




一、前言
个人深度学习课程实验记录,最后修改于2023.5.25
比赛链接:https://tianchi.aliyun.com/competition/entrance/531883/
本代码最后排名:

二、题目要求
赛题背景
赛题以医疗数据挖掘为背景,要求选手使用提供的心跳信号传感器数据训练模型并完成不同心跳信号的分类的任务。
赛题数据
赛题以预测心电图心跳信号类别为任务,数据集数据来自某平台心电图数据记录,总数据量超过20万,主要为1列心跳信号序列数据,其中每个样本的信号序列采样频次一致,长度相等。从中抽取10万条作为训练集,2万条作为测试集A,2万条作为测试集B,同时会对心跳信号类别(label)信息进行脱敏。
字段表

评测要求

结果提交
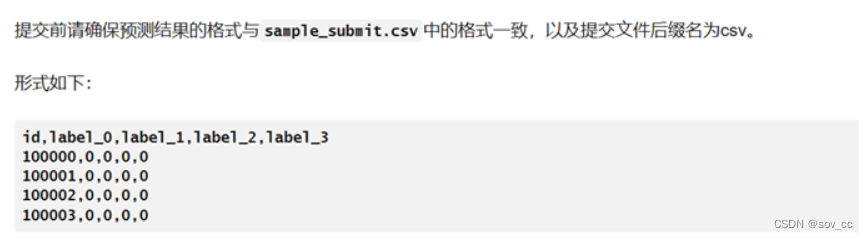
三、主要涉及技术
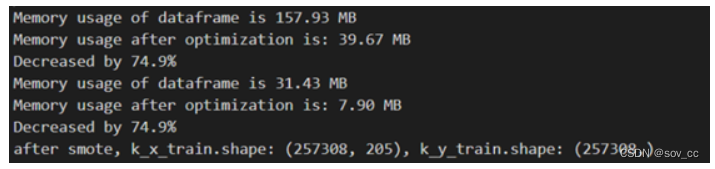
reduce_mem_usage函数
该函数是使用pandas读取csv,减少读取内存的一个常见方法。主要目的是通过降低数据类型的精度来减小内存占用,同时保持数据的可用性。
# 这是用pandas读取csv,减少读取内存的一个常见方法
def reduce_mem_usage(df):
# 处理前 数据集总内存计算
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
# 遍历特征列
for col in df.columns:
# 当前特征类型
col_type = df[col].dtype
# 处理 numeric 型数据。numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
# int 型数据 精度转换
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.iZnt32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
# float 型数据 精度转换
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
# 处理 object 型数据,即文本类如str。
else:
df[col] = df[col].astype('category')
# object 转 category。object类型(python中),category类型(pandas中特有)
# category实际上是动态枚举的一种形式。
# 如果某个字段的内容中,其可能值的范围是固定且有限的,则category类型数据最为适用
# 处理后 数据集总内存计算
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(
100 * (start_mem - end_mem) / start_mem))
return df
运行后效果:
SMOTE算法
SMOTE(Synthetic Minority Over-sampling Technique)是一种常用的数据不平衡问题处理算法,用于解决分类问题中的样本不平衡情况。在许多实际应用中,分类任务中的样本分布通常不平衡,即其中一个类别的样本数量明显少于其他类别。
SMOTE算法通过生成合成样本来增加少数类别的样本数量,从而平衡数据集。
主要思想:对于少数类别的每个样本,从其k个最近邻居中选择一个或多个样本,并在两个样本之间的特征空间中进行插值,生成新的合成样本。这样可以有效地增加少数类别的样本数量,使其更接近多数类别。
# 由于存在严重的类别不平衡问题。使用 SMOTE 对数据进行上采样以解决类别不平衡问题,提高精度。
# 但运算量大幅度增加,且容易导致过拟合
smote = SMOTE(random_state=2021, n_jobs=-1)
k_x_train, k_y_train = smote.fit_resample(x_train, y_train)
print(
f"after smote, k_x_train.shape: {k_x_train.shape}, k_y_train.shape: {k_y_train.shape}")
SMOTE算法主要步骤:
1、对于每个少数类别样本,计算其与其他样本之间的欧氏距离,并找出其k个最近邻居。
2、针对每个少数类别样本,从其k个最近邻居中随机选择一个或多个样本。
3、对于每个选中的最近邻居样本,计算其与原始样本的差值,乘以一个随机值(通常为0到1之间的随机数),并加到原始样本上,生成新的合成样本。
4、重复步骤2和步骤3,直到达到所需的样本增长比例。
SMOTE算法能够增加少数类别的样本数量,从而提高分类器在少数类别上的性能。它通常与其他分类算法(如决策树、逻辑回归、支持向量机等)结合使用,以改善对少数类别的分类准确性。
但SMOTE算法可能导致合成样本的过度生成,从而引入一定的噪音或过拟合风险。使用SMOTE算法时,需要谨慎选择合适的参数和合成样本生成策略,以避免不必要的问题。
四、LightGBM模型
LightGBM(Light Gradient Boosting Machine)是一种梯度提升框架,用于解决监督学习问题,适用于处理大规模数据集。它是由微软公司开发的一种基于梯度提升树的机器学习算法。
LightGBM 模型相比于传统的梯度提升树算法(如 XGBoost)具有更高的训练速度和更低的内存占用,这使得它适用于大规模数据集和资源受限的环境。此外,LightGBM 还提供了许多高级功能,如类别特征的自动处理、并行训练等,以提升模型的性能和效果。
LightGBM 模型的一般步骤
1、数据准备:将原始数据集划分为训练集和验证集,确保数据集的特征矩阵和目标向量正确准备。
2、参数设置:设置 LightGBM 模型的参数,包括树的深度、学习率、迭代次数、正则化参数等。这些参数会影响模型的性能和训练速度,需要根据具体问题进行调整。
3、创建 LightGBM 数据集:将准备好的训练集和验证集转换为 LightGBM 特定的数据集对象(例如 lgb.Dataset)以进行高效的训练和验证。
4、模型训练:使用准备好的训练集数据进行模型的训练。通过迭代的方式,逐步构建梯度提升树模型,每一轮迭代都会根据损失函数的梯度优化树的结构,使模型逐渐逼近目标。
5、模型验证:使用验证集数据评估训练好的模型在未见过的数据上的性能。可以计算各种指标(如准确率、精确率、召回率、F1 分数等)来衡量模型的效果。
6、参数调优:根据验证集的性能结果,调整模型的参数,例如增加迭代次数、调整学习率等,以提升模型的性能。
7、模型预测:使用训练好的模型对未知数据进行预测。可以使用模型的预测结果进行分类、回归或排序等任务。
模型定义代码
#单模型法,使用lightGBM模型进行分类。利用弱分类器(决策树)迭代训练以得到最优模型,该模型具有训练效果好、不易过拟合等优点。
'''
lightGBM模型常用参数:
max_depth:树的最大深度,过拟合时应降低此值
feature_fraction:意味着在每次迭代中随机选择的特征的比例
bagging_fraction:每次迭代时用的数据比例,即迭代数据量的指定比例时bagging一次
early_stopping_round:如果一次验证数据的一个度量在最近的early_stopping_round 回合中没有提高,模型将停止训练
lambda:指定正则化0~1,如lambda_l2=0.1,表示采用l2正则化系数为0.1,系数越小正则化程度越高,用来防止过拟合
num_boost_round:迭代次数 通常 100+
learning_rate:学习率,常用 0.1, 0.001, 0.003…
num_leaves :叶子数,默认 31,取值应 <= 2 ^(max_depth)
device:设置cpu 或者 gpu
metric:评价指标设置,mae: mean absolute error , mse: mean squared error ,binary_logloss: loss for binary classification ,multi_logloss: loss for multi classification
Task:数据的用途, train 或者 predict
application模型的用途 ,regression: 回归,binary: 二分类,multiclass: 多分类
boosting:要用的算法 gbdt, rf: random forest, dart: Dropouts meet Multiple Additive Regression Trees, goss: Gradient-based One-Side Sampling
'''
def cv_model(clf, train_x, train_y, test_x, clf_name):
folds = 180 #循环总的次数
seed = 2023 # 指定随机数种子
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
test = np.zeros((test_x.shape[0], 4))
cv_scores = []
onehot_encoder = OneHotEncoder(sparse=False)
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
#只是为了分隔符好看一点
print('************************************ {} ************************************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[
train_index], train_x.iloc[valid_index], train_y[valid_index]
if clf_name == "lgb":
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
params = {
'boosting_type': 'gbdt', # 使用梯度提升树
'objective': 'multiclass', # 多分类
'num_class': 4, # 4种类型
'num_leaves': 119, #这行及后两行是贝叶斯调参得到的最佳效果
'feature_fraction': 0.57,
'bagging_fraction': 0.93,
'bagging_freq': 4,
'learning_rate': 0.1, # 学习率,数字越大,迭代速度越快
'seed': seed,
'n_jobs': 24,
'verbose': -1,
}
参数调整
1、什么是超参数
•超参数是无法通过算法学习得到参数;
•超参数需要人为预先设置,而每组超参数会产生结构不同的模型;
•超参数需要一定的调整去适应不同的应用场景;
2、目前常见的调参方法
•Grid Search,当参数空间较小时,网格搜索是个不错的选择,并且容易并行化;当参数空间较大时,网格搜索效率会变得极低,通常该方法需结合一定的调参经验来缩小参数空间。
•Random Search,随机搜索,相当于对参数空间的简单随机抽样,在相同的参数空间下,实际效果要比网格搜索低,但搜索效率更快。有时候会先用随机搜索确定每个参数的大致范围,然后再用网格搜索进行密集运算。
•手动调参,靠经验直觉。
•自动调参,这就是今天讲到的这个调参框架,贝叶斯调优,属于概率模型,由于模型训练代价昂贵,所以在参数的选取上,下一个参数的选择会考虑之前参数的模型效果。
3、贝叶斯调参
贝叶斯调参的原理是建立在高斯过程回归上,而高斯过程回归则是在求解目标函数的后验分布。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-80AfHjbM-1692977285943)(C:\Users\coral\AppData\Roaming\Typora\typora-user-images\image-20230825232049182.png)]
4、代码
from sklearn.model_selection import cross_val_score
from sklearn.metrics import make_scorer
"""定义优化函数"""
def rf_cv_lgb(num_leaves, max_depth, bagging_fraction, feature_fraction,min_data_in_leaf,lambda_l2):
# 建立模型
model_lgb = lgb.LGBMClassifier(boosting_type='gbdt', objective='multiclass', num_class=4,
learning_rate=0.1,
num_leaves=int(num_leaves), max_depth=int(max_depth),
bagging_fraction=round(bagging_fraction, 2),
feature_fraction=round(feature_fraction, 2),
min_data_in_leaf=int(min_data_in_leaf),
lambda_l2=lambda_l2
)
f1 = make_scorer(f1_score, average='micro')
val = cross_val_score(model_lgb, X_train_split, y_train_split, cv=5, scoring=f1).mean()
return val
from bayes_opt import BayesianOptimization
"""定义优化参数"""
bayes_lgb = BayesianOptimization(
rf_cv_lgb,
{
'num_leaves':(31, 200),
'max_depth':(4, 20),
'bagging_fraction':(0.5, 1),
'feature_fraction':(0.5, 1),
'min_data_in_leaf':(10,100),
'lambda_l2':(0.01, 0.5)
}
)
"""开始优化"""
bayes_lgb.maximize(n_iter=10)
bayes_lgb.max
LightGBM模型的贝叶斯调参可以通过以下步骤实现:
\1. 定义模型参数空间:定义需要调节的参数和它们的取值空间。
\2. 定义目标函数:目标函数可以是模型的验证集准确率或其他性能指标。
\3. 设计贝叶斯优化算法:选择一种贝叶斯优化算法,例如高斯过程贝叶斯优化或树形结构的贝叶斯优化。
\4. 迭代调参:运行贝叶斯优化算法来迭代地搜索模型参数空间,不断更新下一组待测试参数。
\5. 评估模型:对于每组参数,使用交叉验证或其他方法来评估模型的性能,记录每组参数的性能指标。
\6. 选择最佳参数:在所有测试的参数中,选择性能最佳的一组参数作为最终模型的参数。
需要注意的是,贝叶斯调参的过程需要对计算资源和时间进行充分的考虑,因为每次迭代都需要训练和验证模型,计算量比较大。
模型训练代码
#训练模型
model = clf.train(params,
train_set=train_matrix,
valid_sets=valid_matrix,
num_boost_round=2000,
verbose_eval=100,
early_stopping_rounds=200)
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(
test_x, num_iteration=model.best_iteration)
val_y = np.array(val_y).reshape(-1, 1)
val_y = onehot_encoder.fit_transform(val_y)
print('预测的概率矩阵为:')
print(test_pred)
test += test_pred
score = abs_sum(val_y, val_pred)
cv_scores.append(score)
print(cv_scores)
print("%s_scotrainre_list:" % clf_name, cv_scores)
print("%s_score_mean:" % clf_name, np.mean(cv_scores))
print("%s_score_std:" % clf_name, np.std(cv_scores))
test = test/kf.n_splits
return test
五、完整代码
import os
import gc
import math
import time
import pandas as pd
import numpy as np
import lightgbm as lgb
import xgboost as xgb
from catboost import CatBoostRegressor
from sklearn.linear_model import SGDRegressor, LinearRegression, Ridge
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import StratifiedKFold, KFold
from sklearn.metrics import log_loss
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from imblearn.over_sampling import SMOTE
from tqdm import tqdm
import warnings
#此语句用来忽略警告输出,保持输出的整洁性
warnings.filterwarnings('ignore')
# 加载训练集和测试集(相对路径),读入为dataframe格式
train = pd.read_csv('train.csv')
test = pd.read_csv('testA.csv')
# 数据精度量化压缩,df是dataframe
# 这是用pandas读取csv,减少读取内存的一个常见方法
def reduce_mem_usage(df):
# 处理前 数据集总内存计算
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
# 遍历特征列
for col in df.columns:
# 当前特征类型
col_type = df[col].dtype
# 处理 numeric 型数据。numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
# int 型数据 精度转换
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.iZnt32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
# float 型数据 精度转换
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
# 处理 object 型数据,即文本类如str。
else:
df[col] = df[col].astype('category')
# object 转 category。object类型(python中),category类型(pandas中特有)
# category实际上是动态枚举的一种形式。
# 如果某个字段的内容中,其可能值的范围是固定且有限的,则category类型数据最为适用
# 处理后 数据集总内存计算
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(
100 * (start_mem - end_mem) / start_mem))
return df
# 训练集特征处理与精度量化
train_list = []
for items in train.values:
train_list.append([items[0]] + [float(i)
for i in items[1].split(',')] + [items[2]])
train = pd.DataFrame(np.array(train_list)) # 把train_list转换成df形式
train.columns = ['id'] + ['s_'+str(i)
for i in range(len(train_list[0])-2)] + ['label'] # 特征分离
train = reduce_mem_usage(train) # 精度量化
# 测试集特征处理与精度量化,与上面同理
test_list = []
for items in test.values:
test_list.append([items[0]] + [float(i) for i in items[1].split(',')])
test = pd.DataFrame(np.array(test_list))
test.columns = ['id'] + ['s_'+str(i) for i in range(len(test_list[0])-1)]
test = reduce_mem_usage(test)
# 查看训练集, 分离标签与样本, 去除 id
x_train = train.drop(['id', 'label'], axis=1)
y_train = train['label']
x_test = test.drop(['id'], axis=1)
# 由于存在严重的类别不平衡问题。使用 SMOTE 对数据进行上采样以解决类别不平衡问题,提高精度。
# 但运算量大幅度增加,且容易导致过拟合
smote = SMOTE(random_state=2021, n_jobs=-1)
k_x_train, k_y_train = smote.fit_resample(x_train, y_train)
print(
f"after smote, k_x_train.shape: {k_x_train.shape}, k_y_train.shape: {k_y_train.shape}")
# 评估函数,辅助用
def abs_sum(y_pre, y_tru):
y_pre = np.array(y_pre)
y_tru = np.array(y_tru)
loss = sum(sum(abs(y_pre-y_tru)))
return loss
#单模型法,使用lightGBM模型进行分类。利用弱分类器(决策树)迭代训练以得到最优模型,该模型具有训练效果好、不易过拟合等优点。
'''
lightGBM模型常用参数:
max_depth:树的最大深度,过拟合时应降低此值
feature_fraction:意味着在每次迭代中随机选择的特征的比例
bagging_fraction:每次迭代时用的数据比例,即迭代数据量的指定比例时bagging一次
early_stopping_round:如果一次验证数据的一个度量在最近的early_stopping_round 回合中没有提高,模型将停止训练
lambda:指定正则化0~1,如lambda_l2=0.1,表示采用l2正则化系数为0.1,系数越小正则化程度越高,用来防止过拟合
num_boost_round:迭代次数 通常 100+
learning_rate:学习率,常用 0.1, 0.001, 0.003…
num_leaves :叶子数,默认 31,取值应 <= 2 ^(max_depth)
device:设置cpu 或者 gpu
metric:评价指标设置,mae: mean absolute error , mse: mean squared error ,binary_logloss: loss for binary classification ,multi_logloss: loss for multi classification
Task:数据的用途, train 或者 predict
application模型的用途 ,regression: 回归,binary: 二分类,multiclass: 多分类
boosting:要用的算法 gbdt, rf: random forest, dart: Dropouts meet Multiple Additive Regression Trees, goss: Gradient-based One-Side Sampling
'''
def cv_model(clf, train_x, train_y, test_x, clf_name):
folds = 180 #循环总的次数
seed = 2023 # 指定随机数种子
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
test = np.zeros((test_x.shape[0], 4))
cv_scores = []
onehot_encoder = OneHotEncoder(sparse=False)
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
#只是为了分隔符好看一点
print('************************************ {} ************************************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[
train_index], train_x.iloc[valid_index], train_y[valid_index]
if clf_name == "lgb":
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
params = {
'boosting_type': 'gbdt', # 使用梯度提升树
'objective': 'multiclass', # 多分类
'num_class': 4, # 4种类型
'num_leaves': 119, #这行及后两行是贝叶斯调参得到的最佳效果
'feature_fraction': 0.57,
'bagging_fraction': 0.93,
'bagging_freq': 4,
'learning_rate': 0.1, # 学习率,数字越大,迭代速度越快
'seed': seed,
'n_jobs': 24,
'verbose': -1,
}
#训练模型
model = clf.train(params,
train_set=train_matrix,
valid_sets=valid_matrix,
num_boost_round=2000,
verbose_eval=100,
early_stopping_rounds=200)
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(
test_x, num_iteration=model.best_iteration)
val_y = np.array(val_y).reshape(-1, 1)
val_y = onehot_encoder.fit_transform(val_y)
print('预测的概率矩阵为:')
print(test_pred)
test += test_pred
score = abs_sum(val_y, val_pred)
cv_scores.append(score)
print(cv_scores)
print("%s_scotrainre_list:" % clf_name, cv_scores)
print("%s_score_mean:" % clf_name, np.mean(cv_scores))
print("%s_score_std:" % clf_name, np.std(cv_scores))
test = test/kf.n_splits
return test
def lgb_model(x_train, y_train, x_test):
lgb_test = cv_model(lgb, k_x_train, k_y_train, x_test, "lgb")
return lgb_test
lgb_test = lgb_model(k_x_train, k_y_train, x_test)
temp = pd.DataFrame(lgb_test)
result = pd.DataFrame()
result['id'] = range(100000, 120000)#根据sample_submit写的
result['label_0'] = temp[0]
result['label_1'] = temp[1]
result['label_2'] = temp[2]
result['label_3'] = temp[3]
result.head()
# 第一次后处理未涉及的难样本 index
others = []
# 第一次后处理 - 将预测概率值大于 0.5 的样本的概率置 1,其余置 0
threshold = 0.5
for index, row in result.iterrows():
row_max = max(list(row[1:])) # 当前行中的最大类别概率预测值
if row_max > threshold:
for i in range(1, 5):
if row[i] > threshold:
result.iloc[index, i] = 1 # 大于 0.5 的类别概率预测值置 1
else:
result.iloc[index, i] = 0 # 其余类别概率预测值置 0
else:
others.append(index) # 否则,没有类别概率预测值不小于 0.5,加入第一次后处理未涉及的难样本列表,等待第二次后处理
print(index, row)
result.head(5)
# 第二次后处理 - 在预测概率值均不大于 0.5 的样本中,若最大预测值与次大预测值相差大于 0.04,则将最大预测值置 1,其余预测值置 0;
# 否则,对最大预测值和次大预测值不处理 (难分类),仅对其余样本预测值置 0
for idx in others:
value = result.iloc[idx].values[1:]
ordered_value = sorted(
[(v, j) for j, v in enumerate(value)], reverse=True) # 根据类别概率预测值大小排序
#print(ordered_value)
if ordered_value[0][0] - ordered_value[1][0] >= 0.04: # 最大与次大值相差至少 0.04
result.iloc[idx, ordered_value[0][1]+1] = 1 # 则足够置信最大概率预测值并置为 1
for k in range(1, 4):
result.iloc[idx, ordered_value[k][1]+1] = 0 # 对非最大的其余三个类别概率预测值置 0
else:
for s in range(2, 4):
# 难分样本,仅对最小的两个类别概率预测值置 0
result.iloc[idx, ordered_value[s][1]+1] = 0
print(result.iloc[idx])
# # 检视最后的预测结果
# result.head()
# 保存预测结果
result.to_csv('submit.csv', index=False)
六、可优化角度
1、采用CNN相关模型
2、采取多模型融合方式
如《冠军攻略》所述:共用3个单模融合,A榜得分分别约为:Net1 142,Net3 156,NetB 145,此亦为加权融合设置权重的以据;
模型融合并取得提升的前提是好而不同,为此,3个模型各自具有一定性能(较好)但在细节上都有一定差别(不同)。模型的设计是本方案提升的关键,例如膨胀卷积、各种池化、分类器等。
由于模型及其超参数在B榜时已确定和固定,不再划分训练集和验证集,直接使用全数据集训练模型(但A榜平时采用10-fold CV)
训练策略均为:学习率阶梯衰减策略LearningRateScheduler+Adam优化器+sparse_categorical_crossentropy损失函数+batch_size 64+epoch 30

















&spm=1001.2101.3001.5002&articleId=132504528&d=1&t=3&u=b3692d9f87d6478f86223f69b07fe651)
 4404
4404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










