



一、发布背景与概述
2026 年 4 月 24 日,在 OpenAI 发布 GPT-5.5 仅几小时后,中国 AI 公司深度求索 (DeepSeek) 扔出了自己的 “王炸”—— 全新旗舰模型 DeepSeek-V4 预览版正式上线并同步开源。这不是一次简单的版本更新,它直接改写了开源大模型的性能上限和价格底线,引发了全球 AI 社区的轰动。
DeepSeek-V4 系列包含两款性能强劲的混合专家 (Mixture-of-Experts, MoE) 语言模型:
- DeepSeek-V4-Pro:总参数 1.6 万亿,激活参数 490 亿
- DeepSeek-V4-Flash:总参数 2840 亿,激活参数 130 亿
两款模型均支持 100 万 token 的超长上下文,这是行业首次将百万级上下文作为所有官方服务的标配。

图 1:一图看懂 DeepSeek V4 系列核心参数
DeepSeek 官方表示:“我们将始终秉持长期主义的原则理念,在尝试与思考中踏实前行,努力向实现 AGI 的目标不断靠近。”
二、核心技术创新
DeepSeek-V4 在架构设计与优化策略上实现了多项关键突破,这些创新共同造就了其卓越的性能和效率。
2.1 混合注意力架构:百万上下文的 “效率革命”
为解决长上下文场景下推理效率低、资源占用高的痛点,DeepSeek-V4 创新性地结合了压缩稀疏注意力 (Compressed Sparse Attention, CSA)与重度压缩注意力 (Heavily Compressed Attention, HCA),实现了长上下文处理效率的显著提升。
官方测试数据显示,在百万 token 上下文场景下:
- DeepSeek-V4-Pro 仅需上一代模型 DeepSeek-V3.2 27% 的单 token 推理 FLOPs
- 所需 KV 缓存空间仅为上一代的 10%
这一突破让百万 token 级别的长文本处理从 “奢侈品” 变成了 “标配”。

图 2:1M 上下文效率对比,V4 实现了质的飞跃
2.2 流形约束超连接 (mHC):增强跨层信号传播
在传统残差连接的基础上,DeepSeek-V4 引入了流形约束超连接 (Manifold-Constrained Hyper-Connections, mHC),对传统残差连接进行增强,有效提升了跨层信号传播的稳定性和模型的表达能力。
2.3 Muon 优化器:更快收敛与更高稳定性
DeepSeek-V4 采用了 Muon 优化器,实现了更快的模型收敛速度和更稳定的训练过程。这一优化使得训练万亿参数级别的模型变得更加高效和可靠。
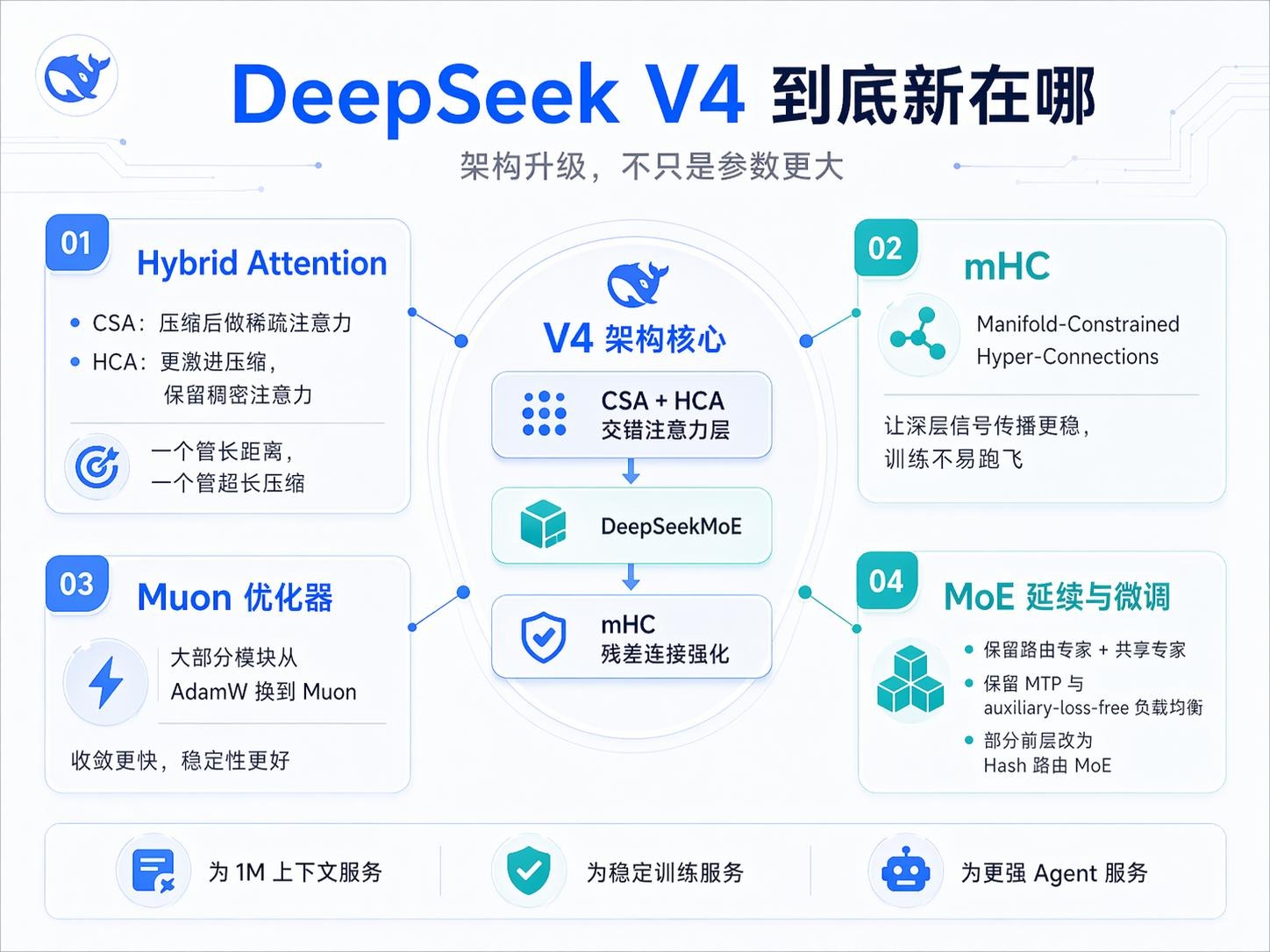
图 3:DeepSeek V4 四大核心技术创新
2.4 整体架构概览
DeepSeek-V4 采用了先进的混合专家架构,结合了上述多项技术创新,形成了一个高效、强大的 AI 系统。
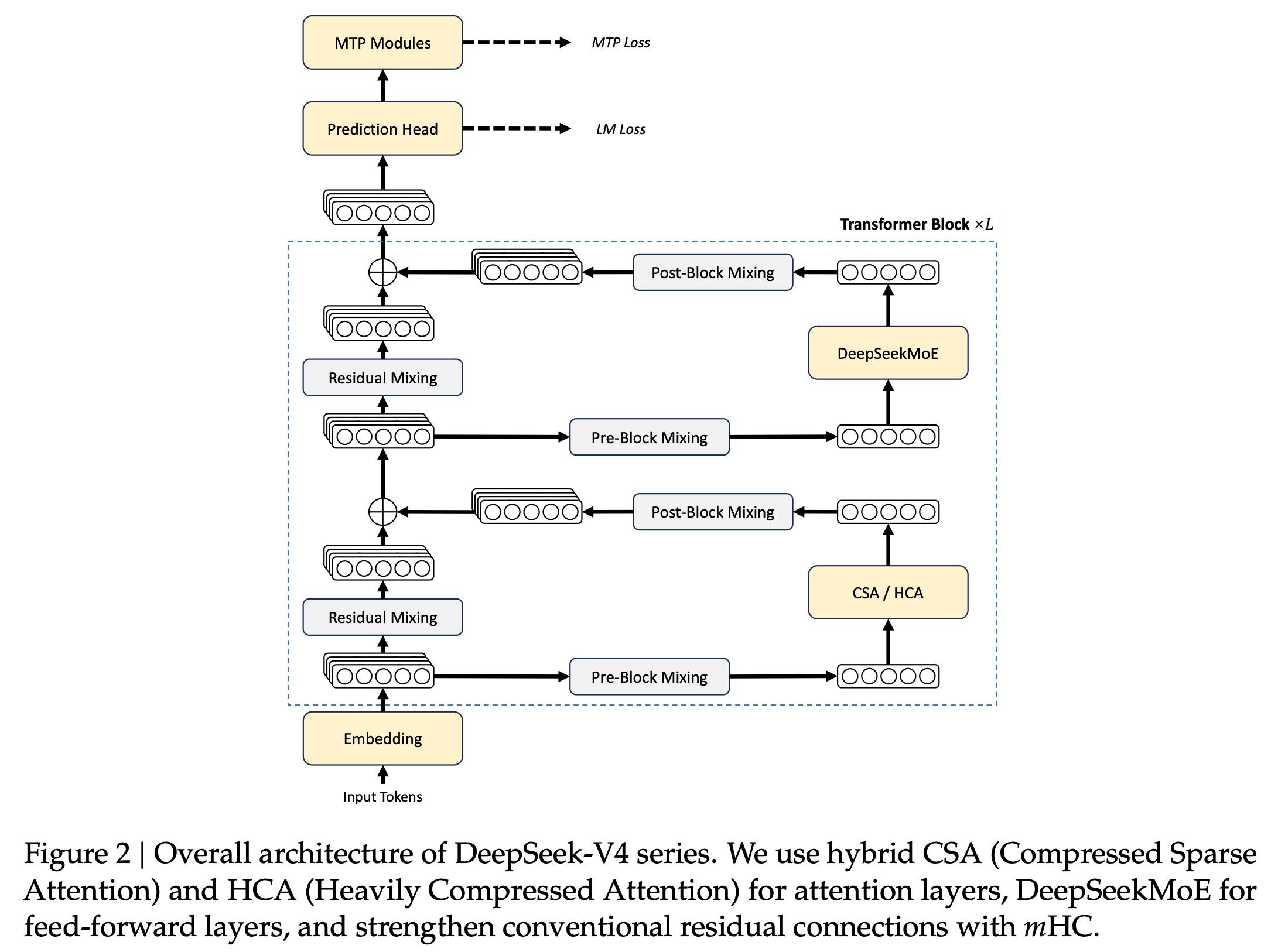
图 4:DeepSeek V4 整体架构图
三、性能表现与对比
DeepSeek-V4 在多个关键评测中展现出了卓越的性能,尤其是在代码能力、Agent 能力和长文本处理方面。
3.1 综合性能对比
在与全球顶尖模型的对比中,DeepSeek-V4-Pro-Max 展现出了强大的实力:
- 代码能力:LiveCodeBench Pass@1 93.5、Codeforces Rating 3206、Apex Shortlist 90.2,三项均为对比组最高
- 知识能力:SimpleQA-Verified 57.9,高于除 Gemini 之外所有模型;Chinese-SimpleQA 84.4,接近 Gemini 的 85.9
- Agent 能力:整体与 Claude Opus-4.6-Max、Kimi K2.6-Thinking 在同一档
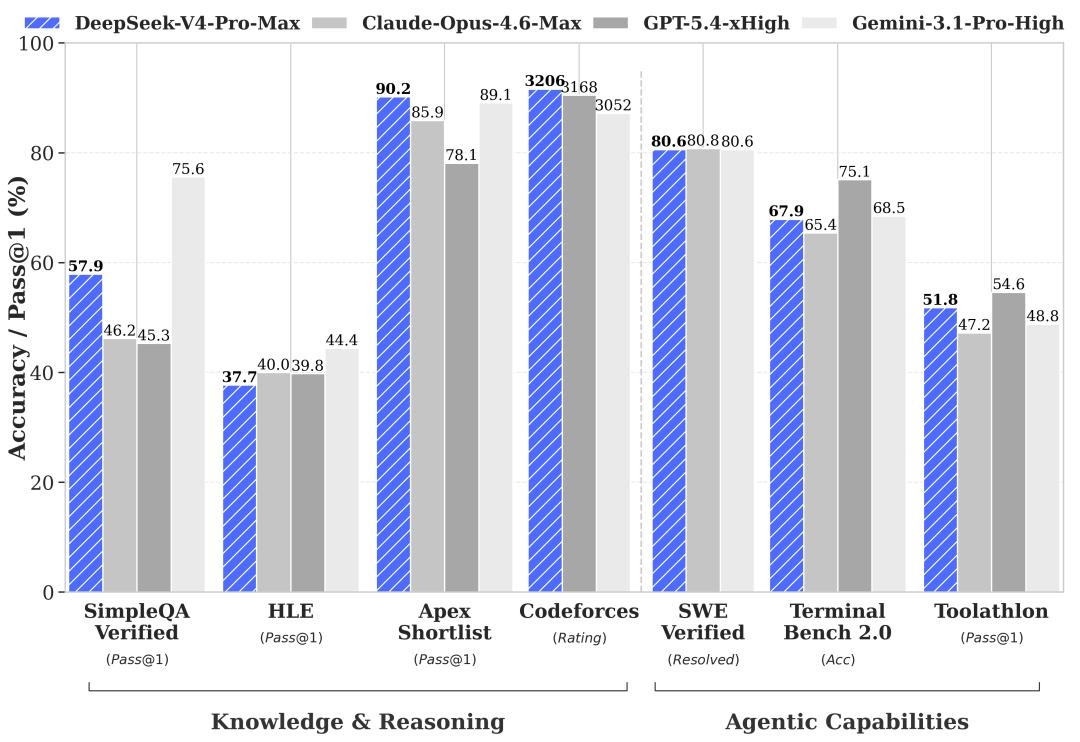
图 5:DeepSeek V4 与全球顶尖模型性能对比
3.2 代码能力:开源界天花板
代码能力是 DeepSeek-V4 最突出的优势之一:
- 在 Vibe Code Benchmark 中以 “压倒性优势” 拿下开源权重模型榜首,击败 Gemini 3.1 Pro 等闭源模型
- 较上代 V3.2 实现约 10 倍性能跃升
- Codeforces 评分高达 3206,排名人类选手第 23 位,达到顶尖竞赛程序员水准
官方表示,DeepSeek 公司内部已经把 V4 作为默认编码模型,反馈是 “优于 Sonnet 4.5,交付质量接近 Opus 4.6 的非思考模式”。
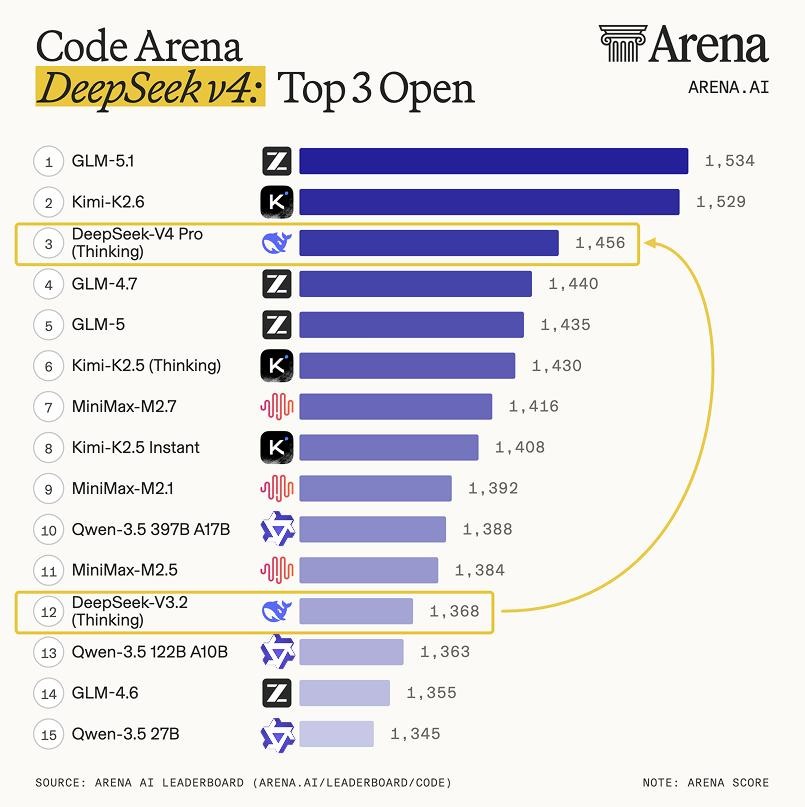
图 6:Code Arena 排行榜,DeepSeek V4 位列开源模型前三
3.3 Agent 能力:开源第一
在智能体任务表现方面,V4-Pro 在真实场景智能体工作任务中,性能位居所有开源权重模型首位,得分 1554,超越 Kimi K2.6 (1484)、GLM-5.1 (1535)、GLM-5 (1402) 以及 MiniMax-M2.7 (1514)。
3.4 官方自我评估
DeepSeek 官方在技术报告中坦诚地表示:
- V4 的 Agent 能力仅比肩 Claude Sonnet 4.5,离 Opus 4.6、4.7 还有差距
- 世界知识离 Gemini-Pro-3.1 还有差距
- 推理性能与 GPT-5.4 旗鼓相当
- 整体发展轨迹约滞后前沿闭源模型 3 到 6 个月
四、价格优势与普惠性
DeepSeek 延续了一贯的 “普惠” 风格,V4 系列的定价再次震惊了整个行业。
4.1 官方 API 定价
| 模型 | 缓存命中输入 | 缓存未命中输入 | 输出 |
|---|---|---|---|
| DeepSeek V4-Flash | ¥0.2 / 百万 Token | ¥1 / 百万 Token | ¥2 / 百万 Token |
| DeepSeek V4-Pro | ¥1 / 百万 Token | ¥12 / 百万 Token | ¥24 / 百万 Token |
数据来源:DeepSeek 官方 API 定价,2026 年 4 月 24 日
4.2 与全球主流模型价格对比
将价格换算成人民币 / 百万 Token (按 1 美元约 7.2 人民币换算):
| 模型 | 输入价格 | 输出价格 | 输出是 V4-Flash 倍数 |
|---|---|---|---|
| DeepSeek V4-Flash | ¥1 | ¥2 | 1 倍 |
| DeepSeek V4-Pro | ¥12 | ¥24 | 12 倍 |
| GPT-5.5(OpenAI) | ¥36 | ¥210 | 105 倍 |
| Claude Opus 4.6(Anthropic) | ¥105 | ¥525 | 263 倍 |
| Claude Sonnet 4.6 | ¥21 | ¥105 | 53 倍 |
数据来源:各平台官方定价,2026 年 4 月 24 日
4.3 市场实际使用价格
根据全球最大 AI 模型 API 聚合平台 OpenRouter 的数据,截至 2026 年 4 月 24 日 13:30:
- DeepSeek-V4-Flash 的平均输出价低至 0.279 美元 / 百万 Token
- 仅为 OpenAI 新发布的 GPT-5.5 Pro (180 美元 / 百万 Token) 的 1.55‰
- 其他主流大模型的输出价格均在 12~25 美元区间,是 DeepSeek-V4-Flash 的数十倍
DeepSeek 官方特别标注:“受限于高端算力,目前 Pro 的服务吞吐量十分有限,预计下半年昇腾 (Ascend) 950 超节点批量上市后,Pro 的价格会大幅下调。”
五、国产算力适配
DeepSeek-V4 的发布不仅是模型技术的突破,更是中国 AI 全栈国产化的重要里程碑。
5.1 华为昇腾全面支持
华为计算在 DeepSeek-V4 发布后立即宣布:昇腾超节点全系列产品全面支持 DeepSeek V4 系列模型。
通过双方芯模技术紧密协同:
- 昇腾 950 通过融合 kernel 和多流并行技术降低 Attention 计算和访存开销
- 结合多种量化算法,实现了高吞吐、低时延的推理部署
- 基于 DeepSeek V4-Pro 模型,在 8K 输入场景,昇腾 950 超节点可实现 TPOT 约 20ms 时单卡 Decode 吞吐 4700TPS
- DeepSeek V4-Flash 模型,8K 长序列输入场景下可实现 TPOT 约 10ms 时单卡 Decode 吞吐 1600TPS
5.2 其他国产芯片支持
除了华为昇腾外:
- 寒武纪基于 vLLM 推理框架完成了对 DeepSeek-V4 两个版本的 Day0 适配
- 天数智芯等国产芯片厂商也已支持 DeepSeek-V4 新模型
5.3 技术架构转变
DeepSeek-V4 的技术架构从 CUDA 彻底转向华为 CANN 框架:
- 华为 CANN 已实现超 95% 的 CUDA 代码兼容
- 迁移效率辅以一键迁移工具,代码重构从按月计缩短到按小时计
- 经过优化后的 DeepSeek V4 在昇腾 950PR 上的推理速度较初期版本提升 35 倍,能耗降低 40%
- 单卡推理性能达到英伟达特供版 H20 芯片的 2.87 倍
英国路透社指出:“华为昇腾等中国国产算力也已适配 DeepSeek-V4,表明中国正在努力减少对美国尖端芯片的依赖。”
六、实际应用场景
DeepSeek-V4 的百万上下文能力和强大的综合性能,使其在多个领域展现出巨大的应用价值。
6.1 金融投研:整份年报一次性分析
一家头部金融机构的投研部门使用 DeepSeek-V4 处理长达 200 页的上市公司年报:
- 分析师将整份年报一次性上传,直接提问
- AI 在 8 秒内给出了精准答案,并指出了不同章节数据间的潜在关联
- 报告生成效率提升了 4 倍,并替代了原有的 3 套闭源分析工具
6.2 软件开发:全仓库级别代码理解
DeepSeek-V4 支持百万级 TOKEN 上下文,能够直接加载 10 万行代码库:
- 进行跨文件重构
- 理解并操作大型代码库中的复杂逻辑和依赖关系
- 自主规划多个核心模块和数据表的完整数据库设计
- 全程无需人工干预,自我纠错与工具调用能力拉满
6.3 文档处理:百万字长文本一站式服务
DeepSeek-V4 能够处理一整部《三体》(约 90 万字) 级别的长文本:
- 法律合同审查:一次性审查数百页的合同文本,找出潜在风险点
- 学术论文综述:一次性阅读上百篇相关论文,生成全面的研究综述
- 书籍内容分析:分析整本书的结构、主题和人物关系
6.4 智能体开发:低成本大规模部署
V4-Flash 的极致性价比使其成为大规模 Agent 应用的理想选择:
- 开发者在构建 AI 应用时,成本几乎可以忽略不计
- 能够支持成千上万的智能体同时运行
- 为 AI Agent 的普及铺平了道路
七、局限性与不足
尽管 DeepSeek-V4 取得了显著的进步,但它仍然存在一些局限性和不足。
7.1 幻觉率上升
海外评测显示,相较于 V3.2 的幻觉率 (82%),V4 两款模型的幻觉问题更为突出:
- V4-Pro 幻觉率为 94%
- V4-Flash 幻觉率为 96%
意味着模型在未知问题场景下,几乎都会强行生成答案。
7.2 Token 消耗大
完成标准测评流程:
- V4-Pro 输出 Token 消耗量达 1.9 亿,属于本次测评中 Token 消耗最高的模型之一
- V4-Flash 消耗进一步攀升至 2.4 亿 Token
即便定价偏低,高额的 Token 消耗仍是 V4-Pro 综合使用成本高于其他开源模型的核心原因。
7.3 本地 skill 调用不灵敏
有开发者实测发现:
- V4 在本地 skill 调用方面不够主动
- 有时候需要明确提示才去调用工具
- 问题不是不会调 skill,而是 “判断该不该调的决策不够果断”
7.4 复杂约束下的理解力有待提升
在处理带有复杂约束的任务时,V4 的表现有时不够理想:
- 对多重嵌套指令容易遗漏
- 在复杂的视觉渲染任务中可能出现问题
- 如生成高度逼真的交互式 3D 纸质小票时,视觉渲染和物理效果都存在缺陷
7.5 官方承认的差距
DeepSeek 官方在技术报告中坦诚:
- 知识类和最前沿的推理任务仍有 3-6 个月的 gap
- HLE (高阶逻辑推理) 上 V4-Pro-Max 37.7,低于 Gemini-3.1-Pro 的 44.4 和 Claude-Opus-4.6-Max 的 40.0
- 1M MRCR 上 V4 优于 Gemini 但明显不如 Claude
八、行业影响与未来展望
8.1 全球 AI 格局的改变
DeepSeek-V4 的发布在全球范围内引起了广泛关注:
英国路透社指出:“DeepSeek-V4 在世界知识测评中大幅领先于其他开源模型,仅次于谷歌的顶尖闭源模型,反映出中国企业在 AI 领域突飞猛进的技术实力。”
卡塔尔半岛电视台称:“去年年初,DeepSeek 曾凭借低成本、高性能的推理模型震惊世界,被视为 AI 领域的 ’ 斯普特尼克时刻 '。如今,DeepSeek-V4 再次展现出强大的性能,令人瞩目。”
英伟达 CEO 黄仁勋 4 月中旬在一档播客节目中直言:“DeepSeek 的进步意义重大。要是哪天像 DeepSeek 这样的公司不再需要我们的芯片了,那才是真正的问题。”
8.2 价格战的新阶段
DeepSeek-V4 把大模型价格战从 “聊天便宜” 推入了 “Agent 便宜” 的新时代:
- 百万上下文从 “奢侈品” 变成了 “标配”
- 开发者可以用极低的成本构建复杂的 AI 应用
- 这将加速 AI 技术的普及和应用落地
8.3 未来发展方向
DeepSeek 在技术报告中指出了未来的发展方向:
- 探索新维度的稀疏性 (点名了 Engram 那条线)
- 开发低延迟架构
- 提升长时程多轮 agentic 任务能力
- 增强多模态能力
- 优化数据 curation
九、总结
DeepSeek-V4 的发布是中国 AI 发展史上的一个重要里程碑。它不仅在技术上实现了多项突破,更在普惠性和国产化方面迈出了关键一步。
核心亮点:
✅ 双版本开源:1.6T Pro 和 284B Flash 均开源,支持本地部署
✅ 百万上下文标配:行业首次将 1M 上下文作为所有官方服务的标配
✅ 极致性价比:V4-Flash 输出价格仅为 GPT-5.5 的 1/105,Claude Opus 4.6 的 1/263
✅ 代码能力突出:开源界天花板,接近顶级闭源模型水平
✅ 国产算力全面支持:华为昇腾、寒武纪等国产芯片均已适配
待改进之处:
⚠️ 幻觉率较高,需要进一步优化
⚠️ Token 消耗较大,影响综合使用成本
⚠️ 与最前沿闭源模型仍有 3-6 个月的差距
⚠️ 复杂任务处理能力有待提升
DeepSeek-V4 证明了中国 AI 企业有能力在全球 AI 竞争中占据一席之地。它不仅为开发者提供了一个强大、低成本的 AI 工具,也为中国 AI 产业的自主可控发展奠定了坚实基础。
正如 DeepSeek 官方所言:“不诱于誉,不恐于诽,率道而行,端然正己。” 在通往 AGI 的道路上,DeepSeek 正以自己的节奏稳步前行。




















 1783
1783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












