



从 Token 到 Transformer:大模型底层原理技术入门
聊大模型时,我们经常会听到一堆词:Token、Embedding、Transformer、Attention、预训练、微调、RLHF、RAG、Agent。
如果你刚开始从技术角度理解大模型,很容易有一种感觉:每个词都听过,但它们之间到底怎么连起来,好像还差一张地图。
这篇文章就试着补上这张地图。
我们不深挖复杂公式,也不把文章写成论文,而是从技术链路出发,看看一句话从输入到输出,会经历什么;一个大模型从零到可用,又大概经过哪些阶段。读完你会对大模型的底层结构和训练流程有一个更清晰的整体认识。
大模型处理的不是“字”,而是 Token
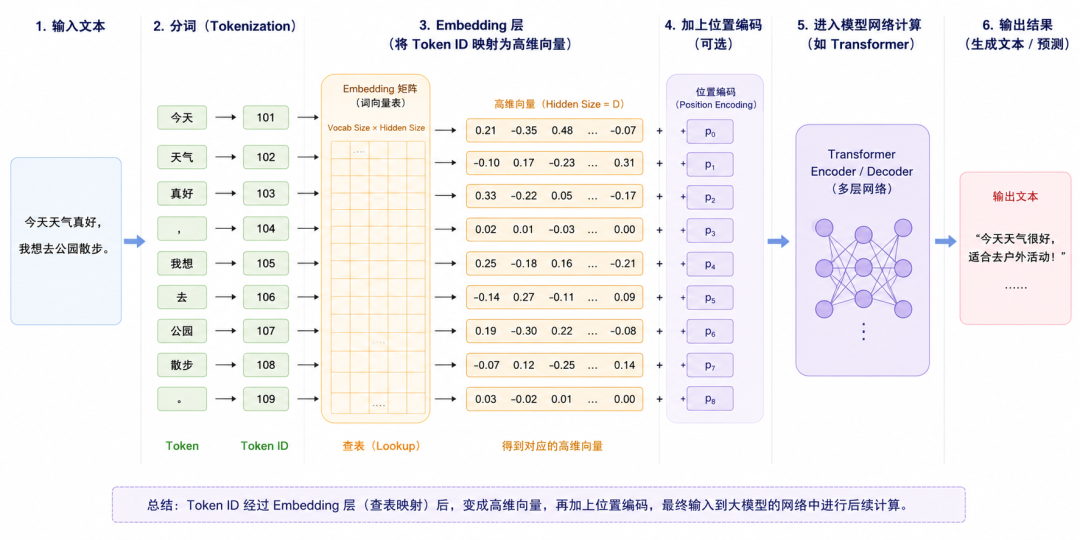
在技术视角里,第一件要理解的事是:模型不能直接处理自然语言。
我们输入的是文字,模型真正处理的是数字。
这中间的第一步叫 Tokenization,也就是分词或切词。它会把文本切成模型可以识别的最小片段,这些片段就是 Token。
比如:
我喜欢人工智能
可能会被切成:
我 / 喜欢 / 人工 / 智能
英文单词也可能被拆开:
unbelievable
可能会被切成:
un / believable
为什么不直接按字切?因为按字切会让序列变长,计算成本更高。为什么不直接按完整词切?因为词表会爆炸,而且遇到新词、专业词、拼写变化时处理起来很麻烦。
所以现代大模型通常使用一种折中方式:把文本切成子词级别的 Token。
Tokenization 之后,每个 Token 会被映射成一个整数 ID。例如:
我 -> 1024
喜欢 -> 3812
人工 -> 9045
智能 -> 7721
到这里,文本已经变成了一串数字 ID。
但问题还没结束。ID 只是编号,编号本身没有语义。模型还需要把这些 ID 转成能表达语义关系的向量。
Embedding:把 Token 放进语义空间
Token ID 会进入一个 Embedding 层。
Embedding 可以理解为一张巨大的查询表:每个 Token ID 对应一个向量。这个向量不是普通坐标,而是一个高维数字表示。
比如一个 Token 可能被表示成:
[0.12, -0.47, 0.83, ...]
这些数字没有单独可解释的含义,但整体上能表达语义关系。
在训练过程中,模型会慢慢调整这些向量,让经常在相似语境中出现的 Token,在向量空间中更接近。
例如:
- “医生”和“医院”会建立某种关联。
- “函数”和“参数”会在编程语境中靠近。
- “利率”和“央行”会在金融语境中靠近。
这就是 Embedding 的意义:它把离散的文字碎片,转换成连续的数学空间。
不过,仅有 Token 的语义还不够。模型还要知道 Token 的顺序。
因为:
我喜欢你
和:
你喜欢我
Token 差不多,但意思明显不同。
所以模型还需要加入位置信息,这就是 Position Encoding 或位置嵌入。它告诉模型每个 Token 在句子中的位置。
Transformer:大模型的核心骨架
现在我们有了 Token 向量,也有了位置信息。接下来,它们会进入大模型的核心结构:Transformer。
Transformer 最早在 2017 年的论文《Attention Is All You Need》中提出。今天的大多数大语言模型,底层都和 Transformer 架构密切相关。
从宏观上看,一个 Transformer 模型由很多层堆叠而成。每一层大致包含两类核心模块:
- Self-Attention:让 Token 之间互相“看见”。
- Feed Forward Network:对每个位置的表示做进一步变换。
你可以把每一层想象成一次“重新理解上下文”的过程。
第一层可能学到比较浅的关系,比如词性、局部搭配。
更深的层可能学到句法结构、指代关系、逻辑关系,甚至任务模式。
多层堆叠之后,每个 Token 的向量就不再只是它自己的含义,而是融合了上下文后的表示。
Attention:让模型知道重点在哪里
Transformer 最关键的能力来自 Attention,也就是注意力机制。
它解决的问题是:当模型处理某个 Token 时,应该关注上下文中的哪些 Token?
比如:
小王把钥匙放进抽屉,因为它很小。
这里的“它”大概率指“钥匙”,不是“抽屉”。
模型要做的,就是在处理“它”时,给“钥匙”更高的注意力权重。
Attention 的核心思想可以简化成三个向量:
- Query:当前 Token 想找什么信息。
- Key:其他 Token 能提供什么信息。
- Value:其他 Token 实际携带的信息。
模型会用 Query 和 Key 计算相关性,再根据相关性加权汇总 Value。
简化来看就是:
当前词:它
更关注:钥匙
较少关注:小王、放进、抽屉
这使得模型能够动态捕捉上下文关系。
更进一步,大模型会使用 Multi-Head Attention,也就是多头注意力。多个注意力头可以从不同角度理解句子:
- 一个头关注语法结构。
- 一个头关注指代关系。
- 一个头关注时间顺序。
- 一个头关注代码里的变量依赖。

这也是 Transformer 强大的根源:它不是按固定规则理解文本,而是通过训练学会“在不同场景下该关注什么”。
预训练:大模型能力的来源
有了模型结构,还需要训练。
大语言模型最重要的训练阶段叫 预训练。预训练通常使用海量文本数据,让模型学习语言规律和世界知识。
对于很多生成式大模型来说,常见目标是:
根据前面的 Token,预测下一个 Token。
比如训练样本是:
人工智能正在改变
模型要预测下一个 Token 可能是:
世界
行业
教育
医疗
训练系统知道真实答案是什么,于是可以计算模型预测和真实答案之间的误差。这个误差叫 Loss。
训练过程大致是:
- 输入一段文本。
- 模型预测下一个 Token。
- 计算预测误差。
- 使用反向传播更新参数。
- 重复数万亿次类似过程。
这就是大模型能力的来源。
表面上看,它只是在预测下一个 Token;但在海量数据和巨大参数规模下,它会学到很多复杂模式:
- 语言结构
- 常识知识
- 专业知识
- 代码语法
- 推理步骤
- 对话格式
- 文体风格
所谓“涌现能力”,很多时候就来自这种规模化训练。当模型、数据和计算量达到一定程度后,一些原本不明显的能力会突然变得可用,比如多步推理、代码生成、复杂指令跟随。
指令微调:让模型从“会续写”变成“会听话”
预训练后的模型很强,但它不一定好用。
因为它学到的是“预测文本”,不是“按用户要求完成任务”。
如果你问它:
请总结这篇文章。
未经指令微调的模型可能只是继续写类似的文本,而不一定真的给你总结。
所以还需要 Instruction Tuning,也就是指令微调。
这个阶段会使用大量“指令-回答”数据,让模型学习人类常见任务格式:
指令:把下面这段话翻译成英文。
回答:...
指令:解释这段代码的作用。
回答:...
指令:请用三点总结这篇文章。
回答:...
经过指令微调后,模型会更像一个助手,能够理解“请你做什么”。
这一步非常关键。没有它,大模型可能更像一个强大的文本补全器;有了它,才更像我们今天使用的聊天助手。
RLHF:让模型更符合人类偏好
指令微调之后,模型能回答问题了,但回答质量还不一定符合人类偏好。
比如它可能:
- 语气生硬。
- 回答太长或太短。
- 遇到危险问题时不拒绝。
- 不知道什么时候该承认不确定。
- 给出看似合理但不负责任的建议。
为了解决这些问题,很多模型会经历 RLHF,也就是 Reinforcement Learning from Human Feedback,中文常译为“基于人类反馈的强化学习”。
它的大致过程是:
- 模型针对同一个问题生成多个回答。
- 人类标注员比较哪个回答更好。
- 训练一个奖励模型,学习人类偏好。
- 再用强化学习方法优化原模型,让它更倾向于生成高评分回答。
你可以把 RLHF 理解成一种“品味校准”。
预训练让模型有知识。
指令微调让模型会做任务。
RLHF 让模型更像一个靠谱、礼貌、符合人类预期的助手。
当然,RLHF 不是完美方案。它也可能带来副作用,比如模型过度迎合、回答保守、拒绝过多,或者在不确定时仍然表现得很自信。
推理阶段:模型是怎么生成回答的?
训练完成后,用户真正使用模型时,进入的是 推理阶段。
假设你输入:
请用一句话解释 Transformer。
模型会先把输入切成 Token,再转成向量,通过 Transformer 层计算,最后输出下一个 Token 的概率分布。
比如下一个 Token 的候选可能是:
Transformer: 0.32
它: 0.21
一种: 0.18
简单: 0.05
模型会根据采样策略选择一个 Token,然后把它接到上下文后面,再继续预测下一个 Token。
如此循环,直到生成完整回答。
这里有几个常见参数:
- Temperature:控制随机性。越高越发散,越低越稳定。
- Top-k:只从概率最高的 k 个候选里选。
- Top-p:只从累计概率达到 p 的候选集合里选。
- Max tokens:限制最大生成长度。
所以,大模型不是一次性“想好一整段话”再输出,而是一个 Token 一个 Token 地生成。
这也解释了为什么它有时会前后不一致:因为生成过程是连续采样,后面的内容依赖前面已经生成的内容。
上下文窗口:模型的“短期记忆”
大模型每次回答时,能看到的内容是有限的,这个限制叫 上下文窗口。
上下文窗口越大,模型能处理的内容越多,比如长文档、多轮对话、大段代码。
但上下文窗口不是无限的。超过限制的内容,模型就看不到,或者需要被压缩、截断、检索后再放入上下文。
这也是为什么长对话里,模型可能忘记前面说过什么。
技术上,很多应用会通过以下方式缓解:
- 对历史对话做摘要。
- 把文档切块后检索相关片段。
- 使用向量数据库存储知识。
- 只把当前任务相关内容放进上下文。
这也引出了一个重要应用架构:RAG。
RAG:让模型接入外部知识
RAG 全称是 Retrieval-Augmented Generation,检索增强生成。
它解决的是一个很现实的问题:大模型的参数知识不一定新、不一定全,也不一定包含企业内部资料。
RAG 的思路是:
- 把文档切成小块。
- 转成向量并存入向量数据库。
- 用户提问时,把问题也转成向量。
- 检索最相关的文档片段。
- 把这些片段连同问题一起交给模型。
- 模型基于检索内容生成回答。
这样做的好处是:
- 可以接入最新资料。
- 可以使用私有知识库。
- 可以减少幻觉。
- 可以给出引用来源。
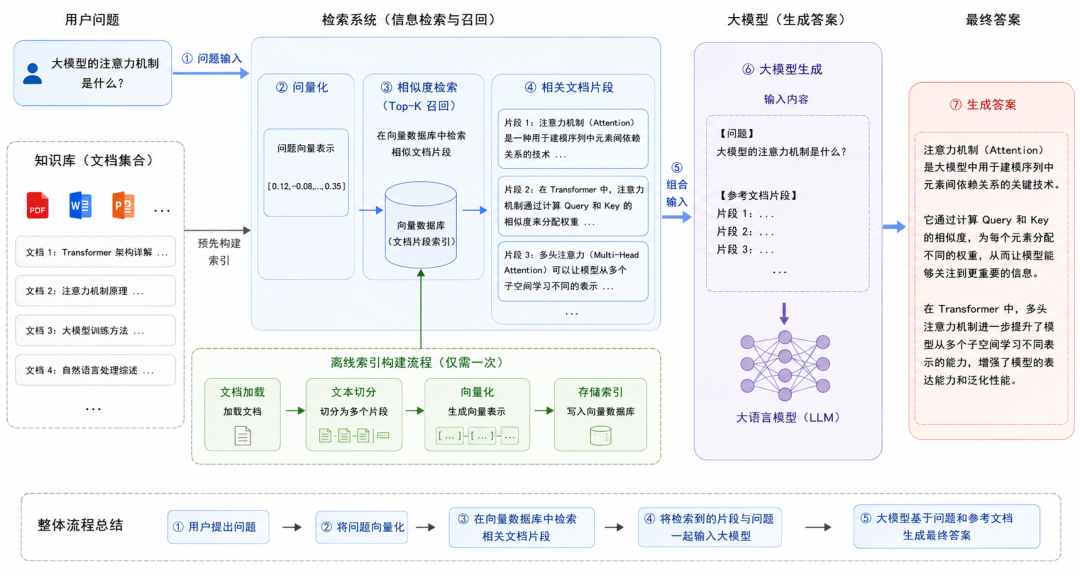
RAG 并不是让模型“记住”新知识,而是在生成前把相关资料放到它眼前。
就像开卷考试:模型本身会答题,RAG 给它提供教材和资料页。
Agent:从回答问题到执行任务
如果说 RAG 让模型能查资料,那么 Agent 让模型能做事情。
一个 Agent 通常具备几类能力:
- 理解目标
- 拆解步骤
- 调用工具
- 观察结果
- 修正计划
- 持续执行
比如你说:
帮我分析这个项目为什么测试失败,并尝试修复。
Agent 可能会:
- 读取测试日志。
- 定位失败用例。
- 打开相关文件。
- 修改代码。
- 重新运行测试。
- 如果失败,再继续调整。
- 最后总结改动。
这已经不是单纯的文本生成,而是“模型 + 工具 + 环境反馈”的系统。
现在很多 AI 编码工具、数据分析助手、办公自动化工具,本质上都在往 Agent 方向发展。
但 Agent 也更需要权限控制。因为一旦模型能调用工具,它就可能修改文件、执行命令、访问数据。能力越强,边界越要清楚。
技术视角下,大模型为什么会幻觉?
从技术角度看,幻觉不是偶然的小毛病,而是生成式模型天然可能出现的问题。
原因主要有几个:
- 模型的训练目标是预测下一个 Token,不是验证事实。
- 参数知识可能过时或不完整。
- 用户问题可能没有足够上下文。
- 采样过程可能生成看似合理但错误的内容。
- 模型倾向于维持语言连贯性,即使它并不知道答案。
所以,解决幻觉不能只靠一句“模型更聪明”。
常见工程手段包括:
- 接入 RAG。
- 要求模型引用来源。
- 使用工具查询事实。
- 对关键回答做规则校验。
- 在高风险场景引入人工审核。
- 降低采样随机性。
- 使用测试或代码执行验证结果。
大模型的输出不是数据库查询结果。它更像一个强大的生成器,需要和检索、验证、权限、审计一起组成可靠系统。
结尾:大模型是一套系统,不只是一个模型
从技术角度看,大模型的链路可以这样串起来:
文本先被切成 Token,再通过 Embedding 变成向量;Transformer 利用 Attention 建立上下文关系;预训练让模型学到语言和知识;指令微调与 RLHF 让模型更像助手;推理阶段则通过逐 Token 生成回答;RAG 和 Agent 又把模型扩展成能查资料、能调用工具的应用系统。
这篇文章可以总结成三个关键点:
- Token、Embedding、Transformer、Attention 构成了大模型理解和生成语言的基础。
- 预训练、指令微调、RLHF 决定了模型从“会续写”到“会协作”的能力演进。
- RAG 和 Agent 让大模型从单纯聊天走向真实应用,但也带来了事实校验和权限控制问题。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】


















 6035
6035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










