



目录
简介
高并发和大数据量下需要实现一下几个业务场景
1、内容的点赞总数
2、内容是否被当前用户点赞
列表展示:
1、内容的点赞用户列表
2、用户的内容点赞列表
架构设计
1、流量路由层(决定流量应该去往哪个机房)
2、业务网关层(统一鉴权、反黑灰产等统一流量筛选)
3、点赞服务(thumbup-service),提供统一的RPC接口
4、点赞异步任务(thumbup-job):
点赞数据写入、刷新缓存、为下游其他服务发送点赞、点赞数消息等功能
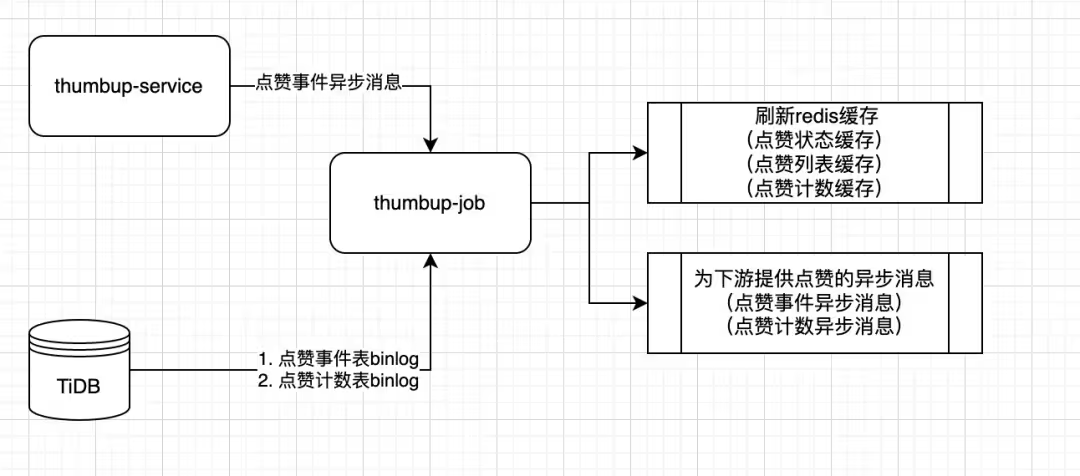
5、数据层(db、kv、redis)
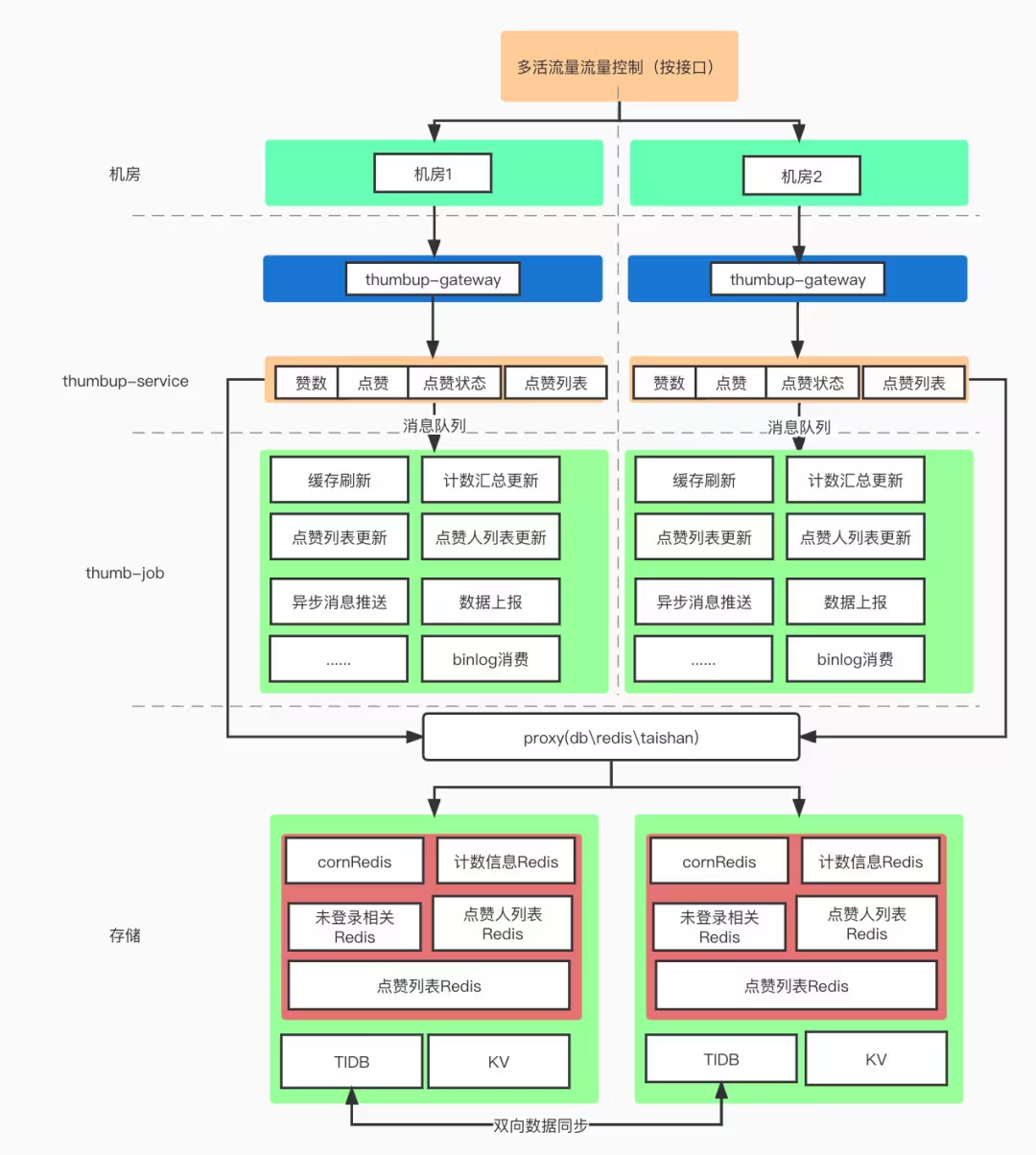
判断是否点赞:
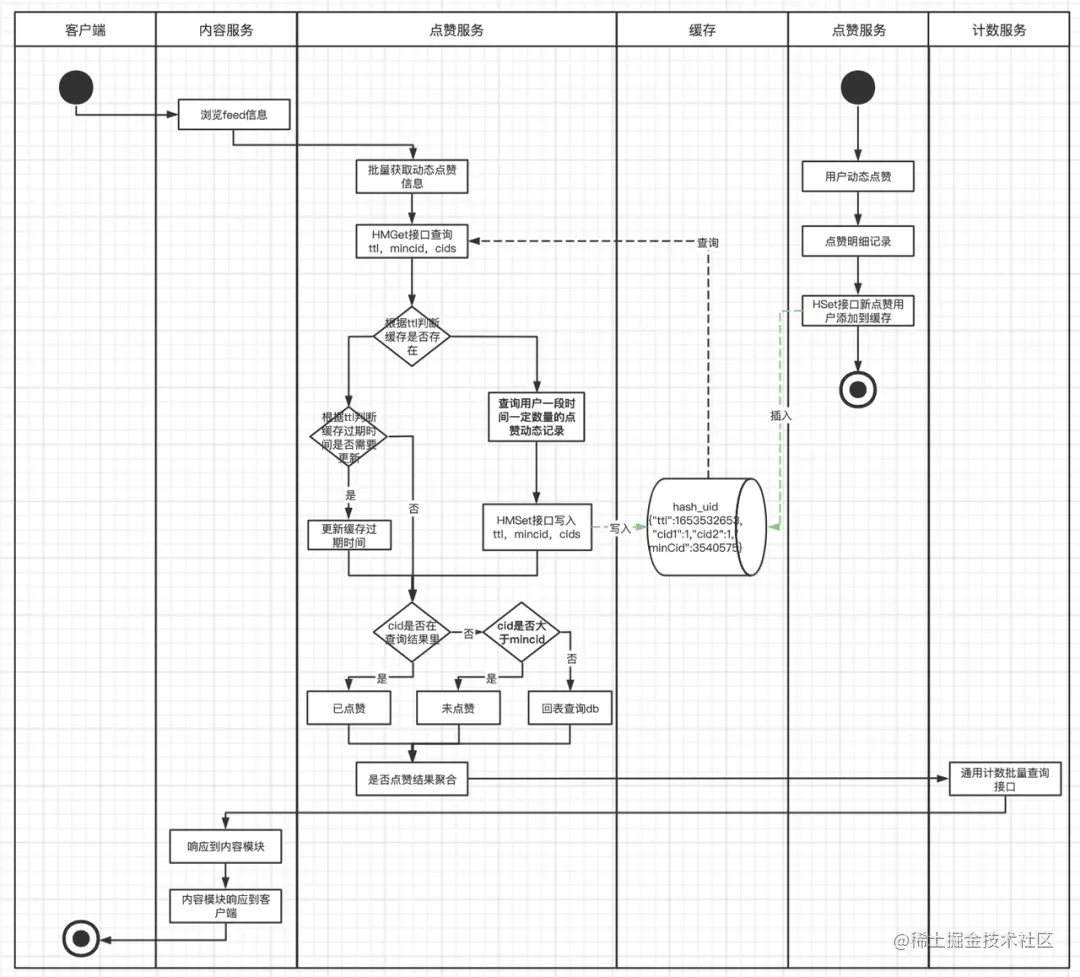
缓存设计
缓存更新:在缓存维护上,每次有新增点赞时,主动向zset集合中添加用户ID,并更新缓存过期时间。每次查询时,也同样会查询缓存的剩余过期时间,如果低于三分之一,就会重新更新过期时间,这样避免了热门动态有大量新增点赞动作时,出现缓存击穿的情况
1、redis缓存
缓存结构设计:
- 内容key(zset):存储内容的点赞用户,按user_id进行切片处理
- 用户key(hash):用来判断内容该用户是否点赞。
- redis缓存key举例说明:
1、点赞关系存储
//记录内容被哪些用户点赞了(内容点赞历史)
String likeKey = "like:content:" + contentId; // ZSet<userId,timestamp>
//用户点赞了哪些内容(用户点赞历史、是否点赞某些内容)
String userLikeKey1 = "user:like:" + userId; // Zset<contentId, timestamp>
2、点赞数设计
String countKey = "count:content:" + contentId; // String 计数
String hotKey = "hot:content"; // ZSet热门排行
3、考虑到内容点赞记录都要存储到redis zset,且feed流批量查询会增加并发量,可以考虑使用redis Map结构进行数据存储
(判断是否点赞某些内容)
{
"userId":{
"ttl":1653532653, //缓存新建或更新时时间戳
"cid1":1, //用户近一段时间点赞过的动态id
"cid2":1, //用户近一段时间点赞过的动态id
"cidn":1, //用户近一段时间点赞过的动态id
"minCid":3540575, //缓存中最小的动态id,用以区分冷热数据,
}
}
4、key格式参考
# 基础格式(无哈希分片)
zset:like:vid:{视频ID}:ts:{时间窗口}
# 叠加哈希分片(爆火视频)
zset:like:vid:{视频ID}:ts:{时间窗口}:shard:{分片ID}2、大key问题
解析:内容redisKey可能被很多用户点赞,存在大key问题
解决方案:
- 对大Key按user_id进行打散处理,所有视频固定100个分片,便于架构统计管理。
- 按照固定长度裁剪用户的点赞记录缓存,超过该长度的数据请求需要回源DB查询。
- 打散分片再维护到缓存,每次操作缓存时先通过缓存key配置地址拿到分片key,这样每个分片都具有更小的体积和更快的维护和响应速度。
contentid1_slice1 => [uid1,uid11,uid111...]
contentid1_slice2 => [uid2,uid22,uid222...]
contentid1_slice3 => [uid3,uid33,uid333...]
注意:
- 所有视频,无论冷热,ZSet 全部统一分片,没有例外。分片不是为了解决 “量大”,而是为了 “架构安全 + 冷转热无迁移”
- 为了避免数据量过大,需要在每一次加入新的点赞记录的时候,按照固定长度裁剪用户的点赞记录缓存
3、热点key问题
多级缓存进行处理,利用最小堆算法,在可配置的时间窗口范围内,统计出访问最频繁的缓存Key,并将热Key(Value)按照业务可接受的TTL存储在本地内存中。
4、举例查询视频点赞用户(第二页数据)
// 1、批量查询所有分片的候选数据(Pipeline减少网络IO)
List<Set<ZSetOperations.TypedTuple<String>>> shardResults = redisTemplate.executePipelined((RedisCallback<Object>) connection -> {
for (int shard = 0; shard < 100; shard++) {
String zsetKey = String.format("video:%s:like:zset:%d", videoId, shard);
// ZREVRANGEBYSCORE key max min LIMIT offset count
// max=lastCursor(上一页最后一条的score),min=0,offset=0,count=20
connection.zRevRangeByScoreWithScores(
zsetKey.getBytes(),
String.valueOf(lastCursor).getBytes(),
"0".getBytes(),
0, 20
);
}
return null;
});
//2、多路归并排序(简化版,生产用优先队列PriorityQueue优化)
private List<ZSetOperations.TypedTuple<String>> mergeShardResults(List<Set<ZSetOperations.TypedTuple<String>>> shardResults) {
List<ZSetOperations.TypedTuple<String>> globalList = new ArrayList<>();
for (Set<ZSetOperations.TypedTuple<String>> shardData : shardResults) {
if (shardData != null && !shardData.isEmpty()) {
globalList.addAll(shardData);
}
}
// 按score降序排序(即点赞时间从新到旧)
globalList.sort((a, b) -> Double.compare(b.getScore(), a.getScore()));
return globalList;
}
//3、截取第二页数据(第一页0~19,第二页20~39)
int secondPageStart = pageSize;
int secondPageEnd = secondPageStart + pageSize - 1;
List<Long> secondPageUserIds = new ArrayList<>();
Long nextCursor = null;
for (int i = secondPageStart; i <= secondPageEnd && i < globalSortedList.size(); i++) {
ZSetOperations.TypedTuple<String> tuple = globalSortedList.get(i);
secondPageUserIds.add(Long.parseLong(tuple.getValue()));
if (i == Math.min(secondPageEnd, globalSortedList.size() - 1)) {
nextCursor = tuple.getScore().longValue();
}
}
//4、Redis数据不足,兜底查MySQL
if (secondPageUserIds.size() < pageSize) {
// 转换cursor为时间戳:timestamp = Long.MAX_VALUE - lastCursor
long maxCreateTime = Long.MAX_VALUE - lastCursor;
int needCount = pageSize - secondPageUserIds.size();
// 从MySQL分页查询:按点赞时间倒序,取小于maxCreateTime的前needCount条
List<Long> dbUserIds = likeMapper.selectLikeUsersByVideoIdAndTime(
videoId, maxCreateTime, needCount
);
secondPageUserIds.addAll(dbUserIds);
// 补缓存(临时缓存1小时,避免重复查库)
cacheUserIdsToRedis(videoId, dbUserIds);
// 更新下一页cursor(若有数据库数据)
if (!dbUserIds.isEmpty()) {
// 取数据库最后一条的时间戳,转换为score
long lastDbTimestamp = likeMapper.getLastCreateTimeByUserIds(videoId, dbUserIds);
nextCursor = Long.MAX_VALUE - lastDbTimestamp;
}
}
return new PageResult(secondPageUserIds, nextCursor);
5、过期和归档策略(举例:100万点赞,高并发场景)
1、写入原子截断,原子化控制单分片≤1000 条
- 点赞单分片上限 1000 条(用户翻页需求少,核心看 “是否点赞”);
- 评论单分片上限 2000 条(用户翻评论列表更深,留存略多)。
-- KEYS[1] = 分片ZSet Key;ARGV[1] = userId;ARGV[2] = 倒序score;ARGV[3] = 单分片上限(1000);ARGV[4] = TTL(按热度定)
-- 1. 原子写入点赞数据
redis.call('ZADD', KEYS[1], ARGV[2], ARGV[1])
-- 2. 原子检查并截断:超过1000条则删除旧数据(只留最新1000条)
local card = redis.call('ZCARD', KEYS[1])
if card > tonumber(ARGV[3]) then
redis.call('ZREMRANGEBYRANK', KEYS[1], tonumber(ARGV[3]), -1) -- 删除rank≥1000的元素(旧数据)
end
-- 3. 原子设置TTL(分层过期)
redis.call('EXPIRE', KEYS[1], ARGV[4])
return 12、分层 TTL 过期(自动淘汰冷数据)
给不同热度的数据设置差异化过期时间,让 Redis 自动淘汰低价值数据,无需人工干预
- 写入时:根据数据的 “创建时间 / 访问频次” 计算 TTL,传入 Lua 脚本;
- 巡检修正:每小时轻量扫描分片,对 TTL 不合理的(如核心热数据 TTL<7 天)自动修正,避免误淘汰。
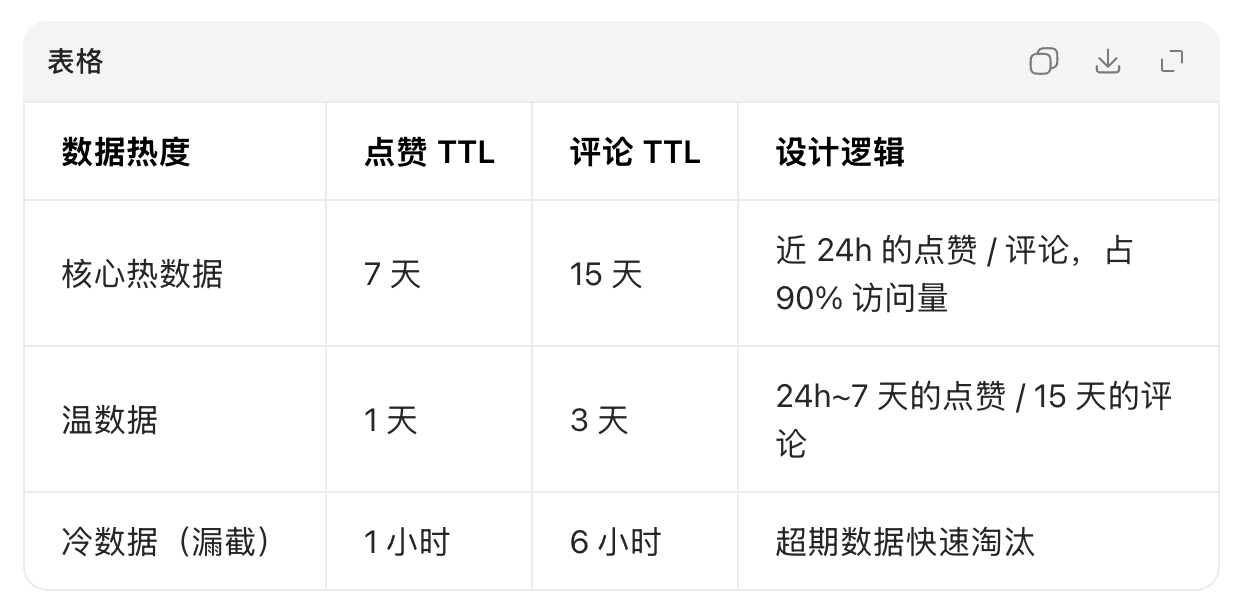
3、低峰定时冷数据清理(低峰期兜底)
- 每天凌晨2点,扫描的热门视频,把7天前的点赞数据删除
- 前两层可覆盖 99% 的淘汰场景,再通过凌晨低峰期(2:00-4:00)的定时任务做兜底,确保分片绝对合规,且不影响白天高并发。
- 违代码:
// 1. 筛选需清理的热门视频(100万+点赞)
List<Long> hotVideoIds = videoService.listHotVideo(100_0000);
for (Long videoId : hotVideoIds) {
for (int shard = 0; shard < 100; shard++) { // 遍历100个分片
String zsetKey = String.format("video:%s:like:zset:%d", videoId, shard);
// 清理逻辑1:删除7天前的冷数据(score阈值 = Long.MAX_VALUE - 7天前时间戳)
long sevenDaysAgo = System.currentTimeMillis() - 7L*24*3600*1000;
double scoreThreshold = Long.MAX_VALUE - sevenDaysAgo;
redisTemplate.opsForZSet().removeRangeByScore(zsetKey, 0, scoreThreshold);
// 清理逻辑2:冷分片收缩(7天无访问的分片)
Long idleTime = (Long) redisTemplate.execute((RedisCallback<Long>) conn ->
conn.objectIdleTime(zsetKey.getBytes()) // 获取分片空闲时间(秒)
);
if (idleTime != null && idleTime > 604800) { // 7天无访问
redisTemplate.opsForZSet().removeRange(zsetKey, 500, -1); // 收缩到500条/分片
redisTemplate.expire(zsetKey, 12, TimeUnit.HOURS); // 缩短TTL加速淘汰
}
}
}4、redis统一进行lru内存淘汰策略
5、冷数据分层处理
- 当用户翻到缓存外的分页(如第 50 页后),直接从 ClickHouse查询。
- 发布超过 30 天的视频,Redis 中仅保留 “点赞数计数器”,点赞列表直接从 ClickHouse 查询。
高并发场景引对策略设计(读300k 写15k)
1、写入【点赞数】数据的时,在内存中做部分聚合写入,比如聚合10s内的点赞数,再一次性写入
2、点赞操作采用异步处理(写缓存+发消息+异步持久化)
- 写缓存:先更新Redis中的用户点赞关系(Hash添加元素)、点赞计数(String自增)、用户点赞列表(ZSet添加元素)
- 发消息:发送点赞事件(包含用户ID、实体类型、实体ID、时间戳),实现业务解耦(点赞服务无需等待数据库持久化完成)
- 写数据库:消费消息队列中的点赞事件,将数据写入分布式数据库(如TiDB),失败重试
3、对强一致性场景(如电商订单的点赞奖励),采用分布式事务框架(如Seata),实现Redis与数据库的原子操作(如点赞成功后,同时更新Redis计数与数据库奖励积分)。
数据库设计
Redis 作为缓存
数据库层面:Mysql存储近一年数据,clickhouse存储点赞归档数据,TIDB考虑大数据量下可以替代MySQL进行使用。
稳定性设计
- redis-->KV数据库-->TIDB
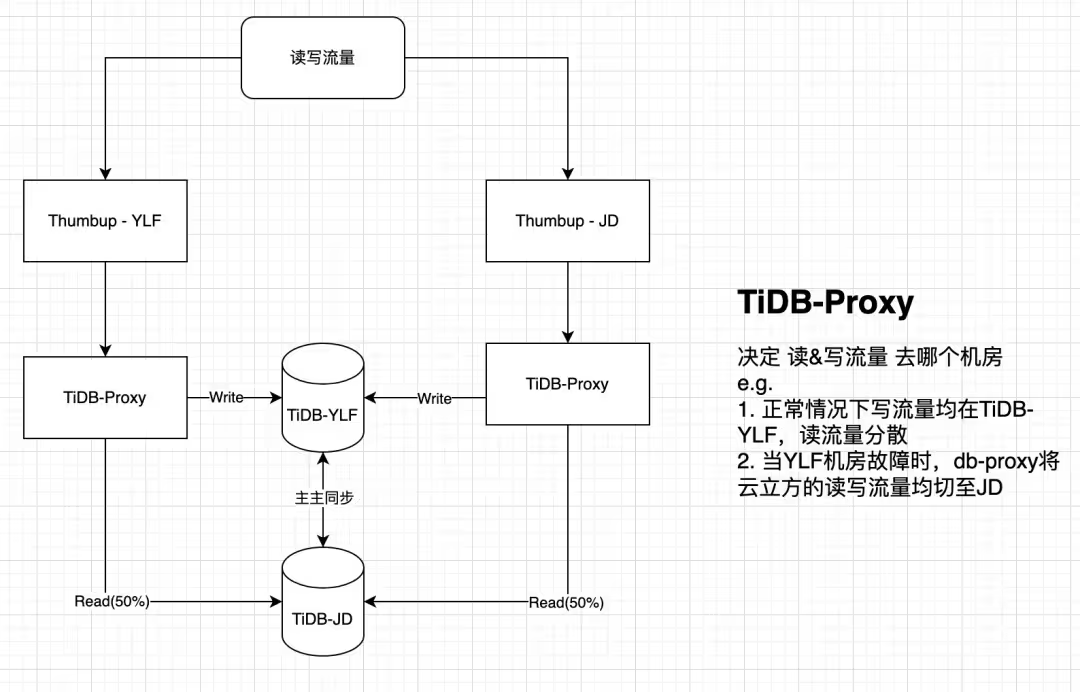
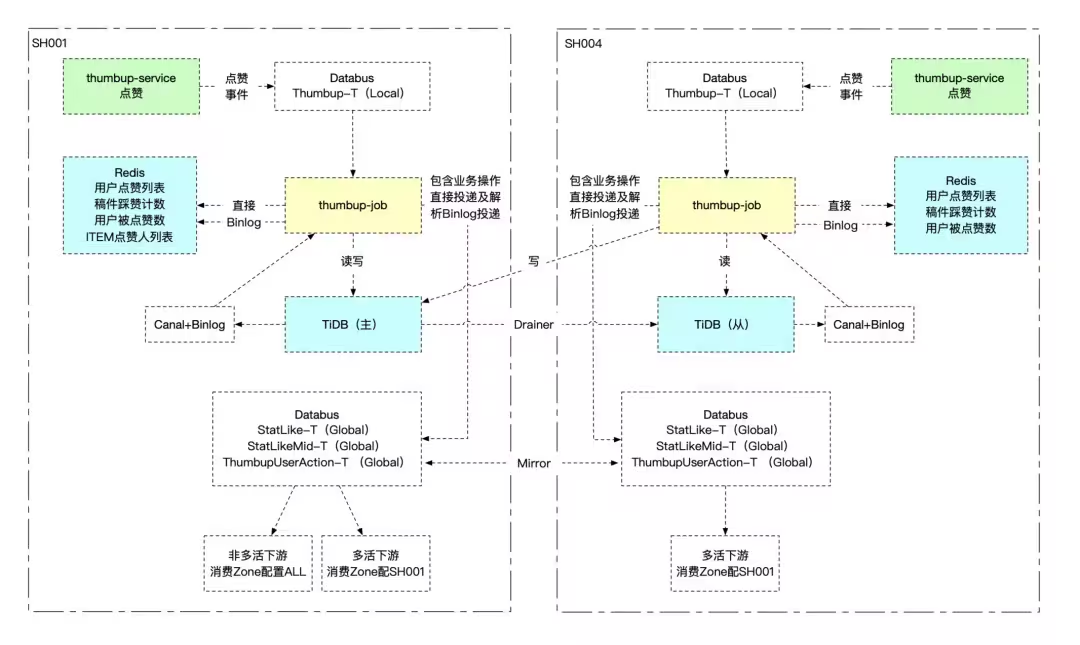
- 服务部署异地多活,数据库分别负责:读写(上海机房)、读流量(杭州机房)。
参考:
点赞设计(得物)
https://juejin.cn/post/7124511400948400142
点赞设计(B站)
https://www.bilibili.com/read/cv21576373/?opus_fallback=1
https://blog.csdn.net/zhaozhiqiang1981/article/details/141072196b



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










