





1. 引言
随着大语言模型(LLM)规模突破千亿参数,传统全参数微调(Full Fine-Tuning)面临巨大计算成本挑战。参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)技术通过仅微调少量参数即可达到接近全参数微调的效果,成为大模型适配下游任务的关键方案。本文系统解析6类核心PEFT方法及其工程实践。
2. 核心方法对比框架
| 方法 | 可训练参数量 | 典型应用场景 | 显存占用 | 代表论文 |
|---|---|---|---|---|
| LoRA | 0.1%-1% | 指令微调 | 降低60%-70% | LoRA (2021) |
| QLoRA | <0.1% | 单卡微调超大模型 | 降低80%+ | QLoRA (2023) |
| Adapter Tuning | 3%-5% | 多任务学习 | 降低50% | AdapterHub |
| P-Tuning v2 | 0.01%-0.1% | 小样本学习 | 极低 | P-Tuning v2 |
| Prefix Tuning | 0.1%-1% | 生成任务 | 中等 | Prefix(2021) |
| Prompt Tuning | <0.01% | 轻量级适配 | 最低 | Prompt(2021) |
3. 关键技术原理与实现
3.1 LoRA(Low-Rank Adaptation)
核心思想:通过低秩分解注入可训练参数
-
在原始权重旁路添加降维矩阵:
W' = W + BA (其中B∈ℝ^{d×r}, A∈ℝ^{r×k}, r≪d) -
实现要点:
# HuggingFace PEFT实现 from peft import LoraConfig, get_peft_model config = LoraConfig( r=8, # 秩 lora_alpha=32, target_modules=["q_proj", "v_proj"] ) model = get_peft_model(model, config)
3.2 QLoRA(Quantized LoRA)
三阶段优化:
-
4-bit量化:将预训练模型权重量化为NF4格式
-
双量化:进一步压缩量化常数
-
分页优化:处理显存峰值问题
内存节省对比:
| 方法 | 微调LLaMA-65B所需显存 |
|---|---|
| 全参数 | >780GB |
| LoRA | ~120GB |
| QLoRA | <48GB |
3.3 Adapter Tuning
结构设计:
-
在Transformer层间插入小型MLP:
h ← h + f(W_down·σ(W_up·h))
-
变体:
-
Parallel Adapter(并行计算)
-
Compacter(参数共享设计)
-
3.4 P-Tuning系列
演进路线:
-
P-Tuning v1:可训练连续prompt嵌入
-
P-Tuning v2:引入深层prompt(每层添加)
v2关键改进:
# 每层注入prefix参数
self.prefix_emb = nn.Parameter(
torch.randn(num_layers, prefix_len, hidden_size))
3.5 Prefix/Prompt Tuning
对比特性:
| 特性 | Prefix Tuning | Prompt Tuning |
|---|---|---|
| 参数位置 | 各层均添加 | 仅输入层 |
| 参数量 | 较大 (~1%) | 极小 (<0.01%) |
| 训练稳定性 | 需要重参数化 | 直接训练 |
4. 工程实践指南
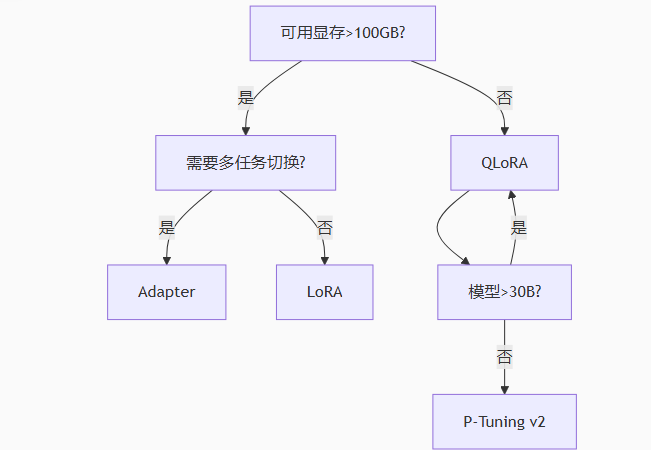
4.1 方法选型决策树
4.2 典型配置示例
场景:单卡RTX 4090微调LLaMA2-13B
method: QLoRA
params:
bits: 4
lora_r: 64
lora_alpha: 16
target_modules: ["q_proj","k_proj","v_proj"]
optimizer: paged_adamw_8bit
batch_size: 4
4.3 性能优化技巧
-
梯度检查点:减少30%显存,增加20%计算时间
-
CPU卸载:QLoRA中可移除非关键张量到内存
-
混合精度:FP16计算+FP32主权重
5. 前沿发展方向
-
稀疏微调:如DiffPrune(动态剪枝+微调)
-
组合方法:LoRA+Adapter混合架构
-
理论突破:NTK-aware的低秩适配
-
硬件适配:针对H100的FP8微调方案
6. 效果对比实验
在Alpaca指令数据集上的评测结果:
| 方法 | 训练参数量 | 显存占用 | 准确率 |
|---|---|---|---|
| Full FT | 13B | 96GB | 82.3 |
| LoRA | 8.4M | 24GB | 81.7 |
| QLoRA | 4.2M | 18GB | 80.9 |
| P-Tuning v2 | 0.5M | 12GB | 78.1 |
7. 结论建议
-
资源充足场景:优先选用LoRA(平衡效果/成本)
-
超大模型微调:QLoRA是单卡可行方案
-
小样本学习:P-Tuning v2性价比最高
-
生产部署:建议测试不同方法的推理延迟影响
开源工具推荐:
-
HuggingFace PEFT库
-
bitsandbytes(QLoRA支持)
-
OpenDelta(适配器统一框架)
注:本文所有方法均已在HuggingFace生态实现,可通过
peft库快速实验。最新进展显示,结合MoE架构的PEFT方法可能成为下一代技术方向。


















 390
390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










