



文本分块(Chunking)是决定 RAG(检索增强生成)系统成败的核心技术之一,却常常在幕后默默发挥作用。简单来说,分块就是把长文档切分成更小、结构化的片段,让 AI 系统能够真正检索和推理。
分块可以:
- • 降低数据检索中的噪声
- • 减少 AI 幻觉(即生成错误或误导性结果)
- • 缓解上下文丢失问题
上下文丢失,指模型要么收到文本过多、要么过少,无法判断哪些信息属于同一主题,也记不住句子、话题、章节之间的关联。简言之,因为检索到的数据杂乱无章,模型根本无法理解用户在问什么。 只要采用合适的分块策略,RAG 应用就能成为高度可靠的知识系统,返回简洁、上下文相关的答案。
分块不只是一个预处理技巧,而是 RAG 的基石,它让系统能够快速、规模化地稳定运行,并输出准确、上下文感知的响应。下图展示了信息在 RAG 系统中的流转过程。
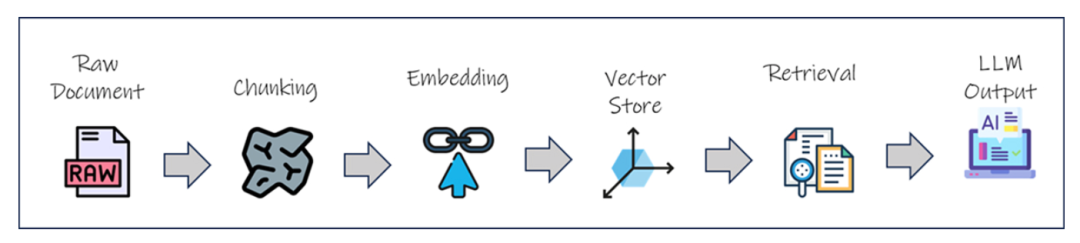
RAG 架构中的文本分块
分块在数据入库之后、向量化之前执行,是决定信息如何存储、检索并最终被大模型使用的最关键一步。
我们不会把整篇文档直接喂给模型,而是通过分块,将其切分成语义上有意义的上下文窗口。 在数据入库阶段,系统会收集 PDF、规章制度、手册、网页、对话记录、内部知识库等原始文档,并将其转为纯文本。这些提取出的文本通常过长、格式混乱、噪声多,不适合直接向量化或检索。在向量化之前,内容必须被结构化和规范化——这就是分块的核心价值。
分块将大文本切分成语义或结构上有意义的单元。 这一点之所以重要,是因为:
- • 向量嵌入模型有上下文长度限制,超长输入效果极差
- • 检索引擎在上下文过大、包含无关数据时表现糟糕
分块通过把数据整理成兼顾语义完整性与嵌入效率的均衡单元,解决了这些问题。
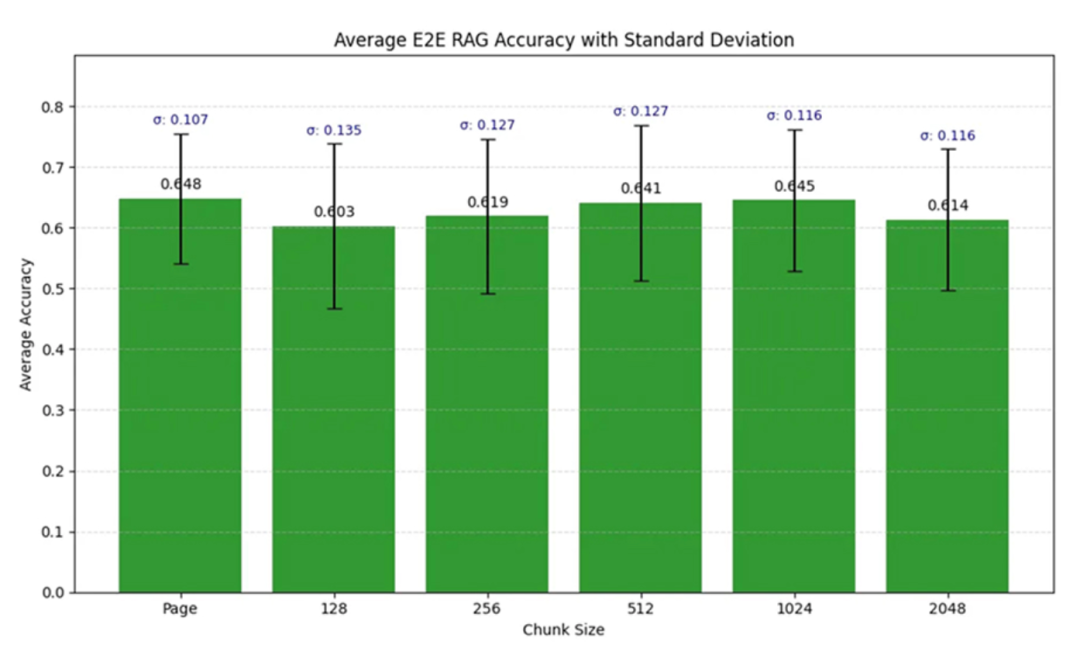
上图展示了不同分块大小对 RAG 准确率的影响。 分块边界决定了嵌入的粒度,进而影响向量检索精度——因为相似度检索(如余弦相似度、距离度量)依赖每个分块的语义指纹质量。 在 RAG 架构中,分块是一项核心结构决策,直接决定整条 pipeline 的性能。
主流 RAG 文本分块策略
实际应用中有多种分块策略,各有优劣,以下是几种关键方案:
固定大小分块(Fixed-Size Chunking)
最直接的分块方式,按 Token 数量切分。例如每 300 个 Token 切一块。
- • 优点:嵌入大小可预测,实现简单
- • 缺点:可能在句子中间切断,造成检索噪声
- • 适用:日志、邮件等结构规整、模式重复的文本
from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter( chunk_size=300, chunk_overlap=0)
语义分块(Semantic Chunking)
不按固定长度切分,而是基于语义与含义切分,可通过 NLP 或 LLM 实现:
- • NLP 方式:依赖句子边界、段落分隔、章节标题,成本低、速度快,但更僵化
- • LLM 方式:深度分析内容,识别话题切换,自动决定边界,对格式差的文本更友好
下面是基于 LangChain 的语义分块示例: SemanticChunker 根据语义相似度而非固定 Token 数划分边界,需要嵌入模型计算相邻文本的相似度,以检测话题切换。
from langchain_experimental.text_splitter import SemanticChunkerfrom langchain_openai.embeddings import OpenAIEmbeddingsembed_model = OpenAIEmbeddings()semantic_chunker = SemanticChunker( embed_model, breakpoint_threshold_type="percentile")
滑动窗口分块(Sliding Window Chunking)
混合方案,用来解决固定分块切断重要上下文的问题。 通过创建重叠分块避免信息丢失,例如 400 Token 的分块,设置 20%–30% 重叠。 这样,靠近边界的概念至少会出现在两个分块中,提升连贯性。
from langchain_text_splitters import TokenTextSplittertext_splitter = TokenTextSplitter( chunk_size=400, chunk_overlap=100)
反向分块(Reverse Chunking)
适用于关键信息出现在章节末尾、总结、脚注的数据集。 不从文档开头分块,而是从末尾向前分块,确保以总结为核心的文档,关键要点保留在同一块内,而不是散落在多个分块中。 这能让检索系统直接返回高信息密度内容,而不必使用过大的分块。
from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter( chunk_size=300, chunk_overlap=0)chunks = text_splitter.split_text(text)chunks = list(reversed(chunks))
Agentic 分块(Agentic Chunking)
一种新兴的智能分块机制:由 LLM Agent 根据预设指令、检索目标和评估反馈,动态决定分块边界。 Agent 会通读整篇文档,然后决定如何切分信息,以最大化特定场景的检索准确率。 到目前为止,这种方式最接近人类整理知识库时的分块逻辑。
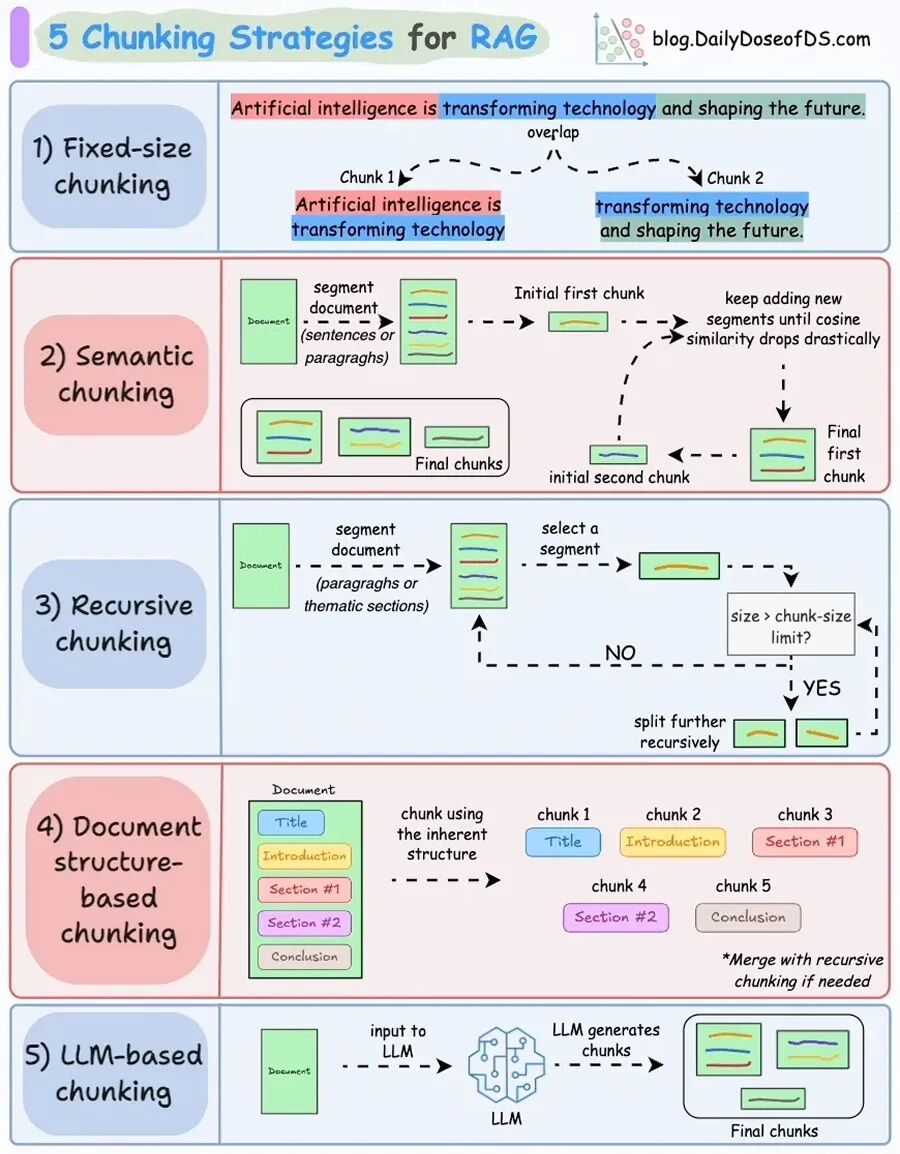
如何选择合适的分块以实现最优检索
分块策略的选择,取决于多个因素:内容结构、查询类型、检索精度要求、成本与延迟、模型混淆风险。
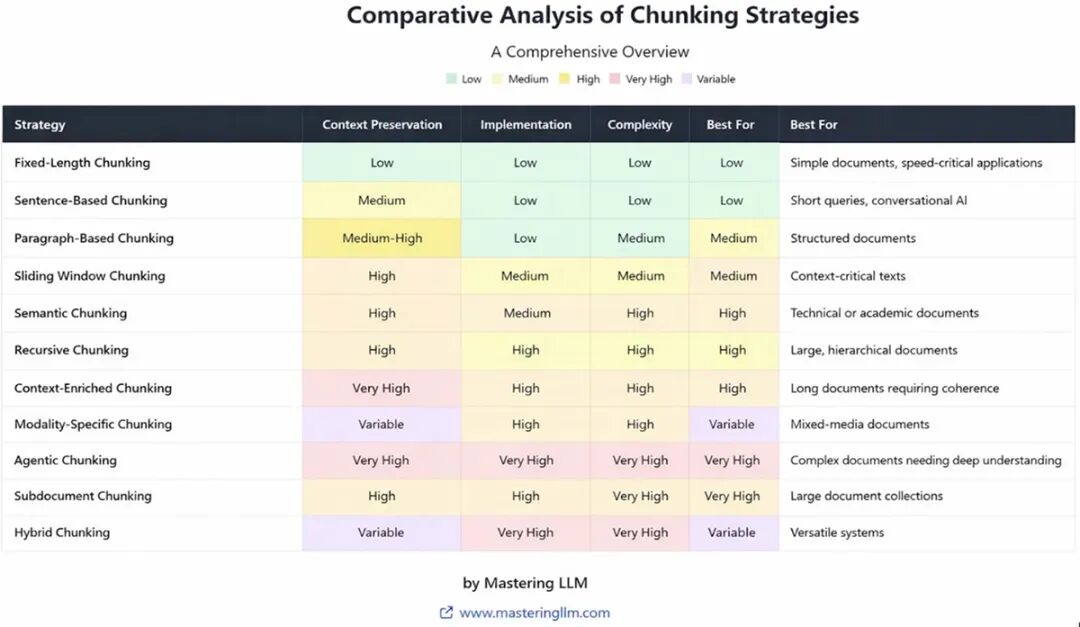
内容结构
- • 学术/研究类文本:概念层层递进,随意固定分块会破坏核心思想,优先语义分块
- • 产品手册、API 文档:格式重复、结构规整,可接受固定大小分块
查询类型
- • 高精度问题(审计推理、法律解释):必须保留语义边界,确保整段相关条款被完整检索
- • 宽泛意图问题:更大的分块更有利于保留叙事逻辑
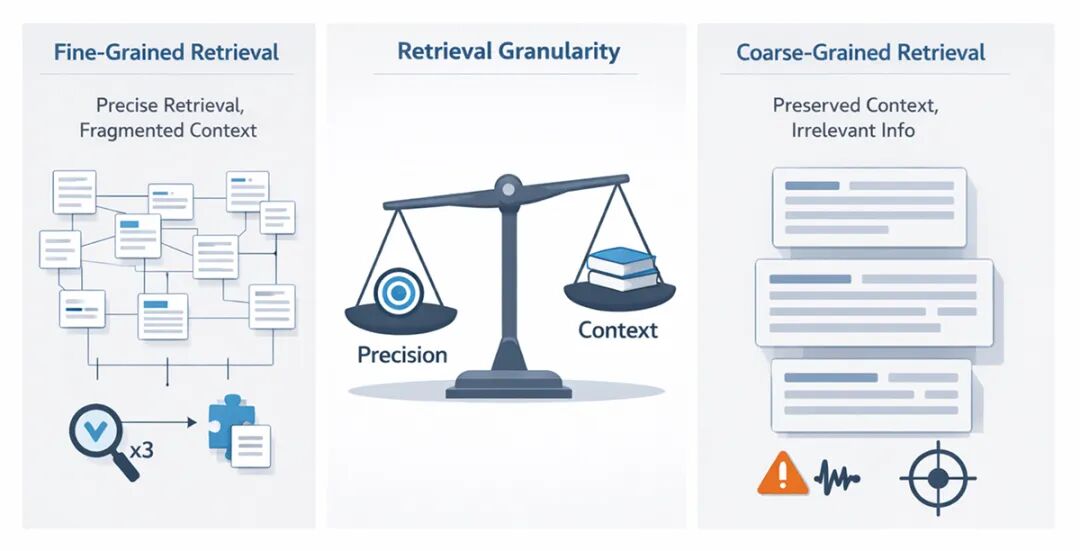
检索粒度
- • 小块:检索更精准,但容易丢失上下文,模型需要拼接多段信息
- • 大块:保留上下文,但会引入噪声,降低精度
是追求“手术刀式精准”还是“更丰富的上下文”,取决于具体场景。
成本与延迟
分块越多,嵌入计算与存储成本越高。 滑动窗口因为重叠分块,会进一步增加计算量与成本。 企业规模化落地 RAG 时,必须权衡:精度提升是否值得额外成本。
最小化模型混淆
- • 分块太小:模型需要拼接大量碎片,幻觉增多、回答不连贯
- • 分块太大:检索返回噪声内容,稀释精度
企业级 RAG 系统的真实应用场景与挑战
分块在企业场景中是安全与合规级别的关键环节,典型场景包括:
合规与风险检索
处理审计材料的企业,必须保证关键词与其上下文绑定,错误切分可能导致关键审计上下文被割裂。
客服自动化
银行、电信、酒店、航空、保险等行业用 RAG 提供故障排查、政策解读、高频问答。
医疗与保险
分块直接影响安全性与准确性。 临床笔记、诊断描述、保单规则必须保留在同一块内,否则检索可能合并不兼容上下文,或错误呈现关键信息。
企业常见挑战
- • 原始文档存在 OCR 错误、异常空格、断句
- • 不同部门数据噪声大、高度重叠
- • 过度使用滑动窗口会抬高存储成本
- • 过于粗糙的分块会直接导致检索失败
这些挑战都说明:分块是一项战略设计,直接决定 RAG 系统成败。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
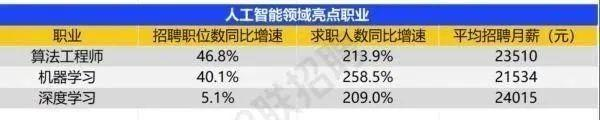
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

















&spm=1001.2101.3001.5002&articleId=159955554&d=1&t=3&u=2a53f297c4f3435099914451a7b5686a)
 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










