


好的,各位开发者朋友们,又到了咱们一起搞技术的时间!
处理大量数据时,绝对绕不开的神器——Spring Batch。
你可能会说:“嗨,不就是个批处理框架嘛,能有多复杂?”
嘿,你别说,Spring Batch 还真不是“简历上写了精通,其实就会个 HelloWorld”那么简单。
它里面有很多门道,比如任务怎么停了还能接着跑?
几百个任务怎么管理?微服务里怎么玩批处理?出了问题怎么快速定位?
准备好了吗?发车!
目录
四. 微服务下的批处理:Spring Batch + Spring Cloud Task
Spring Batch 与 MyBatis/Hibernate 的整合
Spring Batch 与 Elasticsearch 数据同步
一. 一切的基石:Job 的状态管理与持久化
想象一下,你一个批处理任务要跑几个小时,处理上百万的数据。跑到一半,服务器重启了、数据库挂了……怎么办?从头再来?那不得被业务方骂死。
Spring Batch 的核心魅力就在于它的状态管理。它能记住你的 Job 跑到了哪一步,无论是成功、失败,还是正在进行中。
这一切都归功于一个核心组件:JobRepository。
你可以把 JobRepository 想象成一个敬业的“任务管家”。它通过一系列的数据库表(默认是以 BATCH_ 开头的表),默默记录着 JobInstance(一次任务的唯一实例)、JobExecution(一次任务的执行)、StepExecution(步骤的执行)以及 ExecutionContext(执行上下文,可以理解为任务的“记忆”)等所有状态。
JobRepository 的工作机制 :
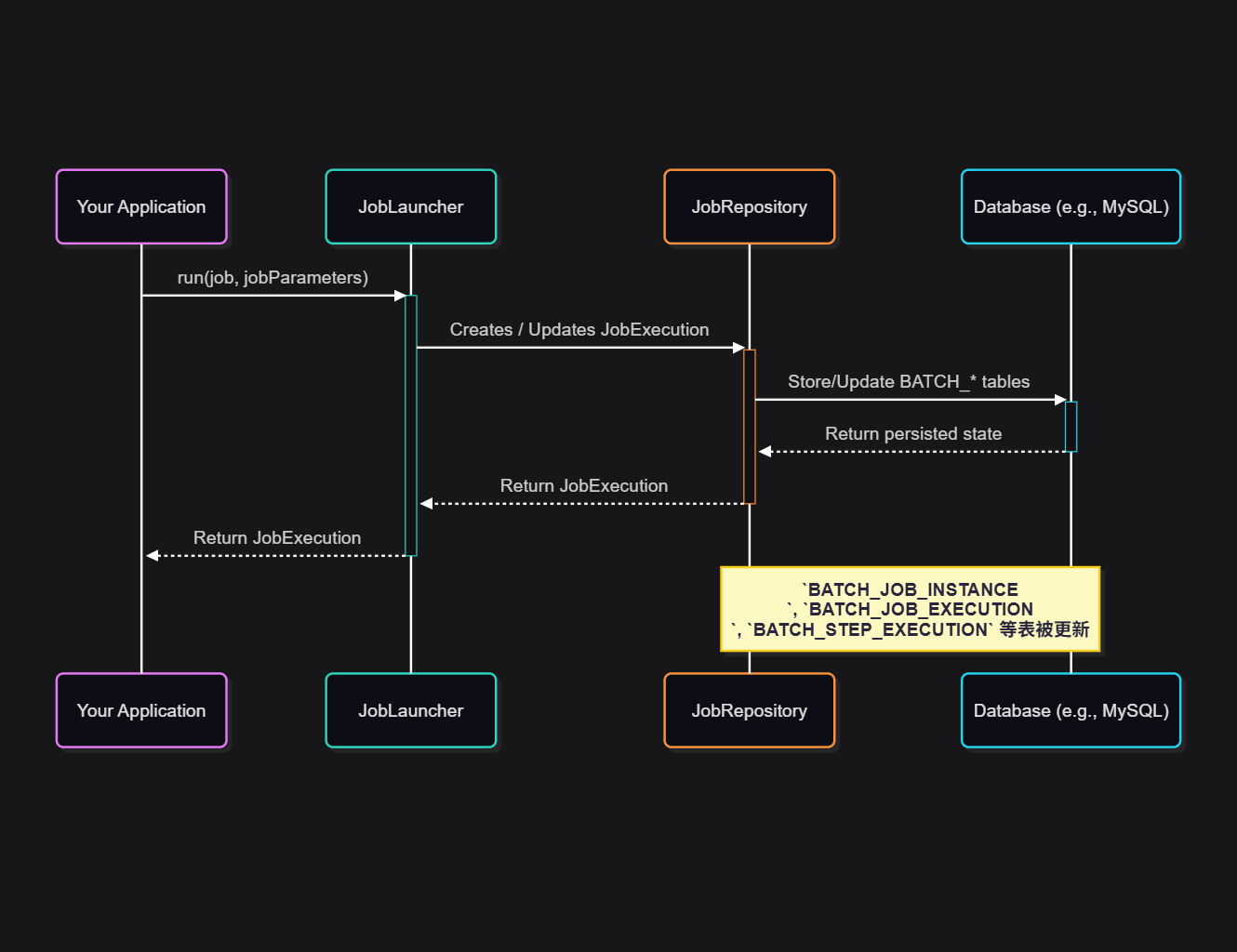
默认情况下,只要你引入了 Spring Batch 的依赖,并且配置了数据源(DataSource),这个机制就自动生效了。Spring Boot 会为你自动配置好一切。
二. 断点重启:让你的 Job 拥有“复活”的能力
基于上面强大的状态管理,断点重启(Restartable Jobs) 就成了水到渠成的事情。如果一个 Job 失败了,下次你用相同的 JobParameters 再次启动它时,Spring Batch 会聪明地从上次失败的那个 Step 开始继续执行,而不是从头再来。
默认情况下,Job 就是可以重启的 (restartable = true)。关键在于你的 ItemReader 要能支持“续读”。比如,JdbcCursorItemReader 或 FlatFileItemReader 默认就保存了读取的行数,重启时能从下一行开始。
代码例子:一个简单的可重启 Job
@Configuration
public class RestartableJobConfig {
@Autowired
private JobRepository jobRepository;
@Autowired
private PlatformTransactionManager transactionManager;
@Bean
public Job restartableDemoJob() {
return new JobBuilder("restartableDemoJob", jobRepository)
.start(step1())
// .preventRestart() // 如果你确定某个Job不应该被重启,可以加上这个
.build();
}
@Bean
public Step step1() {
return new StepBuilder("step1", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(itemReader())
.writer(itemWriter())
.build();
}
// 注意:为了演示,这里我们用一个简单的 List Reader
// 在真实场景中,ItemReader 需要是持久化的,比如 JpaPagingItemReader
@Bean
@StepScope
public ListItemReader<String> itemReader() {
List<String> items = new ArrayList<>();
for (int i = 1; i <= 100; i++) {
items.add("Item " + i);
}
return new ListItemReader<>(items);
}
@Bean
public ItemWriter<String> itemWriter() {
return items -> {
for (String item : items) {
if (item.equals("Item 55")) {
System.out.println("Oh no! A wild bug appears! Simulating failure.");
throw new RuntimeException("Simulated error at item 55");
}
System.out.println("Writing item: " + item);
}
};
}
}
怎么玩?
-
第一次运行这个 Job,它会在处理到 "Item 55" 时失败。
-
查看数据库的
BATCH_STEP_EXECUTION表,你会发现step1的状态是FAILED,并且read_count可能停在了 50 或者 60 附近(取决于 chunk 大小)。 -
用完全相同的参数再次启动这个 Job。你会惊奇地发现,它不会从 "Item 1" 开始打印,而是会跳过已经成功处理的部分,从失败的那个 chunk 开始重试。
三. 多 Job 管理:JobRegistry 的妙用
当你的系统里有几十上百个 Job 时,如何优雅地管理它们?比如,你想在运行时通过 Job 名称动态地启动一个任务,而不是通过硬编码。
JobRegistry 就是干这个的。它是一个 Job 的“注册中心”。你可以把项目里所有的 Job 都注册进去,然后通过它来查找。
配置 JobRegistry:
import org.springframework.batch.core.configuration.support.JobRegistryBeanPostProcessor;
import org.springframework.batch.core.configuration.JobRegistry;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class JobRegistryConfig {
// 这个 BeanPostProcessor 会自动扫描上下文中的所有 Job 定义,并注册到 JobRegistry 中
@Bean
public JobRegistryBeanPostProcessor jobRegistryBeanPostProcessor(JobRegistry jobRegistry) {
JobRegistryBeanPostProcessor postProcessor = new JobRegistryBeanPostProcessor();
postProcessor.setJobRegistry(jobRegistry);
return postProcessor;
}
}
如何使用?
@RestController
@RequestMapping("/jobs")
public class JobController {
@Autowired
private JobLauncher jobLauncher;
@Autowired
private JobRegistry jobRegistry;
@PostMapping("/launch/{jobName}")
public void launchJob(@PathVariable String jobName, @RequestBody Map<String, String> params) throws Exception {
Job job = jobRegistry.getJob(jobName);
JobParameters jobParameters = new JobParametersBuilder()
.addDate("run.date", new Date()) // 添加时间戳保证每次执行都是新的 JobInstance
.toJobParameters();
jobLauncher.run(job, jobParameters);
}
}
这样,你就可以通过一个简单的 API 接口来动态触发任意一个已注册的 Job 了。
四. 微服务下的批处理:Spring Batch + Spring Cloud Task
在微服务架构里,我们通常希望批处理任务是一个独立的、短暂运行的服务。跑完就销毁,不占用常驻资源。这正是 Spring Cloud Task 的用武之地。
Spring Cloud Task 可以将一个 Spring Boot 应用包装成一个“任务”。当这个应用启动、运行、结束时,它会通过消息总线(如 RabbitMQ 或 Kafka)发送事件。你可以结合像 Spring Cloud Data Flow 这样的工具来编排和调度这些任务。
Spring Cloud Task 与 Spring Batch:
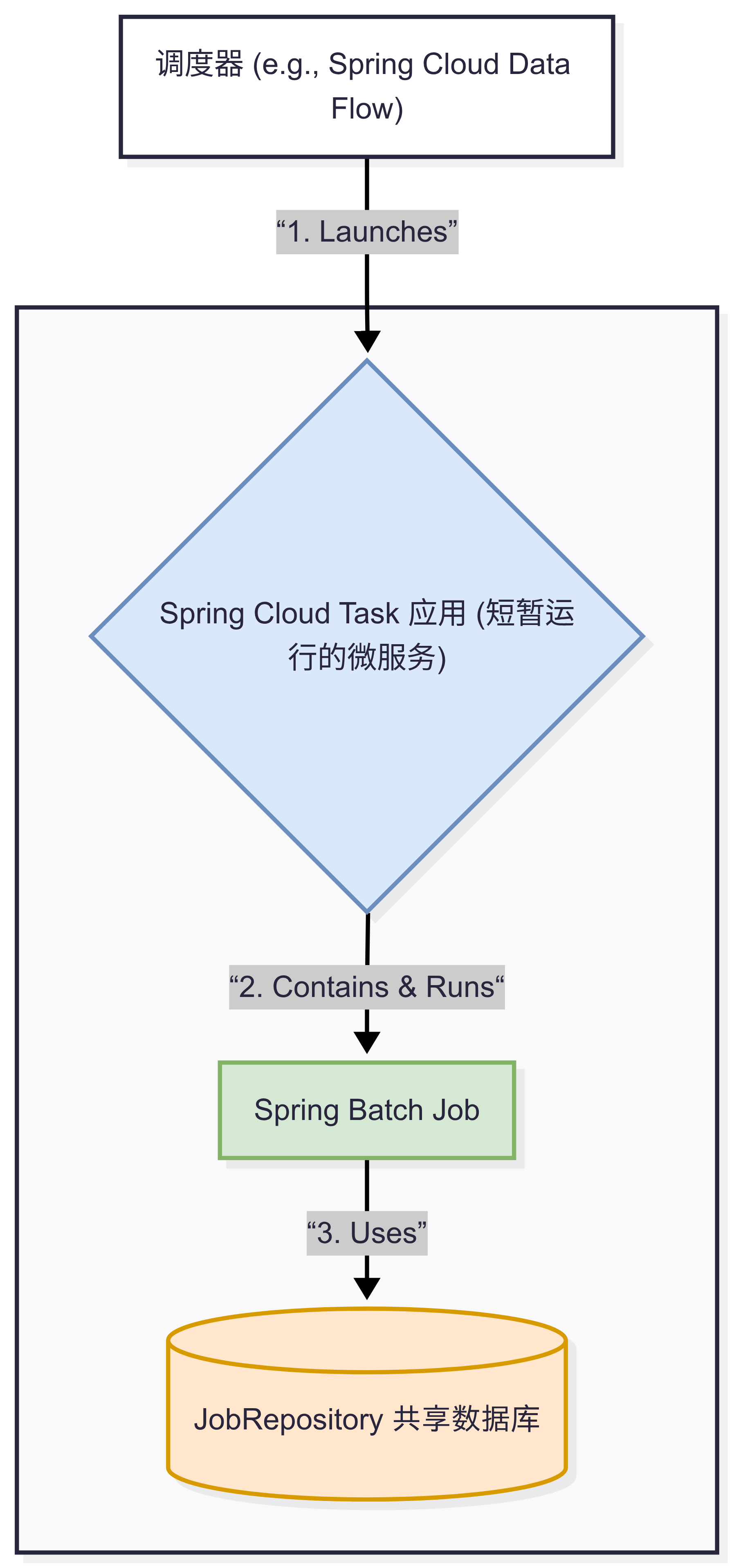
如何整合?
-
在你的 Spring Batch 项目中加入
spring-cloud-starter-task依赖。 -
在主启动类上加上
@EnableTask注解。
@SpringBootApplication
@EnableTask // 开启 Spring Cloud Task
@EnableBatchProcessing // 开启 Spring Batch
public class BatchTaskApplication {
public static void main(String[] args) {
SpringApplication.run(BatchTaskApplication.class, args);
}
// 你的 Job 定义...
@Bean
public CommandLineRunner commandLineRunner(JobLauncher jobLauncher, Job myJob) {
// Task 启动时自动运行这个 Job
return args -> {
JobParameters params = new JobParametersBuilder()
.addString("JobID", String.valueOf(System.currentTimeMillis()))
.toJobParameters();
jobLauncher.run(myJob, params);
};
}
}
现在,当你把这个应用打包成 Jar 并运行时,它就是一个标准的 Spring Cloud Task。它会自动执行你的批处理任务,并在 TASK_EXECUTION 表中记录这次任务的执行情况。
五. 事务与回滚:数据一致性的守护神
批处理的事务至关重要。Spring Batch 的 chunk 模型天然就是为事务而生的。
一个 chunk 就是一个事务单元。ItemReader 读取数据,ItemProcessor 处理数据,这些操作在事务之外。当处理的数据量达到 chunk 大小后,ItemWriter 会把这一批数据一次性写入。整个写入过程(writer.write())是被一个事务包裹的。
-
成功:整个 chunk 的数据被提交。
-
失败:如果在写入过程中任何地方抛出异常,整个 chunk 的操作都会被回滚,数据库状态回到写入之前。
回滚机制:
默认情况下,任何 Exception(及其子类)都会导致事务回滚。但你可以通过 <skippable-exception-classes> 或 .skip() 来配置某些“可跳过”的异常。当遇到这些异常时,当前这个 item 会被跳过,事务不会回滚,chunk 会继续处理剩下的 item。
@Bean
public Step stepWithSkipLogic() {
return new StepBuilder("stepWithSkipLogic", jobRepository)
.<Order, ProcessedOrder>chunk(10, transactionManager)
.reader(orderReader())
.processor(orderProcessor())
.writer(orderWriter())
.faultTolerant() // 开启容错模式
.skip(InvalidDataException.class) // 定义可跳过的异常
.skipLimit(100) // 最多跳过100次
.build();
}
六. 强强联合:Spring Batch + Kafka
在现代数据管道中,消息队列(如 Kafka)是常客。Spring Batch 当然也能和它无缝集成。
-
KafkaItemReader: 从 Kafka 的一个或多个 topic 分区中读取消息。 -
KafkaItemWriter: 将处理完的数据发送到 Kafka 的 topic。
场景: 从数据库读取数据,处理后,推送到 Kafka。
@Configuration
public class BatchKafkaIntegration {
@Autowired
private JobRepository jobRepository;
@Autowired
private PlatformTransactionManager transactionManager;
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
@Bean
public Job dbToKafkaJob() {
return new JobBuilder("dbToKafkaJob", jobRepository)
.start(dbToKafkaStep())
.build();
}
@Bean
public Step dbToKafkaStep() {
return new StepBuilder("dbToKafkaStep", jobRepository)
.<User, User>chunk(100, transactionManager)
.reader(databaseReader()) // 你的 JpaPagingItemReader 或类似 reader
.writer(kafkaItemWriter())
.build();
}
@Bean
public KafkaItemWriter<String, Object> kafkaItemWriter() {
KafkaItemWriter<String, Object> writer = new KafkaItemWriter<>();
writer.setKafkaTemplate(kafkaTemplate);
// 定义 item 到 Kafka 消息的转换逻辑
writer.setItemKeyMapper(user -> String.valueOf(((User) user).getId()));
writer.setDelete(false); // true 的话会发送 tombstone 消息
writer.setTopic("user-updates-topic");
return writer;
}
// ... databaseReader 的定义
}
关键点: 这种整合让 Spring Batch 成为了一个强大的 ETL 工具,可以轻松地在不同数据源(数据库、文件、消息队列)之间搬运和转换数据。
七. 调试与监控:千里眼和顺风耳
Job 跑起来了,但它是黑盒吗?当然不是!
如何查看执行日志?
Spring Batch 的日志非常详细。你需要关注 org.springframework.batch 包下的日志级别。在 application.properties 中配置:
Properties
logging.level.org.springframework.batch=DEBUG
这样你就能看到 Job、Step 的生命周期,chunk 的边界,事务的提交和回滚等详细信息。
Admin 面板
-
Spring Batch Admin(已过时): 官方的老项目,已经不再维护,不推荐在新项目中使用。
-
Spring Boot Admin(推荐替代): 这是一个通用的 Spring Boot 应用监控工具。虽然它没有专门为 Batch 设计的视图,但你可以通过它的 JMX 或 HTTP endpoints 来监控和管理 Job。
Spring Batch 会暴露很多 JMX MBeans,你可以通过 jconsole 或 Spring Boot Admin 的 JMX 模块来:
-
查看正在运行的 Job。
-
停止一个 Job。
-
查看 Job 的历史执行记录和统计数据。
如何排查 Job 执行失败问题?
-
看日志:这是第一步,也是最重要的一步。找到堆栈跟踪(Stack Trace),看看是哪个类、哪行代码出的错。
-
查数据库:去
BATCH_*表里看。-
BATCH_JOB_EXECUTION:查看STATUS和EXIT_MESSAGE。EXIT_MESSAGE通常包含了异常的简短描述。 -
BATCH_STEP_EXECUTION:定位到具体失败的那个 Step,看它的READ_COUNT,WRITE_COUNT,COMMIT_COUNT等,可以帮你判断问题出在 Reader、Processor 还是 Writer。
-
-
检查
ExecutionContext:BATCH_JOB_EXECUTION_CONTEXT和BATCH_STEP_EXECUTION_CONTEXT表里存储了任务的“记忆”。有时候错误是由于上下文里存的数据不对导致的。
实现自定义的 JobExecutionListener
如你想在 Job 开始、结束或异常时执行一些自定义逻辑(比如发邮件、发通知),JobExecutionListener 是你的不二之选。
@Component
public class MyJobListener implements JobExecutionListener {
private static final Logger log = LoggerFactory.getLogger(MyJobListener.class);
@Override
public void beforeJob(JobExecution jobExecution) {
log.info("JOB {} IS STARTING...", jobExecution.getJobInstance().getJobName());
// 可以在这里做一些初始化工作
}
@Override
public void afterJob(JobExecution jobExecution) {
if (jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("JOB {} COMPLETED SUCCESSFULLY!", jobExecution.getJobInstance().getJobName());
// 发送成功通知
} else if (jobExecution.getStatus() == BatchStatus.FAILED) {
log.error("JOB {} FAILED!", jobExecution.getJobInstance().getJobName());
log.error("Exceptions: {}", jobExecution.getAllFailureExceptions());
// 发送失败告警邮件,附带异常信息
}
}
}
注册 Listener:
@Bean
public Job myMonitoredJob(MyJobListener listener) {
return new JobBuilder("myMonitoredJob", jobRepository)
.start(someStep())
.listener(listener) // 在这里注册
.build();
}
八. 更多实战场景
Spring Batch 与 MyBatis/Hibernate 的整合
Spring Batch 提供了 JpaPagingItemReader 来方便地与 JPA (Hibernate) 集成。对于 MyBatis,你可以使用 MyBatisPagingItemReader 或 MyBatisCursorItemReader。
Java
@Bean
public MyBatisPagingItemReader<Product> mybatisProductReader(SqlSessionFactory sqlSessionFactory) {
return new MyBatisPagingItemReaderBuilder<Product>()
.sqlSessionFactory(sqlSessionFactory)
.queryId("com.example.mapper.ProductMapper.findProducts") // Mapper 中的查询ID
.pageSize(100)
.build();
}
读取固定宽度格式数据
有些老系统还在用固定宽度的文本文件交换数据。FlatFileItemReader 配合 FixedLengthTokenizer 可以轻松搞定。
@Bean
public FlatFileItemReader<Customer> fixedWidthFileReader() {
return new FlatFileItemReaderBuilder<Customer>()
.name("fixedWidthFileReader")
.resource(new ClassPathResource("data/customers.dat"))
.lineTokenizer(new FixedLengthTokenizer() {{
setNames("id", "name", "zipCode");
setColumns(new Range(1, 10), new Range(11, 30), new Range(31, 35));
}})
.fieldSetMapper(new BeanWrapperFieldSetMapper<>() {{
setTargetType(Customer.class);
}})
.build();
}
Spring Batch 与 Elasticsearch 数据同步
这通常是一个 "Reader-Processor-Writer" 的经典模式。
-
Reader: 使用
JdbcPagingItemReader或JpaPagingItemReader从数据库分页读取数据。 -
Processor: (可选)将数据库实体转换成 Elasticsearch 的文档模型。
-
Writer: 创建一个自定义的
ItemWriter,使用 Elasticsearch 的RestHighLevelClient或新的ElasticsearchClient将数据批量索引到 ES。
@Bean
public ItemWriter<ProductDocument> elasticsearchProductWriter(ElasticsearchClient elasticsearchClient) {
return items -> {
BulkRequest.Builder br = new BulkRequest.Builder();
for (ProductDocument doc : items) {
br.operations(op -> op
.index(idx -> idx
.index("products")
.id(doc.getId())
.document(doc)
)
);
}
elasticsearchClient.bulk(br.build());
log.info("{} documents indexed to Elasticsearch.", items.size());
};
}
使用 Spring Batch 做数据迁移
-
可靠性: 断点续传和事务保证了迁移过程即使中断也不会丢失数据或产生重复数据。
-
高性能: 并发执行 Step、远程分区(Remote Partitioning)等高级特性可以极大提升迁移速度。
-
灵活性: 可以轻松处理异构数据源之间的迁移(如 Oracle 到 MySQL,DB2 到 PostgreSQL)。
-
可监控: 详细的日志和状态持久化让你对迁移进度了如指掌。
一个典型的数据迁移 Job 可能包含多个 Step:
-
Step 1: 禁用目标表的约束。
-
Step 2: 使用分页读取源表数据,写入目标表。
-
Step 3: 迁移相关联的表。
-
Step 4: 启用目标表的约束,重建索引。
-
Listener: 在结束后进行数据校验,生成迁移报告。
总结
好了,老铁们,今天的内容有点硬核,但绝对是干货满满。
记住,Spring Batch 不是一个简单的“for 循环”,它是一个工业级的、健壮的、功能完备的批处理解决方案。
掌握了它,无论是处理日常的数据报表,还是进行大规模的数据迁移,你都能游刃有余,成为团队里那个“靠谱”的仔。














 6827
6827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












