




痛点:AI 编程助手为何总是“半途而废”?
在使用 AI 编程工具时,开发者经常遭遇以下困境:
-
过早退出:AI 在它认为“足够好”时就停止工作,而非真正完成任务
-
单次提示脆弱:复杂任务无法通过一次提示完成,需要反复人工干预
-
重新提示成本高:每次手动重新引导都在浪费开发者时间
-
上下文断裂:会话重启后,之前的所有进展和上下文全部丢失
这些问题的本质是:LLM 的自我评估机制不可靠——它会在主观认为“完成”时退出,而非达到客观可验证的标准。
解决思路:让 AI 持续工作直到真正完成
Claude Code 社区诞生了一种极简但有效的范式——Ralph Loop(也称 Ralph Wiggum Loop):
while :; docat PROMPT.md | claude-code --continuedone
核心思想:同一个提示反复输入,让 AI 在文件系统和 Git 历史中看到自己之前的工作成果。这不是简单的“输出反馈为输入”,而是通过外部状态(代码、测试结果、提交记录)形成自我参照的迭代循环。其技术实现依赖于 Stop Hook 拦截机制。
Ralph Loop 让大语言模型持续迭代、自动运行直到任务完成,而不在典型“一次性提示 → 结束”循环中退出。这种范式已经被集成到主流 AI 编程工具和框架中,被一些技术博主和开发者称作“AI 持续工作模式”。
甚至 Ralph Loop 结合 Amp Code 被用来构建新编程语言(AFK):https://x.com/GeoffreyHuntley/status/1944377299425706060
TL;DR / 快速开始
Cloud Native
Ralph Loop 让 AI 代理持续迭代直到任务完成。
核心三要素:
-
明确任务 + 完成条件:定义可验证的成功标准
-
Stop Hook 阻止提前退出:未达标时强制继续
-
max-iterations 安全阀:防止无限循环
最简示例(Claude Code):
# 安装插件/plugin install ralph-wiggum@claude-plugins-official# 运行循环/ralph-loop "为当前项目添加单元测试Completion criteria: - Tests passing (coverage > 80%) - Output <promise>COMPLETE</promise>" \--completion-promise "COMPLETE" \--max-iterations 50
场景适用性:详见实践建议-场景适用性。
Ralph Loop 概述
Cloud Native
什么是 Ralph Loop?
Ralph Loop 是一种自主迭代循环机制。你给出一个任务和完成条件后,代理开始执行该任务;当模型在某次迭代中尝试结束时,一个 Stop Hook 会拦截试图退出的动作,并重新注入原始任务提示,从而创建一个自我参照的反馈循环。在这个循环中,模型可以读取上一次迭代改动过的文件、测试结果和 git 历史,并据此逐步修正自己的输出直到达到完成条件或达到设定的迭代上限。
简言之:
-
不是简单的一次性运行,而是持续迭代直到完成任务;
-
循环使用同一个 prompt,但外部状态(代码、测试输出、文件等)在每次迭代后发生改变;
-
需要明确的完成条件(如输出特定关键字、测试通过等)和合理的最大迭代次数作为安全控制。
Ralph 起源
- Ralph Wiggum 名称来自《辛普森一家》的角色,用于象征“反复迭代、不放弃”的精神,但实际实现是一个简单的循环控制机制,并非模型自身拥有特殊认知。
-
核心机制不是模型自行创造循环,而是 Stop Hook(详见 Stop-hook 拦截机制)在模型尝试退出时拦截,并重新注入 prompt,从而在同一会话中形成“自我参照反馈”。
-
迭代不是无条件持续,而是依赖于明确可验证的完成信号或最大迭代次数。否则循环可能永不结束。
- 哲学根源:Ralph 循环可以追溯到软件工程中的“Bash 循环”思维,其核心逻辑是“不断向智能体提供任务,直到任务完成为止”。这种极致的简化体现了将失败视为数据、将持久性置于完美之上的设计哲学。
核心原理
与传统智能体循环的对比
为了深入理解 Ralph Loop 与常规智能体循环的区别,需要首先建立对“智能体”这一概念的通用语义框架。根据当代人工智能实验室的共识,智能体被定义为“在循环中运行工具以实现目标的 LLM 系统”。这种定义强调了三个关键属性:
-
LLM 编排的推理能力:智能体能够根据观察结果进行推理和决策
-
工具集成的迭代能力:智能体可以调用外部工具并基于工具输出调整行为
-
最小化人工监督的自主性:智能体能够在有限指导下自主完成任务
在常规的智能体架构中,循环通常发生在单一会话的上下文窗口内,由 LLM 根据当前观察到的结果决定下一步行动。
ReAct(Reason + Act)模式
ReAct 遵循“观察(Observation)→ 推理(Reasoning)→ 行动(Acting)”的节奏。这种模式的优势在于其动态适应性:当智能体遇到不可预见的工具输出时,它可以在当前的上下文序列中即时修正推理路径。
然而,这种“内部循环”受限于 LLM 的自我评估能力。如果 LLM 在某一步骤产生幻觉,认为任务已经完成并选择退出,系统就会在未达到真实目标的情况下停止运行。
Plan-and-Execute(计划并执行)模式
Plan-and-Execute 将任务分解为静态的子任务序列,由执行器依次完成。虽然这在处理长程任务时比 ReAct 更具结构性,但它对环境变化的适应度较低。如果第三步执行失败,整个计划往往会崩溃,或者需要复杂的重计划机制(Re-planning)。
Ralph 循环的“外部化”范式
Ralph 循环打破了上述依赖 LLM 自我评估的局限性。其实现机制采用停止钩子(Stop Hook)技术:当智能体试图退出当前会话(认为任务完成)时,系统会通过特定的退出代码(如退出码 2)截断退出信号。外部控制脚本会扫描输出结果,如果未发现预定义的“完成承诺”(Completion Promise),系统将重新加载原始提示词并开启新一轮迭代。
这种模式在本质上是强制性的,它不依赖智能体的主观判断,而是依赖外部验证。
对比总结
在开发者语境中,"agent loop" 通常指智能体内部的感知—决策—执行—反馈循环(即典型的感知-推理-行动机制)。而 Ralph Loop 更侧重于迭代执行同一任务直至成功,与典型智能体循环在目的和设计上有所不同:
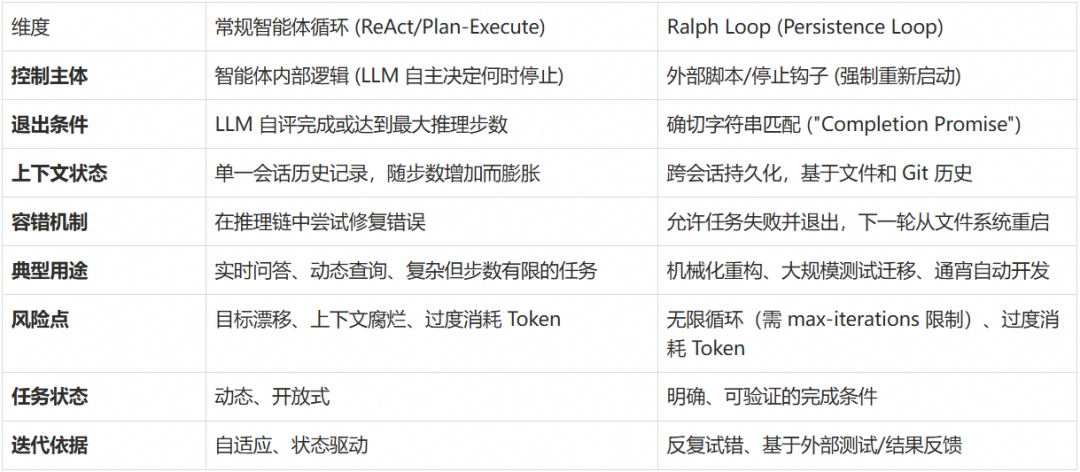
比较结果表明:
-
常规 Agent Loop 通常更通用:用于决策型 agent,可以根据多种状态和输入动态调整下一步操作。ReAct 模式适合需要动态适应的场景,Plan-and-Execute 模式适合结构化任务分解。
-
Ralph Loop 更像是自动驱动的 refine-until-done 模式:重点是让模型在固定任务上不断修正输出直到满足完成条件。它通过外部强制控制避免了 LLM 自我评估的局限性。
因此,它与一般意义上 agent 的循环机制并不矛盾,但定位更专注于可验证任务的持续迭代修正,而非全面的 agent lifecycle 管理。
Stop-hook 拦截机制
Ralph 循环的技术优雅之处在于它如何利用现有的开发工具链(如 Bash、Git、Linter、Test Runner)构建一个闭环反馈系统。在常规循环中,工具的输出仅作为下一步推理的参考;而在 Ralph 循环中,工具的输出成为了决定循环是否存续的“客观事实”。
Ralph 循环的工业实现依赖于对终端交互的深度拦截。通过 hooks/stop-hook.sh 脚本,开发者可以捕获智能体的退出意图。如果智能体没有输出用户指定的承诺标识(如 <promise>COMPLETE</promise>),停止钩子会阻止正常会话结束。
这种机制强迫 LLM 面对这样一个事实:只要没有达到客观的成功标准,它就无法“下班”。这种外部施加的压力通过重复输入相同的提示词(Prompt)来实现,智能体在每一轮迭代中都能看到上一轮留下的改动痕迹和 Git 提交记录。
状态持久化与记忆管理
解决上下文腐烂问题
常规智能体的一个核心痛点是“上下文腐烂(Context Rot)”——随着对话轮次的增加,LLM 对早期指令的注意力和精确度会线性下降。Ralph 循环通过“刷新上下文”解决了这一问题:
-
每一轮循环可以看作是一个全新的会话,智能体不再从臃肿的历史记录中读取状态
-
智能体直接通过文件读取工具扫描当前的项目结构和日志文件
-
这种模式将“状态管理”从 LLM 的内存(Token 序列)转移到了硬盘(文件系统)
由于 Git 历史记录是累积的,智能体可以通过 git log 查看自己之前的尝试路径,从而避免重复同样的错误。这种将环境视为“累积记忆”的做法,是 Ralph 循环能够支持持续数小时甚至数天开发的核心原因。
核心持久化组件
在典型的 Ralph 实现中,智能体会维护以下关键文件:
-
progress.txt:一个追加形式的日志文件,记录了每一轮迭代的尝试、遇到的坑以及已经确认的模式。后续迭代的智能体会首先读取该文件以快速同步进度。
-
prd.json:结构化的任务清单。智能体每完成一个子项,就会在该 JSON 文件中标记
passes: true。这确保了即使循环中断,新的智能体实例也能明确接下来的优先级。 -
Git 提交记录:Ralph 循环被要求在每一步成功后进行提交。这不仅提供了版本回滚能力,更重要的是,它为下一轮迭




















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










