




目录
一、什么是DML?
DML ( Data Manipulation Language),称为数据操作语言,它是 SQL 语言的一个子集,专门用于对数据库中的数据进行操作,包含INSERT、UPDATE、DELETE语句
1.1 INSERT语句
INSERT INTO 表名 (列1, 列2, 列3, ...)
VALUES (值1, 值2, 值3, ...);
mysql
-- 1.注册后通过邮件激活
-- 插入新用户
INSERT INTO users (username, email, password, created_at)
VALUES ('john_doe', 'john@example.com', 'encrypted_password', NOW());
-- 注册后邮件激活
UPDATE users
SET is_active = 1, activated_at = NOW()
WHERE email = 'john@example.com';
-- 2.注册后通过token激活
INSERT INTO users (username, email, password, created_at, activation_token)
VALUES ('john_doe', 'john@example.com', 'encrypted_password', NOW(), 'abc123token');
-- 通过token激活而不是email
UPDATE users
SET is_active = 1, activated_at = NOW(), activation_token = NULL
WHERE activation_token = 'abc123token';
-- 库存管理
-- 用户下单后更新库存
UPDATE products
SET stock = stock - 1,
updated_at = NOW()
WHERE id = 123;
-- 插入订单记录
INSERT INTO orders (user_id, product_id, quantity, order_date)
VALUES (456, 123, 1, NOW());1.2 UPDATE语句
UPDATE 表名
SET 列1 = 新值1, 列2 = 新值2, ...
WHERE 条件;
mysql
-- 给所有销售部员工加薪10%
UPDATE employees
SET salary = salary * 1.1
WHERE department = '销售部';
-- 更新商品库存(售出后减少)
UPDATE products
SET stock = stock - 1, last_sold = NOW()
WHERE id = 5;
--子查询更新
-- 将销售额最高的员工的职位更新为'销售总监'
UPDATE employees
SET position = '销售总监'
WHERE id = (
SELECT employee_id FROM sales
ORDER BY sales_amount DESC
LIMIT 1
);1.3 TRUNCATE vs DELETE
| 特性 | TRUNCATE | DELETE |
|---|---|---|
| 自增计数器 | 重置。下一个插入的记录的ID将从初始值(通常是1)开始。 | 不重置。下一个插入的记录的ID将从之前的最大值+1开始。 |
| 操作性质 | 数据定义语言(DDL)。它通过释放存储表数据的数据页来工作,并只保留表的结构。 | 数据操作语言(DML)。它逐行删除记录。 |
| 可回滚性 | 在大多数数据库(如MySQL)的某些事务隔离级别下,无法回滚。 | 可以回滚。因为它在事务中记录每一行的删除。 |
| WHERE 条件 | 不能使用 WHERE 条件。总是清空整个表。 | 可以使用 WHERE 条件来删除部分数据。 |
| 速度 | 非常快。因为它不操作单个行,而是直接释放数据页。 | 相对较慢。因为需要逐行处理并在事务日志中记录。 |
| 触发器 | 不会激活 DELETE 触发器。 | 会激活 DELETE 触发器。 |
test:
mysql
--创表
CREATE TABLE products (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
price DECIMAL(10,2)
);
--插入测试数据
INSERT INTO products (name, price) VALUES
('笔记本电脑', 5999.00),
('手机', 2999.00),
('耳机', 399.00);
--测试DELETE
-- 删除所有数据
DELETE FROM products;
-- 查看表状态
SELECT * FROM products; -- 没有数据
-- 插入新数据
INSERT INTO products (name, price) VALUES ('新商品', 100.00);
-- 查看结果
SELECT * FROM products;
--DELETE FROM products WHERE name = '新商品'; --部分删除
-- 可以回滚
ROLLBACK;
--测试TRUNCATE
-- 清空表
TRUNCATE TABLE products;
-- 插入新数据
INSERT INTO products (name, price) VALUES ('新商品', 100.00);
-- 查看结果
SELECT * FROM products;
-- 在大多数数据库中无法回滚
ROLLBACK; -- 数据永久丢失1.4 WHERE条件子句
1. 比较运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
= | 等于 | WHERE salary = 5000 |
<> 或 != | 不等于 | WHERE department <> 'HR' |
> | 大于 | WHERE age > 30 |
< | 小于 | WHERE price < 100 |
>= | 大于等于 | WHERE score >= 60 |
<= | 小于等于 | WHERE created_at <= '2023-12-31' |
mysql
-- 查找工资等于8000的员工
SELECT * FROM employees WHERE salary = 8000;
-- 查找年龄大于30岁的员工
SELECT name, age FROM employees WHERE age > 30;
-- 查找非技术部门的员工
SELECT * FROM employees WHERE department != '技术部';2. 逻辑运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
AND | 与(两个条件都满足) | WHERE age > 25 AND salary > 5000 |
OR | 或(满足其中一个条件) | WHERE department = '销售' OR department = '市场' |
NOT | 非(不满足条件) | WHERE NOT department = 'HR' |
mysql
-- 查找技术部且工资大于8000的员工
SELECT * FROM employees
WHERE department = '技术部' AND salary > 8000;
-- 查找销售部或市场部的员工
SELECT name, department FROM employees
WHERE department = '销售部' OR department = '市场部';
-- 查找不是HR部门的员工
SELECT * FROM employees
WHERE NOT department = 'HR';3. 范围运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
BETWEEN | 在某个范围内 | WHERE salary BETWEEN 5000 AND 10000 |
IN | 在指定值列表中 | WHERE department IN ('技术部', '销售部') |
NOT IN | 不在指定值列表中 | WHERE department NOT IN ('HR', '行政') |
mysql
-- 查找工资在5000到10000之间的员工
SELECT * FROM employees
WHERE salary BETWEEN 5000 AND 10000;
-- 查找特定部门的员工
SELECT * FROM employees
WHERE department IN ('技术部', '销售部', '市场部');
-- 查找不在特定部门的员工
SELECT * FROM employees
WHERE department NOT IN ('HR', '行政部');4. 模糊匹配运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
LIKE | 模式匹配 | WHERE name LIKE '张%' |
NOT LIKE | 不匹配模式 | WHERE email NOT LIKE '%@gmail.com' |
通配符说明:
-
%:匹配任意多个字符(包括0个) -
_:匹配单个字符
mysql
-- 查找姓"张"的员工
SELECT * FROM employees WHERE name LIKE '张%';
-- 查找名字中包含"五"的员工
SELECT * FROM employees WHERE name LIKE '%五%';
-- 查找邮箱以"company.com"结尾的员工
SELECT * FROM employees WHERE email LIKE '%@company.com';
-- 查找名字为3个字的员工(每个_代表一个字符)
SELECT * FROM employees WHERE name LIKE '___';5. 空值判断
| 运算符 | 描述 | 示例 |
|---|---|---|
IS NULL | 是空值 | WHERE phone IS NULL |
IS NOT NULL | 不是空值 | WHERE email IS NOT NULL |
mysql
-- 查找没有填写电话的员工
SELECT * FROM employees WHERE phone IS NULL;
-- 查找已填写邮箱的员工
SELECT * FROM employees WHERE email IS NOT NULL;6. 综合
mysql
-- 查找技术部工资在8000-15000之间,且年龄在25-35岁的员工
SELECT name, age, salary, department
FROM employees
WHERE department = '技术部'
AND salary BETWEEN 8000 AND 15000
AND age BETWEEN 25 AND 35
AND email IS NOT NULL;
-- 查找销售部或市场部,工资大于6000,或者工龄超过3年的员工
SELECT name, department, salary, hire_date
FROM employees
WHERE (department IN ('销售部', '市场部') AND salary > 6000)
OR DATEDIFF(CURDATE(), hire_date) > 365 * 3;
-- 查找2023年入职的员工
SELECT name, hire_date
FROM employees
WHERE hire_date BETWEEN '2023-01-01' AND '2023-12-31';
-- 查找最近30天内入职的员工
SELECT name, hire_date
FROM employees
WHERE hire_date >= DATE_SUB(CURDATE(), INTERVAL 30 DAY);
/*
DATE_SUB() 是MySQL中的日期减法函数:从一个日期中减去指定的时间间隔
DATE_SUB(date, INTERVAL value unit)
date:要处理的原始日期
value:要减去的时间数值
unit:时间单位(YEAR, MONTH, DAY, HOUR等)
*/二、DQL
DQL 的全称是 Data Query Language,中文是数据查询语言,它是 SQL 语言的一个专门用于数据检索的子集,只有SELECT一个语句
ASC vs DESC
| 特性 | ASC(升序) | DESC(降序) |
|---|---|---|
| 全称 | Ascending | Descending |
| 中文含义 | 升序 | 降序 |
| 排序方向 | 从小到大,从A到Z,从早到晚 | 从大到小,从Z到A,从晚到早 |
| 默认行为 | 是。如果 ORDER BY 后不指定,默认使用 ASC。 | 必须显式指定。 |
| 空值处理 | NULL 值会被视为最小值,排在最先。 | NULL 值会被视为最小值,但因为是降序,所以排在最后。 |
ALL vs DISTINCT
| 特性 | ALL | DISTINCT |
|---|---|---|
| 含义 | 全部 | 去重 |
| 返回结果 | 返回所有符合条件的行,包括重复项 | 只返回唯一不重复的行 |
| 默认行为 | 是。如果既不写 ALL 也不写 DISTINCT,默认使用 ALL | 必须显式指定 |
| 性能 | 更快,因为它不需要检查重复项 | 较慢,因为它需要比较和删除重复项 |
| 使用场景 | 需要看到所有数据记录时 | 需要查看唯一值列表时 |
ALL表示查询所有满足条件的记录,可以省略;
DISTINCT表示去掉查询结果中重复的记录;
AS可以给数据列、数据表取一个别名;
2.1 什么是聚合函数?
聚合函数是对一组值执行计算并返回单个值的函数,常用于数据统计和分析场景
mysql
--1.COUNT() - 计数函数
-- 统计学生总人数
SELECT COUNT(*) AS 总人数 FROM student;
-- 统计不同入学年份的数量
SELECT COUNT(DISTINCT enroll_year) AS 不同入学年份数 FROM student;
-- 统计有年龄记录的学生数量
SELECT COUNT(age) AS 有年龄记录人数 FROM student;
--2.SUM() - 求和函数
-- 计算所有学生年龄总和
SELECT SUM(age) AS 年龄总和 FROM student;
-- 按入学年份统计年龄总和
SELECT enroll_year, SUM(age) AS 该年级年龄总和
FROM student
GROUP BY enroll_year;
--3.AVG() - 平均值函数
-- 计算学生平均年龄
SELECT AVG(age) AS 平均年龄 FROM student;
-- 计算每个入学年份的平均年龄
SELECT enroll_year, AVG(age) AS 平均年龄
FROM student
GROUP BY enroll_year;
--4.MAX() / MIN() - 最值函数
-- 找出最大和最小年龄
SELECT MAX(age) AS 最大年龄, MIN(age) AS 最小年龄 FROM student;
-- 每个入学年份的年龄范围
SELECT
enroll_year,
MAX(age) AS 最大年龄,
MIN(age) AS 最小年龄,
MAX(age) - MIN(age) AS 年龄跨度
FROM student
GROUP BY enroll_year;
2.2 HAVING
HAVING 是 SQL 中用于对分组后的结果进行过滤的子句,类似于 WHERE,但作用时机不同
HAVING vs WHERE
| 特性 | WHERE | HAVING |
|---|---|---|
| 作用时机 | 分组前过滤行 | 分组后过滤组 |
| 使用场景 | 过滤原始数据 | 过滤分组结果 |
| 可用的条件 | 普通列条件 | 聚合函数条件 |
mysql
-- 多条件筛选分组的结果
SELECT
enroll_year,
COUNT(*) AS 总人数,
AVG(age) AS 平均年龄,
MAX(age) AS 最大年龄
FROM student
GROUP BY enroll_year
HAVING COUNT(*) >= 2 AND AVG(age) > 19 AND MAX(age) < 22; --此处三个条件筛选2.3 ORDER BY
ORDER BY子句用于对 SQL 查询结果集进行排序。它可以按照一个或多个列进行排序,并且可以指定每个列是升序还是降序排列。如果不使用ORDER BY,查询返回的记录顺序通常是不可预测的(取决于数据库的物理存储和查询计划)
mysql
SELECT 列1, 列2, ...
FROM 表名
ORDER BY 排序列1 [ASC|DESC], 排序列2 [ASC|DESC], ...;2.4 LIMIT
LIMIT 是 MySQL 中用于限制查询结果返回行数的子句,主要用于分页查询和限制数据量
例表格:
mysql
-- 基础用法
SELECT * FROM 表名 LIMIT 行数;
-- 分页用法
SELECT * FROM 表名 LIMIT 起始位置, 行数;
-- 或者
SELECT * FROM 表名 LIMIT 行数 OFFSET 起始位置;
-- 例基础用法:只查看前3个学生
SELECT * FROM student LIMIT 3;
-- 分页查询
-- 第1页:每页3条 (第1-3条)
SELECT * FROM student LIMIT 0, 3;
-- 第2页:每页3条 (第4-6条)
SELECT * FROM student LIMIT 3, 3;
-- 第3页:每页3条 (第7-8条)
SELECT * FROM student LIMIT 6, 3;
----
--OFFSET 写法
-- 跳过前4条,取后面的数据
SELECT * FROM student LIMIT 4 OFFSET 4;
-- 等价于:LIMIT 4, 4
-- 结合 ORDER BY 使用
-- 按年龄降序排列,取前3名
SELECT * FROM student
ORDER BY age DESC
LIMIT 3;
实用场景
mysql
-- 网页分页查询 (假设每页显示10条,当前第2页)
SELECT * FROM articles
ORDER BY create_time DESC
LIMIT 10 OFFSET 10;
-- 随机抽样
-- 随机查看2个学生
SELECT * FROM student
ORDER BY RAND()
LIMIT 2;
----
-- 先排序再限制
SELECT * FROM student
ORDER BY id
LIMIT 1000;
-- 避免:大数据表直接LIMIT而不排序
SELECT * FROM student
LIMIT 1000; -- 可能性能不稳定
----
-- 分页公式
-- 第n页,每页size条数据的通用公式
LIMIT (n-1)*size, size2.5 SELECT语句
mysql
// 基本语法框架
SELECT [DISTINCT] 列1, 列2, ...
FROM 表名
[WHERE 条件]
[GROUP BY 分组列]
[HAVING 分组条件]
[ORDER BY 排序列 [ASC|DESC]]
[LIMIT 数量];mysql
--1.
-- 查询所有列
SELECT * FROM employees;
--查询特定列
SELECT name, salary, department FROM employees;
--使用别名
SELECT
name AS 姓名,
salary AS 工资,
department AS 部门
FROM employees;
--2.
--数据筛选(WHERE)
-- 比较运算
SELECT * FROM products WHERE price > 100;
-- 逻辑运算
SELECT * FROM employees
WHERE department = '技术部' AND salary > 8000;
-- 范围查询
SELECT * FROM products WHERE price BETWEEN 50 AND 200;
-- 模糊查询
SELECT * FROM customers WHERE name LIKE '张%';
-- 空值判断
SELECT * FROM users WHERE email IS NOT NULL;
--3.
--数据排序(ORDER BY)
-- 按工资升序排列(单列排序)
SELECT name, salary FROM employees ORDER BY salary ASC;
-- 按入职日期降序排列(多列排序)
SELECT name, hire_date FROM employees ORDER BY hire_date DESC;
-- 先按部门升序,再按工资降序
SELECT name, department, salary
FROM employees
ORDER BY department ASC, salary DESC;
--4.
--数据分组(GROUP BY)
-- 统计每个部门的人数(聚合)
SELECT department, COUNT(*) as 人数
FROM employees
GROUP BY department;
-- 统计每个部门的平均工资
SELECT department, AVG(salary) as 平均工资
FROM employees
GROUP BY department;
--分组后筛选(HAVING)
-- 查询平均工资超过8000的部门
SELECT department, AVG(salary) as 平均工资
FROM employees
GROUP BY department
HAVING AVG(salary) > 8000;
--5.
--数据去重(DISTINCT)
-- 查询所有不重复的部门
SELECT DISTINCT department FROM employees;
-- 查询不重复的职位和部门组合
SELECT DISTINCT position, department FROM employees;
--6.
--结果集限制(LIMIT)限制返回行数
-- 查询前10条记录
SELECT * FROM products LIMIT 10;
-- 分页查询(从第20条开始,取10条)
SELECT * FROM products LIMIT 20, 10;三、大综合--Final Part
Step 1
mysql
CREATE TABLE IF NOT EXISTS student (
id BIGINT(20) AUTO_INCREMENT PRIMARY KEY NOT NULL COMMENT '学生ID',
name VARCHAR(20) NOT NULL COMMENT '姓名',
age TINYINT(3) UNSIGNED NOT NULL COMMENT '年龄',
enroll_year INT NOT NULL COMMENT '入学年份',
years_left TINYINT(2) NOT NULL COMMENT '还有多少年毕业'
) ENGINE=InnoDB CHARSET=UTF8 COMMENT '学生表';
mysql
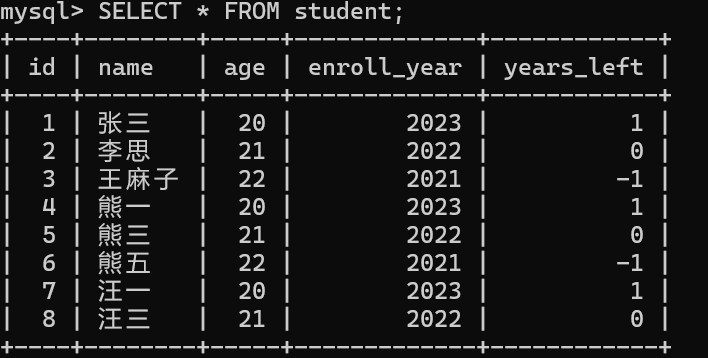
INSERT INTO student(name, age, enroll_year, years_left)
VALUES
('张三', 20, 2023, 1), -- 2027毕业,剩余2年
('李思', 21, 2022, 0), -- 2026毕业,今年毕业
('王麻子', 22, 2021, -1); -- 2025毕业,已超期
INSERT INTO student
VALUES
(DEFAULT, '熊一', 20, 2023, 1),
(DEFAULT, '熊三', 21, 2022, 0),
(DEFAULT, '熊五', 22, 2021, -1);
INSERT INTO student(name, age, enroll_year, years_left)
VALUES
('汪一', 20, 2023, 1),
('汪三', 21, 2022, 0);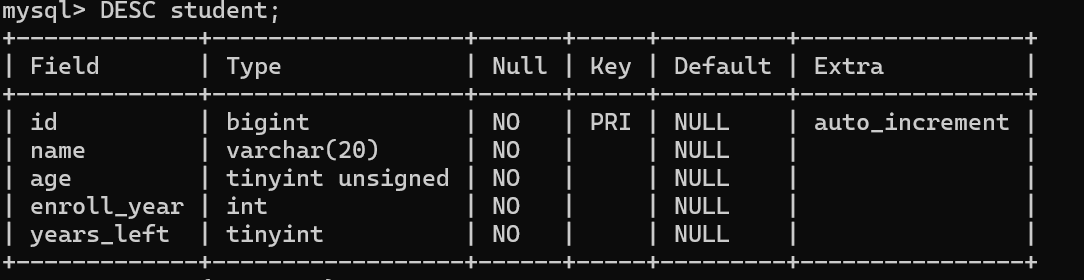
Step 2
mysql
-- 熊一因学业优秀提前毕业
UPDATE student
SET years_left = 0
WHERE name = '熊一';
-- 李思因休学延期毕业
UPDATE student
SET years_left = years_left + 1
WHERE name = '李思';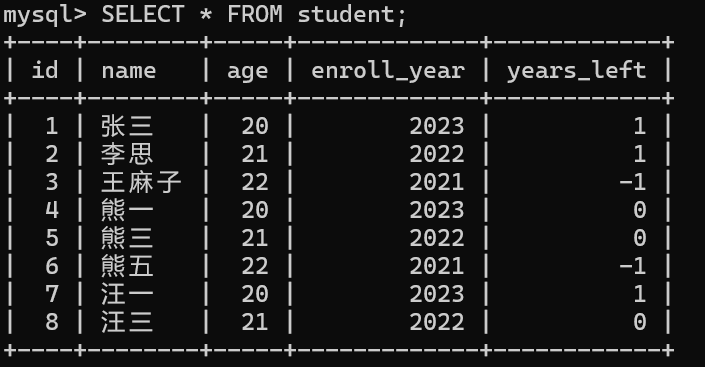
Step 3
mysql
-- 王麻子已毕业离校,从表中删除其记录
DELETE FROM student
WHERE name = '王麻子' AND years_left = -1;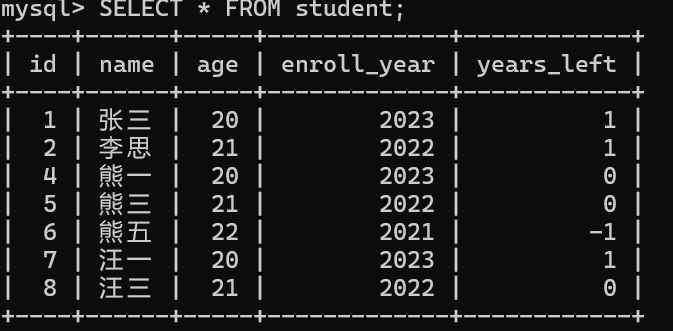
Step 4
mysql
// 查询在读学生(未毕业)
SELECT name, age, enroll_year, years_left
FROM student
WHERE years_left >= 0
ORDER BY years_left ASC;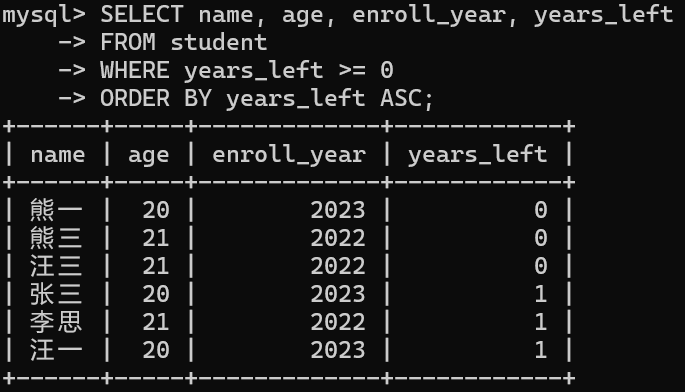
Step 5
mysql
// 统计2023年入学学生情况
SELECT
COUNT(*) AS 在读人数,
AVG(age) AS 平均年龄,
MIN(years_left) AS 最短毕业年限,
MAX(years_left) AS 最长毕业年限
FROM student
WHERE enroll_year = 2023 AND years_left >= 0;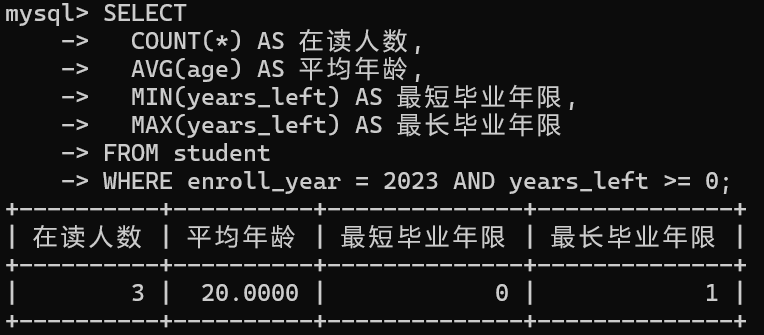
mysql
// 统计各入学年份在读学生数量
SELECT
enroll_year AS 入学年份,
COUNT(*) AS 在读人数
FROM student
WHERE years_left >= 0
GROUP BY enroll_year
ORDER BY enroll_year DESC;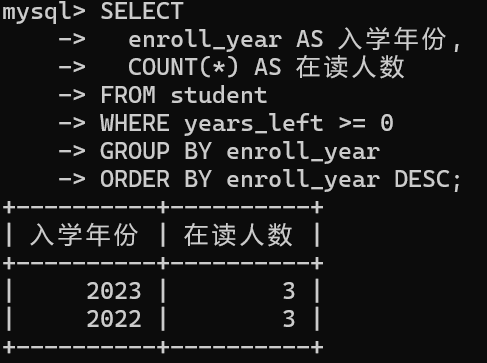
mysql
// 查询今年毕业的学生
SELECT
name AS 姓名,
age AS 年龄,
enroll_year AS 入学年份
FROM student
WHERE years_left = 0
ORDER BY enroll_year DESC;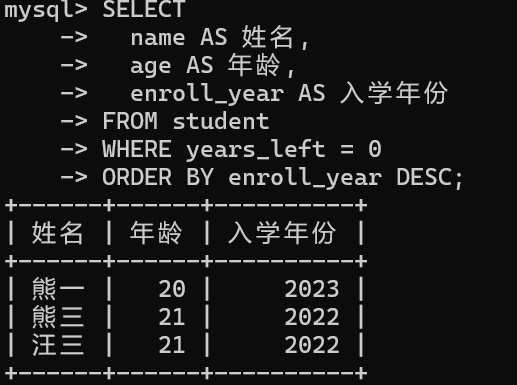
下篇博文再见啦~
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!



















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










