



如何根据训练出的输电线路缺陷数据集(绝缘子自爆,破损,闪络,鸟巢,防震锤脱落五种缺陷)权重,建立深度学习yolov8输电线缺陷检测系统
文章目录
输电线路数据集(绝缘子自爆,破损,闪络,鸟巢,防震锤脱落五种缺陷)
包括

1.绝缘子自爆
2.绝缘子破损绝、闪络
3.鸟巢
4.防震锤脱落

数据增强后的数量
对应数量:1828,1467,4370,1050,2185

用Lableme标注的,每张图片都会有一个相应的xml文件在旁边,,如何用于深度学习目标检测研究?
输电线路缺陷检测数据集 包含五种常见电力设备缺陷类型,非常适合用于深度学习目标检测研究(如YOLO、Faster R-CNN、SSD等模型)。以下是使用 YOLOv8 模型训练这套数据集的完整流程指南,涵盖从数据准备、预处理、模型训练、评估到部署的全流程。
以下文字及代码仅供参考学习
✅ 一、数据集概述
| 缺陷类别 | 数量 |
|---|---|
| 绝缘子自爆 | 1828 张 |
| 绝缘子破损 | 1467 张 |
| 闪络 | 与“绝缘子破损”共用?请确认是否为独立类别 |
| 鸟巢 | 4370 张 |
| 防震锤脱落 | 2185 张 |
| 总计 | ~10900 张(增强后) |
- 标注格式:Labelme 的 XML文件
- 输出格式需转换为 YOLO 格式
.txt(类别 + 归一化坐标) - 图像格式:JPG 或 PNG
- 可用于:目标检测、工业巡检、无人机图像分析等场景
✅ 二、环境准备
# 创建虚拟环境(可选)
python -m venv powerline_env
source powerline_env/bin/activate # Windows: powerline_env\Scripts\activate
# 安装依赖
pip install ultralytics opencv-python-headless numpy tqdm albumentations labelme
数据集是 XML 格式标注的(LabelImg / VOC 风格)**。
基于 XML 标注文件的数据处理流程 + YOLOv8 的训练方案,包括:
✅ XML 转换为 YOLO 格式 .txt
✅ 数据集划分(train/val/test)
✅ 创建 data.yaml
✅ 使用 YOLOv8 进行模型训练、评估、推理和部署
✅ 一、数据集结构与说明
输电线路缺陷检测数据集使用 XML 格式标注,每张图像都有一个对应的 .xml 文件,格式如下:
<annotation>
<filename>image1.jpg</filename>
<size>
<width>640</width>
<height>480</height>
<depth>3</depth>
</size>
<object>
<name>insulator_burst</name>
<bndbox>
<xmin>100</xmin>
<ymin>200</ymin>
<xmax>150</xmax>
<ymax>250</ymax>
</bndbox>
</object>
</annotation>
📁 推荐目录结构如下:
powerline_dataset/
├── images/
│ ├── image1.jpg
│ └── ...
├── annotations/
│ ├── image1.xml
│ └── ...
✅ 二、XML 转 YOLO TXT 标签脚本
import os
import xml.etree.ElementTree as ET
# 类别映射(请根据你的实际类别顺序填写)
class_mapping = {
'insulator_burst': 0,
'insulator_damage': 1,
'flashover': 2,
'bird_nest': 3,
'damper_fall': 4
}
def convert_xml_to_yolo(xml_file, output_dir, img_dir):
tree = ET.parse(xml_file)
root = tree.getroot()
filename = root.find('filename').text
img_path = os.path.join(img_dir, filename)
if not os.path.exists(img_path):
print(f"Image {img_path} not found. Skipping.")
return
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
label_file = os.path.join(output_dir, os.path.splitext(filename)[0] + '.txt')
with open(label_file, 'w') as out_file:
for obj in root.findall('object'):
cls = obj.find('name').text
if cls not in class_mapping:
continue
cls_id = class_mapping[cls]
xml_box = obj.find('bndbox')
xmin = int(xml_box.find('xmin').text)
ymin = int(xml_box.find('ymin').text)
xmax = int(xml_box.find('xmax').text)
ymax = int(xml_box.find('ymax').text)
# 归一化坐标
xc = (xmin + xmax) / 2 / w
yc = (ymin + ymax) / 2 / h
bw = (xmax - xmin) / w
bh = (ymax - ymin) / h
out_file.write(f"{cls_id} {xc:.6f} {yc:.6f} {bw:.6f} {bh:.6f}\n")
# 批量转换
annotations_dir = "powerline_dataset/annotations"
images_dir = "powerline_dataset/images"
labels_output_dir = "powerline_dataset/labels"
os.makedirs(labels_output_dir, exist_ok=True)
for xml_file in os.listdir(annotations_dir):
if xml_file.endswith('.xml'):
convert_xml_to_yolo(os.path.join(annotations_dir, xml_file), labels_output_dir, images_dir)
✅ 三、划分数据集(train/val/test)
import os
import random
import shutil
# 设置路径
images_dir = "powerline_dataset/images"
labels_dir = "powerline_dataset/labels"
# 创建目录
os.makedirs("dataset/images/train", exist_ok=True)
os.makedirs("dataset/images/val", exist_ok=True)
os.makedirs("dataset/images/test", exist_ok=True)
os.makedirs("dataset/labels/train", exist_ok=True)
os.makedirs("dataset/labels/val", exist_ok=True)
os.makedirs("dataset/labels/test", exist_ok=True)
# 获取所有图片名称
all_images = [f for f in os.listdir(images_dir) if f.endswith(('.jpg', '.jpeg', '.png'))]
random.shuffle(all_images)
# 划分比例
train_ratio = 0.8
val_ratio = 0.15
train_split = int(len(all_images) * train_ratio)
val_split = train_split + int(len(all_images) * val_ratio)
train_files = all_images[:train_split]
val_files = all_images[train_split:val_split]
test_files = all_images[val_split:]
def copy_files(files, src_img, src_lbl, dst_img, dst_lbl):
for file in files:
base_name = os.path.splitext(file)[0]
shutil.copy(os.path.join(src_img, file), os.path.join(dst_img, file))
label_file = base_name + ".txt"
if os.path.exists(os.path.join(src_lbl, label_file)):
shutil.copy(os.path.join(src_lbl, label_file), os.path.join(dst_lbl, label_file))
copy_files(train_files, images_dir, labels_dir, "dataset/images/train", "dataset/labels/train")
copy_files(val_files, images_dir, labels_dir, "dataset/images/val", "dataset/labels/val")
copy_files(test_files, images_dir, labels_dir, "dataset/images/test", "dataset/labels/test")
✅ 四、创建 data.yaml 文件
在项目根目录下创建 data.yaml:
train: ./dataset/images/train
val: ./dataset/images/val
test: ./dataset/images/test
nc: 5 # 总共5个类别
names: ['insulator_burst', 'insulator_damage', 'flashover', 'bird_nest', 'damper_fall']
✅ 五、YOLOv8 模型训练命令
yolo task=detect mode=train model=yolov8s.pt data=data.yaml epochs=100 imgsz=640 batch=16 workers=4
—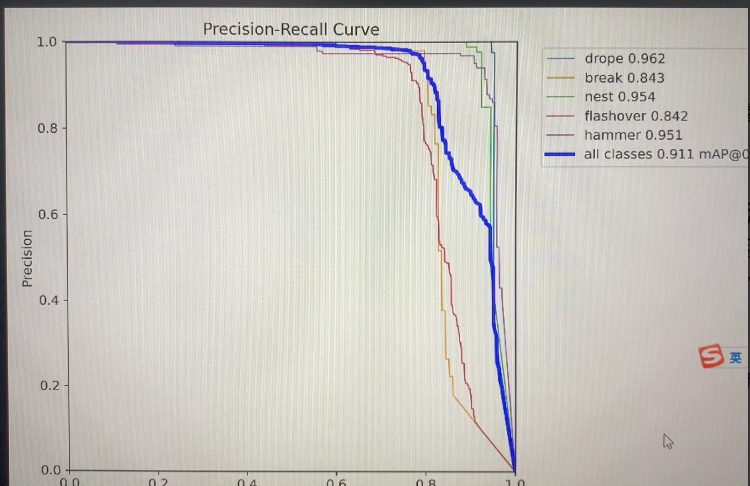
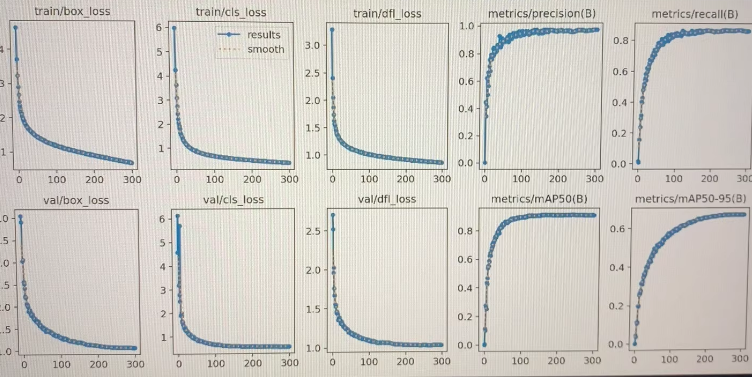
✅ 六、性能评估
yolo task=detect mode=val model=runs/detect/train/weights/best.pt data=data.yaml
✅ 七、推理与部署
# 单图推理
yolo task=detect mode=predict model=best.pt source=path/to/image.jpg save=True
# 视频或摄像头
yolo task=detect mode=predict model=best.pt source=path/to/video.mp4 save=True

✅ 八、模型导出(ONNX / TensorRT / OpenVINO)
# 导出 ONNX
yolo export model=best.pt format=onnx
# 导出 TensorRT(NVIDIA 设备)
yolo export model=best.pt format=engine device=0
# 导出 OpenVINO(Intel 设备)
yolo export model=best.pt format=openvino
基于训练好的权重建立一个深度学习输电线缺陷检测系统涉及多个步骤,
代码示例,仅供参考。
1. 准备工作
确保完成了模型的训练,并保存了最佳权重文件(如 best.pt)。同时,确保你的环境中安装了必要的库:
pip install ultralytics opencv-python-headless numpy tqdm
2. 模型加载与推理
首先,需要加载训练好的模型,并使用它进行图像或视频的推理。
加载模型
from ultralytics import YOLO
# 加载预训练模型
model = YOLO('runs/detect/train/weights/best.pt') # 替换为你的最佳权重路径
单张图片推理
import cv2
def detect_image(image_path):
results = model(image_path) # 进行推理
for r in results:
im_array = r.plot() # 绘制结果
im = Image.fromarray(im_array[..., ::-1]) # 转换颜色通道顺序
im.show() # 显示结果
# 使用示例
detect_image('path/to/image.jpg')
视频或摄像头实时检测
def detect_video(video_path=0): # 默认使用摄像头
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = model(frame)
annotated_frame = results[0].plot()
cv2.imshow("Transmission Line Defect Detection", annotated_frame)
if cv2.waitKey(1) & 0xFF == ord('q'): # 按 q 键退出
break
cap.release()
cv2.destroyAllWindows()
# 使用示例
detect_video() # 使用摄像头
# 或者指定视频路径
# detect_video('path/to/video.mp4')
3. 结果分析与后处理
在得到模型预测结果后,可以根据需要对结果进行进一步分析和处理。例如,计算每个类别的检测数量,或者根据检测结果执行特定操作。
for result in results:
boxes = result.boxes # 获取边界框
for box in boxes:
cls = int(box.cls.item()) # 类别ID
conf = box.conf.item() # 置信度
xyxy = box.xyxy.tolist() # 边界框坐标
print(f"Detected {result.names[cls]} with confidence {conf:.2f} at {xyxy}")
4. 部署
根据的需求选择合适的部署方式。
Web 应用部署
将模型封装成 API,使用 Flask 或 Django 等框架提供服务。
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
file = request.files['image']
img_bytes = file.read()
results = model(img_bytes) # 假设模型支持直接从字节流读取
# 处理结果并返回
return jsonify(results)
if __name__ == '__main__':
app.run(port=5000)
Docker 容器化部署
创建一个 Dockerfile 来打包你的应用程序及其依赖项,便于部署到任何支持 Docker 的环境。
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt
COPY . .
CMD ["python", "app.py"]
然后构建并运行容器:
docker build -t defect-detection .
docker run -p 5000:5000 defect-detection
移动端或边缘设备部署
对于移动端或边缘设备(如 NVIDIA Jetson),你可以将模型导出为 TensorRT、ONNX 或 OpenVINO 格式以获得更好的性能。
yolo export model=best.pt format=engine device=0 # 导出为 TensorRT
5. 系统集成与优化
- 性能优化:考虑使用量化技术减少模型大小,提高推理速度。
- 用户界面:开发一个简单的 GUI 界面(如使用 Tkinter 或 PyQt)使系统更易于使用。
- 持续更新:定期收集新数据并重新训练模型以保持其准确性。
通过以上步骤,建立一个基于深度学习的输电线缺陷检测系统。
仅供参考学习,

















 2358
2358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










