



大家好,今天,我将为大家带来 Stable Diffusion webUI 入门的超详细教程,从 0 到 1 入门,再到进阶,让你轻松掌握这款强大的AI绘画工具。这期内容很长也很干,你可能不止看一遍这个文章频建议点赞收藏
一、本地部署 Stable Diffusion
我们都知道目前市面上有两款比较权威的 AI绘画软件,分别是Midjourney 和 Stable-Diffusion。Midjourney 需要付费使用,而 Stable-Diffusion 则是开源免费使用的。
大家应该现在最关心的是到底要怎么安装部署,或者我不安装不需要高配置电脑是不是也能使用这个工具,答案是可以的,目前很多平台都有相应提供的算力云平台,不需要高配置电脑一样可以使用,比如CephalonCloud 端脑云 - AIGC 应用平台
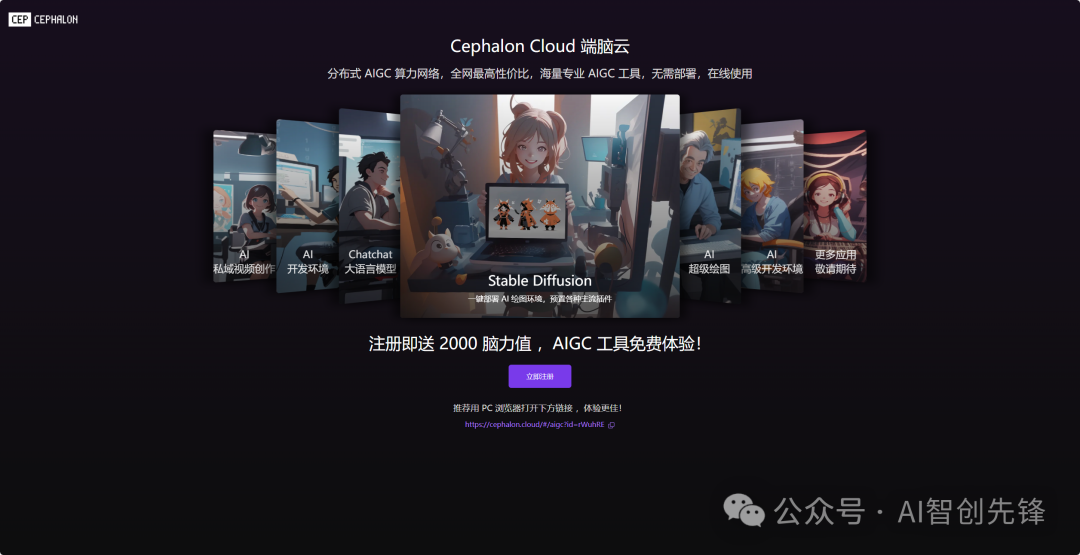
没有高配置电脑的可以选择在里面选择你的需要板块就能直接使用,不用进行安装部署的步骤,里面基本都是给帮你部署完了。
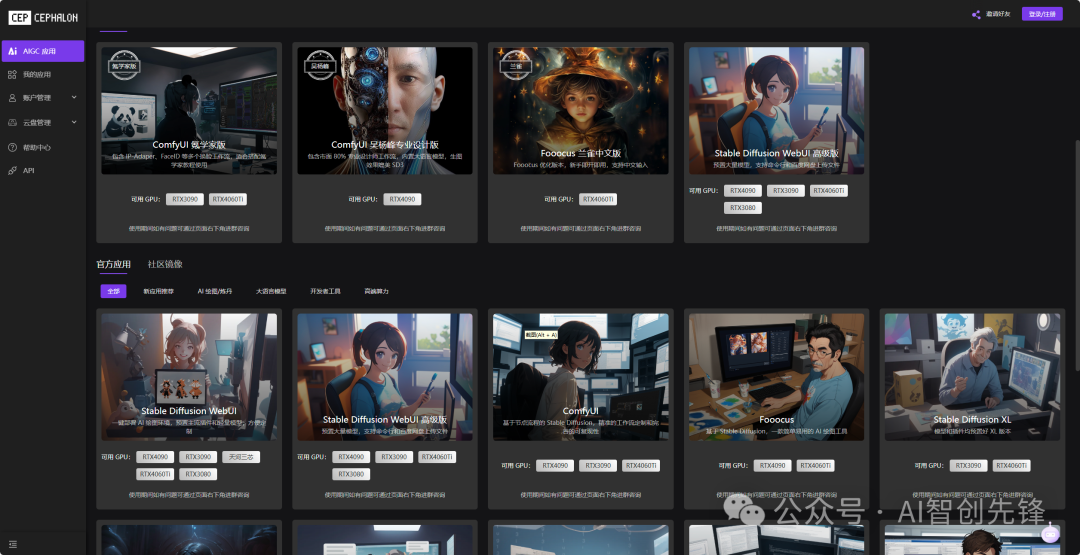
像一些comfyui、chatGPT、LORA炼丹这种里面全都有,按照自己的要求打开就好了,(ps:平台需要购买算力值,这个看自己的取舍)这里也不多说了,回到我们的正题,很多人关心的是我本地安装在哪里安装,怎么找资源呢?下面我来讲一下如如何安装部署
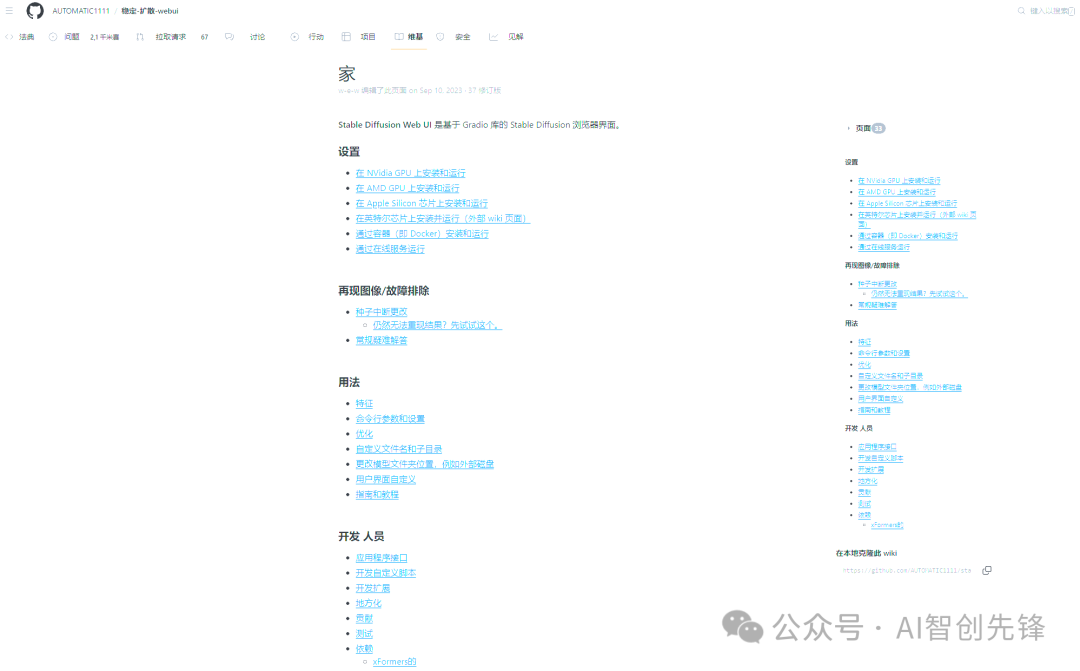
SD 开源地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki目前大家普遍采用的
Stable Diffusion Web UI 是发布于开源程序分享网站 Github 的 Python
项目,和平常软件安装方法有所不同,不是下载安装即可用的软件,需要准备执行环境、编译源码,针对不同操作系统(操作系统依赖)、不同电脑(硬件依赖)还有做些手工调整,这需要使用者拥有一定的程序开发经验(可以现学),已经有很多大佬们写了详细的安装教程。(如
https://www.tonyisstark.com/846.html)
如果像我一样是小白不会装,现在可以直接使用大佬们做的一键启动程序包,比如国内@秋葉 aaaki 大大开发的整合包,极大的降低了安装门槛。
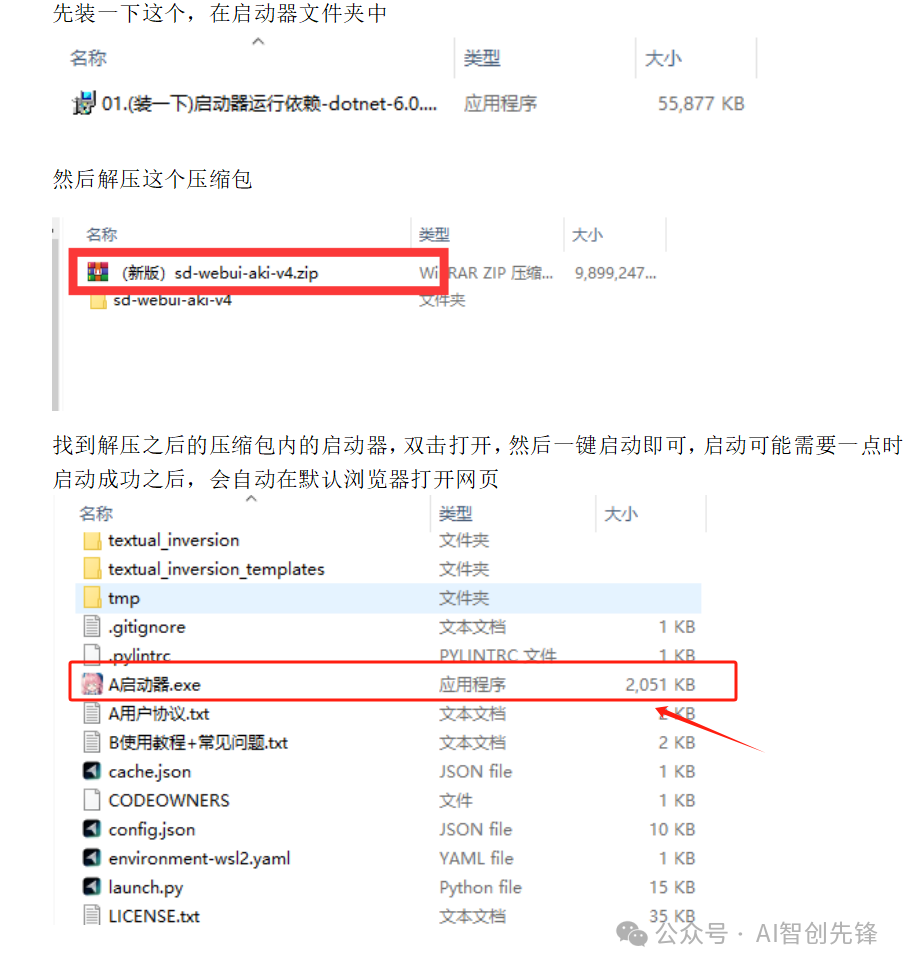 安装完之后就会得到这个页面,直接点击A启动器启动就可以了。
安装完之后就会得到这个页面,直接点击A启动器启动就可以了。
进入之后如果全都是英文看不懂怎么办?
如果需要中文语言包,可以下载如下中文语言包扩展,下载界面网址为:https://github.com/VinsonLaro/stable-
diffusion-webui-chinese
方法 1:通过 WebUI 拓展进行安装
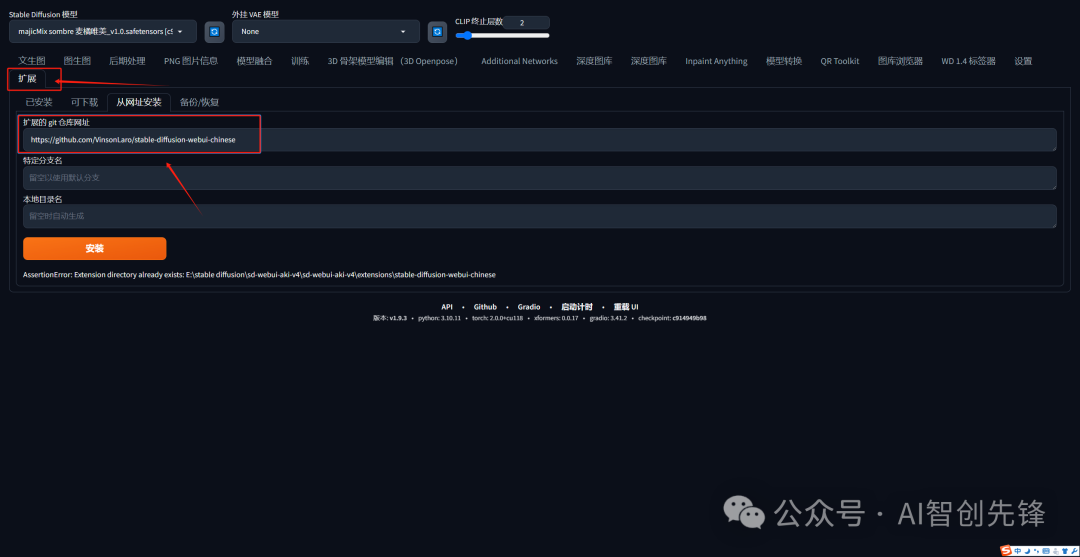
打开 stable diffusion webui,进入"Extensions"选项卡
点击"Install from URL",注意"URL for extension’s git repository"下方的输入框
粘贴或输入本 Git 仓库地址 https://github.com/VinsonLaro/stable-diffusion-webui-chinese
点击下方的黄色按钮"Install"即可完成安装,然后重启 WebUI(点击"Install from
URL"左方的"Installed",然后点击黄色按钮"Apply and restart UI"网页下方的"Reload UI"完成重启)
点击"Settings",左侧点击"User interface"界面,在界面里最下方的"Localization (requires
restart)“,选择"Chinese-All"或者"Chinese-English”
点击界面最上方的黄色按钮"Apply settings",再点击右侧的"Reload UI"即可完成汉化
(如果你是下载的是秋叶大佬的安装包的话则不需要汉化包,里面会自带汉化功能)
二、界面基础:
1. 了解界面
当前对于 SD 并无通行且可靠的使用规范,因每个人电脑配置与需求各异,如 cpkd/Safetensors 大模型、VAE、embeding、lora 等
AI 模型,以及各类插件、提示词、输出参数等组合极为复杂,牵一发动全身。所以需要大家有足够耐心去查阅插件开发者的说明文档以及如
https://civitai.com/等分享网站的使用心得。大家可先在 civitai
上搜索喜欢的图例,复用原作者的出图提示词、参数和模型,再在此基础上进行修改,这样学习效果最为可观。
2. 具体功能
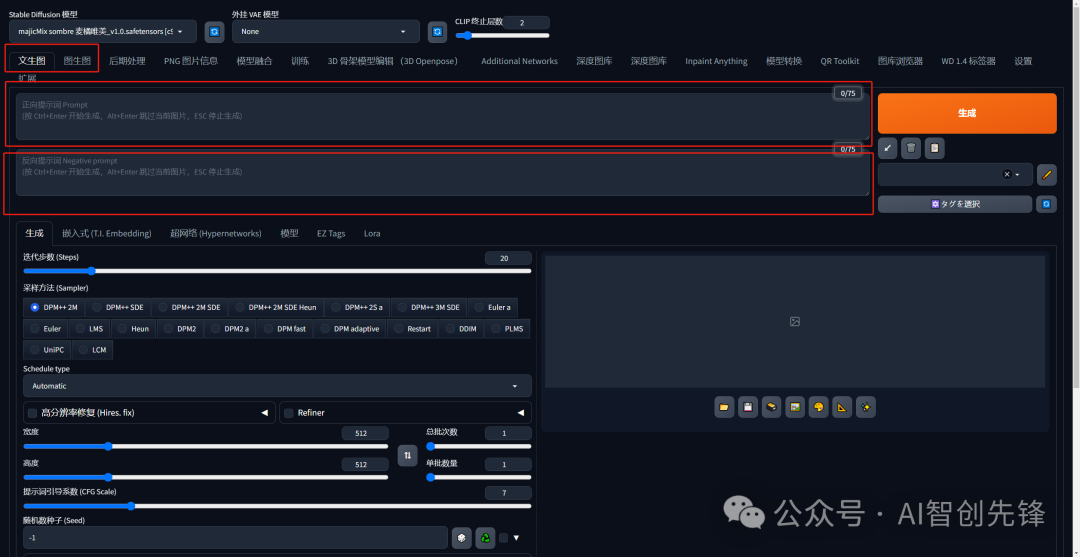
文生图:依据文本提示生成图像。
图生图:以提供的图像为范本并结合文本提示生成图像。
更多:可对图像进行优化(如清晰、扩展等)。
图片信息:显示图像基本信息,包含提示词和模型信息(除非被隐藏)。
模型合并:能将已有模型按不同比例合并生成新模型。
训练:根据提供的图片训练具有特定图像风格的模型。
- 描述词
描述语包括正向与负向描述,也被称为 tag(标签)或 prompt(提示词)。
正面提示词:相比 Midjourney 需写得更精准细致,描述少则给予 AI 更多自由发挥空间。
负面提示词:是不希望 SD 生成的内容。
正向:如 masterpiece、best quality 等更多画质词以及画面描述。
反向:如 nsfw、lowres、bad anatomy、bad hands、text、error、missing fingers、extra
digit、fewer digits、cropped、worst quality、low quality、normal quality、jpeg
artifacts、signature、watermark、username、blurry 等,可根据画面产出添加不想出现的画面。
4.采样方法
DPM++ 2M 或 DPM++ 2M Karras(二次元图)或 UniPC;若想要些惊喜与变化,可选择 Euler a、DPM++ SDE、DPM++
SDE Karras(写实图)、DPM2 a Karras(注意调整对应 eta 值)。
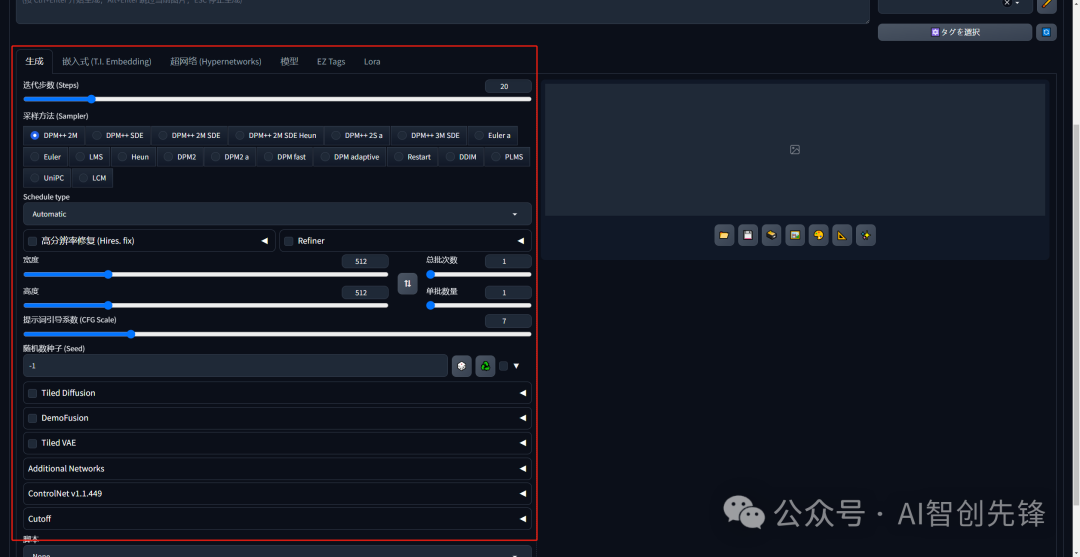
eta 和 sigma 均与多样性相关,但它们的多样性源于步数的变化,若追求更多样性,应关注 seed
的变化,这两项参数应在确定图片框架后,在此基础上进行微调时使用。
采样步数:稳定扩散从充满噪音的画布开始创建图像,并逐渐去噪以达成最终输出,此参数控制去噪步骤数量。通常越高越好,默认值为 25
步。不同情况下使用的步骤编号指南如下:
若正在测试新提示并期望快速得到结果以调整输入,可使用 10-15 步。
当找到喜欢的提示时,将步骤增加到 25。
若为有毛皮的动物或有纹理的主题,生成图像缺少细节,可尝试提高到 40。
面部修复:可修复人物面部,但非写实风格人物开启面部修复可能导致面部崩坏。
平铺:生成可平铺的图像。
高分辨率重绘:采用两步过程生成,先以较小分辨率创建图像,然后在不改变构图的情况下改进细节,选中该选项会有一系列新参数,其中重要的是:
放大算法:Latent 在很多情况下效果不错,但重绘幅度小于 0.5 后效果不理想。ESRGAN_4x、SwinR 4x 对 0.5
以下重绘幅度有较好支持。
放大倍数:通常为 2 倍。
重绘幅度:决定算法对图像内容的保留程度,该值越高,放大后图像与放大前图像差别越大。低 denoising 意味着修正原图,高 denoising
与原图相关性不大。一般阈值为 0.7 左右,超过 0.7 与原图基本无关,0.3 以下只是稍作修改,0 则什么都不改变,1
会得到完全不同的图像。具体执行步骤为重绘强度*重绘步数。
长宽尺寸(分辨率):长宽尺寸并非越大越好,最佳范围应在 512 至 768 像素之间,比如正方形图多为 512512 和 768768,人像肖像为
512x768,风景画为 768×512。
最后
如果你是真正有耐心想花功夫学一门技术去改变现状,我可以把这套AI教程无偿分享给你,包含了AIGC资料包括AIGC入门学习思维导图、AIGC工具安装包、精品AIGC学习书籍手册、AI绘画视频教程、AIGC实战学习等。
这份完整版的AIGC资料我已经打包好,长按下方二维码,即可免费领取!

【AIGC所有方向的学习路线思维导图】
【AIGC工具库】

【精品AIGC学习书籍手册】
【AI绘画视频合集】
这份完整版的AIGC资料我已经打包好,长按下方二维码,即可免费领取!


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










