



背景
在前端可观测建设中,资源请求通常是最先被接入的一类数据。对于已经启用了观测云 Browser RUM 的团队来说,页面加载、接口耗时、状态码、错误率等信息往往可以较快建立起来。但在继续深入分析接口行为时,很多团队会遇到同一个问题:资源事件虽然能记录 URL、状态码、耗时等基础信息,却不足以完整还原一次请求的输入上下文。
这种缺口在排查问题时会特别明显。例如,GET 请求的查询参数虽然可以从 URL 中解析出来,但如果是 POST、PUT 或 PATCH 这类带请求体的方法,仅靠 URL 和状态码很难判断接口当时究竟收到了什么输入。即便是相同路径的请求,也可能因为 query、body 或 header 的不同,触发完全不同的业务逻辑。
为什么值得做
对 Browser RUM 的资源事件补充请求参数上下文,通常可以带来以下几项直接收益:
- 在排查接口异常时,能够更快还原用户当时的请求输入场景。
- 对同一路径、不同 query 或 body 触发的差异行为有更清晰的区分依据。
- 为前后端联合定位问题提供更完整的现场信息,而不必完全依赖服务端日志。
- 在调试和验证阶段,可以更准确地确认 SDK 对不同请求类型参数的采集边界。
方案说明
这次实践的核心思路是:不直接改动现有业务接口调用方式,而是在前端项目中增加一组独立的调试请求,并利用 Browser RUM 的 beforeSend(event, context) 钩子补充资源请求的参数上下文。
这里的“请求参数上下文”,不是单指 POST 请求体,而是按请求形态分别覆盖以下几类信息:
- URL 上的 query 参数
- 请求方法
- 请求头
- 请求体
- 请求输入类型
通过这种方式,可以让资源事件从“记录请求发生了什么”进一步走向“记录请求是在什么输入条件下发生的”。
前提条件
在开始之前,需要满足以下条件:
- 前端项目已经接入观测云 Browser RUM。
- 项目能够正常发送资源请求,并且可以区分 fetch 与 XHR 两种调用链路。
- 具备一个独立的调试页面或调试入口,用于触发测试请求。
- 团队已经明确哪些请求字段允许被记录,避免把敏感数据直接写入观测事件。
如果项目当前主要使用的是 axios,需要先明确浏览器侧最终走的是 XHR 还是 fetch。因为对 Browser RUM 来说,不同请求实现方式在 beforeSend 中可读取到的上下文能力并不完全相同,这会直接影响补充参数时的实现路径。
配置步骤
第一步:先把 query 参数作为所有请求的基础上下文补齐
对于资源请求来说,最通用的一层参数上下文是 URL 上的 query。无论请求方法是 GET 还是 POST,只要 URL 上带有查询字符串,都可以统一从资源 URL 中解析出来。
示例逻辑如下:
const url = new URL(event.resource.url, window.location.origin)
const query = Object.fromEntries(url.searchParams.entries())
event.context = {
...event.context,
requestQuery: query
}
这一步的价值在于,它把 query 参数从 URL 文本变成了结构化上下文,便于后续在观测平台中直接查看和筛选。
第二步:针对带请求体的请求补充 body 与 headers
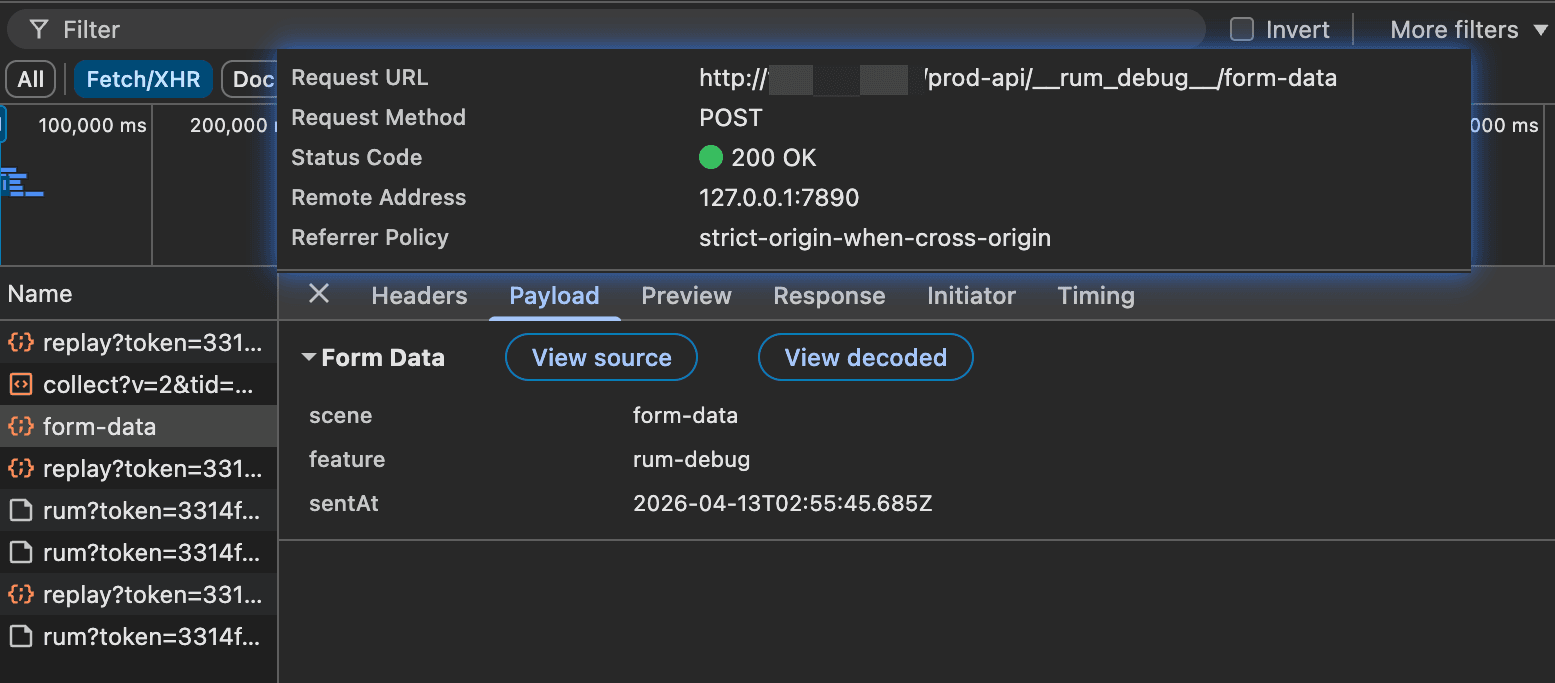
仅有 query 还不够。对于 POST、PUT、PATCH 以及部分 DELETE 请求,更关键的业务输入通常来自 body。因此在 beforeSend 中,还需要进一步从请求上下文中提取方法、请求头和请求体。
这一步的重点不是“所有请求都强行读取 body”,而是根据请求实现方式和上下文可用性,补充真正可读、可序列化的字段。
第三步:在 fetch 场景下读取 requestInit 和 requestInput
在这次实践中,调试请求采用了 fetch。这样做的原因是,fetch 场景下通常可以在 beforeSend 中直接读取 context.requestInit 与 context.requestInput,从而更方便地拿到请求方法、请求头和请求体。
在这一过程中,建议重点关注以下几个字段:
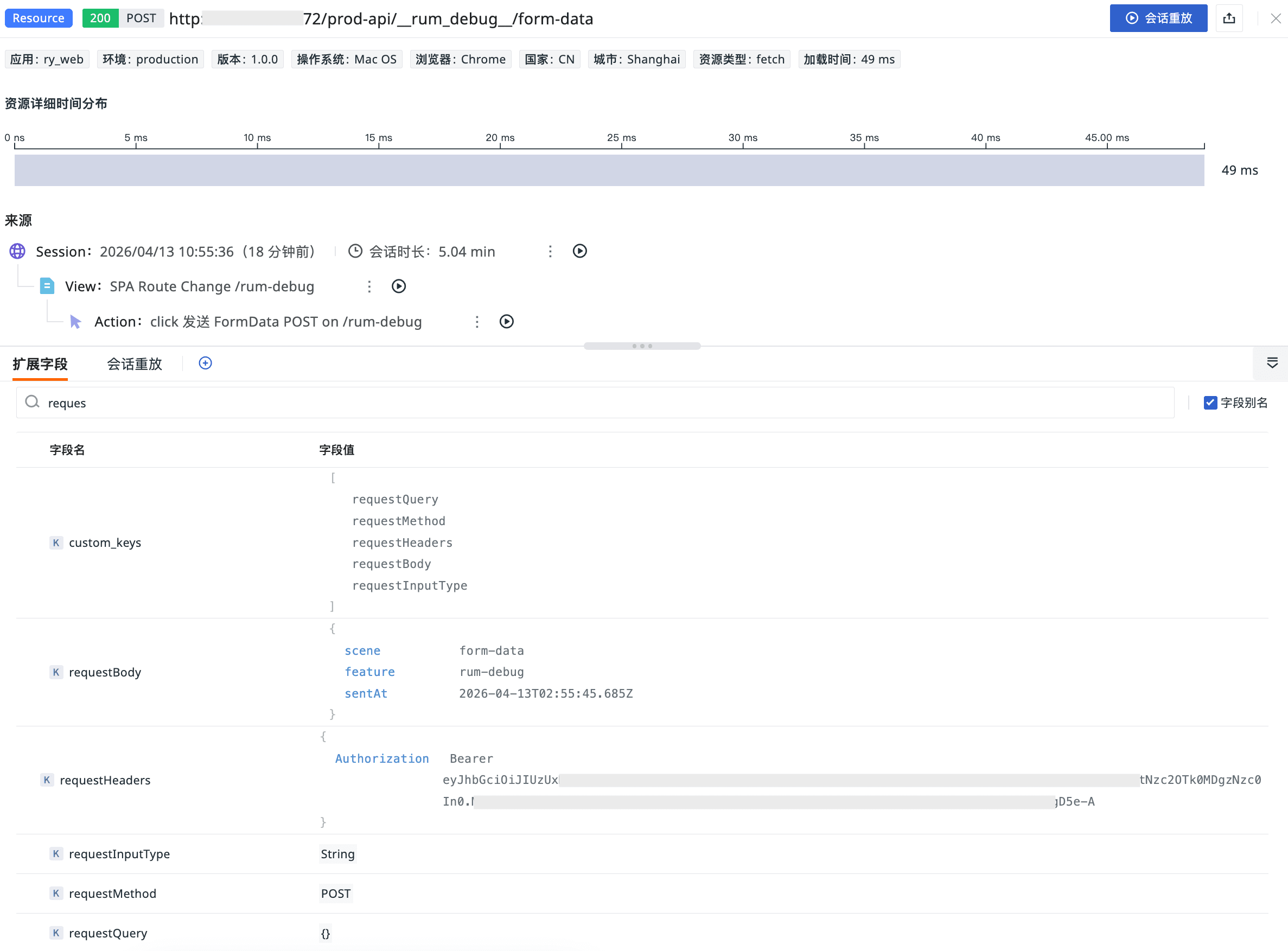
requestInit.method:用于识别请求方法。requestInit.headers:用于获取请求头。requestInit.body:用于读取请求体。requestInput:用于识别请求输入类型。
第四步:对不同参数类型做统一序列化
请求头和请求体并不总是天然可读。实际项目里经常会遇到以下几种情况:
HeadersURLSearchParamsFormData- JSON 字符串
Blob
因此更推荐先做一次统一序列化,再写入 event.context。这样不仅便于在控制台中验证,也便于后续直接在观测云中查看。
示例代码如下:
<script>
function parseBody(body) {
if (body == null) return body
if (typeof body === 'string') {
try {
return JSON.parse(body)
} catch (_) {
return body
}
}
if (body instanceof URLSearchParams) {
return Object.fromEntries(body.entries())
}
if (body instanceof FormData) {
const data = {}
body.forEach((value, key) => {
data[key] = value instanceof File ? '[File]' : value
})
return data
}
return body
}
function parseHeaders(headers) {
if (!headers) return {}
if (headers instanceof Headers) {
return Object.fromEntries(headers.entries())
}
return headers
}
window.DATAFLUX_RUM &&
window.DATAFLUX_RUM.init({
beforeSend(event, context) {
if (event.type !== 'resource' || !event.resource?.url) {
return true
}
const url = new URL(event.resource.url, window.location.origin)
event.context = {
...event.context,
requestQuery: Object.fromEntries(url.searchParams.entries())
}
if (
event.resource.type === 'fetch' &&
url.pathname.startsWith('/__rum_debug__/')
) {
const requestInit = context?.requestInit || {}
event.context = {
...event.context,
requestMethod: requestInit.method || 'GET',
requestHeaders: parseHeaders(requestInit.headers),
requestBody: parseBody(requestInit.body)
}
}
return true
}
})
</script>
第五步:控制补充范围,避免把调试逻辑扩散到所有请求
在实践中,不建议一开始就对全量资源请求写入 headers 和 body。更稳妥的方式是像示例中一样,只对特定调试路径进行补充,例如 /__rum_debug__/。这样既能验证 SDK 行为,也能降低对正式数据的干扰。
当验证完成后,再根据实际需要,把逻辑扩展到指定接口、指定业务域名或指定交互场景。
第六步:为正式场景增加脱敏与裁剪策略
请求参数可见并不意味着请求参数应该被完整记录。对于生产环境,更推荐保留对排障真正有帮助的字段,并对以下内容做处理:
- 密码、Token、身份证、手机号等敏感字段脱敏。
- 大体积请求体截断或摘要化。
- 文件对象只记录占位说明,而不记录实际内容。
效果验证
完成配置后,Browser RUM 中的资源事件不再只停留在 URL、状态码和耗时这类基础信息,而是可以进一步补充请求参数上下文。
对于 GET 请求,可以直接在事件上下文中看到解析后的 requestQuery,从而更方便地确认查询条件是否符合预期。对于带请求体的方法,则可以进一步看到 requestMethod、requestHeaders 以及 requestBody 等补充字段,用来还原接口调用时的实际输入。
这样做的价值在于,即使多个请求命中了同一个接口路径,也能够从上下文字段中快速判断它们是否属于同一种业务场景,而不必只依赖 URL 或服务端日志进行推断。
补充前,资源事件只能看到基础 URL、状态码和耗时信息。
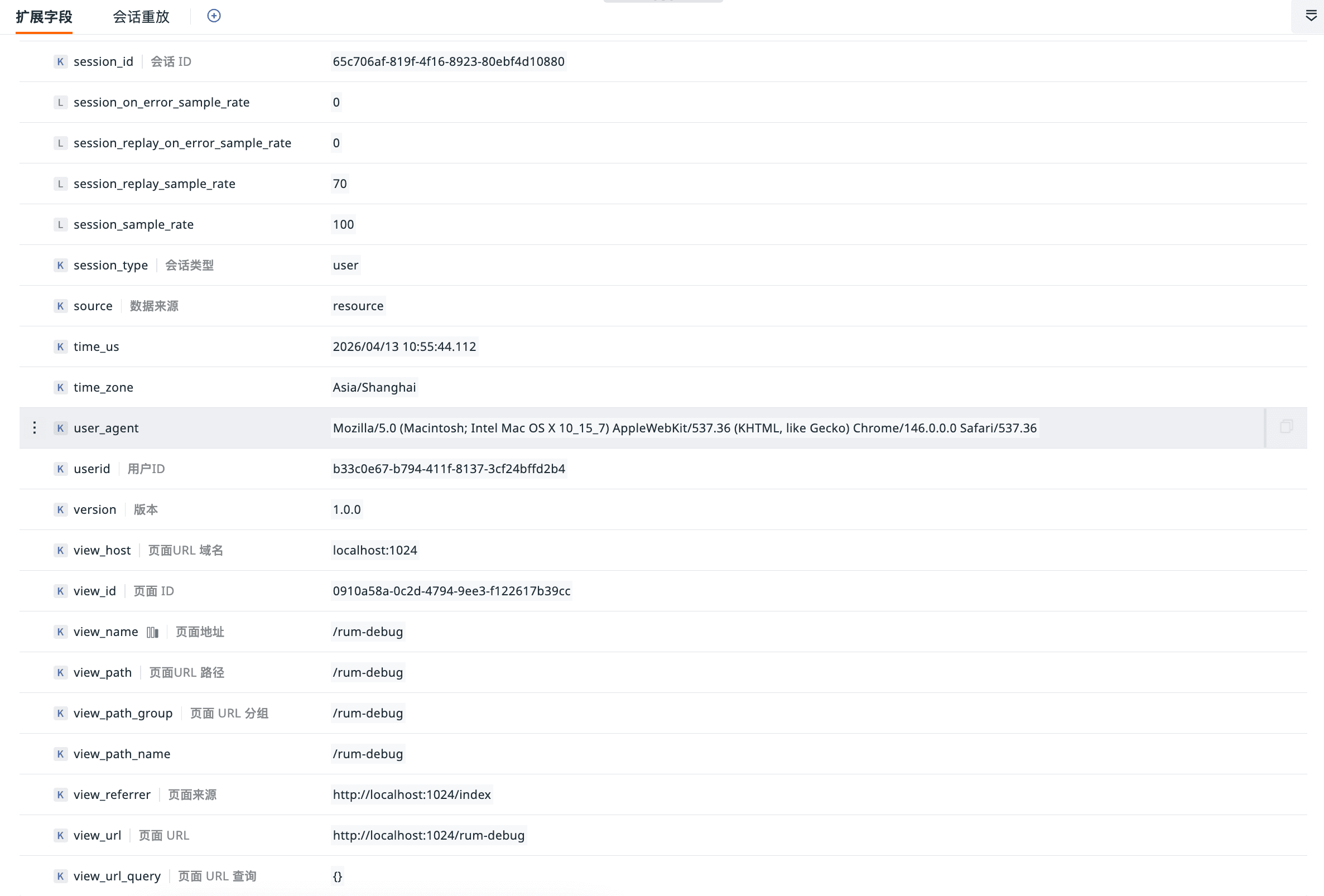
图 2:补充后,资源事件中已经可以直接查看 requestQuery、requestMethod、requestHeaders、requestBody 等上下文字段。
实际请求:
平台展示:
常见问题
1. 为什么 requestQuery 是空对象
如果请求本身没有 query string,例如 URL 只是 /__rum_debug__/json,那么 requestQuery 为空是正常现象。因为 query 参数属于 URL 层信息,而不是 body 层信息。
2. 为什么不能只围绕 POST 来设计方案
因为从可观测角度看,问题的本质不是“POST 请求看不到”,而是“资源事件默认只覆盖了部分请求参数”。GET 请求的 query、POST 请求的 body、甚至自定义 header,都是请求上下文的一部分。最佳实践应该覆盖所有对排障有价值的请求参数,而不是把方案限制在某一种方法上。
3. 为什么 axios 场景下不一定能直接拿到 body
很多前端项目虽然业务代码中使用 axios,但浏览器侧最终走的是 XHR。对于 Browser RUM 来说,fetch 与 XHR 在请求上下文保留能力上并不完全一致,因此在 beforeSend 中直接读取请求体,fetch 场景通常比默认的 XHR 场景更直接。
4. 是否应该对所有资源请求都记录完整请求体
不建议直接全量开启。请求参数中往往包含敏感信息,也可能带来额外的事件体积压力。更适合的方式是先做调试验证,再按接口白名单、字段白名单或环境开关逐步扩展。
总结
这次实践的重点,不只是“让 Browser RUM 看到 POST 请求体”,而是建立一套更完整的前端资源请求参数补充方式。
对于 Browser RUM 来说,URL、query、method、headers 和 body 共同构成了一次请求的输入上下文。通过独立的调试请求、对 requestInit 的序列化处理,以及对补充字段范围的控制,团队就可以更清晰地判断 Browser RUM 能记录什么、适合记录什么,以及应当如何安全地记录。
如果后续要把这套方式用于正式观测场景,建议优先保留最能帮助排障的字段,并配套做好敏感信息脱敏与数据量控制。


















 292
292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










