




第 8 章 图像压缩与水印
(Image Compression and Watermarking)
目录
8.1.2 空间和时间冗余(Spatial and Temporal Redundancy)
8.1.3 无关信息(Irrelevant information)
8.1.4 度量图像信息(Measuring Image information)
8.1.5 保真度标准(Fidelity Criteria)
8.1.6 图像压缩模型(Image Compression Models)
8.1.6.1 编码或压缩过程(The Encoding or Compression Process)
8.1.6.2 解码或解压缩过程(The Decoding or Decompression Process)
8.1.7 图像格式、容器和压缩标准(Image Formats, Containers , and Compression Standards)
8.4.1 自适应上下文相关概率估计(Adaptive Context Dependent Probability Estimates)
8.6.1 一维CCITT 压缩(One-Dimensional CCITT Compression)
8.6.2 二维CCITT 压缩(Two-Dimensional CCITT Compression)
8.7 基于符号的编码(Symbol-Based Coding)
8.7.1 JBIG2 压缩(JBIG2 Compression)
8.9 块变换编码(Block Transform Coding)
8.9.1 变换选择(Transform Selection)
8.9.2 子图像大小选择(Subimage Size Selection)
8.9.3.1 区域编码实现(Zonal Coding Implementation)
8.9.3.2 阈值编码实现(Threshold Coding Implementation)
8.9.4 JPEG编码标准(Joint Photographic Experts Group)
导读(Preview)
图像压缩是减少表示图像所需数据量的技术,它是数字图像处理领域中最实用、商业上最成功的技术之一。每天被压缩和解压缩的图像数量惊人,而压缩和解压缩过程对用户来说几乎是无感的。每个拥有数码相机、浏览网页或通过互联网观看最新好莱坞(Hollywood)电影的人都受益于本章将要讨论的算法和标准。本章内容主要为入门级知识,适用于静态图像和视频应用。我们将介绍理论和实践两方面的内容,探讨最常用的压缩技术,并描述使这些技术得以应用的行业标准。本章最后将介绍数字图像水印技术,即在图像中嵌入可见或不可见的数据(例如版权信息)。
8.1 基础知识(Fundamentals)
数据压缩是指减少表示给定信息量所需数据量的过程。在这个定义中,数据和信息并非同一概念;数据是传递信息的载体。由于可以使用不同数量的数据来表示相同的信息量,
因此,包含无关或重复信息的表示形式视为包含冗余数据(redundant data)。如果我们用 b 和 分别表示同一信息的两种表示形式中的二进制位数(或携带信息单位数),则包含 b 个二进制位的表示形式的相对数据冗余度(Relative data redundancy) R 为
(8-1)
其中,C (通常称为压缩比(Compression ratio))定义为
(8-2)
例如,若 C = 10 (有时候记为 10:1),则较小表示形式用 1 位表示的数据,较大表示形式需要用 10 位数据来表示。较大表示形式对应的相对数据冗余度为 0.9 ( R = 0.9 ),表明其 90% 的数据是冗余的。
在数字图像压缩领域,公式 (8-2) 中的 b 通常表示将图像表示为二维强度值数组所需的位数。第 2.4 节介绍的二维强度数组是人类观看和理解图像的首选格式,也是衡量所有其他表示方法的标准。然而,就图像的紧凑表示而言,这些格式远非最佳。二维强度数组存在三种主要类型的数据冗余,这些冗余可以识别并加以利用:
(1) 编码冗余(coding redundancy)。一种编码是一种符号系统(例如字母、数字、二进制位等),用于表示信息或事件集合。每一条信息或每一个事件都赋予一串代码符号(code symbols),称为码字(code word)。每一个码字中的符号数量称为码字长度(length)。大多数二维强度数组中用于表示强度的 8 位编码所包含的位数比实际表示强度所需的位数要多。
(2) 空间和时间冗余(spatial and temporal redundancy)。由于大多数二维强度数组的像素在空间上是相关的(即每一个像素与相邻像素相似或相互依赖),因此相关像素的表示中存在不必要的信息冗余。在视频序列中,时间上相关的像素(即与相邻帧中的像素相似或相互依赖的像素)也会导致信息重复。
(3) 无关信息冗余(irrelevant information)。大多数二维强度数组包含的信息要么会被人类视觉系统忽略,要么与图像的预期用途无关。从使用的角度来看,这些信息是冗余的(译注:未用到,或未产生价值)。
图 8.1(a) 至 (c) 中的计算机生成图像展示了这些基本冗余。正如接下来的三节所示,当一种或多种冗余可以减少或消除时,即可实现压缩。

-----------------------------图 8.1:计算机生成了 256 × 256 × 8 位的图像,这些图像分别包含 (a) 编码冗余、(b) 空间冗余和 (c) 无关信息。(每一幅图像的设计初衷是展示一种主要的冗余类型,但可能也包含其他类型的冗余。)------------------------
8.1.1 编码冗余(Coding Redundancy)
在第三章中,我们假设图像的像素强度值是随机变量,并基于直方图处理技术开发了图像增强方法。在本节中,我们将采用类似的公式来介绍最优信息编码。
假设在区间 [0, L - 1] 内的离散随机变量 用于表示 M × N 图像的像素强度,并且每个
出现的概率为
。 同第 3.3 节中的那样,有
(8-3)
其中,L 是强度值数量,而 是出现在图像中的第 k 个强度值的次数。若用于表示
的每一个值是
,则所要求的表示每一个像素的平均位数是
(8-4)
即,分配给各种强度值的码字的平均长度是通过将表示每一种强度所需的位数与该强度出现的概率相乘,然后将所有乘积相加得到的。表示 M × N 图像所需的总位数是 。如果强度值用 m 位的自然定长编码表示(注:自然二进制编码是指将每一个待编码的事件或信息(例如强度值)分配给一个 m 位二进制计数序列中的
个编码之一),则公式 (8-4) 的右侧简化为 m 位。也就是说,当用 m 代替
时,
。常数 m 可以移到求和符号外面,只剩下对
从 0 到 L - 1 的求和,而这个求和当然等于1 。
例子 8.1:变长编码的一个简单例释。
图 8.1(a) 中的计算机生成图像的强度分布如表 8.1 第二列所示。如果使用自然 8 位二进制码(在表 8.1 中记为编码 1 ) 来表示其四种可能的强度,则 ( 代码 1 的平均位数)为 8 位,因为对于所有
位 。另一方面,如果使用表 8.1 中指定为编码 2 的方案,则根据公式 (8-4),编码像素的平均长度为
位(bits)
表示整个图像所需的总二进制位数是 ,或 118,621 。从公式 (8-2) 和 (8-1) ,所得的压缩比和对应的相对冗余度分别是
和
因此,原 8 位二维强度数组中 77.4% 的数据是冗余的。
上述通过编码 2 实现的压缩效果是通过为较少的位分配最可能的强度值而为较多的位分配最不可能的概率的强度值来实现的。按最终的变长编码, (图像最可能的强度值) 被赋予 (长度
) 的 1 位码字 1 ,而
(其最不可能发生的强度值)被赋予(长度为
)的 3 位码字 001 。注意,可以分配给图 8.1(a) 中图像强度值的最佳定长编码是自然的 2 位计数序列 {00,01,10,11},但由此产生的压缩比仅为 8:2 或 4:1,比变长编码的 4.42:1 压缩比低约 10% 。
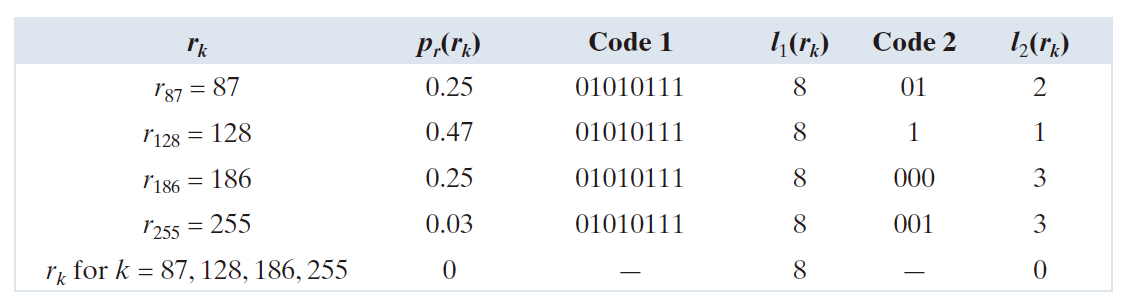
----------------------------表 8.1:变长编码例子-------------------------------
正如前述例子所示,当分配给一组事件(例如强度值)的代码没有充分利用事件的概率时,就会出现编码冗余。当使用自然二进制码表示图像的强度时,几乎总是存在编码冗余。原因是大多数图像由具有规则且在某种程度上可预测的形态(形状)和反射率的物体组成,并且采样时所描绘的物体远大于像素。自然而然地,对于大多数图像,某些强度值比其他强度值出现的概率更高(即,大多数图像的直方图不是均匀分布的)。自然二进制编码为最可能和最不可能的值分配相同的位数,无法使公式 (8-4) 最小化,从而导致编码冗余。
8.1.2 空间和时间冗余(Spatial and Temporal Redundancy)
考虑图 8.1(b) 中计算机生成的等强度线集合。在相应的二维强度数组中:
(1) 所有 256 个灰度值出现的概率相等。如图 8.2 所示,图像的直方图是均匀分布的。
(2) 由于每条线的强度是随机选择的,因此其像素在垂直方向上彼此独立。
(3) 由于每条线上的像素都相同,因此它们在水平方向上具有最大的相关性(彼此完全依赖)。
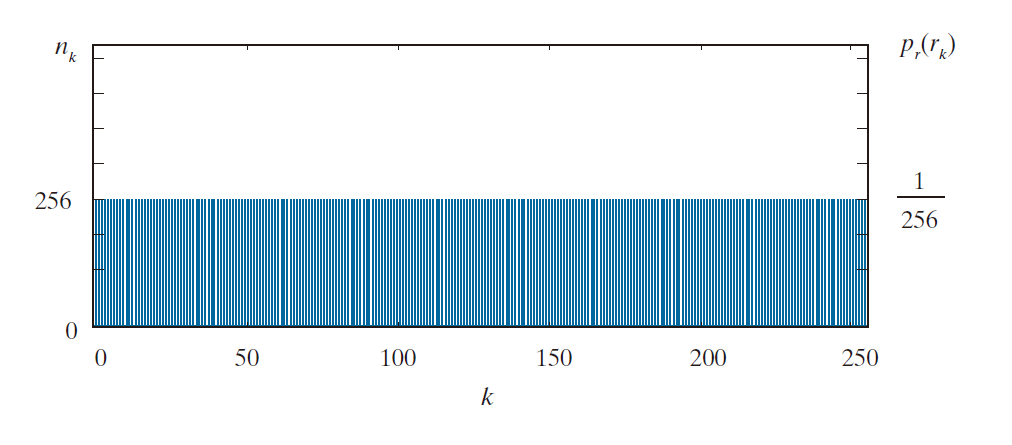
-----------------------图 8.2:图 8.1(b)中图像的强度直方图--------------------
第一个观察结果表明,图 8.1(b) 中的图像(当表示为传统的 8 位强度数组时)无法仅通过变长编码进行压缩。与图 8.1(a) 和示例 8.1 中的图像不同(它们的直方图不均匀),在这种情况下,定长的 8 位编码可以使公式 (8-4) 最小化。观察结果 2 和 3 揭示了显著的空间冗余,可以通过将图 8.1(b) 中的图像表示为一系列游程对(run-length pairs)来消除这种冗余。每一个游程对指定新强度的起始位置以及具有该强度的连续像素的数量。基于游程的表示方法可以将原二维 8 位强度数组压缩到 (256 * 256 * 8) / [(256 + 256) * 8] 或 128:1 的比例。在游程表示中,原表示中的每一行 256 个像素被一个 8 位强度值和长度 256 所取代 。
在大多数图像中,像素在空间上( x 轴和 y 轴方向)和时间上(当图像是视频序列的一部分时)都存在相关性。由于大多数像素的强度可以从相邻像素的强度合理地预测,因此单个像素携带的信息量很小。从某种意义上说,它的大部分视觉信息是冗余的,因为它可以从其相邻像素推断出来。为了减少与空间和时间相关的像素所带来的冗余,必须将二维强度数组转换为更高效但通常“非视觉”的表示形式 。例如,可以使用游程编码或相邻像素之间的差值。这种类型的转换称为映射。如果可以从转换后的数据集无误差地重建原二维强度数组的像素,则称该映射是可逆的;否则,该映射是不可逆的。
8.1.3 无关信息(Irrelevant information)
压缩一组数据的最简单方法之一是删除数据集中多余的数据。在数字图像压缩领域,人眼视觉系统忽略的信息,或者与图像预期用途无关的信息,都可以删除。因此,图 8.1(c) 中的计算机生成图像,由于它看起来是一个均匀的灰色区域,可以用其平均强度来表示——一个单独的 8 位值。原的 256 × 256 × 8 位强度数组压缩为一个字节,压缩比为 (256 × 256 × 8) : 8,即 65,536:1。当然,为了查看和/或分析图像,必须重新创建原 256 × 256 × 8 位图像,但重建后的图像质量几乎不会有任何明显的下降。
图 8.3(a) 显示了图 8.1(c) 中图像的直方图。请注意,图中实际存在多个强度值(从125 到 131)。人眼视觉系统会对这些强度值进行平均,只感知平均值,从而忽略了图中存在的微小强度变化。图 8.3(b) 是图 8.1(c) 图像的直方图均衡化版本,它使强度变化变得可见,并揭示了两个先前未检测到的恒强度区域——一个垂直方向,另一个水平方向。如果仅用平均值来表示图 8.1(c) 中的图像,那么这种“不可见”的结构(即恒强度区域)以及周围的随机强度变化(真实信息)就会丢失。是否应该保留这些信息取决于具体的应用。如果这些信息很重要,例如在数字 X 射线存档等医学应用中,则不应将其忽略;否则,这些信息是冗余的,为了提高压缩性能可以将其排除。
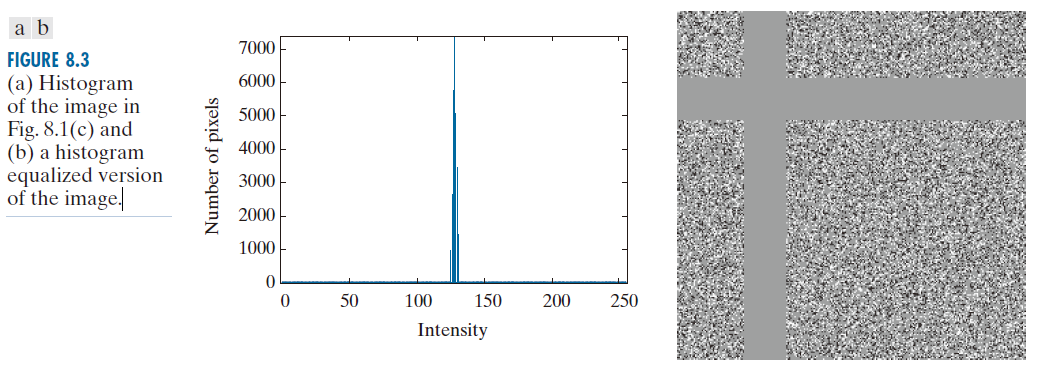
---------------------------图 8.3:(a) 图 8.1(c) 所示图像的直方图;(b) 经过直方图均衡化处理后的图像。-------------------------------------------------------
本节最后,我们指出此处讨论的冗余与前两节讨论的冗余有着根本区别。之所以可以消除这种冗余,是因为这些信息本身对于正常的视觉处理和/或图像的预期用途并非必不可少。由于省略这些信息会导致定量信息的丢失,因此这种去除冗余的过程通常称为量化(quantization)。这种术语与该词的常用含义一致,即通常指将广泛的输入值映射到有限数量的输出值(参见第 2.4 节)。由于信息会丢失,因此量化是一种不可逆的操作。
8.1.4 度量图像信息(Measuring Image information)
在前面的章节中,我们介绍了几种减少图像数据量的方法。由此自然引出一个问题:表示图像信息究竟需要多少二进制位?也就是说,是否存在一个最小数据量,足以描述图像而不丢失信息?信息论提供了回答这个问题以及相关问题的数学框架。其基本前提是,信息的产生可以建模为一个概率过程,并且可以用一种符合直觉的方式进行度量。根据这一假设,一个概率为 P(E) 的随机事件 E 视为包含
(8-5)
个信息单位。若 P( E ) = 1 (即,事件总是发生) ,I(E) = 0 且无信息贡献给它。因为没有与事件相关的不确定性,告知已发生的事件并不会传递任何信息。公式 (8-5) 中的对数底数决定了用于测度信息的单位。如果使用底数为 m 的对数,则称信息量以 m 进制单位表示。如果选择底数为 2,则信息单位为二进制位(bit)。注意,若 P( E ) = 1/2 ,则 或 1 位。即, 1 位信息量是指在两个可能性相等且互斥的事件中,其中一个事件发生时所传递的信息量。一个简单的例子是抛硬币并告知结果。
给定一个统计独立的随机事件源,该事件源来自一组离散的可能事件 ,其对应的概率为
,则每一个源输出的平均信息量(称为源的熵)为
(8-6)
公式中的 称为信源符号(source symbols)。因为它们在统计是独立的,这种信源本身称为零记忆信源(zero-memory source)。
如果将图像视为一个假想的零记忆“强度源”的输出,则我们可以利用观测图像的直方图来估计该强度源的符号概率。然后,强度源的熵变为
(8-7)
其中, 变量 L , 和
分别如先前和 3.3节中所定义,因为使用了底 2 对数,公式 (8-7) 表示的是位中的虚(imaginary)强度源的每强度输出的平均信息量。不可能使用少于
位/像素的位数对虚源(以及样本图像)的强度值进行编码。
例子 8.2:图像熵估算。
图 8.1(a) 中图像的熵可以通过将表 8.1 中的强度概率代入公式 (8-7) 来估算:
类似地,图 8.1(b) 和 (c) 中图像的熵可以分别计算为 8 位/像素和 1.566 位/像素。值得注意的是,图 8.1(a) 中的图像看起来包含最多的视觉信息,但其计算出的熵却几乎是最低的——1.66 位/像素。图 8.1(b) 中图像的熵几乎是图 8.1(a) 中图像的五倍,但其视觉信息量看起来却大致相同(或更少)。图 8.1(c) 中的图像似乎几乎不包含任何信息,但其熵却与图 8.1(a) 中的图像几乎相同。显而易见的结论是,图像的熵(以及图像中包含的信息量)与直观感受相去甚远。
Shannon第一定理(Shannon’s First Theorem)
回想一下,例 8.1 中的变长码仅用 1.81 位/像素就能表示图 8.1(a) 中图像的强度。虽然这高于例 8.2 中 1.6614 位/像素的熵估计值,但 Shannon 第一定理(也称为无噪编码定理(noiseless coding theorem),Shannon [1948])确保,图 8.1(a) 中的图像可以用低至 1.6614 位/像素的位来表示。为了更一般地证明这一点,Shannon研究了用单个码字表示一组连续的信源符号(而不是每一个信源符号一个码字),并证明了
(8-8)
其中, 是所要求的表示所有 n 符号组的平均编码符号数。在其证明中,他将一个零记忆信源的第 n 个扩展定义为使用原信源的符号产生的 n 符号块的假设信源(注:第 n次扩展的输出是由底层单符号源中的符号组成的 n 元组。它视为一个块随机变量,其中每个 n 元组的概率是其各个符号概率的乘积。因此,第 n 次扩展的熵是其所源自的单符号源的熵的 n 倍),并应用公式 (8-4) 于用于表示 n 符号块的码字来计算
。根据公式 (8-8),
可以通过对单符号源的无限长扩展进行编码来实现对 H 的无限接近,即,可以用平均每一个信源符号包含 H 个信息单元的方式来表示无记忆信源的输出。
如果我们回到图像是产生它的强度源的“样本”这一概念,那么 n 个源符号块对应于 n 个相邻像素组成的像素块。为了构建 n 像素块的变长编码,必须计算这些像素块的相对频率。但是,一个具有 256 个强度值的假设强度源的第 n 个扩展会产生 个可能的 n像素块。即使在 n = 2 的简单情况下,也必须生成一个包含 65,536 个元素的直方图以及多达 65,536 个变长码字。对于 n = 3,则需要多达 16,777,216 个码字。因此,即使对于较小的 n 值,计算复杂度也会限制扩展编码方法在实际应用中的实用性。
最后,我们注意到,虽然公式 (8-7) 给出了对统计独立像素进行直接编码时可实现的压缩率的下限,但当图像像素之间存在相关性时,该公式就会失效。相关像素块的平均每像素编码位数可以比该公式预测的更少。通常情况下,人们不会使用信源扩展,而是选择相关性较低的描述符(例如强度游程)进行编码,而无需进行扩展。在关于空间和时间冗余的章节中,压缩图 8.1(b) 时就采用了这种方法。当信息源的输出取决于有限数量的先前输出时,该信息源被称为 Markov 信源或有限记忆信源(finite memory source)。
8.1.5 保真度标准(Fidelity Criteria)
前面提到,去除“无关视觉”信息会导致真实或定量图像信息的丢失。由于信息会丢失,因此需要一种量化信息丢失程度的方法。可以使用两种类型的标准进行此类评估:(1) 客观保真度标准,和 (2) 主观保真度标准。
当信息损失可以表示为压缩过程输入和输出的数学函数时,就称其基于客观保真度标准。例如,两幅图像之间的均方根 (rms) 误差。设 f (x, y) 为输入图像, 为对输入图像进行压缩和解压缩后得到的 f ( x, y ) 的近似值。对于任意 x 和 y 值,f (x, y) 和
之间的误差 e( x, y ) 为
(8-9)
因此,两幅图像之间的总误差为
其中,图像的大小为 M × N 。则 f ( x, y ) 与 之间的方均根误差(root-mean-squared error) (
) 是 M × N 数组上的平方误差的平均值的平方根,或
(8-10)
若将 视为[通过对公式 (8-9) 中的项作简单的重排]原图像 f ( x, y ) 与一个 误差或“噪声”信号 e( x, y ) 之和,则输出图像的均方信噪比(mean squared signal-to-noise ratio)(表示为
)可按 5.8 中那样定义为:
(8-11)
信澡比的 rms 值(方均根) ( 表示为 ) 可通过对公式 (8-11) 取平方根而求得。
虽然客观保真度标准提供了一种简单便捷的评估信息丢失的方法,但解压缩后的图像最终通常是由人来观看的。因此,通过人们的主观评价来衡量图像质量往往更为合适。这可以通过将解压缩后的图像呈现给一组观众并对他们的评价进行平均来实现。评价可以使用绝对评分量表进行,也可以通过对 f ( x, y ) 和 进行并排比较来完成。表 8.2 显示了一种可能的绝对评分量表。
可以使用 {-3 ,-2 ,-1 , 0 , 1, 2 , 3 } 这样的量表(scale)来分别进行并排比较,以表示主观评价 { 甚差,很差, 稍差,相同,稍好,很好,甚好 }。无论哪种情况,评估都是基于主观的保真度标准。
| 值 | 级别(Rating) | 描述 |
| 1 | 优(Excellent) | 这是一幅质量极高的图像,堪称完美,无可挑剔。 |
| 2 | 良(Fine) | 图像质量高,观感舒适。干扰现象不明显,可以接受。 |
| 3 | 合格(Passable) | 图像质量尚可。干扰程度可以接受。 |
| 4 | 边沿(Marginal) | 图像质量不佳;你希望能够改善它。干扰情况有些令人不满意。 |
| 5 | 合格线下(Inferior) | 图像质量很差,但勉强还能看。画面中确实存在令人不快的干扰。 |
| 6 | 不可用(Unusable) | 画面糟糕到你根本无法观看。 |
---------表 8.2 :电视分配研究组织的评级量表。(Frendendall 和 Behrend。)------
例子 8.3 :图像质量比较。
图 8.4 显示了图 8.1(a) 图像的三种不同近似结果。使用公式 (8-10),并将图 8.1(a) 作为 f ( x, y ),图 8.4(a) 至 (c) 分别作为 ,计算得到的 rms 分别为 5.17,15.67 和 14.17 灰度级。从 rms(一种客观的图像保真度标准)来看,图像质量从高到低依次为 {(a), (c), (b)}。然而,如果使用表 8.2 进行主观评价,则 (a) 可能获得优秀评级,(b) 获得勉强合格评级,而 (c) 则获得较差或不可用评级。因此,如果使用主观保真度标准,(b) 的排名会高于 (c)。

------------------图 8.4:图 8.1(a) 所示图像的三种近似表示。-------------------
8.1.6 图像压缩模型(Image Compression Models)
如图 8.5 所示,图像压缩系统由两个不同的功能组件组成:编码器和解码器。编码器执行压缩操作,解码器执行相应的解压缩操作。这两种操作都可以通过软件实现,例如在网络浏览器和许多商业图像编辑应用程序中;也可以通过硬件和固件的组合来实现,例如在商用 DVD 播放器中。编解码器是指能够同时执行编码和解码功能的设备或程序。
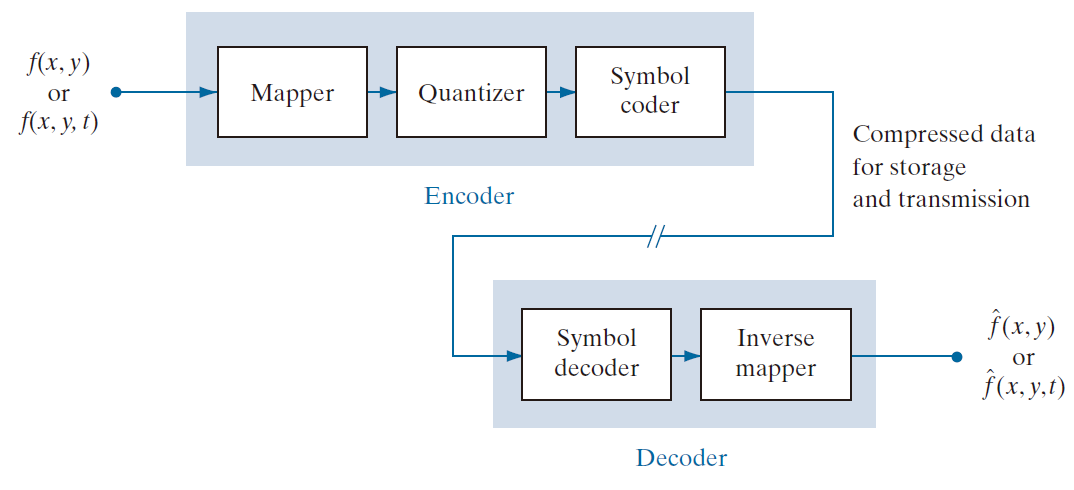
------------------图 8.5:通用图像压缩系统的功能框图。-------------------
输入图像 f ( x, … ) 被输入到编码器,编码器会生成输入的压缩表示。这种表示可以存储起来供以后使用,也可以传输到远程位置进行存储和使用。当将压缩表示输入到相应的解码器时,会生成重建的输出图像 。在静态图像应用中,编码后的输入和解码器输出分别为 f ( x, y ) 和
。在视频应用中,它们分别为 f ( x , y ,t ) 和
,其中离散参数 t 表示时间。通常,
可能与 f ( x, p) 完全相同,也可能不完全相同。如果完全相同,则称该压缩系统是无误差的、无损的或保信息的。如果不同,则重建的输出图像会失真,这种压缩系统被称为有损压缩系统。
8.1.6.1 编码或压缩过程(The Encoding or Compression Process)
图 8.5 中的编码器旨在通过一系列三个独立的操作来消除前几节所述的冗余。在编码过程的第一阶段,映射器将 f ( x, … ) 转换为一种(通常是非可视的)格式,旨在减少空间和时间冗余。此操作通常是可逆的,并且可能直接减少或不减少表示图像所需的数据量。游程编码是一种映射示例,它通常在编码过程的第一步实现压缩。将图像映射到一组相关性较低的变换系数(参见第 8.9 节)是另一种情况的示例(必须对系数进行进一步处理才能实现压缩)。在视频应用中,映射器使用前面的(在某些情况下也使用未来的)视频帧来帮助消除时间冗余。
图 8.5 中的量化器根据预先设定的保真度标准降低映射器输出的精度。其目的是将无关信息排除在压缩表示之外。如前所述,此操作是不可逆的。如果需要无损压缩,则必须省略此操作。在视频应用中,通常会测量编码输出的位率(以位/秒为单位),并用它来调整量化器的操作,以维持预定的平均输出速率。因此,输出的视觉质量会根据图像内容的不同而逐帧变化。
在编码过程的第三个也是最后一个阶段,图 8.5 所示的符号编码器生成固定长度或变长的代码来表示量化器的输出,并根据该代码对输出进行映射。在许多情况下,会使用变长代码。最短的代码字分配给出现频率最高的量化器输出值,从而最大限度地减少编码冗余。此操作是可逆的。操作完成后,输入图像已完成处理,消除了前面章节描述的三种冗余。
8.1.6.2 解码或解压缩过程(The Decoding or Decompression Process)
图 8.5 所示的解码器仅包含两个组件:符号解码器和逆映射器。它们以相反的顺序执行编码器中符号编码器和映射器的逆操作。由于量化会导致不可逆的信息损失,因此通用解码器模型中不包含逆量化器模块。在视频应用中,解码后的输出帧保存在内部帧存储器(图中未显示)中,用于重新插入编码器端移除的时间冗余。
8.1.7 图像格式、容器和压缩标准(Image Formats, Containers , and Compression Standards)
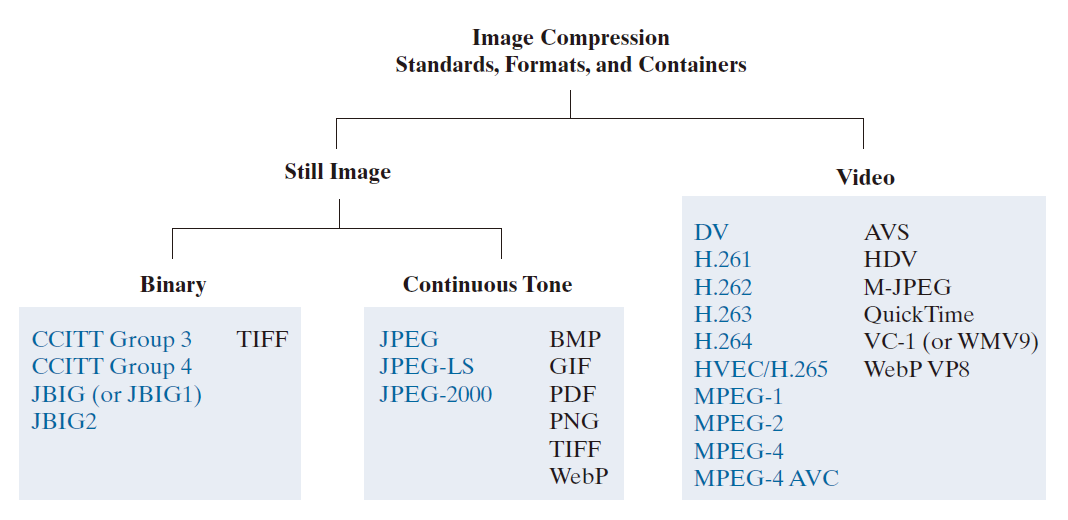
在数字图像领域,图像文件格式是一种组织和存储图像数据的标准方式。它定义了数据的排列方式以及使用的压缩类型(如果使用压缩)。图像容器类似于文件格式,但可以处理多种类型的图像数据(译注:可以存放多种文件格式的文件格式)。在另一方面,图像压缩标准定义了图像压缩和解压缩的程序(procedure)——即,减少表示一幅图像所需数据量。这些标准是图像压缩技术被广泛接受的基础。
图 8.6 列出了当今使用的最重要的图像压缩标准、文件格式和容器,并按处理的图像类型进行分组。蓝色条目表示由国际标准化组织 (ISO)、国际电工委员会 (IEC) 和/或国际电信联盟 (ITU-T)(一个联合国组织,前身为国际电话电报咨询委员会 (CCITT))批准的国际标准。图中还包括两个视频压缩标准:电影电视工程师协会 (SMPTE) 的 VC-1 标准和中国信息产业部 (MII) 的 AVS 标准。请注意,这两个标准以黑色显示,图 8.6 中用黑色表示未获得国际标准组织批准的条目。
译注:
Still Image——静态图像
Continuous Tone——连续色调
Binary——二值图像
-----------------------------图 8.6:一些常用的图像压缩标准、文件格式和容器。国际认可的标准以蓝色显示;其他标准以黑色显示。-----------------------------------
表 8.3 至 8.5 总结了图 8.6 中列出的标准、格式和容器。表中列出了负责制定标准的组织、目标应用以及关键压缩方法。压缩方法本身是第 8.2 至 8.11 节的主题,我们将在这些章节中描述目前使用的主要有损和无损压缩方法。这些章节重点介绍已在主流二值图像、连续色调静止图像和视频压缩标准中被证明有效的压缩方法。这些标准本身被用来演示所介绍的方法。在表 8.3 至 8.5 中,指向描述压缩方法的相应章节的交叉引用使用方括号括起来。
表 8.3 :国际认可的图像压缩标准。括号中的数字指的是本章中的章节。
| 名称 | 组织 | 描述 |
| 二值静态图像(bi-level still images) | ||
| CCITT Group 3 | ITU-T | 该系统设计用于通过电话线传输二进制文档,采用传真(FAX)方式。支持一维和二维游程编码 [8.6] 以及霍夫曼编码 [8.2]。 |
| CCITT Group 4 | ITU-T | 这是 CCITT Group 3 标准的简化版本,仅支持二维游程编码。 |
| JBIG 或 JBIG1 | ISO/IEC/ITU-T | 一种由联合双层图像专家组制定的标准,用于对双层图像进行渐进式无损压缩。最多可对每像素 6 位的连续色调图像进行位平面编码 [8.8]。该标准采用上下文敏感算术编码 [8.4],并且可以通过添加额外的压缩数据逐步增强初始的低分辨率图像版本。 |
| JBIG2 | ISO/IEC/ ITU-T | 它是 JBIG1 的后续版本,用于桌面、互联网和传真应用中的二值图像压缩。其压缩方法基于内容,对文本和半色调区域采用基于字典的方法 [8.7],对其他图像内容则采用霍夫曼编码 [8.2] 或算术编码 [8.4]。它可以是有损压缩,也可以是无损压缩。 |
| 连续色调静态图像(Continuous-Tone Still Images) | ||
| JPEG | ISO/IEC/ ITU-T | JPEG(联合图像专家组)是一种用于高质量图像的标准。其有损基线编码系统(最常见的实现方式)使用对图像块进行量化离散余弦变换(DCT)[8.9]、Huffman[8.2]和游程编码[8.6]。它是互联网上最流行的图像压缩方法之一。 |
| JPEG-LS | ISO/IEC/ ITU-T | 一种基于自适应预测[8.10]、上下文建模[8.4]和Golomb编码[8.3]的连续色调图像无损或接近无损压缩标准。 |
| JPEG-2000 | ISO/IEC/ ITU-T | 这是 JPEG 的后续标准,用于进一步压缩高质量图像。该标准采用算术编码 [8.4] 和量化离散小波变换 (DWT) [8.11]。压缩可以是无损的,也可以是有损的。 |
表 8.4
国际认可的视频压缩标准。括号中的数字指的是本章中的相关章节。
| 名称 | 组织 | 描述 |
| DV | IEC | 数字视频。这是一种专为家庭和半专业视频制作应用及设备(例如电子新闻采集和摄像机)量身定制的视频标准。帧采用类似于 JPEG 的基于 DCT 的方法独立压缩,以便于编辑 [8.9]。 |
| H.261 | ITU-T | 这是一种用于ISDN(综合业务数字网)线路的双向视频会议标准。它支持非隔行扫描的 352×288 和 176×144 分辨率图像,分别称为 CIF(通用中间格式)和 QCIF(四分之一CIF)。该标准采用类似于JPEG的基于离散余弦变换(DCT)的压缩方法[8.9],并使用帧间预测差分[8.10]来减少时间冗余。此外,还采用基于块的技术来补偿帧间的运动。 |
| H.262 | ITU-T | 见下述 MPEG-2 |
| H.263 | ITU-T | H.261 的增强版本,专为普通电话调制解调器(例如 28.8 Kb/s)设计,并增加了以下分辨率:SQCIF (子四分之一(Sub-Quarter)CIF,128 * 96)、4CIF(704 * 576)和 16CIF(1408 * 512)。 |
| H.264 | ITU-T | 它是 H.261–H.263 标准的扩展,用于视频会议、流媒体和电视。它支持帧内预测差分 [8.10]、可变块大小整数变换(而不是离散余弦变换)以及上下文自适应算术编码 [8.4]。 |
| H.265 MPEG-H HEVC | ISO/IEC ITU-T | 高效视频编码 (HEVC)。它是 H.264 的扩展,支持高达 64*64 像素的宏块大小以及额外的帧内预测模式,这些特性对于 4K 视频应用都非常有用。 |
| MPEG-1 | ISO/IEC | 一种用于CD-ROM应用的运动图像专家组标准,支持高达1.5 Mb/s的非隔行扫描视频。它类似于H.261标准,但帧预测可以基于前一帧、后一帧或两者的插值。几乎所有计算机和DVD播放器都支持该标准。 |
| MPEG-2 | ISO/IEC | MPEG-2 是 MPEG-1 的扩展版本,专为 DVD 设计,传输速率高达 15 Mb/s。它支持隔行扫描视频和高清电视 (HDTV)。它是迄今为止最成功的视频标准。 |
| MPEG-4 | ISO/IEC | MPEG-2 的一个扩展版本,支持帧内可变块大小和预测差分 [8.10]。 |
| MPEG-4 AVC | ISO/IEC | MPEG-4 第 10 部分高级视频编码 (AVC)。与 H.264 标准相同。 |
表 8.5:表 8.3 和表 8.4 中未包含的常用图像和视频压缩标准、文件格式和容器。括号中的数字指的是本章中的相关章节。(译注:以下数据,有的是视频文件格式,有的是视频编码标准,有的是图像容器,这种文件格式支持多种视频编码标准。JPEG 即指一种压缩标准,也指一种文件格式,后缀 *.jpg 或 *.jpeg 。)
| 名称 | 组织 | 描述 |
| 连续色调静态图像(Continuous-Tone Still Images) | ||
| BMP | 微软 | Windows 位图。一种主要用于存储简单未压缩图像的文件格式。 |
| GIF | CompuServe | 图形交换格式(GIF)。一种文件格式,使用无损 LZW 编码 [8.5] 来处理 1 位到 8 位图像。它常用于制作用于互联网的小型动画和低分辨率短片。 |
| PDF(文档格&容器) | Adobe Systems | 可移植文档格式(PDF)。一种以独立于设备和分辨率的方式表示二维文档的格式。它可以作为 JPEG、JPEG-2000、CCITT 和其他压缩图像的容器。某些 PDF 版本已成为 ISO 标准。 |
| PNG | World Wide Web Consortium (W3C) | 便携式网络图形(PNG)。这是一种文件格式,它通过对每一个像素值与基于先前像素的预测值之间的差值进行编码,实现对带有透明度的全彩色图像(高达 48 位/像素)的无损压缩 [8.10]。 |
| TIFF(容器) | Aldus | 标签图像文件格式(TIFF)。一种灵活的文件格式,支持多种图像压缩标准,包括 JPEG、JPEG-LS、JPEG-2000、JBIG2 等。 |
| WebP(容器) | 谷歌 | WebP 支持有损压缩(通过 WebP VP8 帧内视频压缩,详见下)和无损压缩,无损压缩采用空间预测 [8.10]、LZW 反向引用的一种变体 [8.5] 和Huffman熵编码 [8.2]。此外,WebP 也支持透明度。 |
| 视频 | ||
| AVS | MII | 音视频标准。类似于 H.264,但使用指数哥伦布编码 [8.3]。由中国开发。 |
| HDV | 公司联合体 | 高清视频标准。它是DV格式的扩展,用于高清电视,采用类似于MPEG-2的压缩技术,包括通过预测差分去除时间冗余[8.10]。 |
| M-JPEG | 各种公司 | 运动 JPEG(Motion JPEG)。一种压缩格式,其中每一帧都使用 JPEG 格式独立压缩。 |
| Quick- Time(容器) | 苹果计算机 | 一种媒体容器,支持 DV、H.261、H.262、H.264、MPEG-1、MPEG-2、MPEG-4 等视频压缩格式。 |
| VC-1 WMV9 | SMPTE 微软 | 这是互联网上最常用的视频格式。已被用于高清和蓝光高清 DVD。它类似于 H.264/AVC,使用可变块大小的整数离散余弦变换(DCT)[8.9 和 8.10] 和上下文相关的变长编码表 [8.2],但不进行帧内预测。 |
| WebP VP8 | 谷歌 | 这是一种基于块变换编码的文件格式[8.9],它利用帧内和帧间预测的差值[8.10]。这些差值使用自适应算术编码器进行熵编码[8.4]。 |
8.2 Huffman编码(Huffman Coding)
Huffman 编码(Huffman [1952])是消除编码冗余的最常用技术之一。在对信息源的符号进行单独编码时,Huffman 编码可以使每一个信源符号所需的编码符号数量达到最小。根据 Shannon 第一定理(参见第 8.1 节),对于一个固定的 n 值,在信源符号逐个编码的约束条件下,由此产生的编码是最优的。在实际应用中,信源符号可以是图像的像素强度,也可以是强度映射操作的输出(例如像素差值、游程等等)。
Huffman 方法的第一个步骤是创建一系列信源符号缩减,方法是对待编码符号的概率进行排序,然后将概率最低的两个符号组合成一个新符号,并在下一次信源符号缩减中用该新符号替换它们。图 8.7 展示了二进制编码的这一过程(也可以构建 K 进制Huffman编码)。在最左侧,一组假设的源符号及其概率从上到下按概率值递减的顺序排列。为了形成第一次信源符号缩减,将底部两个概率值 0.06 和 0.04 组合成一个概率为 0.1 的“复合符号”。这个复合符号及其关联的概率被放置在第一个信源符号缩减列中,使得缩减后的信源符号的概率也从高到低排列。然后重复此过程,直到得到一个包含两个符号的缩减信源(最右侧)。
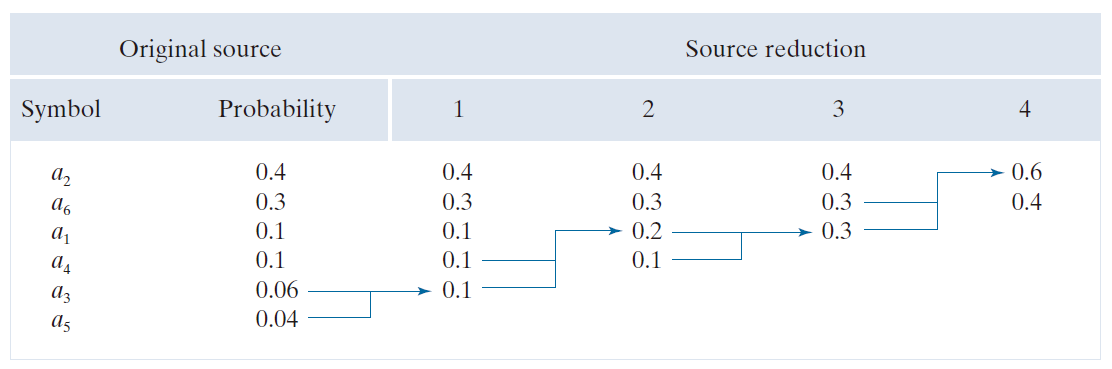
----------------------------图 8.7:Huffman 信源编码压缩。--------------------
Huffman 编码的第二步是对每一个缩减后的信源进行编码,从最小的信源开始,逐步回溯到原信源。对于一个双符号信源,最短的二进制编码当然是符号 0 和 1。如图 8.8 所示,这两个符号被分配给右侧的两个符号。(这种分配是任意的;将 0 和 1 的顺序颠倒也同样有效。) 由于概率为 0.6 的缩减信源符号是由其左侧缩减信源中的两个符号组合而成的,因此用于编码该符号的 0 现在被分配给这两个符号,并在每个符号后任意附加一个 0 和一个 1 以区分它们。然后对每个缩减后的信源重复此操作,直到得到原始信源。最终的编码出现在图 8.8 的最左侧。该编码的平均长度为
信源的熵为 2.14 位/符号。
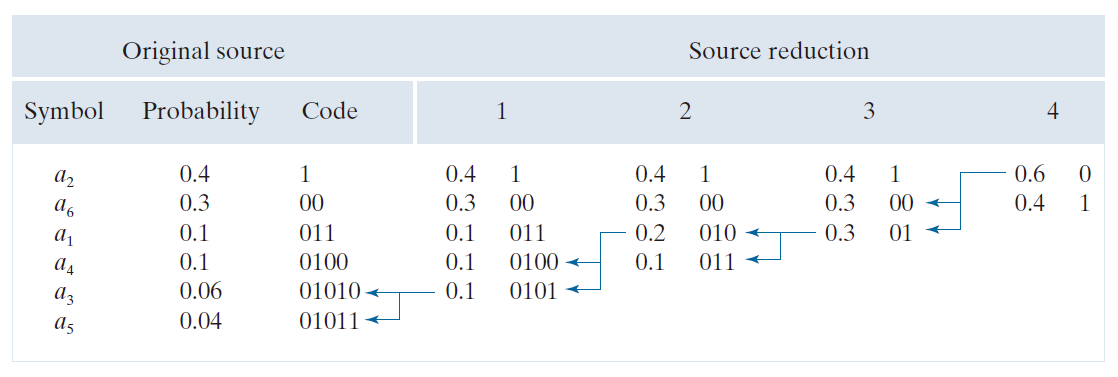
----------------------------图 8.8:Huffman 编码分配过程。--------------------
Huffman 算法为一组符号及其概率创建最优编码,但前提是符号必须逐个编码。编码创建完成后,编码和/或无差错解码可以通过简单的查找表方式实现。该编码本身是一种瞬时唯一可解码的分组码。之所以称为分组码,是因为每一个信源符号都被映射到一个固定的码符号序列。之所以称为瞬时码,是因为码符号串中的每一个码字都可以独立解码,无需参考后续符号。之所以称为唯一可解码码,是因为任何码符号串都只能以一种方式解码。因此,任何 Huffman 编码的符号串都可以通过从左到右依次检查每一个符号来解码。对于图 8.8 中的二进制编码,从左到右扫描编码字符串 010100111100 可以发现,第一个有效的码字是 01010,它是符号 的编码。下一个有效的码字是 011,对应于符号
。以此类推,最终解码得到的消息是
。
例子 8.4:Huffman 编码。
图 8.9(a) 所示的 512 × 512 像素的 8 位单色图像的强度直方图如图 8.9(b) 所示。由于像素强度并非等概率分布,因此我们使用 MATLAB 实现的 Huffman 编码算法对其进行编码,编码后每个像素需要 7.428 位,其中包括用于重建原 8 位图像强度所需的Huffman编码表。压缩后的表示大小超过了图像的估计熵 [根据公式 (8-7) 计算,熵为 7.3838 位/像素],超出部分为 位,约占 0.6%。由此得到的压缩比和相应的相对冗余度分别为 C = 8 / 7.428 = 1.077 和 R = 1 - (1 / 1.077) = 0.0715。因此,原始 8 位固定长度强度表示中约 7.15% 的冗余信息被去除。
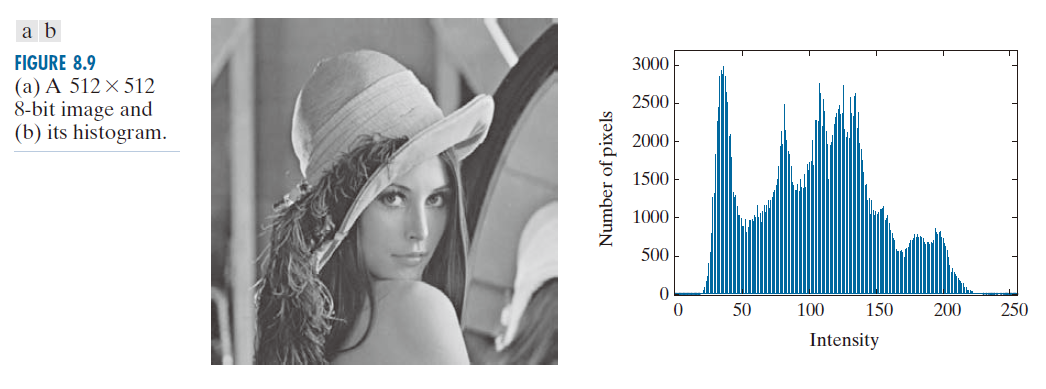
------------------------------图 8.9:(a) 一幅 512 * 512 像素的 8 位图像;(b) 该图像的直方图。--------------------------------------------------------------
当需要对大量符号进行编码时,构建最优 Huffman 编码并非易事。对于一般的 J 个信源符号,需要 J 个符号概率、J - 2 次信源符号合并以及 J - 2 次代码分配。如果可以预先估计信源符号的概率,则可以使用预先计算好的 Huffman 编码来实现“接近最优”的编码。一些流行的图像压缩标准,包括第 8.9 节和第 8.10 节讨论的 JPEG 和 MPEG 标准,都规定了基于实验数据预先计算好的默认 Huffman 编码表。
8.3 Golomb编码(Golomb Coding)
在本节中,我们考虑对具有指数衰减概率分布的非负整数输入进行编码。可以使用一系列比 Huffman 编码计算复杂度更低的编码方案,对这类输入进行最优编码(根据 Shannon 第一定理)。这些编码方案最初是为表示非负游程而提出的(Golomb [1966])。在接下来的讨论中,符号 表示小于或等于 x 的最大整数,
表示大于或等于 x 的最小整数,x mod y 表示 x (整)除以 y 的余数。
已知一个非负整数 n 以及一个正整数除数 m > 0 ,则 n 针对 m 的 Golomb 编码( 记为 ) 是商
的一元码(unary code)(译注:数字是几就有几个1,最后接一个0表示结束) 和余数 n mod m 的二值表示的一个组合。
可按如下构建:
I 构成商 的一元码 。( 一个整数 q 的一元码定义为 q 个 1 后面再接一个0 ) 。
II 令 ,
,
,并计算截断余数
,使得
(8-12) 
III 将步骤 1 和步骤 2 的结果连接起来。
例如,为了计算 ,首先确定商
的一元码,其值为 110 (根据第 I 步计算所得)。然后令
,
,
, 其按二进制编码为 9 mod 4 = 1001 mod 0100 或 0001 。根据公式 (8-12) ,
即是 r ( 即 0001 )截断为两个位,即 01 (根据第 II 步计算所得)。最后,将来自第 I 步的 110 和来自第 II 步的 01 连接在一起得到 11001 ,其为
。
对于 这种特殊情况,c = 0 ,且
按公式 (8-12)对于所 n 截断为 k 。生成所得 Golomb 码所需的除法运算变成了二进制移位运算,这些计算上更简单的编码称为 Golomb-Rice 码或 Rice 码 ( Rice [1975] )。表 8.6 的第 2、3 和 4 列列出了前十个非负整数的
,
和
码。由于在每一种情况下 m 都是 2 的幂 ( 即
,
和
) ,因此它们也是前三个 Golomb-Rice 码。此外,
是非负整数的一元码,因为对于所有 n ,都有
且 n mod 1 = 0 。
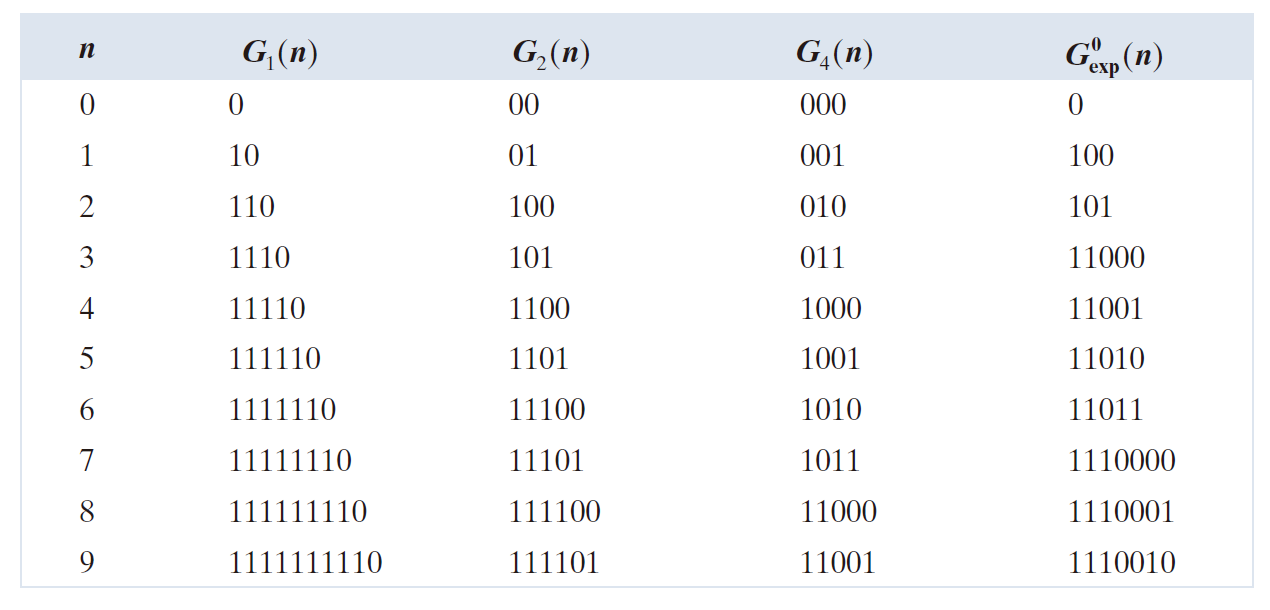
---------------表 8.6:用于表示整数 0-9 的几种 Golomb 编码。---------------
考虑到 Golomb 编码只能用于表示非负整数,并且存在多种 Golomb 编码可供选择,因此有效应用 Golomb 编码的关键步骤是选择除数 m 。当待表示的整数服从几何分布,且其概率质量函数 (PMF)( 注:概率质量函数 (PMF) 是一个函数,它定义了离散随机变量取某个特定值的概率。PMF 与概率密度函数(PDF)的区别在于,PDF 的值本身不是概率;相反,PDF 在特定区间上的积分才是概率) 为
(8-13) ( 对于 0 < ρ < 1 )
可以证明在后述意义上 Golomb 编码是最优的,即当
(8-14)
时, 提供了所有可唯一解码的代码中平均代码长度最短的代码。图 8.10(a) 绘制了公式 (8-13) 在三个不同 ρ 值下的曲线,并以图形方式展示了 Golomb 编码能够有效处理(即高效编码)的符号概率分布。如图所示,小整数的概率远高于大整数的概率。
由于图像中各强度值的概率(例如,参见图 8.9(b) 的直方图)不太可能与公式 (8-13) 中指定的概率以及图 8.10(a) 中所示的概率相匹配,因此 Golomb 编码很少用于强度值的编码。然而,当需要对强度差值进行编码时,所得“差值”(参见 8.10 节)的概率(负差值除外)通常与公式 (8-13) 和图 8.10(a) 中的概率相似。为了处理 Golomb 编码中只能表示非负整数的负差值, 通常使用类似
(8-15)
这样的公式。例如,利用这种映射关系,图 8.10(b) 所示的双边概率质量函数 (PMF) 可以转换为图 8.10(c) 所示的单边概率质量函数。其整数重新排列,负整数和正整数交替出现,从而将负整数映射到奇数正整数位置。如果 P(n) 是以零为中心对称分布的双边概率质量函数,则 P( M(n)) 将是单边概率质量函数。然后,可以使用合适的 Golomb-Rice 编码( Weinberger 等人 [1996])对映射后的整数 M(n) 进行高效编码。
例子 8.5:Golomb-Rice 编码。
再次考虑图 8.1(c) 中的图像,并注意其直方图[参见图 8.3(a)]与上文图 8.10(b) 中的双边分布相似。如果我们令 n 为图像中的某个非负整数强度值,其中 0 ≤ n ≤ 225,μ 为平均强度值,则 P(n - μ) 是图 8.11(a) 所示的双边分布。该图是通过将图 8.3(a) 中的直方图除以图像中的总像素数进行归一化,并将归一化后的值向左平移 128(这实际上是从图像中减去平均强度值)而生成的。根据公式 (8-15),P(n - μ) 则是图 8.11(b) 所示的单边分布。如果使用 MATLAB 实现的表 8.6 第二列中的 代码对重新排列的强度值进行 Golomb 编码,则编码后的表示比原始图像小 4.5 倍(即 C = 4.5 ) 。
代码实现了变长编码理论压缩率的 4.5/5.1(即 88% )。[根据示例 (8-2) 中计算的熵,通过变长编码可实现的最大压缩比为 C = 8/1.566 ≈ 5.1。] 此外,Golomb 编码实现了 MATLAB 实现的 Huffman 编码方法所提供的压缩率的 96%,并且不需要计算自定义的 Huffman 编码表。
现在考虑图 8.9(a) 中的图像。如果使用与上述相同的 编码对该图像的像素强度进行 Golomb 编码,则 C = 0.0922。也就是说,数据发生了膨胀。这是因为图 8.9(a) 中图像像素强度的概率分布与公式 (8-13) 中定义的概率分布存在很大差异。类似地,当用于编码的符号的概率分布与计算编码时所依据的概率分布不同时,Huffman 编码也可能导致数据膨胀。实际上,输入概率分布与编码设计时所依据的概率分布偏差越大,压缩性能越差,数据膨胀的风险也越大。
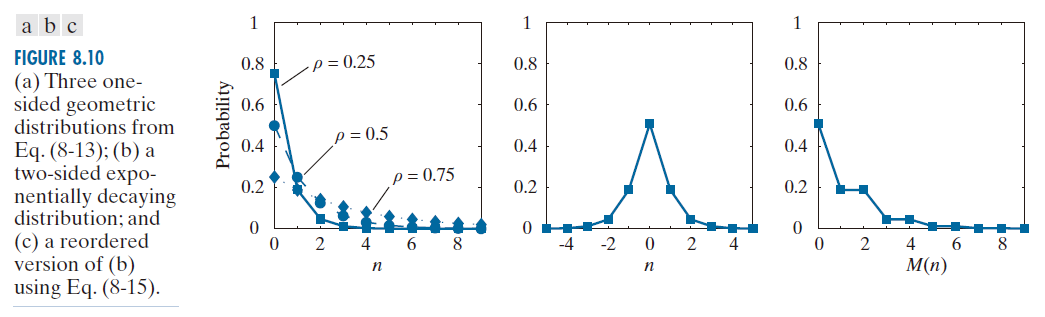
-------------图 8.10:(a) 来自公式 (8-13) 的三个单侧几何分布;(b) 一个双侧指数衰减分布;以及 (c) 使用公式 (8-15) 对 (b) 进行重新排列后的版本。--------------
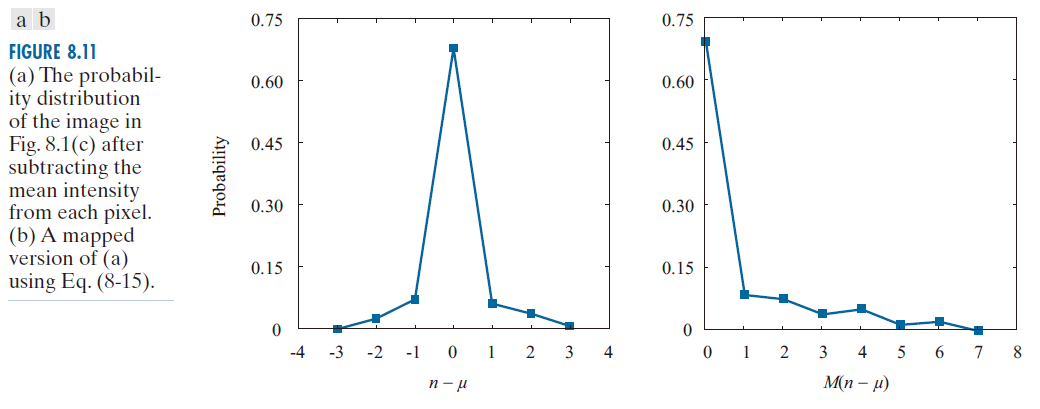
----------------图 8.11:(a) 图 8.1(c) 中图像在减去每个像素的平均强度后的概率分布。(b) 使用公式 (8-15) 对 (a) 进行映射后的结果。----------------------------
为了结束我们对 Golomb 编码的介绍,我们注意到表 8.6 的第5列包含零阶指数Golomb 编码的前 10 个编码,记为 。指数 Golomb 编码对于编码游程非常有用,因为它可以有效地编码短游程和长游程。k 阶指数 Golomb 编码
的计算方法如下:
I 求得一个整数 i ≥ 0 使得
(8-16)
并构成 i 的一元编码。若 k = 0 , 则 ,且此编码称为 Elias γ 编码。
II 将
(8-17)
的二进制表示截断为 ( k + i ) 个最低有效位。
III 将第 I 步和 II 步的结果连接起来。
例如,为了求得 ,在第 I 步我们令
或 3 ,因为 k = 0 。则公式 (8-16) 的条件得到满足,因为
3 的一元编码是 1110 且根据第 2 步的公式 (8-17) 得到
当其截断为 3 + 0 位最低有效位后为 001。将步骤 1 和步骤 2 的结果连接起来,得到 1110001。请注意,这正是表 8.6 中 n = 8 时第 4 列的条目。最后,我们注意到,与上一节的 Huffman 编码类似,表 8.6 中的 Golomb 编码是变长、即时且唯一可解码的分组码。
8.4 算术编码(Arithmetic Coding)
与前两节的变长编码不同,算术编码生成的是非分组编码。算术编码可以追溯到 Elias 的研究( Abramson [1963] ),它不像前两种编码那样,信源符号和码字之间不存在一一对应的关系。相反,整个信源符号序列(或消息)赋予一个单独的算术码字。该码字本身定义了介于 0 和 1 之间的实数区间。随着消息中符号数量的增加,用于表示该消息的区间变得越来越小,而表示该区间所需的信息单元(例如,二制制位)数量则越来越多。消息中的每一个符号都会根据其出现的概率缩小区间的范围。由于这种技术不像 Huffman 编码那样要求每一个源符号都转换为整数个码字(即,符号不是逐个编码的),因此它(仅在理论上)能够达到第 8.1 节中 Shannon 第一定理所确定的极限。
图 8.12 演示了基本的算术编码过程。这里,对来自四符号信源的五符号序列或消息
进行编码。在编码过程开始时,假设消息占据整个半开区间 [0, 1)。如表 8.7 所示,该区间最初根据每一个信源符号的概率细分为四个区域。例如,符号
与子区间 [0, 0.2) 相关联。由于它是待编码消息的第一个符号,因此消息区间最初缩小到 [0, 0.2)。因此,在图 8.12 中,[0, 0.2) 被扩展到图形的完整高度,其端点标有缩小范围的值。然后,根据原信源符号概率对缩小后的范围进行细分,并继续处理下一个消息符号。按这种方式,符号
将子区间缩小到 [0.04, 0.08),
进一步将其缩小到 [0.056, 0.072),依此类推。最后一个消息符号(必须保留作为特殊的结束消息指示符)将范围缩小到 [0.06752, 0.0688)。当然,此子区间内的任何数,例如 0.068,都可以用来表示该消息。在图 8.12 的算术编码消息中,使用三个十进制数字来表示五符号消息。这意味着每一个信源符号需要 0.6 个十进制数字,这与信源的熵(按公式 8.6 计算,每一个信源符号为 0.58 个十进制数字)相比表现良好。随着待编码序列长度的增加,生成的算术编码会接近 Shannon 第一定理建立的界限。实际上,有两个因素导致编码性能低于该界限:(1)需要添加结束消息指示符来区分不同的消息,以及(2) 使用有限精度算术运算。算术编码的实际实现通过引入缩放策略和舍入策略来解决后一个问题( Langdon 和 Rissanen [1981])。缩放策略在根据符号概率对每一个子区间进行细分之前,将其重新规范化到 [0, 1) 范围内。舍入策略确保与有限精度算术相关的截断不会妨碍编码子区间得到精确表示。
表 8.7:算术编码例子。
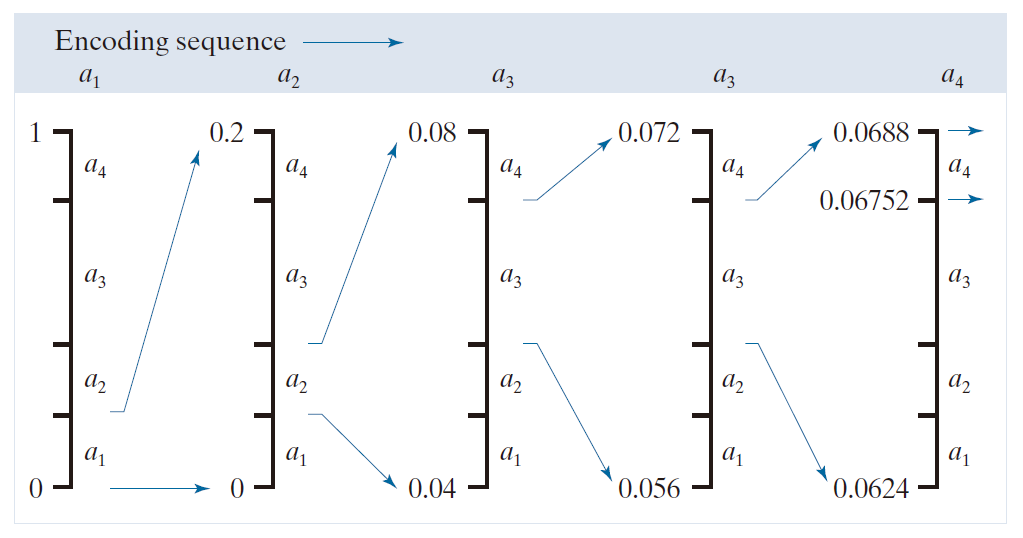
-------------------------图 8.12:算术编码过程-----------------------------
8.4.1 自适应上下文相关概率估计(Adaptive Context Dependent Probability Estimates)
如果输入符号概率模型准确,即模型能够提供待编码符号的真实概率,那么算术编码器在最小化表示待编码符号所需的平均码字数量方面接近最优。然而,与 Huffman 编码和 Golomb 编码一样,不准确的概率模型会导致非最优结果。提高所用概率准确性的一种简单方法是使用自适应的上下文相关概率模型。自适应概率模型会随着符号的编码或成为已知而更新符号概率。因此,概率会适应待编码符号的局部统计特性。上下文相关模型提供的概率基于待编码符号周围预定义的像素邻域(称为上下文)。通常使用因果上下文(仅限于已编码的符号)。Q 编码器(Pennebaker 等人 [1988])和 MQ 编码器(ISO/IEC [2000])是两种著名的算术编码技术,已被纳入 JBIG、JPEG-2000 和其他重要的图像压缩标准中,它们都使用自适应且上下文相关的概率模型。Q 编码器在算术编码过程中的区间归一化阶段动态更新符号概率。自适应上下文相关模型也已用于 Golomb 编码,例如在 JPEG-LS 压缩标准中。
图 8.13(a) 示意图展示了二元信源符号的自适应、上下文相关算术编码所涉及的步骤。当需要对二元符号进行编码时,通常会使用算术编码。在每一个符号(或位)开始编码过程时,其上下文会在图 8.13(a) 的上下文确定模块中形成。图 8.13(b) 至 (d) 显示了三种可能的上下文:(1) 紧邻的前一个符号,(2) 一组前置符号,以及 (3) 一定数量的前置符号加上前一行扫描线上的符号。对于所示的三种情况,概率估计模块必须管理 (或 2)、
(或 256) 和
(或 32 )个上下文及其相关的概率。例如,如果使用图 8.13(b) 中的上下文,则必须跟踪条件概率 P(0| a = 0)( 给定前一个符号为 0 的情况下,当前编码符号为 0 的概率 )、P( 1|a = 0)、P(0 | a = 1) 和 P(1 | a = 1 )。然后,根据当前上下文,将相应的概率传递给算术编码模块,并根据图 8.12 所示的过程驱动算术编码输出序列的生成。然后更新与当前编码步骤相关的上下文的概率,以反映在该上下文中又处理了一个符号的事实。
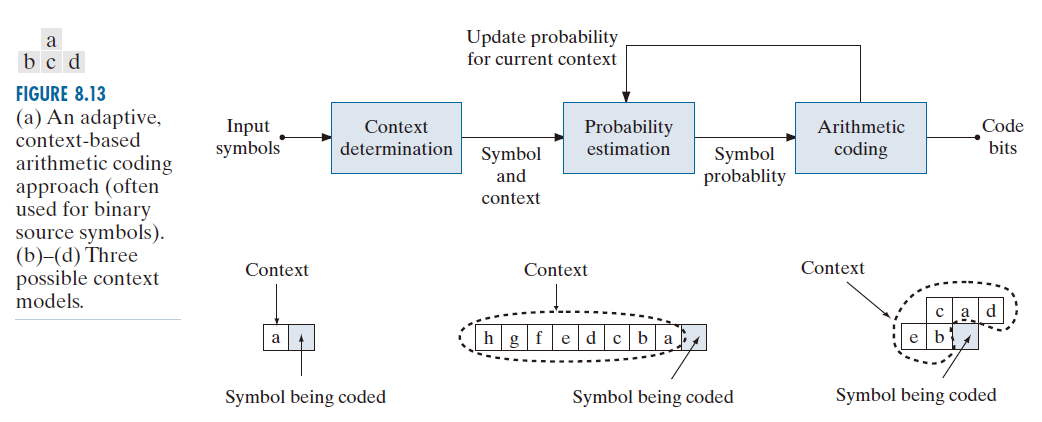
----------------------图 8.13:(a) 一种自适应的、基于上下文的算术编码方法(常用于二进制信源符号)。(b)-(d) 三种可能的上下文模型。----------------------
最后,我们注意到多种算术编码技术受美国专利保护(也可能在其他司法管辖区受到保护)。由于这些专利以及侵权可能导致的不利经济判决,大多数 JPEG 压缩标准的实现(该标准包含 Huffman 编码和算术编码两种选项)通常只支持 Huffman 编码。
8.5 LZW编码(LZW Coding)
第 8.2 节至 8.4 节介绍的技术着重于消除编码冗余。在本节中,我们将探讨一种无损压缩方法,该方法也能处理图像中的空间冗余。这种技术称为 Lempel-Ziv-Welch (LZW) 编码,它将定长码字分配给变长信源符号序列。回想一下前面关于图像信息度量的章节,Shannon 在他的第一个定理的证明中使用了对信源符号序列而不是单个信源符号进行编码的思想。LZW 编码的一个关键特点是它不需要事先了解待编码符号的出现概率。尽管直到最近它仍然受到美国专利的保护,但 LZW 压缩已被集成到各种主流图像文件格式中,包括 GIF、TIFF 和 PDF。PNG 格式的创建就是为了规避 LZW 的许可要求。
例子 8.6:LZW 编码图 7.9(a)。
再次考虑图 8.9(a) 中的 512 × 512 像素、8 位图像。使用 Adobe Photoshop,该图像的未压缩 TIFF 版本需要 286,740 字节的磁盘空间——其中 262,144 字节用于存储 512 × 512 像素的 8 位图像数据,另加 24,596 字节的开销。然而,如果使用 TIFF 的 LZW 压缩选项,生成的文件大小为 224,420 字节。压缩比为 C = 1.28 。回想一下,在示例 8.4 中,图 8.9(a) 的 Huffman 编码表示的压缩比为 C = 1.077。LZW 方法实现的额外压缩是由于消除了图像中的一些空间冗余。
LZW 编码在概念上非常简单(Welch [1984])。在编码过程开始时,会构建一个包含待编码源符号的码本或字典。对于 8 位单色图像,字典的前 256 个词被分配给强度值0、1、2、……、255 。编码器依次扫描图像像素,将字典中不存在的强度序列存储到算法确定的位置(例如,下一个未使用的位置)。例如,如果图像的前两个像素是白色,则序列“255-255”可能会被分配到位置 256,即紧随强度级别 0 到 255 保留位置之后的地址。下次遇到两个连续的白色像素时,将使用码字 256 (即包含序列 255-255 的位置的地址)来表示它们。如果在编码过程中使用 9 位 512 字的字典,则用于表示这两个像素的原 (8+8)位将被单个 9 位码字替换。显然,字典的大小是一个重要的系统参数。如果字典太小,检测匹配强度序列的可能性就会降低;如果字典太大,码字的大小会不利于压缩性能。
例子 8.7:LZW 编码。
考虑以下这张 4 * 4 像素、8 位深度的垂直边缘图像:
表 8.8 详细描述了对其 16 个像素进行编码的步骤。假设使用一个包含以下初始内容的 512 字词典:
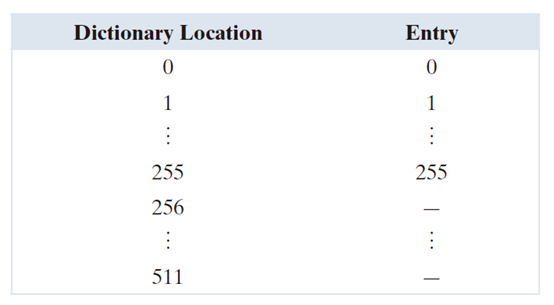
位置 256 到 511 最初是未使用的。
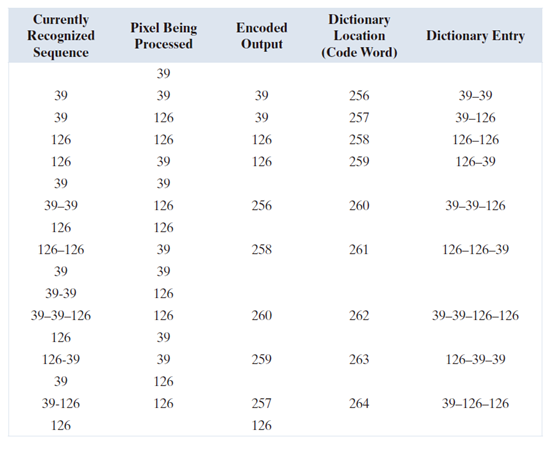
图像通过从左到右、从上到下的方式处理像素进行编码。每个连续的强度值都与一个变量(表 8.8 的第一列)连接起来,该变量称为“当前识别序列”。如图所示,该变量最初为空。对每一个连接后的序列进行字典查找,如果找到(如表第一行所示),则将其替换为新连接并识别的序列(即在字典中找到的序列)。这在表第二行的第一列中完成。此时不生成输出代码,也不修改字典。但是,如果未找到连接后的序列,则将当前识别序列的地址作为下一个编码值输出,将连接但未识别的序列添加到字典中,并将当前识别序列初始化为当前像素值。这发生在表的第二行。最后两列详细描述了扫描整个 128 位图像时添加到字典中的强度序列。定义了九个额外的码字。编码完成后,字典包含 265 个码字,LZW 算法成功识别了几个重复的强度序列——利用这些序列将原 128 位图像压缩到 90 位(即 10 个 9 位代码)。编码输出是通过从上到下读取第三列获得的。最终的压缩比为 1.42:1。
表 8.8:LZW 编码例子。
刚才演示的 LZW 编码的一个独特之处在于,编码字典或代码簿是在数据编码过程中创建的。值得注意的是,LZW 解码器在同时解码编码数据流的同时,也会构建一个相同的解压缩字典。读者可以尝试完成以下练习(参见问题 8.20),对前面示例的输出进行解码并重建代码簿。虽然在本示例中不需要,但大多数实际应用都需要一种处理字典溢出的策略。一种简单的解决方案是,当字典满时清空或重新初始化字典,并使用新的初始化字典继续编码。另一种更复杂的方案是监控压缩性能,并在性能下降或无法接受时清空字典。此外,还可以跟踪使用频率最低的字典条目,并在必要时进行替换。
8.6 游程编码(Run Length Coding)
如前所述,图像中沿行(或列)方向具有重复强度值的区域通常可以通过游程编码进行压缩。游程编码将连续的相同强度值表示为游程对,其中每个游程对指定新强度值的起始位置以及具有该强度值的连续像素数量。这种技术称为游程编码(RLE),它于20世纪50年代开发出来,并与它的二维扩展一起成为传真编码的标准压缩方法。压缩是通过消除一种简单的空间冗余形式——即一组相同的强度值——来实现的。当相同像素的连续序列很少(或没有)时,游程编码会导致数据膨胀。
例子 8.8:BMP文件格式中的 RLE 压缩。
BMP 文件格式使用一种游程编码方式,其中图像数据以两种不同的模式表示:编码模式和绝对模式。这两种模式可以出现在图像的任何位置。在编码模式下,使用两个字节的行程长度编码表示。第一个字节指定具有第二个字节中包含的颜色索引的连续像素的数量。8 位颜色索引从包含 256 种可能强度的表中选择该行程的强度(颜色或灰度值)。
在绝对模式下,第一个字节为 0,第二个字节指示四种可能情况之一,如表 8.9 所示。当第二个字节为 0 或 1 时,表示已到达行尾或图像末尾。如果第二个字节为 2,则接下来的两个字节包含指向图像中新空间位置(和像素)的无符号水平和垂直偏移量。如果第二个字节介于 3 到 255 之间,则指定后面未压缩像素的数量,每个后续字节包含一个像素的颜色索引。总字节数必须对齐到 16 位字边界。
表 8.9:BMP 绝对编码模式选项。在此模式下,BMP 对的第一个字节为 0。

图 8.9(a) 所示的 512 × 512 × 8 位图像,如果使用 Photoshop 保存为未压缩的 BMP 文件,需要 263,244 字节的内存。如果使用 BMP 的 RLE 选项进行压缩,文件大小会膨胀到 267,706 字节,压缩比为 C = 0.98。由于图像中没有足够的连续相同像素值,因此游程编码压缩效果不佳,反而导致文件略微增大。然而,对于图 8.1(c) 中的图像,使用 BMP 的 RLE 选项可以获得 C = 1.35 的压缩比。(请注意,由于开销不同,未压缩的 BMP 文件比示例 8.6 中的未压缩 TIFF 文件要小。)
游程编码在压缩二值图像时特别有效。由于只有两种可能的像素值(黑色和白色),相邻像素更有可能相同。此外,每行图像只需用一系列长度来表示,而不是像示例 8.8 中那样使用长度-强度对。基本思想是,在对图像行进行从左到右扫描时,将遇到的每一个连续的 0 或 1 序列(即游程)用其长度进行编码,并建立一种约定来确定游程的值。最常见的约定是:(1) 指定每行第一个游程的值;或(2) 假设每行都以白色游程开头,其游程实际上可能为零。
尽管游程编码本身就是一种有效的二值图像压缩方法,但通过对游程本身进行变长编码,可以实现额外的压缩。黑色和白色游程可以分别使用专门针对其自身统计特性定制的变长码进行编码。例如,令符号 表示长度为 j 的黑色游程,我们可以通过以下方式估计符号
由假想的黑色游程信源发出的概率:将整幅图像中长度为 j 的黑色游程的数量除以黑色游程的总数。将这些概率代入公式 (8-6),即可得到该黑色游程源的熵估计值,记为
。类似的论证也适用于白色游程的熵,记为
。图像的近似游程熵为:
(8-18)
其中,变量 和
分别表示黑白游程之平均值。公式 (8-18) 提供了使用变长编码对二值图像中的游程进行编码所需的平均每像素位数的估计值。
两种最古老、应用最广泛的图像压缩标准是用于二值图像压缩的 CCITT Group 3 和 Group 4 标准。尽管它们已被用于各种计算机应用,但最初设计它们是为了作为传真 (FAX) 编码方法,用于通过电话网络传输文档。Group 3 标准使用一维游程编码技术,其中每组 K 行( K = 2 或 4 ) 的最后 K - 1 行可以选择性地以二维方式编码。Group 4 标准是 Group 3 标准的简化或精简版本,仅允许二维编码。这两个标准都使用相同的二维编码方法,这种方法之所以称为二维,是因为它利用前一行的信息来编码当前行。接下来将讨论一维和二维编码。
8.6.1 一维CCITT 压缩(One-Dimensional CCITT Compression)
在一维 CCITT Group 3 压缩标准中,图像的每一行(注:在标准中,图像称为页面,图像序列称为文档)都编码为一系列变长 Huffman 码字,这些码字代表了从左到右扫描该行时交替出现的白色和黑色像素序列的长度。这种压缩方法通常称为改进 Huffman(MH-Modified Huffman)编码。码字本身有两种类型,标准中称之为终止码和补码。如果像素序列长度 r 小于或等于 63 ,则使用终止码来表示它。该标准为黑色和白色像素序列指定了不同的终止码。如果 r > 63,则使用两个码字:一个补码用于表示商 ,一个终止码用于表示余数 r mod 64。补码可能取决于也可能不取决于被编码像素序列的颜色(黑色或白色)。如果
,则指定了单独的黑色和白色像素序列补码;否则,补码与像素序列的颜色无关。该标准要求每一行都以一个白色像素序列长度码字开头,该码字实际上可以是 00110101,表示长度为零的白色像素序列。最后,使用一个唯一的行结束(EOL)码字 000000000001 来终止每一行,并用于标记每个新图像的第一行。连续六个 EOL 码字表示图像序列的结束。
8.6.2 二维CCITT 压缩(Two-Dimensional CCITT Compression)
CCITT Group 3 和 Group 4 标准都采用了二维压缩方法,这是一种逐行编码方法,其中每一个黑白或白黑像素序列转换的位置都相对于当前编码行上的参考元素 的位置进行编码。前一行称为参考行;对于每一幅新图像的第一行,其参考行是一条假想的白色行。所使用的二维编码技术称为相对元素地址指定(READ)编码。在 Group 3 标准中,连续的 MH 编码行之间允许有一到三行 READ 编码行;这种技术称为改进型 READ (MR) 编码。在 Group 4 标准中,允许更多的 READ 编码行,这种方法称为改进的改进型 READ (MMR) 编码。如前所述,这种编码是二维的,因为编码当前行时使用了前一行的信息。但其中不涉及二维变换。
图 8.14 显示了单条扫描线的基本二维编码过程。请注意,该过程的初始步骤旨在定位几个关键的变换元素: 和
。根据标准,变换元素定义为与同一行上上一个像素值不同的像素。最重要的变换元素是
(参考元素),它要么设置为每一条新编码行第一个像素左侧的假想白色变换元素的位置,要么根据之前的编码模式确定。编码模式将在下一段中讨论。找到
后,
确定为当前编码行上右侧的下一个变换元素的位置,
确定为编码行上
右侧的下一个变换元素的位置,
确定为参考(或上一)行上与
值相反且位于
右侧的变换元素,
确定为参考行上
右侧的下一个变换元素。如果未检测到任何这些变换元素,则将其设置为相应行上最后一个像素右侧的假想像素位置。图 8.15 提供了各种变换元素之间一般关系的两个示例。
在确定当前参考元素和相关变化元素后,执行两个简单的测试来选择三种可能的编码模式之一:直通模式、垂直模式或水平模式。第一个测试对应于图 8.14 流程图中的第一个分支点,它比较 的位置与
的位置。第二个测试对应于图 8.14 中的第二个分支点,它计算
和
位置之间的距离(以像素为单位),并将其与 3 进行比较。根据这些测试的结果,进入图 8.14 中所示的三种编码块之一,并执行相应的编码过程。然后,根据流程图,建立一个新的参考元素,为下一次编码迭代做准备。
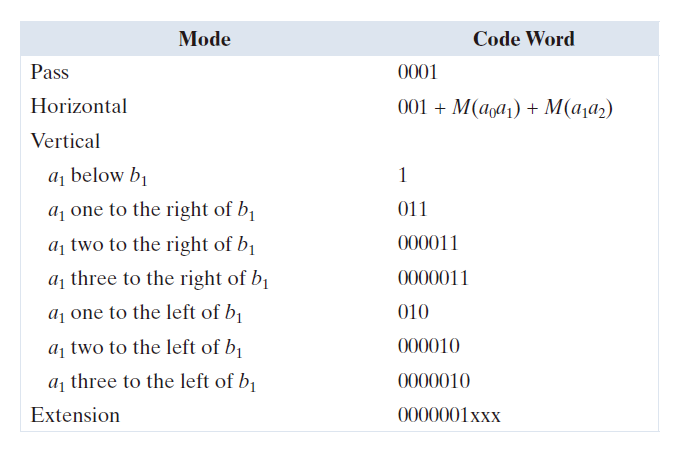
表 8.10 定义了三种可能的编码模式所使用的特定代码。在跳过模式下(该模式特指 不直接位于
上方的情况),只需要使用跳过模式代码字 0001。如图 8.15(a) 所示,此模式用于识别与当前白色或黑色编码行不重叠的白色或黑色参考行。在水平编码模式下,
到
和
到
的距离必须根据一维 CCITT 第三组压缩的终止码和构成码进行编码,然后附加到水平模式代码字 001 之后。表 8.10 中用符号
表示,其中
和
分别表示
到
和
到
的距离。最后,在垂直编码模式下,将六个特殊的变长代码之一分配给
和
之间的距离。图 8.15(b) 说明了水平和垂直模式编码中涉及的参数。表 8.10 底部的扩展模式代码字用于进入可选的传真编码模式。例如,代码 0000001111 用于启动未压缩的传输模式。
表 8.10:CCITT 二维编码表。
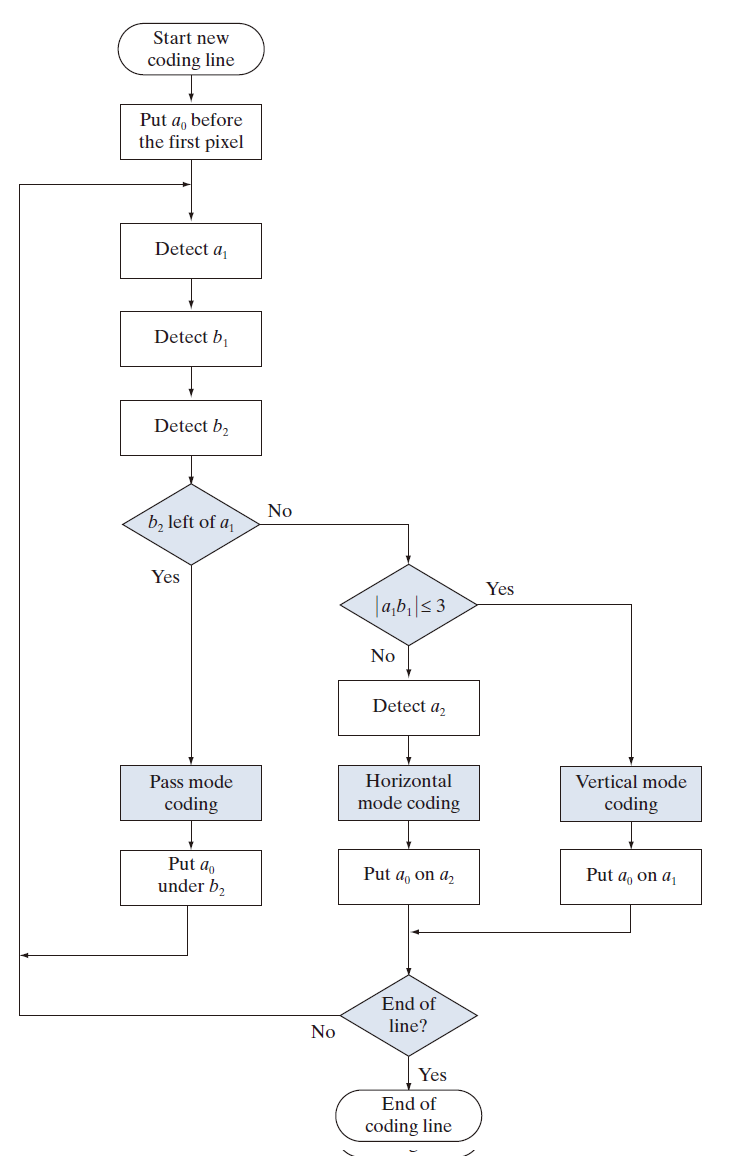
-------------------------图 8.14:CCITT 二维 READ 编码过程。符号 表示变化元素
和
之间距离的绝对值。----------------------------------------
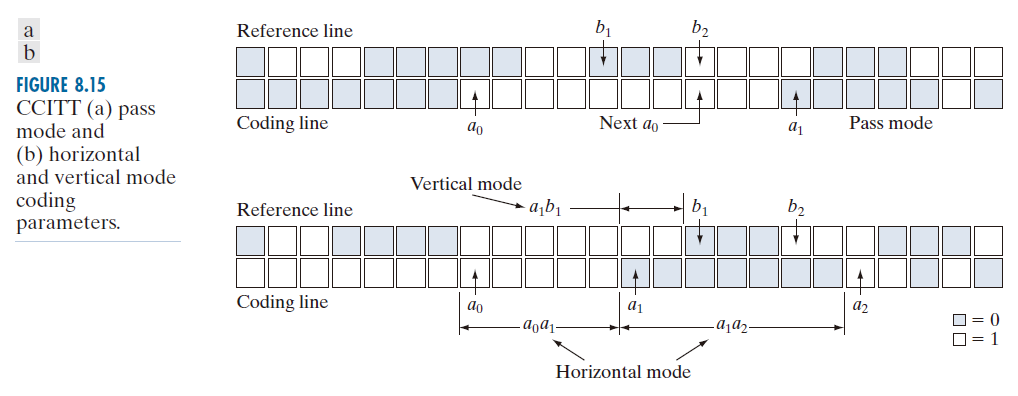
-------------图 8.15:CCITT (a) 直通模式和 (b) 水平及垂直模式编码参数。-------
例子 8.9:CCITT 垂直模式编码例子。
尽管图 8.15(b) 中标注了水平和垂直模式编码的参数(以便于上述讨论),但图中所示的黑白像素模式实际上是垂直模式编码的情况。这是因为 位于
的右侧,所以图 8.14 中的第一个测试(即跳过模式测试)失败。第二个测试用于确定是进入垂直编码模式还是水平编码模式,该测试表明应该使用垂直模式编码,因为
到
的距离小于 3 。根据表 8.10,相应的码字是 000010,这意味着
位于
左侧两个像素的位置。为了准备下一次编码迭代,
被移动到
的位置。
例子 8.10:CCITT 压缩例子。
图 8.16(a) 是对一张 7 × 9.25 英寸书页进行 300 dpi 扫描后得到的图像,显示比例约为 1/3。请注意,页面约有一半是文字,约 9% 是半色调图像,其余部分是空白。图 8.16(b) 显示了该页面的一部分放大图。请记住,我们处理的是二值图像;正如第 4.5 节所述,灰度效果是通过印刷中使用的半色调处理过程产生的。如果图 8.16(a) 中的二值像素以每字节 8 个像素为一组存储,则 1952 × 2697 位的扫描图像(通常称为文档)需要 658,068 字节。该文档的未压缩 PDF 文件(使用 Photoshop 创建)需要 663,445 字节。CCITT Group 3 压缩将文件大小减小到 123,497 字节,压缩比 C = 5.37 。CCITT Group 4 压缩将文件大小减小到 110,456 字节,使压缩比提高到约 6 。

----------------------图 8.16:书页的二值图像扫描图:(a)按比例缩放以显示页面整体内容;(b)按比例缩放以显示用于抖动处理的二值像素。----------------------
8.7 基于符号的编码(Symbol-Based Coding)
在基于符号或标记的编码中,图像表示为一组频繁出现的子图像,这些子图像称为符号。每一个符号都存储在符号字典中,图像编码为一组三元组 ,其中每一对
指定符号在图像中的位置,标记
是符号或子图像在字典中的地址。也就是说,每一个三元组代表图像中字典符号的一个实例。只存储一次重复出现的符号可以显著压缩图像,尤其是在文档存储和检索应用中,因为这些符号通常是字符位图,并且会重复出现多次。
考虑图 8.17(a) 中的简单二值图像。它包含单词“banana”,该单词由三个不同的符号组成:一个 b、三个 a 和两个 n 。假设在编码过程中首先识别到符号 b ,则其 9 × 7 的位图存储在符号字典的第 0 个位置。如图 8.17(b) 所示,标识 b 位图的标记为 0。因此,编码图像表示中的第一个三元组[参见图 8.17(c)] 是 (0, 2, 0),表示代表符号 b 的矩形位图的左上角(一个任意约定)应放置在解码图像的 (0, 2) 位置。在识别出符号 a 和 n 的位图并将其添加到字典后,图像的其余部分可以用另外五个三元组进行编码。只要定位图像中符号所需的六个三元组以及定义这些符号所需的三个位图的总大小小于原始图像的大小,就会发生压缩。在本例中,原始图像的大小为 9 × 51 × 1 或 459 位,假设每个三元组由三个字节组成,则压缩后的表示大小为 (6 × 3 × 8) + [(9 × 7) + (6 × 7) + (6 × 6)] 或 285 位;得到的压缩比 C = 1.61 。要解码图 8.17(c) 中的基于符号的表示,只需从符号字典中读取三元组中指定的符号的位图,并将它们放置在每个三元组指定的空间坐标处即可。

----------------------------------图 8.17:(a) 一份双层文档,(b) 符号字典,以及 (c) 用于定位文档中符号的三元组。-------------------------------------------
8.7.1 JBIG2 压缩(JBIG2 Compression)
JBIG2 是一种用于二值图像压缩的国际标准。它将图像分割成重叠和/或不重叠的文本、半色调和通用内容区域,并对每种类型的内容采用专门优化的压缩技术:
(1) 文本区域(Text regions)由字符组成,这些字符非常适合基于符号的编码方法。通常,每一个符号对应一个字符位图——一个代表文本字符的子图像。在符号字典中,每一种字体的大写和小写字符通常只有一个字符位图(或子图像)。例如,字典中会有一个“a”的位图,一个“A”的位图,一个“b”的位图,依此类推。
在有损 JBIG2 压缩(通常称为感知无损或视觉无损压缩)中,我们忽略了字典位图(即参考字符位图或字符模板)与图像中相应字符的特定实例之间的差异。在无损压缩中,这些差异会被存储起来,并与用于编码每个字符的三元组(由解码器)结合使用,以生成实际的图像位图。所有位图都使用算术编码或 MMR 编码(参见第 8.6 节)进行编码;用于访问字典条目的三元组则使用算术编码或 Huffman 编码。
(2) 半色调区域(Halftone regions)与文本区域类似,都是由规则排列的图案组成。然而,字典中存储的符号并非字符位图,而是周期性图案,这些图案代表经过抖动处理以生成用于打印的双色图像的强度(例如照片的强度)。
(3) 通用区域(Generic regions)包含非文本、非半色调信息,例如线条图和噪点,并使用算术编码或 MMR 编码进行压缩。
与许多图像压缩标准一样,JBIG2 标准定义了解码器的行为。它没有明确定义标准编码器,但其灵活性足以允许各种编码器设计。尽管编码器的设计未作具体规定,但它至关重要,因为它决定了最终实现的压缩率。毕竟,编码器必须将图像分割成不同的区域,选择存储在字典中的文本和半色调符号,并判断这些符号与图像中潜在的符号实例是基本相同还是有所不同。解码器只需利用这些信息即可重建原图像。
例子 8.11:JBIG2 压缩例子。
再次考虑图 8.16(a) 中的二值图像。图 8.18(a) 显示了使用无损 JBIG2 编码(通过市售文档压缩应用程序)后重建的图像片段。它是原图像的精确副本。请注意,尽管重建文本中的字符 d 都是由字典中相同的 d 条目生成的,但它们之间略有差异。这些差异被用于改进字典的输出。标准定义了一种算法,用于在解码编码后的字典位图时实现这一过程。为了便于理解,您可以将其视为将字典位图与图像中相应字符的特定实例之间的差异添加到从字典读取的位图中。
图 8.18(b) 是对图 8.18(a) 所示区域进行感知无损 JBIG2 压缩后的重建图像。请注意,图中所有的“d”字符都是相同的。它们直接复制自符号字典。这种重建被称为感知无损,因为文本清晰可读,甚至字体也完全相同。图 8.18(c) 显示了原始图像中的“d”字符与字典中的“d”字符之间的微小差异,这些差异被认为是无关紧要的,因为它们不会影响可读性。请记住,我们处理的是二值图像,因此图 8.18(c) 中只有三种灰度值。灰度值 128 表示图 8.18(a) 和 (b) 中对应像素值相同的区域;灰度值 0(黑色)和 255(白色)表示两个图像中像素值相反的区域——例如,一个图像中的黑色像素在另一个图像中是白色像素,反之亦然。
用于生成图 8.18(a) 的无损 JBIG2 压缩将原始 663,445 字节的未压缩 PDF 图像文件大小减小到 32,705 字节;压缩比为 C = 20.3。感知无损 JBIG2 压缩将图像文件大小减小到 23,913 字节,使压缩比提高到约 27.7。这些压缩效果比示例 8.10 中 CCITT Group 3 和 Group 4 的压缩效果高 4 到 5 倍。

--------------------------图 8.18:JBIG2 压缩比较:(a)无损压缩和重建;(b)感知无损压缩;(c)两者之间的缩放差异。---------------------------------------------
8.8 位平面编码(Bit Plane Coding)
前几节介绍的游程编码和基于符号的技术可以应用于具有两个以上灰度级的图像,方法是分别处理其位平面。这种技术称为位平面编码,其基本思想是将多级(单色或彩色)图像分解为一系列二值图像(参见第 3.2 节),然后使用几种常用的二值图像压缩方法之一对每一个二值图像进行压缩。在本节中,我们将介绍两种最常用的分解方法。
一个 m 位单色图像的像素强度可以表示为以 2 为底的多项式
(8-19)
基于此特性,一种将图像分解为一系列二值图像的简单方法是将多项式的 m 个系数分离成 m 个 1 位位平面。正如第 3.2 节所述,最低阶位平面(对应于最低有效位的平面)是通过收集每一个像素的 位生成的,而最高阶位平面包含
位或系数。通常,每一个位平面都是通过将其像素值设置为原图像中每一个像素的相应位或多项式系数的值来构建的。这种分解方法的固有缺点是,强度值的微小变化会对位平面的复杂性产生显著影响。例如,如果强度为 127 (01111111) 的像素与强度为 128 (10000000) 的像素相邻,则每一个位平面都将包含相应的 0 到 1 (或 1 到 0)的转变。例如,由于 127 和 128 的二进制代码的最高有效位不同,因此最高位平面将包含一个值为零的像素,其旁边是一个值为 1 的像素,从而在该点产生 0 到 1(或 1 到 0)的转变。
另一种分解方法(可以减少微小强度变化的影响)是先用 m 位 Gray 码来表示图像。与公式 (8-19) 中的多项式相对应的 m 位 Gray 码 可根据
(8-20) ( 0 ≤ i ≤ m - 2 )
进行计算。这里,⊕ 表示异或运算。这段代码具有一个独特的特性,即连续的码字之间只有一个位不同。因此,强度上的微小变化不太可能影响所有 m 个位平面。例如,当强度级别为 127 和 128 时,只有最高位的位平面会发生从 0 到 1 的转变,因为与 127 和 128 对应的 Gray 码分别是 01000000 和 11000000 。
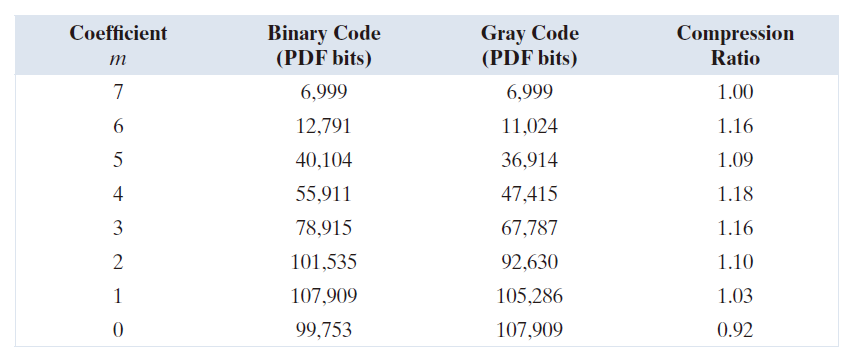
例子 8.12:位平面编码。
图 8.19 和图 8.20 显示了图 8.19(a) 中儿童图像的 8 位单色图像的八个二进制和Gray 码位平面。请注意,高阶位平面比低阶位平面复杂程度低得多。也就是说,它们包含大面积的均匀区域,细节、纹理或随机性显著减少。此外,Gray 码位平面比相应的二进制位平面复杂程度更低。这两个观察结果都反映在表 8.11 的 JBIG2 编码结果中。例如,请注意, 和
的结果明显大于
和
的压缩结果,并且
和
都小于其对应的
和
。这种趋势贯穿整个表格,唯一的例外是
。Gray 码平均提供约 1.06:1 的压缩优势。综合来看,Gray 码文件将原始单色图像压缩到 678, 676/475, 964,即 1.43:1;非 Gray 码文件将图像压缩到 678,676/503,916,即 1.35:1 。
最后,我们注意到图 8.20 中两个最低有效位几乎没有明显的结构。由于大多数 8 位单色图像都具有这种特性,因此位平面编码通常仅限于每像素 6 位或更少的图像。JBIG1(JBIG2 的前身)就强制规定了这样的限制。

------------------------图 8.19:(a) 一幅256级灰度图像。(b)-(h) 图(a)所示图像的四个最高有效二进制位平面和 Gray 码位平面。----------------------------------
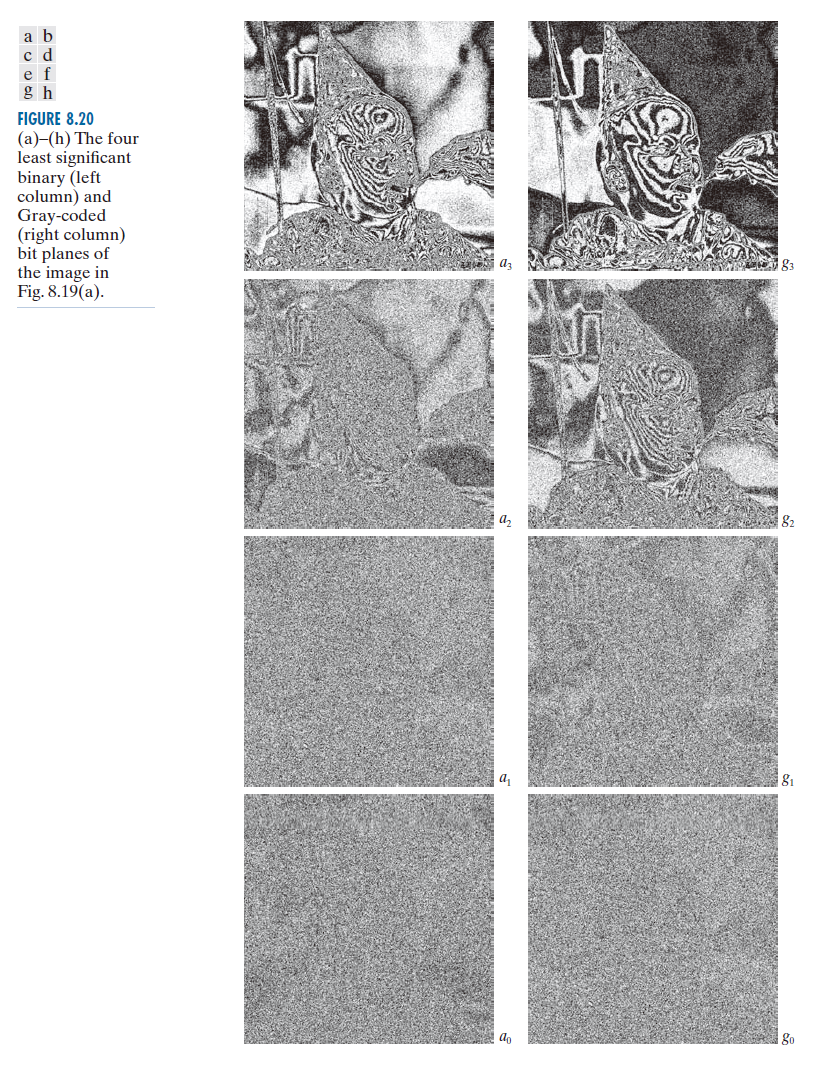
------------------------图 8.20:(a)至(h):图 8.19 (a)中图像的四个最低有效二进制位(左列)平面和 Gray 码(右列)位平面。----------------------------------------
表 8.11:图 8.19(a) 中二值位平面和格雷码位平面的 JBIG2 无损编码结果。这些结果包含了每个位平面 PDF 表示的开销。
8.9 块变换编码(Block Transform Coding)
在本节中,我们将讨论一种压缩技术,该技术将图像分割成大小相等且互不重叠的小块(例如 8×8 像素),并使用二维变换独立处理这些图像块。在块变换编码中,使用可逆线性变换(例如 Fourier 变换)将每一个图像块或子图像映射到一组变换系数,然后对这些系数进行量化和编码。对于大多数图像,相当一部分系数的幅值较小,可以进行粗略量化(或完全丢弃),而不会造成明显的图像失真。可以使用多种变换方法来变换图像数据,包括第四章中介绍的离散 Fourier 变换 ( DFT )。
图 8.21 显示了一个典型的块变换编码系统。解码器执行与编码器相反的步骤序列(量化功能除外),编码器执行四个相对简单的操作:子图像分解、变换、量化和编码。一个 M × N 的输入图像首先被细分为 n × n 大小的子图像,然后对这些子图像进行变换,生成 个子图像变换数组,每个数组的大小为 n × n 。变换过程的目标是消除每一个子图像像素之间的相关性,或者将尽可能多的信息压缩到最少的变换系数中。量化阶段选择性地消除或更粗略地量化那些在预定义意义上携带信息量最少的系数(本节后面将讨论几种方法)。这些系数对重建子图像的质量影响最小。编码过程最终对量化后的系数进行编码(通常使用变长编码)。所有或部分变换编码步骤都可以根据局部图像内容进行调整,这称为自适应变换编码(adaptive transform coding);或者对所有子图像使用固定的步骤,这称为非自适应变换编码(nonadaptive transform coding)。
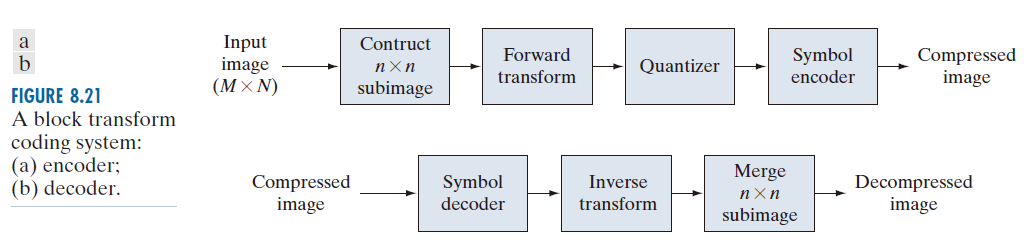
----------------图 8.21:一种块变换编码系统:(a) 编码器;(b) 解码器。--------
8.9.1 变换选择(Transform Selection)
基于各种二维离散变换的块变换编码系统已获广泛构建和/或研究。在特定应用中选择哪种变换取决于可容忍的重建误差大小和可用的计算资源。压缩是在对变换系数进行量化时实现的(而不是在变换步骤中实现的)。
例子 8.13:用 DFT、WHT 和 DCT 进行块变换编码。
图 8.22(a) 至 (c) 显示了图 8.9(a) 所示的 512 × 512 单色图像的三种近似图像。这些图像是通过将原图像分割成 8 × 8 大小的子图像,然后使用第 7 章中描述的三种变换(DFT、WHT 和 DCT 变换)对每个子图像进行变换,截断 50% 的变换系数,最后对截断后的系数数组进行逆变换得到的。
在每一种情况下,都根据系数的绝对值大小选择了保留的 32 个系数。值得注意的是,在所有情况下,被舍弃的 32 个系数对重建图像的质量几乎没有视觉影响。然而,舍弃这些系数会导致一定的均方误差,这可以从图 8.22( d ) 到 ( f ) 的缩放误差图像中看出。实际的均方根误差分别为 2.32、1.78 和 1.13 强度单位。

-------------图 8.22:图 8.9(a) 的近似结果,分别使用 (a) Fourier变换、(b) Walsh-Hadamard 变换和 (c) 余弦变换,以及相应的缩放误差图像 ( d )-( f )。------
前面例子中观察到的均方重建误差的微小差异与所使用的变换的能量或信息压缩特性直接相关。根据第 7.5 节中的公式 (7-75) 和 (7-76),一个 n × n 的子图像 g ( x, y ) 可以表示为其二维变换 T ( u ,v ) 的函数:
(8-21) ( 对于 x, y = 0 ,1 ,2,…,n - 1 )
G 是包含输入子图像像素的矩阵,其显式定义为大小为 n × n 的 个基图像的一个线性组合。回顾一下, n = 8 时 DFT , DCT , 和 WHT 变换如图 7.7 ,7.10,和 7.16 所示。这时,若我们定义一个变换系数掩码函数(masking function)
(8-22)
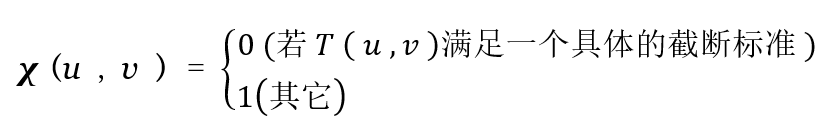
( 对于 u, v = 0 ,1 ,2,…,n - 1 ) ,则 G 的一个近似可以从截断展式
(8-23)
而求得,其中,χ (u , v ) 的构建是用于消除使得对公式 (8-21) 中的总和贡献最小的基图像。则子图像 G 和近似 之间的均方误差是
(8-24)
其中, 是矩阵
而
是变换位置 (u , v ) 处的系数之方差,最终的简化是基于基图像的正交归一化特征以及 G 的像素是由具有零均值和已知协方差的随机过程生成的假设。因此,近似的总均方误差是所有被舍弃的变换系数的方差之和;即,对于那些 χ (u , v ) = 0 的系数,公式 (8-24)中的 [ 1 - χ (u , v ) ] 1 。能够将大部分信息集中到最少系数中的变换可以提供最佳的子图像近似,从而产生最小的重建误差。最后,在导致公式 (8-24) 成立的假设下,M × N 图像的 MN 个子图像的均方误差是相同的。因此,M × N 图像的均方误差(作为平均误差的度量)等于单个子图像的均方误差。
前面的例子表明, DCT 的信息压缩能力优于离散 DFT和 WHT 。虽然这种情况通常适用于大多数图像,但从信息压缩的角度来看,最优变换是 Karhunen-Loève 变换(参见第11章),而不是DCT。这是因为 KLT 可以使公式(8-24)中的均方误差最小化,适用于任何输入图像和任何数量的保留系数( Kramer 和 Mathews [1956])。然而,由于 KLT 是数据相关的,因此,对于每一个子图像,获取 KLT 基图像通常是一项计算量很大的任务。正因如此,KLT 很少用于图像压缩。取而代之的是,通常使用基图像固定(与输入无关)的变换,例如DFT、WHT 或 DCT。在所有可能的与输入无关的变换中,非正弦变换( 例如 WHT 变换)实现起来最简单。而正弦变换(例如 DFT 或 DCT )则更接近最优 KLT 的信息压缩能力。
因此,大多数变换编码系统都基于 DCT ,因为它在信息压缩能力和计算复杂度之间取得了良好的平衡。事实上,DCT 的特性已被证明具有极高的实用价值,因此 DCT 已成为变换编码系统的国际标准。与其他输入无关的变换相比,它具有以下优点:可以集成到单个集成电路中实现;能够将最多的信息压缩到最少的系数中(对于大多数图像而言)(注:Ahmed 等人 [1974] 最早注意到,一阶 Markov 图像信源的 KLT 基图像与 DCT 的基图像非常相似。随着相邻像素之间的相关性趋近于 1,依赖于输入的 KLT 基图像将与不依赖于输入的 DCT 基图像完全相同(Clarke [1985]));并且能够最大限度地减少子图像边界可见而产生的块状伪影(称为块效应)。最后一个特性在与其他正弦变换的比较中尤为重要。正如第 7.6 节图7.11(a)所示,DFT 的隐式 n 点周期性会导致边界不连续,从而产生大量高频变换分量。当 DFT 变换系数被截断或量化时,Gibbs 现象(注:这种现象在大多数电路分析方面的电气工程教科书中都有描述,其原因是 Fourier 变换在断点处无法均匀收敛。在断点处,Fourier级数会取断点处的平均值)会导致边界点出现错误值,这些错误值在图像中表现为块状伪影。即,相邻子图像之间的边界变得可见,因为子图像的边界像素会取边界点处形成的不连续性的平均值[参见图7.11(a)]。图7.11(b) 所示的 DCT 可以减少这种效应,因为其隐式 2n 点周期性本身不会产生边界不连续。
8.9.2 子图像大小选择(Subimage Size Selection)
影响变换编码误差和计算复杂度的另一个重要因素是子图像大小。在大多数应用中,图像会分割成子图像,以降低相邻子图像之间的相关性(冗余度),使其达到可接受的水平;同时,子图像的尺寸 n 通常是 2 的整数次幂( n 为子图像的维数)。后一个条件简化了子图像变换的计算(参见第 4.11 节讨论的以 2 为基数的逐次加倍法)。一般来说,随着子图像尺寸的增大,压缩率和计算复杂度都会增加。最常用的子图像尺寸是 8 × 8 和 16 × 16。
例子 8.14:子图像大小对变换编码的影响。
图 8.23 以图形方式展示了子图像大小对变换编码重建误差的影响。图中绘制的数据是通过将图 8.9(a) 中的单色图像分割成大小为 n × n 的子图像(其中 n = 2, 4, 8, 16, …, 256, 512),计算每个子图像的变换,截断 75% 的变换系数,然后对截断后的系数进行逆变换得到的。请注意,当子图像大小大于 8 × 8 时,Hadamard 变换和余弦变换的曲线趋于平坦,而 Fourier 变换的重建误差在该区域继续下降。随着 n 的进一步增大,Fourier 变换的重建误差曲线与 Walsh-Hadamard 变换曲线相交,并趋近于余弦变换的结果。这一结果与 Netravali 和 Limb [1980] 以及 Pratt [2001] 对二维 Markov 图像信源的理论和实验研究结果一致。
当使用 2 × 2 子图像时,三条曲线相交。在这种情况下,每一个变换数组的四个系数中只保留了一个(25%)。在所有情况下,保留的系数都是 AC 分量,因此逆变换只是简单地用四个子图像像素的平均值替换它们[参见公式 (4-92)]。这种情况在图 8.24(b) 中清晰可见,该图显示了 2 × 2 DCT 结果的放大局部图像。请注意,随着子图像尺寸增大到 4 × 4 和 8 × 8(如图 8.24(c) 和 (d) 所示),这种结果中普遍存在的块状伪影会减少。图 8.24(a) 显示了原图像的放大局部图像,以供参考。
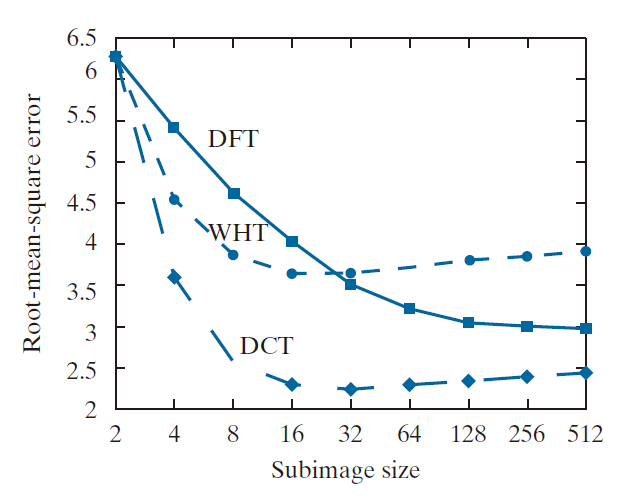
-------------------------图 8.23:重建误差与子图像尺寸的关系。----------------

-------------------------图 8.24:图 8.24 的近似结果:(a) 使用 25% 的 DCT 系数进行近似;(b) 使用 2 × 2 子图像进行近似;(c) 使用 4 × 4 子图像进行近似;(d) 使用 8 × 8 子图像进行近似。(a) 中的原始图像是图 8.9(a) 的放大局部图像。----------------------------------------------
8.9.3 位分配(Bit Allocation)
与公式 (8-23) 的截断级数展开相关的重建误差是丢弃的变换系数的数量和相对重要性以及用于表示保留系数的精度函数。在大多数变换编码系统中,保留的系数是根据最大方差(称为区域编码)或最大幅度(称为阈值编码)来选择的(即构建公式 (8-22) 中的掩码函数)。对变换后的子图像系数进行截断、量化和编码的整个过程通常称为位分配。
例子 8.15:位分配。
图 8.25(a) 和 (c) 显示了图 8.9(a) 的两种近似结果,其中每一个 8 × 8 子图像的 87.5% 的 DCT 系数被丢弃。第一个结果是通过阈值编码获得的,保留了八个最大的变换系数;第二个图像是通过区域编码方法生成的。在后一种情况下,每个 DCT 系数都被视为一个随机变量,其分布可以通过所有变换后的子图像的集合来计算。求得方差最大的八个分布(占变换后的 8 × 8 子图像中 64 个系数的 12.5% ),并用它们来确定所有子图像中保留的系数的坐标 [u 和 v ,T(u ,v)]。请注意,图 8.25(b) 中的阈值编码误差图像比图 8.25(d) 中的区域编码结果包含的误差更少。两个图像都已进行缩放,以使误差更加明显。相应的均方根误差分别为 4.5 和 6.5 强度值。

----------------图 8.25:图 8.9(a) 的近似结果(使用 12.5% 的 DCT 系数):(a)-(b)阈值编码结果;(c)-(d)区域编码结果。差异图像已缩放 4 倍。----------------------
8.9.3.1 区域编码实现(Zonal Coding Implementation)
区域编码基于信息论中将信息视为不确定性的概念。因此,方差最大的变换系数携带最多的图像信息,应在编码过程中保留下来。方差本身可以直接从 个变换后的子图像数组集合计算得出(如前例所示),或者基于假设的图像模型( 例如,Markov 自相关函数 ) 计算得出。无论哪种情况,根据公式 (8-23),区域采样过程都可以看作是将每一个 T(u ,v) 乘以区域掩码中对应的元素,该掩码的构建方法是在方差最大的位置置 1 ,在所有其他位置置 0。方差最大的系数通常位于图像变换的原点附近,从而形成图 8.26(a) 所示的典型区域掩码。
在区域采样过程中保留的系数必须进行量化和编码,因此有时会使用区域掩码来显示用于编码每一个系数的位数[参见图 8.26(b)]。在大多数情况下,这些系数分配到相同的位数,或者将一定数量的位数不均匀地分配给它们。在第一种情况下,系数通常会根据其标准差进行归一化并进行均匀量化。在第二种情况下,会为每一个系数设计一个量化器,例如最优的 Lloyd-Max 量化器(参见第 8.10 节中的最优量化器)。为了构建所需的量化器,通常将零阶或 AC 系数建模为 Rayleigh 概率密度函数,而其余系数则建模为 Laplace 或 Gauss 概率密度函数。(注:由于每一个系数都是其子图像中像素的线性组合[参见公式(7-31)],因此中心极限定理表明,随着子图像尺寸的增大,系数趋于服从Gauss 分布。然而,这一结论不适用于 AC 系数,因为非负图像的 AC 系数始终为正值。)分配给每一个量化器的量化级别数(以及位数)与 ) 成正比。因此,公式 (8-23) 中保留的系数(在当前讨论的上下文中,这些系数是基于最大方差选择的)被分配的位数与系数方差的对数成正比。
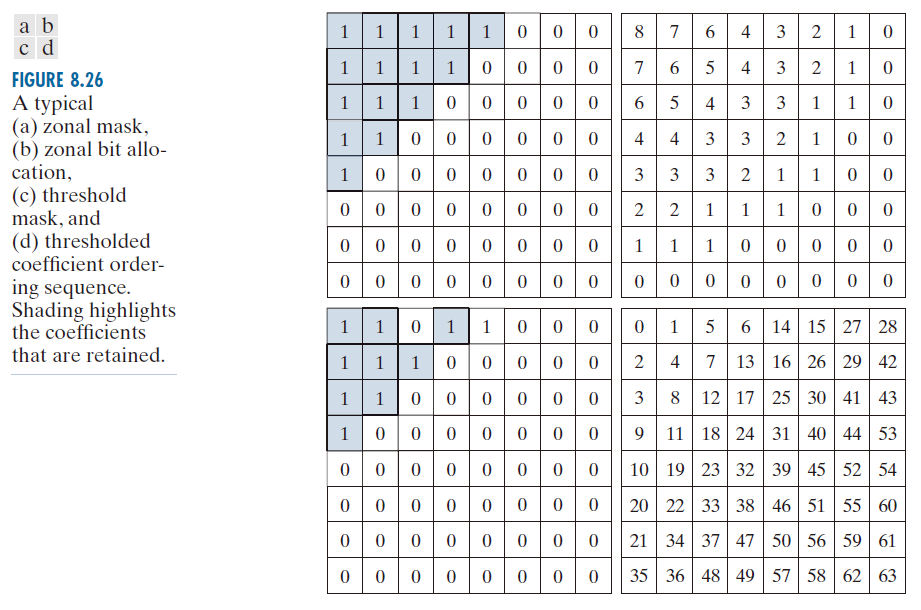
--------------------------图 8.26:典型的 (a) 分区掩码、(b) 分区位分配、(c) 阈值掩码和 (d) 阈值系数排序序列。阴影部分突出显示保留的系数。----------------
8.9.3.2 阈值编码实现(Threshold Coding Implementation)
区域编码通常使用一个固定的掩码对所有子图像进行处理。然而,阈值编码本质上是自适应的,因为每g一个子图像保留的变换系数的位置各不相同。事实上,由于计算简单,阈值编码是实践中最常用的自适应变换编码方法。其基本概念是,对于任何子图像,幅度最大的变换系数对重建子图像的质量贡献最大,正如最后一个示例所示。由于最大系数的位置因子图像而异,因此通常会对 χ(u , v )T(u , v ) 的元素进行重新排序(以预定义的方式),形成一维游程编码序列。图 8.26(c) 显示了假设图像的一个子图像的典型阈值掩码。该掩码提供了一种方便的方式来可视化相应子图像的阈值编码过程,并可以使用公式 (8-23) 对该过程进行数学描述。当将该掩码应用于(通过公式 (8-23))生成它的子图像时,并将得到的 n × n 数组按照图 8.26(d) 的锯齿形排序模式重新排列,形成一个包含 个元素的系数序列,则重新排序后的一维序列包含几个很长的零序列。[从图 8.26(d) 中的 0 开始并按顺序跟踪数字,即可看出锯齿形模式。]这些零序列通常采用游程编码。非零或保留的系数(对应于掩码中包含 1 的位置)使用变长编码表示。
对变换后的子图像进行阈值处理,或者换言之,创建如公式 (8-22) 所示的子图像阈值掩码函数,有三种基本方法:(1) 对所有子图像应用单个全局阈值;(2) 对每个子图像使用不同的阈值;(3) 阈值可以根据子图像中每个系数的位置而变化。在第一种方法中,压缩级别因图像而异,取决于超过全局阈值的系数数量。在第二种方法(称为 N 最大值编码)中,每个子图像丢弃相同数量的系数。因此,码率是恒定的且可以预先确定。第三种技术与第一种技术一样,会导致可变的码率,但其优点在于,可以通过将公式 (8-23) 中的 χ(u , v )T(u , v ) 替换为
(8-25)
从而将阈值处理和量化结合起来。其中, 是 T(u , v ) 的一个阈值和量化近似,而 Z(u , v ) 是下述变换正规数组的一个元素:
(8-26)
在对归一化(经过阈值处理和量化)后的子图像变换 进行逆变换以获得子图像 g(x, y) 的近似值之前,必须将其乘以 Z(u , v )。所得的去归一化数组 (记作
) 是
的近似值:
(8-27)
之逆变换生成了解压缩子图像的近似。
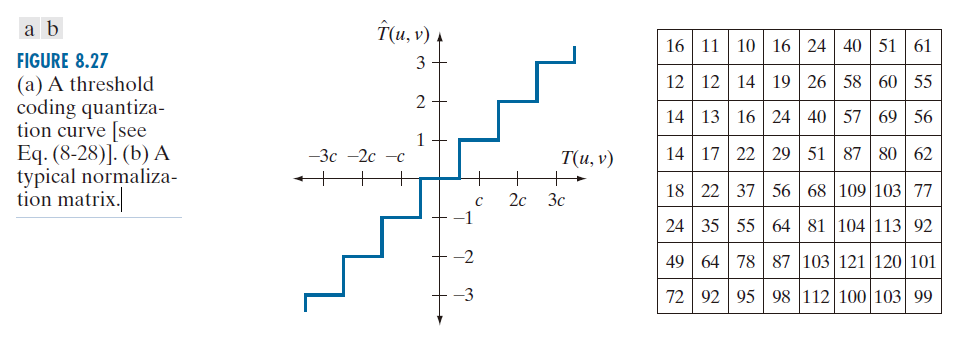
对于 Z(u , v ) 赋予了一个具体值 c 时公式 (8-25) 的情况,其图形化描述见图 8.27(a) 。注意,当且仅当
(8-28)
时, 呈现为整数。
若 Z(u , v ) > 2T(u , v ) ,则 ,从而变换系数完全截断或抛弃。当使用变长编码表示
时,编码长度会随着 k 的绝对值增大而增加,因此用于表示 T(u , v ) 的位数由 c 的值控制。这样,就可以对 Z 的元素进行缩放,以实现不同的压缩级别。图 8.27(b) 显示了一个典型的归一化数组。该数组已在 JPEG 标准化工作中得到广泛应用(参见下一节),它根据启发式确定的感知或视觉重要性对变换后的子图像的每个系数进行加权。
-------------------------图 8.27:(a) 阈值编码量化曲线[参见公式(8-28)]。(b) 典型的归一化矩阵。-------------------------------------
例子 8.16:阈值编码演示。
图 8.28(a) 至 (f) 显示了图 8.9(a) 所示单色图像的六种阈值编码近似图像。所有图像均使用 8 × 8 DCT 和图 8.27(b) 所示的归一化数组生成。第一个结果的压缩比约为 12:1( 即 C = 12 ),它是通过直接应用该归一化数组获得的。其余结果的压缩比分别为 19:1,30:1,49:1,85:1 和 182:1 ,这些结果是在将归一化数组分别乘以 2,4,8,16 和 32 后生成的。相应的均方根误差分别为 3.83,4.93,6.62,9.35,13.94 和 22.46 灰度级。

-------------------------------------图 8.28:图 8.9(a) 使用 DCT 和图 8.27(b) 中的归一化数组进行近似处理后的结果:(a) Z ,(b) 2Z ,(c) 4Z ,(d) 8Z,(e) 16Z,和 (f) 32Z。----------------------------------------------------------------
8.9.4 JPEG编码标准(Joint Photographic Experts Group)
最流行、最全面的连续色调静态图像压缩标准之一是 JPEG 标准。它定义了三种不同的编码系统:(1) 基于 DCT 的有损基线(baseline)编码系统,适用于大多数压缩应用;(2) 用于更高压缩率、更高精度或渐进式重建应用的扩展编码系统;(3) 用于可逆压缩的无损独立编码系统。为了与 JPEG 标准兼容,产品或系统必须支持基线系统。该标准没有指定特定的文件格式、空间分辨率或颜色空间模型。
在基线系统中(通常称为顺序基线系统),输入和输出数据的精度限制为 8 位,而量化后的 DCT 值则限制为 11 位。压缩过程本身分为三个顺序步骤:DCT 计算、量化和变长编码分配。图像首先被分割成 8 × 8 像素块,这些像素块从左到右、从上到下依次处理。当遇到每个 8 × 8 像素块或子图像时,其 64 个像素值会通过减去量 进行电平偏移,其中
是最大强度级别数。然后计算该像素块的二维离散余弦变换,并根据公式 (8-25) 进行量化,最后使用图 8.26(d) 所示的锯齿形模式重新排列,形成一维量化系数序列。
由于图 8.26(d) 所示的锯齿形扫描模式生成的一维重排数组是按空间频率递增的顺序排列的,因此 JPEG 编码过程旨在利用重排后通常产生的长串零值。具体而言,非零 AC(注:在标准中,术语 AC 指除零阶或 AC 系数之外的所有变换系数(All Coefficients))系数使用变长编码进行编码,该编码定义了系数的值和前面零的个数。DC 系数相对于前一个子图像的 DC 系数进行差分编码。彩色图像亮度分量或单色图像强度的默认 JPEG Huffman 编码可在本书网站上找到。JPEG 推荐的亮度量化数组如图 8.27(b) 所示,并且可以进行缩放以提供不同的压缩级别。该数组的缩放允许用户选择 JPEG 压缩的“质量”。虽然为彩色和单色图像处理都提供了默认的编码表和量化数组,但用户可以自由构建自定义的表格和/或数组,这些表格和/或数组可以根据待压缩图像的特性进行调整。
例子 8.17:JPEG 基线编码和解码。
考虑使用 JPEG 基线标准对以下 8 × 8 子图像进行压缩和重建:
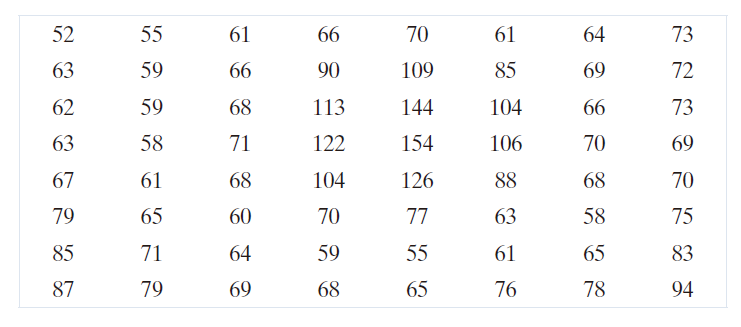
原图像包含 256 或 个可能的强度值,因此编码过程首先将原子图像的像素值向低
或 -128 个强度级别进行电平偏移。得到的偏移数组为
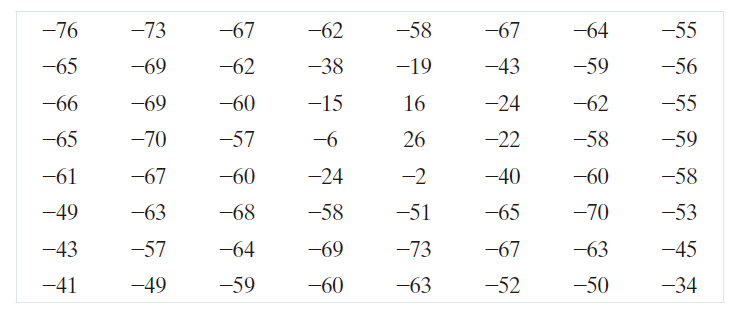
当按照公式 (7-31) 的前向 DCT 变换,并令式 (7-85) 中的 r ( x , y , u , v ) = s ( x , y , u , v ),且 n = 8 时,该式变为
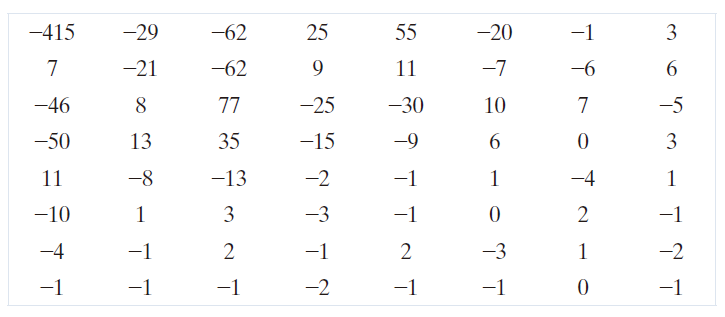
如果使用图 8.27(b) 所示的 JPEG 推荐归一化数组对变换后的数组进行量化,则缩放和截断(即根据公式(8-25)进行归一化)后的系数为

其中(例如),DC 系数可计算为
注意,变换和归一化过程会产生大量零值系数。当按照图 8.26(d) 的锯齿形排序模式重新排列系数时,得到的 1 维系数序列为
[-26 - 3 1 - 3 - 2 - 6 2 - 4 1 - 4 1 1 5 0 2 0 0 - 1 2 0 0 0 0 0 - 1 - 1 EOB]
其中 EOB 符号表示块结束条件。提供了一个特殊的 EOB Huffman 编码字(参见本书网站上的 JPEG 默认 AC 编码表中的类别 0 和游程 0 ),用于指示重排序列中剩余的系数均为零。
重新排列系数序列的默认 JPEG 编码的构建过程始于计算当前 DC 系数与先前编码的子图像的 DC 系数之间的差值。假设其左侧相邻的变换量化子图像的 DC 系数为 -17,则得到的 DPCM 差值为 [-26 - (-17)] 或 -9,该值位于 JPEG 系数类别表中的 DC 差值类别 4(参见本书网站)。根据默认的 Huffman 差值编码,类别 4 差值的相应基本码为 101(一个 3 位代码),而完整编码的类别 4 系数的总长度为 7 位。剩余的 4 位必须由差值的最低有效位 ( LSB ) 生成。对于一般的 DC 差值类别(例如,类别 K ),需要额外的 K 位,这些位计算为正差值的 K 个最低有效位或负差值减 1 的 K 个最低有效位。对于差值 -9,相应的最低有效位为 (0111) - 1 或 0110,完整的 DPCM 编码 DC 码字为 1010110。
重排序数组中非零 AC 系数的编码方式类似。主要区别在于,每个默认的 AC Huffman 编码字取决于待编码的非零系数前面零值系数的数量,以及该非零系数的幅度类别。(参见本书网站上 JPEG AC 编码表中的“运行/类别”列。) 因此,重排序数组中的第一个非零 AC 系数 (-3) 被编码为 0100 。该编码的前两位表示该系数属于幅度类别 2,且前面没有零值系数;后两位的生成过程与 AC 差分码的最低有效位(LSB)的生成过程相同。以此类推,最终得到完全编码(重排序)的数组
1010110 0100 001 0100 0101 100001 0110 100011 001 100011 001
001 100101 11100110 110110 0110 11110100 000 1010
其中插入空格仅是为了提高可读性。虽然在此示例中并非必需,但默认的 JPEG 代码包含一个特殊的代码字,用于表示连续 15 个零后跟一个零的情况。完全编码后的重排数组的总位数(因此也是表示此示例中整个 8 × 8 , 8 位子图像所需的位数)为 92 位。最终的压缩比为 512:92,约为 5.6:1 。
要解压缩 JPEG 压缩子图像,解码器必须首先重建生成压缩位流的归一化变换系数。由于 Huffman 编码的二进制序列是瞬时且唯一可解码的,因此这一步骤可以通过简单的查找表方式轻松完成。这里,重新生成的量化系数数组是

根据公式(8-27)进行去归一化后,数组变为
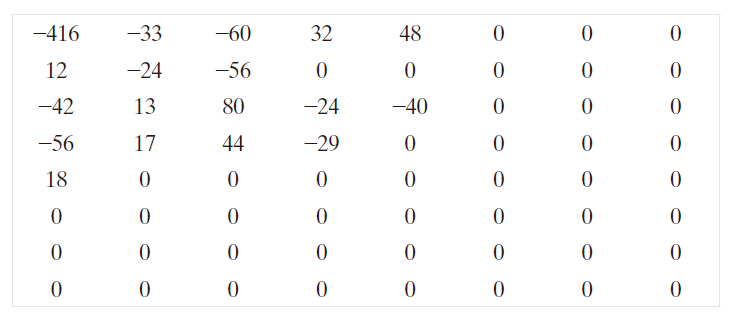
例如,AC 系数的计算方法如下:
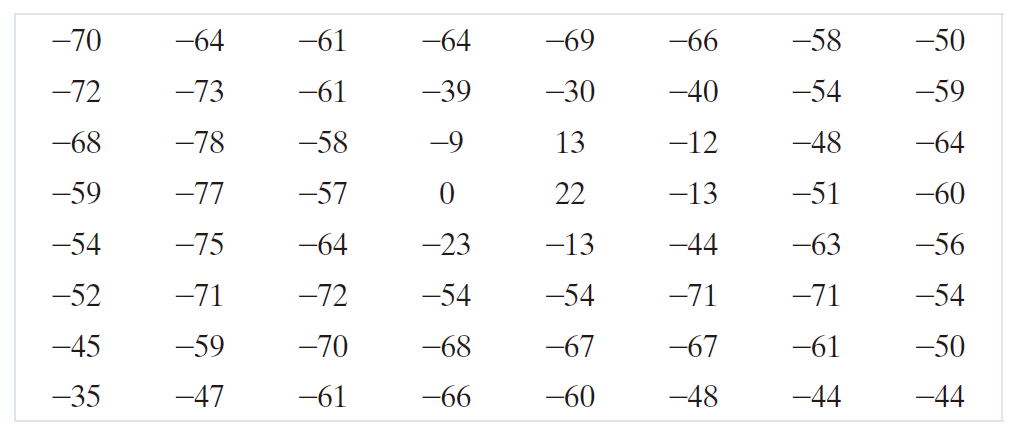
根据公式 (7-32) 和 (7-85) ,对去归一化后的数组进行逆 DCT 变换,即可得到完全重建的子图像
将每一个反向变换后的像素值偏移 ( 或 +128 ) ,得到
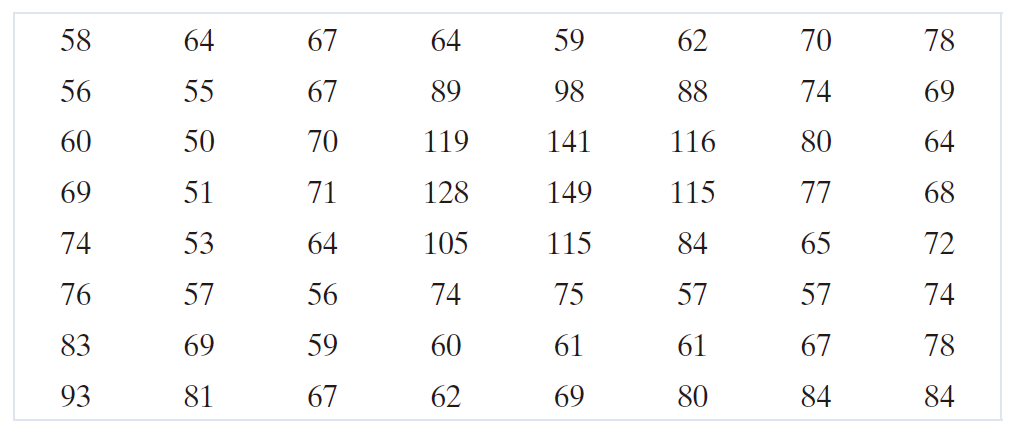
原子图像与重建子图像之间的任何差异都是由于 JPEG 压缩和解压缩过程的有损特性造成的。在本例中,误差范围为 -14 到 +11,分布如下:

整个压缩和重建过程的均方根误差约为 5.8 个强度级别。
例子 8.18:JPEG 编码例释。
图 8.29(a) 和 (d) 显示了图 8.9(a) 所示单色图像的两种 JPEG 压缩近似结果。第一个结果的压缩比为 25:1;第二个结果的压缩比为 52:1。图 8.29(a) 和 (d) 中重建图像与原始图像之间的差异分别显示在图 8.29(b) 和 (e) 中。相应的均方根误差分别为 5.4 和 10.7 灰度值。这些误差在图 8.29(c) 和 ( f ) 的放大图像中清晰可见。这些图像分别显示了图 8.29(a) 和 (d) 的放大区域。请注意,JPEG 压缩伪影随着压缩比的增加而增加。

------------------------------------图 8.29:图 8.9(a) 的两种 JPEG 压缩近似结果。每一行包含压缩和重建后的图像、重建图像与原图像之间的缩放差值,以及重建图像的局部放大图。---------------------------------------------------------------

















 473
473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










