



很多人做 Agent,第一个版本看起来都很聪明。
用户问一句,它能答一句; 接一个工具,它能调用; 塞一点上下文,它也能分析。
但只要对话稍微长一点,问题马上暴露:
前面刚说过的要求,后面就忘了; 用户已经确认过的结论,下一轮又重新问; 今天聊过的偏好,明天打开又像第一次见面; 历史信息越塞越多,Prompt 越来越长,效果反而越来越不稳定。
这时候你会发现:
没有记忆系统的 Agent,本质上只是一个“会调用工具的聊天窗口”。
真正能落地的 Agent,一定要解决一个核心问题:
Agent 到底应该记住什么? 应该忘掉什么? 什么时候用短期记忆? 什么时候用长期记忆? 记错了、记重了、记过期了,又该怎么治理?
这也是大厂面试里非常高频的问题:
Agent 的记忆系统是什么?短期记忆和长期记忆方案怎么设计?
一、先给面试官一个标准答案
在工程落地里,我通常会把 Agent 的记忆系统拆成两层:
第一层是短期记忆。
短期记忆主要服务当前会话,用来保证当前任务不断片。常见方案包括:
-
最近 N 轮对话窗口
-
最近 N 个 token 截断
-
滚动摘要
-
当前任务状态缓存
-
工具调用结果缓存
它解决的是:
当前这轮对话里,Agent 不要前言不搭后语。
第二层是长期记忆。
长期记忆主要服务跨会话、跨任务的历史信息复用。常见方案包括:
-
用户画像 / 偏好存储
-
结构化数据库
-
向量数据库
-
文档记忆
-
图谱记忆
它解决的是:
用户下次再来,Agent 不要像第一次见面。
但真正的重点不在“存不存”,而在:
-
什么内容值得存?
-
存成什么结构?
-
什么时候召回?
-
召回多少?
-
旧记忆和新记忆冲突怎么办?
-
用户要求删除怎么办?
一句话总结:
短期记忆解决当前会话连贯性,长期记忆解决跨会话个性化和历史复用,记忆治理决定这个系统能不能长期稳定运行。
二、为什么 Agent 一定需要记忆系统?
很多人以为 Agent 只要有大模型、有工具调用、有工作流编排就够了。
但真实业务里,Agent 很少只是一次性问答。
比如一个测试开发助手,用户第一轮说:
这个项目是电商下单链路,核心接口包括登录、商品查询、购物车、提交订单、支付回调和订单状态查询。 测试方案要按业务风险分层,不要只按接口数量堆用例。
第十轮用户说:
那你帮我把这套接口自动化方案整理成评审文档。
如果没有记忆系统,Agent 可能已经忘了:
-
项目是电商下单链路
-
核心接口有哪些
-
用户要求按业务风险分层
-
前面已经确认过哪些高风险场景
-
哪些方案已经被用户否定过
-
自动化脚本需要考虑哪些环境约束
最后生成的内容可能看起来很完整,但完全不贴合当前任务。
这就是很多 Agent Demo 能演示、难落地的原因。
它不是不会回答,而是不会持续记住上下文。
三、Agent 记忆系统整体架构
一个比较完整的 Agent 记忆系统,可以抽象成下面这张图:
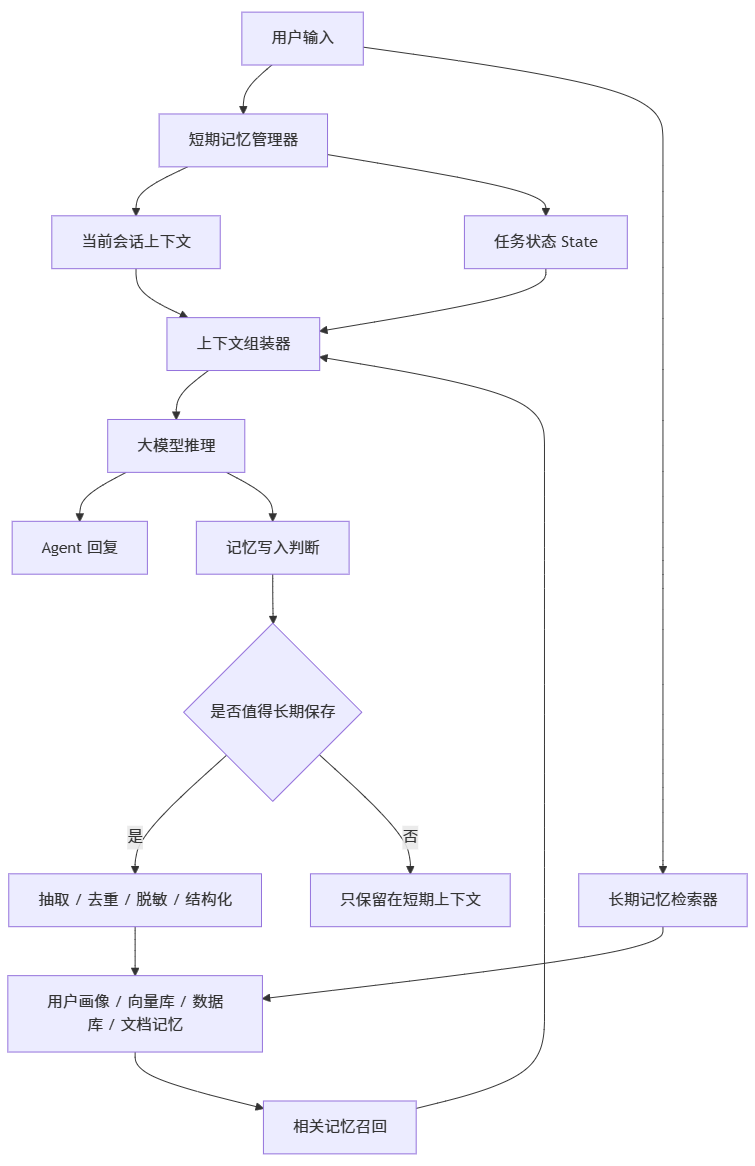
从工程视角看,记忆系统不是简单地“保存聊天记录”。
它至少包含五个模块:
|
模块 |
作用 |
核心问题 |
|---|---|---|
|
短期记忆管理 |
维护当前会话上下文 |
怎么不超 Prompt 长度 |
|
任务状态管理 |
保存当前任务进度 |
怎么避免任务断片 |
|
长期记忆存储 |
保存跨会话信息 |
什么内容值得长期存 |
|
记忆检索 |
找到相关历史信息 |
怎么召回准、不污染上下文 |
|
记忆治理 |
清理、合并、更新、删除 |
怎么避免记忆库变脏 |
面试时只说“用向量库存历史对话”是不够的。
更好的回答是:
记忆系统本质上是围绕上下文生命周期设计的一套工程能力,既要解决模型窗口限制,也要解决跨会话信息复用,还要考虑记忆准入、检索质量、冲突更新和用户可控。
四、短期记忆方案一:固定窗口截断
最简单的短期记忆方案,就是固定窗口截断。
比如:
-
只保留最近 10 轮对话
-
只保留最近 8000 个 token
-
超出窗口的历史内容直接丢弃
伪代码大概是这样:
def build_short_term_context(messages, max_rounds=10):
return messages[-max_rounds:]
或者按 token 控制:
def truncate_by_token(messages, max_tokens):
result = []
total_tokens = 0
for msg in reversed(messages):
token_count = count_tokens(msg["content"])
if total_tokens + token_count > max_tokens:
break
result.insert(0, msg)
total_tokens += token_count
return result
这种方案非常常见,尤其适合:
-
简单客服
-
闲聊机器人
-
单轮任务问答
-
信息价值衰减很快的场景
它的优点很明确:
|
优点 |
说明 |
|---|---|
|
实现简单 |
不需要复杂架构 |
|
成本低 |
不需要额外模型调用 |
|
长度稳定 |
Prompt 可控 |
|
响应快 |
没有额外摘要和检索成本 |
但它的问题也很明显:
固定窗口截断是一种“一刀切”的遗忘机制。
如果早期对话里有关键约束,被截掉之后,Agent 就会突然失忆。
比如用户一开始说:
这次接口自动化方案要优先覆盖订单主链路,不要只测接口返回 200。
如果对话很长,这句话被截掉了,Agent 后面可能又开始机械地罗列接口状态码校验。
再比如用户前面已经否定过一个方案:
不要依赖线上真实支付渠道,支付回调要用 Mock 服务模拟。
如果这句话被截断,Agent 后面又建议接入真实支付环境,就会显得非常不专业。
所以固定窗口截断适合简单场景,但不适合长任务和复杂协作。
五、短期记忆方案二:滚动摘要
滚动摘要是更适合长任务的方案。
核心思路是:
当对话历史快要超出窗口时,不直接丢掉早期内容,而是先把它压缩成摘要,再用摘要替代原始对话。
流程如下:
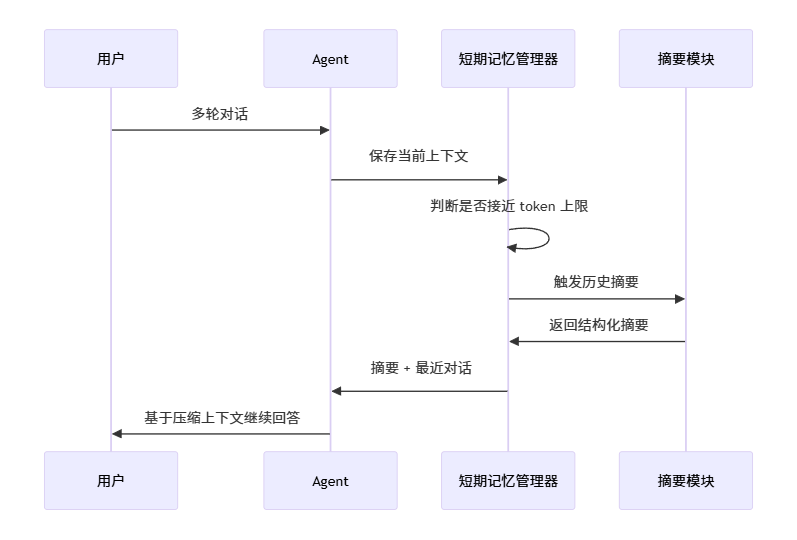
为了避免这个例子太抽象,我们用测试开发场景来看。
假设一个 Agent 正在协助测试团队设计电商下单链路的接口自动化方案。这个任务不是一问一答就能完成的,它会经历需求澄清、链路拆解、风险识别、用例设计、数据准备、脚本生成和结果复盘。
如果没有短期记忆,Agent 很容易在后续对话中忘记前面已经确认过的业务链路、风险优先级和测试约束。
这时,滚动摘要就可以把前面多轮对话压缩成一份结构化任务状态:
【任务目标】
用户正在让 Agent 协助设计一套电商下单流程的接口自动化测试方案。
【业务背景】
1. 核心链路包括:登录、浏览商品、加入购物车、提交订单、支付回调、订单状态查询。
2. 当前优先保障主流程稳定性,其次覆盖异常场景和边界条件。
3. 测试环境已经提供用户服务、商品服务、订单服务和支付模拟服务。
【用户要求】
1. 测试用例要按业务链路分层,不要只罗列接口。
2. 优先覆盖高风险场景,例如库存不足、重复下单、支付回调重复通知。
3. 输出内容要能直接给测试团队评审和落地执行。
4. 自动化脚本要考虑数据隔离、环境清理和接口依赖关系。
【已确认结论】
1. 下单主流程必须作为 P0 级用例优先覆盖。
2. 支付回调需要重点验证幂等性。
3. 库存扣减和订单状态流转属于高风险校验点。
4. 自动化执行前需要准备独立测试账号和测试商品数据。
【已否定方向】
1. 不要只测接口返回 200。
2. 不要把所有场景都堆在一个大用例里。
3. 不要依赖线上真实支付渠道。
这样即使原始对话被压缩,后续 Agent 仍然知道当前任务在做什么。
滚动摘要的优点是:
|
优点 |
说明 |
|---|---|
|
适合长任务 |
能保留关键上下文 |
|
降低 token 压力 |
历史内容被压缩 |
|
减少注意力稀释 |
无关细节被清理 |
|
保留任务状态 |
适合项目规划、测试方案设计、代码分析 |
但它也有代价:
第一,摘要需要额外模型调用,会增加成本和延迟。 第二,摘要质量会直接影响后续效果。 第三,如果摘要总结错了,后续模型会基于错误记忆继续推理。 第四,摘要经过多轮压缩后,可能出现信息损失和偏差累积。
所以滚动摘要最好不要只生成一段自然语言,而要尽量结构化。
推荐摘要格式:
- 当前任务:
- 业务背景:
- 用户要求:
- 关键约束:
- 已确认结论:
- 已否定方案:
- 当前进度:
- 后续待办:
这比一段泛泛而谈的总结更适合工程落地。
六、短期记忆不只是聊天记录,还包括任务状态
很多人理解短期记忆时,只想到多轮对话。
但在 Agent 系统里,短期记忆还包括任务状态。
比如一个代码生成 Agent,当前任务可能包含:
-
已读取哪些文件
-
已修改哪些文件
-
哪些测试已经运行
-
哪些错误还没解决
-
用户是否确认过某个方案
-
当前执行到了哪个步骤
-
下一步应该执行什么
这类状态如果只靠自然语言对话保存,很容易丢。
更工程化的做法是把短期记忆拆成几类:
|
类型 |
内容 |
存储方式 |
|---|---|---|
|
对话上下文 |
用户和 Agent 的多轮交流 |
messages |
|
任务状态 |
当前目标、步骤、结果、约束 |
state / JSON / Redis |
|
工具观察结果 |
工具调用返回的信息 |
tool observation |
|
临时计划 |
当前任务拆解和执行路径 |
plan / scratchpad |
例如:
{
"task_goal": "设计电商下单链路接口自动化测试方案",
"business_flow": [
"登录",
"商品查询",
"加入购物车",
"提交订单",
"支付回调",
"订单状态查询"
],
"risk_points": [
"库存不足",
"重复下单",
"支付回调重复通知",
"订单状态流转异常",
"优惠券核销失败"
],
"confirmed_points": [
"主流程作为 P0 用例优先覆盖",
"支付回调必须验证幂等性",
"自动化脚本必须考虑测试数据隔离"
],
"rejected_points": [
"不要只校验接口返回 200",
"不要依赖线上真实支付渠道",
"不要把所有场景堆到一个大用例里"
],
"next_action": "输出接口自动化测试方案评审稿"
}
这类结构化状态比自然语言更稳定,也更方便程序读取。
所以面试时可以补一句:
对复杂任务型 Agent 来说,短期记忆不能只依赖聊天历史,还要有结构化 task state,用来保存当前任务目标、执行进度、工具结果和关键约束。
这句话会比单纯讲“最近 N 轮对话”更工程化。
七、长期记忆:不是保存聊天记录,而是构建可复用记忆资产
短期记忆解决当前会话,长期记忆解决跨会话。
比如一个测试负责人多次要求:
我们团队设计自动化测试方案时,优先按业务风险分层,不要只按接口数量堆用例;核心链路必须先保障稳定性,再考虑低频边界场景。
如果这是一个长期稳定的团队测试规范,就值得写入长期记忆。
下次用户再让 Agent 设计测试方案时,Agent 不需要重新询问,就能自动按照“业务风险优先、核心链路优先、用例可落地”的方式来组织方案。
但长期记忆不是简单保存完整聊天记录。
更准确的流程应该是:

这里要注意一点:
向量库是长期记忆的常见实现,但不是唯一实现。
不同类型的记忆,适合不同存储方式。
|
记忆类型 |
示例 |
推荐存储方式 |
|---|---|---|
|
用户偏好 |
测试方案优先按风险分层 |
Profile / KV / 关系型数据库 |
|
历史对话片段 |
某次讨论过的接口测试细节 |
向量数据库 |
|
项目事实 |
系统技术栈、接口范围、测试环境 |
关系型数据库 / 文档库 |
|
业务关系 |
用户、订单、支付、库存之间的依赖关系 |
图数据库 |
|
长期任务文档 |
测试计划、复盘报告、质量规范 |
文件系统 / 文档库 |
|
可复用经验 |
某类故障对应的测试补强策略 |
向量库 + 元数据 |
所以长期记忆不是“把聊天记录向量化”这么简单。
更好的做法是:
先抽取高价值记忆,再根据记忆类型选择合适的存储方式。
八、长期记忆到底应该存什么?
长期记忆最大的坑,就是“什么都存”。
如果把所有聊天记录、临时讨论、一次性任务细节全部写进去,记忆库很快会变成垃圾场。
真正值得长期保存的信息,一般有四类。
|
类型 |
示例 |
是否适合长期保存 |
|---|---|---|
|
长期稳定偏好 |
团队要求测试方案按业务风险分层 |
适合 |
|
任务核心目标 |
团队正在建设接口自动化测试体系 |
适合 |
|
已确认事实 |
订单系统采用支付 Mock 服务做回调测试 |
适合 |
|
可复用结论 |
支付回调必须重点验证幂等性 |
适合 |
|
临时上下文 |
今天下午临时评审某个测试用例 |
不一定 |
|
一次性草稿 |
某次临时测试报告修改 |
通常不适合 |
|
敏感信息 |
密码、Token、生产账号、隐私数据 |
默认不应保存 |
一个简单的准入判断可以这样设计:
def should_write_memory(info):
if info.is_sensitive:
returnFalse
if info.is_temporary:
returnFalse
if info.confidence < 0.8:
returnFalse
if info.type in [
"long_term_preference",
"stable_fact",
"reusable_conclusion",
"project_goal"
]:
returnTrue
returnFalse
比如下面这条,就比较适合写入长期记忆:
{
"memory_type": "team_testing_preference",
"content": "该测试团队设计自动化测试方案时,优先按业务风险和核心链路分层,而不是简单按接口数量堆用例。",
"source": "conversation",
"created_at": "2026-06-27",
"confidence": 0.92
}
面试里可以这样回答:
长期记忆不应该默认写入所有历史,而应该通过记忆准入策略筛选,只保存稳定、明确、可复用、低风险的信息。对于临时信息、低置信度信息、敏感信息,默认不写入,或者需要用户明确确认。
这句话非常关键。
因为它能体现你不是只会堆向量库,而是考虑了真实系统里的数据质量和风险控制。
九、长期记忆检索不能只讲 TopK
很多人讲长期记忆,会说:
用户提问后,向量检索 TopK,再塞回 Prompt。
这个答案只能算入门。
真实工程里,长期记忆检索至少要考虑六个问题。
1、相似度不等于相关性
用户问:
帮我设计订单接口自动化测试方案。
系统可能会召回很多历史接口文档、旧测试用例、缺陷记录。
但真正有价值的,不一定是所有历史材料本身,而是和当前任务直接相关的测试规范、核心链路、历史高频缺陷和团队约定。
例如系统可以召回:
-
团队要求测试方案优先按业务风险分层
-
核心链路必须优先覆盖登录、下单、支付、订单状态流转
-
支付回调需要重点验证幂等性
-
自动化脚本必须考虑测试数据隔离和环境清理
-
输出方案要能直接进入测试评审,而不是停留在概念设计
所以记忆需要分类:
-
preference:团队偏好
-
fact:事实信息
-
project:项目背景
-
decision:历史决策
-
constraint:限制条件
-
summary:历史摘要
检索时可以按类型加权:
score = semantic_score * 0.6 + type_weight * 0.2 + recency_score * 0.1 + confidence_score * 0.1
2、旧记忆可能已经过期
比如早期记忆里记录的是:
下单接口只需要校验订单创建成功。
后来团队在故障复盘中更新了要求:
下单接口除了校验订单创建成功,还必须校验库存扣减、优惠券核销、订单状态流转和消息通知是否一致。
如果长期记忆不更新,Agent 后续仍然只生成“订单创建成功”的基础用例,就会漏掉真正高风险的校验点。
所以记忆需要版本、时间戳和状态:
{
"content": "订单接口自动化测试需要同时校验订单创建、库存扣减、优惠券核销、订单状态流转和消息通知一致性。",
"status": "active",
"created_at": "2026-06-27",
"replaces": ["memory_1024"]
}
3、记忆之间可能冲突
例如:
-
旧记忆:团队接口自动化只要求覆盖主流程
-
新记忆:团队现在要求主流程、异常流程、幂等场景和数据一致性一起覆盖
系统不能简单都保留。
更合理的方式是标记旧记忆失效,或者把它限定到历史项目中,避免后续生成测试方案时继续按旧标准输出。
可以采用三种策略:
|
冲突类型 |
处理方式 |
|---|---|
|
新信息明确覆盖旧信息 |
标记旧记忆失效 |
|
新旧信息适用场景不同 |
按场景拆分 |
|
置信度不足 |
让用户确认 |
4、记忆需要权限过滤
企业场景尤其要注意。
比如一个企业 Agent 同时服务多个部门:
-
A 项目的测试策略不能被 B 项目随意召回
-
管理层的复盘结论不能被普通成员看到
-
用户个人偏好不能污染团队公共知识
-
生产环境账号、Token、密钥不能进入长期记忆
所以长期记忆检索前,必须先做权限过滤。
5、召回太多会污染上下文
长期记忆不是越多越好。
召回太多,会导致:
-
Prompt 变长
-
模型注意力分散
-
无关历史干扰当前任务
-
旧信息覆盖新信息
更合理的流程是:
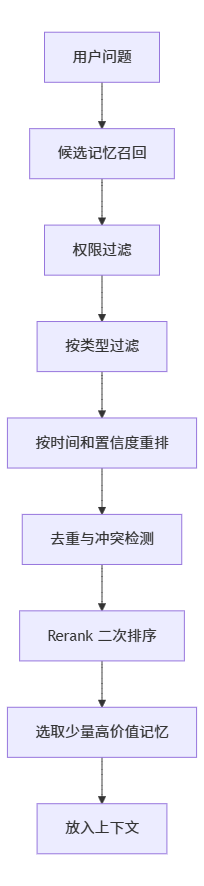
6、召回结果要可解释
尤其是企业场景,最好能知道:
-
这条记忆来自哪里
-
什么时候写入
-
为什么被召回
-
当前是否仍然有效
-
是否经过用户确认
否则一旦 Agent 基于错误记忆做出错误判断,很难排查问题。
十、记忆治理:长期记忆系统能不能跑稳,关键看这里
长期记忆不是一次写入就结束了。
它更像一类动态数据资产,需要持续治理。
否则系统运行一段时间后会出现几个问题:
-
重复记忆越来越多
-
过期信息没有清理
-
测试规范相互冲突
-
临时信息被错误保存
-
召回结果越来越不准
-
敏感信息带来安全风险
所以一个成熟的记忆系统,至少要设计四类策略。
1、Write Policy:什么内容可以写入?
写入前要判断:
-
是否长期稳定?
-
是否未来可复用?
-
是否已经明确确认?
-
是否涉及敏感信息?
-
是否已经存在相似记忆?
简单来说:
不是所有内容都值得成为长期记忆。
比如下面这些内容可以考虑写入:
-
团队长期采用的测试分层规范
-
项目的核心业务链路
-
反复出现的高风险缺陷类型
-
已确认的自动化环境约束
-
稳定复用的测试数据准备方式
但下面这些内容不建议默认写入:
-
一次性临时讨论
-
未确认的猜测
-
生产账号和密钥
-
临时测试数据
-
已经过期的接口文档结论
2、Read Policy:什么场景可以读取?
读取长期记忆时要判断:
-
当前问题是否需要历史记忆?
-
记忆是否和当前任务相关?
-
用户是否有权限访问?
-
记忆是否仍然有效?
-
召回数量是否会污染上下文?
比如用户只是问一个通用技术问题,不一定需要读取团队历史记忆。
但用户说:
按我们团队之前的规范,帮我设计订单接口自动化测试方案。
这就明显需要召回长期记忆。
3、Update Policy:新旧记忆冲突怎么办?
长期记忆必须支持更新。
常见策略包括:
-
新记忆覆盖旧记忆
-
按场景拆分记忆
-
降低旧记忆权重
-
标记旧记忆 inactive
-
让用户确认冲突项
例如:
{
"old_memory": "订单接口自动化只需要覆盖下单成功主流程",
"new_memory": "订单接口自动化需要同时覆盖主流程、库存不足、重复提交、支付回调幂等和订单状态一致性",
"action": "标记旧记忆为过期,新测试方案统一按高风险场景分层设计"
}
这样就不会粗暴地互相覆盖。
4、Delete Policy:什么内容应该删除?
长期记忆必须支持删除和清理。
包括:
-
用户主动要求删除
-
临时记忆过期
-
低置信度记忆长期不用
-
重复记忆合并后删除旧项
-
敏感信息误存后立即清除
尤其是用户可控非常重要。
用户应该可以:
-
查看记忆
-
修改记忆
-
删除记忆
-
关闭某类记忆
-
清空全部记忆
这不是产品细节,而是生产级 Agent 的基本能力。
面试里可以这样说:
长期记忆不是越多越好,而是越干净越好。记忆系统要有准入、更新、清理、合并、删除机制,否则后期检索质量会持续下降,甚至让 Agent 产生错误个性化。
十一、短期记忆和长期记忆怎么配合?
短期记忆和长期记忆不是互相替代,而是分工协作。
|
维度 |
短期记忆 |
长期记忆 |
|---|---|---|
|
作用范围 |
当前会话 |
跨会话、跨任务 |
|
保存内容 |
最近上下文、任务状态、工具结果 |
稳定偏好、重要事实、历史结论 |
|
典型技术 |
窗口截断、滚动摘要、状态缓存 |
Profile、向量库、数据库、文档库 |
|
生命周期 |
会话级 |
长期持续 |
|
核心风险 |
截断导致失忆 |
脏数据导致错误召回 |
|
设计重点 |
控制 Prompt 长度 |
控制记忆质量 |
一个比较合理的上下文组装顺序是:
System Prompt
↓
角色与安全约束
↓
相关长期记忆
↓
当前任务状态
↓
短期摘要
↓
最近几轮对话
↓
用户最新问题
为什么长期记忆不建议随便放太多?
因为长期记忆一旦放入上下文,就会影响模型判断。
所以要遵循一个原则:
宁可少放几条高置信度记忆,也不要塞一堆模糊相关的历史内容。
十二、面试官可能继续追问什么?
追问 1:长期记忆和 RAG 有什么区别?
可以这样回答:
RAG 通常面向外部知识库,比如文档、规范、FAQ、代码库。 长期记忆更偏用户维度和交互历史,比如团队偏好、历史决策、任务背景。
两者技术上都可能用 Embedding 和向量数据库,但数据来源和使用目标不同。
|
对比项 |
RAG 知识库 |
长期记忆 |
|---|---|---|
|
数据来源 |
文档、网页、知识库 |
对话、行为、用户反馈 |
|
目标 |
补充外部知识 |
保持个性化和连续性 |
|
更新方式 |
批量导入、定期同步 |
持续写入、动态更新 |
|
核心风险 |
文档过期、召回不准 |
记忆污染、隐私风险 |
一句话:
RAG 解决 Agent 知不知道,长期记忆解决 Agent 记不记得当前用户、团队和任务背景。
追问 2:为什么不能把所有历史对话都放进 Prompt?
因为会带来三个问题。
第一,成本高。 Prompt 越长,推理成本越高。
第二,效果不稳定。 长上下文会引入噪声,模型注意力容易被稀释。
第三,有风险。 过期信息、敏感信息、无关信息都可能影响模型输出。
所以正确做法不是全量塞上下文,而是:
短期内容摘要压缩,长期内容按需召回。
追问 3:如何判断一条记忆是否值得保存?
可以从四个维度判断:
|
维度 |
判断问题 |
|---|---|
|
稳定性 |
这个信息未来还会成立吗? |
|
复用性 |
后续任务会多次用到吗? |
|
置信度 |
这个信息是否明确、已确认? |
|
安全性 |
是否涉及隐私或敏感信息? |
只有同时满足“稳定、可复用、高置信、低风险”,才适合写入长期记忆。
追问 4:记忆召回不准怎么办?
可以从六个方向优化:
-
记忆切片不要太碎,也不要太长
-
记忆要带类型、时间、来源、置信度
-
检索前做权限过滤
-
检索后做 rerank
-
召回结果要去重
-
对冲突记忆做版本管理
追问 5:长期记忆如何防止越用越脏?
核心是记忆治理:
-
写入前做准入判断
-
写入时做结构化
-
检索时做过滤和重排
-
定期做合并和清理
-
用户可以查看和删除
-
敏感信息默认不保存
这也是区分“Demo Agent”和“生产级 Agent”的关键点。
十三、一个生产级记忆系统可以这样设计
如果让我设计一个企业级 Agent 记忆系统,我会拆成下面几层:
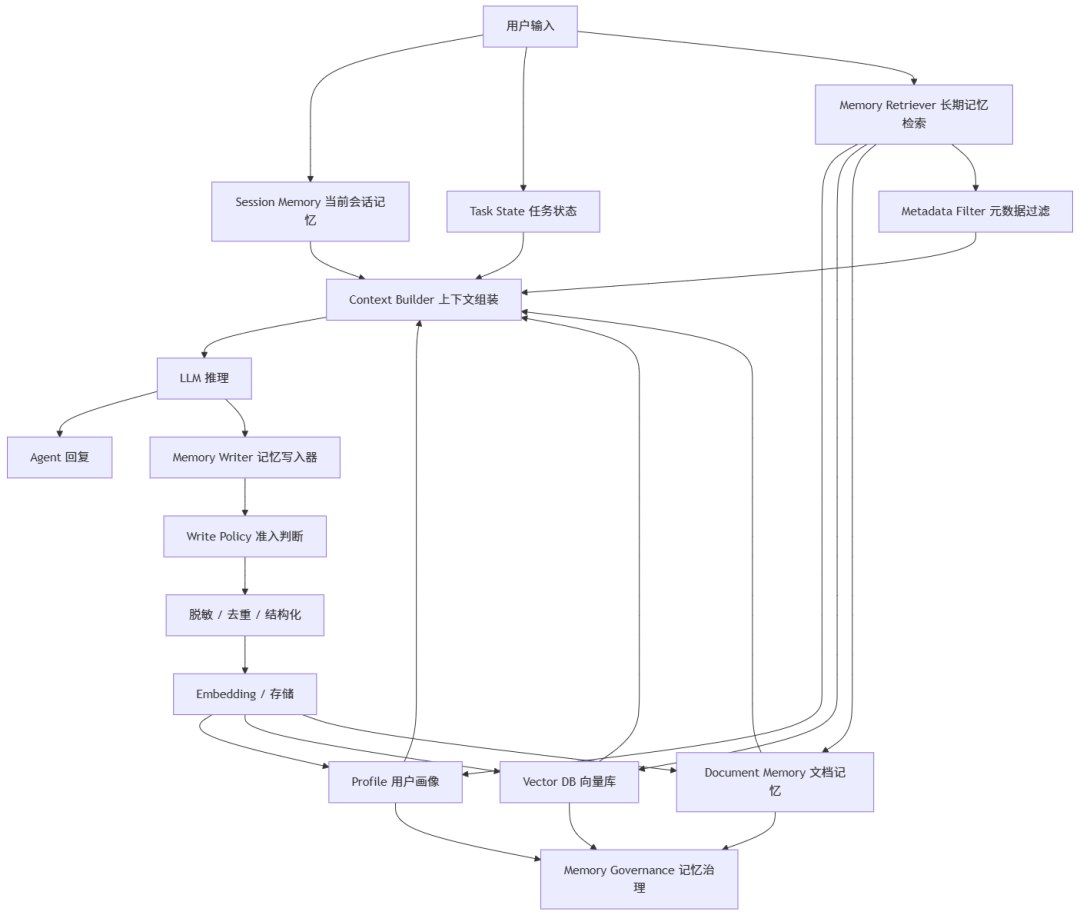
每层职责如下:
|
层级 |
设计重点 |
|---|---|
|
Session Memory |
保存当前会话最近上下文和滚动摘要 |
|
Task State |
保存结构化任务状态,避免任务断片 |
|
Memory Retriever |
按当前问题召回相关长期记忆 |
|
Context Builder |
控制放入 Prompt 的内容和顺序 |
|
Memory Writer |
判断哪些信息值得长期保存 |
|
Memory Governance |
清理、合并、更新、删除、审计 |
|
User Control |
允许用户管理自己的长期记忆 |
这套设计的核心思想是:
短期记忆负责“当前任务不断片”,长期记忆负责“历史经验可复用”,记忆治理负责“系统越用越干净”。
十四、面试回答可以这样收尾
如果面试官问:
Agent 的记忆系统怎么设计?
你可以这样回答:
在工程落地里,我会把 Agent 记忆拆成短期记忆和长期记忆两层。
短期记忆服务当前会话,主要解决上下文连续性和 Prompt 长度控制。简单场景可以用最近 N 轮对话或 token 窗口截断;复杂长任务可以用滚动摘要,把早期对话压缩成结构化摘要,同时保留最近几轮原始对话。如果是任务型 Agent,还要把当前目标、已完成步骤、已确认约束、工具调用结果做成结构化 task state,而不是完全依赖自然语言聊天记录。
长期记忆服务跨会话场景,通常会把用户偏好、重要事实、历史决策、可复用结论抽取成记忆片段。存储方式不一定只有向量库,也可以结合用户画像、关系型数据库、文档库、图数据库等。用户新提问时,系统先根据当前问题召回相关记忆,再结合类型、时间、置信度、权限做过滤和重排,最后只把少量高价值记忆放回上下文。
但我不会默认把所有对话都写入长期记忆。长期记忆必须有准入条件,只保存稳定、明确、可复用、低风险的信息。对于临时信息、敏感信息、低置信度信息,默认不写入,或者需要用户确认。
另外,长期记忆还需要治理机制,包括过期清理、重复合并、冲突更新、用户查看和删除权限。否则记忆库越用越脏,反而会影响 Agent 的输出质量。
所以我理解的 Agent 记忆系统,不只是保存历史记录,而是一套围绕上下文生命周期设计的工程能力。短期记忆保证当前对话不断片,长期记忆保证跨会话可复用,记忆治理保证系统长期稳定。
十五、最后总结
Agent 的记忆系统,不是一个可有可无的功能。
它决定了 Agent 能不能从“一次性问答工具”,变成真正能长期协作的智能助手。
短期记忆解决的是:
这一轮对话里,Agent 不能忘。
长期记忆解决的是:
下一次再见面,Agent 还记得关键背景。
记忆治理解决的是:
Agent 不能什么都记,更不能记错、记脏、记过期。
很多 Agent Demo 看起来很惊艳,但真正进入业务场景后,很快会卡在记忆系统上。
因为真实用户不会每次都从头解释背景,真实任务也不会永远停留在单轮问答。
尤其在测试开发场景里,一个 Agent 如果记不住业务链路、测试约束、历史缺陷和团队规范,就很难真正参与测试方案设计、用例生成、自动化脚本规划和质量复盘。
能把短期记忆、长期记忆和记忆治理讲清楚,基本就说明你已经不只是会用 Agent 框架,而是开始理解 Agent 系统工程了。
我是 霍格沃兹测试开发学社,持续分享优质 Agent 开发面试题和工程落地经验。

















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










