




ReLU是目前深度学习中最常用、最基础的激活函数,广泛用于卷积神经网络(CNN)和全连接层中。
1. 数学公式
ReLU 的数学表达式非常简单:
ReLU(x)=max(0,x) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)
也就是说:
- 当输入 x>0x > 0x>0 时,输出等于输入 xxx。
- 当输入 x≤0x \le 0x≤0 时,输出等于 000。
2. 几何特征与性质
- 输出范围:[0,+∞)[0, +\infty)[0,+∞)。
- 形状:在坐标系中,它是一条在原点处“折断”的折线。左半部分贴着 x 轴(y=0),右半部分是一条斜率为 1 的直线(y=x)。
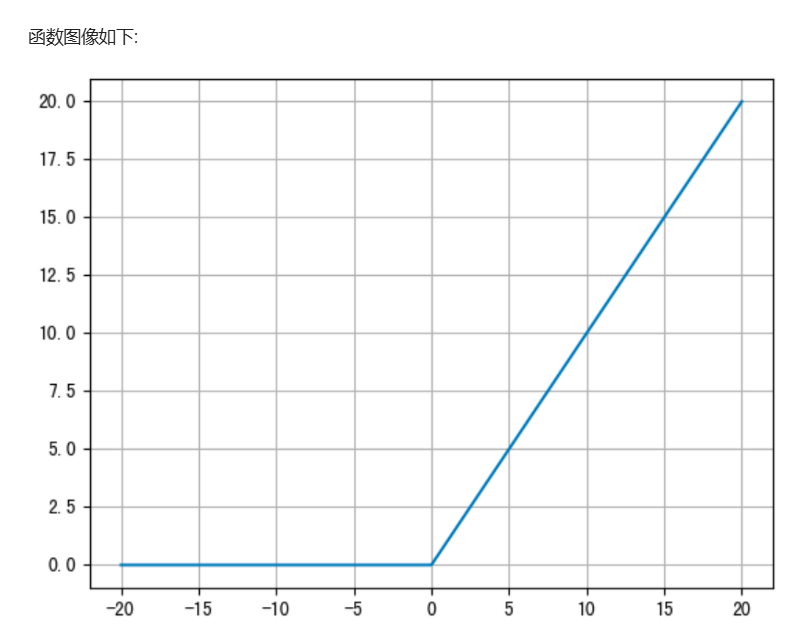
- 非线性:虽然它看起来像线性函数,但因为在 x=0x=0x=0 处的拐折,它整体是非线性的。这一点至关重要,正是这个非线性使得神经网络能够学习复杂的非线性映射。如果它完全是线性的,那么多层神经网络叠加起来依然等效于单层,失去了深度的意义。
3. 导数(梯度)
在反向传播中,ReLU 的导数同样极其简单:
ReLU′(x)={1,x>00,x≤0 \text{ReLU}'(x) = \begin{cases} 1, & x > 0 \\ 0, & x \le 0 \end{cases} ReLU′(x)={1,0,x>0x≤0
- 当 x>0x > 0x>0 时,梯度恒为 1。
- 当 x≤0x \le 0x≤0 时,梯度为 0。
(注:在 x=0x=0x=0 处严格来说是不可导的,但在代码实现中通常将其归为 0 或 1,不影响实际训练。结尾专门有补充这部分的内容)

4. ReLU 的变体(为了解决“死亡 ReLU”)
为了克服死亡 ReLU 和非零中心化的问题,人们提出了许多 ReLU 的变体:
- Leaky ReLU(带泄漏的 ReLU):
- 公式:f(x)={x,x>0αx,x≤0f(x) = \begin{cases} x, & x > 0 \\ \alpha x, & x \le 0 \end{cases}f(x)={x,αx,x>0x≤0 (α\alphaα 通常是一个很小的常数,如 0.01)。
- 作用:在负区间引入一个微小的斜率,使得负区间也有梯度,彻底解决死亡 ReLU 问题。
- PReLU (Parametric ReLU):把 Leaky ReLU 里的 α\alphaα 当作一个可学习的参数,让网络自己训练出最佳的负区间斜率。
- RReLU (Randomized ReLU):在训练时随机采样负斜率(如α∼U(0.01,0.3)),增加模型鲁棒性。
- ELU (Exponential Linear Unit):负区间使用指数函数平滑过渡到 −1-1−1,输出均值更接近 0(缓解了非零中心化问题),但计算包含了指数,稍慢。
- GELU / Swish:更现代的平滑激活函数,目前在 Transformer(如 GPT、BERT)中极为常见,性能优于传统 ReLU。
5. 常见应用场景
- CNN(卷积神经网络)的隐藏层:几乎所有现代 CNN(如 ResNet, VGG, YOLO)的卷积层后都默认使用 ReLU。
- MLP(多层感知机)的隐藏层:深度全连接网络的标配。
- 注:通常不会在输出层使用 ReLU,因为输出层通常有特定的任务需求(如分类用 Softmax,回归用线性或 tanh)。
扩展问题:既然ReLU 在 0 处不可导,为什么还能使用?
尽管ReLU在 ( x = 0 ) 处不可导,但在实际训练中不影响使用,因为实际训练中某个神经元的输入为 0 的概率极低,即使偶尔碰到,也可以通过工程上的约定来处理【即:在实现反向传播时,我们通常会约定 ReLU 在 x=0 处的导数为 0 或 1,这种约定对结果无影响】。


















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










