




文章目录
- 一、看论文
- 二、用AutoDL算力平台配置环境
- 三、关于AutoDL的一些坑和操作
- 四、部署环境
- 五、复现实验
- 六、保存AutoDL镜像
一、看论文
1.粗读论文
把论文发给AI大模型,让其给你总结概况一下这篇论文在做什么。

2.精读论文
可以先跑起来实验,回头再精度论文
3.有论文的github仓库
举例,复现一篇用3DGS作为渲染模拟训练环境的具身智能论文,需要用到NVIDIA的 Iscca-sim 和 Iscca-Lab
3DGS结合仿真器,代码仓库:https://github.com/zst1406217/VR-Robo
如果没提供代码,over,不用复现了。
二、用AutoDL算力平台配置环境
1.AutoDL租服务器
1.AutoDL网址:https://www.autodl.com/market/list
2.充值并租一台服务器,并开机

2.用VSCode远程连接AutoDL
(1)安装插件:Remote-SSH
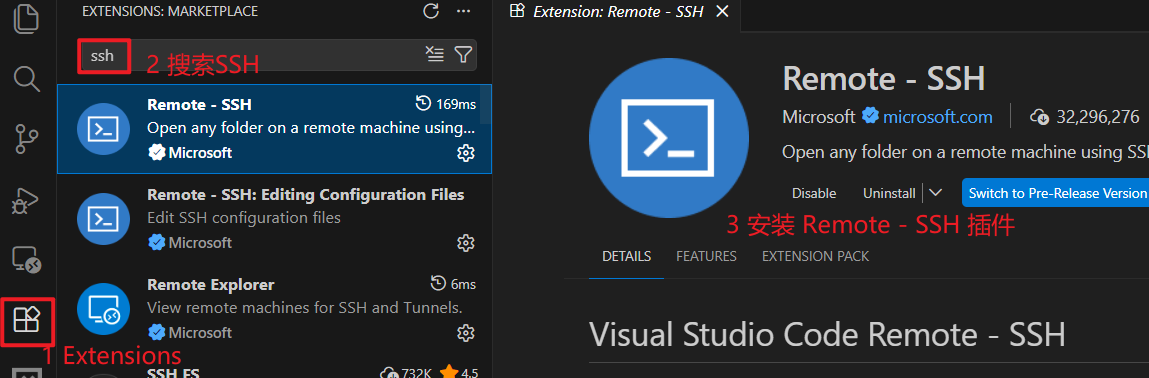
(2)远程连接AutoDL
1.添加ssh配置
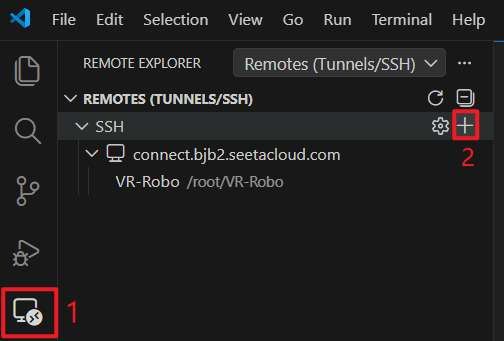
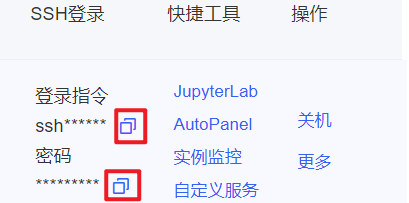
2.输入AutoDL里的登录指令和密码
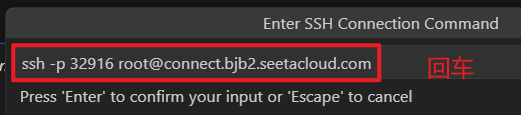
3.直接回车,保存在用户本地的 .ssh\config 目录下

4.点击箭头进行连接
5.复制密码

6.建立端口转发
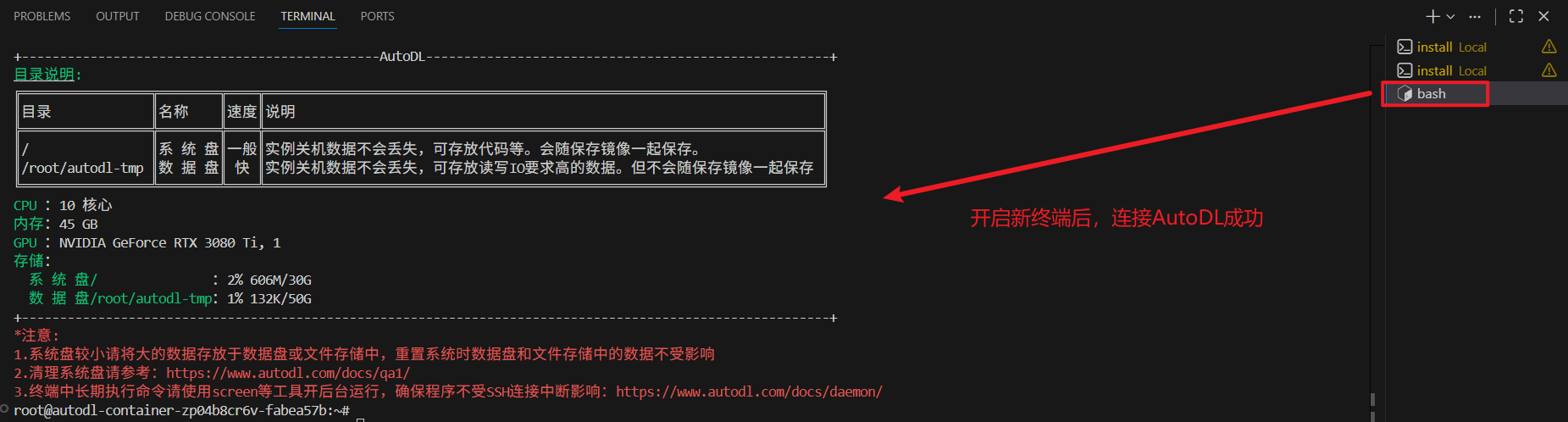
7.开启一个新终端,连接AutoDL成功
三、关于AutoDL的一些坑和操作
1.AutoDL配环境时可选无卡模式,仅¥0.1/小时
在漫长的配置环境的过程中,我们用不到GPU显卡,可以选择无卡模式开机,仅¥0.1/小时。
不然有卡开机,RTX 4090 费用为 ¥2.5/小时。
2.访问github 或者 HuggingFace很慢甚至超时,只有几十KB/s:、清华源、手动用JupyterLab上传
(1)github的国内镜像:ghfast.top
如果是git clone github上的代码仓库,可使用国内的github镜像访问github:ghfast.top
AutoDL学术加速:https://www.autodl.com/docs/network_turbo/
(2)pip/conda/apt 的包的国内镜像:清华源
如果是安装依赖,可以考虑国内清华源是否有对应的镜像:
清华源:https://blog.csdn.net/Edward1027/article/details/158284843
(3)Hugging Face Hub的模型权重文件的国内镜像:https://hf-mirror.com
export HF_HOME=/root/autodl-tmp/hf_home
export HUGGINGFACE_HUB_CACHE=$HF_HOME/hub
export HF_ENDPOINT=https://hf-mirror.com
(4)都不行的最终绝招:本地手动下载后,用JupyterLab手动上传
git clone 有时会遇到 ssh 和 https 都连接不顺利的情况,同一条命令大多数情况下无法连接,偶尔能连上,网络还只有 60KB/s。但是就算这样,下着下着也会因为网速过慢,被掐断网络连接。
所以只能在github手动download到电脑本地,然后用JupyterLab手动将本地的内容上传到AutoDL租赁的服务器平台里。
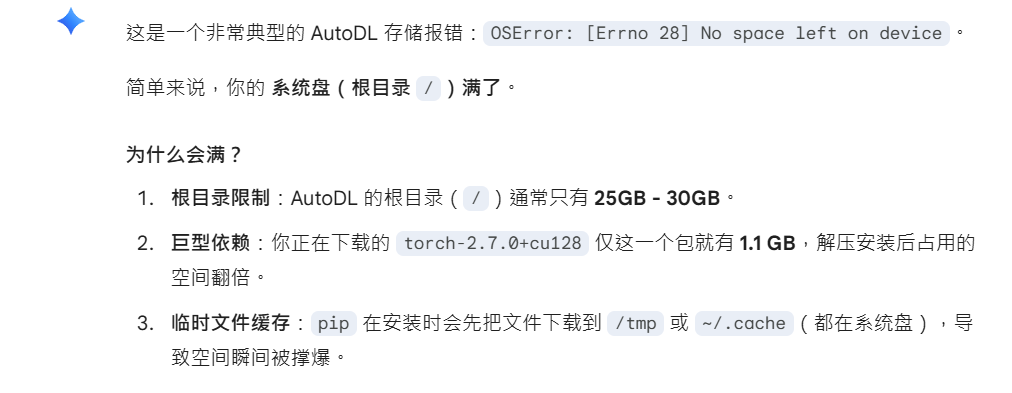
3.系统盘容易爆满:要转移到数据盘 /root/autodl-tmp
0.AutoDL官方帮助文档:
清理系统盘:https://www.autodl.com/docs/qa1/
(1)AutoDL的系统盘和数据盘的区别
| 名称 | 目录 | 速度 | 说明 |
|---|---|---|---|
| 系统盘 | / | 一般 | 实例关机,数据不会丢失,可存放代码等。 系统盘数据会随镜像一起保存 |
| 数据盘 | /root/autodl-tmp | 快 | 实例关机,数据不会丢失,可存放读写IO要求高的数据。 数据盘数据不会随镜像一起保存 |

(2)在AutoDL上的生存法则
除了Linux系统本身和运行时需要用到的核心指令,剩下的所有东西(Conda 环境、数据集、IsaacLab 源码、训练出的模型)通通都要住在数据盘 (/root/autodl-tmp) 里。
(3)从一开始就让conda环境的依赖下载到数据盘(/root/autodl-tmp)中
mkdir -p /root/autodl-tmp/conda_envs
conda config --add envs_dirs /root/autodl-tmp/conda_envs
mkdir -p /root/autodl-tmp/conda_pkgs
conda config --add pkgs_dirs /root/autodl-tmp/conda_pkgs
检查:
conda config --show envs_dirs
conda config --show pkgs_dirs
(4)将之前建在系统盘的conda环境目录移动到数据盘

#1.移动conda环境vr-robo-isaaclab
mv /root/miniconda3/envs/vr-robo-isaaclab /root/autodl-tmp/conda_envs/
#2.创建软链接,让系统盘的路径指向数据盘的环境
ln -s /root/autodl-tmp/conda_envs/vr-robo-isaaclab /root/miniconda3/envs/vr-robo-isaaclab
#1.移动conda环境vr-robo-renderer
mv /root/miniconda3/envs/vr-robo-renderer /root/autodl-tmp/conda_envs/
#2.创建软链接,让系统盘的路径指向数据盘的环境
ln -s /root/autodl-tmp/conda_envs/vr-robo-renderer /root/miniconda3/envs/vr-robo-renderer
移动了以后,conda环境名从相对路径变成绝对路径了。其他应该没有影响

(5)处理缓存文件
#1.删除缓存文件
rm -rf ~/.cache
#2.创建软链接,将缓存指向数据盘
ln -s /root/autodl-tmp/.cache ~/.cache
#3.验证软链接是否创建成功
cd ~
ll
#4.重新执行 pip 安装命令


(6)报错实例
思路就是清系统盘的缓存,然后把模型文件都搬到数据盘。
不仅仅是数据集和代码要放在数据盘,conda环境的依赖包也要放在数据盘。
(1)依赖放到数据盘:
(2)conda环境也搬到数据盘:
把整个Python环境搬到数据盘。在AutoDL上,这是唯一的治本方法。我们需要把Conda环境整体迁移到空间巨大的 /root/autodl-tmp。

①步骤1:清理残留,腾出呼吸空间
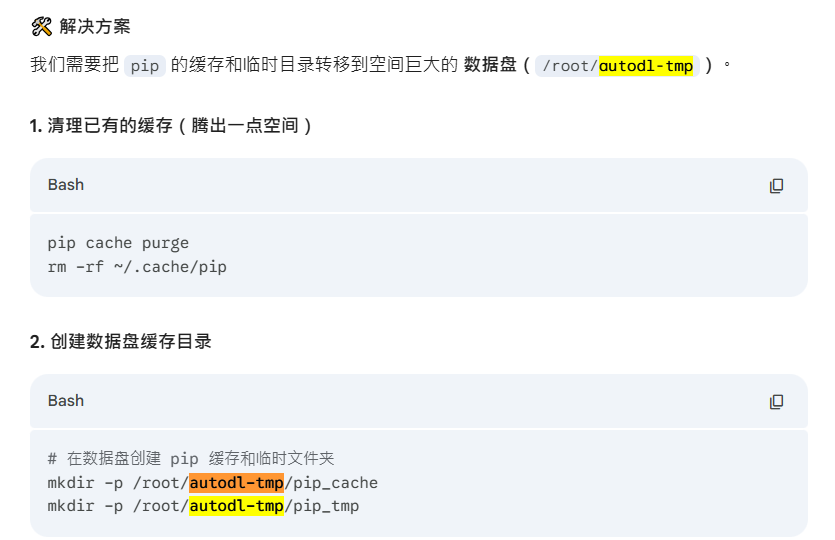
先删掉之前报错留下的半截子文件:
# 清理 pip 缓存
pip cache purge
# 删除临时目录里的垃圾
rm -rf /root/autodl-tmp/pip_tmp/*
②步骤2:搬迁 Conda 环境
我们将现有的环境克隆到数据盘。
# 1. 在数据盘创建一个放环境的目录
mkdir -p /root/autodl-tmp/conda_envs
# 2. 将当前的 vr-robo-isaaclab 环境克隆到数据盘(这可能需要几分钟)
# 这里的 --prefix 指定了新环境的物理位置
conda create --prefix /root/autodl-tmp/conda_envs/vr-robo-new --clone vr-robo-isaaclab
③步骤3:激活新环境并删除旧环境
# 激活新路径下的环境
conda activate /root/autodl-tmp/conda_envs/vr-robo-new
# 删除原本在系统盘(/root/miniconda3/...)下的旧环境,释放系统盘空间
conda remove -n vr-robo-isaaclab --all -y
④步骤4:重新运行安装
现在你的 Python 运行环境已经在大仓库(数据盘)里了,系统盘再也不会因为装库而爆满了:
cd ~/VR-Robo/IsaacLab
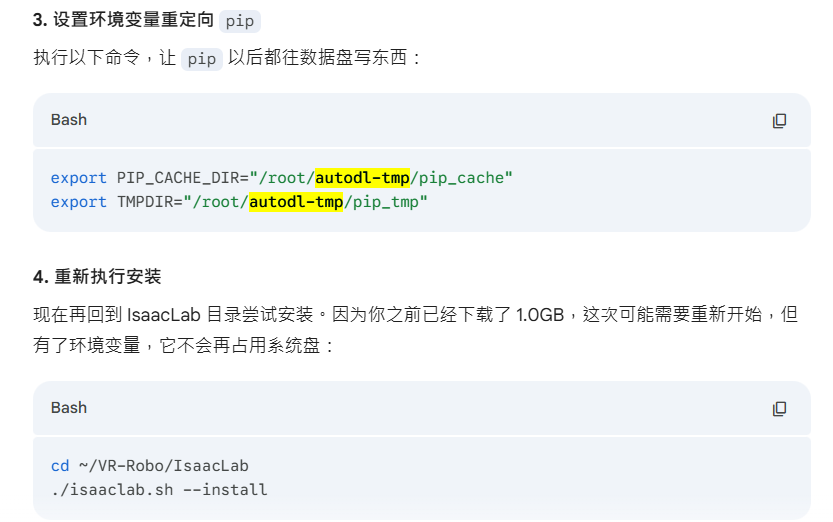
# 别忘了再次确认环境变量(虽然之前写入了.bashrc,但保险起见执行一下)
export PIP_CACHE_DIR="/root/autodl-tmp/pip_cache"
export TMPDIR="/root/autodl-tmp/pip_tmp"
./isaaclab.sh --install
⑤清理完conda环境后,系统盘占用比例从87%下降到27%

4.需要GPU卡,但是只能无卡开机,该机器所有GPU卡已被别人占用:克隆实例到另一台机器
当需要含GPU卡开机时,发现这个服务器的GPU卡都被别人用了。
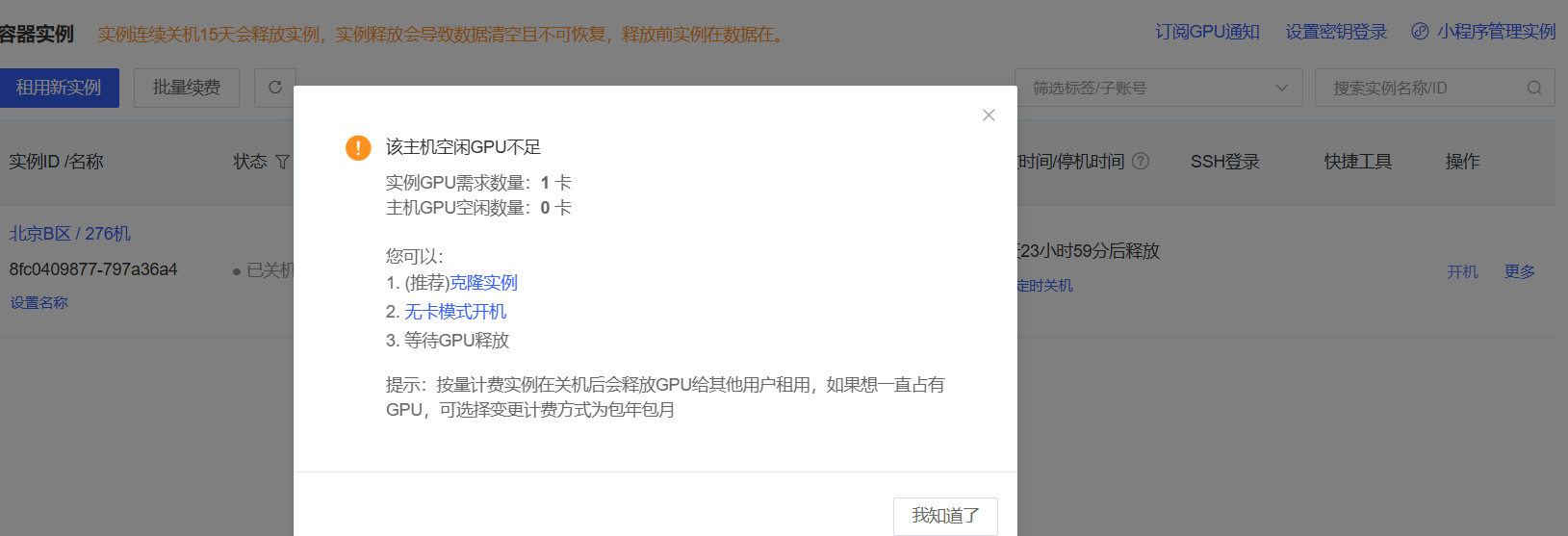
此时推荐克隆实例,换一台机器开机。此时旧机器的实例处于【克隆锁定中】
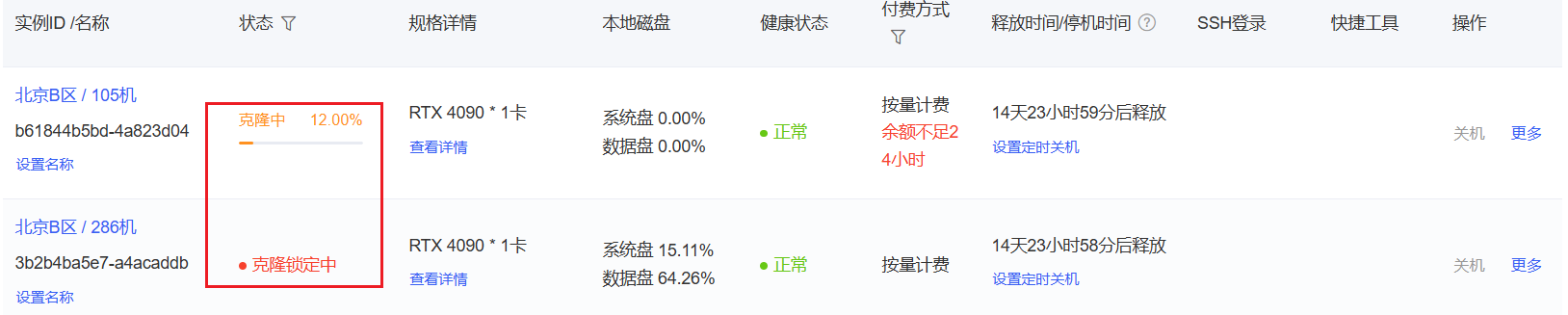

过一会,待旧机器克隆关闭,会自动处于【关机】状态,这时候旧可以【手动释放旧的实例】了

5.去掉pip install安全提示warning
1.现象
pip install 报warning:
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager, possibly rendering your system unusable.It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv . Use the --root-user-action option if you know what you are doing and want to suppress this warning.
2.原因
用的是root用户
3.措施:如何去掉warning提示?
(1)每次pip install 加参数
pip install xxx --root-user-action=ignore
(2)设置环境变量
export PIP_ROOT_USER_ACTION=ignore
6.设置SSH密钥,免密码登录
1.本地生成密钥:
ssh-keygen -t ed25519
回车
回车
回车
2.复制密钥
cat ~/.ssh/id_ed25519.pub
3.添加本地的密钥到AutoDL

添加SSH公钥

4.创建下个实例时ssh公钥生效,可以免密码登录。
7.后期数据盘也满了,怎么办:付费扩容数据盘
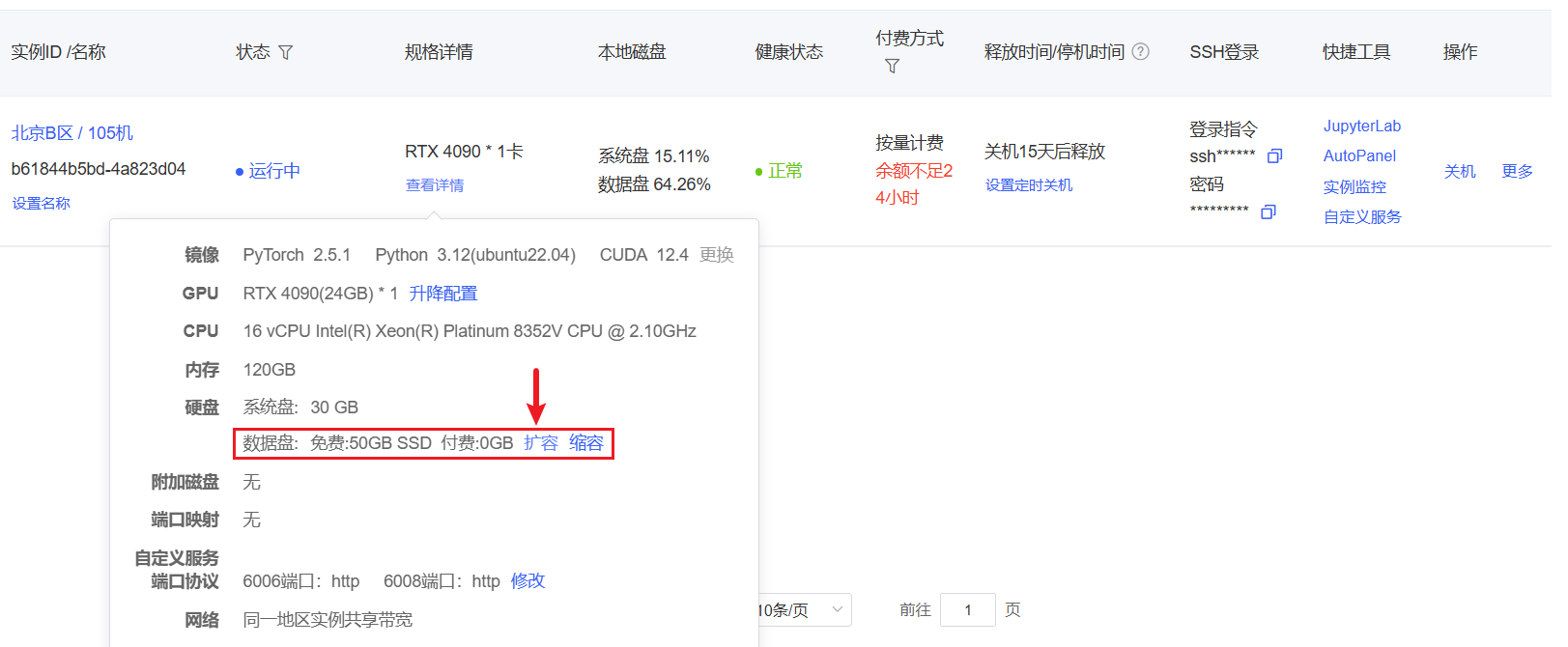
四、部署环境
1.下载论文源码到AutoDL算力平台上:git clone
1.在数据盘里下载:(避免直接使用系统盘导致系统盘满)
cd /root/autodl-tmp/
2.git clone项目:
git clone https://github.com/zst1406217/VR-Robo.git
或者
git clone git@github.com:zst1406217/VR-Robo.git (要配置SSH:将该AutoDL实例的公钥添加到github)
但是正常来说下载github项目,网速只有60KB/s。这时就必须用国内镜像了。
使用AutoDL帮助文档中提到的镜像ghfast:
git clone https://ghfast.top/https://github.com/zst1406217/VR-Robo.git
现在速度就来到了3MB/s,速度提高了50倍。耐心等待下载完成。
现在,论文源码就被我们部署到了我们租的算力服务器上
2.部署虚拟环境、按照README.md下载环境依赖
(1)渲染服务器 (3DGS):vrrobo_renderer
<1>创建并启动conda环境
cd /root/autodl-tmp/VR-RoBo
conda create -n vr-robo-renderer python=3.8 -y
conda activate vr-robo-renderer
使用默认源,也就是 repo.anaconda.com
源的Channels就默认使用Anaconda官方的defaults就行

<2>在创建的conda虚拟环境中,安装深度学习通用基础依赖:PyTorch、CUDA
安装PyTorch (PyTorch 2.2.0 + CUDA 11.8):
pip install torch==2.2.0+cu118 torchvision==0.17.0+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
下文要安装的pytorch3d需要pytorch最低版本为2.2.0。README中的Pytorch 2.1.2不支持pytorch3d
下载PyTorch时会自动切换到阿里源,最高速率可达40MB/s
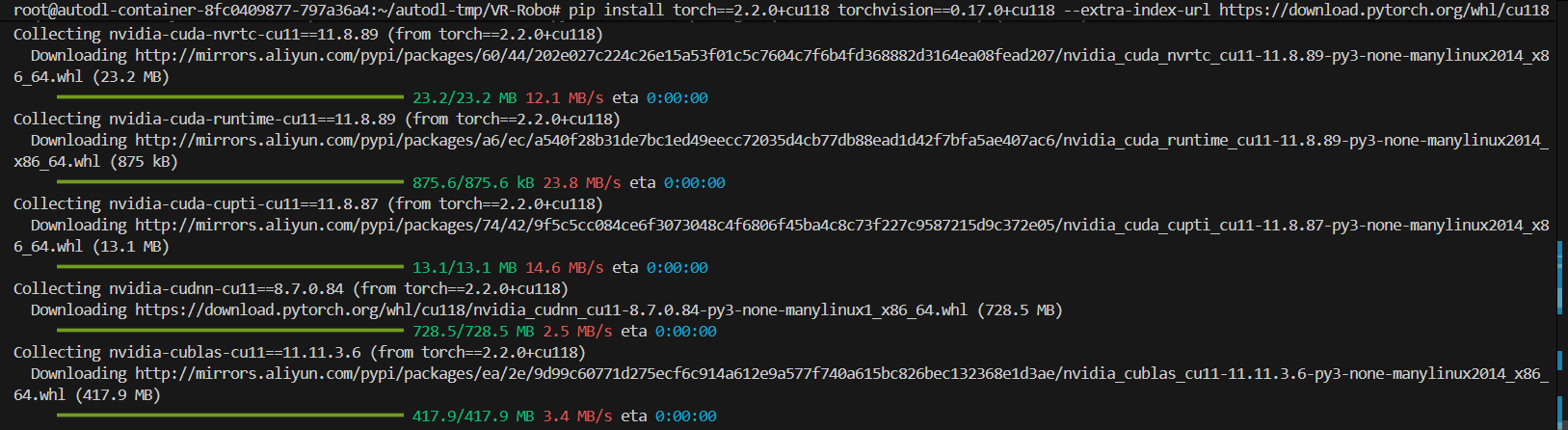
PyTorch全部相关依赖:
Installing collected packages: nvidia-nvtx-cu11, nvidia-nccl-cu11, nvidia-cusparse-cu11, nvidia-curand-cu11, nvidia-cufft-cu11, nvidia-cuda-runtime-cu11, nvidia-cuda-nvrtc-cu11, nvidia-cuda-cupti-cu11, nvidia-cublas-cu11, nvidia-cusolver-cu11, nvidia-cudnn-cu11, torch, torchvision
<3>在创建的conda虚拟环境中,安装该论文所需的依赖:3D相关
pip install open3d pytorch3d plyfile opencv-python einops e3nn rpyc gdown
<4>安装项目修改的3DGS的两个子模块 (需要GPU)
注意:编译这两个子模块时,必须是含GPU卡开机 (因为需要检测CUDA架构)
pip install submodules/diff-plane-rasterization
pip install submodules/simple-knn
会自动调用setup.py
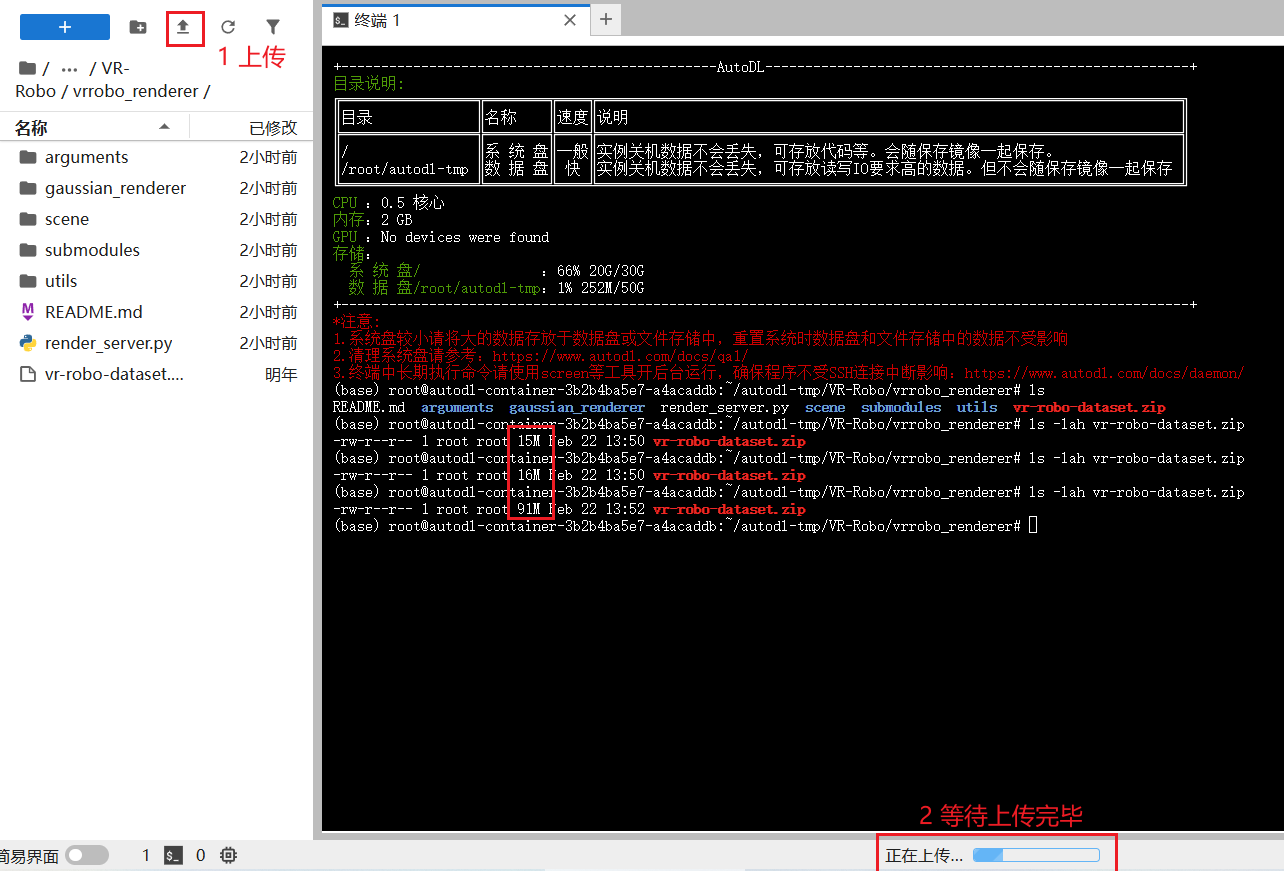
<5>下载数据集 vr-robo-dataset.zip
直接用README里的 gdown 1qvmFvhSha5FnKgFldW8WFAEO50HhQ7GZ 会访问Timeout,推荐用浏览器手动下载,并用Jupyter传进去:
1.Google上下载数据集:https://drive.google.com/uc?export=download&id=1qvmFvhSha5FnKgFldW8WFAEO50HhQ7GZ

2.Jupyter手动点击上传,然后慢慢等待上传
3.解压数据集
unzip vr-robo-dataset.zip
里面有很多的点云数据 point_cloud.ply

到现在,渲染服务器 配置完毕。
<6>启动渲染服务
python render_server.py
(2)仿真服务器 (rsl_rl 机器人强化学习训练):vrrobo_isaac_lab
<1>创建并启动conda环境
cd /root/autodl-tmp/VR-RoBo
conda create -n vr-robo-isaaclab python=3.10 -y
conda activate vr-robo-isaaclab
<2>安装基础库 Pytorch 和 CUDA
pip install torch==2.4.0 torchvision==0.19.0 --index-url https://download.pytorch.org/whl/cu118
<3>安装 Isaac Sim
第二条命令要下载的依赖较大
pip install isaacsim==4.2.0.2 --extra-index-url https://pypi.nvidia.com
pip install isaacsim-extscache-physics==4.2.0.2 isaacsim-extscache-kit-sdk==4.2.0.2 isaacsim-extscache-kit==4.2.0.2 --extra-index-url https://pypi.nvidia.com
<4>安装 Isaac Lab
cd /root/autodl-tmp/VR-Robo
git clone https://github.com/isaac-sim/IsaacLab.git -b v1.3.0 【原版,应该比较慢】
git clone https://ghfast.top/https://github.com/isaac-sim/IsaacLab.git -b v1.3.0 【推荐用AutoDL学术加速镜像】
直接访问github网速为60KB/s,用国内镜像ghfast.top加速可以达到3MB/s
<5>修改setup.py代码
sed -i '/rsl_rl\.git/d' IsaacLab/source/extensions/omni.isaac.lab_tasks/setup.py
sed -i '/EXTRAS_REQUIRE\["rsl_rl"\] = EXTRAS_REQUIRE\["rsl-rl"\]/d' IsaacLab/source/extensions/omni.isaac.lab_tasks/setup.py
<6>修改并执行 isaaclab.sh 安装脚本
1.修改脚本,在开头将gituhub源换为ghfast:
cd IsaacLab
vim isaaclab.sh
在开头添加这一段:
#github -> ghfast
git config --global url."https://ghfast.top/https://github.com/".insteadOf "https://github.com/"
2.执行安装脚本
./isaaclab.sh --install
<7>安装 项目vrrobo_isaaclab 所需要的依赖
cd /root/autodl-tmp/VR-Robo/vrrobo_isaaclab
pip install toml
pip install -e exts/vrrobo_isaaclab --no-build-isolation
pip install -e exts/rsl_rl
pip install gymnasium==0.29.0 rpyc timm
中间不可避免要出现一些包依赖版本不一致的问题。靠AI解决一下,升级或降级某些包的版本。
比如:
项目要求 gymnasium==0.29.0。但是stable-baselines3 2.7.1 要求 gymnasium>=0.29.1。所以只能降级stable-baselines3的版本
pip install "stable-baselines3<2.6" "gymnasium==0.29.0"
五、复现实验
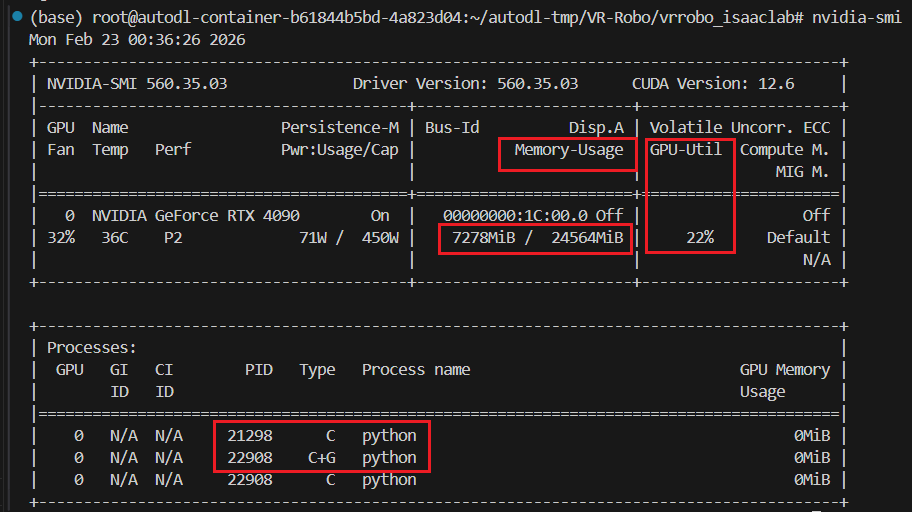
0.含GPU卡开机 RTX4090,使用nvidia-smi确认GPU状态
nvidia-smi
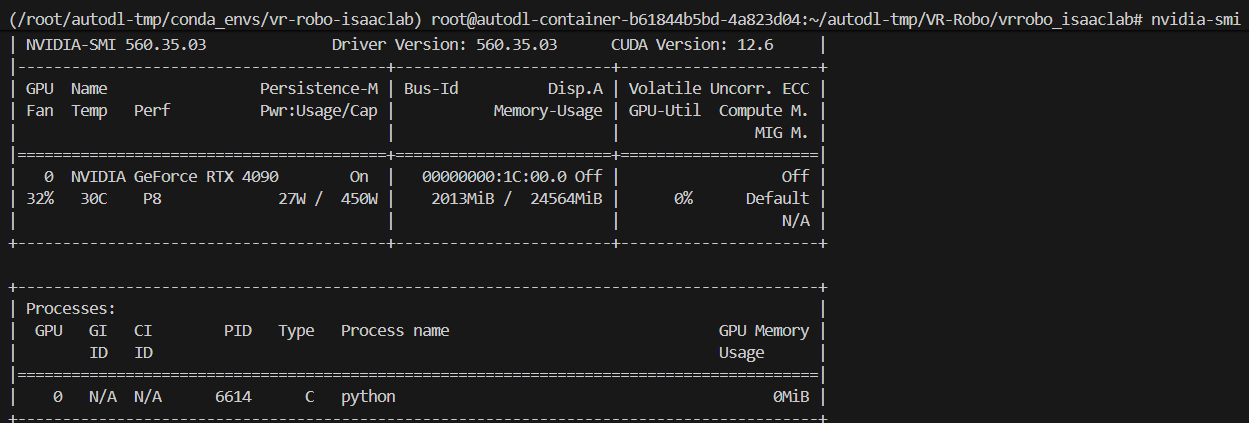
你需要打开 两个独立的终端(Terminal),分别运行渲染器和仿真器。
🔴 终端 A:配置并启动“渲染服务器” (vrrobo_renderer)
这个部分负责高保真的 3D 场景渲染(比如 3D 高斯溅射 Gaussian Splatting),它使用 Python 3.8。
🔵终端 B:配置“物理与强化学习客户端” (vrrobo_isaaclab)
它负责跑 Isaac 物理引擎和 RSL-RL 强化学习算法,使用 Python 3.10。
1.渲染服务器 (3DGS):vrrobo_renderer
(1)建环境:严格按照文档建一个名叫 vr-robo-renderer 的 Python 3.8 环境。
(2)装核心库:安装 PyTorch、CUDA Toolkit 和各种 3D 渲染库(PyTorch3D、Open3D 等)。这里编译 diff-plane-rasterization 可能会花点时间,耐心等待。
(3)下数据:用 gdown 下载作者提供的真实场景扫描数据,并按规定解压到 vr-robo-dataset 目录。
(4)启动服务:
配置环境时做了前面三步,现在做第四步
(1)启动渲染端
cd ~/autodl-tmp/VR-Robo/vrrobo_renderer
conda activate /root/autodl-tmp/conda_envs/vr-robo-renderer
python render_server.py
(注意:这个终端以后就挂在这里不要关,它会一直监听仿真器发来的渲染请求。)
当仿真端也跑起来时,渲染端会一直打印:
Successfully sent tensor torch.Size([1, 172800])
Successfully sent tensor torch.Size([1, 172800])
(2)解决端口占用问题

sudo apt-get update
sudo apt-get install net-tools lsof iproute2
sudo lsof -i :18861

发现是上次渲染服务器卡在了CLOSE_WAIT状态。现在直接杀死它
sudo kill 18763
2.仿真服务器 (rsl_rl):vrrobo_isaac_lab
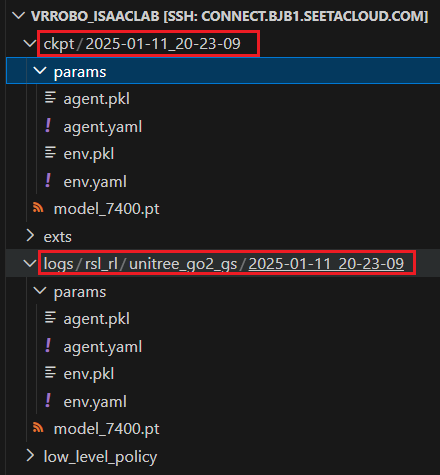
(1)复制checkpoint到对应位置
1.将训练好的 Unitree Go2 rsl_rl模型的checkpoint,整理归档到结构化的日志目录中,方便后续加载、测试或继续训练。
cd ~/autodl-tmp/VR-Robo/vrrobo_isaaclab
mkdir -p logs/rsl_rl/unitree_go2_gs
cp -r ckpt/2025-01-11_20-23-09 logs/rsl_rl/unitree_go2_gs/
(2)修改配置文件 resume = True,意思是从上次的checkpoint继续
cd ~/autodl-tmp/VR-Robo/vrrobo_isaaclab
vim exts/vrrobo_isaaclab/vrrobo_isaaclab/tasks/vrrobo/config/go2/agents/rsl_rl_ppo_cfg.py
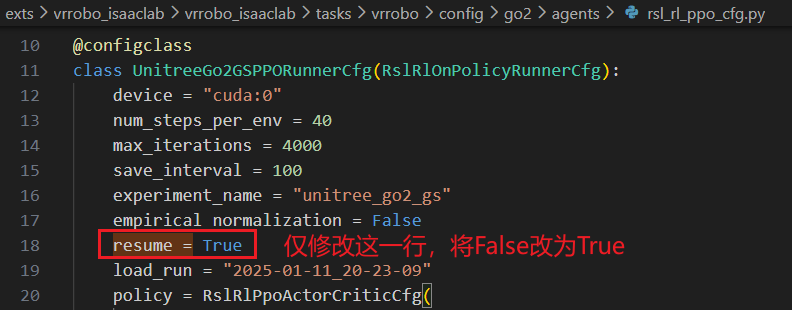
将里面的 resume = False 改为 True:
resume = True
load_run = "2025-01-11_20-23-09"
load_run=“2025-01-11_20-23-09” 对应的是作者提供的预训练run的目录名,包含 params目录 和 模型权重文件 model_*.pt
resume = False:
意思是从头训练,不加载旧 checkpoint,按初始化开始一个新 run。
resume = True:
意思是从上个checkpoint继续训练
(3)启动仿真端
cd ~/autodl-tmp/VR-Robo/vrrobo_isaaclab
conda activate /root/autodl-tmp/conda_envs/vr-robo-isaaclab
python scripts/rsl_rl/play_gs.py --task go2_gs_play
(4)解决warning
1.如果看到一大堆如图的warning报错,这是底层C++提示的没找到对应device id,只能启动GPU0。
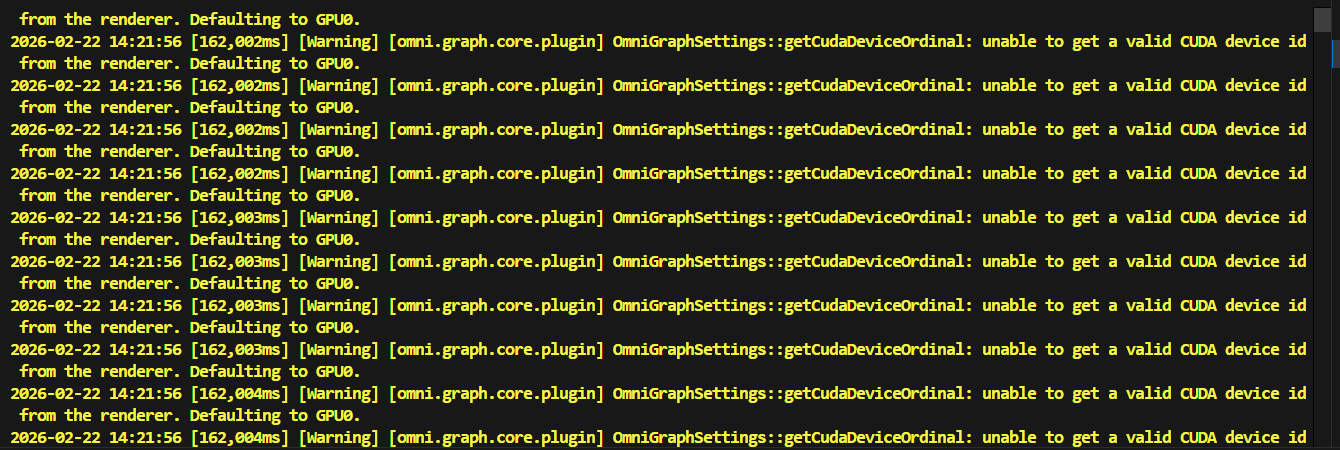
可以用命令行屏蔽warning的屏幕输出:
运行脚本时,用 grep -v 过滤掉包含指定警告字符串的行
python scripts/rsl_rl/play_gs.py --task go2_gs_play 2>&1 | grep -v "OmniGraphSettings::getCudaDeviceOrdinal: unable to get a valid CUDA device id from the renderer"
2.如果不打算用GUI,那么用headless模式跑
python scripts/rsl_rl/play_gs.py --task go2_gs_play --headless 2>&1 | grep -v "OmniGraphSettings::getCudaDeviceOrdinal: unable to get a valid CUDA device id from the renderer"
(5)解决error,修复Isaac-sim 仿真引擎问题
1.补充图形化依赖
apt-get update
apt-get install -y libglu1-mesa
apt-get install -y mesa-vulkan-drivers vulkan-tools
apt-get install -y libx11-6 libx11-xcb1 libxext6 libxrender1 libxi6 libxrandr2 libxcursor1 libxinerama1 libsm6 libice6 libxt6 zenity
2.路径改为数据盘路径:
export ISAACSIM_PKG=/root/autodl-tmp/conda_envs/vr-robo-isaaclab/lib/python3.10/site-packages/isaacsim
export USD_LIB_BIN=$ISAACSIM_PKG/extscache/omni.usd.libs-1.0.1+10a4b5c0.lx64.r.cp310/bin
# 这几个通常也很关键:Kit 自身、PhysX、以及一些通用插件的 bin
export KIT_BIN=$ISAACSIM_PKG/kit
export PHYSX_BIN=$ISAACSIM_PKG/extsPhysics/omni.physx/bin
export LD_LIBRARY_PATH=$USD_LIB_BIN:$KIT_BIN:$PHYSX_BIN:$LD_LIBRARY_PATH
# 可选但推荐:让动态链接器也能找到(对某些系统/容器更稳)
export PATH=$USD_LIB_BIN:$KIT_BIN:$PATH
3.下载ViT-Tiny的预训练参数(权重文件),避免访问Hugging Face Hub超时
(1)将访问Hugging Face Hub改为访问国内镜像 https://hf-mirror.com
export HF_HOME=/root/autodl-tmp/hf_home
export HUGGINGFACE_HUB_CACHE=$HF_HOME/hub
export HF_ENDPOINT=https://hf-mirror.com
(2)从https://hf-mirror.com下载ViT-Tiny权重文件
python - <<'PY'
import timm
m = timm.create_model("vit_tiny_patch16_224", pretrained=True)
print("vit weights ready:", type(m))
PY
(3)查看运行状态
nvidia-smi
GPU使用率22%
显存使用情况:7GB / 24GB
两个进程和一个线程在跑
六、保存AutoDL镜像
好不容易才配好的 Isaac-lab、Isaac-sim 镜像,似乎是全网独一份,赶紧保存镜像。




















 1254
1254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












