




1.相关概念
dragonfly源于阿里技术团队开发的一款开源的镜像分发系统,主要利用p2p的机制来解决镜像在大规模集群中下载分发时给上游仓库所带来的压力,导致镜像拉取缓慢性能低下等问题。
dragonfly目前也已入CNCF接受孵化,这也是继TiKV、harbor之后的第三个加入CNCF中来自中国的开源项目。
在介绍dragonfly的工作原理及架构前,先来说一下dragonfly中有的几个名词概念
Host:这个host在这里被看作是运行dragonfly客户端程序下载镜像文件的主机
Peer:下载同一个文件的Host 彼此之间称为 Peer
dfget:一个类似wget的文件下载程序,通常部署在dragonfly客户端也就是peer节点
dfdaemon:一个守护进程,监控用户发来的下载请求,同时与dragonfly的管理服务(supernode)进行交互,调用dfget程序从supernode缓存下载或源地址下载
DFclient:是dragonfly的客户端其中包含dfdaemon、dfget等程序,安装在每台peer主机上,主要负责分块的上传与下载。
SuperNode:是dragonfly任务调度节点,它主要负责种子块的生命周期管理以及构造P2P 网络并调度peer间互传指定分块。
其职责主要有两类:第一是以被动CDN 方式从文件源下载文件并生成一组种子分块数据,第二构造 P2P 网络并调度每个peer之间互传指定的分块数据。
2.工作原理
首先我们先来看一下dragonfly的一个架构图
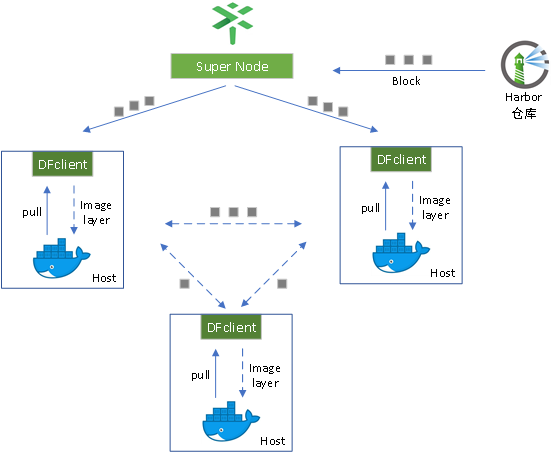
如上图所示,至少2个host和1个调度节点组成一个p2p网络,supernode对内接收host中dfclient发来的请求,对外接收镜像预热的请求。
如果是外部发来的预热请求,将创建一个preheat任务,supernode从仓库中获取镜像文件并生成分片数据在本地缓存,当有下载请求时会被dfclient也就是运行的dfdaemon进行拦截,如果dfclient本地也没有缓存,那么会向supernode问询,从supernode中获得数据分片,每下载一个分片会上传至其他peer(也就是相邻的dfclient)中,以此类推直至全部的peer节点完成对该文件所有分片缓存;
如果是内部dfclient向supernode主动发起请求,supernode首先检查本地是否有缓存,如果没有则向文件源地址获取并下载对应文件,生成分片数据,分片数据无需等待全部的文件下载完成再分发,只要生成分片数据会立即分发至dfclient,dflicent会通过wget来从supernode中获取分片数据,然后再传输给其他peer节点。
值得一提的是,本地下载的时候会将下载分片进度通过metadata文件进行记录,如果突然中断了,再次执行dfget 命令会进行断点续传。下载结束后,会比对 MD5,以确保下载的文件和源文件是完全一致的,dragonfly还会通过HTTP cache协议来控制supernode对文件的缓存时长。
这类似我们用的BT下载技术(例如早期的迅雷




















 421
421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










