




在前面的章节中,我们深入剖析了跳表(skiplist)的实现原理,并探讨了Redis为何选择跳表而非红黑树作为有序数据结构的核心。跳表以其简洁的实现、优秀的平均性能和良好的缓存局部性,成为Redis的关键基础设施。
但在实际工程中,Redis并非无脑使用跳表——对于小规模数据集,跳表的指针开销反而成为累赘。本文将揭示ZSet如何通过双编码自适应机制,在不同数据规模下自动选择最优存储方式,实现内存与性能的完美平衡。
一、ZSet是什么?
有序集合(Sorted Set,简称 ZSet)是 Redis 最强大的数据结构之一。它同时具备:
- 集合性:元素不重复
- 有序性:每个元素关联一个score,按score排序
- 可查性:按元素查score、按score查范围、按排名查范围
ZADD myzset 1 "one" 2 "two" 3 "three"
ZRANGE myzset 0 -1 → "one" "two" "three"
ZRANGEBYSCORE myzset 1 2 → "one" "two"
ZRANK myzset "three" → 2
ZSCORE myzset "two" → 2
为了同时高效支持这些操作,Redis为ZSet设计了双层编码机制。
二、ZSet的两种编码
2.1 编码常量
// server.h
#define OBJ_ENCODING_ZIPLIST 5 // 压缩列表编码
#define OBJ_ENCODING_SKIPLIST 7 // 跳表编码
2.2 编码选择规则
元素数量 <= 128 且 每个元素长度 <= 64 字节 → ZIPLIST
否则 → SKIPLIST
// server.h:804-807
#define OBJ_ZSET_MAX_ZIPLIST_ENTRIES 128
#define OBJ_ZSET_MAX_ZIPLIST_VALUE 64
这两个阈值可以通过 Redis 配置文件中的 zset-max-ziplist-entries 和 zset-max-ziplist-value 参数进行调整。例如:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
分别控制ziplist编码下ZSet最大元素数量和单个元素最大长度,超过任一阈值就会自动升级为skiplist编码。
2.3 编码转换触发
ZIPLIST → SKIPLIST:
- 元素数量超过 128
- 任意元素长度超过 64 字节
SKIPLIST → ZIPLIST:
- 不会自动转回(即使元素被大量删除)
编码转换在zsetAdd函数中触发,发生在每次添加元素时。
三、ZIPLIST编码
3.1 存储结构
ZIPLIST编码下,ZSet的元素以紧凑的方式存储在一个连续的内存块中:
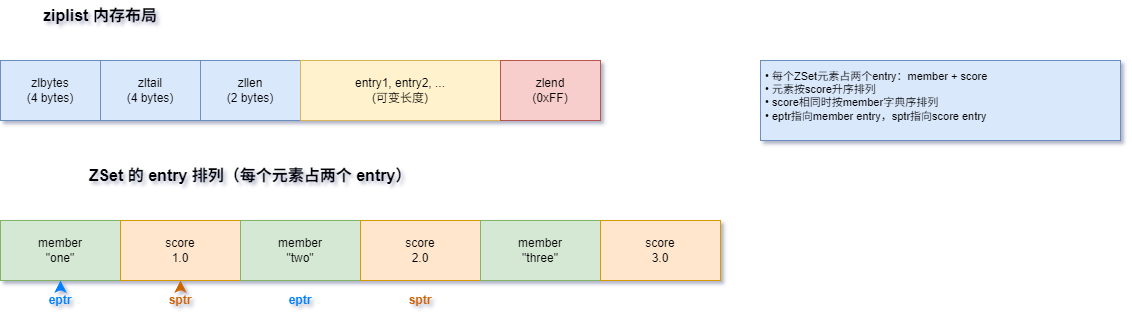
- 每个元素占两个entry:一个存member(字符串),一个存score(浮点数的字符串表示)
- 元素按score从小到大排列
- score相同时按member的字典序排列
3.2 为什么用ziplist?
| 优势 | 说明 |
|---|---|
| 内存紧凑 | 连续内存,无指针开销,每个元素节省16-32字节 |
| 缓存友好 | 连续内存,CPU缓存命中率高 |
| 适合小数据量 | 元素少时遍历开销可忽略,内存优势明显 |
代价是所有操作都是O(n),但n <= 128时,O(n)的实际耗时远小于跳表O(log n)的指针跳转开销。
3.3 ziplist相关API
Redis为ziplist编码封装了一组zzl*函数,与skiplist编码的zsl*函数对称:
// t_zset.c — ziplist 编码操作
// 读取 score
double zzlGetScore(unsigned char *sptr);
// 查找元素
unsigned char *zzlFind(unsigned char *zl, sds ele, double *score);
// 插入元素
unsigned char *zzlInsert(unsigned char *zl, sds ele, double score);
// 删除元素
unsigned char *zzlDelete(unsigned char *zl, unsigned char *eptr);
// 范围删除
unsigned char *zzlDeleteRangeByScore(unsigned char *zl, zrangespec *range, unsigned long *deleted);
unsigned char *zzlDeleteRangeByRank(unsigned char *zl, unsigned int start, unsigned int end, unsigned long *deleted);
// 范围查询
unsigned char *zzlFirstInRange(unsigned char *zl, zrangespec *range);
unsigned char *zzlLastInRange(unsigned char *zl, zrangespec *range);
// 遍历
void zzlNext(unsigned char *zl, unsigned char **eptr, unsigned char **sptr);
void zzlPrev(unsigned char *zl, unsigned char **eptr, unsigned char **sptr);
// 元素数
unsigned int zzlLength(unsigned char *zl); // = ziplistLen(zl) / 2
3.4 zzlFind —— 按元素查找
// t_zset.c:1001-1018
unsigned char *zzlFind(unsigned char *zl, sds ele, double *score) {
// eptr指向当前遍历到的member entry,sptr指向其后面的score entry
unsigned char *eptr = ziplistIndex(zl,0), *sptr;
while (eptr != NULL) {
sptr = ziplistNext(zl,eptr); // sptr指向eptr后面的score entry
serverAssert(sptr != NULL); // 保证score entry存在
// 比较当前member entry内容与目标ele是否相等
if (ziplistCompare(eptr,(unsigned char*)ele,sdslen(ele))) {
// 如果需要,解析score entry并返回
if (score != NULL) *score = zzlGetScore(sptr);
return eptr; // 返回找到的member entry指针
}
// 跳到下一个member entry(即当前score entry的下一个)
eptr = ziplistNext(zl,sptr);
}
// 未找到,返回NULL
return NULL;
}
从头遍历ziplist,逐个比较member。找到后,下一个entry就是score。
3.5 zzlInsert —— 有序插入
// t_zset.c:1056-1087
// 在ziplist中有序插入一个(member, score)对,保持score升序,score相同按member字典序。
unsigned char *zzlInsert(unsigned char *zl, sds ele, double score) {
// eptr指向当前遍历到的member entry,sptr指向其后面的score entry
unsigned char *eptr = ziplistIndex(zl,0), *sptr;
double s;
while (eptr != NULL) {
sptr = ziplistNext(zl,eptr); // sptr指向eptr后面的score entry
serverAssert(sptr != NULL); // 保证score entry存在
s = zzlGetScore(sptr); // 解析当前元素的score
// 如果当前score大于待插入score,找到插入点
if (s > score) {
zl = zzlInsertAt(zl,eptr,ele,score);
break;
} else if (s == score) {
// score相等时,按member字典序插入
if (zzlCompareElements(eptr,(unsigned char*)ele,sdslen(ele)) > 0) {
zl = zzlInsertAt(zl,eptr,ele,score);
break;
}
}
// 继续遍历下一个member entry
eptr = ziplistNext(zl,sptr);
}
// 如果遍历到末尾还未插入,则插入到ziplist尾部
if (eptr == NULL)
zl = zzlInsertAt(zl,NULL,ele,score);
return zl;
}
遍历找到插入位置(score从小到大,score相同时按member字典序),然后调用zzlInsertAt在该位置插入两个entry。
3.6 zzlDelete —— 删除元素
// t_zset.c:1022-1029
unsigned char *zzlDelete(unsigned char *zl, unsigned char *eptr) {
unsigned char *p = eptr;
zl = ziplistDelete(zl,&p); // 删除 member entry
zl = ziplistDelete(zl,&p); // 删除 score entry
return zl;
}
连续调用两次ziplistDelete,删除member和score两个entry。
四、SKIPLIST编码
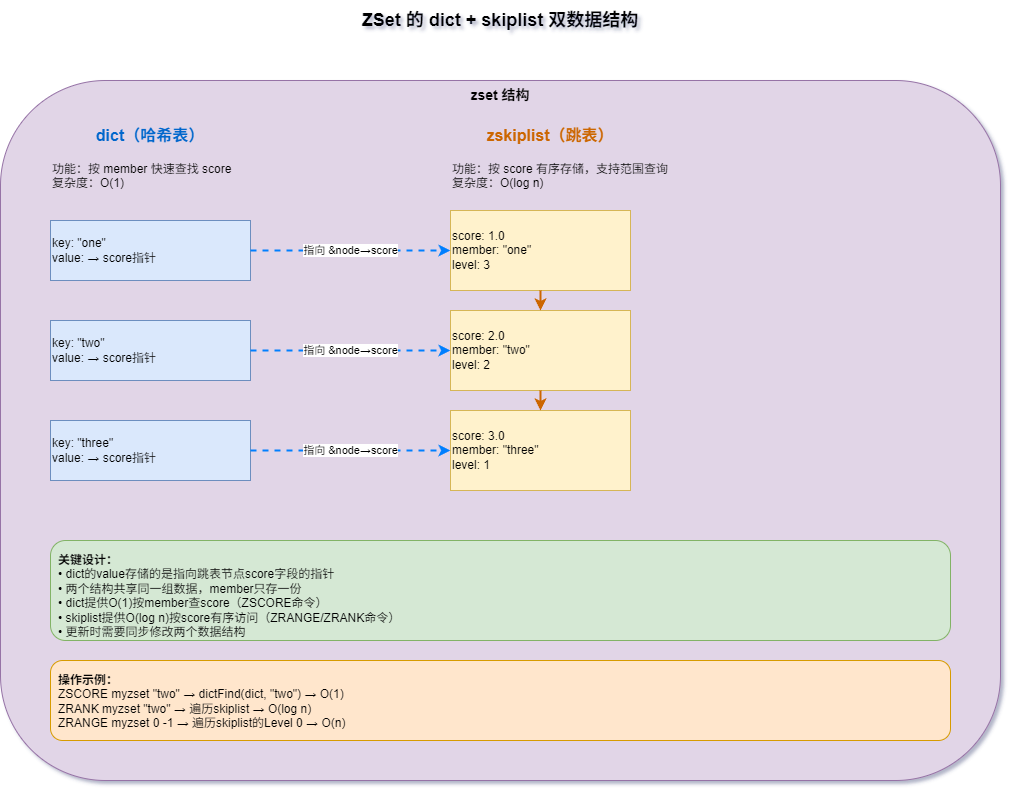
4.1 双数据结构
SKIPLIST编码下,ZSet使用两个数据结构协同工作:
// server.h:818-822
typedef struct zset {
dict *dict; // 哈希表,key为member,value为指向score的指针
zskiplist *zsl; // 跳表,按score有序存储所有元素
} zset;
ZSet的底层结构,包含两种数据结构:
- dict:用于按member快速查找score,支持O(1)的ZSCORE等操作
- zskiplist:用于按score有序存储元素,支持范围查询和有序遍历
两者共享同一组元素,数据只存一份
4.2 为什么需要dict?
跳表只支持按score查找,但ZSCORE命令需要按member查score。如果只用跳表:
ZSCORE myzset "two"
→ 需要遍历整个跳表找 member="two",O(n)
加了dict后:
ZSCORE myzset "two"
→ dictFind(dict, "two"),O(1)
dict和zskiplist共享同一组元素:dict的val指向跳表节点的score,跳表节点的ele就是member的SDS。数据只存一份,两个结构各自提供高效的访问路径。
4.3 操作映射
| 命令 | dict 操作 | zskiplist 操作 |
|---|---|---|
ZADD | dictAdd / dictReplace | zslInsert |
ZREM | dictDelete | zslDelete |
ZSCORE | dictFind | — |
ZRANK | — | zslGetRank |
ZRANGE | — | 遍历 Level 0 |
ZRANGEBYSCORE | — | zslFirstInRange + 遍历 |
ZREVRANGE | — | tail + backward 遍历 |
ZINCRBY | dictFind + 更新 | zslUpdateScore / zslInsert |
ZCARD | — | zsl->length |
ZCOUNT | — | zslFirstInRange + 计数 |
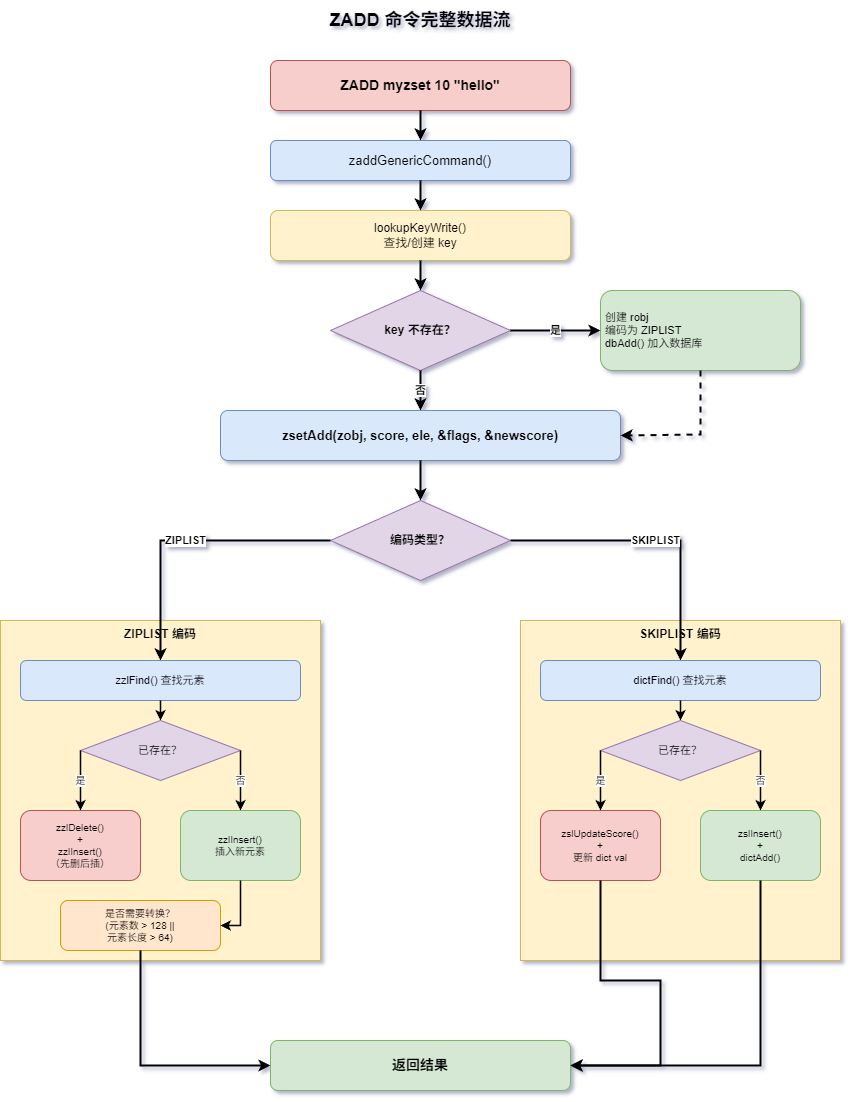
五、zsetAdd —— ZSet的核心写入函数
zsetAdd是所有ZSet写入命令(ZADD、ZINCRBY)的底层实现,它处理了编码判断、编码转换、增删改等所有逻辑。
// t_zset.c:1278-1437
int zsetAdd(robj *zobj, double score, sds ele, int *flags, double *newscore) {
5.1 编码判断与转换
// 如果当前zset对象采用ziplist编码
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *eptr;
// 查找元素是否已存在
if ((eptr = zzlFind(zobj->ptr,ele,NULL)) != NULL) {
// 元素已存在,需更新score(具体逻辑见下文)
...
} else {
// 元素不存在,插入新元素
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
// 检查是否需要转换为skiplist编码:
// 条件1:元素数量超过阈值(128)
if (zzlLength(zobj->ptr) > server.zset_max_ziplist_entries)
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
// 条件2:任意元素长度超过阈值(64字节)
if (sdslen(ele) > server.zset_max_ziplist_value)
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
}
}
转换条件(两个独立条件,满足任一即转换):
- 元素数量超过
zset_max_ziplist_entries(默认128) - 任意元素长度超过
zset_max_ziplist_value(默认64字节)
5.2 ziplist编码下的更新
// 查找元素是否已存在(eptr指向member entry,curscore为当前score)
if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {
// 元素已存在
if (flags & ZADD_INCR) {
// INCR模式,累加score
score += curscore;
if (isnan(score)) { // 检查累加后是否为NaN
*flags = ZADD_NAN;
return 0;
}
if (newscore) *newscore = score; // 返回新score
}
// 只有score发生变化才需要更新
if (score != curscore) {
// ziplist不支持原地修改,需先删后插
zobj->ptr = zzlDelete(zobj->ptr,eptr); // 删除原有元素
zobj->ptr = zzlInsert(zobj->ptr,ele,score); // 插入新score
*flags |= ZADD_UPDATED;
}
}
ziplist不支持原地修改score(因为修改可能改变score的字符串长度,导致ziplist重分配),所以采用先删后插的策略。
5.3 skiplist编码下的更新
} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
zset *zs = zobj->ptr;
zskiplistNode *znode;
dictEntry *de;
// 先在dict中查找元素是否存在
de = dictFind(zs->dict,ele);
if (de != NULL) {
// 元素已存在
double curscore = *(double*)dictGetVal(de); // 当前score
if (flags & ZADD_INCR) {
// INCR模式,累加score
score += curscore;
if (isnan(score)) { // 检查累加后是否为NaN
*flags = ZADD_NAN;
return 0;
}
if (newscore) *newscore = score; // 返回新score
}
// 只有score发生变化才需要更新
if (score != curscore) {
// 跳表支持原地更新score(如位置变化则删除再插入)
znode = zslUpdateScore(zs->zsl,curscore,ele,score); // 更新score
dictGetVal(de) = &znode->score; // dict同步指向新score
*flags |= ZADD_UPDATED;
}
} else {
// 元素不存在,插入新元素
znode = zslInsert(zs->zsl,score,ele); // 跳表插入
dictAdd(zs->dict,ele,&znode->score); // dict同步
if (newscore) *newscore = score;
}
}
dict的val存储的是 &znode->score,即指向跳表节点score字段的地址,这样 ZSCORE 查询时可以 O(1) 直接获取分数,无需额外存储一份数据。当需要更新分数时,通过调用 zslUpdateScore,如果节点位置不变则直接修改分数,否则会先删除再插入新的节点。每次分数变动后,dict的val都会同步更新为新节点的score地址,确保dict和zskiplist始终保持一致。
六、编码转换 —— zsetConvert
// t_zset.c:1170-1215
/*
* zsetConvert: 编码转换函数,将zset对象从ziplist编码转换为skiplist编码
* 只实现ziplist→skiplist的自动转换,反向仅用于特殊场景
*/
void zsetConvert(robj *zobj, int encoding) {
zset *zs;
zskiplistNode *node, *next;
sds ele;
double score;
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *zl = zobj->ptr;
unsigned char *eptr, *sptr;
unsigned char *vstr;
unsigned int vlen;
long long vlong;
// 1. 分配新zset结构(dict+zskiplist)
zs = zmalloc(sizeof(*zs));
zs->dict = dictCreate(&zsetDictType,NULL);
zs->zsl = zslCreate();
// 2. 遍历ziplist,逐对(member, score)迁移到新结构
eptr = ziplistIndex(zl,0);
while (eptr != NULL) {
sptr = ziplistNext(zl,eptr); // sptr指向score entry
serverAssert(sptr != NULL);
serverAssert(ziplistGet(eptr,&vstr,&vlen,&vlong)); // 解析member
if (vstr == NULL)
ele = sdsfromlonglong(vlong); // 数值型member
else
ele = sdsnewlen((char*)vstr,vlen); // 字符串型member
score = zzlGetScore(sptr); // 解析score
node = zslInsert(zs->zsl,score,ele); // 跳表插入
dictAdd(zs->dict,ele,&node->score); // dict同步
eptr = ziplistNext(zl,sptr); // 下一个member entry
}
// 3. 释放旧ziplist,更新zobj指针和编码
zfree(zl);
zobj->ptr = zs;
zobj->encoding = OBJ_ENCODING_SKIPLIST;
} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
// ... 反向转换(用于 DEBUG 等场景)
}
}
转换过程如下:
- 创建
zset结构(dict + zskiplist) - 遍历ziplist的所有member-score对
- 对每个元素,同时插入dict和zslInsert到zskiplist
- 释放旧ziplist
- 更新
zobj->ptr和zobj->encoding
为什么没有自动的SKIPLIST → ZIPLIST回转? 因为元素被大量删除后,ziplist的内存优势不再显著(ziplist的删除需要内存搬移),且频繁的编码转换本身也有开销。Redis选择只在编码升级时转换,不回退。
七、两种编码的性能对比
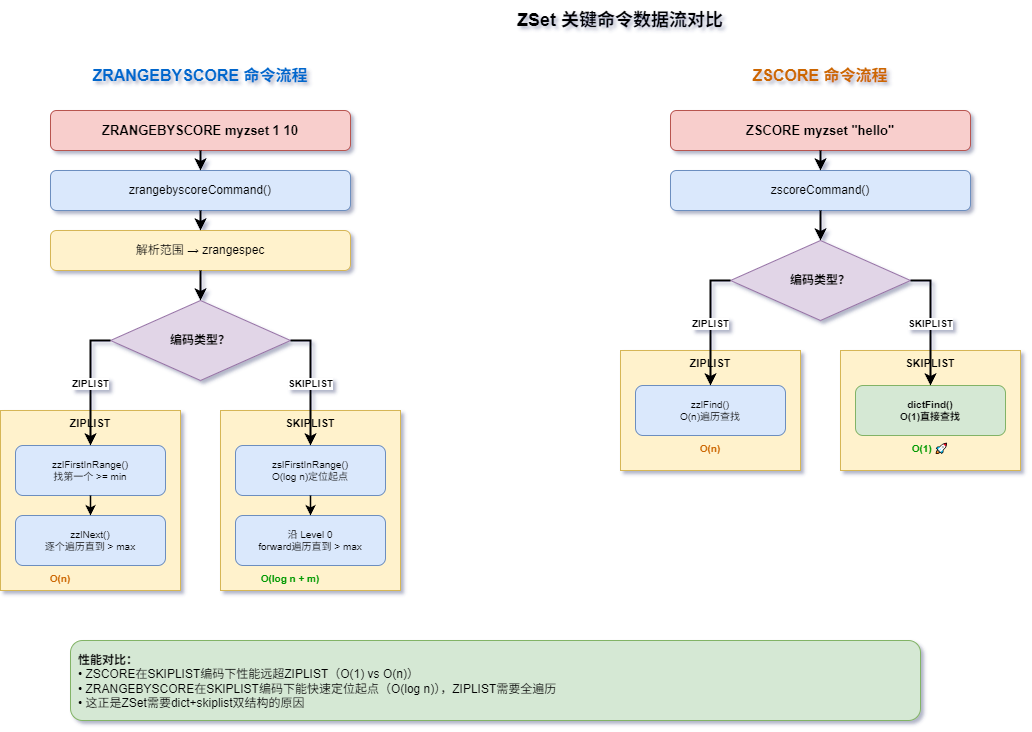
7.1 操作复杂度
| 操作 | ZIPLIST | SKIPLIST |
|---|---|---|
| ZSCORE | O(n) | O(1)(dict) |
| ZADD | O(n) | O(log n) |
| ZREM | O(n) | O(log n) + O(1) |
| ZRANK | O(n) | O(log n) |
| ZRANGE | O(m) | O(log n + m) |
| ZRANGEBYSCORE | O(n) | O(log n + m) |
| ZCARD | O(1) | O(1) |
7.2 实际性能
| 元素数量 | ZIPLIST内存 | SKIPLIST内存 | ZSCORE耗时比 |
|---|---|---|---|
| 10 | ~200B | ~2KB | ZIPLIST 更快 |
| 64 | ~1.5KB | ~12KB | 接近 |
| 128 | ~3KB | ~24KB | SKIPLIST 更快 |
| 10000 | — | ~2MB | SKIPLIST 远快 |
约100个元素时,SKIPLIST的O(log n)开始超过ZIPLIST的O(n)(因为ZIPLIST的O(n)常数极小,缓存友好)。Redis将阈值设为128,偏向内存节省。
7.3 内存对比
每个元素的内存开销:
| 编码 | 每元素开销 | 总计(128元素) |
|---|---|---|
| ZIPLIST | entry header + member + entry header + score | ~3 KB |
| SKIPLIST | zskiplistNode(约64B) + dictEntry(约32B) + SDS | ~24 KB |
ZIPLIST的内存优势约8倍。对于大量小规模ZSet(如用户标签、排行榜),这种差距在总量上非常可观。
八、ZSet命令的完整数据流
8.1 ZADD命令
8.2 ZRANGEBYSCORE / ZSCORE命令
九、ziplist与skiplist的统一API
Redis通过zsetAdd、zsetDel、zsetGetScore等函数屏蔽了底层编码差异,上层命令无需关心当前使用哪种编码:
// 统一API
int zsetAdd(robj *zobj, double score, sds ele, int *flags, double *newscore);
int zsetDel(robj *zobj, sds ele);
double zsetGetScore(robj *zobj, sds ele);
unsigned long zsetLength(robj *zobj);
long zsetRank(robj *zobj, sds ele, int reverse);
这种设计使得新增命令时只需调用统一API即可,无需关心底层编码细节。
ZSet的底层实现通过自动选择ziplist或skiplist编码、dict与跳表双结构协作、数据共享、单向不可逆转换、统一API封装和可调阈值配置,完美体现了Redis的核心设计原则:在简单中追求极致的效率——小数据时极致节省内存,大数据时保证高效操作,两者无缝切换。
在下一章节中,我们将深入剖析Redis内存紧凑结构的演进历程,从ziplist的经典设计到listpack的终极方案,全面揭示Redis如何在极致节省内存的同时保持合理的性能。这些压缩结构不仅服务于ZSet,更是List、Hash、Stream等多种数据类型的内存优化基石。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










