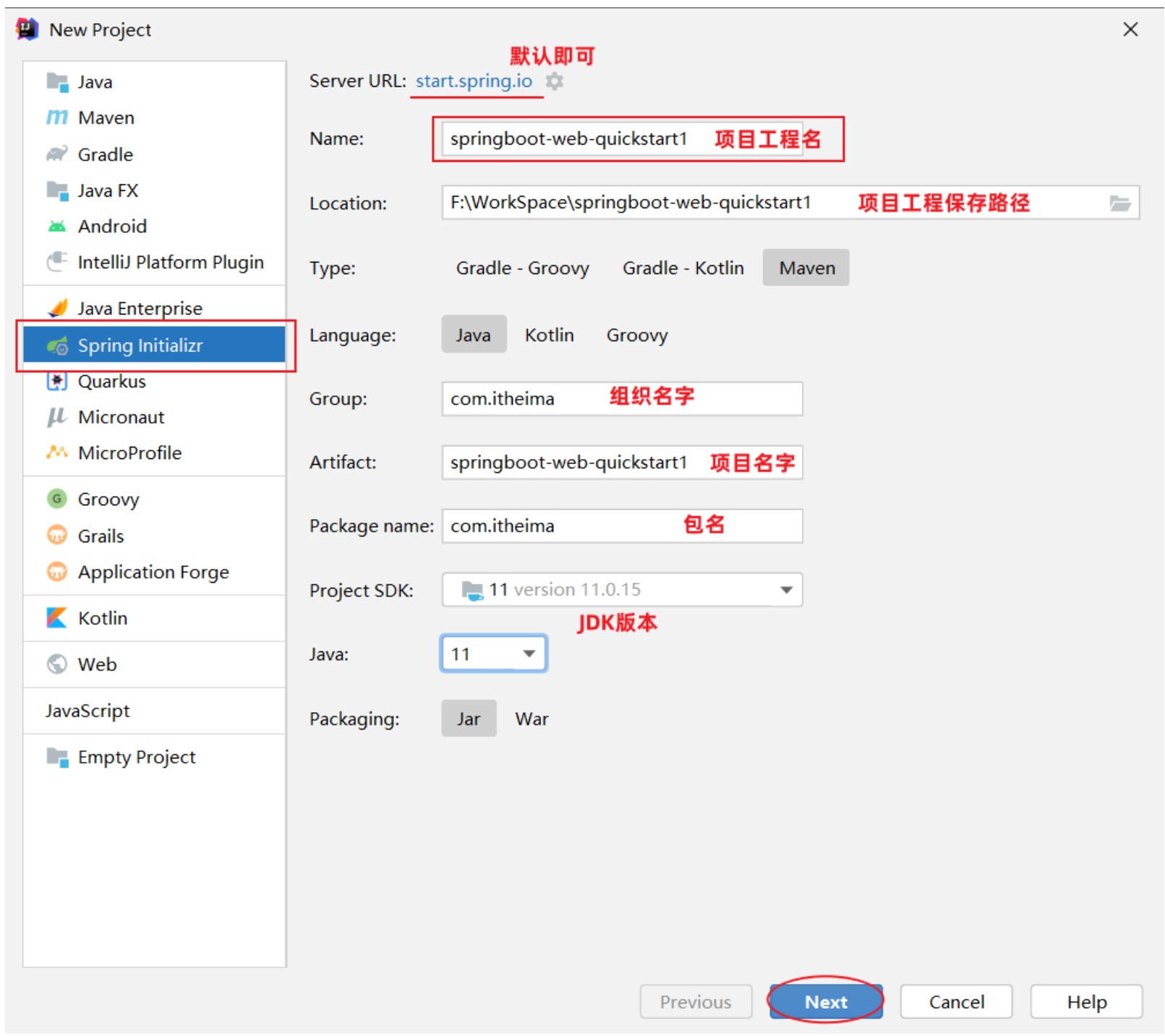
之后选上Spring Web即可。
1.2 定义请求处理类
在Demo1Application类所在的包下创建java类HelloController:
package com.itheima.controller;
import org.springframework.web.bind.annotation.*;
@RestController
public class HelloController {
@RequestMapping("/hello")
public String hello(){
System.out.println("Hello World ~");
return "Hello World ~";
}
}
1.3 运行测试
- 运行SpringBoot自动生成的引导类HelloController
- 打开浏览器,输入
http://localhost:8080/hello,出现Hello World~即表示成功。
1.4 Web分析

浏览器:
-
输入网址:
http://192.168.100.11:8080/hello-
通过IP地址192.168.100.11定位到网络上的一台计算机
我们之前在浏览器中输入的localhost,就是127.0.0.1(本机)
-
通过端口号8080找到计算机上运行的程序
localhost:8080, 意思是在本地计算机中找到正在运行的8080端口的程序 -
/hello是请求资源位置
- 资源:对计算机而言资源就是数据
- web资源:通过网络可以访问到的资源(通常是指存放在服务器上的数据)
localhost:8080/hello,意思是向本地计算机中的8080端口程序,获取资源位置是/hello的数据- 8080端口程序,在服务器找/hello位置的资源数据,发给浏览器
- 资源:对计算机而言资源就是数据
-
服务器:(可以理解为ServerSocket)
- 接收到浏览器发送的信息(如:/hello)
- 在服务器上找到/hello的资源
- 把资源发送给浏览器
2.HTTP协议
HTTP协议(超文本传输协议),规定了浏览器与服务器之间数据传输的规则,即浏览器在向服务器发送请求数据时,或是服务器在向浏览器发送响应数据时,都必须按照固定的格式进行数据传输。
特点:
- 基于TCP协议:面向连接,安全
- 基于请求-响应模型:一次请求对应一次响应(先请求后响应,没有请求就没有响应)
- 无状态协议:对于数据没有记忆能力,每次请求-响应都是独立的。无状态指客户端发送HTTP请求给服务端之后,服务端根据请求响应数据,响应完后,不会记录任何信息
2.1 HTTP-请求协议
HTTP协议分为请求协议和响应协议。
- 请求协议:浏览器将数据以请求格式发送到服务器
- 包括:请求行、请求头 、请求体
- 响应协议:服务器将数据以响应格式返回给浏览器
- 包括:响应行 、响应头 、响应体
在HTTP1.1版本中,浏览器访问服务器的几种方式:
| 请求方式 | 请求说明 |
|---|---|
| GET | 获取资源。 向特定的资源发出请求。例:http://www.baidu.com/s?wd=itheima |
| POST | 传输实体主体。 向指定资源提交数据进行处理请求(例:上传文件),数据被包含在请求体中。 |
| OPTIONS | 返回服务器针对特定资源所支持的HTTP请求方式。 因为并不是所有的服务器都支持规定的方法,为了安全有些服务器可能会禁止掉一些方法,例如:DELETE、PUT等。那么OPTIONS就是用来询问服务器支持的方法。 |
| HEAD | 获得报文首部。 HEAD方法类似GET方法,但是不同的是HEAD方法不要求返回数据。通常用于确认URI的有效性及资源更新时间等。 |
| PUT | 传输文件。 PUT方法用来传输文件。类似FTP协议,文件内容包含在请求报文的实体中,然后请求保存到URL指定的服务器位置。 |
| DELETE | 删除文件。 请求服务器删除Request-URI所标识的资源 |
| TRACE | 追踪路径。 回显服务器收到的请求,主要用于测试或诊断 |
| CONNECT | 要求用隧道协议连接代理。 HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器 |
在我们实际应用中常用的也就是 :GET、POST
2.1.1 GET方式的请求协议

-
请求行 :HTTP请求中的第一行数据。由:
请求方式、资源路径、协议/版本组成(之间使用空格分隔)- 请求方式:GET
- 资源路径:/brand/findAll?name=OPPO&status=1
- 请求路径:/brand/findAll
- 请求参数:name=OPPO&status=1
- 请求参数是以key=value形式出现
- 多个请求参数之间使用
&连接
- 请求路径和请求参数之间使用
?连接
- 协议/版本:HTTP/1.1
-
请求头 :第二行开始,上图黄色部分内容就是请求头。格式为key: value形式
- http是个无状态的协议,所以在请求头设置浏览器的一些自身信息和想要响应的形式。这样服务器在收到信息后,就可以知道是谁,想干什么了
常见的HTTP请求头有:
Host: 表示请求的主机名 User-Agent: 浏览器版本。 例如:Chrome浏览器的标识类似Mozilla/5.0 ...Chrome/79 ,IE浏览器的标识类似Mozilla/5.0 (Windows NT ...)like Gecko Accept:表示浏览器能接收的资源类型,如text/*,image/*或者*/*表示所有; Accept-Language:表示浏览器偏好的语言,服务器可以据此返回不同语言的网页; Accept-Encoding:表示浏览器可以支持的压缩类型,例如gzip, deflate等。 Content-Type:请求主体的数据类型 Content-Length:数据主体的大小(单位:字节)
举例说明:服务端可以根据请求头中的内容来获取客户端的相关信息,有了这些信息服务端就可以处理不同的业务需求。
比如:
- 不同浏览器解析HTML和CSS标签的结果会有不一致,所以就会导致相同的代码在不同的浏览器会出现不同的效果
- 服务端根据客户端请求头中的数据获取到客户端的浏览器类型,就可以根据不同的浏览器设置不同的代码来达到一致的效果(这就是我们常说的浏览器兼容问题)
- 请求体 :存储请求参数
- GET请求的请求参数在请求行中,故不需要设置请求体
2.1.2 POST方式的请求协议
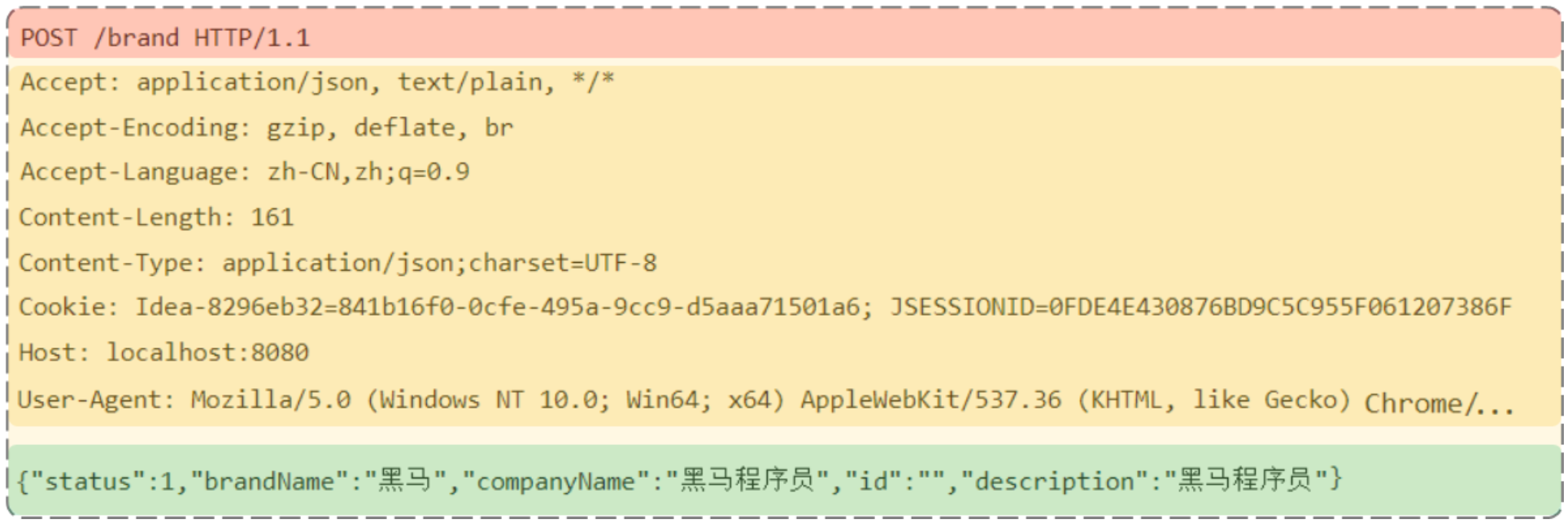
- 请求行(以上图中红色部分):包含请求方式、资源路径、协议/版本
- 请求方式:POST
- 资源路径:/brand
- 协议/版本:HTTP/1.1
- 请求头(以上图中黄色部分)
- 请求体(以上图中绿色部分) :存储请求参数
- 请求体和请求头之间是有一个空行隔开(作用:用于标记请求头结束)
GET请求和POST请求的区别:
| 区别方式 | GET请求 | POST请求 |
|---|---|---|
| 请求参数 | 请求参数在请求行中。 例:/brand/findAll?name=OPPO&status=1 | 请求参数在请求体中 |
| 请求参数长度 | 请求参数长度有限制(浏览器不同限制也不同) | 请求参数长度没有限制 |
| 安全性 | 安全性低。原因:请求参数暴露在浏览器地址栏中。 | 安全性相对高 |
2.2 HTTP-响应协议
与HTTP的请求一样,HTTP响应的数据也分为3部分:响应行、响应头 、响应体。

-
响应行(以上图中红色部分):响应数据的第一行。响应行由
协议及版本、响应状态码、状态码描述组成- 协议/版本:HTTP/1.1
- 响应状态码:200
- 状态码描述:OK
-
响应头(以上图中黄色部分):响应数据的第二行开始。格式为key:value形式
- http是个无状态的协议,所以可以在请求头和响应头中设置一些信息和想要执行的动作,这样,对方在收到信息后,就可以知道你是谁,你想干什么
常见的HTTP响应头有:
Content-Type:表示该响应内容的类型,例如text/html,image/jpeg ; Content-Length:表示该响应内容的长度(字节数); Content-Encoding:表示该响应压缩算法,例如gzip ; Cache-Control:指示客户端应如何缓存,例如max-age=300表示可以最多缓存300秒 ; Set-Cookie: 告诉浏览器为当前页面所在的域设置cookie ;
- 响应体(以上图中绿色部分): 响应数据的最后一部分。存储响应的数据
- 响应体和响应头之间有一个空行隔开(作用:用于标记响应头结束)
响应状态码
| 状态码分类 | 说明 |
|---|---|
| 1xx | 响应中 — 临时状态码。表示请求已经接受,告诉客户端应该继续请求或者如果已经完成则忽略 |
| 2xx | 成功 — 表示请求已经被成功接收,处理已完成 |
| 3xx | 重定向 — 重定向到其它地方,让客户端再发起一个请求以完成整个处理 |
| 4xx | 客户端错误 — 处理发生错误,责任在客户端,如:客户端的请求一个不存在的资源,客户端未被授权,禁止访问等 |
| 5xx | 服务器端错误 — 处理发生错误,责任在服务端,如:服务端抛出异常,路由出错,HTTP版本不支持等 |
| 状态码 | 英文描述 | 解释 |
|---|---|---|
| 200 | OK | 客户端请求成功,即处理成功,这是我们最想看到的状态码 |
| 302 | Found | 指示所请求的资源已移动到由Location响应头给定的 URL,浏览器会自动重新访问到这个页面 |
| 304 | Not Modified | 告诉客户端,你请求的资源至上次取得后,服务端并未更改,你直接用你本地缓存吧。隐式重定向 |
| 400 | Bad Request | 客户端请求有语法错误,不能被服务器所理解 |
| 403 | Forbidden | 服务器收到请求,但是拒绝提供服务,比如:没有权限访问相关资源 |
| 404 | Not Found | 请求资源不存在,一般是URL输入有误,或者网站资源被删除了 |
| 405 | Method Not Allowed | 请求方式有误,比如应该用GET请求方式的资源,用了POST |
| 428 | Precondition Required | 服务器要求有条件的请求,告诉客户端要想访问该资源,必须携带特定的请求头 |
| 429 | Too Many Requests | 指示用户在给定时间内发送了太多请求(“限速”),配合 Retry-After(多长时间后可以请求)响应头一起使用 |
| 431 | Request Header Fields Too Large | 请求头太大,服务器不愿意处理请求,因为它的头部字段太大。请求可以在减少请求头域的大小后重新提交。 |
| 500 | Internal Server Error | 服务器发生不可预期的错误。服务器出异常了,赶紧看日志去吧 |
| 503 | Service Unavailable | 服务器尚未准备好处理请求,服务器刚刚启动,还未初始化好 |
状态码大全:https://cloud.tencent.com/developer/chapter/13553
关于响应状态码,我们先主要认识三个状态码,其余的等后期用到了再去掌握:
- 200 ok 客户端请求成功
- 404 Not Found 请求资源不存在
- 500 Internal Server Error 服务端发生不可预期的错误
2.3 HTTP-协议解析
以下是一个自定义的服务器代码,主要使用到的是ServerSocket和Socket:
package com.itheima;
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
import java.nio.charset.StandardCharsets;
/*
* 自定义web服务器
*/
public class Server {
public static void main(String[] args) throws IOException {
ServerSocket ss = new ServerSocket(8080); // 监听指定端口
System.out.println("server is running...");
while (true){
Socket sock = ss.accept();
System.out.println("connected from " + sock.getRemoteSocketAddress());
Thread t = new Handler(sock);
t.start();
}
}
}
class Handler extends Thread {
Socket sock;
public Handler(Socket sock) {
this.sock = sock;
}
public void run() {
try (InputStream input = this.sock.getInputStream();
OutputStream output = this.sock.getOutputStream()) {
handle(input, output);
} catch (Exception e) {
try {
this.sock.close();
} catch (IOException ioe) {
}
System.out.println("client disconnected.");
}
}
private void handle(InputStream input, OutputStream output) throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(input, StandardCharsets.UTF_8));
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(output, StandardCharsets.UTF_8));
// 读取HTTP请求:
boolean requestOk = false;
String first = reader.readLine();
if (first.startsWith("GET / HTTP/1.")) {
requestOk = true;
}
for (;;) {
String header = reader.readLine();
if (header.isEmpty()) { // 读取到空行时, HTTP Header读取完毕
break;
}
System.out.println(header);
}
System.out.println(requestOk ? "Response OK" : "Response Error");
if (!requestOk) {// 发送错误响应:
writer.write("HTTP/1.0 404 Not Found\r\n");
writer.write("Content-Length: 0\r\n");
writer.write("\r\n");
writer.flush();
} else {// 发送成功响应:
//读取html文件,转换为字符串
InputStream is = Server.class.getClassLoader().getResourceAsStream("html/a.html");
BufferedReader br = new BufferedReader(new InputStreamReader(is));
StringBuilder data = new StringBuilder();
String line = null;
while ((line = br.readLine()) != null){
data.append(line);
}
br.close();
int length = data.toString().getBytes(StandardCharsets.UTF_8).length;
writer.write("HTTP/1.1 200 OK\r\n");
writer.write("Connection: keep-alive\r\n");
writer.write("Content-Type: text/html\r\n");
writer.write("Content-Length: " + length + "\r\n");
writer.write("\r\n"); // 空行标识Header和Body的分隔
writer.write(data.toString());
writer.flush();
}
}
}
启动ServerSocket程序:
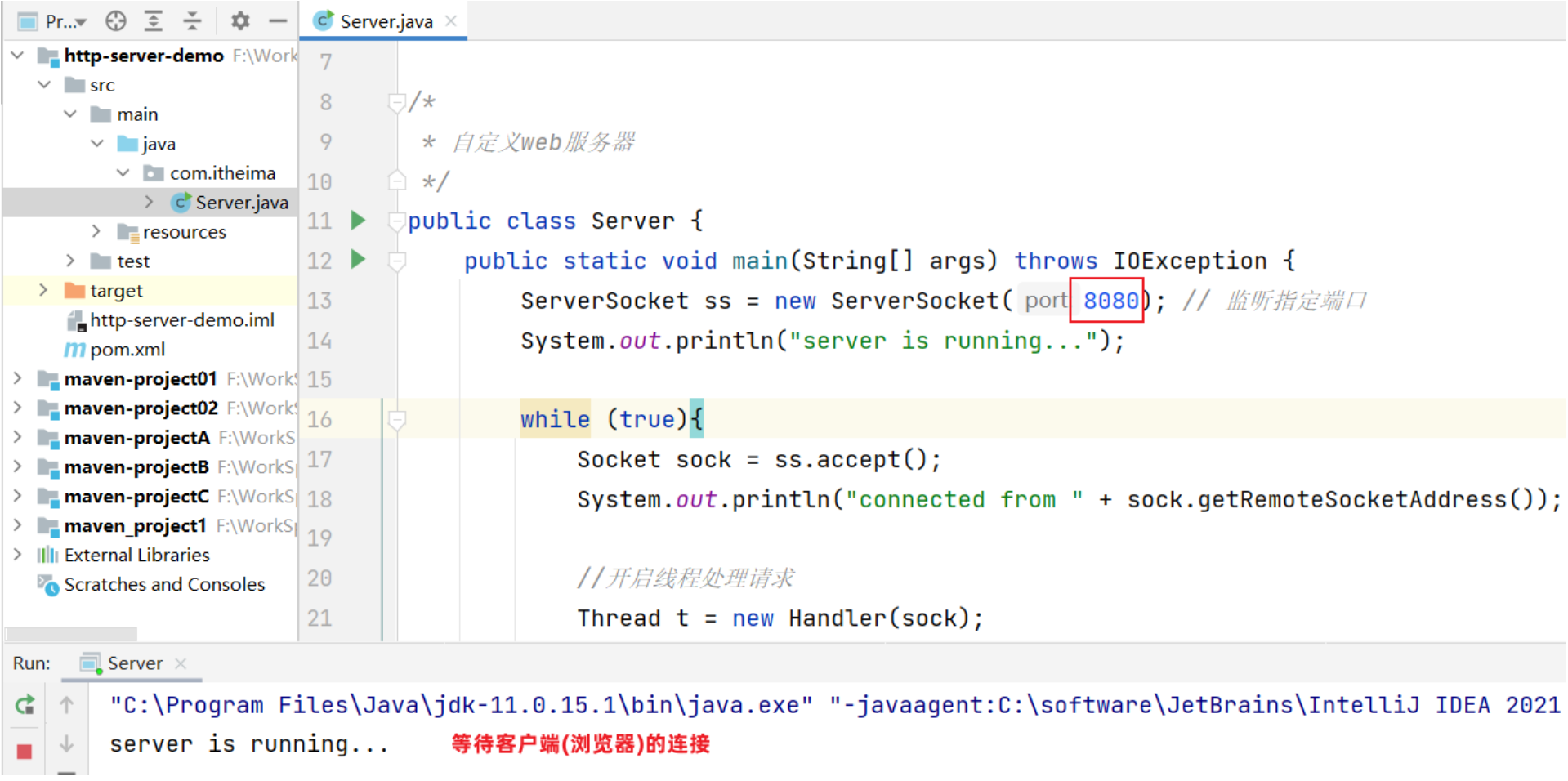
浏览器输入:http://localhost:8080 就会访问到ServerSocket程序
- ServerSocket程序,会读取服务器上
html/a.html文件,并把文件数据发送给浏览器 - 浏览器接收到a.html文件中的数据后进行解析,显示一个表格
在开发中真正用到的Web服务器,我们不会自己写的,都是使用目前比较流行的web服务器。如:Tomcat
3.WEB服务器-Tomcat
Web服务器是一个应用程序(软件),对HTTP协议的操作进行封装,使得程序员不必直接对协议进行操作(不用程序员自己写代码去解析http协议规则),让Web开发更加便捷。主要功能是"提供网上信息浏览服务"。
将来我们把自己写的Web项目部署到Tomcat服务器软件中,当Web服务器软件启动后,部署在Web服务器软件中的页面就可以直接通过浏览器来访问了。
Web服务器软件使用步骤
- 准备静态资源:直接找到资料中的 部署项目 文件夹即可
- 下载安装Web服务器软件:解压即安装
- 将静态资源部署到Web服务器上:将 部署项目 下的demo直接拷贝到Tomcat安装目录下的webapps即可
- 启动Web服务器使用浏览器访问对应的资源:双击启动bin目录下的startup.bat即可
浏览器输入:http://localhost:8080/demo/index.html看到表格就表示成功了
3.1 Tomcat基本使用
直接从官方网站下载:https://tomcat.apache.org/download-90.cgi
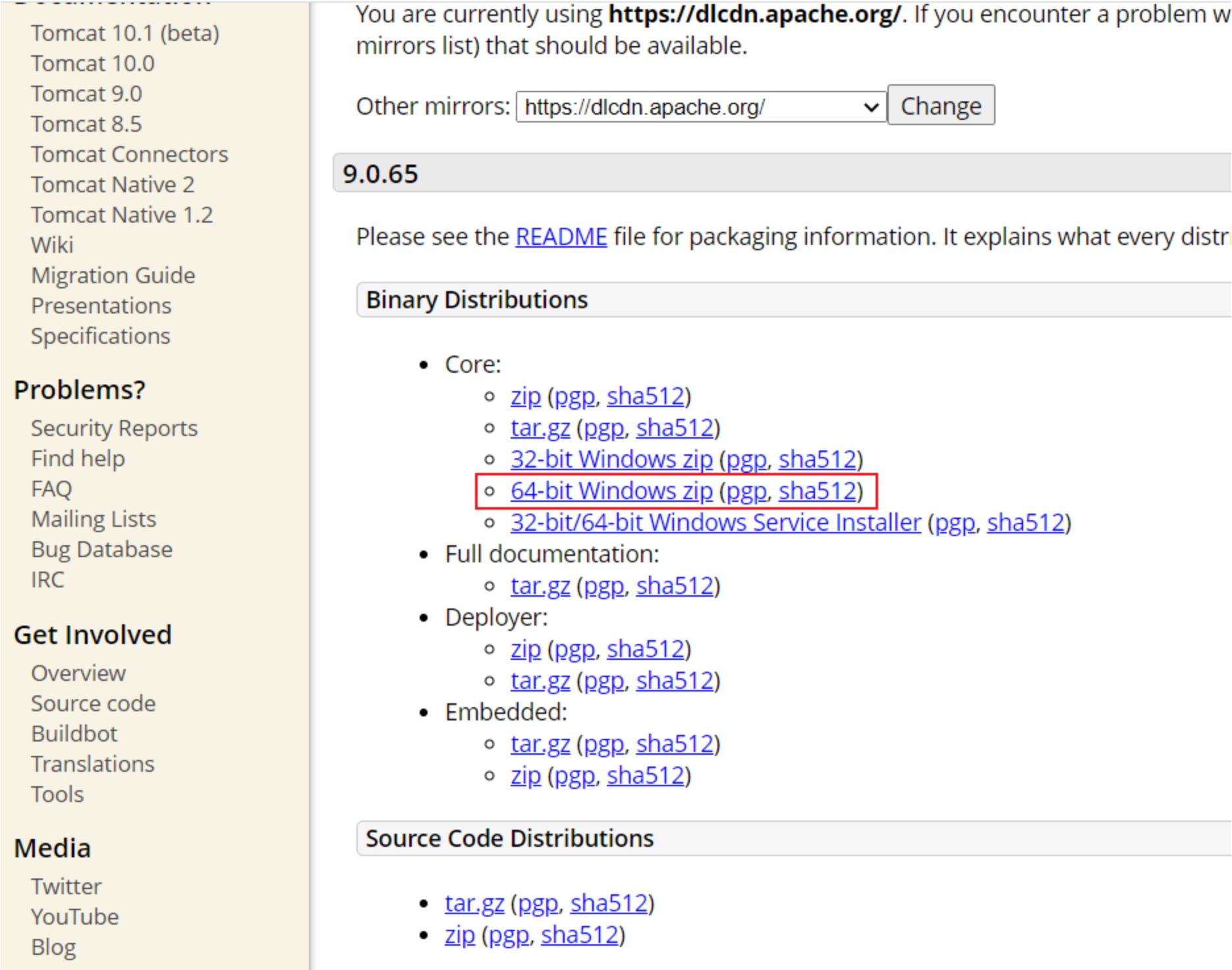
Tomcat软件类型说明:
- tar.gz文件,是linux和mac操作系统下的压缩版本
- zip文件,是window操作系统下压缩版本
直接解压到不含中文和空格的目录下即安装,卸载直接删除这个文件夹即可。
3.1.1 目录结构
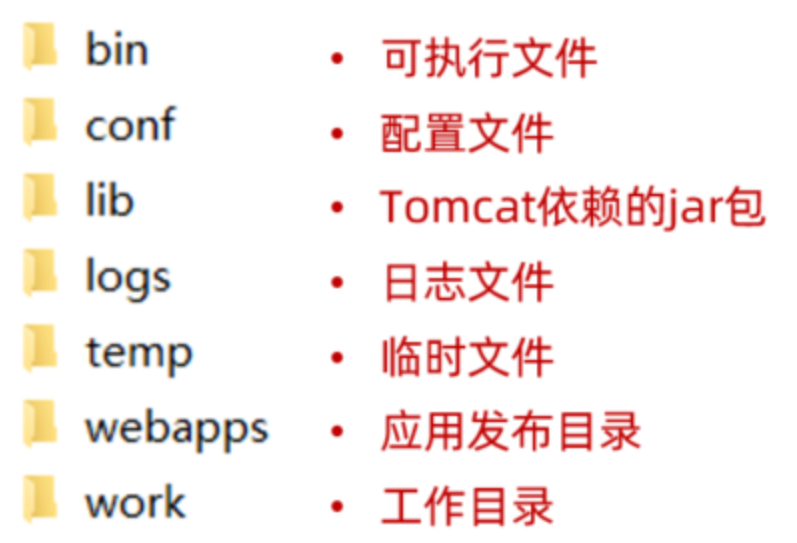
bin:目录下有两类文件,一种是以.bat结尾的,是Windows系统的可执行文件,一种是以.sh结尾的,是Linux系统的可执行文件。
webapps:就是以后项目部署的目录
3.1.2 启动与关闭
启动Tomcat :
双击tomcat解压目录/bin/startup.bat文件即可启动tomcat。
Tomcat的默认端口为8080,所以在浏览器的地址栏输入:http://127.0.0.1:8080 即可访问tomcat服务器
注意:Tomcat启动的过程中,遇到控制台有中文乱码时,可以通常修改conf/logging.pro perties文件解决

关闭:
方式一:强制关闭 -> 直接x掉Tomcat窗口(不建议)
方式二:正常关闭 -> bin\shutdown.bat
方式三:正常关闭 -> 在Tomcat启动窗口中按下 Ctrl+C
3.1.3 常见问题
问题1:Tomcat启动时,窗口一闪而过
检查JAVA_HOME环境变量是否正确配置:…\JDKXxx
问题2:端口号冲突
修改Tomcat启动的端口号,需要修改 conf/server.xml文件

注: HTTP协议默认端口号为80,如果将Tomcat端口号改为80,则将来访问Tomcat时,将不用输入端口号。
3.2 入门程序解析
3.2.1 Spring官方骨架
Spring官方骨架,可以理解为Spring官方为程序员提供一个搭建项目的模板。之前创建项目就是使用的官方骨架:
可以通过访问:https://start.spring.io/ ,进入到官方骨架页面。
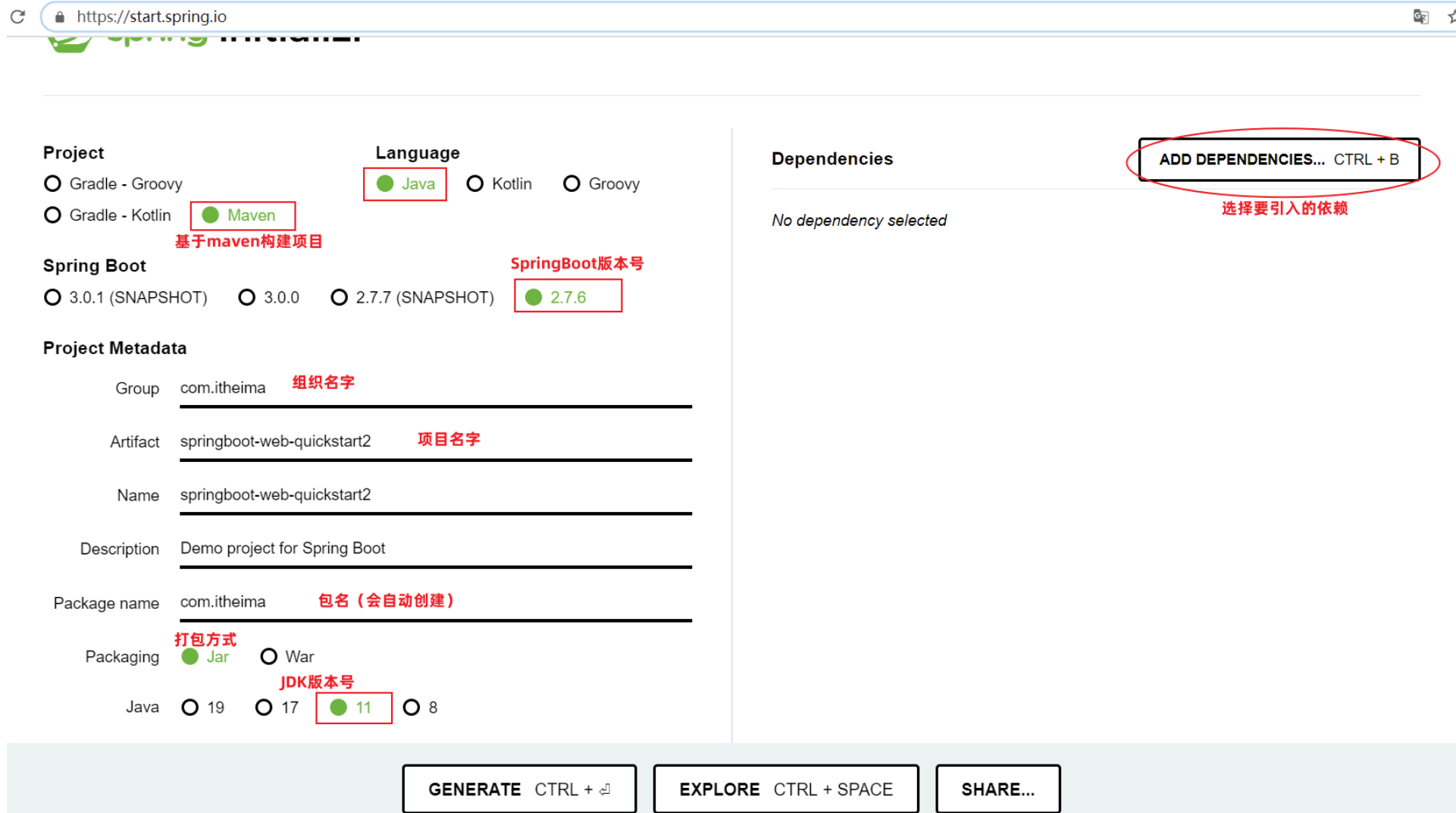
- SpringBoot项目需要依赖Spring Web
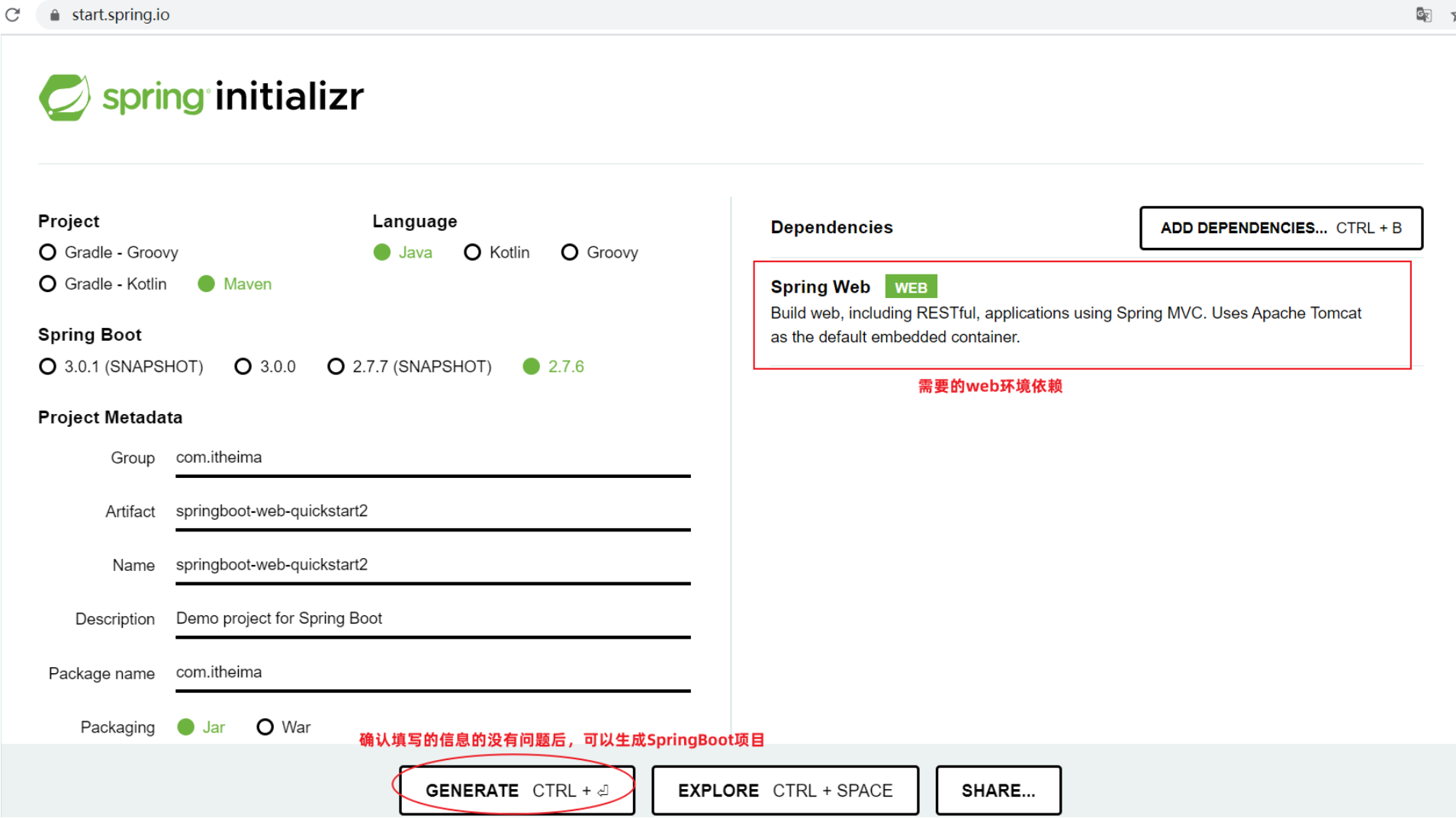
-
SpringBoot项目创建成功后,会下载到本地,解压缩后就可以得到一个Spring Boot项目文件夹
-
不论使用IDEA创建SpringBoot项目,还是直接在官方网站利用骨架生成SpringBoot项目,项目的结构和pom.xml文件中内容是相似的。
3.2.2 起步依赖
spring-boot-starter-web和spring-boot-starter-test,在SpringBoot中又称为起步依赖,每一个起步依赖,都用于开发一个特定的功能。
起步依赖共同的特征就是以spring-boot-starter-作为开头。
- spring-boot-starter-web:包含了web应用开发所需要的常见依赖。内部把关于Web开发所有的依赖都已经导入并且指定了版本,只需引入
spring-boot-starter-web依赖就可以实现Web开发的需要的功能 - spring-boot-starter-test:包含了单元测试所需要的常见依赖
起步依赖官方地址:https://docs.spring.io/spring-boot/docs/2.7.2/reference/htmlsingle/#using.build-systems.starters
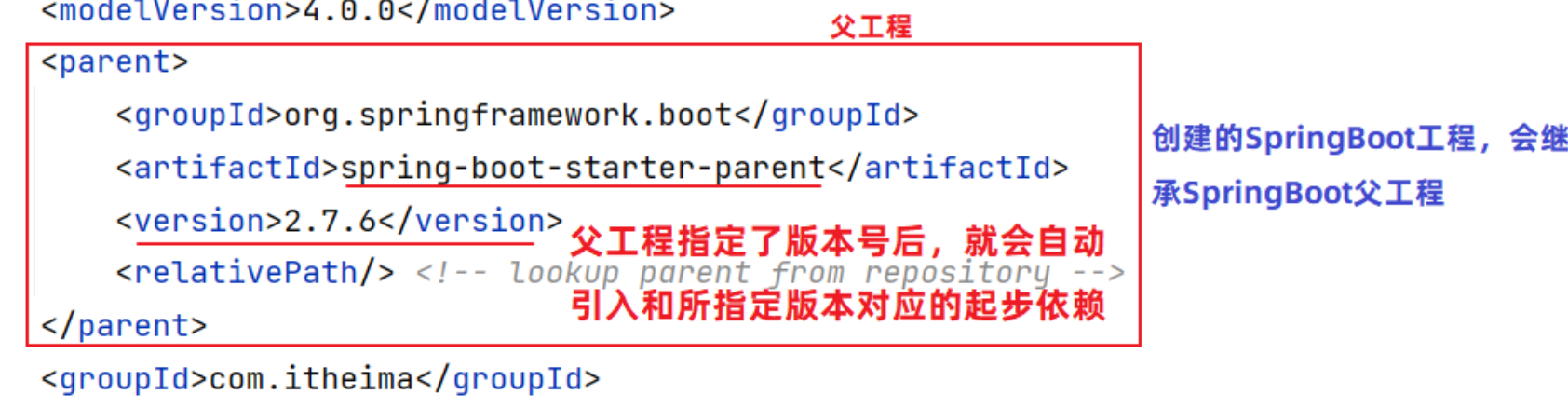
3.2.3 SpringBoot父工程
每一个SpringBoot工程,都有一个父工程。依赖的版本号,在父工程中统一管理,所以不用指定依赖的版本号:
3.2.4 内嵌Tomcat
spring-boot-starter-web起步依赖内部已经集成了内置的Tomcat服务器,所以不用部署springboot项目也能运行。
当我们运行SpringBoot的引导类时(运行main方法),就会看到命令行输出的日志,其中占用8080端口的就是Tomcat。
十一、SpringBootWeb请求响应
1.前言
浏览器发送请求请求web服务器 (也就是内置的Tomcat),被部署在Tomcat中的控制器类Controller接收,Controller再给浏览器一个响应,整个过程遵守http协议。但是Tomcat不识别自定义的Controller,可以识别 Servlet程序。所以Tomcat内置了一个核心的Servlet程序 DispatcherServlet(核心控制器),负责接收页面发送的请求,然后根据执行规则将请求再转发给请求处理器Controller,请求处理器处理完请求后再由DispatcherServlet给浏览器响应数据
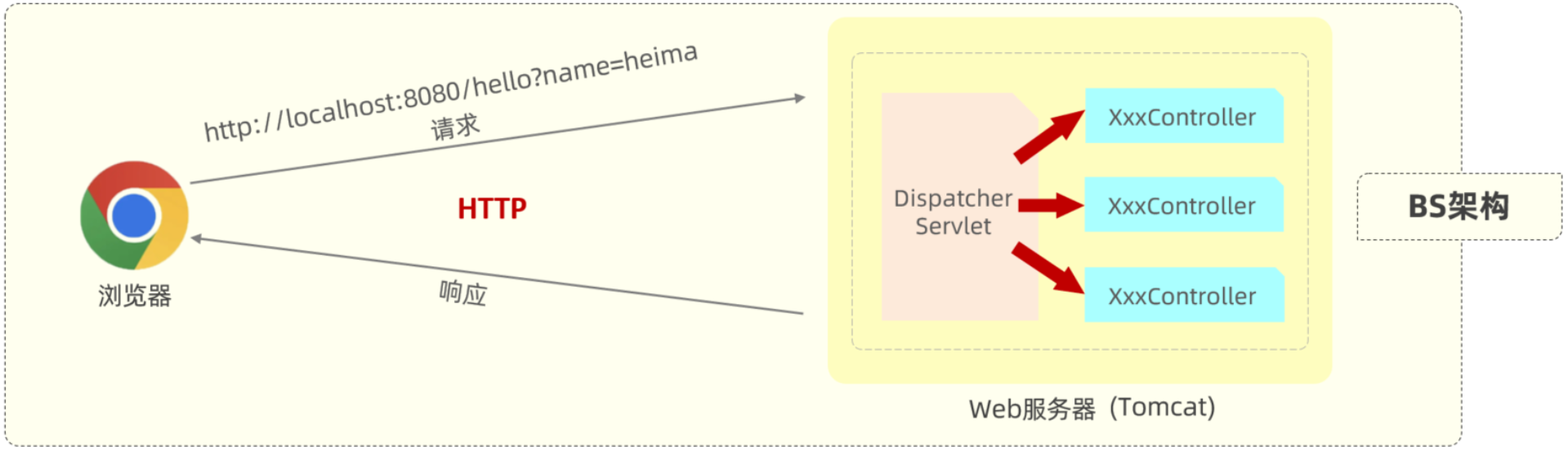
- BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。
Tomcat接收到浏览器发送的数据后,会先解析这些请求数据,然后将解析后的请求数据传递给Servlet程序的HttpServletRequest对象,Tomcat还会给Servlet程序传递一个参数 HttpServletResponse用以给浏览器设置响应数据。
2.请求
2.1 Postman
Postman工具是后端开发员用来测试自己所开发的程序的,可以在没有前端页面的情况下测试后端程序的正确性,即模拟浏览器向后端服务器发起任何形式(如:get、post)的HTTP请求。
安装:双击资料中提供的Postman-win64-8.3.1-Setup.exe即可自动安装。
基本使用
登录完成之后,可以创建工作空间:
创建请求:
点击"Save",保存当前请求
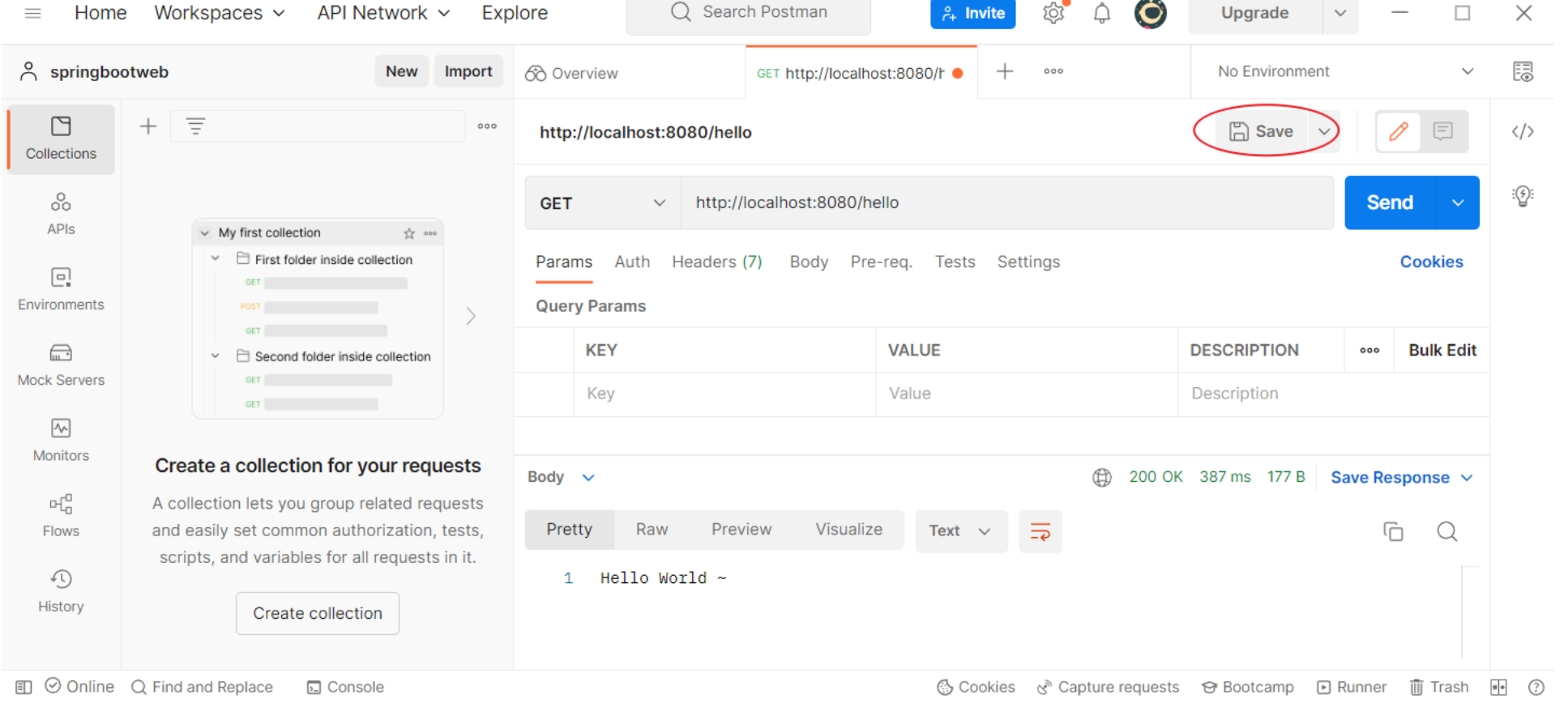
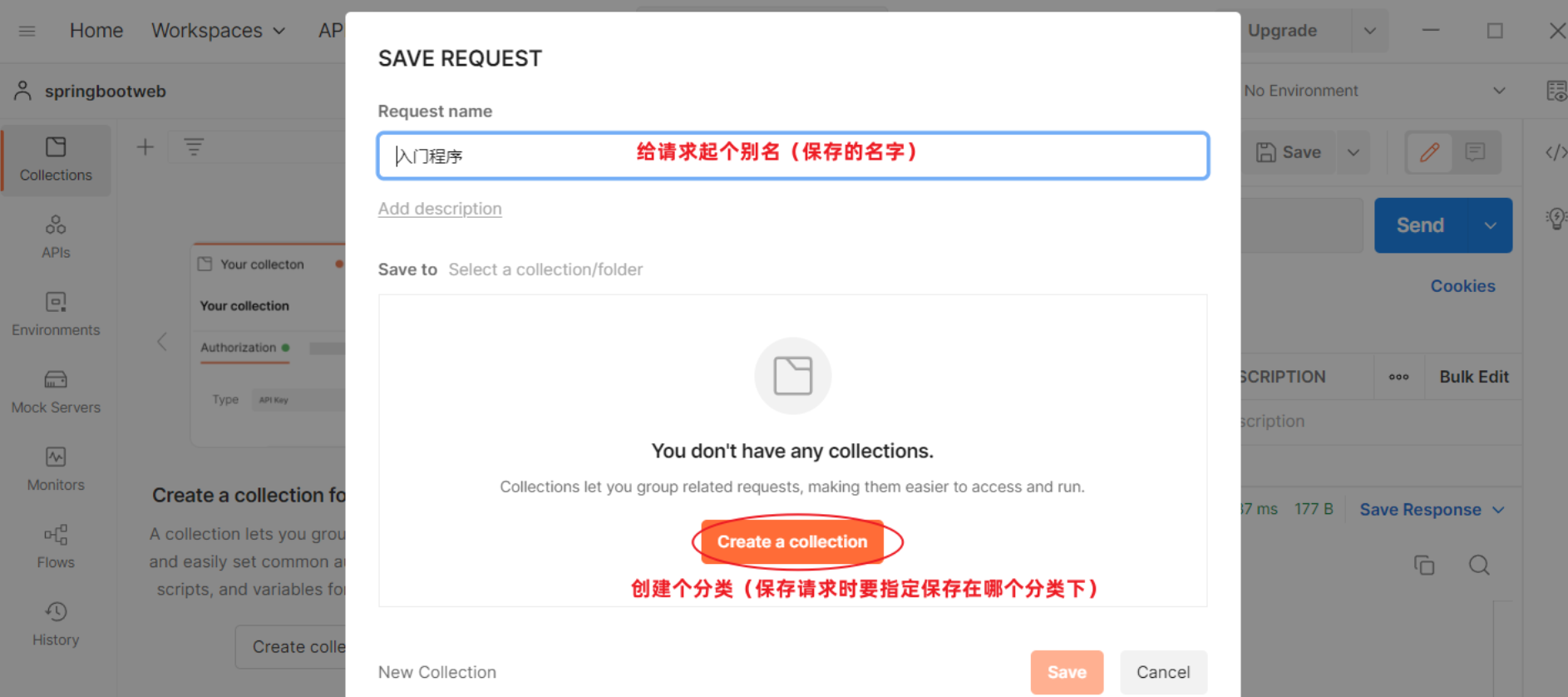

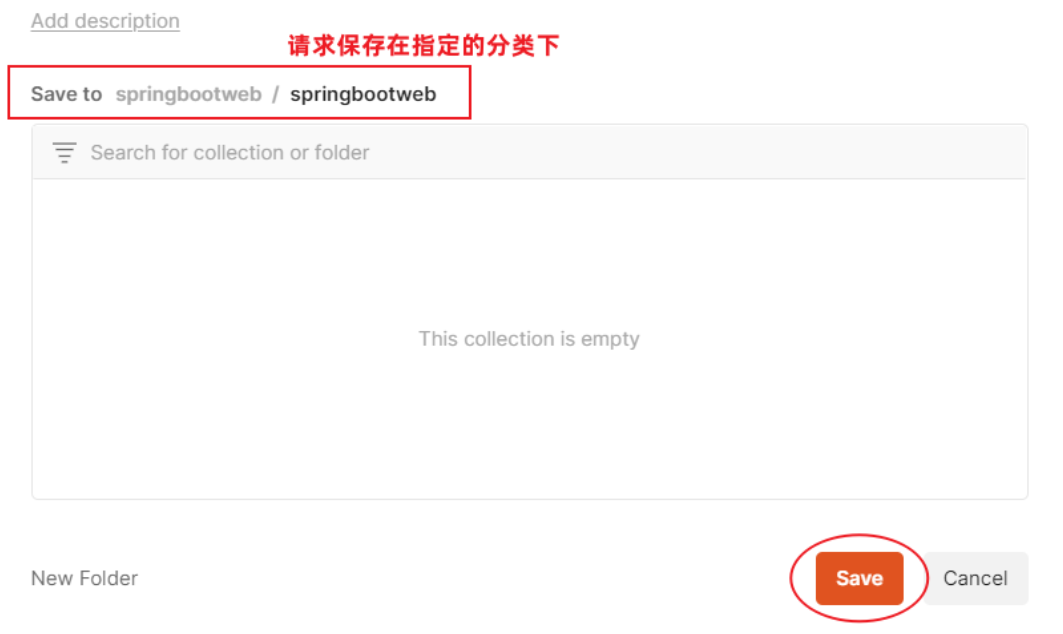
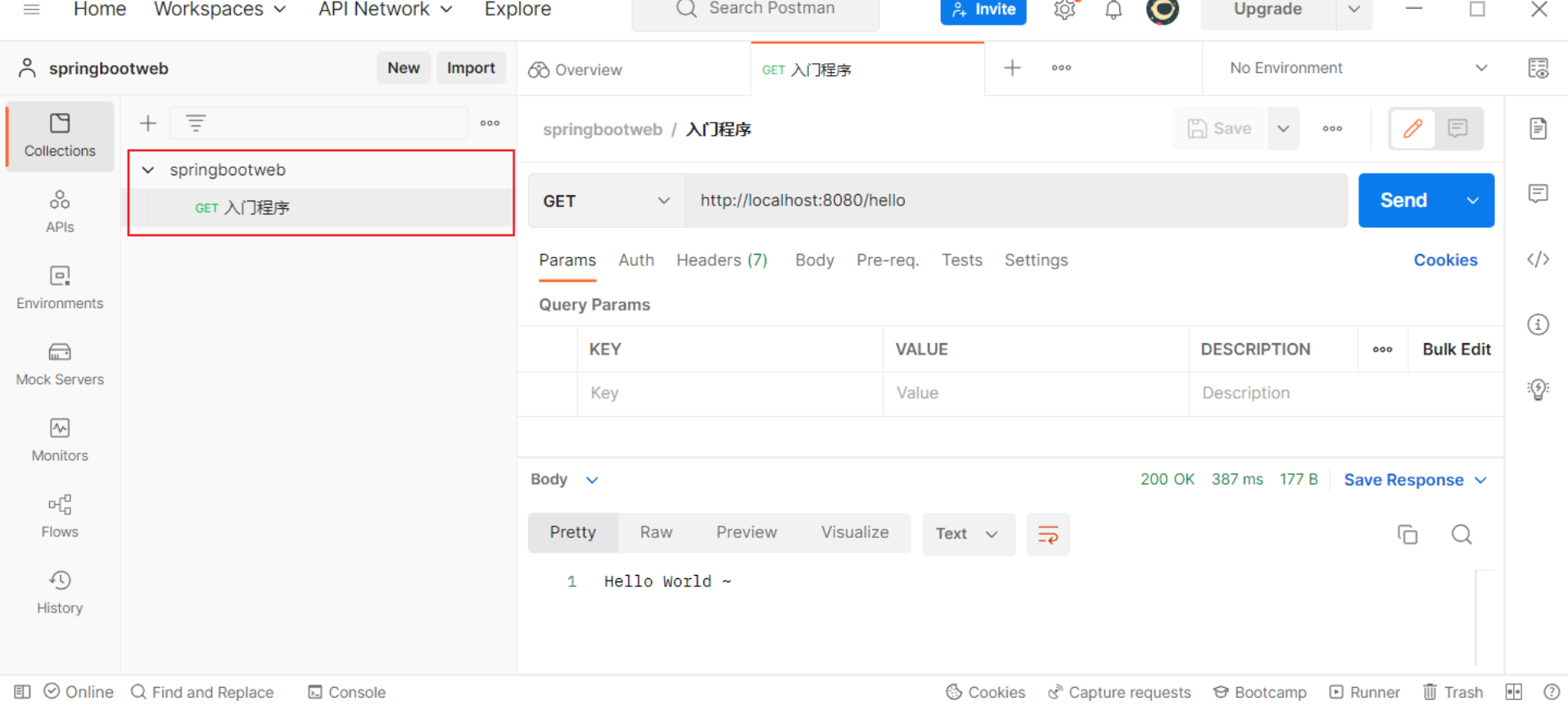
2.2 简单参数

后端程序接收浏览器传递过来的普通参数数据有两种方式:
2.2.1 原始方式(不建议)
通过Servlet中提供的API:HttpServletRequest(请求对象),获取请求的相关信息,即在方法的形参中声明 HttpServletRequest 对象,通过该对象来获取请求信息。
//根据指定的参数名获取请求参数的数据值
String request.getParameter("参数名")
@RestController
public class RequestController {
//原始方式
@RequestMapping("/simpleParam")
public String simpleParam(HttpServletRequest request){
// http://localhost:8080/simpleParam?name=Tom&age=10
// 请求参数: name=Tom&age=10 (有2个请求参数)
String name = request.getParameter("name");//name就是请求参数名
String ageStr = request.getParameter("age");//age就是请求参数名
int age = Integer.parseInt(ageStr);//需要手动进行类型转换
System.out.println(name+" : "+age);
return "OK";
}
}
2.2.2 SpringBoot方式
参数名与形参变量名相同,定义同名的形参即可接收参数。
@RestController
public class RequestController {
// http://localhost:8080/simpleParam?name=Tom&age=10
// 第1个请求参数: name=Tom 参数名:name,参数值:Tom
// 第2个请求参数: age=10 参数名:age , 参数值:10
//springboot方式
@RequestMapping("/simpleParam")
public String simpleParam(String name , Integer age ){//形参名和请求参数名保持一致
System.out.println(name+" : "+age);
return "OK";
}
}
- 不论是GET请求还是POST请求,对于简单参数来讲,只要保证请求参数名和Controller方法中的形参名保持一致,就可以获取到请求参数中的数据值。
2.2.3 参数名不一致
对于简单参数来讲,请求参数名和controller方法中的形参名不一致时,无法接收到请求数据。
@RequestMapping("/simpleParam")
public String simpleParam(String username , Integer age ){//请求参数名和形参名不相同
// http://localhost:8080/simpleParam?name=Tom&age=20
System.out.println(username+" : "+age); //username=null,age=20
return "OK";
}
解决方案:可以使用Spring提供的@RequestParam注解完成映射:在方法形参前面加上 @RequestParam 然后通过name属性指定请求参数名,从而完成映射。
//springboot方式
@RequestMapping("/simpleParam")
public String simpleParam(@RequestParam("name") String username , Integer age ){
// http://localhost:8080/simpleParam?name=Tom&age=20
System.out.println(username+" : "+age); //username=Tom,age=20
return "OK";
}
注意事项:@RequestParam中的required属性默认为true(默认值也是true),代表该请求参数必须传递,如果不传递将报错,例如username和age缺少任意一个都会响应状态码400,可以将required属性设置为false代表这个参数可选:
@RequestMapping("/simpleParam")
public String simpleParam(@RequestParam(name = "name", required = false) String username, Integer age){
System.out.println(username+ ":" + age);
return "OK";
}
2.3 实体参数
接受请求参数可以封装到一个实体类对象中,这样形参只要一个对象就可以接受所有请求参数,要想完成数据封装,需要遵守如下规则:请求参数名与实体类的属性名相同。
2.3.1 简单实体对象
定义pojo实体类:
public class User {
private String name;
private Integer age;
...
@Override
public String toString() {
return ...;
}
}
Controller方法:
@RestController
public class RequestController {
//实体参数:简单实体对象
@RequestMapping("/simplePojo")
public String simplePojo(User user){
System.out.println(user);
return "OK";
}
}
2.3.2 复杂实体对象
复杂实体对象即在实体类中有一个或多个属性,也是实体对象类型的。
复杂实体对象的封装,需要遵守如下规则:请求参数名与形参对象属性名相同,按照对象层次结构关系即可接收嵌套实体类属性参数。
以http://localhost:8080/complexPojo?name=Tom&age=10&address.province=beijing&address.city=beijing为例。
定义POJO实体类:
- Address实体类
public class Address {
private String province;
private String city;
...
@Override
public String toString() {
return ...;
}
}
- User实体类
public class User {
private String name;
private Integer age;
private Address address; //地址对象
...
@Override
public String toString() {
return ...;
}
}
- Controller方法
@RestController
public class RequestController {
//实体参数:复杂实体对象
@RequestMapping("/complexPojo")
public String complexPojo(User user){
System.out.println(user);
return "OK";
}
}
2.4 数组集合参数
在HTML的表单中,复选框可以提交选择的多个值,接受复选框的参数有两种方式(以http://localhost:8080/arrayParam?hobby=game&hobby=java或http://localhost:8080/arrayParam?hobby=game,java为例):
2.4.1 数组
数组参数:请求参数名与形参数组名称相同且请求参数为多个,定义数组类型形参即可接收参数
Controller方法:
@RestController
public class RequestController {
//数组集合参数
@RequestMapping("/arrayParam")
public String arrayParam(String[] hobby){
System.out.println(Arrays.toString(hobby));
return "OK";
}
}
2.4.2 集合
集合参数:请求参数名与形参集合对象名相同且请求参数为多个,@RequestParam 绑定参数关系
默认情况下,请求中参数名相同的多个值,是封装到数组。如果要封装到集合,要使用@RequestParam绑定参数关系
Controller方法:
@RestController
public class RequestController {
//数组集合参数
@RequestMapping("/listParam")
public String listParam(@RequestParam List<String> hobby){
System.out.println(hobby);
return "OK";
}
}
2.5 日期参数
对于日期类型的参数在进行封装的时候,需要通过@DateTimeFormat注解,以及其pattern属性来设置日期的格式。
后端controller方法中,需要使用Date类型或LocalDateTime类型,来封装传递的参数。
以http://localhost:8080/dataParam?updateTime=2022-12-12 10:05:45为例:
Controller方法:
@RestController
public class RequestController {
//日期时间参数
@RequestMapping("/dateParam")
public String dateParam(@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") LocalDateTime updateTime){
System.out.println(updateTime);
return "OK";
}
}
2.6 JSON参数
Postman发送JSON格式数据:
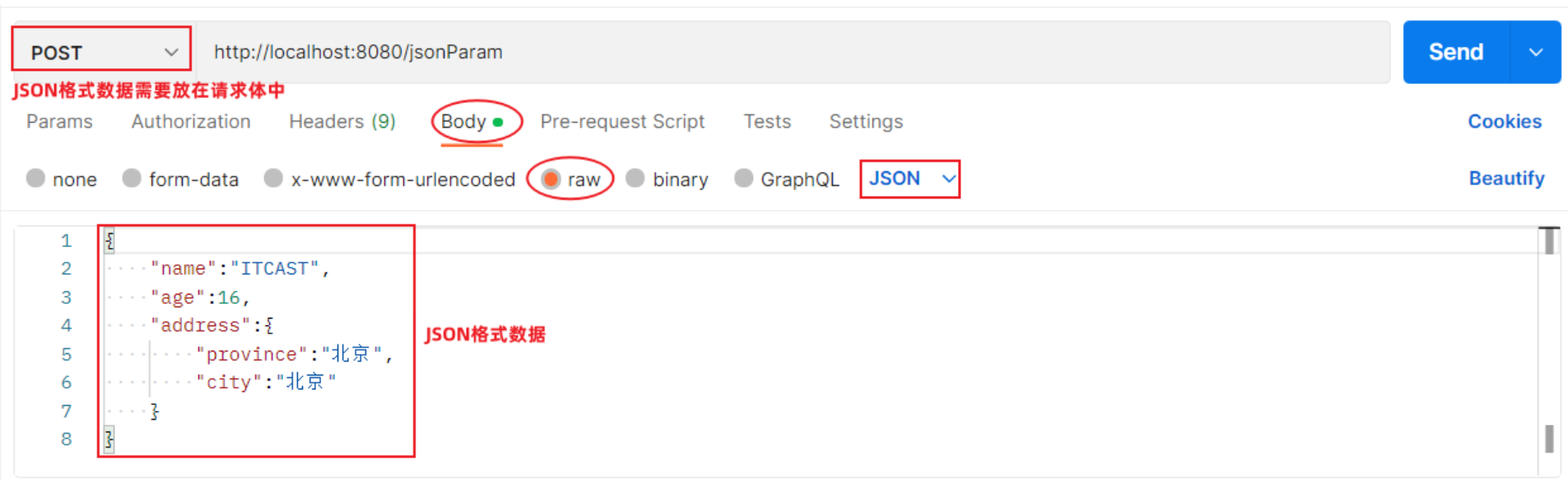
服务端Controller方法接收JSON格式数据:
-
传递json格式的参数,在Controller中会使用实体类进行封装。
-
封装规则:JSON数据键名与形参对象属性名相同,定义POJO类型形参即可接收参数。需要使用 @RequestBody标识。
-
@RequestBody注解:将JSON数据映射到形参的实体类对象中(JSON中的key和实体类中的属性名保持一致)
实体类:Address
public class Address {
private String province;
private String city;
...
}
实体类:User
public class User {
private String name;
private Integer age;
private Address address;
...
}
Controller方法:
@RestController
public class RequestController {
//JSON参数
@RequestMapping("/jsonParam")
public String jsonParam(@RequestBody User user){
System.out.println(user);
return "OK";
}
}
2.7 路径参数
路径参数:
- 前端:通过请求URL直接传递参数
- 后端:使用{…}来标识该路径参数,需要使用@PathVariable获取路径参数
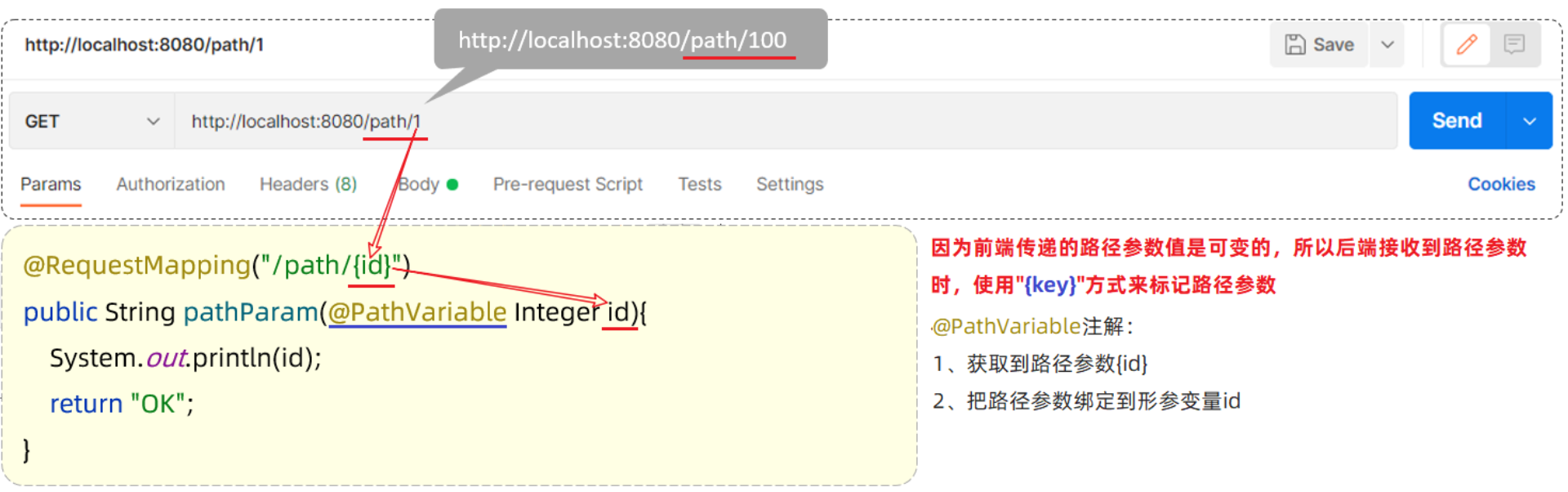
传递单个路径参数:
Controller方法:
@RestController
public class RequestController {
//路径参数
@RequestMapping("/path/{id}")
public String pathParam(@PathVariable Integer id){
System.out.println(id);
return "OK";
}
}
Postman测试:
访问http://localhost:8080/path/1,控制台输出1,浏览器显示OK。
传递多个路径参数:
Controller方法:
@RestController
public class RequestController {
//路径参数
@RequestMapping("/path/{id}/{name}")
public String pathParam2(@PathVariable Integer id, @PathVariable String name){
System.out.println(id+ " : " +name);
return "OK";
}
}
Postman测试:
访问http://localhost:8080/path/1/itcast,控制台输出1 : itcast,浏览器显示OK。
3.响应
3.1 @ResponseBody
@ResponseBody注解:
- 类型:方法注解、类注解
- 位置:书写在Controller方法上或类上
- 作用:将方法返回值直接响应给浏览器
- 如果返回值类型是实体对象/集合,将会转换为JSON格式后在响应给浏览器
注 :@RestController = @Controller + @ResponseBody
@RestController源码:
@Target({ElementType.TYPE}) //元注解(修饰注解的注解)
@Retention(RetentionPolicy.RUNTIME) //元注解
@Documented //元注解
@Controller
@ResponseBody
public @interface RestController {
@AliasFor(
annotation = Controller.class
)
String value() default "";
}
3.2 统一响应结果
统一的返回结果使用类来描述,在这个结果中包含:
-
响应状态码:当前请求是成功,还是失败
-
状态码信息:给页面的提示信息
-
返回的数据:给前端响应的数据(字符串、对象、集合)
定义在一个实体类Result来包含以上信息:
public class Result {
private Integer code;//响应码,1 代表成功; 0 代表失败
private String msg; //状态码 描述字符串
private Object data; //返回的数据
...
//增删改 成功响应(不需要给前端返回数据)
public static Result success(){
return new Result(1,"success",null);
}
//查询 成功响应(把查询结果做为返回数据响应给前端)
public static Result success(Object data){
return new Result(1,"success",data);
}
//失败响应
public static Result error(String msg){
return new Result(0,msg,null);
}
}
4.案例
4.1 需求说明
加载并解析xml文件中的数据,完成数据处理,并在页面展示
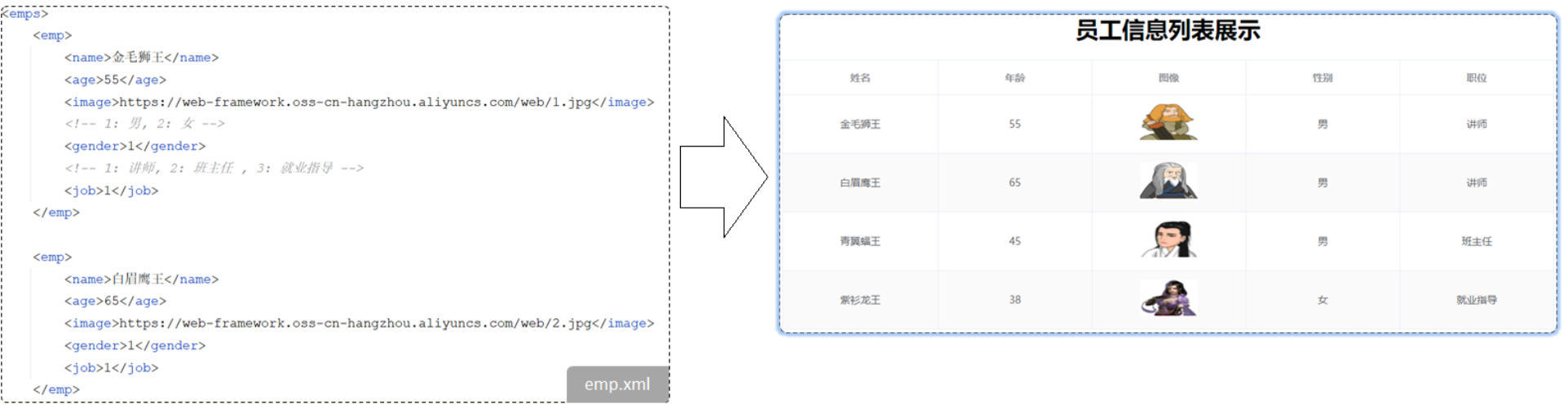
4.2 准备工作
-
XML文件
- 已经准备好(emp.xml),直接导入进来,放在 src/main/resources目录下
-
工具类
- 已经准备好解析XML文件的工具类,无需自己实现
- 直接在创建一个包 com.itheima.utils ,然后将工具类拷贝进来
-
前端页面资源
- 已经准备好,直接拷贝进来,放在src/main/resources下的static目录下
Springboot项目的静态资源(html,css,js等前端资源)默认存放目录为:classpath:/static 、 classpath:/public、 classpath:/resources
在SpringBoot项目中,静态资源默认可以存放的目录:
- classpath:/static/
- classpath:/public/
- classpath:/resources/
- classpath:/META-INF/resources/
classpath:
- 代表的是类路径,在maven的项目中,其实指的就是 src/main/resources 或者 src/main/java,但是java目录是存放java代码的,所以相关的配置文件及静态资源文档,就放在 src/main/resources下。
4.3 实现步骤
-
在pom.xml文件中引入dom4j的依赖,用于解析XML文件
<dependency> <groupId>org.dom4j</groupId> <artifactId>dom4j</artifactId> <version>2.1.3</version> </dependency> -
引入资料中提供的:解析XML的工具类XMLParserUtils、实体类Emp、XML文件emp.xml

- 引入资料中提供的静态页面文件,放在resources下的static目录下

- 创建EmpController类,编写Controller程序,处理请求,响应数据
4.4 代码实现
Contriller代码:
@RestController
public class EmpController {
@RequestMapping("/listEmp")
public Result list(){
//1. 加载并解析emp.xml
String file = this.getClass().getClassLoader().getResource("emp.xml").getFile();
//System.out.println(file);
List<Emp> empList = XmlParserUtils.parse(file, Emp.class);
//2. 对数据进行转换处理 - gender, job
empList.stream().forEach(emp -> {
//处理 gender 1: 男, 2: 女
String gender = emp.getGender();
if("1".equals(gender)){
emp.setGender("男");
}else if("2".equals(gender)){
emp.setGender("女");
}
//处理job - 1: 讲师, 2: 班主任 , 3: 就业指导
String job = emp.getJob();
if("1".equals(job)){
emp.setJob("讲师");
}else if("2".equals(job)){
emp.setJob("班主任");
}else if("3".equals(job)){
emp.setJob("就业指导");
}
});
//3. 响应数据
return Result.success(empList);
}
}
4.5 测试
打开浏览器,在浏览器地址栏输入: http://localhost:8080/emp.html

5.分层解耦
5.1 三层架构
5.1.1 介绍
在进行程序设计以及程序开发时,尽可能让每一个接口、类、方法的职责更单一些(单一职责原则)。

案例中的Contriller代码,从组成上看可以分为三个部分:
- 数据访问:负责业务数据的维护操作,包括增、删、改、查等操作。
- 逻辑处理:负责业务逻辑处理的代码。
- 请求处理、响应数据:负责,接收页面的请求,给页面响应数据。
三层架构就是把这三个部分分离出来,使各层相互独立,互不影响:
- Controller:控制层。接收前端发送的请求,对请求进行处理,并响应数据。
- Service:业务逻辑层。处理具体的业务逻辑。
- Dao:数据访问层(Data Access Object),也称为持久层。负责数据访问操作,包括数据的增、删、改、查。
三层架构的程序执行流程:
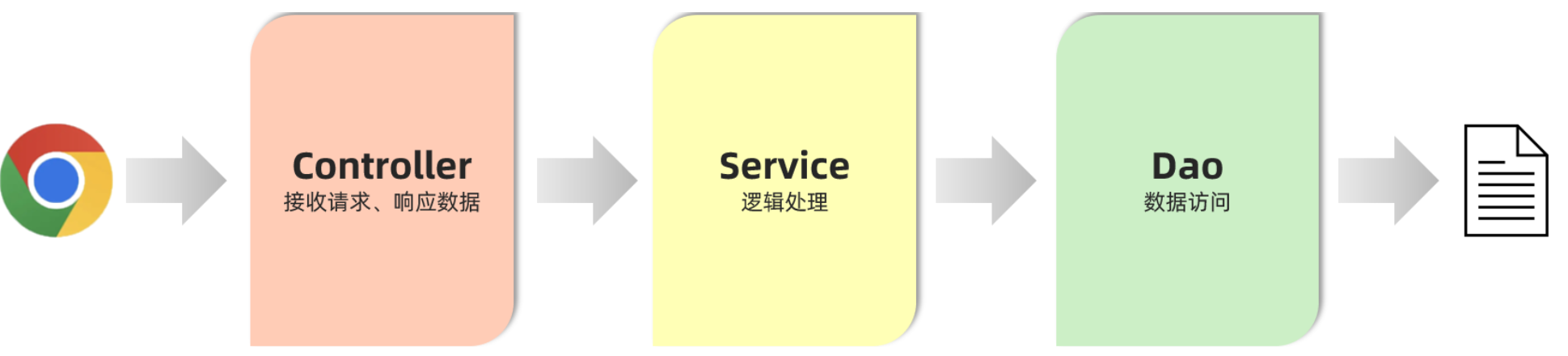
- 前端发起的请求,由Controller层接收(Controller响应数据给前端)
- Controller层调用Service层来进行逻辑处理(Service层处理完后,把处理结果返回给Controller层)
- Serivce层调用Dao层(逻辑处理过程中需要用到的一些数据要从Dao层获取)
- Dao层操作文件中的数据(Dao拿到的数据会返回给Service层)
5.1.2 代码拆分
- 控制层包名:xxxx.controller
- 业务逻辑层包名:xxxx.service
- 数据访问层包名:xxxx.dao
**控制层:**接收前端发送的请求,对请求进行处理,并响应数据
@RestController
public class EmpController {
//业务层对象
private EmpService empService = new EmpServiceA();
@RequestMapping("/listEmp")
public Result list(){
//1. 调用service层, 获取数据
List<Emp> empList = empService.listEmp();
//3. 响应数据
return Result.success(empList);
}
}
**业务逻辑层:**处理具体的业务逻辑
- 业务接口
//业务逻辑接口(制定业务标准)
public interface EmpService {
//获取员工列表
public List<Emp> listEmp();
}
- 业务实现类
//业务逻辑实现类(按照业务标准实现)
public class EmpServiceA implements EmpService {
//dao层对象
private EmpDao empDao = new EmpDaoA();
@Override
public List<Emp> listEmp() {
//1. 调用dao, 获取数据
List<Emp> empList = empDao.listEmp();
//2. 对数据进行转换处理 - gender, job
empList.stream().forEach(emp -> {
... //和之前一样,赋值粘贴即可
});
return empList;
}
}
**数据访问层:**负责数据的访问操作,包含数据的增、删、改、查
- 数据访问接口
//数据访问层接口(制定标准)
public interface EmpDao {
//获取员工列表数据
public List<Emp> listEmp();
}
- 数据访问实现类
//数据访问实现类
public class EmpDaoA implements EmpDao {
@Override
public List<Emp> listEmp() {
//1. 加载并解析emp.xml
String file = this.getClass().getClassLoader().getResource("emp.xml").getFile();
System.out.println(file);
List<Emp> empList = XmlParserUtils.parse(file, Emp.class);
return empList;
}
}

5.2 分层解耦
5.2.1 耦合问题
-
内聚:软件中各个功能模块内部的功能联系。
-
耦合:衡量软件中各个层/模块之间的依赖、关联的程度。
软件设计原则:高内聚低耦合。
-
高内聚:一个模块中各个元素之间的联系的紧密程度,各个元素(语句、程序段)之间的联系程度越高,则内聚性越高。
-
低耦合:软件中各个层、模块之间的依赖关联程序越低越好。
高内聚、低耦合的目的是使程序模块的可重用性、移植性大大增强。
5.2.2 解耦思路
之前对象都是用new创建的,但是这样就使两层耦合了,例如:当service层的实现变了就需要修改controller层的代码。解决思路如下:
首先不能在EmpController中使用new对象,然后提供一个容器,容器中存储一些对象(例:EmpService对象),controller程序从容器中获取EmpService类型的对象。
- **控制反转:**简称IOC。对象的创建权由程序员主动创建转移到容器(由容器创建、管理对象)。这个容器称为:IOC容器或Spring容器
- 依赖注入: 简称DI。容器为应用程序提供运行时,所依赖的资源,称之为依赖注入。
IOC容器中创建、管理的对象,称之为:bean对象
5.3 IOC&DI
5.3.1 IOC&DI入门
任务:完成Controller层、Service层、Dao层的代码解耦
第1步:删除Controller层、Service层中new对象的代码
第2步:Service层及Dao层的实现类,交给IOC容器管理
- 使用Spring提供的注解:@Component ,就可以实现类交给IOC容器管理
第3步:为Controller及Service注入运行时依赖的对象
- 使用Spring提供的注解:@Autowired ,就可以实现程序运行时IOC容器自动注入需要的依赖对象

5.3.2 IOC详解
5.3.2.1 bean的声明
Spring框架提供了@Component的衍生注解用来标识bean对象具体归属于哪一层:
- @Controller (标注在控制层类上)
- @Service (标注在业务层类上)
- @Repository (标注在数据访问层类上)
| 注解 | 说明 | 位置 |
|---|---|---|
| @Controller | @Component的衍生注解 | 标注在控制器类上 |
| @Service | @Component的衍生注解 | 标注在业务类上 |
| @Repository | @Component的衍生注解 | 标注在数据访问类上(由于与mybatis整合,用的少) |
| @Component | 声明bean的基础注解 | 不属于以上三类时,用此注解 |
@RestController = @Controller + @ResponseBody
在IOC容器中,每一个Bean类都有一个属于自己的名字,可以通过注解的value属性指定bean的名字。如果没有指定,默认为类名首字母小写。
@Repository(value = "empRepositoryA") //如果没有指定,默认empDaoA
public class EmpDaoA implements EmpDao{...}
注意:在springboot集成web开发中,声明控制器bean只能用@Controller。
5.3.2.2 组件扫描
bean想要生效,需要被组件扫描。扫描注解@ComponentScan用来扫描组件,@ComponentScan注解虽然没有显式配置,但是实际上已经包含在了引导类声明注解 @SpringBootApplication 中,默认扫描的范围是SpringBoot启动类所在包及其子包。
要想扫描到SpringBoot启动类所在包及其子包之外的组件,有两种解决方案:
- 为SpringBoot启动类手动添加@ComponentScan注解,指定要扫描的包,例如
@ComponentScan({"com.itheima","dao"}). - 将所有需要扫描的包都放在引导类所在包com.itheima的子包下(推荐做法)
5.3.3 DI详解
@Autowired注解,默认是按照类型进行自动装配的(去IOC容器中找某个类型的对象,然后完成注入操作)
如果在IOC容器中存在多个相同类型的bean对象,会出现报错,解决方案如下:
方式一:使用@Primary注解:当存在多个相同类型的Bean注入时,加上@Primary注解,来确定默认的实现。

方式二:使用@Qualifier注解:指定当前要注入的bean对象。 在@Qualifier的value属性中,指定注入的bean的名称。

方式三:使用@Resource注解:是按照bean的名称进行注入。通过name属性指定要注入的bean的名称。

面试题 : @Autowird 与 @Resource的区别
- @Autowired 是spring框架提供的注解,而@Resource是JDK提供的注解
- @Autowired 默认是按照类型注入,而@Resource是按照名称注入
十二、数据库开发-MySQL
数据库:英文为 DataBase,简称DB,它是存储和管理数据的仓库。
数据库管理系统:简称DBMS,是操作和管理数据库的大型软件,通过这个软件可以操纵和管理数据库。
SQL:简称SQL,结构化查询语言,是操作关系型数据库的编程语言,定义了一套操作关系型数据库的统一标准。
三层架构中的数据连接层,就是用来从数据库中获取数据的。
1.MySQL概述
分为商业版本(收费,可以免费试用30天,提供技术支持)和社区版本(免费,但是不提供技术支持),本节使用社区版本(8.0.31)。
1.1 安装
参考资料中的mysql安装文档。
1.2 连接
命令行使用mysql -u用户名 -p[密码] [-h数据库服务器的IP地址 -P端口号]命令就可以连接到MySQL服务器。
- -h 参数不加,默认连接的是本地 127.0.0.1 的MySQL服务器
- -P 参数不加,默认连接的端口号是 3306
1.3 数据模型
关系型数据库:简称RDBMS,建立在关系模型基础上,由多张相互连接的二维表组成的数据库,如MySQL、Oracle、SQLServer等。
非关系型数据库:不是由二维表组成的数据库,如Redis。
MySQL是关系型数据库,是基于二维表进行数据存储的,所有数据都存放在二维表中:
- 通过MySQL客户端连接数据库管理系统DBMS,然后通过DBMS操作数据库
- 使用MySQL客户端,向数据库管理系统发送一条SQL语句,由数据库管理系统根据SQL语句指令去操作数据库中的表结构及数据
- 一个数据库服务器中可以创建多个数据库,一个数据库中也可以包含多张表,而一张表中又可以包含多行记录。
1.4 SQL简介
1.4.1 SQL通用语法
1、SQL语句可以单行或多行书写,以分号结尾。
2、SQL语句可以使用空格/缩进来增强语句的可读性。
3、不区分大小写。
4、注释:
- 单行注释:-- 注释内容 或 # 注释内容(MySQL特有)
- 多行注释: /* 注释内容 */
1.4.2 分类
SQL语句根据其功能被分为四大类:DDL、DML、DQL、DCL
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 |
2.数据库设计-DDL
2.1 项目开发流程
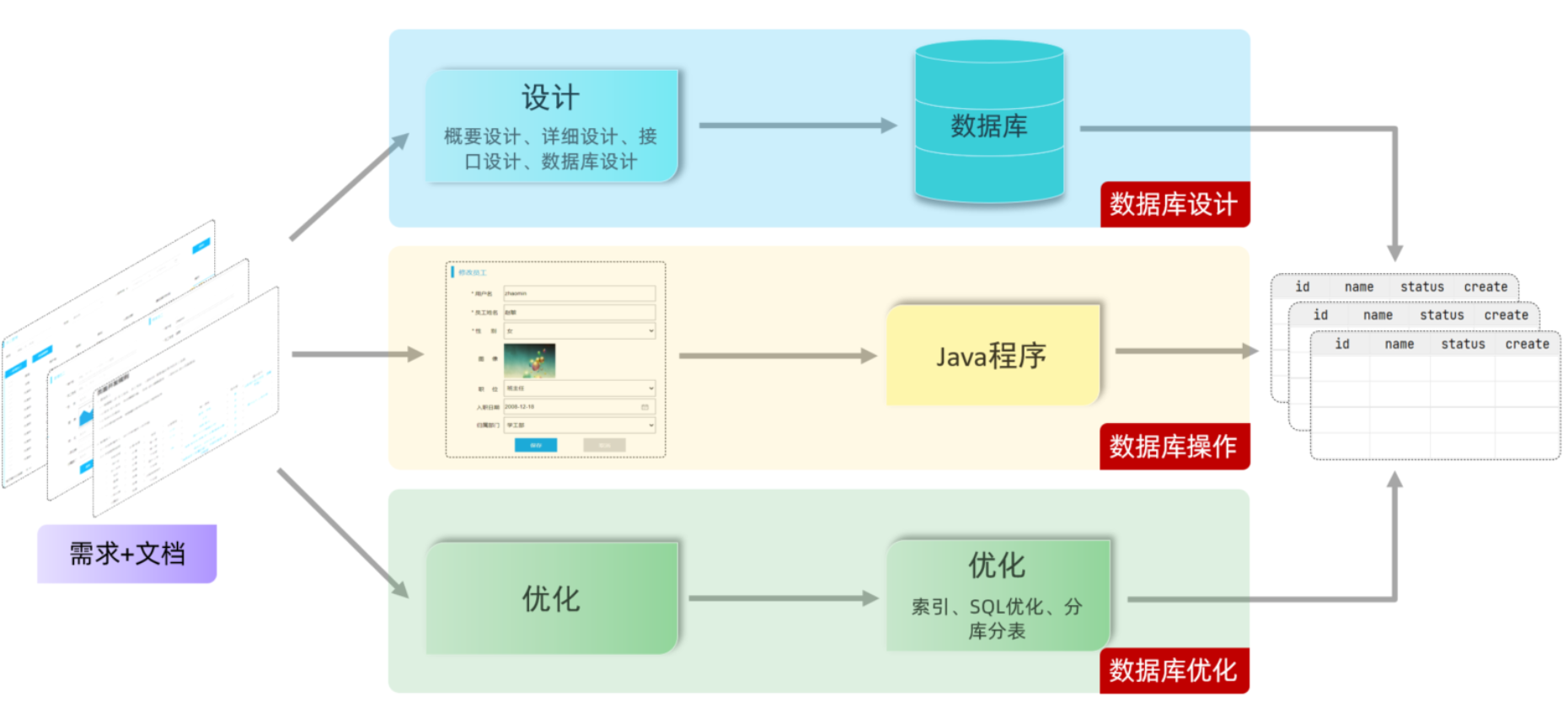
- 数据库设计阶段
- 参照产品经理提供的页面原型和需求文档设计数据库表结构
- 数据库操作阶段
- 根据业务功能的实现,编写SQL语句对数据表中的数据进行增删改查操作
- 数据库优化阶段
- 通过数据库的优化来提高数据库的访问性能。优化手段:索引、SQL优化、分库分表等
2.2 数据库操作
DDL中数据库的常见操作:查询、创建、使用、删除。
2.2.1 查询数据库
查询所有数据库:
show databases;
查询当前数据库:
select database();
2.2.2 创建数据库
语法:
create database [ if not exists ] 数据库名;
在同一个数据库服务器中,不能创建两个名称相同的数据库,否则将会报错,可以使用if not exists来避免这个问题。
2.2.3 使用数据库
语法:
use 数据库名 ;
2.2.4 删除数据库
语法:
drop database [ if exists ] 数据库名 ;
如果删除一个不存在的数据库,将会报错,可以使用if exists来避免这个问题。
注:上述所有语法中的database,也可以替换成 schema
2.3 图形化工具
DataGrip是JetBrains旗下的一款数据库管理工具,是管理和开发MySQL、Oracle、PostgreSQL的理想解决方案。
2.3.1 安装
参考资料中的DataGrip安装手册。
2.3.2 使用
1、打开IDEA自带的Database
2、配置MySQL
3、输入相关信息并下载MySQL连接驱动
4、测试数据库连接
点击Text Connection即可。
5、点击OK创建连接成功
2.4 表操作
关于表结构的操作也是包含四个部分:创建表、查询表、修改表、删除表。
2.4.1 创建
2.4.1.1 语法
create table 表名(
字段1 字段1类型 [约束] [comment 字段1注释 ],
字段2 字段2类型 [约束] [comment 字段2注释 ],
......
字段n 字段n类型 [约束] [comment 字段n注释 ]
) [ comment 表注释 ] ;
2.4.1.2 约束
约束就是作用在表中字段上的规则,用于限制存储在表中的数据,从而保证数据库当中数据的正确性、有效性和完整性。
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段值不能为null | not null |
| 唯一约束 | 保证字段的所有数据都是唯一、不重复的 | unique |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | primary key |
| 默认约束 | 保存数据时,如果未指定该字段值,则采用默认值 | default |
| 外键约束 | 让两张表的数据建立连接,保证数据的一致性和完整性 | foreign key |
注意:约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束。
create table tb_user (
id int primary key auto_increment comment 'ID,唯一标识', #主键自动增长
username varchar(20) not null unique comment '用户名',
name varchar(10) not null comment '姓名',
age int comment '年龄',
gender char(1) default '男' comment '性别'
) comment '用户表';
主键自增:auto_increment
- 每次插入新的行记录时,数据库自动生成id字段(主键)下的值
- 具有auto_increment的数据列是一个正数序列开始增长(从1开始自增)
2.4.1.3 数据类型
MySQL中的数据类型有很多,主要分为三类:数值类型、字符串类型、日期时间类型。
数值类型
| 类型 | 大小 | 有符号(SIGNED)范围 | 无符号(UNSIGNED)范围 | 描述 |
|---|---|---|---|---|
| TINYINT | 1byte | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2bytes | (-32768,32767) | (0,65535) | 大整数值 |
| MEDIUMINT | 3bytes | (-8388608,8388607) | (0,16777215) | 大整数值 |
| INT/INTEGER | 4bytes | (-2147483648,2147483647) | (0,4294967295) | 大整数值 |
| BIGINT | 8bytes | (-263,263-1) | (0,2^64-1) | 极大整数值 |
| FLOAT | 4bytes | (-3.402823466 E+38,3.402823466351 E+38) | 0 和 (1.175494351 E-38,3.402823466 E+38) | 单精度浮点数值 |
| DOUBLE | 8bytes | (-1.7976931348623157 E+308,1.7976931348623157 E+308) | 0 和 (2.2250738585072014 E-308,1.7976931348623157 E+308) | 双精度浮点数值 |
| DECIMAL | 依赖于M(精度)和D(标度)的值 | 依赖于M(精度)和D(标度)的值 | 小数值(精确定点数) |
字符串类型
| 类型 | 大小 | 描述 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串(需要指定长度) |
| VARCHAR | 0-65535 bytes | 变长字符串(需要指定长度) |
| TINYBLOB | 0-255 bytes | 不超过255个字符的二进制数据 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
char是定长字符串,指定长度多长,就占用多少个字符。而varchar是变长字符串,指定的长度为最大占用长度 。char的性能更高。
日期时间类型
| 类型 | 大小 | 范围 | 格式 | 描述 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01 至 9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | -838:59:59 至 838:59:59 | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901 至 2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00 至 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:01 至 2038-01-19 03:14:07 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值,时间戳 |
2.4.2 查询
查询当前数据库所有表:
show tables;
查看指定表结构:
desc 表名 ; #可以查看指定表的字段、字段的类型、是否可以为NULL、是否存在默认值等信息
查询指定表的建表语句:
show create table 表名 ;
2.4.3 修改
添加字段:
alter table 表名 add 字段名 类型(长度) [comment 注释] [约束];
修改数据类型:
alter table 表名 modify 字段名 新数据类型(长度);
alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 注释] [约束];
删除字段:
alter table 表名 drop 字段名;
修改表名:
rename table 表名 to 新表名;
2.4.4 删除
删除表语法:
drop table [ if exists ] 表名;
3.数据库操作-DML
3.1 增加(insert)
向指定字段添加数据:
insert into 表名 (字段名1, 字段名2) values (值1, 值2);
全部字段添加数据:
insert into 表名 values (值1, 值2, ...);
批量添加数据(指定字段):
insert into 表名 (字段名1, 字段名2) values (值1, 值2), (值1, 值2);
批量添加数据(全部字段):
insert into 表名 values (值1, 值2, ...), (值1, 值2, ...);
Insert操作的注意事项:
-
插入数据时,指定的字段顺序需要与值的顺序是一一对应的。
-
字符串和日期型数据应该包含在引号中。
-
插入的数据大小,应该在字段的规定范围内。
3.2 修改(update)
update语法:
update 表名 set 字段名1 = 值1 , 字段名2 = 值2 , .... [where 条件] ;
注意事项:
-
修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据。
-
在修改数据时,一般需要同时修改公共字段update_time,将其修改为当前操作时间。
3.3 删除(delete)
delete语法:
delete from 表名 [where 条件] ;
注意事项:
• DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。
• DELETE 语句不能删除某一个字段的值(可以使用UPDATE,将该字段值置为NULL即可)。
• 当进行删除全部数据操作时,会提示询问是否确认删除所有数据,直接点击Execute即可。
4.数据库操作-DQL
查询操作是所有SQL语句当中最为常见、最为重要的操作。在一个正常的业务系统中,查询操作的使用频次远高于增删改操作。
4.1 语法
SELECT
字段列表
FROM
表名列表
WHERE
条件列表
GROUP BY
分组字段列表
HAVING
分组后条件列表
ORDER BY
排序字段列表
LIMIT
分页参数
4.2 基本查询
在基本查询的DQL语句中,不带任何的查询条件。
查询多个字段:
select 字段1, 字段2, 字段3 from 表名;
查询所有字段(通配符):
select * from 表名;
设置别名:
select 字段1 [ as 别名1 ] , 字段2 [ as 别名2 ] from 表名;
去除重复记录:
select distinct 字段列表 from 表名;
4.3 条件查询
select 字段列表 from 表名 where 条件列表 ; -- 条件列表:意味着可以有多个条件
在SQL语句当中构造条件的运算符分为两类:
- 比较运算符
- 逻辑运算符
比较运算符:
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| between … and … | 在某个范围之内(含最小、最大值) |
| in(…) | 在in之后的列表中的值,多选一 |
| like 占位符 | 模糊匹配(_匹配单个字符, %匹配任意个字符) |
| is null | 是null |
逻辑运算符:
| 逻辑运算符 | 功能 |
|---|---|
| and 或 && | 并且 (多个条件同时成立) |
| or 或 || | 或者 (多个条件任意一个成立) |
| not 或 ! | 非 , 不是 |
4.4 聚合函数
语法:
select 聚合函数(字段列表) from 表名 ;
聚合函数会忽略空值,对NULL值不作为统计。
常用聚合函数:
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
count :按照列去统计有多少行数据。
- 在根据指定的列统计的时候,如果这一列中有null的行,该行不会被统计在其中。
sum :计算指定列的数值和,如果不是数值类型,那么计算结果为0
max :计算指定列的最大值
min :计算指定列的最小值
avg :计算指定列的平均值
4.5 分组查询
分组: 按照某一列或者某几列,把相同的数据进行合并输出。
分组其实就是按列进行分类(指定列下相同的数据归为一类),然后可以对分类完的数据进行合并计算。
分组查询通常会使用聚合函数进行计算。
语法:
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];
注意事项:
• 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
• 执行顺序:where > 聚合函数 > having
where与having区别(面试题)
- 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
4.6 排序查询
语法:
select 字段列表
from 表名
[where 条件列表]
[group by 分组字段 ]
order by 字段1 排序方式1 , 字段2 排序方式2 … ;
-
排序方式:
-
ASC :升序(默认值)
-
DESC:降序
-
如果是升序, 可以不指定排序方式ASC
如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
4.7 分页查询
分页查询语法:
select 字段列表 from 表名 limit 起始索引, 查询记录数 ;
起始索引从0开始。 计算公式 : 起始索引 = (查询页码 - 1)* 每页显示记录数
分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT
如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 条数
5.多表设计
实际项目开发中,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
-
一对多(多对一)
-
多对多
-
一对一
5.1 一对多
实现:在数据库表中多的一方,添加字段,来关联属于一这方的主键。
外键约束:让两张表的数据建立连接,保证数据的一致性和完整性。
对应的关键字:foreign key
外键约束的语法:
-- 创建表时指定
create table 表名(
字段名 数据类型,
...
[constraint] [外键名称] foreign key (外键字段名) references 主表 (主表列名)
);
-- 建完表后,添加外键
alter table 表名 add constraint 外键名称 foreign key(外键字段名) references 主表(主表列名);
当我们添加外键约束时,需要保证当前数据库表中的数据是完整的。
-
物理外键
- 概念:使用foreign key定义外键关联另外一张表。
- 缺点:
- 影响增、删、改的效率(需要检查外键关系)。
- 仅用于单节点数据库,不适用与分布式、集群场景。
- 容易引发数据库的死锁问题,消耗性能。
-
逻辑外键
- 概念:在业务层逻辑中,解决外键关联。
- 实现:通过应用程序逻辑或代码层面的设计来维护表之间的关联关系,从而模拟外键的关联性,不会依赖数据库的物理约束。
- 通过逻辑外键,就可以很方便的解决上述问题。
**在现在的企业开发中,很少会使用物理外键,都是使用逻辑外键。 甚至在一些数据库开发规范中,会明确指出禁止使用物理外键 foreign key **
5.2 一对一
一对一关系通常是用来做单表的拆分,也就是将一张大表拆分成两张小表,将大表中的一些基础字段放在一张表当中,将其他的字段放在另外一张表当中,以此来提高数据的操作效率。
实现:在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
5.3 多对多
多对多的关系在开发中比较常见。比如:学生和老师的关系,一个学生可以有多个授课老师,一个授课老师也可以有多个学生。
实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键。
6.多表查询
6.1 概述
多表查询:查询时从多张表中获取所需数据
单表查询的SQL语句:select 字段列表 from 表名;
那么要执行多表查询,只需要使用逗号分隔多张表即可,如: select 字段列表 from 表1, 表2;
例如,查询用户表和部门表中的数据:
select * from tb_emp , tb_dept;
笛卡尔积:笛卡尔乘积是指在数学中,两个集合(A集合和B集合)的所有组合情况。
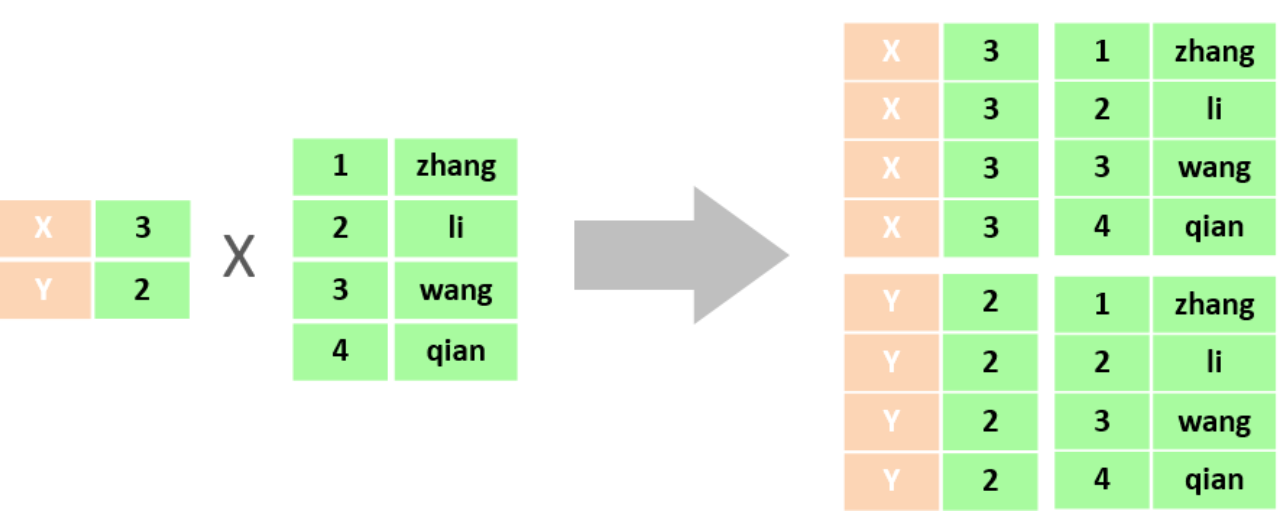
在多表查询时,需要消除无效的笛卡尔积,只保留表关联部分的数据,只需要给多表查询加上连接查询的条件即可:
select * from tb_emp , tb_dept where tb_emp.dept_id = tb_dept.id ;
分类
多表查询可以分为:
-
连接查询
- 内连接:相当于查询A、B交集部分数据
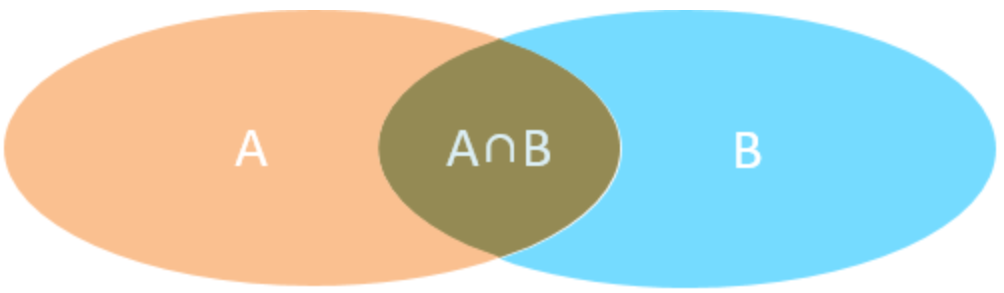
-
外连接
-
左外连接:查询左表所有数据(包括两张表交集部分数据)
-
右外连接:查询右表所有数据(包括两张表交集部分数据)
-
-
子查询
6.2 内连接
内连接查询:查询两表或多表中交集部分数据。
内连接从语法上可以分为:
-
隐式内连接
-
显式内连接
隐式内连接语法:
select 字段列表 from 表1 , 表2 where 条件 ... ;
显式内连接语法:
select 字段列表 from 表1 [ inner ] join 表2 on 连接条件 ... ;
一旦为表起了别名,就不能再使用表名来指定对应的字段了,此时只能够使用别名来指定字段。
6.3 外连接
外连接分为两种:左外连接 和 右外连接。
左外连接语法结构:
select 字段列表 from 表1 left [ outer ] join 表2 on 连接条件 ... ;
左外连接相当于查询表1(左表)的所有数据,当然也包含表1和表2交集部分的数据。
右外连接语法结构:
select 字段列表 from 表1 right [ outer ] join 表2 on 连接条件 ... ;
右外连接相当于查询表2(右表)的所有数据,当然也包含表1和表2交集部分的数据。
左外连接和右外连接可以相互替换,只需要调整连接查询SQL语句中表的先后顺序就形了。在日常开发使用时,更偏向于左外连接。
6.4 子查询
SQL语句中嵌套select语句,称为嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 ... );
子查询外部的语句可以是insert / update / delete / select 的任何一个,最常见的是 select。
根据子查询结果的不同分为:
-
标量子查询(子查询结果为单个值[一行一列])
-
列子查询(子查询结果为一列,但可以是多行)
-
行子查询(子查询结果为一行,但可以是多列)
-
表子查询(子查询结果为多行多列[相当于子查询结果是一张表])
子查询可以书写的位置:
- where之后
- from之后
- select之后
6.4.1 标量子查询
常用的操作符: = <> > >= < <=
6.4.2 列子查询
常用的操作符:
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范围之内,多选一 |
| NOT IN | 不在指定的集合范围之内 |
6.4.3 行子查询
常用的操作符:= 、<> 、IN 、NOT IN
6.4.4 表子查询
子查询返回的结果是多行多列,常作为临时表,这种子查询称为表子查询。
7.事务
事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务作用:保证在一个事务中多次操作数据库表中数据时,要么全都成功,要么全都失败。
7.1 操作
MYSQL中有两种方式进行事务的操作:
- 自动提交事务:即执行一条sql语句提交一次事务。(默认MySQL的事务是自动提交)
- 手动提交事务:先开启,再提交
事务操作有关的SQL语句:
| SQL语句 | 描述 |
|---|---|
| start transaction; / begin ; | 开启手动控制事务 |
| commit; | 提交事务 |
| rollback; | 回滚事务 |
手动提交事务使用步骤:
- 第1种情况:开启事务 => 执行SQL语句 => 成功 => 提交事务
- 第2种情况:开启事务 => 执行SQL语句 => 失败 => 回滚事务
7.2 四大特性
- 原子性(Atomicity):事务是不可分割的最小单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
事务的四大特性简称为:ACID
8.索引
索引(index):是帮助数据库高效获取数据的数据结构,使用索引可以提高查询的效率。
优点:
- 提高数据查询的效率,降低数据库的IO成本。
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。
缺点:
- 索引会占用存储空间。
- 索引大大提高了查询效率,同时却也降低了insert、update、delete的效率。
语法
创建索引
create [ unique ] index 索引名 on 表名 (字段名,... ) ;
查看索引
show index from 表名;
删除索引
drop index 索引名 on 表名;
注意事项:
主键字段,在建表时,会自动创建主键索引
添加唯一约束时,数据库实际上会添加唯一索引
十三、Mybatis
MyBatis是一款优秀的 持久层 框架,用于简化JDBC的开发。
- 持久层:指的是就是数据访问层(dao),是用来操作数据库的。
- 框架:是一个半成品软件,是一套可重用的、通用的、软件基础代码模型。
1.快速入门
1.1 准备工作
创建springboot工程:创建springboot工程,并导入 mybatis的起步依赖、mysql的驱动包。
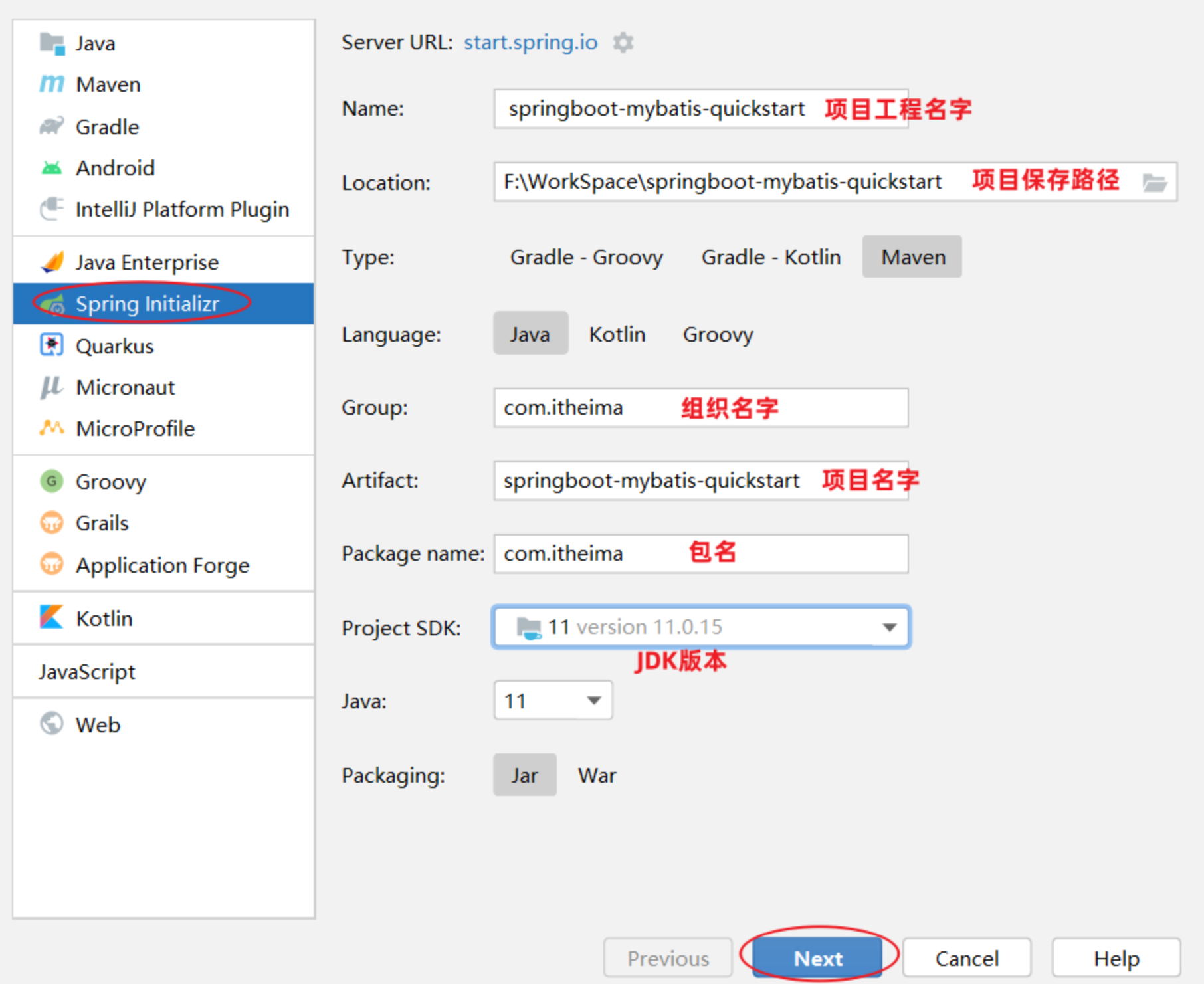
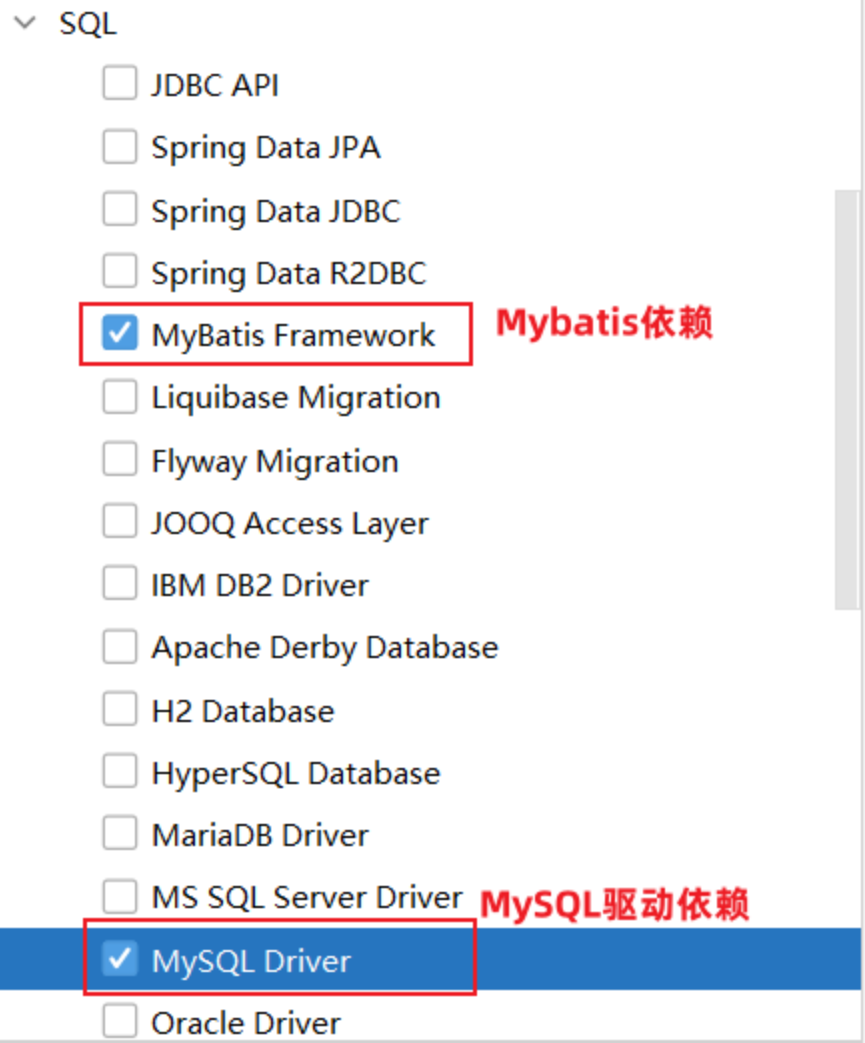
项目工程创建完成后,会自动在pom.xml文件中,导入Mybatis依赖和MySQL驱动依赖
<!-- mybatis起步依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.3.0</version>
</dependency>
<!-- mysql驱动包依赖 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
数据准备:创建用户表user,并创建对应的实体类com.itheima.pojo.User。
用户表
-- 用户表
create table user(
id int unsigned primary key auto_increment comment 'ID',
name varchar(100) comment '姓名',
age tinyint unsigned comment '年龄',
gender tinyint unsigned comment '性别, 1:男, 2:女',
phone varchar(11) comment '手机号'
) comment '用户表';
-- 插入测试数据省略
实体类
public class User {
private Integer id; //id(主键)
private String name; //姓名
private Short age; //年龄
private Short gender; //性别
private String phone; //手机号
//省略GET, SET方法
}
属性名与表中的字段名一一对应。
1.2 配置Mybatis
从上图可以看出连接数据库的四大参数:
- MySQL驱动类
- 登录名
- 密码
- 数据库连接字符串
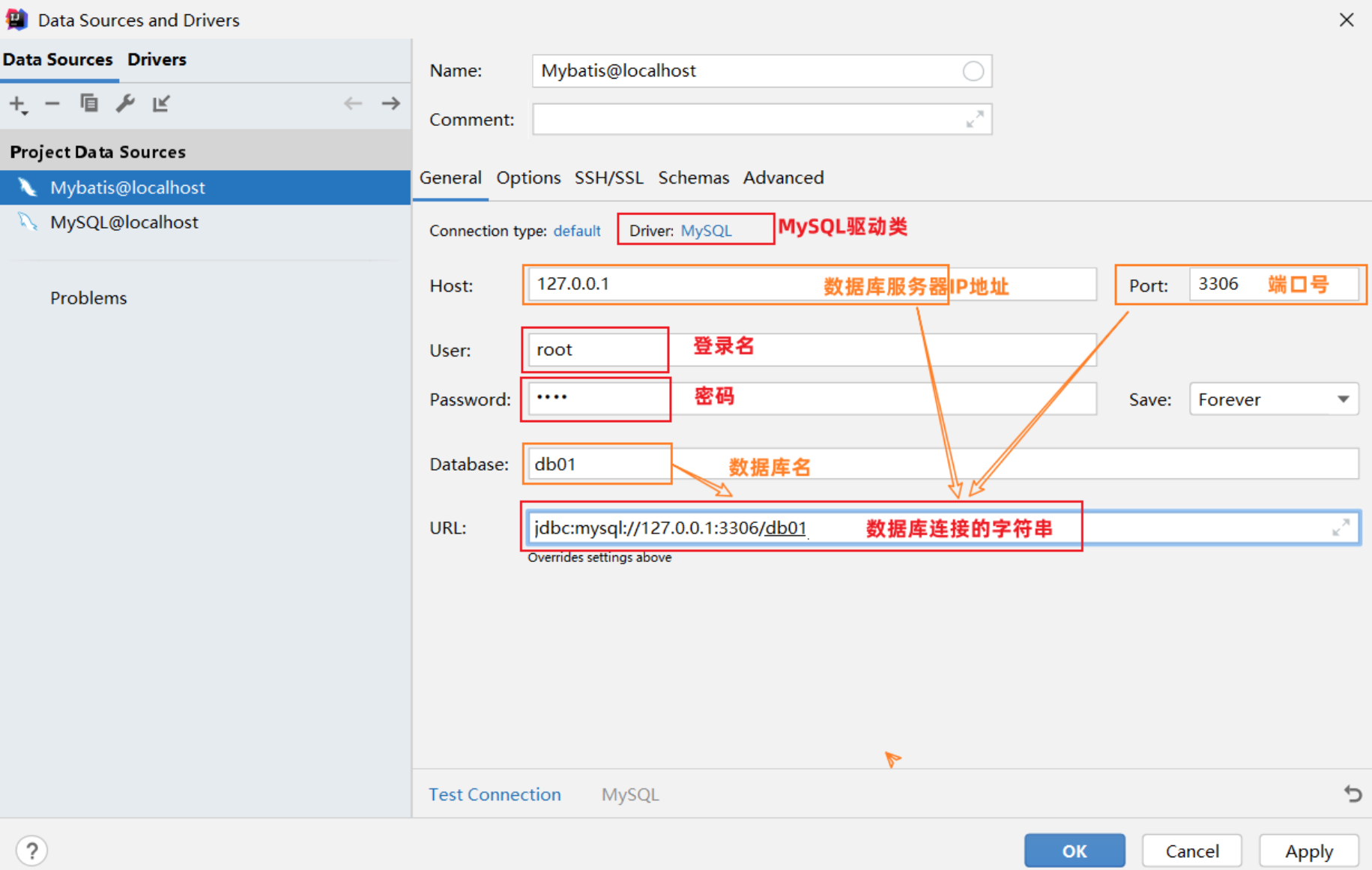
在springboot项目中,编写application.properties文件,配置数据库连接信息driver-class-name、url 、username和password:
#驱动类名称
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#数据库连接的url
spring.datasource.url=jdbc:mysql://localhost:3306/mybatis
#连接数据库的用户名
spring.datasource.username=root
#连接数据库的密码
spring.datasource.password=123456
1.3 编写SQL语句
在创建出来的springboot工程中,在引导类所在包下,在创建一个包 mapper。在mapper包下创建一个接口 UserMapper ,这是一个持久层接口(Mybatis的持久层接口规范一般都叫 XxxMapper)。

UserMapper:
import com.itheima.pojo.User;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
@Mapper
public interface UserMapper {
//查询所有用户数据
@Select("select id, name, age, gender, phone from user")
public List<User> list();
}
@Mapper注解:表示是mybatis中的Mapper接口
- 程序运行时:框架会自动生成接口的实现类对象(代理对象),并给交Spring的IOC容器管理
@Select注解:代表的就是select查询,用于书写select查询语句
1.4 单元测试
在创建出来的SpringBoot工程中,在src下的test目录下,已经自动帮我们创建好了测试类 ,并且在测试类上已经添加了注解 @SpringBootTest,代表该测试类已经与SpringBoot整合。
该测试类在运行时,会自动通过引导类加载Spring的环境(IOC容器)。我们要测试那个bean对象,就可以直接通过@Autowired注解直接将其注入进行,然后就可以测试了。
@SpringBootTest
public class MybatisQuickstartApplicationTests {
@Autowired
private UserMapper userMapper;
@Test
public void testList(){
List<User> userList = userMapper.list();
for (User user : userList) {
System.out.println(user);
}
}
}
1.5 解决SQL警告与提示
如果想让idea给我们提示对应的SQL语句,我们需要在IDEA中配置与MySQL数据库的链接。
如果idea不识别表名,就需要建立连接。
2.JDBC介绍(了解)
java语言操作数据库只能通过sun公司提供的 JDBC 规范。Mybatis框架,就是对原始的JDBC程序的封装。
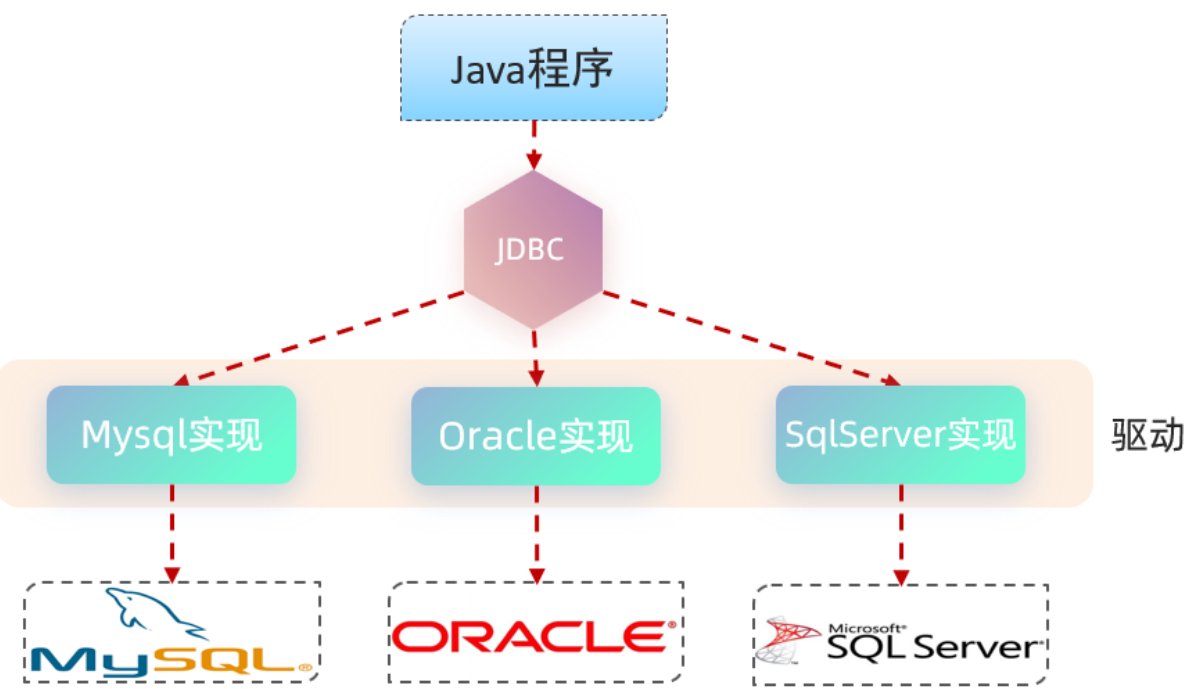
本质:
-
sun公司官方定义的一套操作所有关系型数据库的规范,即接口。
-
各个数据库厂商去实现这套接口,提供数据库驱动jar包。
-
我们可以使用这套接口(JDBC)编程,真正执行的代码是驱动jar包中的实现类。
2.1 代码
... //导包省略
public class JdbcTest {
@Test
public void testJdbc() throws Exception {
//1. 注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//2. 获取数据库连接
String url="jdbc:mysql://127.0.0.1:3306/mybatis";
String username = "root";
String password = "1234";
Connection connection = DriverManager.getConnection(url, username, password);
//3. 执行SQL
Statement statement = connection.createStatement(); //操作SQL的对象
String sql="select id,name,age,gender,phone from user";
ResultSet rs = statement.executeQuery(sql);//SQL查询结果会封装在ResultSet对象中
List<User> userList = new ArrayList<>();//集合对象(用于存储User对象)
//4. 处理SQL执行结果
while (rs.next()){
//取出一行记录中id、name、age、gender、phone下的数据
int id = rs.getInt("id");
String name = rs.getString("name");
short age = rs.getShort("age");
short gender = rs.getShort("gender");
String phone = rs.getString("phone");
//把一行记录中的数据,封装到User对象中
User user = new User(id,name,age,gender,phone);
userList.add(user);//User对象添加到集合
}
//5. 释放资源
statement.close();
connection.close();
rs.close();
//遍历集合
for (User user : userList) {
System.out.println(user);
}
}
}
DriverManager(类):数据库驱动管理类。
-
作用:
-
注册驱动
-
创建java代码和数据库之间的连接,即获取Connection对象
-
Connection(接口):建立数据库连接的对象
- 作用:用于建立java程序和数据库之间的连接
Statement(接口): 数据库操作对象(执行SQL语句的对象)。
- 作用:用于向数据库发送sql语句
ResultSet(接口):结果集对象(一张虚拟表)
- 作用:sql查询语句的执行结果会封装在ResultSet中
2.2 问题分析和对比
JDBC操作数据库把四要素(驱动、链接、用户名、密码)硬性写在java程序中,查询解析非常繁琐,每次都要重新建立和释放资源,导致资源浪费,性能降低。
而JDBC把四要素(驱动、链接、用户名、密码)配置在配置文件 application.properties中,便于修改,查询结果的解析和封装自动映射,不必关注具体的实现,通过数据库连接池技术,避免了频繁创建销毁连接而带来的资源浪费。
对于Mybatis,在操作数据库时,重点关注两个方面:配置文件application.properties和Mapper接口,大大节省开发压力。
3.数据库连接池
数据库连接池是一个容器,负责分配、管理数据库连接,程序启动时,会自动创建一些Connection连接对象放在连接池中。
用户使用SQL时,只需要从连接池中获取一个Connection对象,用完归还。
如果Connection对象的空闲时间 > 连接池中预设的最大空闲时间,此时数据库连接池就会自动收回这个连接对象
产品:
-
官方(sun)提供了数据库连接池标准(javax.sql.DataSource接口)
-
功能:获取连接
public Connection getConnection() throws SQLException; -
第三方组织必须按照DataSource接口实现
-
常见的数据库连接池:
- C3P0
- DBCP
- Druid(德鲁伊)
- Hikari (追光者,springboot默认,间接依赖于mybatis-spring-boot-starter)
Druid(德鲁伊):阿里巴巴开源的数据库连接池项目,功能强大,性能优秀,是Java语言最好的数据库连接池之一。
把默认的数据库连接池Hikari 切换为Druid数据库连接池的步骤:
- 在pom.xml文件中引入依赖
<dependency>
<!-- Druid连接池依赖 -->
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.8</version>
</dependency>
- 在application.properties中引入数据库连接配置
方式1:
spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.druid.url=jdbc:mysql://localhost:3306/mybatis
spring.datasource.druid.username=root
spring.datasource.druid.password=1234
方式2:
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/mybatis
spring.datasource.username=root
spring.datasource.password=1234
4.lombok
Lombok是一个实用的Java类库,可以通过简单的注解来简化和消除一些必须有但显得很臃肿的Java代码。
| 注解 | 作用 |
|---|---|
| @Getter/@Setter | 为所有的属性提供get/set方法 |
| @ToString | 会给类自动生成易阅读的 toString 方法 |
| @EqualsAndHashCode | 根据类所拥有的非静态字段自动重写 equals 方法和 hashCode 方法 |
| @Data | 提供了更综合的生成代码功能(@Getter + @Setter + @ToString + @EqualsAndHashCode) |
| @NoArgsConstructor | 为实体类生成无参的构造器方法 |
| @AllArgsConstructor | 为实体类生成除了static修饰的字段之外带有各参数的构造器方法。 |
使用:
第1步:在pom.xml文件中引入依赖
<!-- 在springboot的父工程中,已经集成了lombok并指定了版本号,故当前引入依赖时不需要指定version -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
第2步:在实体类上添加注解
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private Integer id;
private String name;
private Short age;
private Short gender;
private String phone;
}
在实体类上添加了@Data注解,那么这个类在编译时期,就会生成getter/setter、equals、hashcode、toString等方法。
Lombok的注意事项:
- Lombok会在编译时,会自动生成对应的java代码
- 在使用lombok时,还需要安装一个lombok的插件(新版本的IDEA中自带)
5.Mybatis基础操作
5.1 准备
准备数据库表:
-- 部门管理
create table dept
(
id int unsigned primary key auto_increment comment '主键ID',
name varchar(10) not null unique comment '部门名称',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '部门表';
-- 部门表测试数据
...
-- 员工管理
create table emp
(
id int unsigned primary key auto_increment comment 'ID',
username varchar(20) not null unique comment '用户名',
password varchar(32) default '123456' comment '密码',
name varchar(10) not null comment '姓名',
gender tinyint unsigned not null comment '性别, 说明: 1 男, 2 女',
image varchar(300) comment '图像',
job tinyint unsigned comment '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管, 5 咨询师',
entrydate date comment '入职时间',
dept_id int unsigned comment '部门ID',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '员工表';
-- 员工表测试数据
...
创建一个新的springboot工程,选择引入对应的起步依赖(mybatis、mysql驱动、lombok)
application.properties中引入数据库连接信息
创建对应的实体类Emp(实体类属性采用驼峰命名)
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Emp {
private Integer id;
private String username;
private String password;
private String name;
private Short gender;
private String image;
private Short job;
private LocalDate entrydate; //LocalDate类型对应数据表中的date类型
private Integer deptId;
private LocalDateTime createTime;//LocalDateTime类型对应数据表中的datetime类型
private LocalDateTime updateTime;
}
准备Mapper接口:EmpMapper
@Mapper
public interface EmpMapper {
}
5.2 删除
根据主键删除数据:
@Mapper
public interface EmpMapper {
//使用#{key}方式获取方法中的参数值,将来形参id会替换参数占位符#{id}
@Delete("delete from emp where id = #{id}")
public void delete(Integer id); //可以指定返回值为int型,表示delete删除的行数
}
@Delete注解:用于编写delete操作的SQL语句
如果mapper接口方法形参只有一个普通类型的参数,#{…} 里面的属性名可以随便写,如:#{id}、#{value}。但是建议保持名字一致。
5.3 日志输入
在Mybatis中可以借助日志,查看到sql语句的执行、执行传递的参数以及执行结果:
- 在application.properties文件中开启mybatis的日志,并指定输出到控制台
#指定mybatis输出日志的位置, 输出控制台
mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
5.4 预编译SQL
5.4.1 优势
预编译SQL有两个优势:
- 性能更高:将编译后的SQL语句缓存起来,后面再次执行这条语句时,不会再次编译。(只是输入的参数不同)
- 更安全(防止SQL注入):将敏感字进行转义,保障SQL的安全性。
5.4.2 SQL注入
通过操作输入的数据来修改事先定义好的SQL语句,以达到执行代码对服务器进行攻击的方法。
例如登录页面(用户名和密码),本质是执行查询语句select count(*) from emp where username = '输入的用户名' and password = '输入的密码';,不法分子可以修改密码为‘ or '1' = '1从而进入系统,原理是‘ or '1' = '1替换输入的密码可以得到
select count(*) from emp where username = '输入的用户名' and password = '' or '1' = '1';,由于'1' = '1'始终成立,所以可以登陆成功。而通过预编译就可以避免SQL注入。
5.4.3 参数占位符
在Mybatis中提供的参数占位符有两种:${…} 、#{…}
-
#{…}
- 执行SQL时,会将#{…}替换为?,生成预编译SQL,会自动设置参数值
- 使用时机:参数传递,都使用#{…}
-
${…}
- 拼接SQL。直接将参数拼接在SQL语句中,存在SQL注入问题
- 使用时机:如果对表名、列表进行动态设置时使用
注意事项:在项目开发中,建议使用#{…},生成预编译SQL,防止SQL注入安全。
5.5 插入
@Mapper
public interface EmpMapper {
@Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})")
public void insert(Emp emp);
}
说明:#{…} 里面写的名称是对象的属性名
在数据添加成功后,如果想要拿到主键值,需要在Mapper接口中的方法上添加一个Options注解,并在注解中指定属性useGeneratedKeys=true和keyProperty=“实体类属性名”:
@Mapper
public interface EmpMapper {
//会自动将生成的主键值,赋值给emp对象的id属性
@Options(useGeneratedKeys = true,keyProperty = "id")
@Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})")
public void insert(Emp emp);
}
5.6 更新
@Mapper
public interface EmpMapper {
//根据id修改员工信息
@Update("update emp set username=#{username}, name=#{name}, gender=#{gender}, image=#{image}, job=#{job}, entrydate=#{entrydate}, dept_id=#{deptId}, update_time=#{updateTime} where id=#{id}")
public void update(Emp emp);
}
可以设置返回值类型为int,表示更新操作影响的行数。
5.7 查询
5.7.1 根据ID查询
@Mapper
public interface EmpMapper {
@Select("select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp where id=#{id}")
public Emp getById(Integer id);
}
在测试类测试后,发现deptId、createTime、updateTime这三个字段没有值,这是因为实体类的属性名和数据库的字段名一致会映射成功,而deptId、createTime、updateTime属性在数据库中对应dept_id、create_time、update_time,映射不匹配。解决方案:
方案一:起别名,在SQL语句中,对不一样的列名起别名,别名和实体类属性名一样
@Select("select id, username, password, name, gender, image, job, entrydate, " +
"dept_id AS deptId, create_time AS createTime, update_time AS updateTime " +
"from emp " +
"where id=#{id}")
public Emp getById(Integer id);
方案二:手动结果映射,通过 @Results及@Result 进行手动结果映射
@Results({@Result(column = "dept_id", property = "deptId"),
@Result(column = "create_time", property = "createTime"),
@Result(column = "update_time", property = "updateTime")})
@Select("select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp where id=#{id}")
public Emp getById(Integer id);
方案三:开启驼峰命名(推荐),如果字段名与属性名符合驼峰命名规则,mybatis会自动通过驼峰命名规则映射
# 在application.properties中添加:
mybatis.configuration.map-underscore-to-camel-case=true
要使用驼峰命名前提是 实体类的属性 与 数据库表中的字段名严格遵守驼峰命名。如字段dept_id自动映射到deptId属性。
5.7.2 条件查询
@Mapper
public interface EmpMapper {
@Select("select * from emp " +
"where name like '%${name}%' " + //这里不能使用#{name}占位符,因为在''中会被认为是字符串
"and gender = #{gender} " +
"and entrydate between #{begin} and #{end} " +
"order by update_time desc")
public List<Emp> list(String name, Short gender, LocalDate begin, LocalDate end);
}
方法中的形参名和SQL语句中的参数占位符名保持一致
解决SQL注入风险:使用MySQL提供的字符串拼接函数:concat(‘%’ , ‘关键字’ , ‘%’)
@Mapper
public interface EmpMapper {
@Select("select * from emp " +
"where name like concat('%',#{name},'%') " +
"and gender = #{gender} " +
"and entrydate between #{begin} and #{end} " +
"order by update_time desc")
public List<Emp> list(String name, Short gender, LocalDate begin, LocalDate end);
}
5.7.3 参数名说明
在springBoot的2.x版本:在编译时,会在生成的字节码文件中保留原方法形参的名称,所以#{…}可以直接通过形参名获取对应的值。
在springBoot的1.x版本:编译时生成的字节码文件不再保留原方法形参名,默认是var1、var2 …,可以通过@Param注解保留形参名:

6.Mybatis的XML配置文件
如果需要实现复杂的SQL功能,注解将会非常繁琐,可以通过XML文件存放SQL语句。
6.1 XML配置文件规范
-
XML映射文件的名称与Mapper接口名称一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名)
-
XML映射文件的namespace属性与Mapper接口全限定名一致
-
XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致。
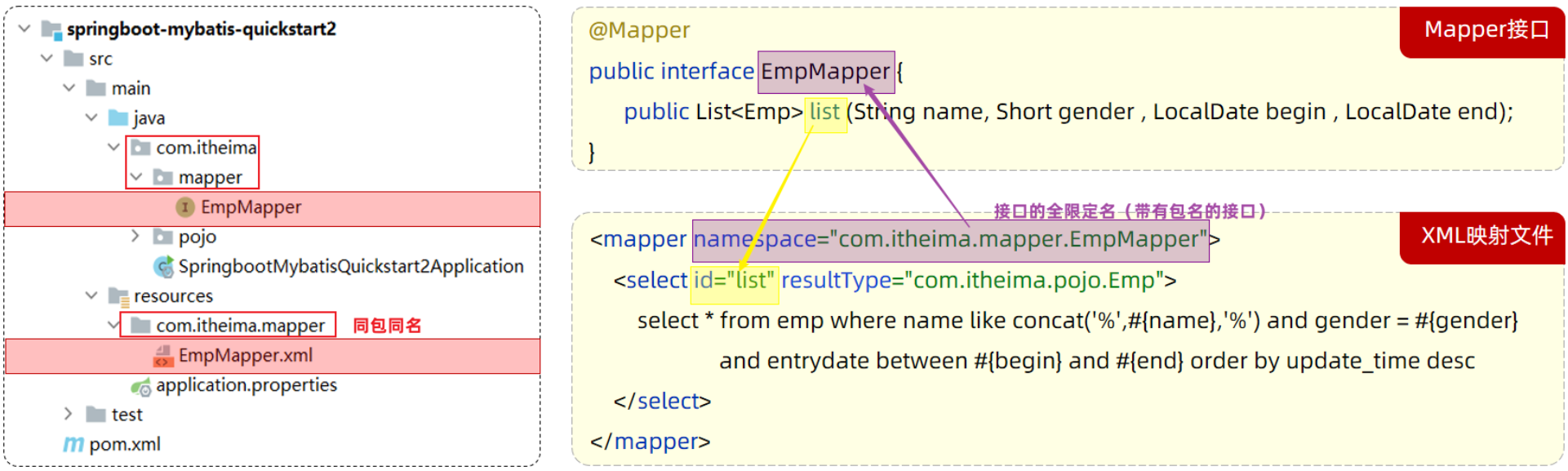
<select>标签:就是用于编写select查询语句的。
- id属性:指定执行SQL语句的方法
- resultType属性,指的是查询返回的单条记录所封装的类型。
6.2 XML配置文件实现
第1步:创建XML映射文件
第2步:编写XML映射文件
- dtd约束,直接从mybatis官网复制即可
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="">
</mapper>
- sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致
<mapper namespace="com.itheima.mapper.EmpMapper">
<!--查询操作-->
<select id="list" resultType="com.itheima.pojo.Emp">
select * from emp
where name like concat('%',#{name},'%')
and gender = #{gender}
and entrydate between #{begin} and #{end}
order by update_time desc
</select>
</mapper>
注解和XML配置文件的选择:
使用Mybatis的注解,主要是来完成一些简单的增删改查功能。
如果需要实现复杂的SQL功能,建议使用XML来配置映射语句。
6.3 MybatisX
MybatisX是一款基于IDEA的快速开发Mybatis的插件,可以通过MybatisX快速定位,直接搜索插件安装即可。
7.动态SQL
动态SQL就是方法参数可以只传递一部分,其他的传递null,实现部分条件的SQL语句执行。例如empMapper.list("张", null, null, null)表示只根据name查询。
7.1 动态SQL-if
<if>:用于判断条件是否成立。使用test属性进行条件判断,如果条件为true,则拼接SQL。
<if test="条件表达式">
要拼接的sql语句
</if>
7.1.1 条件查询
改造5.7.2中的XML配置文件为动态SQL:
<select id="list" resultType="com.itheima.pojo.Emp">
select * from emp
<where>
<!-- if做为where标签的子元素 -->
<if test="name != null">
and name like concat('%',#{name},'%')
</if>
<if test="gender != null">
and gender = #{gender}
</if>
<if test="begin != null and end != null">
and entrydate between #{begin} and #{end}
</if>
</where>
order by update_time desc
</select>
<where>标签只会在子元素有内容的情况下才插入where子句,而且在合适时会自动去除子句的开头的AND或OR
7.1.2 条件更新
改造5.6中的XML配置文件为动态SQL:
<update id="update">
update emp
<!-- 使用set标签,代替update语句中的set关键字 -->
<set>
<if test="username != null">
username=#{usern ame},
</if>
<if test="name != null">
name=#{name},
</if>
<if test="gender != null">
gender=#{gender},
</if>
<if test="image != null">
image=#{image},
</if>
<if test="job != null">
job=#{job},
</if>
<if test="entrydate != null">
entrydate=#{entrydate},
</if>
<if test="deptId != null">
dept_id=#{deptId},
</if>
<if test="updateTime != null">
update_time=#{updateTime}
</if>
</set>
where id=#{id}
</update>
<set>:动态的在SQL语句中插入set关键字,并会在合适时删掉额外的逗号。(用于update语句中)
7.2 动态SQL-foreach
Mapper接口:
@Mapper
public interface EmpMapper {
//批量删除
public void deleteByIds(List<Integer> ids);
}
XML映射文件:
- 使用
<foreach>遍历deleteByIds方法中传递的参数ids集合
<foreach collection="集合名称" item="集合遍历出来的元素/项" separator="每一次遍历使用的分隔符"
open="遍历开始前拼接的片段" close="遍历结束后拼接的片段">
</foreach>
<delete id="deleteByIds">
<!-- delete from emp where id in (1,2,3,...); -->
delete from emp where id in
<foreach collection="ids" item="id" separator="," open="(" close=")">
#{id}
</foreach>
</delete>
7.3 动态SQL-sql&include
在xml映射文件中配置的SQL,有时可能会存在很多重复的片段,此时就会存在很多冗余的代码

-
<sql>:定义可重用的SQL片段 -
<include>:通过属性refid,指定包含的SQL片段
<!-- SQL片段: 抽取重复的代码 -->
<sql id="commonSelect">
select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp
</sql>
<!-- 通过<include>标签在原来抽取的地方进行引用 -->
<select id="list" resultType="com.itheima.pojo.Emp">
<include refid="commonSelect"/>
<where>
<if test="name != null">
name like concat('%',#{name},'%')
</if>
<if test="gender != null">
and gender = #{gender}
</if>
<if test="begin != null and end != null">
and entrydate between #{begin} and #{end}
</if>
</where>
order by update_time desc
</select>
十四、SpringBootWeb案例
具体操作见资料中的SpringBootWeb综合案例。这里只写出现的新知识点。
1.开发规范
1.1 开发规范-REST
在前后端进行交互的时候,我们需要基于当前主流的REST风格的API接口进行交互。
REST(Representational State Transfer):表述性状态转换,它是一种软件架构风格。
传统URL风格:
http://localhost:8080/user/getById?id=1 GET:查询id为1的用户
http://localhost:8080/user/saveUser POST:新增用户
http://localhost:8080/user/updateUser POST:修改用户
http://localhost:8080/user/deleteUser?id=1 GET:删除id为1的用户
原始的传统URL呢,定义比较复杂,而且资源的访问行为对外暴露。
基于REST风格URL:
http://localhost:8080/users/1 GET:查询id为1的用户
http://localhost:8080/users POST:新增用户
http://localhost:8080/users PUT:修改用户
http://localhost:8080/users/1 DELETE:删除id为1的用户
通过URL定位要操作的资源,通过HTTP动词(请求方式)来描述具体的操作。
在REST风格的URL中,通过四种请求方式来操作数据的增删改查:
- GET : 查询
- POST :新增
- PUT :修改
- DELETE :删除
描述模块的功能通常使用复数,也就是加s的格式来描述,表示此类资源,而非单个资源。如:users、emps、books…
1.2 开发规范-统一响应结果
前后端工程在进行交互时,使用统一响应结果 Result。
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Result {
private Integer code;//响应码,1 代表成功; 0 代表失败
private String msg; //响应信息 描述字符串
private Object data; //返回的数据
//增删改 成功响应
public static Result success(){
return new Result(1,"success",null);
}
//查询 成功响应
public static Result success(Object data){
return new Result(1,"success",data);
}
//失败响应
public static Result error(String msg){
return new Result(0,msg,null);
}
}
1.3 开发流程
在进行功能开发时,都是根据如下流程进行:

接口文档一般由后端程序员书写。
2.日志对象
若要使用日志功能,需要在每个类里手动声明一个 Logger 对象:
private static final Logger log = LoggerFactory.getLogger(WithoutSlf4jExample.class);
log.info("Doing something..."); //日志记录
在类上添加 @Slf4j 注解后,Lombok 会在编译阶段自动为该类生成一个 org.slf4j.Logger 类型的日志对象。这个日志对象的名称通常为 log,可以直接使用它进行日志记录操作:
@Slf4j
public class WithSlf4jExample {
public void doSomething() {
log.info("Doing something...");
}
}
3.Controller层请求方式
@RequestMapping注解可以接受任何形式的请求方式,如果想要指定请求方式的限制,可以通过method属性指定:
@RequestMapping(value = "/depts" , method = RequestMethod.GET) //只允许GET请求
@RequestMapping(value = "/depts" , method = RequestMethod.POST) //只允许POST请求
@RequestMapping(value = "/depts" , method = RequestMethod.PUT) //只允许PUT请求
@RequestMapping(value = "/depts" , method = RequestMethod.DELETE) //只允许DELETE请求
springboot还提供了简便方式指定请求方式:
@GetMapping("/depts") //只接受get请求
@POSTMapping("/depts") //只接受post请求
@PUTMapping("/depts") //只接受put请求
@DELETEMapping("/depts") //只接受delete请求
4.请求路径优化
Controller层如果重复的请求路径过多,可以把重复的请求路径抽取到注解@RequestMapping中:
//原注解
@RestController
public class DeptController {
@Autowired
private DeptService deptService;
@GetMapping("/depts")
...
@DeleteMapping("/depts/{id}")
...
@PostMapping("/depts")
...
}
//优化后的注解
@RestController
@RequestMapping("/depts")
public class DeptController {
@Autowired
private DeptService deptService;
@GetMapping ///depts
...
@DeleteMapping("/{id}") ///depts/{id}
...
@PostMapping ///depts
...
}
一个完整的请求路径,应该是类上@RequestMapping的value属性 + 方法上的 @RequestMapping的value属性
5.分页插件
PageHelper是Mybatis的一款功能强大、方便易用的分页插件,支持任何形式的单标、多表的分页查询。
5.1 实现
1、在pom.xml引入依赖
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.4.6</version>
</dependency>
2、代码改造
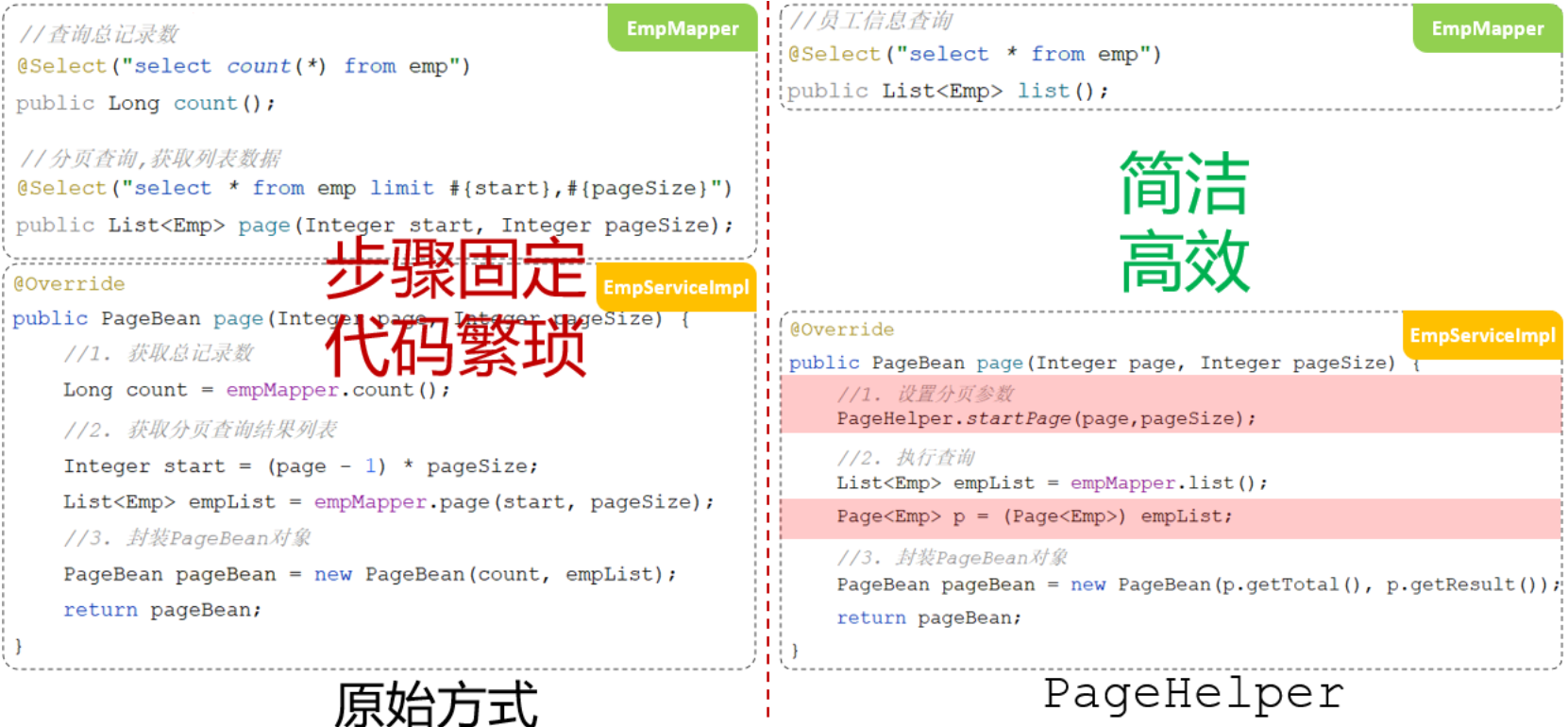
分页插件执行过程:
- 先获取到要执行的SQL语句:select * from emp
- 把SQL语句中的字段列表,变为:count(*)
- 执行SQL语句:select count(*) from emp //获取到总记录数
- 再对要执行的SQL语句:select * from emp 进行改造,在末尾添加 limit ? , ?
- 执行改造后的SQL语句:select * from emp limit ? , ?
5.2 测试
重启项目工程,打开postman,发起GET请求,访问 :http://localhost:8080/emps?page=1&pageSize=5,得到JSON数据。
6.文件上传
文件上传,是指将本地图片、视频、音频等文件上传到服务器,供其他用户浏览或下载的过程。
6.1 简介
想要完成文件上传这个功能需要涉及到两个部分:
- 前端程序
- 服务端程序
6.1.1 前端部分
<form action="/upload" method="post" enctype="multipart/form-data">
姓名: <input type="text" name="username"><br>
年龄: <input type="text" name="age"><br>
头像: <input type="file" name="image"><br>
<input type="submit" value="提交">
</form>
上传文件页面三要素:
-
表单必须有file域,用于选择要上传的文件
<input type="file" name="image"/> -
表单提交方式必须为POST
通常上传的文件会比较大,所以需要使用 POST 提交方式
-
表单的编码类型enctype必须要设置为:multipart/form-data
普通默认的编码格式不适合传输大型的二进制数据,所以在文件上传时,表单的编码格式必须设置为multipart/form-data
实现:
- 将资料里的"upload.html"文件,复制到springboot项目工程下的static目录,在火狐浏览器打开。
- 设置form表单标签中enctype属性值为multipart/form-data,在控制台查看文件传输情况:

如果使用enctype的默认属性值或不指定enctype属性,会看不到文件中的数据,只能看到文件名(带后缀)。
6.1.2 后端部分
-
在服务端定义一个controller层的类用来进行文件上传,然后在controller当中定义一个方法来处理
/upload请求 -
在定义的方法中接收提交过来的数据(形参名和传输的名字相同):
-
用户名:String name
-
年龄: Integer age
-
文件: MultipartFile image
Spring中提供了一个API:MultipartFile,使用这个API就可以来接收到上传的文件
-
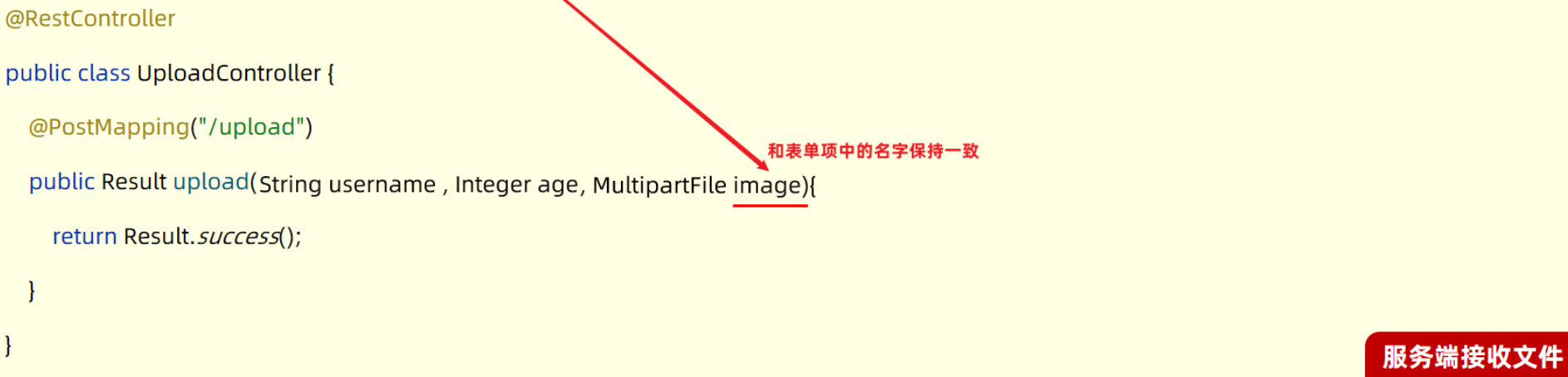
如果表单项的名字和方法中形参名不一致,可以使用@RequestParam注解解决。
6.1.3 测试
- 启动服务端程序
- 打开浏览器输入:http://localhost:8080/upload.html , 录入数据并提交
上传的文件放在了一个临时文件(.tmp)中,通过后端控制台可以得到临时文件的路径,当controller代码正在运行时,临时文件存在,当返回一个结果后,这个临时目录就被释放了。
6.2 本地存储
如果想要保留浏览器传输的文件当程序结束时不被自动释放,就需要把文件保存到本地磁盘中:
- 在服务器本地磁盘上创建images目录,用来存储上传的文件(例:E盘创建images目录)
- 使用MultipartFile类提供的API方法,把临时文件转存到本地磁盘目录下
MultipartFile 常见方法:
- String getOriginalFilename(); //获取原始文件名
- void transferTo(File dest); //将接收的文件转存到磁盘文件中
- long getSize(); //获取文件的大小,单位:字节
- byte[] getBytes(); //获取文件内容的字节数组
- InputStream getInputStream(); //获取接收到的文件内容的输入流
@Slf4j
@RestController
public class UploadController {
@PostMapping("/upload")
public Result upload(String username, Integer age, MultipartFile image) throws IOException {
log.info("文件上传:{},{},{}",username,age,image);
//获取原始文件名
String originalFilename = image.getOriginalFilename();
//将文件存储在服务器的磁盘目录
image.transferTo(new File("E:/images/"+originalFilename));
return Result.success();
}
}
利用postman测试:
由于上传的文件名可能重名,可以使用UUID获取唯一文件名进行本地存储:
@PostMapping("/upload")
public Result upload(String username, Integer age, MultipartFile image) throws IOException {
log.info("文件上传:{},{},{}",username,age,image);
//获取原始文件名
String originalFilename = image.getOriginalFilename();
//构建新的文件名
String extname = originalFilename.substring(originalFilename.lastIndexOf("."));//文件扩展名
String newFileName = UUID.randomUUID().toString()+extname;//随机名+文件扩展名
//将文件存储在服务器的磁盘目录
image.transferTo(new File("E:/images/"+newFileName));
return Result.success();
}
在SpringBoot中,文件上传时默认单个文件最大大小为1M,修改application.properties进行如下配置:
#配置单个文件最大上传大小
spring.servlet.multipart.max-file-size=10MB
#配置单个请求最大上传大小(一次请求可以上传多个文件)
spring.servlet.multipart.max-request-size=100MB
6.3 阿里云OSS
阿里云对象存储OSS,是一款安全可靠的云 存储服务。可以通过网络随时存储和调用包括文本、图片、音频和视频等在内的各种文件。
6.3.1 准备
SDK:软件开发工具包,包括辅助软件开发的依赖(jar包)、代码示例等,都可以叫做SDK。简单说,SDK中包含了使用第三方云服务时所需要的依赖,以及一些示例代码。
Bucket:存储空间是用户用于存储对象(Object,就是文件)的容器,所有的对象都必须隶属于某个存储空间。
使用步骤:

注册登录阿里云后,点击右上角的控制台,点击对象存储OSS:

点击左侧的 “Bucket列表”,创建一个Bucket:
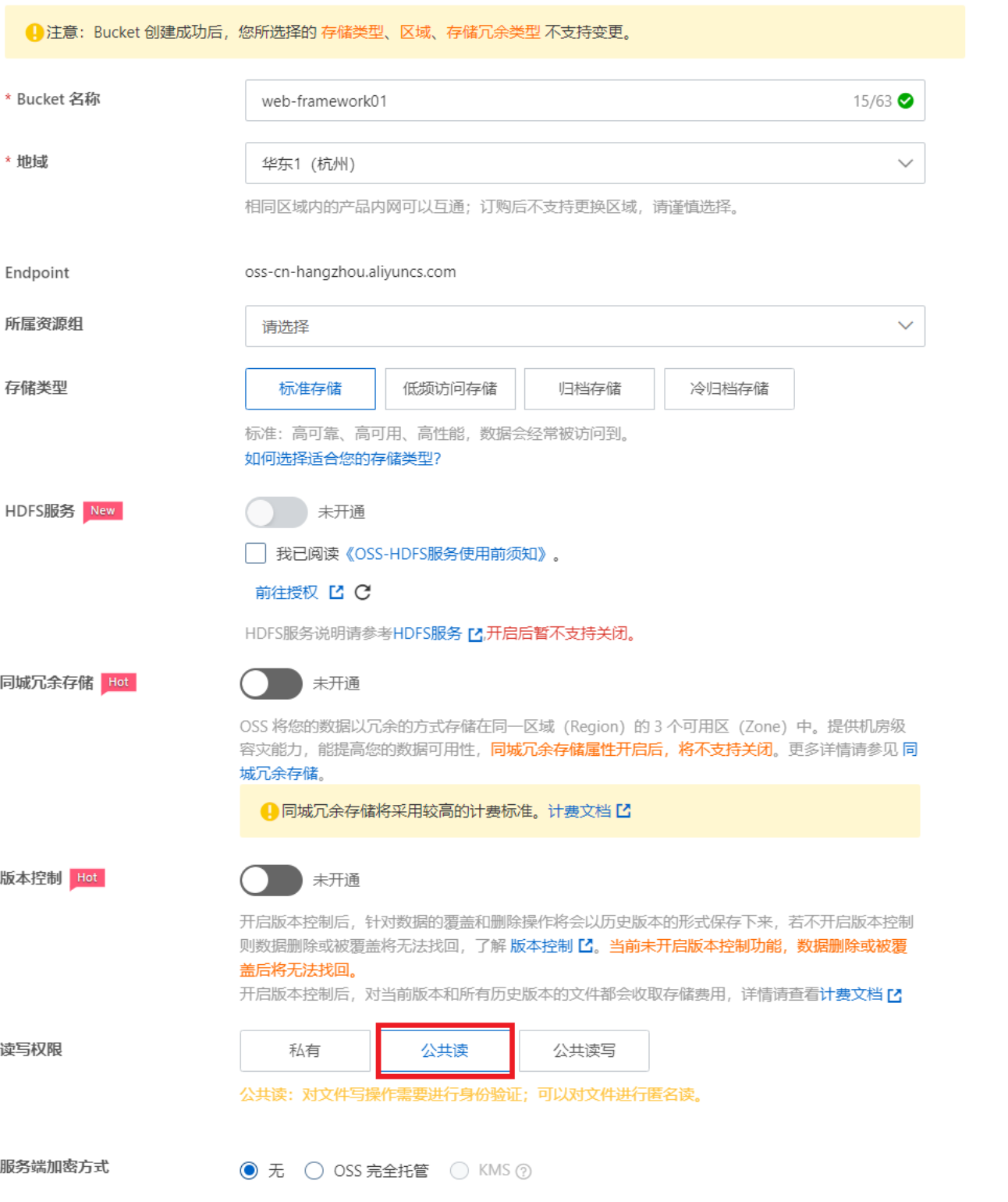
6.3.2 入门
首先需要来打开阿里云OSS的官方文档,在官方文档中找到 SDK 的示例代码:
在实际开发当中,我们是需要从前往后仔细的去阅读这一份文档,这里只说重点。
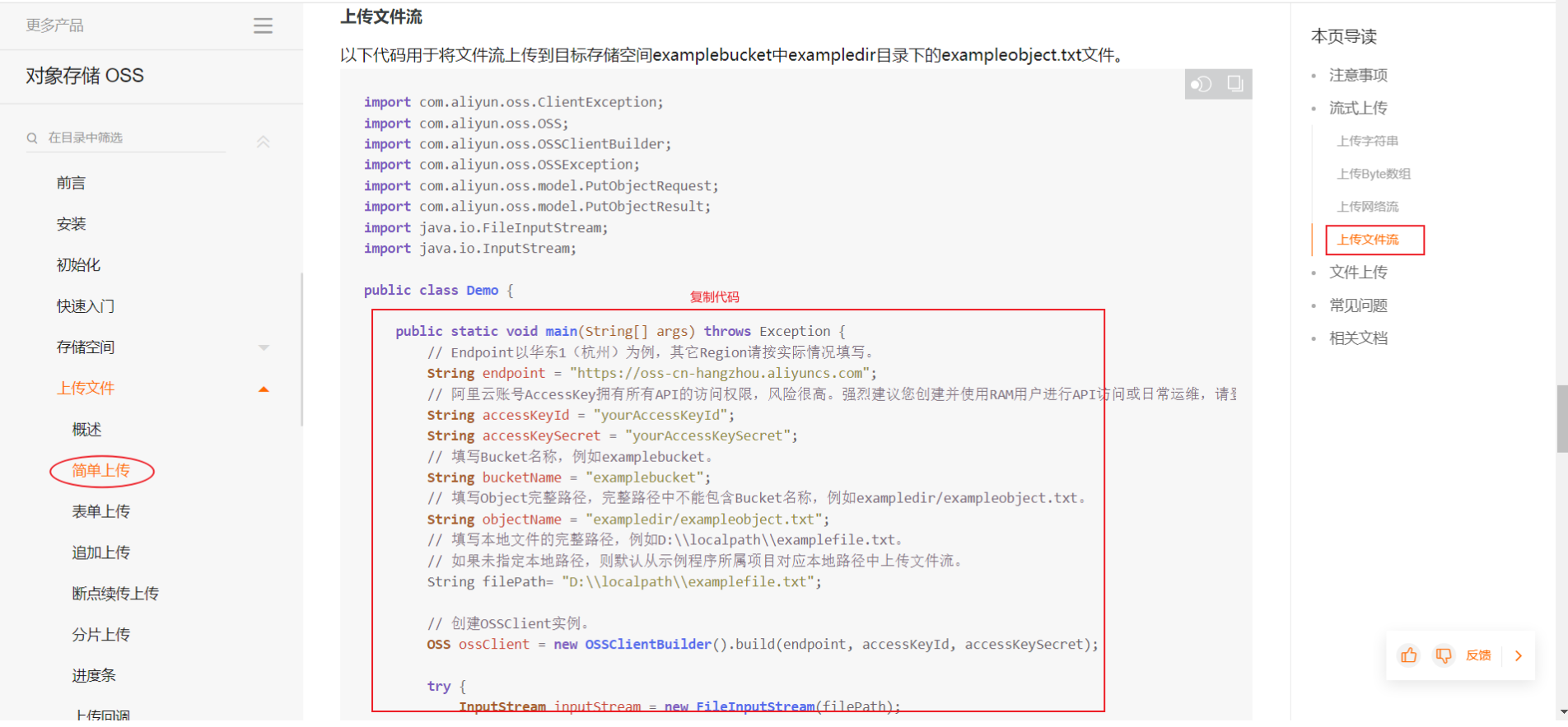
public class AliOssTest {
public static void main(String[] args) throws Exception {
// Endpoint以华东1(杭州)为例,其它Region请按实际情况填写。
String endpoint = "https://oss-cn-hangzhou.aliyuncs.com";
// 阿里云账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM用户进行API访问或日常运维,请登录RAM控制台创建RAM用户。
String accessKeyId = "LTAI5t9MZK8iq5T2Av5GLDxX";
String accessKeySecret = "C0IrHzKZGKqU8S7YQcevcotD3Zd5Tc";
// 填写Bucket名称,例如examplebucket。
String bucketName = "web-framework01";
// 填写Object完整路径,完整路径中不能包含Bucket名称,例如exampledir/exampleobject.txt。
String objectName = "1.jpg";
// 填写本地文件的完整路径,例如D:\\localpath\\examplefile.txt。
// 如果未指定本地路径,则默认从示例程序所属项目对应本地路径中上传文件流。
String filePath= "C:\\Users\\Administrator\\Pictures\\1.jpg";
// 创建OSSClient实例。
OSS ossClient = new OSSClientBuilder().build(endpoint, accessKeyId, accessKeySecret);
try {
InputStream inputStream = new FileInputStream(filePath);
// 创建PutObjectRequest对象。
PutObjectRequest putObjectRequest = new PutObjectRequest(bucketName, objectName, inputStream);
// 设置该属性可以返回response。如果不设置,则返回的response为空。
putObjectRequest.setProcess("true");
// 创建PutObject请求。
PutObjectResult result = ossClient.putObject(putObjectRequest);
// 如果上传成功,则返回200。
System.out.println(result.getResponse().getStatusCode());
} catch (OSSException oe) {
System.out.println("Caught an OSSException, which means your request made it to OSS, "
+ "but was rejected with an error response for some reason.");
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Caught an ClientException, which means the client encountered "
+ "a serious internal problem while trying to communicate with OSS, "
+ "such as not being able to access the network.");
System.out.println("Error Message:" + ce.getMessage());
} finally {
if (ossClient != null) {
ossClient.shutdown();
}
}
}
}
- accessKeyId:阿里云账号AccessKey
- accessKeySecret:阿里云账号AccessKey对应的秘钥
- bucketName:Bucket名称
- objectName:对象名称,在Bucket中存储的对象的名称
- filePath:文件路径
AccessKey获取 :
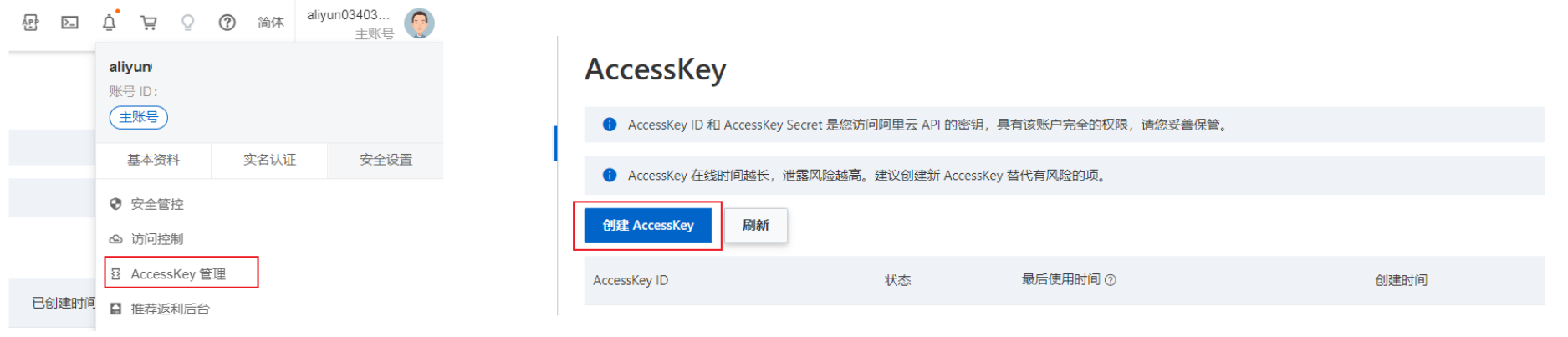
运行以上程序后,会把本地的文件上传到阿里云OSS服务器上,点击文件列表就可以查看了。
注意:在新版本中,抛弃了在代码中硬性使用秘钥,而采用了从系统环境变量中获取,所以需要配置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
7.配置文件
对于代码中重复的且固定的信息,可以配置在配置文件properties中,当需要使用时,通过springboot提供的Value注解注入。
7.1 参数配置化
旧版本的OSS中,需要手动在代码引入OSS地址、秘钥和bucket容器名字,可以把这些信息配置到配置文件增加安全性和代码简洁性:
properties文件
#自定义的阿里云OSS配置信息
aliyun.oss.endpoint=https://oss-cn-hangzhou.aliyuncs.com
aliyun.oss.accessKeyId=LTAI4GCH1vX6DKqJWxd6nEuW
aliyun.oss.accessKeySecret=yBshYweHOpqDuhCArrVHwIiBKpyqSL
aliyun.oss.bucketName=web-tlias
程序代码
@Component
public class AliOSSUtils {
@Value("${aliyun.oss.endpoint}")
private String endpoint;
@Value("${aliyun.oss.accessKeyId}")
private String accessKeyId;
@Value("${aliyun.oss.accessKeySecret}")
private String accessKeySecret;
@Value("${aliyun.oss.bucketName}")
private String bucketName;
...
}
7.2 yml配置文件
传统的配置文件比较臃肿,变量的层级关系不清晰,使用yml配置文件可以很清晰的显示出层级关系,在开发中也更偏向于yml配置文件。
-
application.properties
server.port=8080 server.address=127.0.0.1 -
application.yml
server: port: 8080 address: 127.0.0.1 -
application.yaml
server: port: 8080 address: 127.0.0.1
yml 格式的配置文件,后缀名有两种:
- yml (推荐)
- yaml
yml配置文件的基本语法:
- 大小写敏感
- 数值前边必须有空格,作为分隔符
- 使用缩进表示层级关系,缩进时,不允许使用Tab键,只能用空格(idea中会自动将Tab转换为空格)
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
#表示注释,从这个字符一直到行尾,都会被解析器忽略
yml文件中常见的数据格式:
- 对象/Map集合
user:
name: zhangsan #:后必须要有一个空格
age: 18
password: 123456
- 数组/List/Set集合
hobby:
- java #-后必须要有一个空格
- game
- sport
7.3 @ConfigurationProperties
使用@Value注解给变量赋值在变量很多时会非常繁琐,Spring提供了@ConfigurationProperties注解实现自动注入:
- 创建一个实现类,且实体类中的属性名和配置文件当中key的名字必须一致,实体类当中的属性还需要提供 getter / setter方法
- 将实体类交给Spring的IOC容器管理,成为IOC容器当中的bean对象(@Component)
- 在实体类上添加
@ConfigurationProperties注解,并通过perfect属性来指定配置参数项的前缀
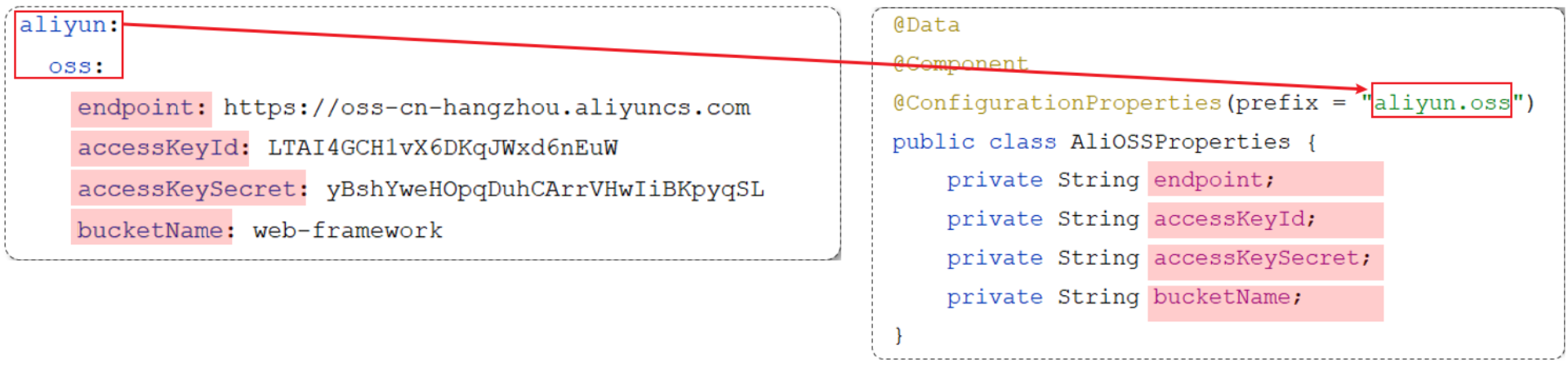
如果出现警告,表明需要添加一个依赖自动识别被@ConfigurationProperties注解标识的bean对象(可选项):
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</dependency>
@ConfigurationProperties注解和@Value注解的区别和选择:
相同点:都是用来注入外部配置的属性的。
不同点:
-
@Value注解只能一个一个的进行外部属性的注入。
-
@ConfigurationProperties可以批量的将外部的属性配置注入到bean对象的属性中。
如果需要注入的属性比较多,而且需要复用,就考虑用@ConfigurationProperties,如果仅仅有少量属性,就可以考虑@Value
8.登录认证
8.1 登录校验
登录校验就是服务器接收到浏览器的请求后,先判断是否已经登录,如果已经登录,就执行对应的业务需求,否则就给前端返回一个错误信息。
登录校验的实现思路:在服务端设置统一拦截,拦截到浏览器的请求后根据请求头获取之前的登录信息,再进行相应的登录校验。
登录校验需要两个技术:
- 会话技术
- 统一拦截技术
统一拦截技术有两种:
- Servlet规范中的Filter过滤器
- Spring提供的interceptor拦截器
8.1.1 会话技术
8.1.1.1 概述
会话:指的是浏览器与服务器之间的一次连接,我们就称为一次会话,如下图有三个浏览器,就有三个会话:
- 一次会话可以包含多次请求和响应
- 会话的一方连接断开,整个会话就结束
会话跟踪:一种维护浏览器状态的方法,服务器需要识别多次请求是否来自于同一浏览器,以便在同一次会话的多次请求间共享数据,例如上图的1和3是否属于同一会话(是),3和5是否属于同一会话(否)。
共享数据:HTTP协议是无状态协议,需要共享数据记录上一次请求的内容,进行登录校验。
8.1.1.2 会话跟踪方案
方案一 :Cookie:
cookie 是客户端会话跟踪技术,它是存储在客户端浏览器的。被HTTP协议支持自带。
当浏览器第一次请求了登录接口,登录接口执行完成之后就可以设置一个cookie,在 cookie 当中我们存储用户相关的一些数据信息。
三个自动:
-
服务器会 自动 的将 cookie 响应给浏览器。
-
浏览器接收到响应回来的数据之后,会 自动 的将 cookie 存储在浏览器本地。
-
在后续的请求当中,浏览器会 自动 的将 cookie 携带到服务器端。
代码测试:
@Slf4j
@RestController
public class SessionController {
//设置Cookie
@GetMapping("/c1")
public Result cookie1(HttpServletResponse response){
response.addCookie(new Cookie("login_username","itheima")); //设置Cookie/响应Cookie
return Result.success();
}
//获取Cookie
@GetMapping("/c2")
public Result cookie2(HttpServletRequest request){
Cookie[] cookies = request.getCookies();
for (Cookie cookie : cookies) {
if(cookie.getName().equals("login_username")){
System.out.println("login_username: "+cookie.getValue()); //输出name为login_username的cookie
}
}
return Result.success();
}
}
打开浏览器,访问c1接口,http://localhost:8080/c1:
访问c2接口 http://localhost:8080/c2,此时浏览器会自动将Cookie携带到服务端,是通过请求头Cookie携带的:
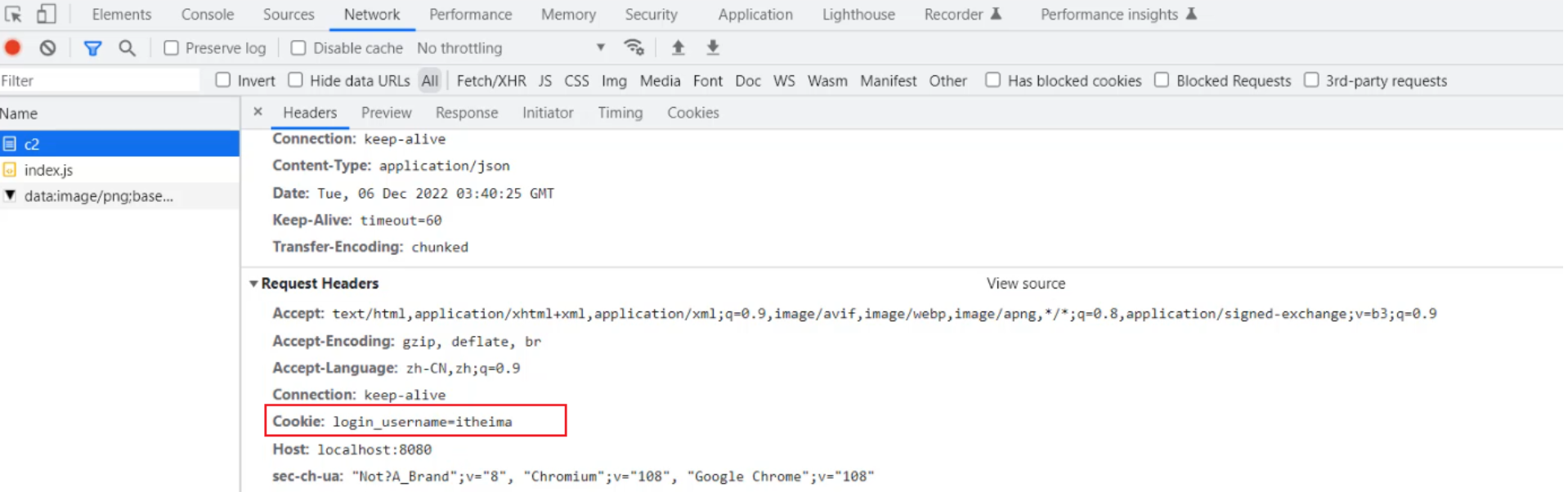
- 优点:HTTP协议中支持的技术
- 缺点:
- 移动端APP(Android、IOS)中无法使用Cookie
- 不安全,用户可以自己禁用Cookie
- Cookie不能跨域
跨域介绍:
前后端分离开发中,前端部署在一台服务器上(假设是192.168.150.200),后端部署在另一台服务器上(假设是192.168.150.100)上,打开浏览器直接访问前端工程http://192.168.150.200/login.html,在该页面发起请求到服务端http://192.168.150.100:8080/login 接口,此时就会出现跨域:
区分跨域的维度:
- 协议
- IP/协议
- 端口
只要上述的三个维度有任何一个维度不同,那就是跨域操作
方案二 :Session:
Session:服务器端会话跟踪技术,存储在服务器端,底层是通过Cookie实现。
浏览器第一次请求服务器,服务器会创建一个Session对象,每个Session对象都有一个ID,响应数据时,服务器将Session 的 ID 通过 Cookie 响应给浏览器,浏览器自动识别这个ID并存储在浏览器本地,之后每一次请求都会将Cookie 的数据携带到服务端,服务端拿到这个ID就会从众多JSESSIONID中找到当前请求对应的JSESSIONID,从而实现数据共享。
代码测试:
@Slf4j
@RestController
public class SessionController {
@GetMapping("/s1")
public Result session1(HttpSession session){
log.info("HttpSession-s1: {}", session.hashCode());
session.setAttribute("loginUser", "tom"); //往session中存储数据
return Result.success();
}
@GetMapping("/s2")
public Result session2(HttpServletRequest request){
HttpSession session = request.getSession();
log.info("HttpSession-s2: {}", session.hashCode());
Object loginUser = session.getAttribute("loginUser"); //从session中获取数据
log.info("loginUser: {}", loginUser);
return Result.success(loginUser);
}
}
访问 s1 接口,http://localhost:8080/s1,就可以通过Set-Cookie看到JSESSIONID:
访问 s2 接口,http://localhost:8080/s2,就可以通过Cookie看到Session数据:
- 优点:Session是存储在服务端的,安全
- 缺点:
- 服务器集群环境下无法直接使用Session
- 移动端APP(Android、IOS)中无法使用Cookie
- 用户可以自己禁用Cookie
- Cookie不能跨域
Session 底层是基于Cookie实现的会话跟踪,如果Cookie不可用,则该方案也就失效了
集群环境为何无法使用Session?
在企业开发中,最终部署时会采用集群部署,即同一个项目部署在多个服务器中,用户访问时,会先访问到负载均衡服务器(将前端发起的请求均匀的分发给后面的这三台服务器)。假如通过 session 进行会话跟踪,若第一次分发到第一台服务器,第二次分发到第二台服务器,这时第二台服务器中没有对应Session对象,就会重新构建一个会话对象,这样两次请求就不是同一个会话。
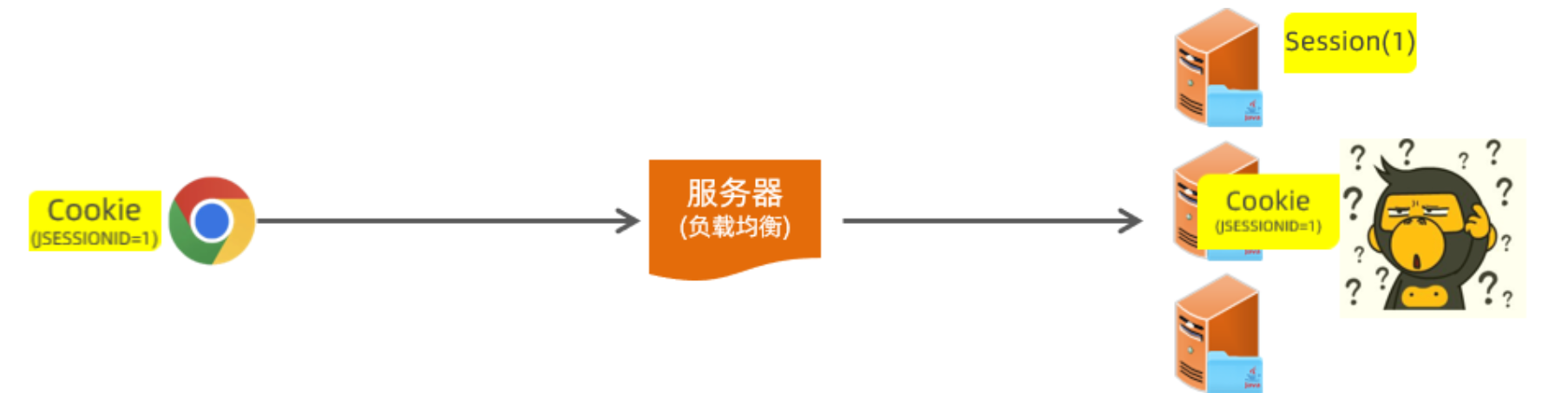
方案三:令牌技术(最常用):
令牌:用户的一个身份凭证,在请求登录接口时,如果登录成功,就会生成一个令牌,将这个令牌响应给前端。
前端接收到令牌后会将令牌存储在cookie 中(也可以存储在其他空间如 localStorage)。后续每一次请求都会将令牌携带到服务端,服务端校验令牌的有效性。如果令牌有效就说明用户已经登录,否则就说明用户未登录。
共享数据可以存放在令牌中
- 优点:
- 支持PC端、移动端
- 解决集群环境下的认证问题
- 减轻服务器的存储压力(无需在服务器端存储)
- 缺点:需要自己实现(包括令牌的生成、令牌的传递、令牌的校验)
8.1.2 JWT令牌
定义了一种简洁的、自包含的格式,用于在通信双方以json数据格式安全的传输信息。由于数字签名的存在,这些信息是可靠的。
简洁:是指jwt就是一个简单的字符串。可以在请求参数或者是请求头当中直接传递。
自包含:指的是jwt令牌,看似是一个随机的字符串,但是可以根据自身的需求在jwt令牌中存储自定义的数据内容。如:可以直接在jwt令牌中存储用户的相关信息。
8.1.2.1 JWT的组成
三个部分之间使用英文的点来分割:
-
第一部分:Header(头), 记录令牌类型、签名算法等。 例如:{“alg”:“HS256”,“type”:“JWT”}
-
第二部分:Payload(有效载荷),携带一些自定义信息、默认信息等。 例如:{“id”:“1”,“username”:“Tom”}
-
第三部分:Signature(签名),防止Token被篡改、确保安全性。将header、payload,并加入指定秘钥,通过指定签名算法计算而来。
一旦jwt令牌当中任何一个部分、任何一个字符被篡改了,整个令牌在校验的时候都会失败,这正是签名保证的。

JWT是如何将原始的JSON格式数据,转变为字符串的呢?
通过base64编码方式进行编码。
Base64:一种基于64个可打印的字符来表示二进制数据的编码方式。64个字符分别是A到Z、a到z、 0- 9,一个加号,一个斜杠,加起来就是64个字符。任何数据经过base64编码之后,最终就会通过这64个字符来表示。当然还有一个符号,那就是等号。等号它是一个补位的符号。
8.1.2.2 生成和校验
引入JWT的依赖(提供工具类Jwts进行JWT的生成和校验):
<!-- JWT依赖-->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.1</version>
</dependency>
- 生成JWT代码实现:
@Test
public void genJwt(){
Map<String,Object> claims = new HashMap<>();
claims.put("id",1);
claims.put("username","Tom");
String jwt = Jwts.builder()
.setClaims(claims) //自定义内容(载荷),需要一个Map集合
.signWith(SignatureAlgorithm.HS256, "itheima") //签名算法
.setExpiration(new Date(System.currentTimeMillis() + 24*3600*1000)) //有效期,需要一个date对象
.compact();
System.out.println(jwt);
}
运行后打开JWT的官网https://jwt.io/,将生成的令牌直接放在Encoded位置,此时就会自动的将令牌解析出来
第三部分由于是有签名算法得出来的,所以不会解码。
- 解析生成的令牌代码实现:
@Test
public void parseJwt(){
Claims claims = Jwts.parser()
.setSigningKey("itheima")//指定签名密钥(必须保证和生成令牌时使用相同的签名密钥)
.parseClaimsJws("eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MSwiZXhwIjoxNjcyNzI5NzMwfQ.fHi0Ub8npbyt71UqLXDdLyipptLgxBUg_mSuGJtXtBk")
.getBody();
System.out.println(claims);
}
运行测试方法,得到{id=1, exp=1672729730}。
注意事项:
-
JWT校验时使用的签名秘钥,必须和生成JWT令牌时使用的秘钥是配套的。
-
如果JWT令牌解析校验时报错,则说明 JWT令牌被篡改 或 失效了,令牌非法。
8.1.3 过滤器Filter
Filter:过滤器, JavaWeb三大组件(Servlet、Filter、Listener)之一,可以把资源的请求拦截下来,从而实现一些特殊的功能,如登录校验、统一编码处理、敏感字符处理等。
8.1.3.1 快速入门
- 第1步,定义过滤器 :1.定义一个类,实现 Filter 接口,并重写其所有方法。
- 第2步,配置过滤器:Filter类上加 @WebFilter 注解,配置拦截资源的路径。引导类上加 @ServletComponentScan 开启Servlet组件支持。
定义过滤器:
//定义一个类,实现一个标准的Filter过滤器的接口
@WebFilter(urlPatterns = "/*") //配置过滤器要拦截的请求路径( /* 表示拦截浏览器的所有请求 )
public class DemoFilter implements Filter { //jakarta.servlet包下
@Override //初始化方法, 只调用一次
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("init 初始化方法执行了");
}
@Override //拦截到请求之后调用, 调用多次
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
System.out.println("Demo 拦截到了请求...放行前逻辑");
//放行
chain.doFilter(request,response);
}
@Override //销毁方法, 只调用一次
public void destroy() {
System.out.println("destroy 销毁方法执行了");
}
}
init方法:初始化方法。web服务器启动时自动创建Filter过滤器对象,创建过滤器对象时自动调用init初始化方法,只会被调用一次。
doFilter方法:每一次拦截到请求之后都会被调用,所以会被调用多次,每拦截一次就调用一次。
destroy方法: 销毁方法。关闭服务器时会自动调用destroy,只会被调用一次。
在启动类上添加注解@ServletComponentScan开启SpringBoot项目对Servlet组件的支持:
@ServletComponentScan
@SpringBootApplication
public class TliasWebManagementApplication {
public static void main(String[] args) {
SpringApplication.run(TliasWebManagementApplication.class, args);
}
}
在浏览器请求一个路径,控制台可以看到相关信息就表示成功。
在过滤器Filter中,如果不执行放行操作,将无法访问后面的资源。 放行操作:chain.doFilter(request, response);
8.1.3.2 Filter详解
执行流程:
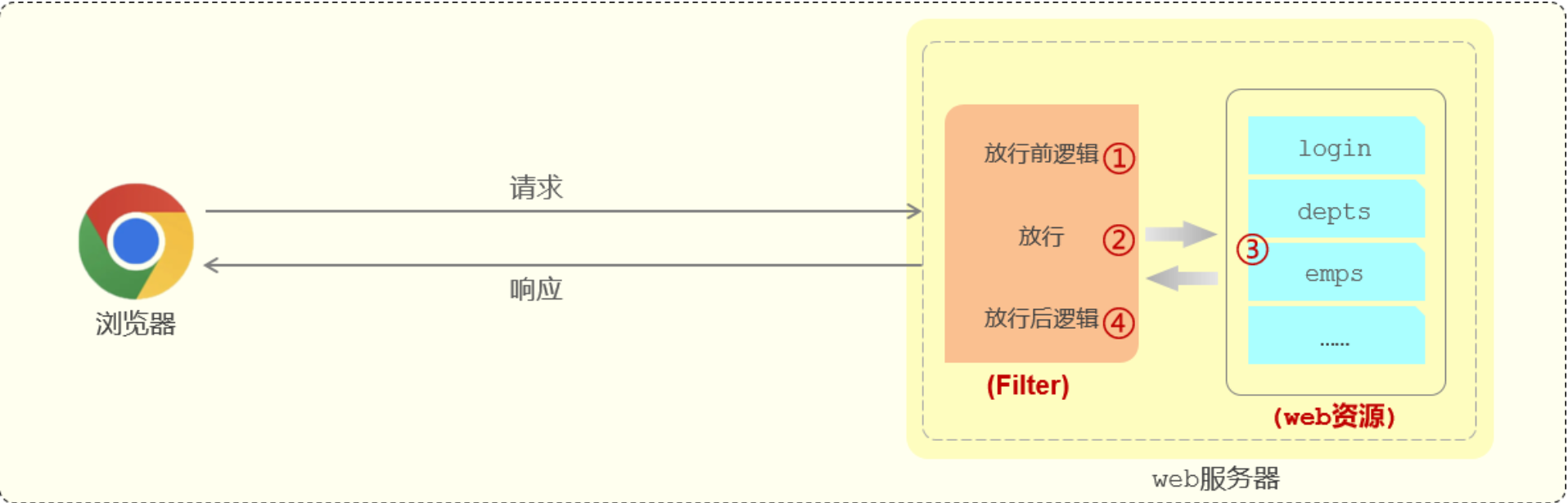
当拦截到一个请求后,要有FilterChain对象当中的doFilter()方法放行,放行后执行相应的逻辑,逻辑执行完毕后会到doFilter方法中执行放行后的逻辑,如果放行后没有逻辑,就结束方法响应。
拦截路径:
| 拦截路径 | urlPatterns值 | 含义 |
|---|---|---|
| 拦截具体路径 | /login | 只有访问 /login 路径时,才会被拦截 |
| 目录拦截 | /emps/* | 访问/emps下的所有资源,都会被拦截 |
| 拦截所有 | /* | 访问所有资源,都会被拦截 |
过滤器链:
在一个web应用程序当中,可以配置多个过滤器,多个过滤器就形成了一个过滤器链:
接收到请求后,先执行Filter1的放行前逻辑和放行,放行后进入Fileter2拦截器,执行相应逻辑后放行,执行完路径的逻辑后先返回到Filter2逻辑中,Filter2中剩余逻辑执行完毕后再执行Filter1中的逻辑。
以注解方式配置的Filter过滤器执行优先级是按过滤器的类名自动排序确定的,类名排名越靠前,优先级越高,例如AFilter和BFilter会先执行AFilter。
8.1.4 拦截器Interceptor
拦截器:Spring框架中提供的一种动态拦截方法调用的机制,类似于过滤器。
拦截器会拦截前端的请求,判断用户是否有JWT令牌且令牌是否合法,再决定是放行还是执行其他操作。
8.1.4.1 快速入门
自定义拦截器:
实现HandlerInterceptor接口,并重写其所有方法
//自定义拦截器
@Component
public class LoginCheckInterceptor implements HandlerInterceptor {
//目标资源方法执行前执行。 返回true:放行 返回false:不放行
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("preHandle .... ");
return true; //true表示放行
}
//目标资源方法执行后执行
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("postHandle ... ");
}
//视图渲染完毕后执行,最后执行
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("afterCompletion .... ");
}
}
preHandle方法:目标资源方法执行前执行。 返回true:放行 返回false:不放行
postHandle方法:目标资源方法执行后执行,请求资源执行完毕后执行
afterCompletion方法:视图渲染完毕后执行,最后执行
注册配置拦截器:
实现WebMvcConfigurer接口,并重写addInterceptors方法
@Configuration
public class WebConfig implements WebMvcConfigurer {
//自定义的拦截器对象
@Autowired
private LoginCheckInterceptor loginCheckInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
//注册自定义拦截器对象
registry.addInterceptor(loginCheckInterceptor).addPathPatterns("/**");//设置拦截器拦截的请求路径( /** 表示拦截所有请求)
}
}
8.1.4.2 Interceptor详解
拦截路径
addPathPatterns("要拦截路径")指定要拦截哪些路径;excludePathPatterns("不拦截路径")指定哪些路径不需要拦截
| 拦截路径 | 含义 | 举例 |
|---|---|---|
| /* | 一级路径 | 能匹配/depts,/emps,/login,不能匹配 /depts/1 |
| /** | 任意级路径 | 能匹配/depts,/depts/1,/depts/1/2 |
| /depts/* | /depts下的一级路径 | 能匹配/depts/1,不能匹配/depts/1/2,/depts |
| /depts/** | /depts下的任意级路径 | 能匹配/depts,/depts/1,/depts/1/2,不能匹配/emps/1 |
执行流程
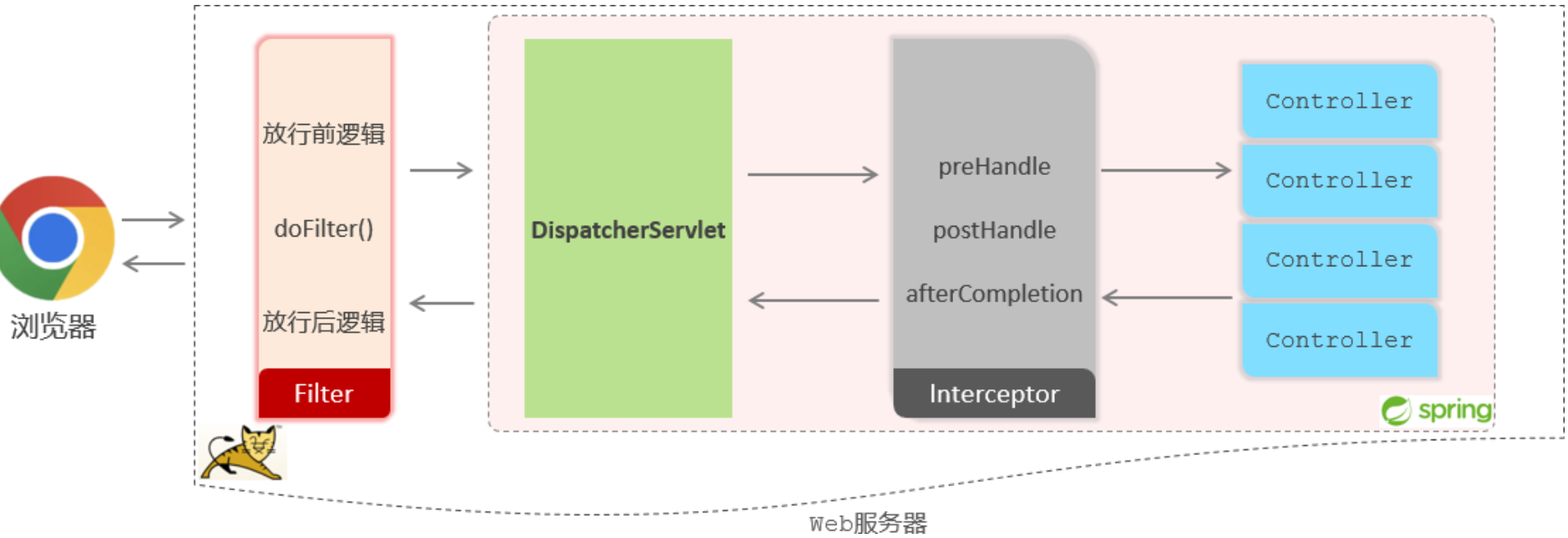
-
浏览器发送一个请求后,先被Filter过滤器拦截,Filter过滤器执行放行前逻辑并放行,此时进入Spring环境要访问controller
-
由于Tomcat识别Servlet而不识别controller,所以请求会先到DispatcherServlet(前端控制器),再将请求转给Controller
-
拦截器此时会拦截请求执行
preHandle()方法,如果返回true,就放行执行相关业务逻辑,执行后执行postHandle()方法和afterCompletion()方法,如果返回false,就不放行
返回false,
postHandle()方法不执行,但是afterCompletion()方法不受影响。
- 然后返回给DispatcherServlet,执行Filter中剩余内容,最后响应数据
过滤器和拦截器之间的区别
- 接口规范不同:过滤器需要实现Filter接口,而拦截器需要实现HandlerInterceptor接口。
- 拦截范围不同:过滤器Filter会拦截所有的资源,而Interceptor只会拦截Spring环境中的资源。
8.2 异常处理
当没有做任何异常处理时,三层架构处理异常的方案:
- Mapper接口出错了,此时异常会往上抛(谁调用Mapper就抛给谁),会抛给service。
- service 中也存在异常了,会抛给controller。
- 而在controller当中,没有做任何的异常处理,所以最终异常会再往上抛。最终抛给框架之后,框架就会返回一个JSON格式的数据,里面封装的就是错误的信息,但是框架返回的JSON格式的数据并不符合开发规范。
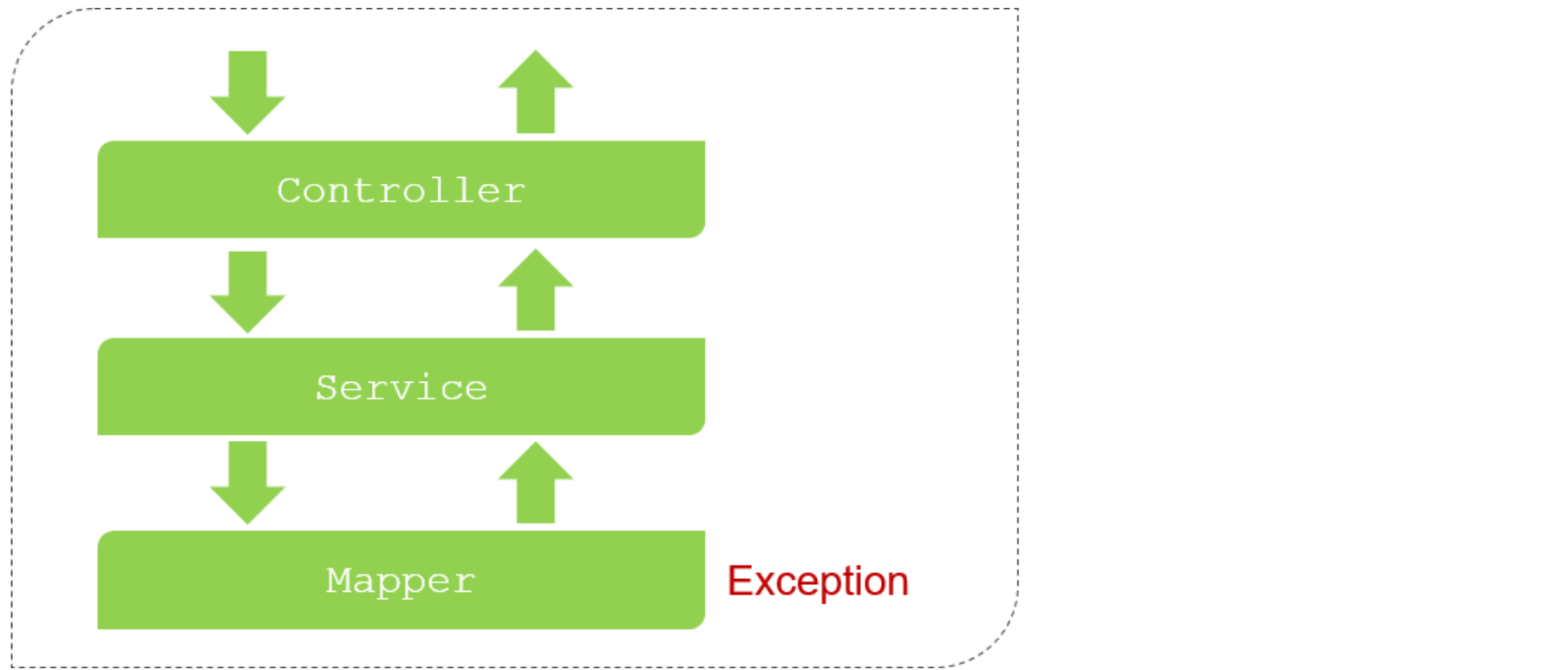
解决方案
- 方案一:在所有Controller的所有方法中进行try…catch处理
- 缺点:代码臃肿(不推荐)
- 方案二:全局异常处理器
- 好处:简单、优雅(推荐)
全局异常处理器
定义一个类,在类上加上@RestControllerAdvice注解表示定义一个全局异常处理器,然后在这个类中定义一个方法处理异常,方法加上@ExceptionHandler注解,并通过value属性指定捕获异常的类型:
@RestControllerAdvice
public class GlobalExceptionHandler {
//处理异常
@ExceptionHandler(Exception.class) //指定能够处理的异常类型
public Result ex(Exception e){
e.printStackTrace();//打印堆栈中的异常信息
//捕获到异常之后,响应一个标准的Result
return Result.error("对不起,操作失败,请联系管理员");
}
}
@RestControllerAdvice = @ControllerAdvice + @ResponseBody,处理异常的方法返回值会转换为json后再响应给前端
十五、事务&AOP
以后得案例均基于SpringBootWeb案例进行讲解,参考资料中的SpringBootWeb综合案例文件夹。
1.事务管理
1.1 Spring事务管理
事务:一组操作的集合,是一个不可分割的工作单位。所有操作要么全部成功,要么一个也不执行。
事务的操作主要有三步:
- 开启事务(一组操作开始前,开启事务):start transaction / begin ;
- 提交事务(这组操作全部成功后,提交事务):commit ;
- 回滚事务(中间任何一个操作出现异常,回滚事务):rollback ;
1.1.1 案例
解散部门:不仅删除部门,还要删除部门下的员工。
此时DeptServiceImpl的代码如下:
@Slf4j
@Service
public class DeptServiceImpl implements DeptService {
@Autowired
private DeptMapper deptMapper;
@Autowired
private EmpMapper empMapper;
//根据部门id,删除部门信息及部门下的所有员工
@Override
public void delete(Integer id){
//根据部门id删除部门信息
deptMapper.deleteById(id);
//模拟:异常发生
int i = 1/0;
//删除部门下的所有员工信息
empMapper.deleteByDeptId(id);
}
}
如果没有异常发生,结果正确,但是出现了异常ArithmeticException,所以删除员工的逻辑不会执行,出现不一致现象。
1.1.2 Transactional注解
@Transactional作用:在当前这个方法执行之前开启事务,方法执行完毕后提交事务。如果执行过程出现异常就回滚事务。
@Transactional注解书写位置:
- 方法:当前方法交给spring进行事务管理
- 类:当前类中所有的方法都交由spring进行事务管理
- 接口:接口下所有的实现类当中所有的方法都交给spring 进行事务管理
在使用@Transactional注解之前需要在配置文件中开启事务管理日志:
#spring事务管理日志
logging:
level:
org.springframework.jdbc.support.JdbcTransactionManager: debug
在案例中可以在delete方法上加上@Transactional注解解决数据不一致的现象。
1.2 事务进阶
@Transactional注解当中有两个常见的属性:
- 异常回滚的属性:rollbackFor
- 事务传播行为:propagation
1.2.1 rollbackFor
在Spring的事务管理中,默认只有运行时异常 RuntimeException才会回滚,如果是手动抛出的异常(throw new Exception),事务不会回滚,而是直接提交。
如果还需要回滚指定类型的异常,可以通过rollbackFor属性来指定。
@Override
@Transactional(rollbackFor=Exception.class)
public void delete(Integer id){
//根据部门id删除部门信息
deptMapper.deleteById(id);
//模拟:异常发生
if(true){
throw new Exception("出现异常了~~~");
}
//删除部门下的所有员工信息
empMapper.deleteByDeptId(id);
}
此时不论是RuntimeException还是手动抛出异常,都会进行回滚。
1.2.2 propagation
当一个事务方法被另一个事务方法调用,此时会出现事务的传播。例如,两个事务方法,A方法和B方法,在A方法当中又调用了B方法。

此时是事务B加入到事务A中还是新建一个事务B,就涉及到事务的传播行为,事务的传播行为由propagation属性决定:
| 属性值 | 含义 |
|---|---|
| REQUIRED | 【默认值】需要事务,有则加入,无则创建新事务 |
| REQUIRES_NEW | 需要新事务,无论有无,总是创建新事务 |
| SUPPORTS | 支持事务,有则加入,无则在无事务状态中运行 |
| NOT_SUPPORTED | 不支持事务,在无事务状态下运行,如果当前存在已有事务,则挂起当前事务 |
| MANDATORY | 必须有事务,否则抛异常 |
| NEVER | 必须没事务,否则抛异常 |
示例:
删除部门时,不论是否删除成功,都要记录日志到deptLog表中。
@Slf4j
@Service
//@Transactional //当前业务实现类中的所有的方法,都添加了spring事务管理机制
public class DeptServiceImpl implements DeptService {
@Autowired
private DeptMapper deptMapper;
@Autowired
private EmpMapper empMapper;
@Autowired
private DeptLogService deptLogService;
//根据部门id,删除部门信息及部门下的所有员工
@Override
@Log
@Transactional(rollbackFor = Exception.class)
public void delete(Integer id) throws Exception {
try {
//根据部门id删除部门信息
deptMapper.deleteById(id);
//模拟:异常
if(true){
throw new Exception("出现异常了~~~");
}
//删除部门下的所有员工信息
empMapper.deleteByDeptId(id);
}finally {
//不论是否有异常,最终都要执行的代码:记录日志
DeptLog deptLog = new DeptLog();
deptLog.setCreateTime(LocalDateTime.now());
deptLog.setDescription("执行了解散部门的操作,此时解散的是"+id+"号部门");
//调用其他业务类中的方法
deptLogService.insert(deptLog);
}
}
//省略其他代码...
}
当程序执行后,会有两个操作,即deleteById(删除部门)和insert(记录日志),deleteByDeptId(删除员工)永远执行不到,此时事务insert默认直接加入到事务delete中,所以遇到异常会直接回滚deleteById和insert,插入失败却没有记录日志。
可以在insert方法上添加@Transactional(propagation = Propagation.REQUIRES_NEW)控制事务的传递行为:
@Service
public class DeptLogServiceImpl implements DeptLogService {
@Autowired
private DeptLogMapper deptLogMapper;
@Transactional(propagation = Propagation.REQUIRES_NEW) //事务传播行为:不论是否有事务,都新建事务
@Override
public void insert(DeptLog deptLog) {
deptLogMapper.insert(deptLog);
}
}
REQUIRES_NEW表示会新建一个事务insert,即使delete中遇到异常,事务insert只要不出错,就能提交从而记录日志。
2.AOP基础
2.1 AOP概述
AOP:面向切面编程、面向方面编程,即面向指定的一个或多个方法的编程。
现在需要统计业务层所有方法的执行时间进行优化,如果在每个方法前后都记录时间,相减得到运行时间会非常繁琐,此时就可以使用AOP设计一个模版方法,方法运行前记录开始时间,方法运行后记录结束时间,中间运行原始业务方法:

例如当需要运行list方法时,不会立即执行list,而是跳转到模版方法中执行:
- 记录方法运行开始时间
- 运行原始的业务方法(那此时原始的业务方法,就是 list 方法)
- 记录方法运行结束时间,计算方法执行耗时
AOP是通过动态代理方式实现的
2.2 AOP快速入门
统计各个业务层方法执行耗时。
pom.xml
<!-- AOP依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
AOP程序:TimeAspect
@Component
@Aspect //当前类为切面类
@Slf4j
public class TimeAspect {
@Around("execution(* com.itheima.service.*.*(..))")
public Object recordTime(ProceedingJoinPoint pjp) throws Throwable {
//记录方法执行开始时间
long begin = System.currentTimeMillis();
//执行原始方法
Object result = pjp.proceed();
//记录方法执行结束时间
long end = System.currentTimeMillis();
//计算方法执行耗时
log.info(pjp.getSignature()+"执行耗时: {}毫秒",end-begin);
return result; //返回值为原有方法返回值
}
}
AOP常见运用场景:
- 记录系统的操作日志
- 权限控制
- 事务管理:Spring事务管理底层是通过AOP实现的,只要添加@Transactional注解,AOP程序会自动在原始方法运行前开启事务,在原始方法运行后提交或回滚事务。
2.3 AOP核心概念
1. 连接点:JoinPoint,可以被AOP控制的方法(暗含方法执行时的相关信息),入门程序当中所有业务方法都是连接点
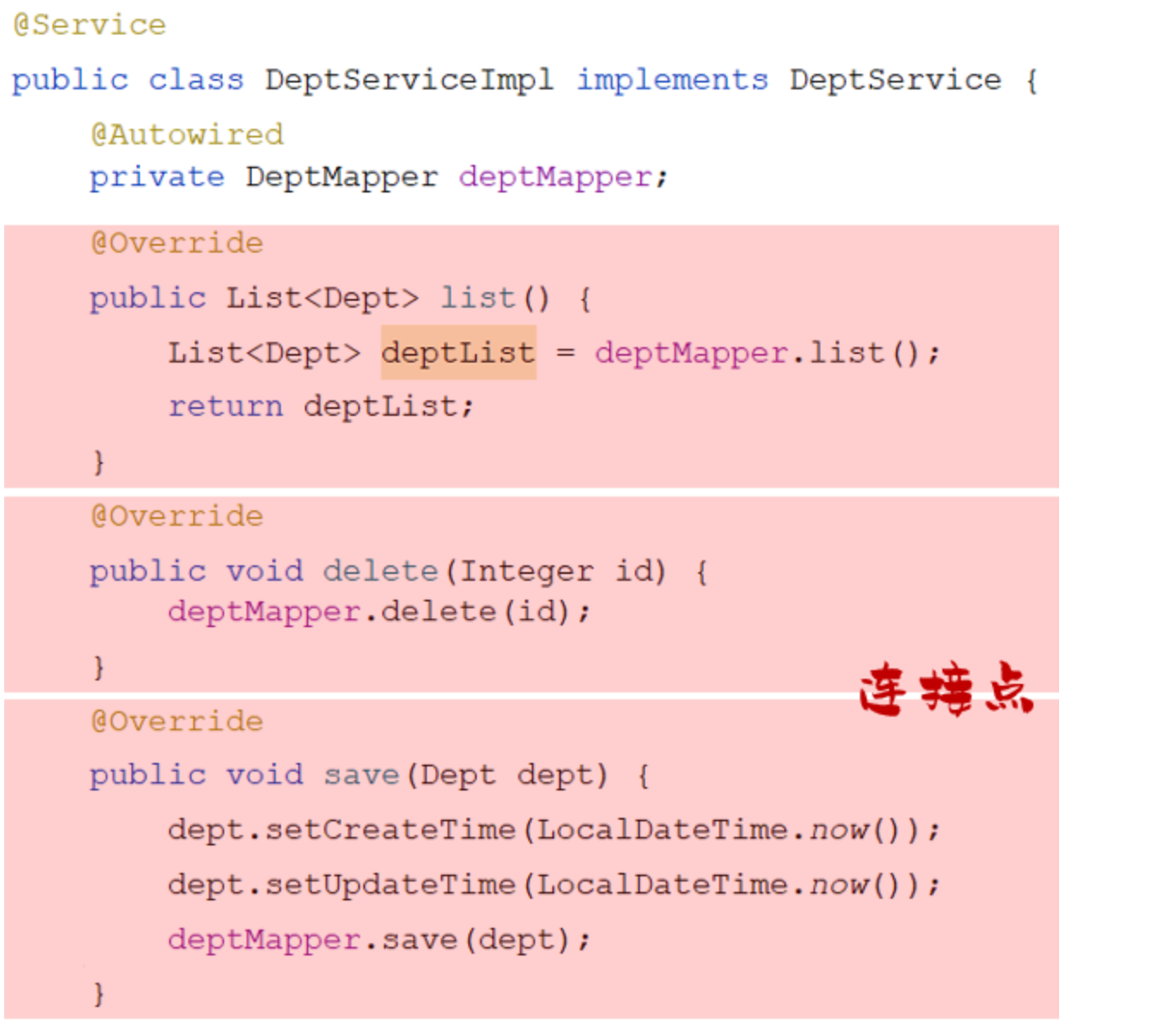
2. 通知:Advice,指哪些重复的逻辑,也就是共性功能(最终体现为一个方法)

3. 切入点:PointCut,匹配连接点的条件,通知仅会在切入点方法执行时被应用
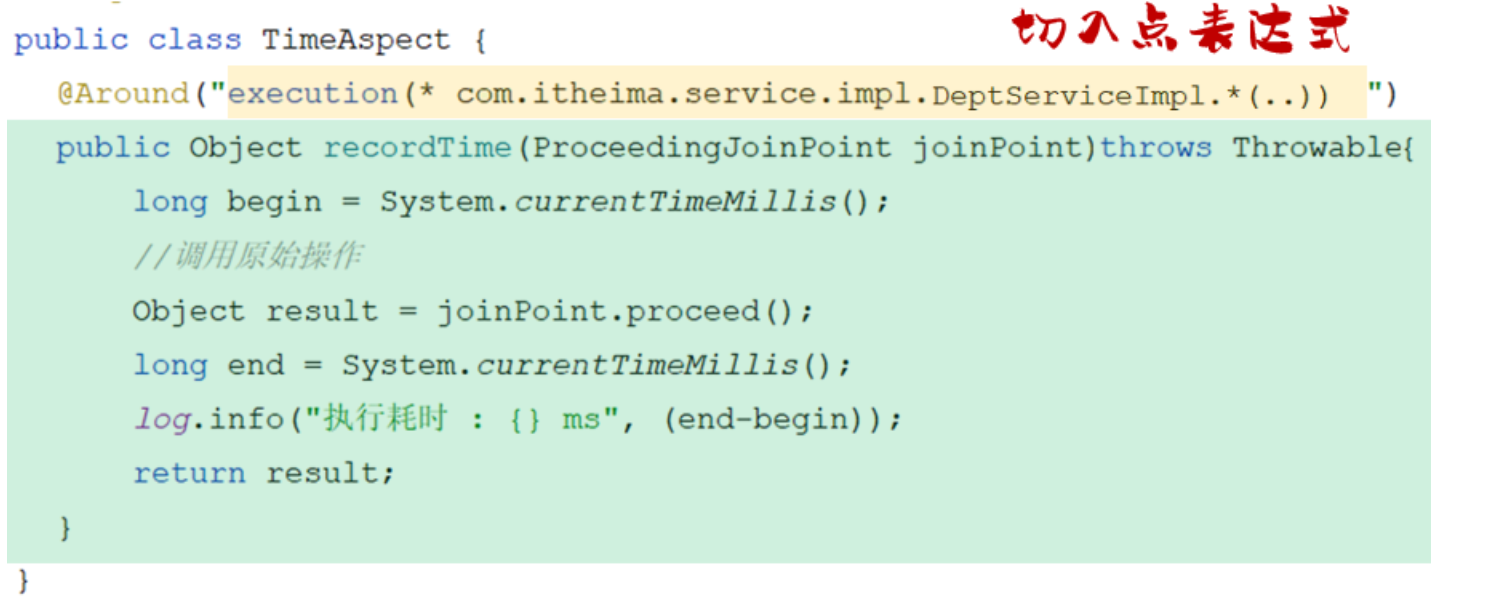
4. 切面:Aspect,描述通知与切入点的对应关系(通知+切入点)
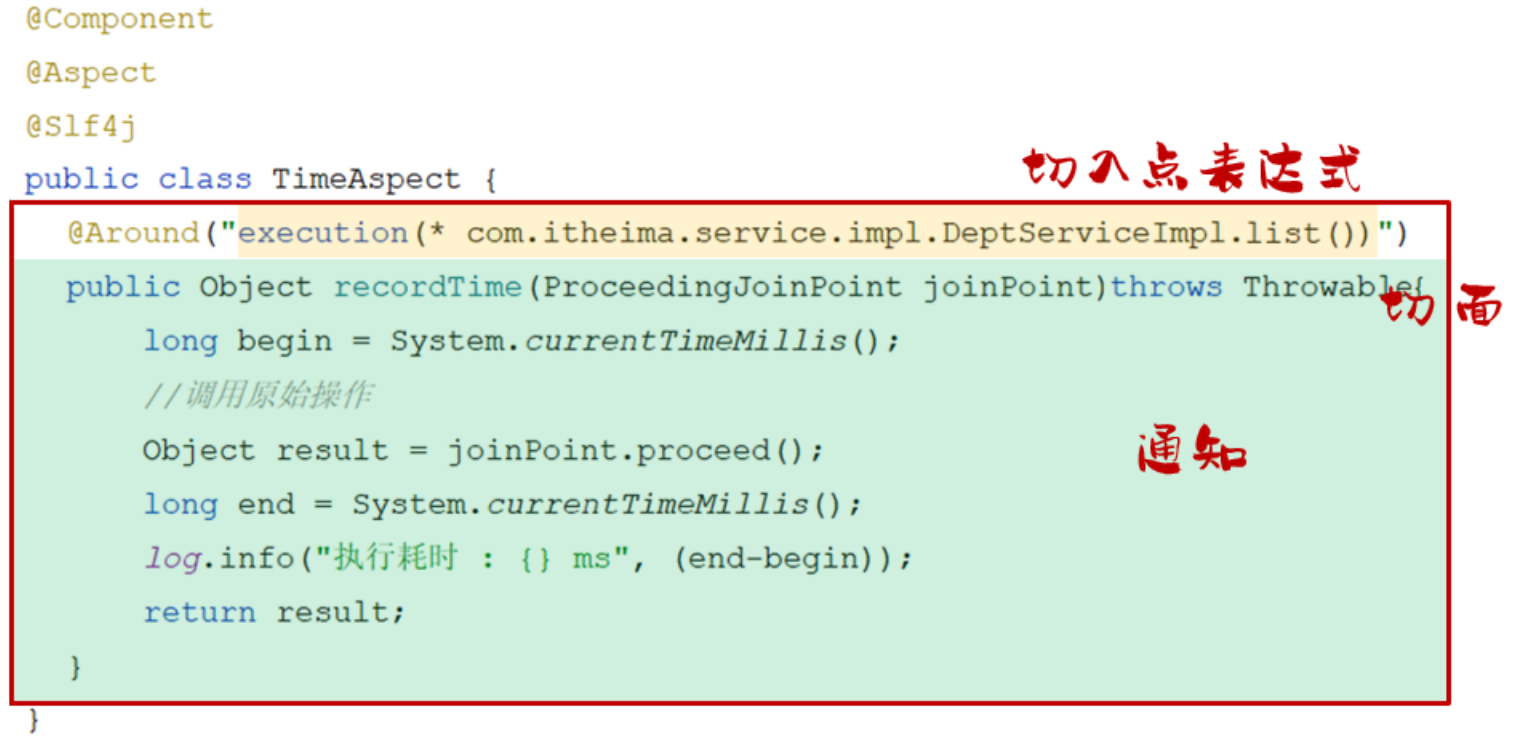
- 切面所在的类,我们一般称为切面类(被@Aspect注解标识的类)
5. 目标对象:Target,通知所应用的对象

通知是如何与目标对象结合在一起,对目标对象当中的方法进行功能增强的?

答:Spring的AOP底层是基于动态代理技术来实现的,即在程序运行的时候,会自动的基于动态代理技术为目标对象生成一个对应的代理对象。在代理对象当中就会对目标对象当中的原始方法进行功能的增强。
3.AOP进阶
3.1 通知类型
- @Around:环绕通知,此注解标注的通知方法在目标方法前、后都被执行
- @Before:前置通知,此注解标注的通知方法在目标方法前被执行
- @After :后置通知,此注解标注的通知方法在目标方法后被执行,无论是否有异常都会执行
- @AfterReturning : 返回后通知,此注解标注的通知方法在目标方法后被执行,有异常不会执行
- @AfterThrowing : 异常后通知,此注解标注的通知方法发生异常后执行
@Slf4j
@Component
@Aspect
public class MyAspect1 {
//切入点方法(公共的切入点表达式)
@Pointcut("execution(* com.itheima.service.*.*(..))")
private void pt(){
}
//前置通知(引用切入点)
@Before("pt()")
public void before(JoinPoint joinPoint){
log.info("before ...");
}
//环绕通知
@Around("pt()")
public Object around(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {
log.info("around before ...");
//调用目标对象的原始方法执行
Object result = proceedingJoinPoint.proceed();
//原始方法在执行时:发生异常
//后续代码不在执行
log.info("around after ...");
return result;
}
//后置通知
@After("pt()")
public void after(JoinPoint joinPoint){
log.info("after ...");
}
//返回后通知(程序在正常执行的情况下,会执行的后置通知)
@AfterReturning("pt()")
public void afterReturning(JoinPoint joinPoint){
log.info("afterReturning ...");
}
//异常通知(程序在出现异常的情况下,执行的后置通知)
@AfterThrowing("pt()")
public void afterThrowing(JoinPoint joinPoint){
log.info("afterThrowing ...");
}
}
切入点方法:将重复的切入点表达式抽取出来,放在自定义方法的注解@Pointcut上,需要使用时可以通过方法名调用,例如:
@Before("pt()")相当于@Before("execution(* com.itheima.service.*.*(..))")。如果要在其他类中使用pt()这个切入点表达式,需要使用
全类名.方法名()(权限修饰符要支持),例如:
@Before("com.itheima.aspect.MyAspect1.pt()")。
程序发生异常的情况下:
-
@AfterReturning标识的通知方法不会执行,@AfterThrowing标识的通知方法会执行
-
@Around环绕通知中原始方法调用时有异常,通知中的环绕后的代码逻辑也不会执行(因为原始方法调用已经出异常了)
使用通知时的注意事项:
- @Around环绕通知需要自己调用 ProceedingJoinPoint.proceed() 让原始方法执行,其他通知不需要考虑目标方法执行
- @Around环绕通知方法的返回值,必须指定为Object,来接收原始方法的返回值,否则原始方法执行完毕,是获取不到返回值的。
3.2 通知顺序
同一个切面类中,通知的执行顺序:
- 目标方法前的通知方法:@Around、@Before
- 目标方法后的通知方法:@AfterReturning | @AfterThrowing、@After、@Around
在不同切面类中,同类型通知默认按照切面类的类名字母排序:
- 目标方法前的通知方法:字母排名靠前的先执行
- 目标方法后的通知方法:字母排名靠前的后执行
如果我们想控制通知的执行顺序有两种方式:
- 修改切面类的类名(这种方式非常繁琐、而且不便管理)
- 使用Spring提供的@Order注解:例如
@Order(2)- 前置通知:数字越小先执行
- 后置通知:数字越小越后执行
3.3 切入点表达式
切入点表达式:描述切入点方法的一种表达式,主要用来决定项目中的哪些方法需要加入通知。
常见形式:
- execution(……):根据方法的签名来匹配
- @annotation(……) :根据注解匹配
3.3.1 execution
execution主要根据方法的返回值、包名、类名、方法名、方法参数等信息来匹配,语法为:
execution(访问修饰符? 返回值 包名.类名.?方法名(方法参数) throws 异常?)
其中带?的表示可以省略的部分
-
访问修饰符:可省略(比如: public、protected)
-
包名.类名: 可省略
-
throws 异常:可省略(注意是方法上声明抛出的异常,不是实际抛出的异常)
示例:
@Before("execution(void com.itheima.service.impl.DeptServiceImpl.delete(java.lang.Integer))")
可以使用通配符描述切入点:
-
*:单个独立的任意符号,可以通配任意返回值、包名、类名、方法名、任意类型的一个参数,也可以通配包、类、方法名的一部分 -
..:多个连续的任意符号,可以通配任意层级的包,或任意类型、任意个数的参数
切入点表达式示例:
//使用*代替包名(一层包使用一个*)
execution(* com.itheima.*.*.DeptServiceImpl.delete(java.lang.Integer))
//使用..省略包名
execution(* com..DeptServiceImpl.delete(java.lang.Integer))
//使用*代替方法名
execution(* com..*.*(java.lang.Integer))
//使用..省略参数
execution(* com..*.*(..))
//匹配DeptServiceImpl类中以find开头的方法
execution(* com.itheima.service.impl.DeptServiceImpl.find*(..))
根据业务需要,可以使用 且(&&)、或(||)、非(!) 来组合比较复杂的切入点表达式:
execution(* com.itheima.service.DeptService.list(..)) ||
execution(* com.itheima.service.DeptService.delete(..))
切入点表达式的书写建议:
- 所有业务方法名在命名时尽量规范,方便切入点表达式快速匹配。如:查询类方法都是 find 开头,更新类方法都是update开头
- 描述切入点方法通常基于接口描述,而不是直接描述实现类,增强拓展性
- 在满足业务需要的前提下,尽量缩小切入点的匹配范围。如:包名匹配尽量不使用 …,使用 * 匹配单个包
3.3.2 @annotation
execution切入点表达式用来匹配多个无规则的方法,通过自定义注解给目标方法添加上自定义注解,就可以通过注解方便的匹配。
实现步骤:
- 自定义注解MyLog
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface MyLog {
}
- 给需要匹配的方法加上注解@MyLog
- 切面类
@Slf4j
@Component
@Aspect
public class MyAspect6 {
//前置通知
@Before("@annotation(com.itheima.anno.MyLog)") //自定义注解的全类名
public void before(){
log.info("MyAspect6 -> before ...");
}
}
3.4 连接点
在Spring中用JoinPoint抽象了连接点,用它可以获得方法执行时的相关信息,如目标类名、方法名、方法参数等。
-
对于@Around通知,获取连接点信息只能使用ProceedingJoinPoint类型
-
对于其他四种通知,获取连接点信息只能使用JoinPoint,它是ProceedingJoinPoint的父类型
@Slf4j
@Aspect
@Component
public class MyAspect8 {
@Before("pt()")
public void before(JoinPoint joinPoint){
log.info("MyAspect8 ... before ...");
}
@Around("pt()")
public Object around(ProceedingJoinPoint joinPoint) throws Throwable {
log.info("MyAspect8 around before ...");
//1. 获取 目标对象的类名 .
String className = joinPoint.getTarget().getClass().getName();
log.info("目标对象的类名:{}", className);
//2. 获取 目标方法的方法名 .
String methodName = joinPoint.getSignature().getName();
log.info("目标方法的方法名: {}",methodName);
//3. 获取 目标方法运行时传入的参数 .
Object[] args = joinPoint.getArgs();
log.info("目标方法运行时传入的参数: {}", Arrays.toString(args));
//4. 放行 目标方法执行 .
Object result = joinPoint.proceed();
//5. 获取 目标方法运行的返回值 .
log.info("目标方法运行的返回值: {}",result);
log.info("MyAspect8 around after ...");
return result;
}
}
| 功能 | 实现 | 返回值类型 |
|---|---|---|
| 获取 目标对象的类名 | joinPoint.getTarget().getClass().getName() | String |
| 获取 目标方法的方法名 | joinPoint.getSignature().getName() | String |
| 获取 目标方法运行时传入的参数 | joinPoint.getArgs() | Object[] |
| 放行 目标方法执行 | joinPoint.proceed() | Object |
| 获取 目标方法运行的返回值 | joinPoint.proceed() | Object |
3.5 AOP案例
具体操作见资料中的SpringBootWeb综合案例。
说明:这篇笔记只是一个初步的第一版笔记哦,相应的配套资料可以下载黑马的资料,我也准备了一个飞书版本的文章,平时博主复习也是使用的飞书知识库进行复习,所以另一个版本的文章会更加完善,而且,另一个版本也有一些资料的提供(不是全部哦),如果你想要,点击链接https://mcnerzykwkel.feishu.cn/wiki/KIfZw5wKAi0rXjkKRDkcPc2onyf就可以了,如果你有更好的建议,直接在飞书内评论说明就可以咯,但是博主还是很自信不会有几个建议的😊。

















&spm=1001.2101.3001.5002&articleId=158385367&d=1&t=3&u=e5cfa7d69e574a48a27389c4a7e912a1)
 2217
2217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










