




转载:https://www.cnblogs.com/365djl/p/16922329.html
https://blog.csdn.net/weixin_41377182/article/details/120808310
https://blog.csdn.net/weixin_41377182/article/details/124245005
官方文档:https://pytorch.org/docs/stable/tensor_view.html?highlight=view
- x.view(),它表示将Tensor的维度转变为view指定的维度
-
permute(),这个函数是做维度交换的
-
torch.view()方法对张量改变“形状”其实并没有改变张量在内存中真正的形状。简单地说,view方法没有拷贝新的张量,没有开辟新内存,与原张量共享内存,只是重新定义了访问张量的规则,使得取出的张量按照我们希望的形状展现。
-
torch.contiguous()方法首先拷贝了一份张量在内存中的地址,然后将地址按照形状改变后的张量的语义进行排列。就是说contiguous()方法改变了多维数组在内存中的存储顺序,以便配合view方法使用。
view()用法
PyTorch allows a tensor to be a
Viewof an existing tensor. View tensor shares the same underlying data with its base tensor. SupportingViewavoids explicit data copy, thus allows us to do fast and memory efficient reshaping, slicing and element-wise operations.For example, to get a view of an existing tensor
t, you can callt.view(...).Pytorch允许tensor 是现有张量的视图。 查看张量与其基本张量共享相同的基础数据。 支持视图避免了明确的数据副本,因此使我们能够进行快速和有效的内存重塑,切片和元素的操作。
例如,要查看现有张量t,您可以调用t.view(...)。
import torch
import torch.nn as nn
t = torch.rand(4, 4)
b = t.view(2, 8) # 将原本shape 4*4的,变为 2*8 的
b.size()
t.storage().data_ptr() == b.storage().data_ptr()
# `t` and `b` share the same underlying data.t和b共享基础数据
b[0][0] = 3.14
t[0][0]结果(忽略warning):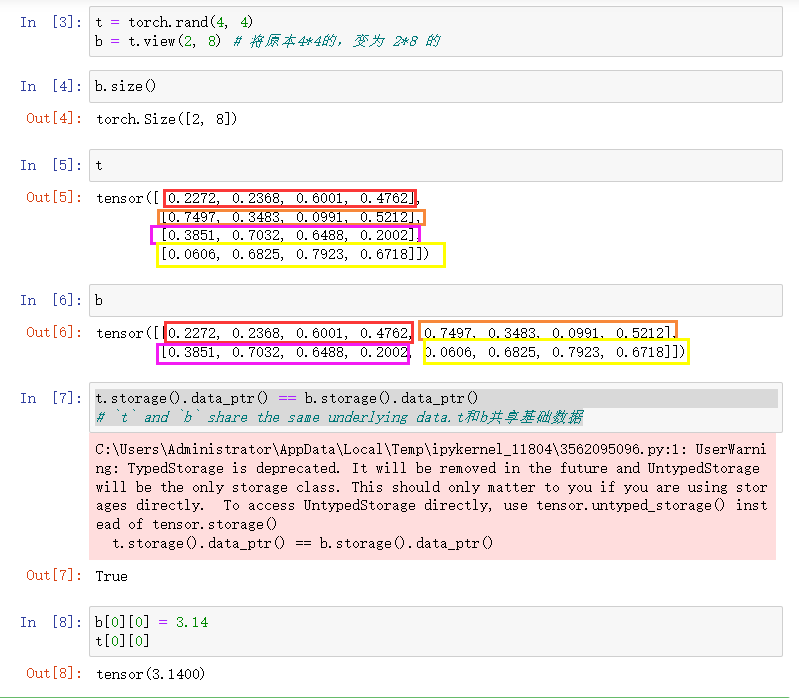
contiguous()用法
Since views share underlying data with its base tensor, if you edit the data in the view, it will be reflected in the base tensor as well.
Typically a PyTorch op returns a new tensor as output, e.g. add(). But in case of view ops, outputs are views of input tensors to avoid unnecessary data copy. No data movement occurs when creating a view, view tensor just changes the way it interprets the same data. Taking a view of contiguous tensor could potentially produce a non-contiguous tensor. Users should pay additional attention as contiguity might have implicit performance impact. transpose() is a common example.
由于视图与基本张量共享基础数据,因此,如果您在视图中编辑数据,则它也会反映在基本张量中。
通常,Pytorch op返回新的张量作为输出,例如 add()。 但是,在视图ops的情况下,输出是输入张量的视图,以避免不必要的数据副本。 创建视图时不会发生数据移动,视图张量只是更改其解释相同数据的方式。 连续张量可能会产生非连续张量。 用户应额外关注,因为连续性可能会产生隐含的性能影响。 transpose()是一个常见的例子。
base = torch.tensor([[0, 1],[2, 3]])
base.is_contiguous()
t = base.transpose(0, 1) # `t` is a view of `base`. No data movement happened here.
t.is_contiguous()
c = t.contiguous()结果: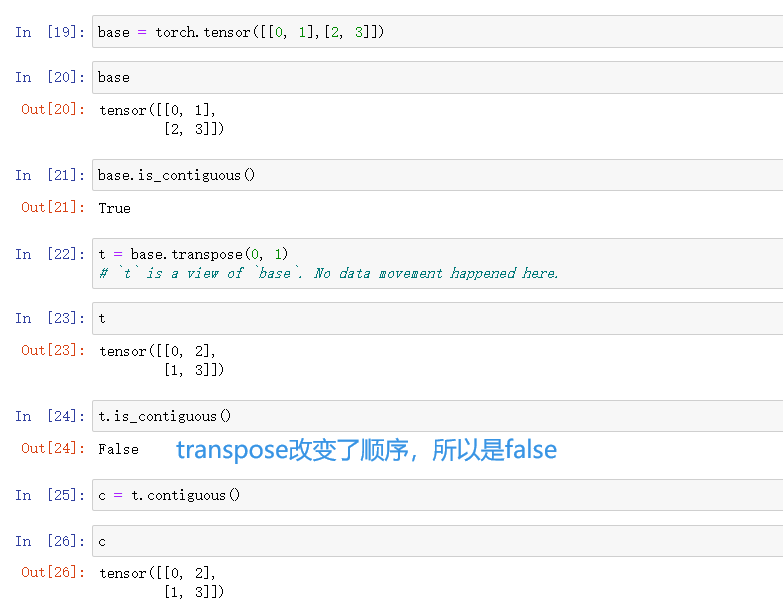
permute()
官方文档:torch.permute — PyTorch 2.0 documentation
x = torch.randn(2, 3, 5)
x.size()
torch.permute(x, (2, 0, 1)).size()
permute(dims)
参数dims用矩阵的维数代入,一般默认从0开始。即第0维,第1维等等
也可以理解为,第0块,第1块等等。当然矩阵最少是两维才能使用permute
如是两维,dims分别为是0和1
可以写成permute(0,1)这里不做任何变化,维数与之前相同
如果写成permute(1,0)得到的就是矩阵的转置
如果三维是permute(0,1,2)
0代表共有几块维度:本例中0对应着3块矩阵
1代表每一块中有多少行:本例中1对应着每块有2行
2代表每一块中有多少列:本例中2对应着每块有5列
所以是3块2行5列的三维矩阵
这些0,1,2并没有任何实际的意义,也不是数值,只是用来标识区别。有点类似于x,y,z来区分三个坐标维度,是人为规定好的
x = torch.linspace(1, 30, steps=30).view(3,2,5) # 设置一个三维数组
b = x.permute(0,2,1) # 每一块的行与列进行交换,即每一块做转置行为
print(b)
print(b.size())





















 2864
2864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










