




一、项目背景及解决方案
1. 项目背景
文本分类是自然语言处理(NLP)的核心任务,广泛应用于内容审核、垃圾邮件识别、情感分析等场景。本项目聚焦辱骂性文本检测:通过朴素贝叶斯算法,自动区分包含辱骂词汇的文本(标注为1)和正常文本(标注为0)。
人工审核辱骂文本效率低、成本高,而朴素贝叶斯算法具有原理简单、计算高效、对小规模文本数据适应性强的特点,非常适合轻量级文本分类场景。本项目基于人工构造的6条文本样本(含标签),训练朴素贝叶斯分类器,实现对新文本的辱骂性判定。
2. 解决方案(基于朴素贝叶斯原理)
核心公式:P(yi∣X)=P(X∣yi)P(yi)P(X)P(y_i|X) = \frac{P(X|y_i)P(y_i)}{P(X)}P(yi∣X)=P(X)P(X∣yi)P(yi)(P(X)P(X)P(X) 对所有类别相同,比较时可忽略)
- P(yi)P(y_i)P(yi):类别yiy_iyi(辱骂/非辱骂)的先验概率(样本中该类别的占比);
- P(X∣yi)P(X|y_i)P(X∣yi):给定类别yiy_iyi时,文本XXX出现的条件概率(词汇在该类别下的加权占比);
- P(yi∣X)P(y_i|X)P(yi∣X):文本XXX属于类别yiy_iyi的后验概率(最终比较该值,取最大者为预测结果)。
具体实现步骤:
- 加载文本样本和标签,统计类别先验概率P(yi)P(y_i)P(yi);
- 构建全局词汇表(所有文本的不重复词汇);
- 提取TF-IDF特征(TF:词频,IDF:逆文档频率,衡量词汇重要性),将文本转换为数值向量;
- 计算每个类别下的条件概率P(X∣yi)P(X|y_i)P(X∣yi)(类别内词汇TF-IDF的加权占比);
- 测试集映射到词汇表,转换为同维度向量;
- 计算测试文本的后验概率,输出概率最大的类别。
二、项目中库的作用及常见用法
本项目仅使用numpy库,以下是详细说明:
| 库名 | 核心作用 | 常见用法示例 | 用法说明 |
|---|---|---|---|
| numpy | 高性能数值计算,提供多维数组(ndarray)和数组操作函数,支撑向量/矩阵运算 | np.zeros([m, n]) | 创建m行n列全0数组,用于初始化词频向量、条件概率矩阵 |
np.shape(arr) | 获取数组形状(行数/列数),校验测试集向量维度是否匹配词汇表 | ||
np.sum(arr) | 计算数组元素和,统计类别内词汇总权重、概率乘积和 | ||
np.log(arr) | 数组元素取自然对数,用于计算IDF(逆文档频率) | ||
np.multiply(a, b) | 数组对应元素相乘(哈达玛积),计算TF-IDF(TF * IDF) | ||
arr / float(n) | 数组元素除以标量,归一化词频(消除文本长度差异) |
三、详细注释的代码(含中文说明)
import numpy as np
import matplotlib.pyplot as plt # 新增:用于可视化
plt.rcParams['font.sans-serif'] = ['SimHei'] # 支持中文显示
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
def loadDataSet():
"""
加载数据集:构造辱骂文本检测的样本和标签
返回值:
postingList: 文本样本列表,每个元素是分词后的词汇列表
classVec: 类别标签列表,1=辱骂文本,0=正常文本
"""
# 6条文本样本(分词后)
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmatian', 'is', 'so', 'cute', 'I', 'love', 'him', 'my'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
# 对应的类别标签
classVec = [0, 1, 0, 1, 0, 1] # 1是辱骂的,0不是
print("数据集加载完成,样本数量:{},标签数量:{}".format(len(postingList), len(classVec)))
return postingList, classVec
class NBayes(object):
"""朴素贝叶斯分类器类:实现辱骂文本检测"""
def __init__(self):
"""初始化分类器参数"""
self.vocabulary = [] # 全局词汇表(所有文本的不重复词汇)
self.idf = [] # 逆文档频率(IDF)向量
self.tf = [] # 词频(TF)矩阵
self.tdm = 0 # 条件概率矩阵 p(x|yi)(每行对应一个类别,每列对应一个词汇)
self.Pcates = {} # 类别先验概率字典,key=类别(0/1),value=先验概率P(yi)
self.labels = [] # 所有样本的类别标签列表
self.doclength = 0 # 训练集文本数量
self.vocablen = 0 # 词汇表长度(词汇数量)
self.testset = 0 # 测试集映射后的向量
def cate_prob(self, classVec):
"""
计算每个类别的先验概率 P(yi) = 该类别样本数 / 总样本数
参数:
classVec: 所有样本的类别标签列表(0/1)
"""
self.labels = classVec
# 去重获取所有类别(0和1)
labeltemps = set(self.labels)
for labeltemp in labeltemps:
# 统计该类别样本数
cate_count = self.labels.count(labeltemp)
# 计算先验概率
self.Pcates[labeltemp] = float(cate_count) / float(len(self.labels))
print("类别先验概率计算完成:")
for cate, prob in self.Pcates.items():
print(f"类别{cate}({'辱骂文本' if cate==1 else '正常文本'})的先验概率P(y={cate}) = {prob:.4f}")
def calc_wordfreq(self, trainset):
"""
生成普通词频向量(未使用,保留作为对比)
参数:
trainset: 训练集文本样本列表(分词后)
"""
# 初始化IDF和TF为全0矩阵
self.idf = np.zeros([1, self.vocablen])
self.tf = np.zeros([self.doclength, self.vocablen])
# 遍历每条文本
for index in range(self.doclength):
# 统计每条文本中每个词汇的出现次数(TF)
for word in trainset[index]:
self.tf[index, self.vocabulary.index(word)] += 1
# 统计包含该词汇的文本数量(用于IDF)
for signleword in set(trainset[index]):
self.idf[0, self.vocabulary.index(signleword)] += 1
def build_tdm(self):
"""
计算条件概率矩阵 p(x|yi):每个类别下,词汇表中每个词汇的条件概率
公式:p(x|yi) = 类别yi下词汇x的TF-IDF总和 / 类别yi下所有词汇的TF-IDF总和
"""
# 初始化条件概率矩阵:行数=类别数,列数=词汇表长度
self.tdm = np.zeros([len(self.Pcates), self.vocablen])
# 初始化每个类别的TF-IDF总和(用于归一化)
sumlist = np.zeros([len(self.Pcates), 1])
# 遍历每条文本,按类别累加TF-IDF值
for index in range(self.doclength):
self.tdm[self.labels[index]] += self.tf[index]
# 统计每个类别的TF-IDF总和
sumlist[self.labels[index]] = np.sum(self.tdm[self.labels[index]])
# 归一化得到条件概率 p(x|yi)
self.tdm = self.tdm / sumlist
print("\n条件概率矩阵p(x|yi)构建完成,矩阵形状:", self.tdm.shape)
# 可视化条件概率(前10个词汇)
self.plot_tdm()
def calc_tfidf(self, trainset):
"""
计算TF-IDF特征:将文本转换为TF-IDF向量(消除文本长度影响,突出重要词汇)
参数:
trainset: 训练集文本样本列表(分词后)
"""
# 初始化IDF(1行×词汇表长度列)和TF(文本数行×词汇表长度列)为全0
self.idf = np.zeros([1, self.vocablen])
self.tf = np.zeros([self.doclength, self.vocablen])
# 遍历每条文本计算TF
for index in range(self.doclength):
# 统计每条文本中每个词汇的出现次数
for word in trainset[index]:
self.tf[index, self.vocabulary.index(word)] += 1
# 归一化TF(除以文本长度,消除文本长度差异)
self.tf[index] = self.tf[index] / float(len(trainset[index]))
# 统计包含该词汇的文本数量(用于计算IDF)
for singleword in set(trainset[index]):
self.idf[0, self.vocabulary.index(singleword)] += 1
# 计算IDF:IDF = log(总文本数 / 包含该词汇的文本数)
self.idf = np.log(float(self.doclength) / self.idf)
# 计算TF-IDF:TF * IDF(对应元素相乘)
self.tf = np.multiply(self.tf, self.idf)
print("TF-IDF特征提取完成,TF矩阵形状:{},IDF向量形状:{}".format(self.tf.shape, self.idf.shape))
def train_set(self, trainset, classVec):
"""
训练朴素贝叶斯分类器
参数:
trainset: 训练集文本样本列表(分词后)
classVec: 训练集类别标签列表(0/1)
"""
print("\n开始训练朴素贝叶斯分类器...")
# 1. 计算类别先验概率 P(yi)
self.cate_prob(classVec)
# 2. 获取训练集文本数量
self.doclength = len(trainset)
# 3. 构建全局词汇表(所有文本的不重复词汇)
tempset = set()
[tempset.add(word) for doc in trainset for word in doc] # 遍历所有文本的所有词汇
self.vocabulary = list(tempset)
self.vocablen = len(self.vocabulary)
print("全局词汇表构建完成,词汇数量:{}".format(self.vocablen))
# 4. 提取TF-IDF特征(替换普通词频)
self.calc_tfidf(trainset)
# 5. 构建条件概率矩阵 p(x|yi)
self.build_tdm()
print("分类器训练完成!")
def map2vocab(self, testdata):
"""
将测试文本映射到全局词汇表,转换为数值向量(统计词汇出现次数)
参数:
testdata: 测试文本(分词后的词汇列表)
"""
# 初始化测试集向量为全0(1行×词汇表长度列)
self.testset = np.zeros([1, self.vocablen])
# 统计测试文本中每个词汇的出现次数
for word in testdata:
# 仅处理词汇表中存在的词汇
if word in self.vocabulary:
self.testset[0, self.vocabulary.index(word)] += 1
else:
print(f"警告:测试词汇[{word}]不在词汇表中,已忽略")
print("\n测试文本映射完成,映射后向量形状:", self.testset.shape)
def predict(self, testset):
"""
预测测试文本的类别
参数:
testset: 映射后的测试集向量(1行×词汇表长度列)
返回值:
preclass: 预测的类别(0=正常,1=辱骂)
predvalue: 该类别的后验概率加权值(P(X|yi)*P(yi)的总和)
"""
# 校验测试集向量维度是否匹配词汇表
if np.shape(testset)[1] != self.vocablen:
print('输入错误:测试集向量维度({})与词汇表长度({})不匹配'.format(np.shape(testset)[1], self.vocablen))
exit(0)
predvalue = 0 # 初始化最大后验概率加权值
preclass = '' # 初始化预测类别
print("\n开始计算每个类别的后验概率(P(X|yi)*P(yi)):")
# 遍历每个类别的条件概率向量和先验概率
for tdm_vect, keyclass in zip(self.tdm, self.Pcates):
# 计算 P(X|yi) * P(yi) 的总和(因取对数易下溢,直接相乘累加)
temp = np.sum(testset * tdm_vect * self.Pcates[keyclass])
# 打印中间计算过程(中文说明)
print(f"类别{keyclass}({'辱骂文本' if keyclass==1 else '正常文本'}):")
print(f" - 条件概率向量长度:{len(tdm_vect)},先验概率:{self.Pcates[keyclass]:.4f}")
print(f" - 后验概率加权值(P(X|y={keyclass})*P(y={keyclass})):{temp:.6f}")
# 更新最大概率和对应类别
if temp > predvalue:
predvalue = temp
preclass = keyclass
# 输出预测结果
cate_desc = "辱骂文本" if preclass == 1 else "正常文本"
print(f"\n预测结果:测试文本属于类别{preclass}({cate_desc}),后验概率加权值:{predvalue:.6f}")
return preclass, predvalue
def plot_tdm(self):
"""可视化条件概率矩阵(前10个词汇),对比两个类别的条件概率"""
# 取前10个词汇(避免图形过密)
vocab_top10 = self.vocabulary[:10]
# 类别0(正常)和类别1(辱骂)的条件概率
prob_0 = self.tdm[0][:10]
prob_1 = self.tdm[1][:10]
# 绘制柱状图
x = np.arange(len(vocab_top10))
width = 0.35
plt.figure(figsize=(12, 6))
plt.bar(x - width/2, prob_0, width, label='正常文本(类别0)', color='skyblue')
plt.bar(x + width/2, prob_1, width, label='辱骂文本(类别1)', color='salmon')
# 添加标签和标题
plt.xlabel('词汇', fontsize=12)
plt.ylabel('条件概率 p(x|yi)', fontsize=12)
plt.title('前10个词汇的条件概率对比(正常文本 vs 辱骂文本)', fontsize=14)
plt.xticks(x, vocab_top10, rotation=45)
plt.legend()
plt.tight_layout()
plt.show()
if __name__ == '__main__':
# 1. 加载数据集
dataSet, listClasses = loadDataSet()
# 2. 初始化分类器
nb = NBayes()
# 3. 训练分类器
nb.train_set(dataSet, listClasses)
# 4. 选择第一条样本作为测试集(正常文本)
test_doc = dataSet[0]
print("\n测试文本:", test_doc)
# 5. 测试文本映射到词汇表
nb.map2vocab(test_doc)
# 6. 预测类别
result = nb.predict(nb.testset)
# 7. 打印最终结果
print("\n===== 最终预测结果 =====")
print(f"测试文本:{test_doc}")
print(f"预测类别:{result[0]}({'辱骂文本' if result[0]==1 else '正常文本'})")
print(f"后验概率加权值:{result[1]:.6f}")
四、无注释的简洁版代码
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def loadDataSet():
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmatian', 'is', 'so', 'cute', 'I', 'love', 'him', 'my'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0, 1, 0, 1, 0, 1]
print("数据集加载完成,样本数量:{},标签数量:{}".format(len(postingList), len(classVec)))
return postingList, classVec
class NBayes(object):
def __init__(self):
self.vocabulary = []
self.idf = []
self.tf = []
self.tdm = 0
self.Pcates = {}
self.labels = []
self.doclength = 0
self.vocablen = 0
self.testset = 0
def cate_prob(self, classVec):
self.labels = classVec
labeltemps = set(self.labels)
for labeltemp in labeltemps:
cate_count = self.labels.count(labeltemp)
self.Pcates[labeltemp] = float(cate_count) / float(len(self.labels))
print("类别先验概率计算完成:")
for cate, prob in self.Pcates.items():
print(f"类别{cate}({'辱骂文本' if cate==1 else '正常文本'})的先验概率P(y={cate}) = {prob:.4f}")
def calc_wordfreq(self, trainset):
self.idf = np.zeros([1, self.vocablen])
self.tf = np.zeros([self.doclength, self.vocablen])
for index in range(self.doclength):
for word in trainset[index]:
self.tf[index, self.vocabulary.index(word)] += 1
for signleword in set(trainset[index]):
self.idf[0, self.vocabulary.index(signleword)] += 1
def build_tdm(self):
self.tdm = np.zeros([len(self.Pcates), self.vocablen])
sumlist = np.zeros([len(self.Pcates), 1])
for index in range(self.doclength):
self.tdm[self.labels[index]] += self.tf[index]
sumlist[self.labels[index]] = np.sum(self.tdm[self.labels[index]])
self.tdm = self.tdm / sumlist
print("\n条件概率矩阵p(x|yi)构建完成,矩阵形状:", self.tdm.shape)
self.plot_tdm()
def calc_tfidf(self, trainset):
self.idf = np.zeros([1, self.vocablen])
self.tf = np.zeros([self.doclength, self.vocablen])
for index in range(self.doclength):
for word in trainset[index]:
self.tf[index, self.vocabulary.index(word)] += 1
self.tf[index] = self.tf[index] / float(len(trainset[index]))
for singleword in set(trainset[index]):
self.idf[0, self.vocabulary.index(singleword)] += 1
self.idf = np.log(float(self.doclength) / self.idf)
self.tf = np.multiply(self.tf, self.idf)
print("TF-IDF特征提取完成,TF矩阵形状:{},IDF向量形状:{}".format(self.tf.shape, self.idf.shape))
def train_set(self, trainset, classVec):
print("\n开始训练朴素贝叶斯分类器...")
self.cate_prob(classVec)
self.doclength = len(trainset)
tempset = set()
[tempset.add(word) for doc in trainset for word in doc]
self.vocabulary = list(tempset)
self.vocablen = len(self.vocabulary)
print("全局词汇表构建完成,词汇数量:{}".format(self.vocablen))
self.calc_tfidf(trainset)
self.build_tdm()
print("分类器训练完成!")
def map2vocab(self, testdata):
self.testset = np.zeros([1, self.vocablen])
for word in testdata:
if word in self.vocabulary:
self.testset[0, self.vocabulary.index(word)] += 1
else:
print(f"警告:测试词汇[{word}]不在词汇表中,已忽略")
print("\n测试文本映射完成,映射后向量形状:", self.testset.shape)
def predict(self, testset):
if np.shape(testset)[1] != self.vocablen:
print('输入错误:测试集向量维度({})与词汇表长度({})不匹配'.format(np.shape(testset)[1], self.vocablen))
exit(0)
predvalue = 0
preclass = ''
print("\n开始计算每个类别的后验概率(P(X|yi)*P(yi)):")
for tdm_vect, keyclass in zip(self.tdm, self.Pcates):
temp = np.sum(testset * tdm_vect * self.Pcates[keyclass])
print(f"类别{keyclass}({'辱骂文本' if keyclass==1 else '正常文本'}):")
print(f" - 条件概率向量长度:{len(tdm_vect)},先验概率:{self.Pcates[keyclass]:.4f}")
print(f" - 后验概率加权值(P(X|y={keyclass})*P(y={keyclass})):{temp:.6f}")
if temp > predvalue:
predvalue = temp
preclass = keyclass
cate_desc = "辱骂文本" if preclass == 1 else "正常文本"
print(f"\n预测结果:测试文本属于类别{preclass}({cate_desc}),后验概率加权值:{predvalue:.6f}")
return preclass, predvalue
def plot_tdm(self):
vocab_top10 = self.vocabulary[:10]
prob_0 = self.tdm[0][:10]
prob_1 = self.tdm[1][:10]
x = np.arange(len(vocab_top10))
width = 0.35
plt.figure(figsize=(12, 6))
plt.bar(x - width/2, prob_0, width, label='正常文本(类别0)', color='skyblue')
plt.bar(x + width/2, prob_1, width, label='辱骂文本(类别1)', color='salmon')
plt.xlabel('词汇', fontsize=12)
plt.ylabel('条件概率 p(x|yi)', fontsize=12)
plt.title('前10个词汇的条件概率对比(正常文本 vs 辱骂文本)', fontsize=14)
plt.xticks(x, vocab_top10, rotation=45)
plt.legend()
plt.tight_layout()
plt.show()
if __name__ == '__main__':
dataSet, listClasses = loadDataSet()
nb = NBayes()
nb.train_set(dataSet, listClasses)
test_doc = dataSet[0]
print("\n测试文本:", test_doc)
nb.map2vocab(test_doc)
result = nb.predict(nb.testset)
print("\n===== 最终预测结果 =====")
print(f"测试文本:{test_doc}")
print(f"预测类别:{result[0]}({'辱骂文本' if result[0]==1 else '正常文本'})")
print(f"后验概率加权值:{result[1]:.6f}")
运行结果
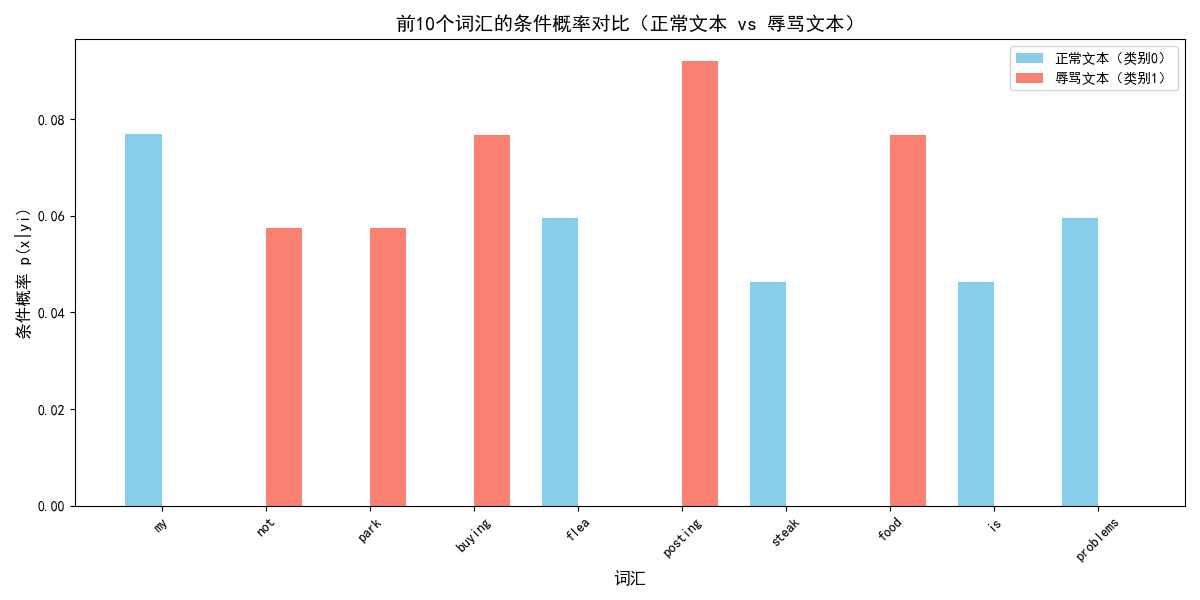
数据集加载完成,样本数量:6,标签数量:6
开始训练朴素贝叶斯分类器...
类别先验概率计算完成:
类别0(正常文本)的先验概率P(y=0) = 0.5000
类别1(辱骂文本)的先验概率P(y=1) = 0.5000
全局词汇表构建完成,词汇数量:32
TF-IDF特征提取完成,TF矩阵形状:(6, 32),IDF向量形状:(1, 32)
条件概率矩阵p(x|yi)构建完成,矩阵形状: (2, 32)
分类器训练完成!
测试文本: ['my', 'dog', 'has', 'flea', 'problems', 'help', 'please']
测试文本映射完成,映射后向量形状: (1, 32)
开始计算每个类别的后验概率(P(X|yi)*P(yi)):
类别0(正常文本):
- 条件概率向量长度:32,先验概率:0.5000
- 后验概率加权值(P(X|y=0)*P(y=0)):0.198850
类别1(辱骂文本):
- 条件概率向量长度:32,先验概率:0.5000
- 后验概率加权值(P(X|y=1)*P(y=1)):0.025933
预测结果:测试文本属于类别0(正常文本),后验概率加权值:0.198850
===== 最终预测结果 =====
测试文本:['my', 'dog', 'has', 'flea', 'problems', 'help', 'please']
预测类别:0(正常文本)
后验概率加权值:0.198850
进程已结束,退出代码为 0


















 2879
2879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










