




“为什么这条 SQL 跑得这么慢?”——猎捕慢查询:执行计划的微观解析与索引调优实战

在过去的专栏里面,我们把数据库的安全问题搞了搞,像僵尸进程、行锁死锁,还有磁盘满的这些情况,都给处理了。那么数据库不经常挂了,也不报空间不够了,其实这只是说明,它算是在生产环境里面稳下来了而已。
不过呢,运维的日子没那么好过。系统稳了没几天,业务那边的人又开始叫了。“服务器也没挂啊,磁盘也还有空间,但是,我点一下前端页面的查询按钮,那个圈圈要转个 10 秒钟才能出结果。这是为啥啊?”
这个时候,你登到服务器上去看,就会发现一个很奇怪的情况。数据库连接数看起来挺正常的,死锁也没有。但是,CPU 使用率却一直下不来,长时间都在 90% 以上。
这个其实就是企业层级里的数据库运维里面,碰到最多、也是最看技术的情况了,那就是慢查询(Slow Query)把性能搞崩了。一条写得烂的 SQL,它不光是自己跑得慢。它还会把整台服务器的 CPU 和内存都给吃光。那么其他的正常业务也就跟着跑不动了。
作为搞数据库调优的人,我们肯定不能靠猜的,去猜哪里慢是不行的。这篇文章的话,就带你看看数据库查询优化器(Optimizer)它是怎么去算的。接着手把手教你用 EXPLAIN ANALYZE 这个很好用的诊断工具。我们会弄点真实的数据压测一下,看看执行计划到底长啥样。也就是看看,全表扫描和索引扫描到底有啥不一样。最后,我们再来聊聊,那些明明建了索引却不走索引的情况,到底该怎么避开这些坑。
文章目录
第一阶段:案发现场布置 —— 制造千万级数据的“性能怪兽”
在性能调优的世界里,数据量就是一切。一条全表扫描的 SQL,在 1 万条数据的开发环境里可能只需要 1 毫秒,但在 1000 万条数据的生产环境里可能会跑上几十分钟。
为了让今天的实战具有真实的生产级压迫感,我们首先要在你的测试库中,利用 ksql 瞬间制造一张拥有海量数据的测试表。
1. 一键生成百万级测试表
请打开你的 Win11 ksql 客户端,连入数据库,执行以下极速造数脚本:
-- 1. 创建一张模拟的用户交易流水表
CREATE TABLE opt_test_log (
log_id INT,
user_id INT,
action_type VARCHAR(50),
trade_amount NUMERIC(10, 2),
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 2. 疯狂注入 200 万条测试数据(执行可能需要十几秒到半分钟,请耐心等待)
INSERT INTO opt_test_log (log_id, user_id, action_type, trade_amount)
SELECT
i,
(random() * 100000)::INT, -- 随机生成 10万以内的用户ID
'PAYMENT',
(random() * 500)::NUMERIC(10, 2)
FROM generate_series(1, 2000000) AS i;
此时,你已经拥有了一张体积庞大、毫无优化的“原生态”千万级数据表。接下来,好戏开场。
第二阶段:猎物显形 —— EXPLAIN ANALYZE 执行计划的硬核解剖
假设业务同学写了这样一条 SQL:他想精确查询 log_id = 1500000(第 150 万号)的这条交易流水。
如果直接执行 SELECT * FROM opt_test_log WHERE log_id = 1500000;,你只会看到结果和漫长的等待时间,却不知道底层经历了什么。我们需要给这条 SQL 套上“X光机”——也就是 EXPLAIN ANALYZE 命令。
1. 裸奔的代价:全表扫描(Seq Scan)
在查询语句的最前面,加上 EXPLAIN ANALYZE:
EXPLAIN ANALYZE
SELECT * FROM opt_test_log WHERE log_id = 1500000;
2. 读懂“天书”:执行计划关键指标解析
屏幕上给你返回这么几行英文,新手一看,可能觉得像天书一样。那么,一个老手 DBA 跟新手的区别在哪儿呢?其实就在于能不能从这些信息里,快速地拎出来真正有用的东西。下面这三个指标,得盯紧了。
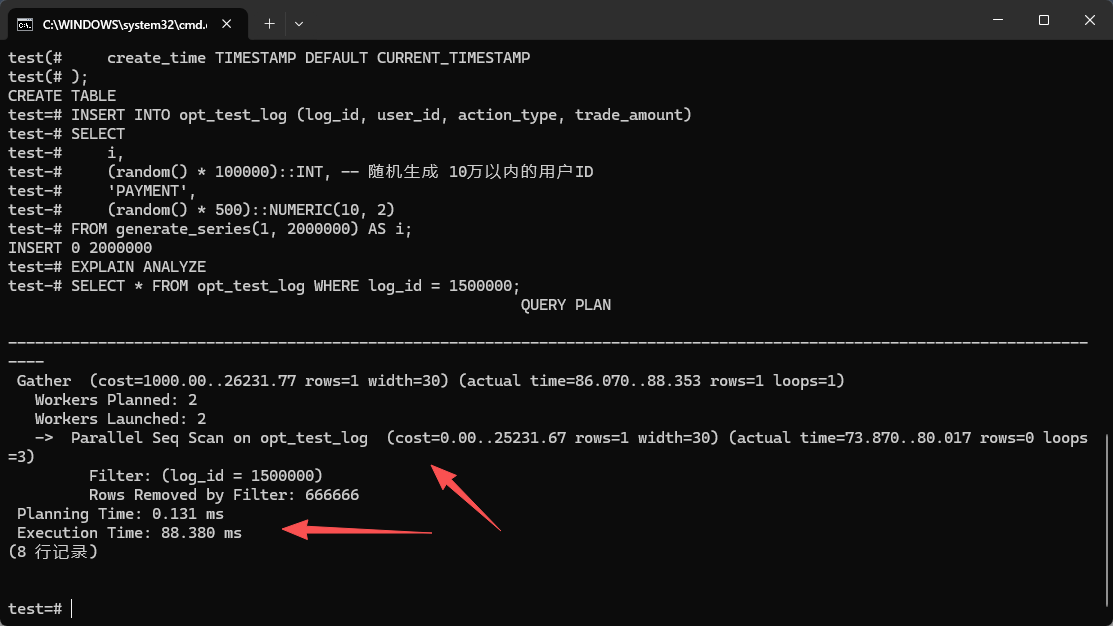
执行节点(Node Type):Parallel Seq Scan on opt_test_log
这个,是最要命的信号。你看截图里,虽然电科金仓的优化器挺聪明的,它自己就开了 Parallel —— 也就是并行多线程,还分了 2 个 Worker 去跑,想着能快一点。但是,它的根儿没变,还是 Seq Scan,也就是顺序全表扫描。这啥意思呢?就为了查那么 1 条数据,数据库动了好几个 CPU 核心,把 200 万行数据从头到尾给翻了一遍。你想啊,并发一上来,服务器 CPU 瞬间飙到 100%,那背后不就是这玩意儿在搞鬼嘛。
代价预估(Cost):cost=0.00…25231.67
这个是优化器给出的一个执行成本估算。前边那个 0.00,是说返回第一行的启动成本。后边的 25231.67 呢,是把这个节点整个扫完的总成本。这个数字啊,它没有单位,就是个相对的值。也就是说,它越大,就代表越吃资源。
真实耗时(Execution Time):Execution Time: 88.380 ms
经常有那种初级开发,一看到这个数,心里就想:“哎呀,才 88 毫秒,连 0.1 秒都没到,这不挺快的嘛。”
我跟你说,这个想法是要出问题的。为啥呢?你想想,对于一个那种在单列上做精确等值匹配的 OLTP 业务,也就是在线交易类的,正常的响应时间,应该是 0.1 毫秒这个级别,也就是亚毫秒级。那么,88 毫秒意味着啥?它比正常情况慢了差不多 1000 倍!你试着想一个场景,比如双十一的时候,每秒有上千个请求打过来,每个请求都要霸着 3 个 CPU 核心在那跑 88 毫秒,那系统不得瞬间排起长队,然后直接崩掉啊。
第三阶段:动手干预 —— 索引(Index)是怎么起作用的还有性能的变化
既然全表扫描的代价这么高,那我们就得用上数据库里面很常用的一个东西了,也就是B-Tree 索引(B树索引)。
索引是个啥原理呢?其实就像是你给那 200 万条数据做了一个排序一样的目录,找数据的时候先查目录,速度自然就快了。
1. 建立 B-Tree 索引
接着我们在 ksql 里面,给 log_id 这个字段建一个单列的索引,操作如下:
-- 在 log_id 字段上创建 B-Tree 索引
CREATE INDEX idx_opt_log_id ON opt_test_log(log_id);
(注:建索引的时候它会把全表扫一遍,你等它提示 CREATE INDEX 完成就行。)
2. 看看效果:索引扫描(Index Scan)
目录搞好了以后,我们把刚才那句用来诊断的 SQL 原封不动再跑一遍:
EXPLAIN ANALYZE
SELECT * FROM opt_test_log WHERE log_id = 1500000;
性能前后的对比情况:
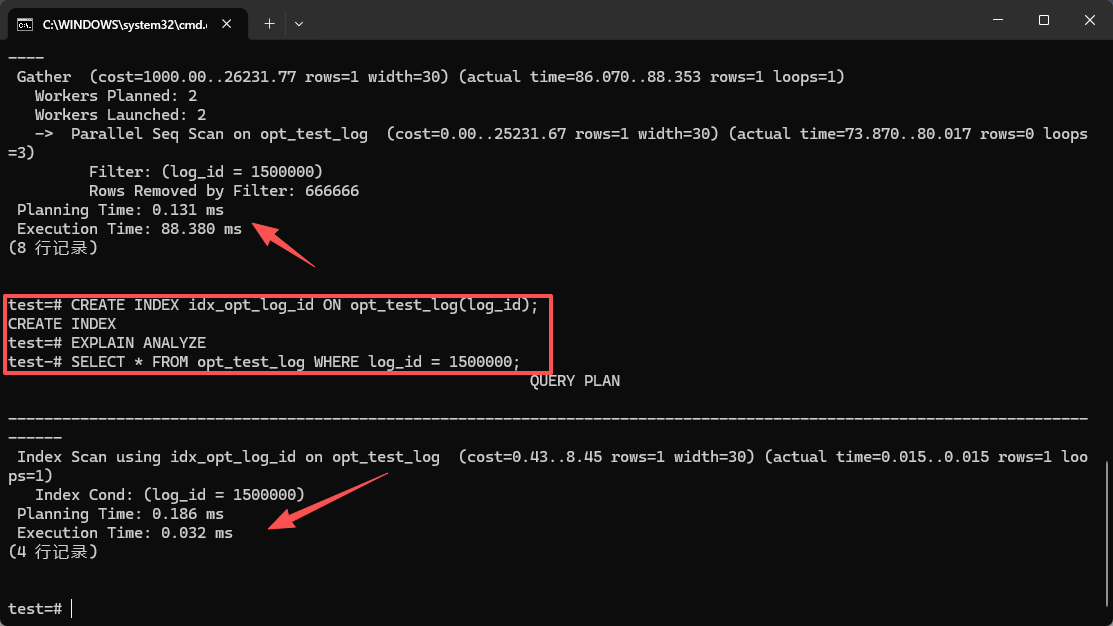
你结合上面这张截图来看,其实执行计划的变化是非常大的:
- 节点变了: 之前那个很吃 CPU 的
Parallel Seq Scan没了,变成了Index Scan using idx_opt_log_id。也就是说,数据库直接去查那个索引树了。顺着树根就走了几个分支,数据就找到了,再也不用去搞多线程扫描了。 - 成本降了很多: 那个执行代价(
Cost)的话,之前还是两万多(25231.67)呢,接着就掉到了0.43..8.45这么小的一个数。 - 响应快了: 真实耗时(
Execution Time)一开始是 88.380 ms,现在的话,变成了 0.032 ms。连 1 毫秒都不到了。性能差不多提了有 2700 倍!通常来说,这就是我们做 DBA 的在生产环境调索引的时候,觉得最爽的时候了。
第四阶段:高阶排雷 —— 为什么我建了索引,SQL 依然在“裸奔”?
掌握了如何看 Index Scan 只是入门。在真实的企业级架构中,最让开发同学崩溃的灵魂拷问是:“DBA 大佬,我明明在这个字段上建了索引,为什么执行计划一看,它还是在走全表扫描?”
这种现象被称为“索引失效”。数据库的优化器极其聪明,但如果你写的 SQL 触碰了底层的架构禁忌,优化器就会果断抛弃你的索引。我们在 ksql 中用实战来逐一演示这三个经典的翻车(或反转)现场。
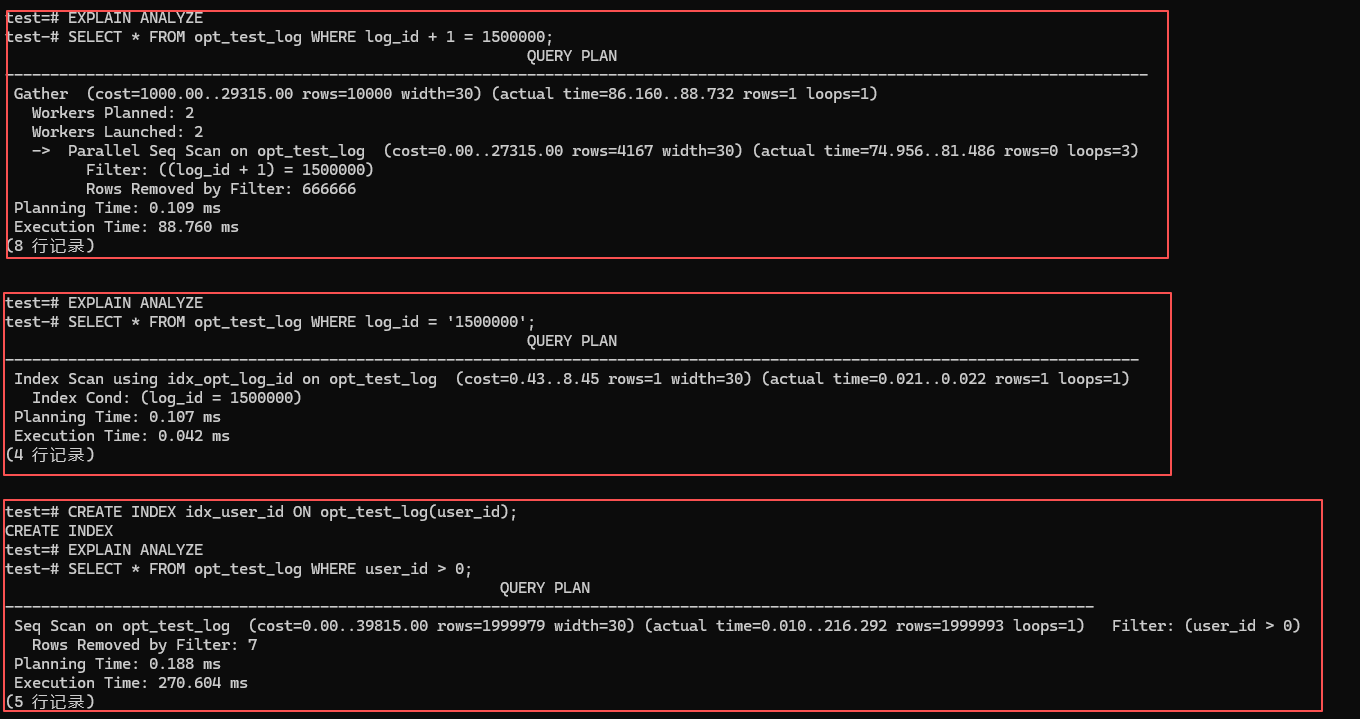
结合上方这张压测全记录,我们来逐一复盘:
禁忌一:在索引列上面搞数学运算或者套函数(肯定出问题)
你仔细看看截图里面第一段 SQL跑出来的结果。我们其实就是为了查 log_id = 1500000 的数据,但是的话,故意在左边写成了 log_id + 1 = 1500001
- 诊断结果: 它马上就变成了
Parallel Seq Scan,也就是说并行全表扫描了,耗时一下子就飙到了 88.760 ms。 - 底层真相: 索引树里面存的其实往往是原来那个
log_id的值。你给这个字段加了个+ 1(或者说套了个TO_CHAR这样的函数),数据库就没办法直接去匹配树的节点了。那怎么办呢?它必须把那 200 万条数据全都拿出来,一条一条算一遍,接着才能去比对等号右边那个值。 - 架构解法: 也就是说,索引列你得让它干干净净的。你改成
WHERE log_id = 1500000 - 1;这样写的话,索引马上就能用上了。
禁忌二:隐式类型转换(有意思的地方:优化器变聪明了)
再看看截图里面的第二段 SQL。log_id 这个字段它是整数型(INT)的,但是的话,等号右边你传进去的却是一个字符串,也就是 '1500000'。很多以前的旧教程都会跟你说:“隐式类型转换的话,那肯定会让索引失效的!”
- 诊断结果: 你看看真实的反馈,它居然走的是
Index Scan,耗时也就 0.042 ms! - 底层真相: 这个其实就是电科金仓现在这个优化器厉害的地方了。当它发现等号右边是个常量字符串的情况,在真正执行之前,它会很聪明地把这个字符串先转成数字。接着再去跟左边的 INT 型索引树去匹配,这样的话索引就保住了!
- 避坑警告: 但是的话,你千万别因为这个就觉得随便传参也行!如果反过来了,你的字段是
VARCHAR,但是你传进去的参数是INT。优化器为了怕精度丢掉,往往就会去对左边的字段做隐式的函数强转。这就相当于你踩到了禁忌一那个坑里面了,此时索引肯定是没法用的。所以啊,传参的类型和表字段的类型一定要严格对齐,这个规矩还是得死死守住的。
禁忌三:优化器其实比你聪明——要拿的数据太多的情况
接着看看截图里面的第三段 SQL。我们在 user_id 上面建了很好的索引,然后去查 user_id > 0 的数据。因为测试数据里面的 ID 基本上都是大于 0 的,也就是说,我们其实是要把全表差不多 100% 的数据都给拿出来。
- 诊断结果: 优化器想都没想就把你刚建好的索引给扔了,它强行走了
Seq Scan,也就是全表扫描,耗时跑到了 270.604 ms。 - 底层真相: 这个其实是基于代价优化器(CBO)聪明的地方。优化器在后台算了一笔账,如果走索引扫描的话,它不光是要去遍历那个很大的索引树,接着还要根据树上的指针,不停地去“回表”。也就是说,要去磁盘上东找西找,把真实的行数据给拼出来。这种海量的随机 I/O,代价太高了。那还不如干脆直接从头到尾扫一遍磁盘,也就是顺序 I/O,这样往往来得更快!
- 架构启示: 也就是说,索引这东西它也不是啥情况都能搞定的。如果你是那种要大批量导出数据的报表类 SQL,你就别光想着建索引了。通常来说,合理去用用时间分区表(Partition),或者说换个列存引擎,这才是靠谱的做法。
结语
这篇文章我们做了什么?先是造了大概 200 万条数据,那个量级,跑起来压力就上来了。然后,用 EXPLAIN ANALYZE 这个命令往深里一看,好嘛,发现它走的是全表扫描,性能的根儿就在这儿。接着我们建了个 B-Tree 索引,这一下,查询速度提升了好几万倍,真的。再往后,又仔细拆解了一下索引会失效的三种情况,那都是架构层面的坑。这么一圈折腾下来,其实就算是把数据库性能调优这事儿,从怎么看一个具体的执行细节,再到怎么从整体上去优化,都给跑通了。
一个真正合格的 DBA 或者架构师,他平时不是说天天在那儿杀进程、重启数据库,到处救火。更多的时候,是通过看执行计划,在开发那边 SQL 还没写得特别烂的时候,就把问题给摁住。对,就是把问题掐死在摇篮里的感觉。
写到这儿,咱们这个金仓数据库的《Kingbase护城河》系列专栏,从网络怎么连调、死锁怎么排查、空间怎么管理,到性能怎么调,这四个难啃的部分,算是都跟着走了一遍。我挺希望这套在 Win 和 Linux 两头实际动手折腾出来的操作方法,能真的帮你把国产的金仓数据库用顺手。毕竟现在这些国产数据库,在越来越多的关键系统里都已经用上了。把底层的那些运行道理整明白,把排错的手艺练扎实,后面再碰到什么新数据库、新挑战,心里也就有个底了。行,那咱们后面新的技术内容再见吧。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












