






一、架构模型
1.分层架构:
TCP/IP协议栈
2.流水线模型:
编译器
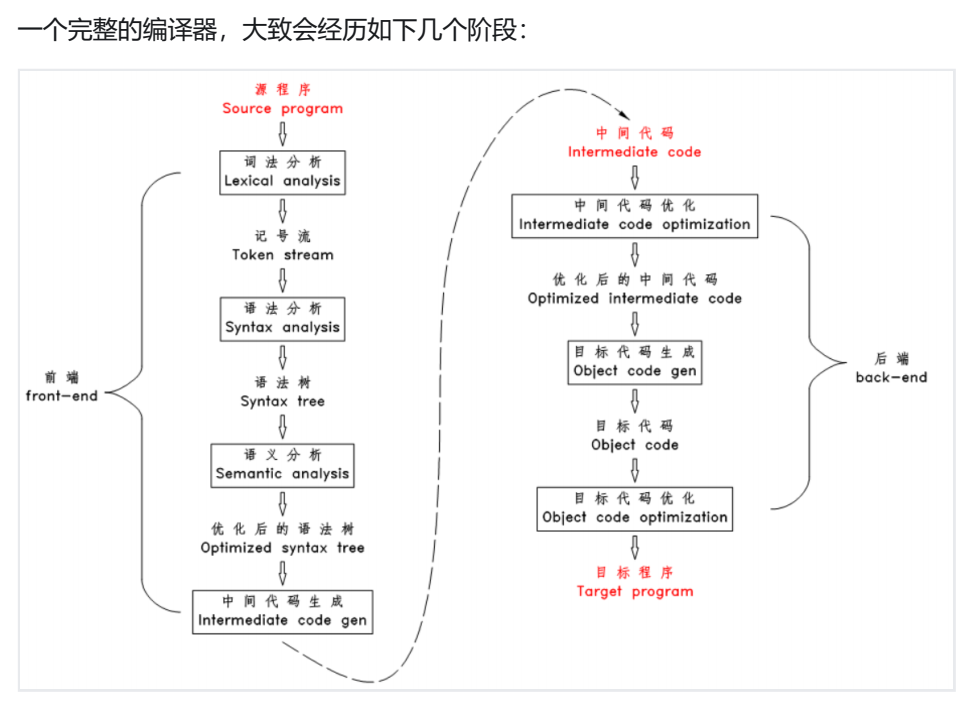
3.各阶段职责
(1)词法分析:对源文件进行扫描,将源文件的字符划分为一个一个的记号(token) (注:类似中文中的分词)。
(2)语法分析:根据语法规则将 Token 序列构造为语法树。
(3)语义分析:结合上下文,推断句子的含义。对语法树的各个结点之间的关系进行检查,检查语义规则是否有被违背,同时对语法树进行必要的优化,此为语义分析。
(4)中间代码生成:遍历语法树的结点,将各结点转化为中间代码,并按特定的顺序拼装起来,此为中间代码生成。
(5)对中间代码进行优化
(6)将中间代码转化为目标代码
(7)对目标代码进行优化,生成最终的目标程序
以上阶段的划分仅仅是逻辑上的划分。实际的编译器中,常常会将几个阶段组合在一起,甚至还可以能省略其中某些阶段。
中间代码:
①Java字节码:每条指令只占一个字节,最多256条,在Java虚拟机上运行。因此Java代码是跨平台的。
②C/C++没有中间代码
二、词法分析
编译器扫描源文件的字符流,过滤掉字符流中的空格、注释等,并将其划分为一个个
的 token,生成 token 序列。
a = value + sum(5, 123);
将被拆分为11个 token :
a 标识符
= 赋值运算符
value 标识符
+ 加号
sum 标识符
( 左括号
5 整数
, 逗号
123 整数
) 右括号
; 分号
1.有限状态机:switch + while + if,做文本分析
①跳过空白字符和注释
②标识符(identifier):字母、数字、下划线的组合,以字母开头
如果以数字开头,编译器就认为进入了数字状态
③数字
④运算符

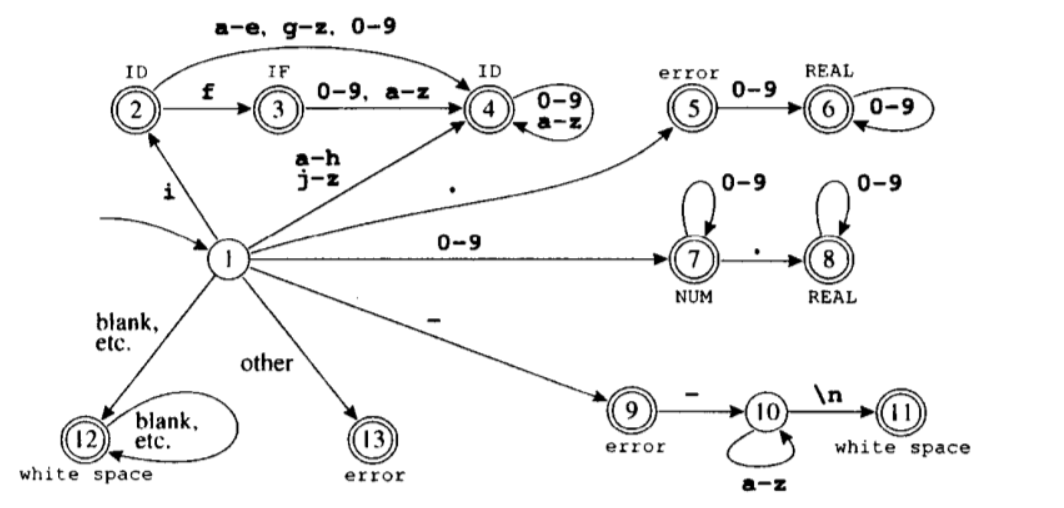
三、实现
1.两种模式
①交互式 ②传文件模式
2.要实现的API
//scanner.c
①static void skipWhitespace √
②static TokenType identifierType √
③static Token number √
④static Token string √
⑤static Token character √
⑥Token scanToken √
//main.c
①static void repl √
②static char* readFile √
3.代码
//scanner.h
// scanner.h
#ifndef scanner_h
#define scanner_h
typedef enum {
// single-character tokens
TOKEN_LEFT_PAREN, TOKEN_RIGHT_PAREN, // '(', ')'
TOKEN_LEFT_BRACKET, TOKEN_RIGHT_BRACKET, // '[', ']'
TOKEN_LEFT_BRACE, TOKEN_RIGHT_BRACE, // '{', '}'
TOKEN_COMMA, TOKEN_DOT, TOKEN_SEMICOLON, // ',', '.', ';'
TOKEN_TILDE, // '~'
TOKEN_COLON, // ':'
TOKEN_ALARM, // '#'
// one or two character tokens
TOKEN_PLUS, TOKEN_PLUS_PLUS, TOKEN_PLUS_EQUAL, // '+', '++', '+='
// '-', '--', '-=', '->'
TOKEN_MINUS, TOKEN_MINUS_MINUS, TOKEN_MINUS_EQUAL, TOKEN_MINUS_GREATER,
TOKEN_STAR, TOKEN_STAR_EQUAL, // '*', '*='
TOKEN_SLASH, TOKEN_SLASH_EQUAL, // '/', '/=',
TOKEN_PERCENT, TOKEN_PERCENT_EQUAL, // '%', '%='
TOKEN_AMPER, TOKEN_AMPER_EQUAL, TOKEN_AMPER_AMPER, // '&', '&=', '&&'
TOKEN_PIPE, TOKEN_PIPE_EQUAL, TOKEN_PIPE_PIPE, // '|', '|=', '||'
TOKEN_HAT, TOKEN_HAT_EQUAL, // '^', '^='
TOKEN_EQUAL, TOKEN_EQUAL_EQUAL, // '=', '=='
TOKEN_BANG, TOKEN_BANG_EQUAL, // '!', '!='
TOKEN_LESS, TOKEN_LESS_EQUAL, TOKEN_LESS_LESS, // '<', '<=', '<<'
TOKEN_GREATER, TOKEN_GREATER_EQUAL, TOKEN_GREATER_GREATER, // '>', '>=', '>>'
// 附加题:'>>=', '<<='
// 字面值: 标识符, 字符, 字符串, 数字
TOKEN_IDENTIFIER, TOKEN_CHARACTER, TOKEN_STRING, TOKEN_NUMBER,
// 关键字
TOKEN_SIGNED, TOKEN_UNSIGNED,
TOKEN_CHAR, TOKEN_SHORT, TOKEN_INT, TOKEN_LONG,
TOKEN_FLOAT, TOKEN_DOUBLE,
TOKEN_STRUCT, TOKEN_UNION, TOKEN_ENUM, TOKEN_VOID,
TOKEN_IF, TOKEN_ELSE, TOKEN_SWITCH, TOKEN_CASE, TOKEN_DEFAULT,
TOKEN_WHILE, TOKEN_DO, TOKEN_FOR,
TOKEN_BREAK, TOKEN_CONTINUE, TOKEN_RETURN, TOKEN_GOTO,
TOKEN_CONST, TOKEN_SIZEOF, TOKEN_TYPEDEF,
TOKEN_STATIC, //新增关键字
// 辅助Token
TOKEN_ERROR, TOKEN_EOF
} TokenType;
typedef struct {
TokenType type;
const char* start; // start指向source中的字符,source为读入的源代码。
int length; // length表示这个Token的长度
int line; // line表示这个Token在源代码的哪一行, 方便后面的报错
// 附加题:int column;
} Token;
// 对 Scanner 进行初始化
void initScanner(const char* source);
// 调用scanToken(), 返回下一个Token.
Token scanToken();
#endif
//scanner.c
// scanner.c
#include "scanner.h"
#include <stdbool.h>
typedef struct {
const char* start;
const char* current;
int line;
} Scanner;
// 全局变量
Scanner scanner;
void initScanner(const char* source) {
// 初始化scanner
scanner.start = source;
scanner.current = source;
scanner.line = 1;
}
/***************************************************************************************
* 辅助方法 *
***************************************************************************************/
static bool isAlpha(char c) {
return (c >= 'a' && c <= 'z') ||
(c >= 'A' && c <= 'Z') ||
c == '_';
}
static bool isDigit(char c) {
return c >= '0' && c <= '9';
}
static bool isAtEnd() {
return *scanner.current == '\0';
}
static char advance() {
return *scanner.current++;
}
static char peek() {
return *scanner.current;
}
static char peekNext() {
if (isAtEnd()) return '\0';
return *(scanner.current + 1);
}
static bool match(char expected) {
if (isAtEnd()) return false;
if (peek() != expected) return false;
scanner.current++;
return true;
}
// 传入TokenType, 创建对应类型的Token,并返回。
static Token makeToken(TokenType type) {
Token token;
token.type = type;
token.start = scanner.start;
token.length = (int)(scanner.current - scanner.start);
token.line = scanner.line;
return token;
}
// 遇到不能解析的情况时,我们创建一个ERROR Token. 比如:遇到@,$等符号时,比如字符串,字符没有对应的右引号时。
static Token errorToken(const char* message) {
Token token;
token.type = TOKEN_ERROR;
token.start = message;
token.length = (int)strlen(message);
token.line = scanner.line;
return token;
}
static void skipWhitespace() {
while (1) {
char c = peek();
switch (c) {
case '/':
if (peekNext() == '/')
{
while (advance() != '\n');
scanner.line++;
}
break;
case ' ': advance(); break;
case '\r':advance(); break;
case '\t':advance(); break;
case '\n':scanner.line++; advance(); break;
default: scanner.start = scanner.current; return; //while的退出条件
}
}
////1.跳过TOKEN前置的空白字符: ' ', '\r', '\t', '\n'和注释
//while (peek() == ' ' || peek() == '\r' || peek() == '\t' || peek() == '\n') {
// advance();
// //若换行,则打印新的行号
// if (peek() == '\n') {
// scanner.line++;
// }
//}
////2.跳过注释
//// 注释以'//'开头, 一直到行尾
//while(peek() == '/' && peekNext() == '/') {
// while (peek()!= '\n') { //注意移动current指针到下一行的行首
// advance();
// }
// advance();
// scanner.line++;
//}
////3.跳过注释后TOKEN前的空白字符: ' ', '\r', '\t', '\n'和注释
//while (peek() == ' ' || peek() == '\r' || peek() == '\t' || peek() == '\n') {
// advance();
// //若换行,则打印新的行号
// if (peek() == '\n') {
// scanner.line++;
// }
//}
}
// 参数说明:
// start: 从哪个索引位置开始比较
// length: 要比较字符的长度
// rest: 要比较的内容
// type: 如果完全匹配,则说明是type类型的关键字
static TokenType checkKeyword(int start, int length, const char* rest, TokenType type) {
int len = (int)(scanner.current - scanner.start); // TOKEN的长度
// start + length: 关键字的长度
if (start + length == len && memcmp(scanner.start + start, rest, length) == 0) {
return type;
}
return TOKEN_IDENTIFIER;
}
// 判断当前Token到底是标识符还是关键字
static TokenType identifierType() {
// 确定identifier类型主要有两种方式:
// 1. 将所有的关键字放入哈希表中,然后查表确认
// 2. 将所有的关键字放入Trie树中,然后查表确认
// Trie树的方式不管是空间上还是时间上都优于哈希表的方式
int token_len = scanner.current - scanner.start;
// 用switch语句实现Trie树
//此时scanner.current已经移动到单词尾部
//第一个字母
switch (scanner.start[0]) {
case 'b': return checkKeyword(1, 4, "reak", TOKEN_BREAK);
case 'c':
if (token_len == 4) {
//第二个字母
switch (scanner.start[1]) {
case 'a': return checkKeyword(2, 2, "se", TOKEN_CASE);
case 'h': return checkKeyword(2, 2, "ar", TOKEN_CHAR);
}
}
else if (token_len == 8) {
return checkKeyword(1, 7, "ontinue", TOKEN_CONTINUE);
}
else if (token_len== 5) {
return checkKeyword(1, 4, "onst", TOKEN_CONST);
}
else {
break;
}
case 'd':
if (token_len == 6) return checkKeyword(1, 5, "ouble", TOKEN_DOUBLE);
else if (token_len == 7) return checkKeyword(1, 6, "efault", TOKEN_DEFAULT);
else break;
case 'e': //enum else
if (token_len == 4) {
switch (scanner.start[1]) {
case 'n': return checkKeyword(2, 2, "um", TOKEN_ENUM);
case 'l': return checkKeyword(2, 2, "se", TOKEN_ELSE);
}
}
case 'f':
if(token_len == 5) return checkKeyword(1, 4, "loat", TOKEN_FLOAT);
else if(token_len == 3) return checkKeyword(1, 2, "or", TOKEN_FOR);
else break;
case 'g': return checkKeyword(1, 3, "oto", TOKEN_GOTO);
case 'i':
if (token_len == 2) return checkKeyword(1, 1, "f", TOKEN_IF);
else if (token_len == 3) return checkKeyword(1, 2, "nt", TOKEN_INT);
else break;
case 'l': return checkKeyword(1, 3, "ong", TOKEN_LONG);
case 'r': return checkKeyword(1, 5, "eturn", TOKEN_RETURN);
case 's':
if (token_len == 5) {
return checkKeyword(1, 4, "ort", TOKEN_SHORT);
}
else if (token_len == 6) {
//第二个字母
switch (scanner.start[1]) {
case 'i':
//第三个字母
switch (scanner.start[2]) {
case 'g': return checkKeyword(3, 3, "ned", TOKEN_SIGNED);
case 'z': return checkKeyword(3, 3, "eof", TOKEN_SIZEOF);
}
case 't':
//第三个字母
switch (scanner.start[2]) {
case 'r': return checkKeyword(3, 3, "uct", TOKEN_STRUCT);
case 'a': return checkKeyword(3, 3, "tic", TOKEN_STATIC);
}
case 'w': return checkKeyword(2, 4, "itch", TOKEN_SWITCH);
}
}
case 't': return checkKeyword(1, 6, "ypedef", TOKEN_TYPEDEF);
case 'u':
if (token_len == 8) return checkKeyword(1, 7, "nsigned", TOKEN_UNSIGNED);
else if(token_len == 5) return checkKeyword(1, 4,"nion",TOKEN_UNION);
else break;
case 'v': return checkKeyword(1, 3, "oid", TOKEN_VOID);
case 'w': return checkKeyword(1, 4, "hile", TOKEN_WHILE);
}
// 标识符 identifier
return TOKEN_IDENTIFIER;
}
static Token identifier() {
// IDENTIFIER包含: 字母,数字和下划线
while (isAlpha(peek()) || isDigit(peek())) {
advance();
}
// 这样的Token可能是标识符, 也可能是关键字, identifierType()是用来确定Token类型的
return makeToken(identifierType());
}
static Token number() {
// 简单起见,我们将NUMBER的规则定义如下:
// 1. NUMBER可以包含数字和最多一个'.'号
// 2. '.'号前面要有数字
// 3. '.'号后面也要有数字
// 这些都是合法的NUMBER: 123, 3.14
// 这些都是不合法的NUMBER: 123., .14
//跳过所有数字
while (isDigit(peek())) {
advance();
}
//跳过小数点
if (peek() == '.') {
if (isDigit(peekNext())) {
//跳过小数点
advance();
//跳过小数点后所有数字
while (isDigit(peek())) {
advance();
}
}
else {
return errorToken("Number must have digits after the decimal point.\n");
}
}
if(peek() == ' ' || peek() == '\n' || peek() == '\0' || peek()==';') return makeToken(TOKEN_NUMBER);
else return errorToken("Not a number");
}
static Token string() {
// 字符串以"开头,以"结尾,而且不能跨行
//跳过开头的左双引号
advance();
while (1) {
if (peek() != '"' && peek() != '\n' && !isAtEnd()) {
advance();
}
if (peek() == '"') {
advance(); //跳过结束的双引号
return makeToken(TOKEN_STRING);
}
if (peek() == '\n') return errorToken("string must be in one line.");
}
}
static Token character() {
// 字符'开头,以'结尾,而且不能跨行
//跳过开头的左单引号
advance();
//判断中间是标识符
if (isAlpha(peek()) || isDigit(peek())) {
advance();
}
if (peek() == '\'') {
advance();
return makeToken(TOKEN_CHARACTER);
}else return errorToken("unterminated character.");
}
/***************************************************************************************
* 分词 *
***************************************************************************************/
//扫描token
Token scanToken() {
// 跳过前置空白字符和注释
skipWhitespace();
// 记录下一个Token的起始位置
scanner.start = scanner.current;
if (isAtEnd()) return makeToken(TOKEN_EOF);
char c = advance();
if (isAlpha(c)) return identifier();
if (isDigit(c)) return number();
switch (c) {
//1.单字符TOKEN:single-character tokens
case '(': return makeToken(TOKEN_LEFT_PAREN);
case ')': return makeToken(TOKEN_RIGHT_PAREN);
case '[': return makeToken(TOKEN_LEFT_BRACKET);
case ']': return makeToken(TOKEN_RIGHT_BRACKET);
case '{': return makeToken(TOKEN_LEFT_BRACE);
case '}': return makeToken(TOKEN_RIGHT_BRACE);
case ',': return makeToken(TOKEN_COMMA);
case '.': return makeToken(TOKEN_DOT);
case ';': return makeToken(TOKEN_SEMICOLON);
case '~': return makeToken(TOKEN_TILDE);
case ':': return makeToken(TOKEN_COLON);
case '#': return makeToken(TOKEN_ALARM);
//2.单字符或双字符TOKEN:one or two characters tokens
case '+':
if (match('+')) return makeToken(TOKEN_PLUS_PLUS);
else if (match('=')) return makeToken(TOKEN_PLUS_EQUAL);
else return makeToken(TOKEN_PLUS);
case '*':
if (match('=')) return makeToken(TOKEN_STAR_EQUAL);
else return makeToken(TOKEN_STAR);
case '/':
if (match('=')) return makeToken(TOKEN_SLASH_EQUAL);
else return makeToken(TOKEN_SLASH);
case '%':
if (match('=')) return makeToken(TOKEN_PERCENT_EQUAL);
else return makeToken(TOKEN_PERCENT);
case '&':
if (match('=')) return makeToken(TOKEN_AMPER_EQUAL);
else if (match('&')) return makeToken(TOKEN_AMPER_AMPER);
else return makeToken(TOKEN_AMPER);
case '|':
if (match('=')) return makeToken(TOKEN_PIPE_EQUAL);
else if (match('|')) return makeToken(TOKEN_PIPE_PIPE);
else return makeToken(TOKEN_PIPE);
case '^':
if (match('=')) return makeToken(TOKEN_HAT_EQUAL);
else return makeToken(TOKEN_HAT);
case '=':
if (match('=')) return makeToken(TOKEN_EQUAL_EQUAL);
else return makeToken(TOKEN_EQUAL);
case '!':
if (match('=')) return makeToken(TOKEN_BANG_EQUAL);
else return makeToken(TOKEN_BANG);
case '<':
if (match('=')) return makeToken(TOKEN_LESS_EQUAL);
else if (match('<')) return makeToken(TOKEN_LESS_LESS);
else return makeToken(TOKEN_LESS);
case '>':
if (match('=')) return makeToken(TOKEN_GREATER_EQUAL);
else if (match('>')) return makeToken(TOKEN_GREATER_GREATER);
else return makeToken(TOKEN_GREATER);
//3.多字符TOKEN:various-character tokens
case '"': return string();
case '\'': return character();
}
//4.其他字符:非法字符
return errorToken("Unexpected character.");
}
//main.c
//main.c
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include "scanner.h"
static char* strtoken(Token token) {
switch (token.type) {
// 单字符Token
case TOKEN_LEFT_PAREN: return "(";
case TOKEN_RIGHT_PAREN: return ")";
case TOKEN_LEFT_BRACKET: return "[";
case TOKEN_RIGHT_BRACKET: return "]";
case TOKEN_LEFT_BRACE: return "{";
case TOKEN_RIGHT_BRACE: return "}";
case TOKEN_COMMA: return ",";
case TOKEN_DOT: return ".";
case TOKEN_SEMICOLON: return ";";
case TOKEN_TILDE: return "~";
case TOKEN_COLON: return ":";
case TOKEN_ALARM: return "#";
// 一个字符或两个字符的Token
case TOKEN_PLUS: return "+";
case TOKEN_PLUS_PLUS: return "++";
case TOKEN_PLUS_EQUAL: return "+=";
case TOKEN_MINUS: return "-";
case TOKEN_MINUS_MINUS: return "--";
case TOKEN_MINUS_EQUAL: return "-=";
case TOKEN_MINUS_GREATER: return "->";
case TOKEN_STAR: return "*";
case TOKEN_STAR_EQUAL: return "*=";
case TOKEN_SLASH: return "/";
case TOKEN_SLASH_EQUAL: return "/=";
case TOKEN_PERCENT: return "%";
case TOKEN_PERCENT_EQUAL: return "%=";
case TOKEN_AMPER: return "&";
case TOKEN_AMPER_EQUAL: return "&=";
case TOKEN_AMPER_AMPER: return "&&";
case TOKEN_PIPE: return "|";
case TOKEN_PIPE_EQUAL: return "|=";
case TOKEN_PIPE_PIPE: return "||";
case TOKEN_HAT: return "^";
case TOKEN_HAT_EQUAL: return "^=";
case TOKEN_EQUAL: return "=";
case TOKEN_EQUAL_EQUAL: return "==";
case TOKEN_BANG: return "!";
case TOKEN_BANG_EQUAL: return "!=";
case TOKEN_LESS: return "<";
case TOKEN_LESS_EQUAL: return "<=";
case TOKEN_LESS_LESS: return "<<";
case TOKEN_GREATER: return ">";
case TOKEN_GREATER_EQUAL: return ">=";
case TOKEN_GREATER_GREATER: return ">>";
// 字面值: 标识符, 字符, 字符串, 数字
case TOKEN_IDENTIFIER: return "IDENTIFIER";
case TOKEN_CHARACTER: return "CHARACTER";
case TOKEN_STRING: return "STRING";
case TOKEN_NUMBER: return "NUMBER";
// 关键字
case TOKEN_SIGNED: return "SIGNED";
case TOKEN_UNSIGNED: return "UNSIGNED";
case TOKEN_CHAR: return "CHAR";
case TOKEN_SHORT: return "SHORT";
case TOKEN_INT: return "INT";
case TOKEN_LONG: return "LONG";
case TOKEN_FLOAT: return "FLOAT";
case TOKEN_DOUBLE: return "DOUBLE";
case TOKEN_STRUCT: return "STRUCT";
case TOKEN_UNION: return "UNION";
case TOKEN_ENUM: return "ENUM";
case TOKEN_VOID: return "VOID";
case TOKEN_IF: return "IF";
case TOKEN_ELSE: return "ELSE";
case TOKEN_SWITCH: return "SWITCH";
case TOKEN_CASE: return "CASE";
case TOKEN_DEFAULT: return "DEFAULT";
case TOKEN_WHILE: return "WHILE";
case TOKEN_DO: return "DO";
case TOKEN_FOR: return "FOR";
case TOKEN_BREAK: return "BREAK";
case TOKEN_CONTINUE: return "CONTINUE";
case TOKEN_RETURN: return "RETURN";
case TOKEN_GOTO: return "GOTO";
case TOKEN_CONST: return "CONST";
case TOKEN_SIZEOF: return "SIZEOF";
case TOKEN_TYPEDEF: return "TYPEDEF";
case TOKEN_STATIC: return "STATIC";
// 辅助Token
case TOKEN_ERROR: return "ERROR";
case TOKEN_EOF: return "EOF";
}
}
static void run(const char* source) {
initScanner(source);
int line = -1;
// 打印Token, 遇到TOKEN_EOF为止
for (;;) {
Token token = scanToken();
if (token.line != line) {
printf("%4d ", token.line);
line = token.line;
}
else {
printf(" | ");
}
printf("%6s '%.*s'\n", strtoken(token), token.length, token.start); //token.length传递给*
if (token.type == TOKEN_EOF) break;
}
}
static void repl() {
// 与用户交互,用户每输入一行代码,分析一行代码,并将结果输出
// repl是"read evaluate print loop"的缩写
while (1) {
char str[1024] = { 0 };
//scanf("%s", str);
//getchar();
fgets(str,1024, stdin);
run(str);
}
}
static char* readFile(const char* path) {
// 用户输入文件名,将整个文件的内容读入内存,并在末尾添加'\0'
// 注意: 这里应该使用动态内存分配,因此应该事先确定文件的大小。
//1.打开文件
FILE* stream = fopen(path, "r");
if (stream == NULL) {
fprintf(stderr, "Open %s failed\n", path);
exit(1);
}
//2.确定文件大小
fseek(stream, 0, SEEK_END);
long n = ftell(stream);
char* content = malloc((n + 1) * sizeof(char)); // 1 for '\0'
//3.读取文件
rewind(stream); //回到文件开头
int bytes = fread(content, 1, n, stream);
content[bytes] = '\0';
//4.关闭文件
fclose(stream);
return content;
}
static void runFile(const char* path) {
// 处理'.c'文件:用户输入文件名,分析整个文件,并将结果输出
char* source = readFile(path);
run(source); // 调用 initScanner 和 scanToken词法分析
free(source);
}
int main(int argc, const char* argv[]) {
if (argc == 1) {
// ./scanner 没有参数,则进入交互式界面
repl();
}
else if (argc == 2) {
// ./scanner file 后面跟一个参数,则分析整个文件
runFile(argv[1]);
}
else {
fprintf(stderr, "Usage: scanner [path]\n");
exit(1);
}
return 0;
}
四、参考文章
C++57期:https://blog.csdn.net/ilovexuanbao/article/details/138112193?spm=1001.2014.3001.5502




















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












