




DPO(Direct Preference Optimization)的相关参数的详细解释和举例说明。这些参数主要用于控制 DPO 训练过程中的损失函数计算方式、优化偏好行为的程度等。
✅ 核心 DPO 参数详解
1. --pref_beta 0.1
含义:
这是 DPO 损失中的超参数 β,用于平衡两个目标之间的 trade-off:模型生成喜欢的回答(chosen)与保持与参考模型(通常是 SFT 模型)接近。
DPO 的核心损失函数如下(sigmoid 版本):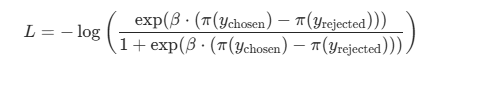
其中:

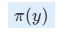 :表示当前模型对回答 y 的 log-prob。
:表示当前模型对回答 y 的 log-prob。- β :控制“倾向差”的敏感程度,β 越大,模型更强调两个回答的分数差异。
举例:
假设模型对 preferred 的输出 log-prob 是 -1.0,rejected 的是 -2.0:
- 如果 β = 0.1,那么模型的 sigmoid 差值 = sigmoid(0.1 × (1.0)) ≈ 0.525;
- 如果 β = 1.0,sigmoid(1.0) ≈ 0.73;
- 所以 β 越大,模型越“自信”,训练越激进;越小则越温和。
建议:
0.1是一个保守但稳定的值;- 可以根据模型训练稳定性或对齐质量微调(如 0.05 / 0.5 / 1.0)。
2. --pref_loss sigmoid
含义:
设置使用的 DPO 损失函数类型,目前 LLaMAFactory 支持:
sigmoid(默认):标准的对比损失形式,鼓励模型输出更偏向 chosen;hinge:类似最大间隔损失,损失为: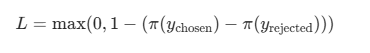
比较:
|
损失函数 |
特点 |
使用建议 |
|
|
平滑、可微,训练稳定 |
推荐大多数情况使用 |
|
|
更像硬间隔分类,收敛快但可能不稳定 |
用于需要强对比信号时 |
举例:
- 若 chosen 更好,但 log-prob 只高一点点,sigmoid 会给较小 loss,hinge 可能直接为 0。
- 适合更有争议性的偏好任务用 sigmoid。
3. --pref_ftx 0
含义:
是否启用“混合 DPO + SFT”损失,即:![]()
其中 pref_ftx=1 时启用 SFT(通常是 cross-entropy)辅助损失,有助于:
- 稳定训练;
- 避免模型偏离原始回答风格过远。
值设置说明:
0:完全 DPO(只基于偏好训练);1:开启 FTX loss(可能需要额外数据结构支持);- 对于你当前的设置(
pref_ftx=0),代表模型仅做偏好对齐,而不再额外用chosen做CE训练。
🔁 举个完整的例子:
假设你有以下一个样本(Pair):
{
"prompt": "病人出现咳嗽、发热,应考虑什么疾病?",
"chosen": "可能是呼吸道感染,如肺炎或支气管炎。",
"rejected": "应该买点感冒药吃就行了。"
}
训练过程中:
- 模型会分别计算
chosen和rejected的 log-prob; - 取其差值,再乘以
beta,进入 sigmoid 函数; - 输出 loss,鼓励模型将
chosen的概率越拉越高,而rejected越低。
如果使用:
--pref_beta 0.1
--pref_loss sigmoid
--pref_ftx 0
那么:
- 模型仅根据 log-prob 差值更新;
- 训练目标是:让
chosen更像模型输出,rejected更不像; - 不再单独强化
chosen本身的 token-level correctness。
✅ 总结推荐
|
场景 |
建议设置 |
|
首次 DPO 微调 |
|
|
追求更强对比训练 |
|
|
模型不稳定/偏离太多 |
|
|
小模型/数据少 |
较小的 β,如 |
如果你有具体偏好数据格式(如三元组、双回答格式)或需要绘制 DPO loss 曲线图,我也可以继续提供例子和代码。是否还需要 DPO 推理(推理时如何只用 chosen)或评估部分说明?


















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










