




更大的标注数据集和更多可用的计算能力是AI革命的基石。在本文中,我列出了我们最近为数据科学家发现的一些非常好玩的深度学习数据集。
1. EMNIST: An Extension of MNIST to Handwritten Letters
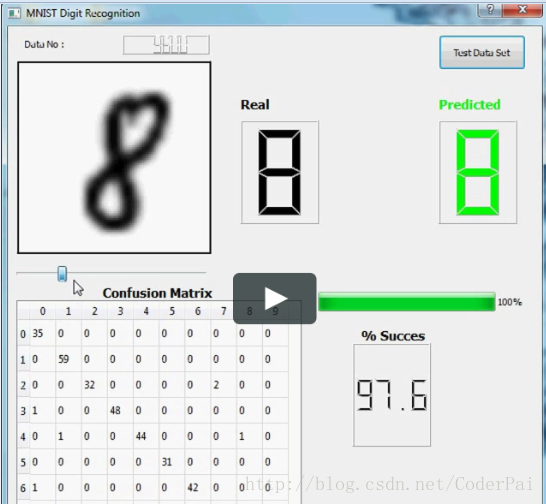
MNIST is a very popular dataset for people getting started with Deep Learning in particular and Machine Learning on images in general. MNIST has images of digits which are to be mapped to the digits themselves. EMNIST extends this to images of letters as well. The dataset can be downloaded here . There is an alternative dataset we discovered as well on Reddit. It’s called HASYv2 and can be downloaded here

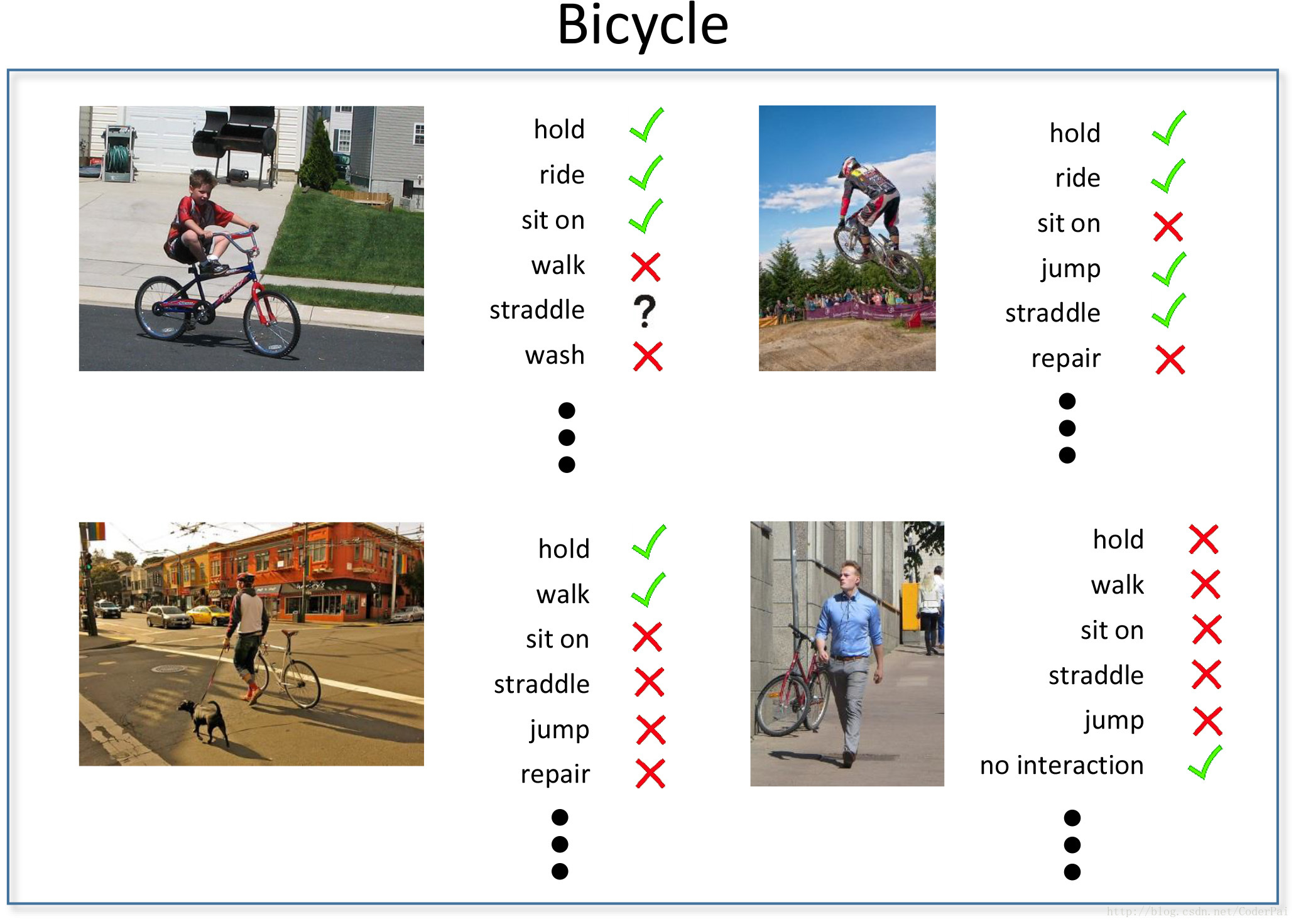
HICO has images containing multiple objects and these objects have been tagged along with their relationships. The proposed problem is for algorithms to be able to dig out objects in an image and relationship between them after being trained on this dataset. I expect multiple papers to come out of this dataset in future.
3. CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning

CLEVR is an attempt by Fei-Fei Li’s group, the same scientist who developed the revolutionary ImageNet dataset. It has objects and questions asked about those objects along with their answers specified by humans. The aim of the project is to develop machines with common sense about what they see. So for example, the machine should be able to find “an odd one out” in an image automatically. You can download the dataset here.
4. HolStep: A Machine Learning Dataset for Higher-order Logic Theorem Proving

This dataset is tagged in a way so that algorithms trained on it can be used for automatic theorem proving . The download link is here.

The Parallel Meaning Bank (PMB), developed at the University of Groningen, comprises sentences and texts in raw and tokenised format, tags for part of speech, named entities and lexical categories, and formal meaning representations. The download link is here.
6. JFLEG: A Fluency Corpus and Benchmark for Grammatical Error Correction
JFLEG dataset is an aim to tag sentences with nominal grammatical corrections and smart grammatical corrections. This dataset aims to build machines that can correct grammar automatically for people making mistakes. The dataset can be downloaded here.
7. Introducing VQA v2.0: A More Balanced and Bigger VQA Dataset!
This dataset has images, questions asked on them and their answers tagged. The aim is to train machines to answer questions asked about images (and in continuation about the real world they are seeing). Visual QA is an old dataset but its 2.0 version came out just this december.

8. Google Cloud & YouTube-8M Video Understanding Challenge

Probably the largest dataset available for training in the open. This is a dataset of 8 Million Youtube videos tagged with the objects within them. There is also a running Kaggle competition on the dataset with a bounty of 1,00,000 dollars.

This turns out to be the largest bounty offered to crack a Data Science problem. There are prizes of $1 Million to be grabbed by Data Scientists who can detect lung cancer using this dataset of tagges CT-Scans.

Today, a team that includes MIT and is led by the Carnegie Institution for Science has released the largest collection of observations made with a technique called radial velocity, to be used for hunting exoplanets. The dataset can be downloaded here.
11. End-to-End Interpretation of the French Street Name Signs Dataset

This is a huge dataset of French Street signs labeled with what they denote. The dataset is easily readable by everyone’s favorite Tensorflow and can be downloaded here.
12. A Realistic Dataset for the Smart Home Device Scheduling Problem for DCOPs
An upcoming dataset for IoT and AI interface. You can download it here.
From Sam Bowman’s team, the creators of the famous SNLI dataset, this dataset about understanding the meaning of the text is going to be out soon as a competition. The dataset is expected by 15th March. You can find it here once it’s live.
A 200 Gb huge dataset, which is aimed to calculate speed of moving vehicles. Can be downloaded here.
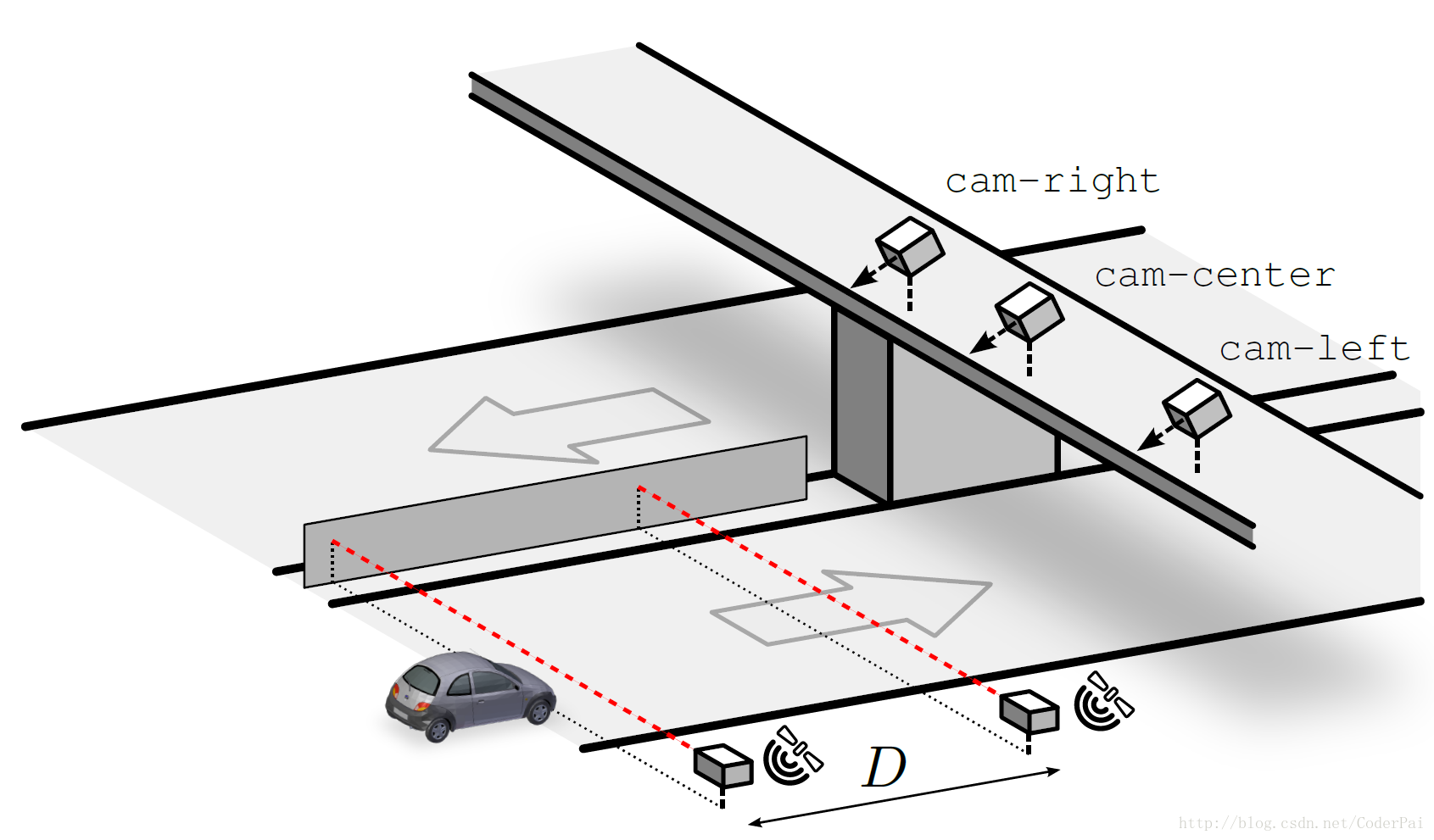
15. NWPU-RESISC45 Remote sensing images dataset
A huge dataset of remote sensing images covering a wide array of landscapes which can be seen through sattelites. Potential technology that can be developed includes satellite surveys, monitoring, and surveillance. Unfortunately, we are still waiting for the download link here.

16. Recipe to create your own free datasets from the open web
This is probably the most interesting of the datasets. This dataset has not been tagged by humans but by machines. Also, the authors make things clear about what is to be done if we want to create a similar dataset from the millions of images which are already available on the web.
This large-scale data set focuses on the semantic understanding of a person. The download link for the dataset is here.
This dataset is a large-scale natural language understanding task and publicly-available dataset with 18 million instances. The downlaod link is here.
MUSCIMA++ is a dataset of handwritten music notation for musical symbol detection. Here is the download link.
20. DeScript (Describing Script Structure)
DeScript is a crowdsourced corpus of event sequence descriptions (ESDs) for different scenarios crowdsourced via Amazon Mechanical Turk. Here is the download link.
Reference:
http://blog.paralleldots.com/data-scientist/new-deep-learning-datasets-data-scientists/
如果觉得内容有用,帮助多多分享哦 :)
长按或者扫描如下二维码,关注 “CoderPai” 微信号(coderpai)。添加底部的 coderpai 小助手,添加小助手时,请备注 “算法” 二字,小助手会拉你进算法群。如果你想进入 AI 实战群,那么请备注 “AI”,小助手会拉你进AI实战群。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










