



导读:新的一年还是要肝起来啊,终于决定“染指”深度学习方向,并打算先更新一波Pytorch学习教程。当然,这会是一个系列。

提及Pytorch就不得不先从深度学习开始讲起。从事数据相关岗位的都知道,深度学习是机器学习的一个子方向,其主要以神经网络为基础模块,通过灵活组合一定层数的网络实现特定的模型功能,尤其擅长于计算机视觉(CV)和自然语言处理(NLP)方向。其发展历史上,在经历了两次高潮和两次低谷之后,目前处于第三次高速发展的蓬勃期。
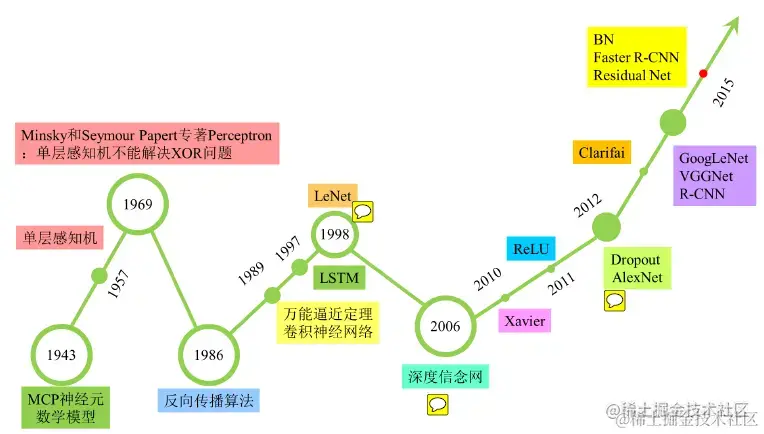
这里,深度学习的深度主要体现为构建的模型层数较多,故称之为“深”;但其实这里隐藏着一个重要假设,就是构建的模型都以神经元作为网络的最小单元,所以严谨的讲应叫做基于神经网络的深度学习。自然,也可以不基于神经网络,比如周志华团队前几年探索提出了深度随机森林模型,可谓是提出了深度学习的一个新的研究思路。
从理论研究到工业应用,其中必然少不了成熟的工业级实现。以python语言为基础,对于经典的机器学习模型,那么必然人人皆知scikit-learn;而若提及深度学习,则相应的工具包则不那么“集中和统一”,甚至称得上是大厂纷争之地。其中,最具代表性和广泛使用的当属TensorFlow和Pytorch,前者源于google,后者发于Facebook;前者以工业应用居多,后者则流行于学术界。当然,单论学术界还是工业界而言,二者也没有明确的界限。
起初,在了解到TensorFlow广泛应用工业界,而自己早已远离院校所以就直接入坑了TensorFlow,当了一段时间的TF boy,尤其是了解到TensorFlow2.0克服了早期1.0版本饱受诟病的静态图问题,所以也不认为TensorFlow有啥缺点。但后来,随着学习的深入,加之通过周边同事的了解,发现Pytorch有着更为优秀的特点:比如与Numpy的设计更为接近,语法风格更加Pythonic等等。所以,个人也就果断转投Pytorch阵营。
本文作为第一篇,仅用来介绍Pytorch能干什么,以及对为什么这么设计的个人理解。
Torch是一个老牌的深度学习框架,最早是基于lua语言开发的,由于其开发语言的小众性,所以其发展和应用也是受到了很多限制。自从Facebook开源了Python生态圈的Torch工具包——Pytroch之后,其就一直是匹敌TensorFlow的一个重量级工具。目前Pytroch在GitHub上获得54k star(TensorFlow目前在GitGHub上获得163k star,差距还是比较大的,大概有3倍之多)。
也正是由于深度学习最广泛的舞台在于图像和语音以及文本等应用方向,所以与Pytorch配套的三个工具包以及一个模型服务工具包:
- torchvision
- torchtext
- torchaudio
当然,Pytorch仍然是基础和核心
作为一个深度学习工具包,Pytorch能用来干什么呢?这里引用官方文档对其定位的描述,广义来说有两方面功能:

即:
- 支持GPU加速的Tensor计算能力
- 支持自动求导的深度神经网络构建
那么问题来了:都说Pytorch是一个深度学习工具,为什么其核心功能设计为如上两点?对此,个人理解如下:
其一:Tensor是深度学习模型构建和训练的基础,其地位就好比是array之于Numpy、DataFrame之于Pandas,其本身是一种数据结构,但却构成了Pytorch的灵魂所在。这里,Tensor英文原义为“张量”,其实就是对应一个多维数组,本质上跟numpy的ndarray是一致的。
从这一角度来看,Pytorch可视作是numpy的升级版,这里的升级主要体现为可以利用GPU的强力并行计算能力。如果有Numpy基础,学习Pytorch其实可以很简单;另一方面,学Pytorch也完全可以作为是对Numpy的一个补充,而不去考虑构建深度学习模型的用途。
其二:Pytorch定位为一个深度学习工具,其更为主体的功能在于支持深度学习模型的构建和训练。与此同时,与经典机器学习中有成熟模型不同的是,深度学习网络大多没有固定的模型或范式,而一般由使用者将多个基础模块灵活搭配来组成(当然,其实也有一些成熟的模型,例如LeNet-5、AlexNet和VGGNet等,但更普遍的仍然需要使用者自己去定制),所以Pytorch对深度学习的支持不在于集成了多少成熟的模型,而在于提供了基础的深度学习模块,这些就好似脚手架一般,可以任意组合搭配,从而实现更为自由定制化的功能。
Pytorch功能还是比较丰富和繁杂的,最好的学习平台是查阅其官方文档,
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










