






 本文探讨了Dubbo 2.5.5版本中服务端与客户端线程池差异,重点分析了线程模型和配置误区。通过案例分析,提出升级到2.7.5版本或自定义线程池策略,以及配置调整和限流降级的建议。
本文探讨了Dubbo 2.5.5版本中服务端与客户端线程池差异,重点分析了线程模型和配置误区。通过案例分析,提出升级到2.7.5版本或自定义线程池策略,以及配置调整和限流降级的建议。
1 背景概述
线上事故:在做活动促销的时候,交易中台的商品服务发生了个别节点的宕机而此时间段内QPS并没有超过告警配置的线程数阈值1500。
于是决定做一次压测,当对自己的商品服务做压测20000个请求时,从监控看到客户端线程池(DubboClientHandler)飙升到800左右、而服务端线程池(DubboServerHandler)只有70左右,抛出线程已耗尽的异常。
当前配置如下:
1)dubbo版本为一直在用的2.5.5版本。
2)当前线程池配置为cached模式的ThreadPool,对应的SPI为:com.alibaba.dubbo.common.threadpool.support.cached.CachedThreadPool。
<dubbo:protocol name="dubbo" port="8888" threads="5000" dispatcher="all"/>
从Grafana监控看,ClientThreadPool非常多,最高达到了7000+。所以很明显这个threads属性的设置并没生效。
于是,业务方的疑问是:
1)为何请求20000时,客户端和服务端线程池从监控图表看差距甚大?两者的差别是什么?
2)两者分工协作的机制是怎样的?设定的这个阈值有没有生效、是作为总和统一分配dispatch还是独立分配管理?
3)自定义业务线程池设置的大小有没有效果?
带着这些问题,作为架构师的我马上来了兴趣,决定做一次比较完整的案件分析。
2 案件分析
2.1 追根溯源
2.1.0 Dubbo常用线程池
Dubbo的线程模型中可使用4种线程池
- CachedThreadPool
- LimitedThreadPool
- FixedThreadPool
- EagerThreadPool
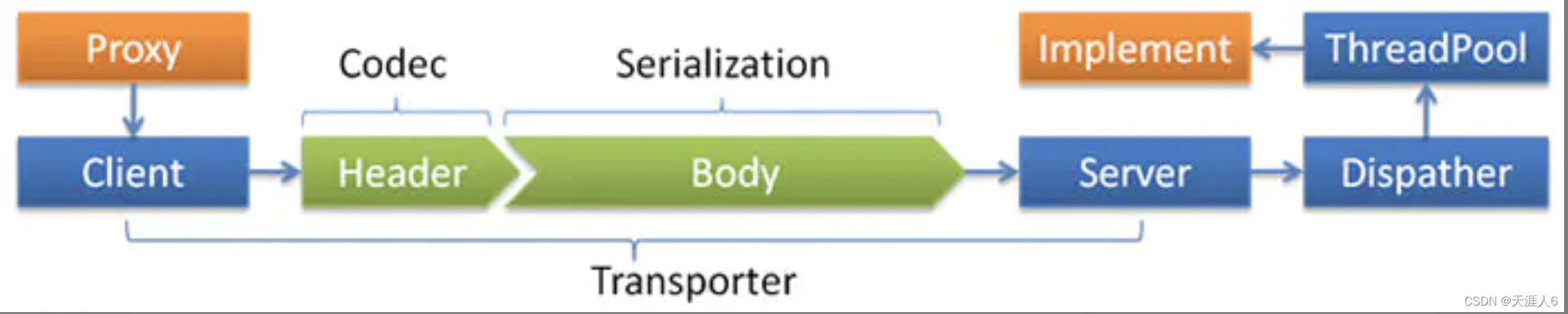
线程主要执行2种逻辑,一是普通IO事件,比如建立连接,断开连接,二是请求IO事件,执行业务逻辑。
在Dubbo的Dispatcher扩展点会使用到这些线程池,Dispatcher这个扩展点用于决定Netty ChannelHandler中的那些事件在Dubbo提供的线程池中执行。
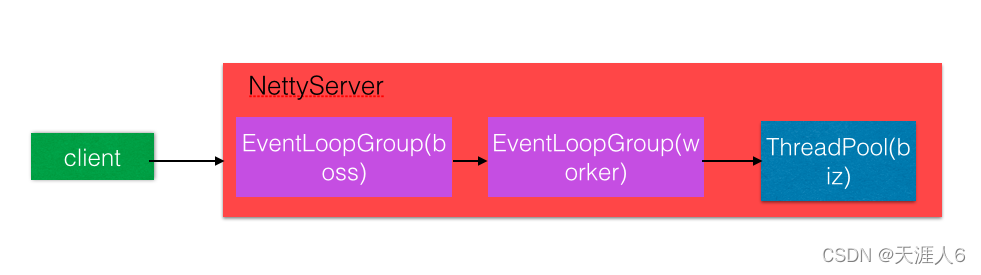
Dubbo默认的底层网络通讯使用的是Netty,服务提供方NettyServer使用两级线程池,其中 EventLoopGroup(boss) 主要用来接受客户端的链接请求,并把接受的请求分发给 EventLoopGroup(worker) 来处理,boss和worker线程组我们称之为IO线程。
如果服务提供方的逻辑能迅速完成,并且不会发起新的IO请求,那么直接在IO线程上处理会更快,因为这减少了线程池调度。但如果处理逻辑很慢,或者需要发起新的IO请求,比如需要查询数据库,则IO线程必须派发请求到新的线程池进行处理,否则IO线程会阻塞,将导致不能接收其它请求。
2.1.1 理解线程模型的区别
根据请求的消息类被IO线程处理还是被业务线程池处理,Dubbo提供了下面几种线程模型:
all : (AllDispatcher类)所有消息都派发到业务线程池,这些消息包括请求/响应/连接事件/断开事件/心跳等,这些线程模型如下图:
direct : (DirectDispacher类)所有消息都不派发到业务线程池,全部在IO线程上直接执行
message : (MessageOnlyDispatcher类)只有请求响应消息派发到业务线程池,其他连接断开事件/心跳等消息,直接在IO线程上执行。
本案件是使用的AllDispatcher模式(默认模式),可知所有事件都直接交给业务线程池进行处理了。cached是缓存线程池,空闲一分钟自动删除,需要时重建,设置的5000从源码看实际上并不会去读取:
| 1 2 3 4 5 6 7 8 |
|
从int threads = url.getParameter("threads", 2147483647);可知默认设置为最大值了,也就可以理解为线程无限扩容。所以,会出现消费端线程数分配多的问题。
2.1.2 Dubbo请求处理分析
Dubbo中的request分为:有去无回(单向)、有来有回(双向)两种:
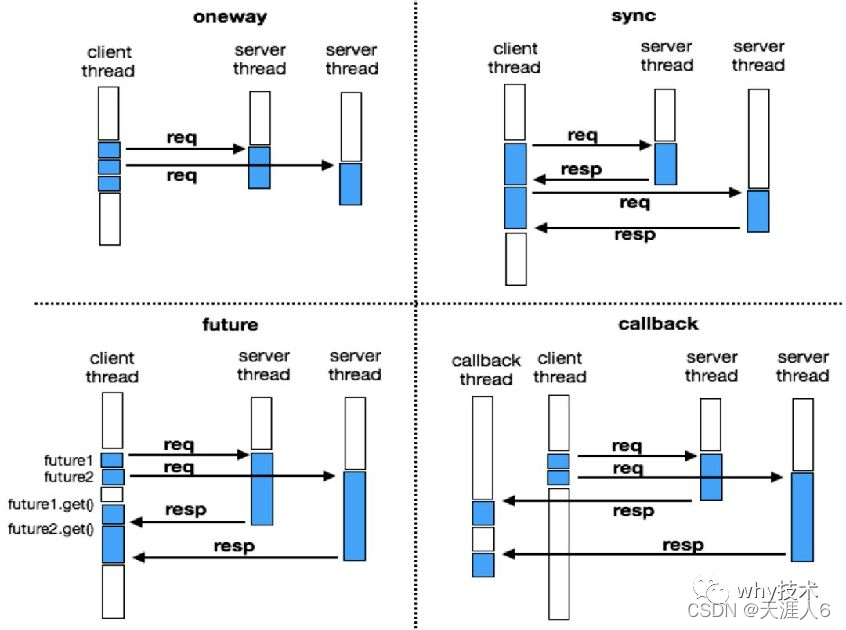
oneway 就是单向,其他的调用类型都是有返回的。
结合2.1.1的派发策略,参考官网线程模型 | Apache Dubbo介绍,
需要通过不同的派发策略和不同的线程池配置的组合来应对不同的场景,所以在默认的情况下,客户端接收到响应后,由于使用 all 的派发策略,会把响应请求派发到客户端线程池中去,但不是必定的,只能说响应会进入客户端线程池中去,但是这个响应可能是一个经过解析后的响应,也可能是一个没有经过解析的响应。所以这个响应有可能在进入线程池之前就被I/O线程解析过了,如果 IO 线程没有解析,那就在客户端线程里面去解析。
通过读源码DubboCodec和DecodeableRpcResult分析,是在I/O线程里面做解码的。
再参考官方消费端线程池模型 | Apache Dubbo分析Consumer和Provider的线程模型:
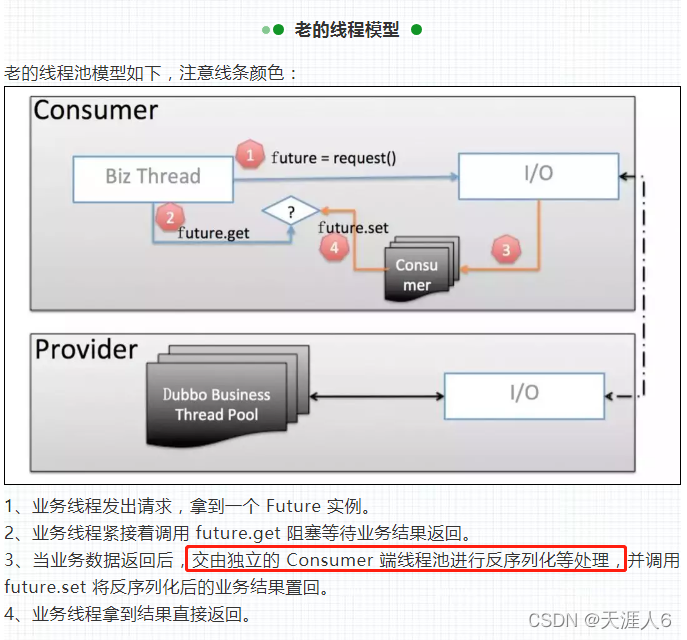
得到结论:
1)当业务数据返回后,默认在 IO 线程上进行反序列化操作,如果配置了 decode.in.io 参数为 false,则延迟到独立的客户端线程池进行反序列化操作。
2)所有响应还是会转发到客户端线程池里面,在这个里面进行解码操作(如果 IO 线程没有解码的话)把结果返回到用户线程中去。
3)对于线程池客户端的默认实现是 cached,服务端的默认实现是 fixed:固定大小线程池,启动时建立线程,不关闭,一直持有(缺省)。
从上述官方如下表述可以看到:
对 2.7.5 版本之前的 Dubbo 应用,尤其是一些消费端应用,当面临需要消费大量服务且并发数比较大的大流量场景时(典型如网关类场景),经常会出现消费端线程数分配过多的问题,具体问题讨论可参见 Need a limited Threadpool in consumer side #2013
改进后的消费端线程池模型,通过复用业务端被阻塞的线程,很好的解决了这个问题。
因为在 2.7.5 版本之前,是每一个连接都对应一个客户端线程池。相当于做了连接级别的线程隔离,但是实际上这个线程隔离是没有必要的。反而影响了性能。参考https://github.com/apache/dubbo/issues/2013。
而在 2.7.5 版本里面,就是不管你多少链接,均共用一个客户端线程池,引入了 Threadless Executor 的概念。
简单的来说,优化结果就是从多个线程池改为了共用一个线程池。
2.2 建议方案
由于2.5.5版本存在这个问题, 官方建议是升级dubbo版本,但由于涉及到很多基础组件需要同步升级、推广周期较长,因此为了及时解决问题,建议先从2.7.5版本fork 修复该问题的代码到当前2.5.5版本并打包dubbo源码为一个特殊版本2.2.5-enhanced。
1)问题讨论&描述:https://github.com/apache/dubbo/issues/2013
2)问题代码块:每次都会去新分配客户端线程池
|
|
3)问题解决的可行性方案:https://github.com/apache/dubbo/pull/4131和https://github.com/apache/dubbo/pull/5490,在2.7.5中进行了修复。
具体代码改动清单:
https://github.com/apache/dubbo/commit/5cc3821438e4f9bcf3a8503ba08e9a0008ef0f4c
和
https://github.com/apache/dubbo/commit/5f8ac2b2e16ef0fa85b25280b3388a187cc415a5
总结来看,2.7.5主要包括了如下几点:
1)ConsumerConfig.java:新增配置项threads和queues(在具体版本 2.6.9中被添加, https://github.com/apache/dubbo/commit/ed4384a2e5ba4d047a3e73d666244b3f41521f5d):
// consumer thread pool type: cached, fixed, limit, eager
private String threadpool;
// consumer threadpool core thread size
private Integer corethreads;
// consumer threadpool thread size
private Integer threads;
// consumer threadpool queue size
private Integer queues;2)定义了新的ThreadlessExecutors和Ring环形队列存储机制来保证不会每次直接产生新实例:
public class DefaultExecutorRepository implements ExecutorRepository {
private static final Logger logger = LoggerFactory.getLogger(DefaultExecutorRepository.class);
private int DEFAULT_SCHEDULER_SIZE = Runtime.getRuntime().availableProcessors();
private final ExecutorService SHARED_EXECUTOR = Executors.newCachedThreadPool(new NamedThreadFactory("DubboSharedHandler", true));
private Ring<ScheduledExecutorService> scheduledExecutors = new Ring<>();
private ScheduledExecutorService reconnectScheduledExecutor;
private ConcurrentMap<String, ConcurrentMap<Integer, ExecutorService>> data = new ConcurrentHashMap<>();
//......
public ExecutorService createExecutorIfAbsent(URL url) {
String componentKey = EXECUTOR_SERVICE_COMPONENT_KEY;
if (CONSUMER_SIDE.equalsIgnoreCase(url.getParameter(SIDE_KEY))) {
componentKey = CONSUMER_SIDE;
}
Map<Integer, ExecutorService> executors = data.computeIfAbsent(componentKey, k -> new ConcurrentHashMap<>());
return executors.computeIfAbsent(url.getPort(), k -> (ExecutorService) ExtensionLoader.getExtensionLoader(ThreadPool.class).getAdaptiveExtension().getExecutor(url));
}
public ExecutorService getExecutor(URL url) {
String componentKey = EXECUTOR_SERVICE_COMPONENT_KEY;
if (CONSUMER_SIDE.equalsIgnoreCase(url.getParameter(SIDE_KEY))) {
componentKey = CONSUMER_SIDE;
}
Map<Integer, ExecutorService> executors = data.get(componentKey);
if (executors == null) {
return null;
}
return executors.get(url.getPort());
}3)针对WrappedChannelHandler弊病:在获取线程池的方法是完全的新增逻辑:
/**
* Currently, this method is mainly customized to facilitate the thread model on consumer side.
* 1. Use ThreadlessExecutor, aka., delegate callback directly to the thread initiating the call.
* 2. Use shared executor to execute the callback.
*
* @param msg
* @return
*/
public ExecutorService getPreferredExecutorService(Object msg) {
if (msg instanceof Response) {
Response response = (Response) msg;
DefaultFuture responseFuture = DefaultFuture.getFuture(response.getId());
// a typical scenario is the response returned after timeout, the timeout response may has completed the future
if (responseFuture == null) {
return getSharedExecutorService();
} else {
ExecutorService executor = responseFuture.getExecutor();
if (executor == null || executor.isShutdown()) {
executor = getSharedExecutorService();
}
return executor;
}
} else {
return getSharedExecutorService();
}
}
/**
* get the shared executor for current Server or Client
*
* @return
*/
public ExecutorService getSharedExecutorService() {
return ExtensionLoader.getExtensionLoader(ExecutorRepository.class).getDefaultExtension().createExecutorIfAbsent(url);
}
@Deprecated
public ExecutorService getExecutorService() {
return getSharedExecutorService();
}参考讨论文章:https://github.com/apache/dubbo/issues/7054、https://github.com/apache/dubbo/pull/7109
2.2.1 其它建议-配置变更
1)建议变更为message模式,cache的线程数根据实际情况调整、建议800-1200。
2)在配置的时候 线程池是针对协议的,有两个属性,一个是threads是配置业务线程数量, 还有一个是iothreads配置I/O线程数量:在com.alibaba.dubbo.remoting.transport.netty.doOpen()逻辑中,通过dubbo URL获取到iothreads数量、创建一个ServerBootstrap并关联到netty NioServerSocketChannel上。
3)不同的调用者共用一个业务线程池。
2.2.2 其它建议-设置限流阈值或降级Fallback
同时接入限流/熔断组件在管理端设定阈值和策略,推荐使用阿里Sentinel组件使用 Sentinel 实现接口限流_运维开发故事的博客-CSDN博客_sentinel 接口限流


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










