




写在前面:
首先感谢兄弟们的订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。
路虽远,行则将至;事虽难,做则必成。只要有愚公移山的志气、滴水穿石的毅力,脚踏实地,埋头苦干,积跬步以至千里,就一定能够把宏伟目标变为美好现实。
Hello,大家好。上一篇文章介绍了ARIMA时间序列算法,今天我们来一起学习一下ARIMAX。
在进入主题之前,给大家分享一下经典语录:
良好的睡眠,健康的身体,快乐的心情,平淡的生活,这些才是最重要的。
以下内容均结合参考资料与个人实操理解原创撰写,不存在滥用原创问题。

在上一篇文章中,我们详细讲解了ARIMA时间序列模型的原理与实战,ARIMA仅依靠数据自身的历史规律做预测,适用于趋势、周期稳定的场景。
但现实业务中,绝大多数数据都不是孤立变化的:
✅销量会受节假日、促销、天气、竞品活动的影响
✅用电量会受天气温度、工作日或者周末的影响
✅客流数据会受活动策划、假期政策的影响
✅商品价格会受促销活动、特殊事件的影响
当核心序列受外部因素干扰明显时,纯ARIMA模型精度会严重不足。这时候,时间序列进阶模型ARIMAX就派上用场了。今天这篇文章,我们从ARIMAX是什么、与ARIMA的区别、代码实战三个部分介绍。
ARIMAX是什么
ARIMAX中文全称:带外生变量的差分自回归移动平均模型。ARIMAX = ARIMA + 外生变量(外部影响因子)。
如果说ARIMA是「只看自己的过去预测未来」,那ARIMAX就是「既看自身历史规律,又参考外部影响因素」的增强版时间序列模型。
核心逻辑:预测值 = 自身时序趋势(ARIMA核心规律) + 外部变量影响(X外生因子)
自身时序趋势(ARIMA核心规律)
通过差分d让数据平稳,通过自回归p捕捉历史趋势,通过移动平均q修正误差,解决时序数据的趋势、周期、残差问题。
外部变量影响(X外生因子)
模型会自动学习每个外部因子对目标值的影响权重。
例如,促销活动对销量正向影响、高温天气对用电量正向影响、节假日对客流负向影响等。
训练完成后,模型既记住了数据自身的变化规律,也记住了外部因素的影响程度,预测结果自然更精准。
ARIMAX与ARIMA区别
ARIMA模型
仅利用目标序列自身的滞后值、误差、差分规律建模
适合:无明显外部干扰、规律稳定的平稳时序数据
缺点:无法捕捉突发、外部因素带来的波动
ARIMAX模型
在ARIMA基础上,引入一个或多个外生解释变量X
适合:受外界因素影响大、波动不规则的业务数据
优势:大幅提升预测精度,贴合真实业务场景
关键差异
- 模型结构不同:ARIMA(p,d,q) vs ARIMAX(p,d,q)+外生变量矩阵
- 训练数据不同:ARIMA只需目标列;ARIMAX需要目标列+影响因子列
- 预测要求不同:ARIMA直接预测;ARIMAX必须提供未来外生变量数据
- 适用场景不同:ARIMA通用稳定数据;ARIMAX业务复杂、有干扰的数据
代码实战
# 导入工具包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
from sklearn.metrics import mean_squared_error, mean_absolute_error
import joblib
import warnings
warnings.filterwarnings('ignore')
# 1. 构建时序数据 + 外生变量
np.random.seed(42)
n = 60
dates = pd.date_range('2020-01-01', periods=n, freq='M')
exog1 = np.linspace(0, 10, n) + np.random.normal(0, 0.5, n)
exog2 = np.sin(np.linspace(0, 4*np.pi, n)) + np.random.normal(0, 0.3, n)
y = 2 * exog1 + 0.5 * exog2 + np.random.normal(0, 1, n)
df = pd.DataFrame({'date': dates, 'y': y, 'exog1': exog1, 'exog2': exog2})
df.set_index('date', inplace=True)
df.to_csv('data_arimax.csv')
# 2. 划分训练集、测试集
train = df.iloc[:-12] # 训练集
test = df.iloc[-12:] # 后12个月数据作为测试集
train_y = train['y']
train_exog = train[['exog1', 'exog2']]
test_exog = test[['exog1', 'exog2']]
# 3. 自动最优阶数筛选(AIC最小准则)
def auto_order(y, exog, max_p=3, max_d=1, max_q=3):
best_aic = np.inf
best_order = (1,1,1)
for p in range(max_p+1):
for d in range(max_d+1):
for q in range(max_q+1):
try:
model = ARIMA(endog=y, exog=exog, order=(p,d,q))
res = model.fit()
if res.aic < best_aic:
best_aic = res.aic
best_order = (p,d,q)
except:
continue
return best_order
best_order = auto_order(train_y, train_exog)
print(f'最佳ARIMA阶数: {best_order}')
# 4. 训练 ARIMAX 模型
model = ARIMA(endog=train_y, exog=train_exog, order=best_order)
model_fit = model.fit()
# 5. 预测未来12期
pred_res = model_fit.get_forecast(steps=len(test), exog=test_exog)
pred_mean = pred_res.predicted_mean
# 6. 模型评估
rmse = np.sqrt(mean_squared_error(test['y'], pred_mean))
mae = mean_absolute_error(test['y'], pred_mean)
print(f'RMSE: {rmse:.2f}, MAE: {mae:.2f}')
# 7. 可视化拟合效果
# 基础设置
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
plt.figure(figsize=(12,5))
plt.plot(train_y, label='训练数据')
plt.plot(test['y'], label='真实值')
plt.plot(test.index, pred_mean, label='ARIMAX预测值')
plt.legend()
plt.title('ARIMAX时序预测结果')
plt.show()
# 8. 保存模型(可直接上线使用)
joblib.dump(model_fit, 'arimax_model.pkl')
本次实战使用的生成的数据集:
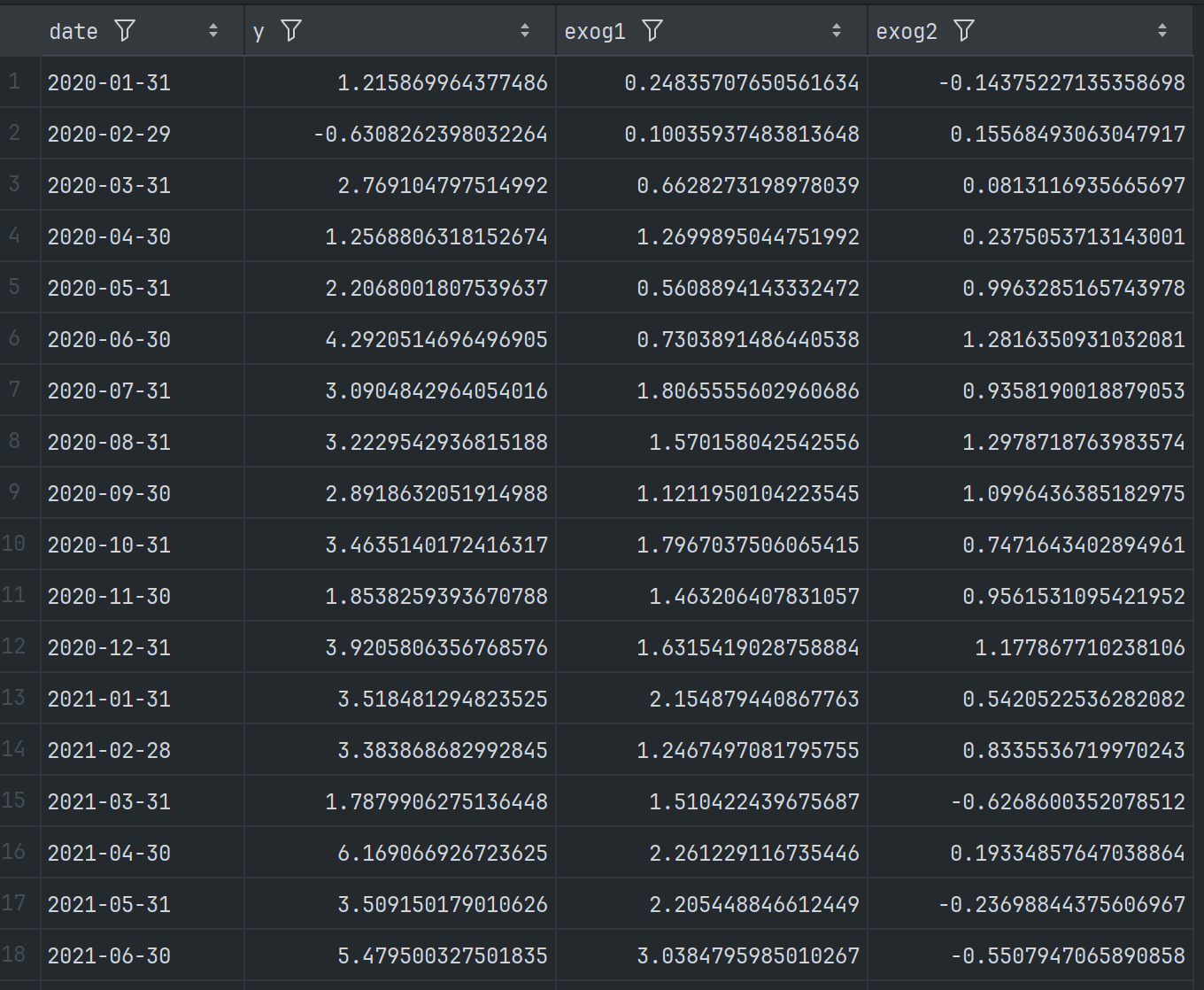
使用后12个月的数据作为测试集,其他的作为训练集,绘制的结果图:
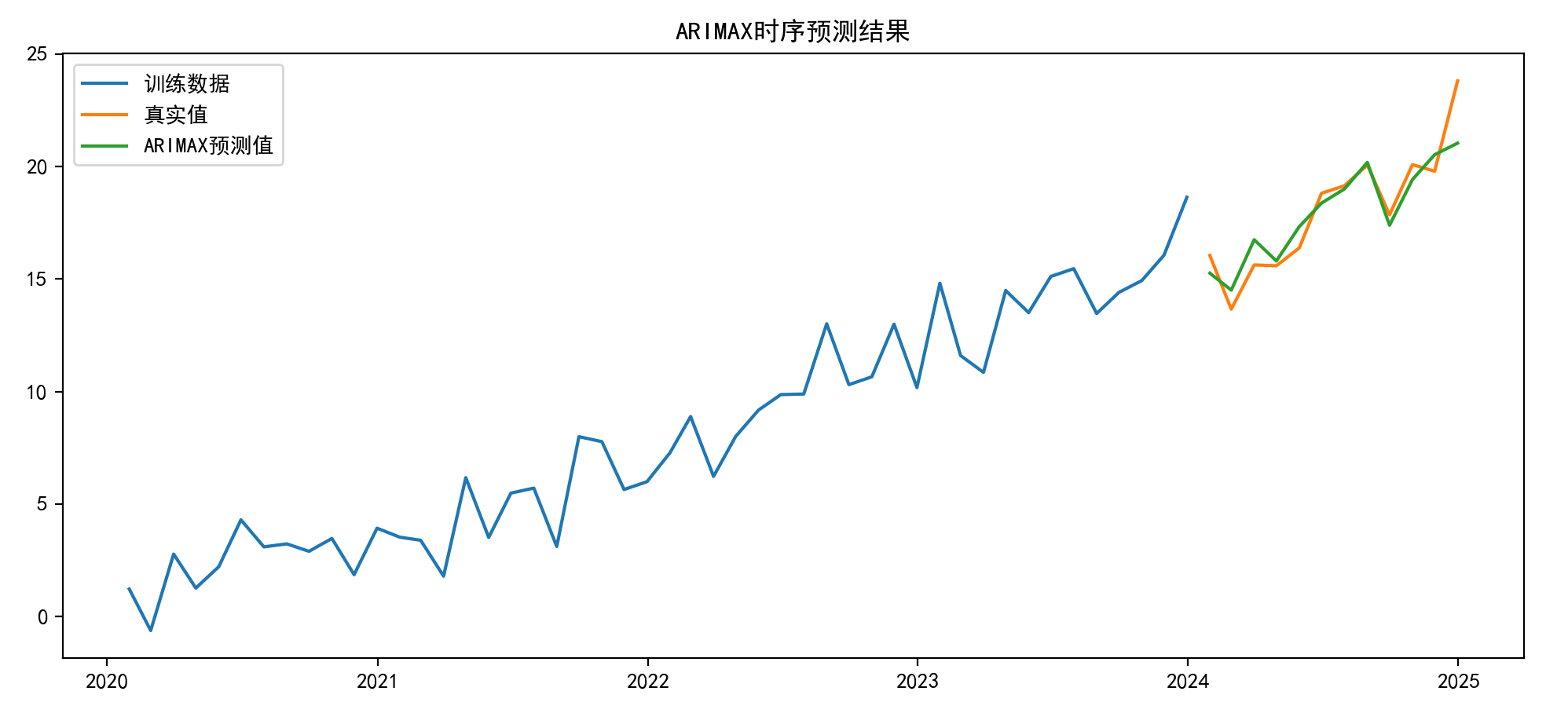
从结果来看,预测的效果还是不错的。
总结
- ARIMAX是ARIMA的增强版,核心优势是引入外部影响因子,适配复杂业务场景
- 原理简单易懂:自身时序规律 + 外部变量权重修正
- 唯一约束:预测必须依赖未来外生变量数据
如果你已经掌握ARIMA,那么ARIMAX可以直接无缝上手,是工业时序预测、销量预测、能耗预测、客流预测的首选进阶模型。
说明:文章首发在微信公众号


















 3964
3964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












