



 该博客介绍了对Airbnb用户数据的预处理和分群分析。首先进行了数据清洗,如年龄异常值处理,将日期转换为时间间隔,将性别变量转化为哑变量,并删除日期列。接着,利用KMeans进行用户分群,通过散点图展示分群结果,并对模型效果进行评估。最后,分析了不同群体在年龄、使用设备上的特征差异。
该博客介绍了对Airbnb用户数据的预处理和分群分析。首先进行了数据清洗,如年龄异常值处理,将日期转换为时间间隔,将性别变量转化为哑变量,并删除日期列。接着,利用KMeans进行用户分群,通过散点图展示分群结果,并对模型效果进行评估。最后,分析了不同群体在年龄、使用设备上的特征差异。
目录
本例中将使用Airbnb的数据。Airbnb是一个旅行服务短期租赁的社区,它拥有广泛的用户出行场景数据,通过这些数据,锁定潜在的目标客群并制定相应的营销策略是Airbnb业务发展的基石。
第一部:导包和数据导入
#调包
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline#数据导入
airbnb=pd.read_csv('w3_airbnb.csv')
airbnb.head()字典数据及解释:
- id:唯一的用户id
- date_account_created:用户创建时间
- date_first_booking:第一次订房日期
- gender:性别
- Age:年龄
- Married:已婚
- Children:小孩数量
- Android:曾在安卓App中预定
- Moweb:曾在手机移动网页中预定
- web:曾在电脑网页版预定
- ios:曾在iso app预定
- Language_EN:使用英文语言
- Language_ZH:使用中文语言
- Country_US:目的地是美国
- Country_EUR:目的地是欧洲国家
导入数据后,我们可以看到,数据中有两个日期,一个是用户注册日期,一个是订房日期,然后还有用户个人信息,渠道信息和基本的网页使用信息。这三类基本信息的分析即可以帮助我们分析人群的基本特征。
本案例中,我们依然遵循数据分析的基本流程,如下所示:
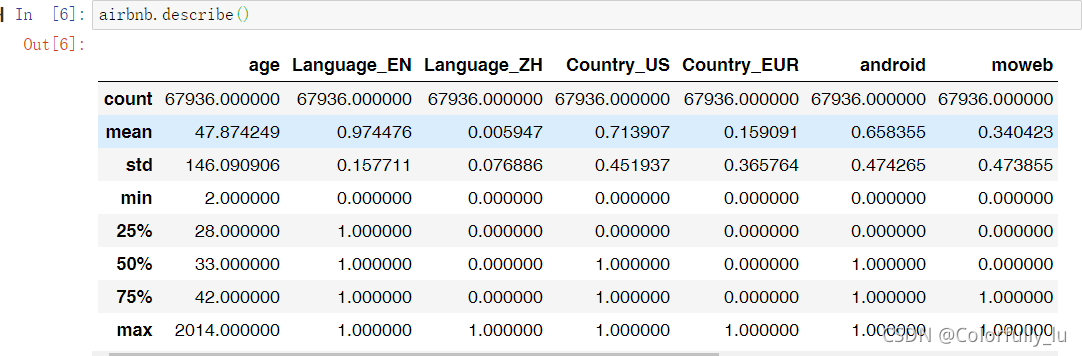
在使用info()和describe()函数查看数据之后,我们发现值得注意的点:
- date_account_created和date_first_booking是时间变量,需要做调整
- gender是字符型变量,同样需要调整
- 我们数据中的gender包括F(Female)和M(Male),在很多时候,网站为了尊重客户隐私,还会出现U,就是unknown
1.数据清洗:
1.1年龄清洗
 发现年龄最小为2,最大为2014,属于异常数据,进行数据清洗,这里保留用户年龄在18-80岁之间的群体。
发现年龄最小为2,最大为2014,属于异常数据,进行数据清洗,这里保留用户年龄在18-80岁之间的群体。
airbnb=airbnb[airbnb['age']>=18]
airbnb=airbnb[airbnb['age']<=80] 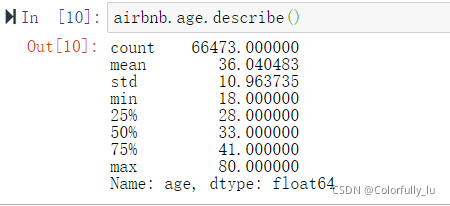
1.2类别型变量(日期)的调整
计算用户注册到2019年的时间
第一步:将注册日期转变成日期时间格式
airbnb['date_account_created']=pd.to_datetime(airbnb['date_account_created'])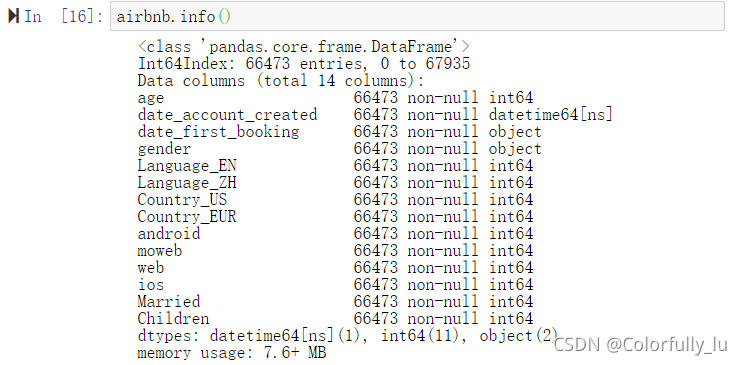
第二步:将年份从中提取出来,将2019-注册日期的年份,并生成一个新的变量year_since_account_created
airbnb['year_since_account_created']=airbnb['date_account_created'].apply(lambda x:2019-x.year)airbnb.year_since_account_created.describe()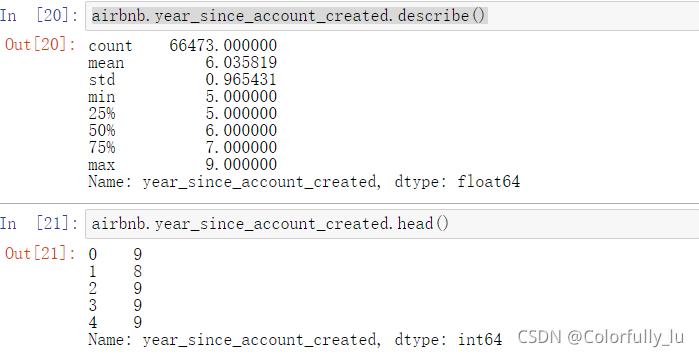
发现注册时间最短的是5年,最长的是9年。
计算用户第一次预定到2019年的时间
第一步:将用户第一次预定时间转变成日期时间格式
airbnb['date_first_booking']=pd.to_datetime(airbnb['date_first_booking'])第二步:将年份从中提取出来,将2019-第一次预定的年份,并生成一个新的变量 year_since_first_booking
airbnb['year_since_first_booking']=airbnb['date_first_booking'].apply(lambda x:2019-x.year)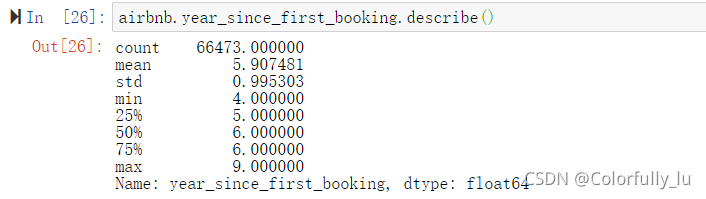
发现距离第一次预定时间最短的是4年,最长的是9年。
1.3将性别型变量转化成哑变量(gender)
airbnb=pd.get_dummies(airbnb)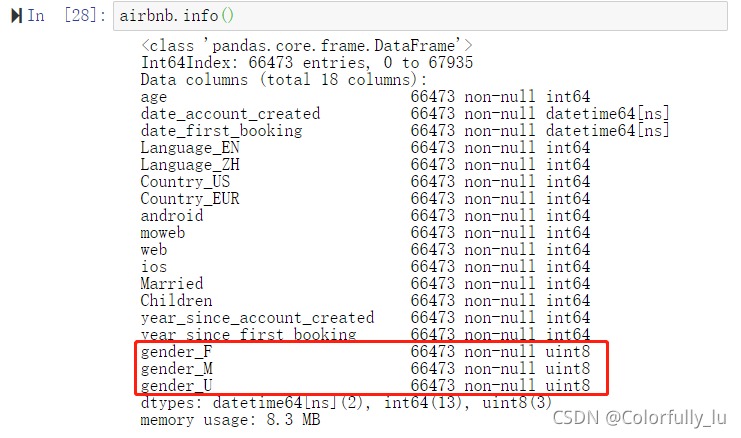
1.4删除2个日期变量,可以根据数据类型来进行drop
airbnb.drop(airbnb.select_dtypes(['datetime64']),inplace=True,axis=1)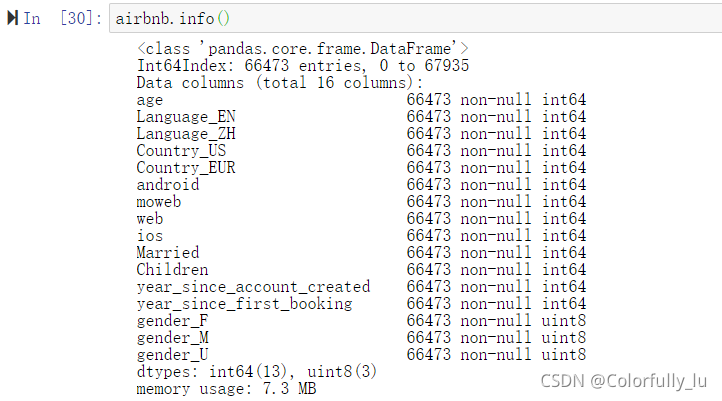
已经没有日期的两列数了 。
2.建立模型
选择5个变量,作为分群的维度
airbnb_5=airbnb[['age','web','moweb','ios','android']]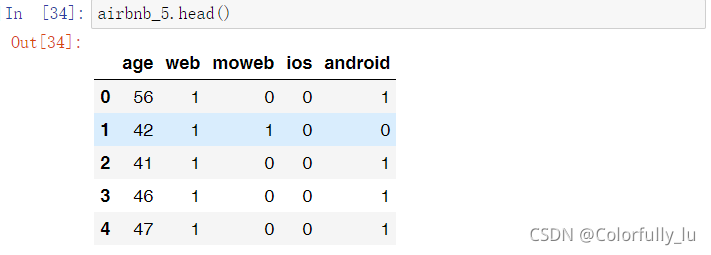
数据标准化,使用sklearn中预处理的scale
from sklearn.preprocessing import scale
x=pd.DataFrame(scale(airbnb_5))建立模型
使用cluster建模
from sklearn import cluster先尝试分为3段
model=cluster.KMeans(n_clusters=3,random_state=10)
model.fit(x) 提取标签,查看分类结果
提取标签,查看分类结果
airbnb_5['cluster']=model.labels_ 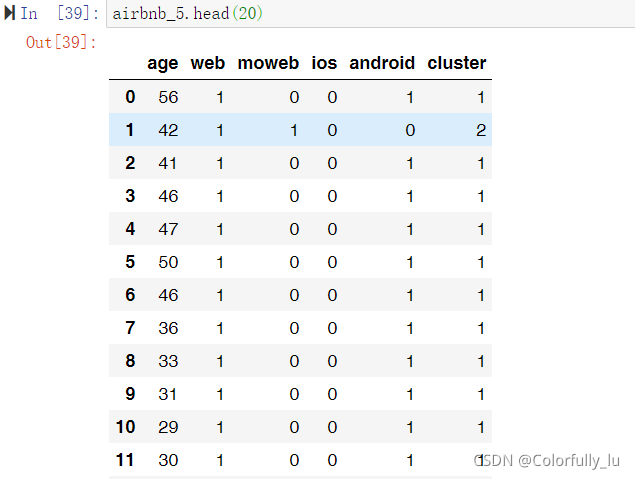
绘制散点图,查看分群结果
横坐标为age(年龄),纵坐标为ios(是否使用ios客户端),类别为分类
sns.scatterplot(x='age',y='ios',hue='cluster',data=airbnb_5)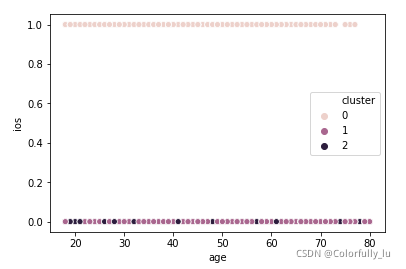
3.模型评估与优化
使用groupby函数,评估各个变量维度的分群效果
airbnb_5.groupby(['cluster'])['age'].describe()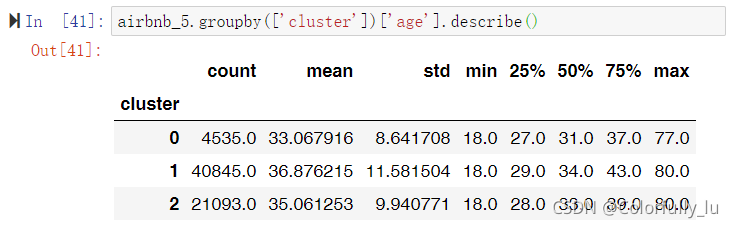
airbnb_5.groupby(['cluster'])['ios'].describe() 
使用silhouette score评估模型效果
from sklearn import metrics#调用sklearn的metrics库
x_cluster=model.fit_predict(x)#个体与群的距离
score=metrics.silhouette_score(x,x_cluster)#评分越高,个体与群越近;评分越低,个体与群越远
centers=pd.DataFrame(model.cluster_centers_)
centers.to_csv('center_3.csv')将群体分成5组
model=cluster.KMeans(n_clusters=5,random_state=10)
model.fit(x)centers=pd.DataFrame(model.cluster_centers_)centers.to_csv('center_5.csv')导出结果到csv
1.理解行和列
行:每一行是系统认为的群组,即0群,1群,2群;
列:重点关注每一列的数据,标注出绝对值较大的数字,如果人群在某个特征变量上数据的绝对值较大,就说明这个群在这个特征上有较明显的区分度
2.结合业务,解读每个群组的特征
例如:下图中0群大多通过H5页面下单,不适用App;2群可能是果粉,是ios重度用户,不怎么使用web




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










