



本文深入介绍了 Hermes Agent 的最新版本,重点讲解了其上下文压缩机制、新增的压缩命令、可插拔的上下文引擎等核心功能。文章还提供了配置 GLM-5.1、飞书接入等实用教程,并探讨了 Hermes 在 AI Agent 岗位求职中的应用。对于想要学习大模型并提升工程落地能力的小白或程序员来说,本文是不可或缺的学习资料。
两周前我在小号发了篇 Hermes Agent 的实测教程,当时 Star 数还是 4 万出头,结果今天一看——90.2k。
两周涨了 50k Star,这增速比我开源的所有项目加起来都要多(AI 时代,一切都变了,star 的增长速度是真的快)。
快到我有时候也会感觉很恍惚。😄
何以解忧,唯有拥抱,唯有拥抱~~~~
我当时的体感是:Hermes 还不错,但上下文长度严重不足,经常需要压缩。
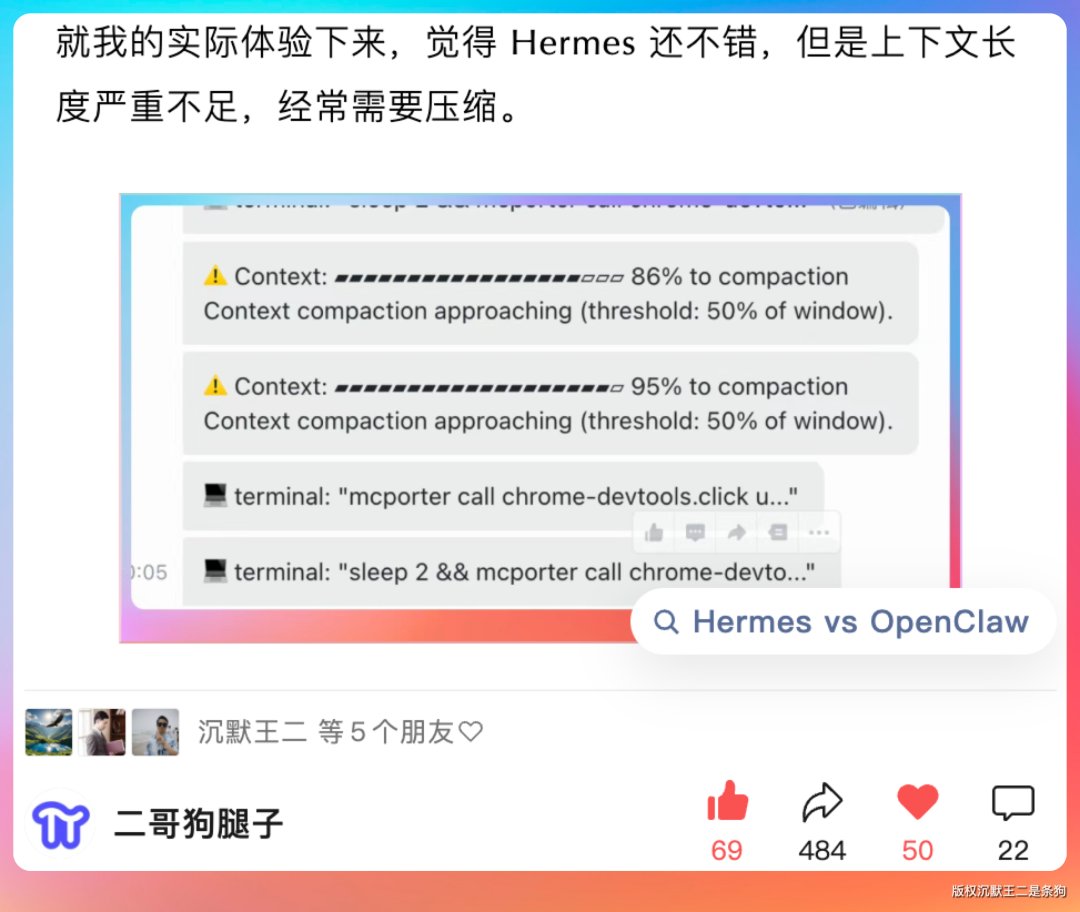
据说,Hermes 最新版本针对这个问题做了优化。
今天这篇内容,就带大家来深度体验一下,Hermes 到底强在哪里,以及,我们求职人,能从 Hermes Agent 上学到什么,从而更好的帮助我们拿到更大的 offer。
现在很多面试都问 AI Agent 相关的内容,Hermes 的上下文压缩、Memory、插件机制、IM 终端,主动 Skill,都挺有话题点。
系好安全带,我们粗粗粗发了~~~
01、Hermes 是如何进行上下文压缩的?
最新版本的 Hermes Agent 上下文管理分成了两层防线。
第一层是 Gateway 级别,在 gateway/run.py 里,阈值设为上下文窗口的 85%。这一层的作用简单粗暴——防止上下文太大导致 API 直接报错。
它不做精细压缩,只是确保请求能发出去。
第二层是 ContextCompressor,在 agent/context_compressor.py 里,默认在 50% 的时候开始介入。
举个例子,如果你用的是 Claude 的 200K 上下文,那么大概在用到 100K token 的时候,ContextCompressor 就会启动。它会预留 20K token 保护最近的消息,确保你和 Hermes 的最新对话不会被干掉。
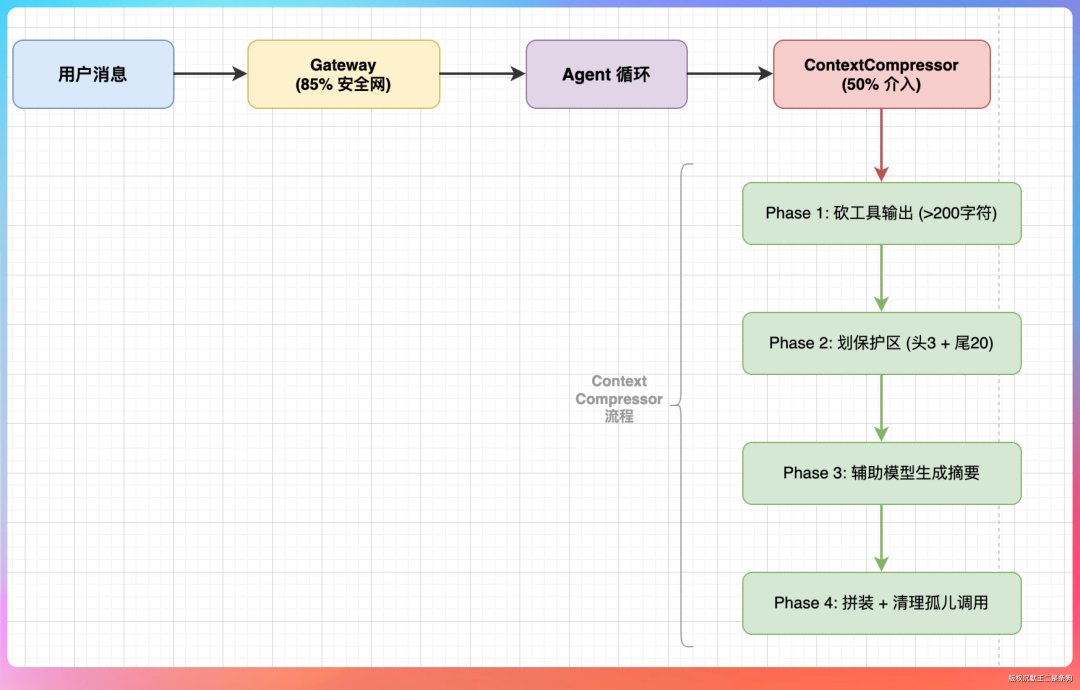
整个压缩分为四个阶段。
第一阶段:先砍工具输出。那些超过 200 个字符的工具返回结果,直接替换成占位符。这一步不需要调用大模型,纯文本处理,速度很快。
第二阶段:划定保护区。系统会保护最前面的 3 条消息(通常是系统提示词和第一轮对话)和最后 20 条消息(你最近的交互),中间的部分标记为“待压缩区”。
这里有个细节做得不错:它会保持 tool_call 和 tool_result 的配对完整,不会出现只有调用没有结果的情况。
第三阶段:生成结构化摘要。这里是最关键的。以前是直接删,现在会调用一个辅助模型来生成摘要。
摘要不是简单的“之前聊了什么”,而是按照固定模板,涵盖目标、进度、关键决策、涉及的文件、下一步计划这五个维度。而且摘要的 token 预算是动态的,按被压缩内容的 20% 来分配,上下限在 2K 到 12K 之间。
第四阶段:拼装消息。把保护区的头部、生成的摘要、保护区的尾部重新拼起来,同时清理那些因为压缩产生的孤儿工具调用。
最关键的改进是:后续压缩会更新已有摘要,而不是重新生成。
这意味着信息不会因为多次压缩导致越来越多的细节丢失。
02、Hermes 新增了/compress 命令
新版加了一个挺实用的功能:/compress <focus> 命令。
以前压缩完全是系统自动触发的,我们没有任何控制权。现在可以主动压缩,而且能指定一个焦点主题。
比如你跟 Hermes 聊了很长一段关于数据库优化的内容,中间穿插了一些闲聊和其他任务,你可以输入 /compress 数据库优化,它就会在压缩的时候重点保留和数据库优化相关的上下文,把那些不相关的内容优先压缩掉。
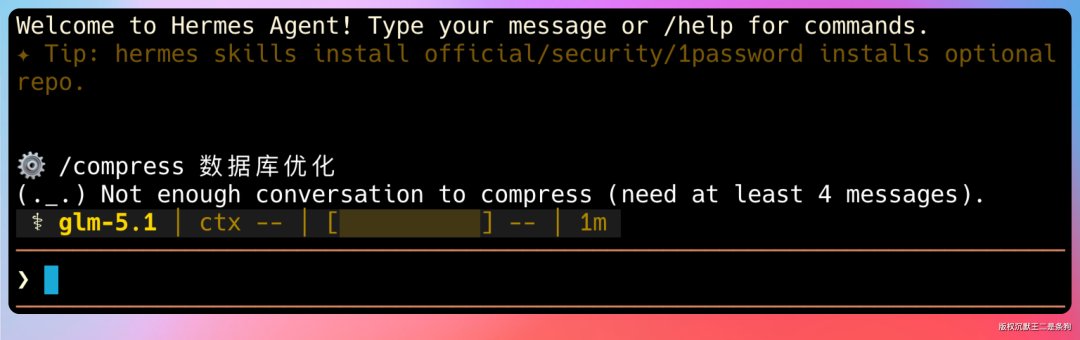
这个设计思路挺好,等于给我们了一个“选择性遗忘”的能力——你告诉 Hermes 什么是重要的,它就记住什么。
03、Hermes 的可插拔上下文引擎
v0.9.0 把上下文管理做成了一个可插拔的插件槽。
我们可以通过 hermes plugins 来切换不同的上下文引擎,甚至自己写一个。
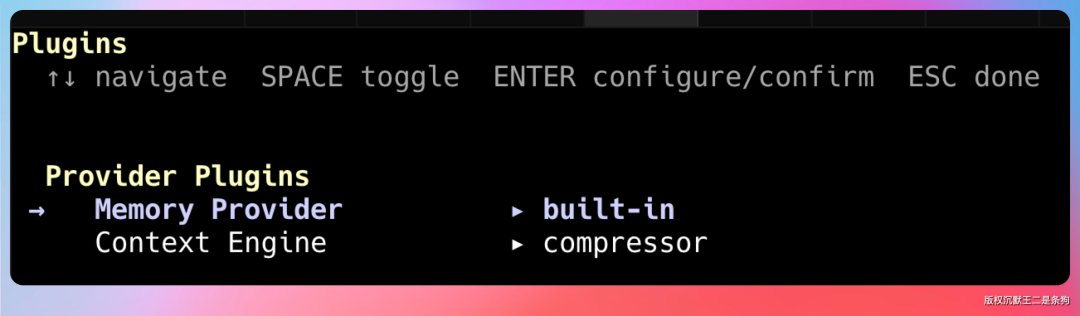
默认用的是内置的 ContextCompressor,但如果你有特殊场景——比如做法律文档分析,需要保留所有的条款引用不被压缩——你可以写一个自定义的上下文引擎,只压缩非条款内容。
插件放在 plugins/context_engine/<name>/ 目录下,需要继承 ContextEngine 这个抽象基类。
对于企业级场景来说,这个扩展还是很有价值的。
如果是做客服系统,可能希望永远保留用户的订单信息不被压缩;如果是做代码审查,可能希望保留所有的文件变更记录。不同场景对“什么该压缩什么不该压缩”的需求完全不一样。
04、更新 Hermes Agent
如果之前装过 Hermes,更新到 v0.9.0 非常简单。
启动 Codex,输入:
帮我更新 Hermes Agent 到最新版本
hermes update
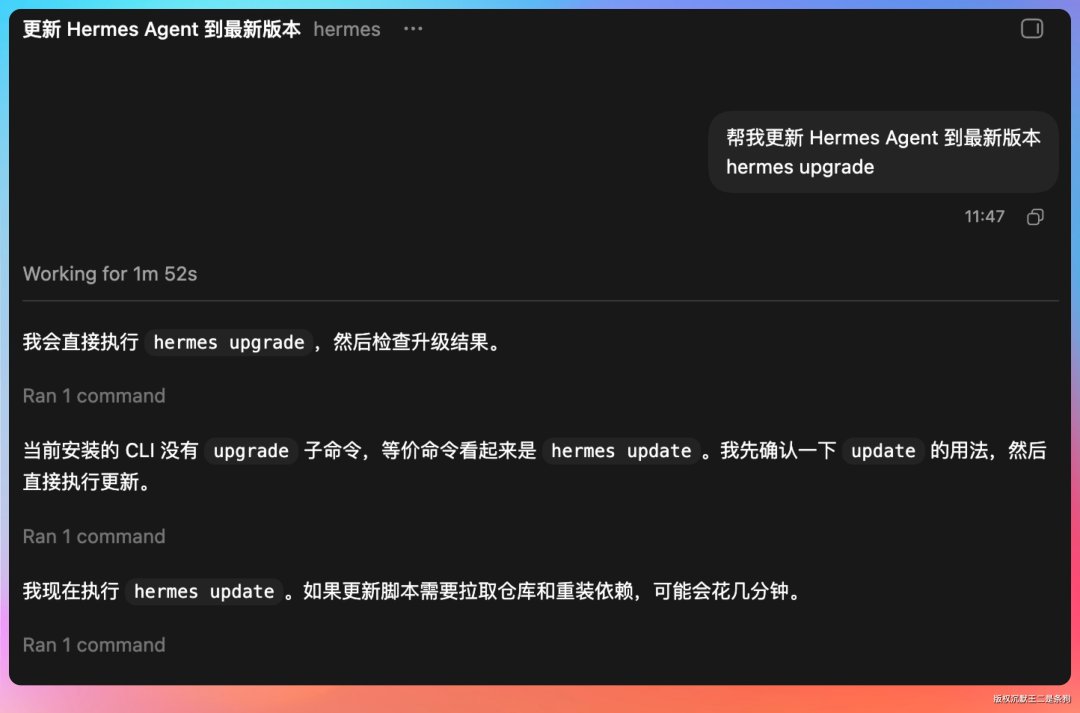
它会自动拉取最新代码,处理依赖更新。
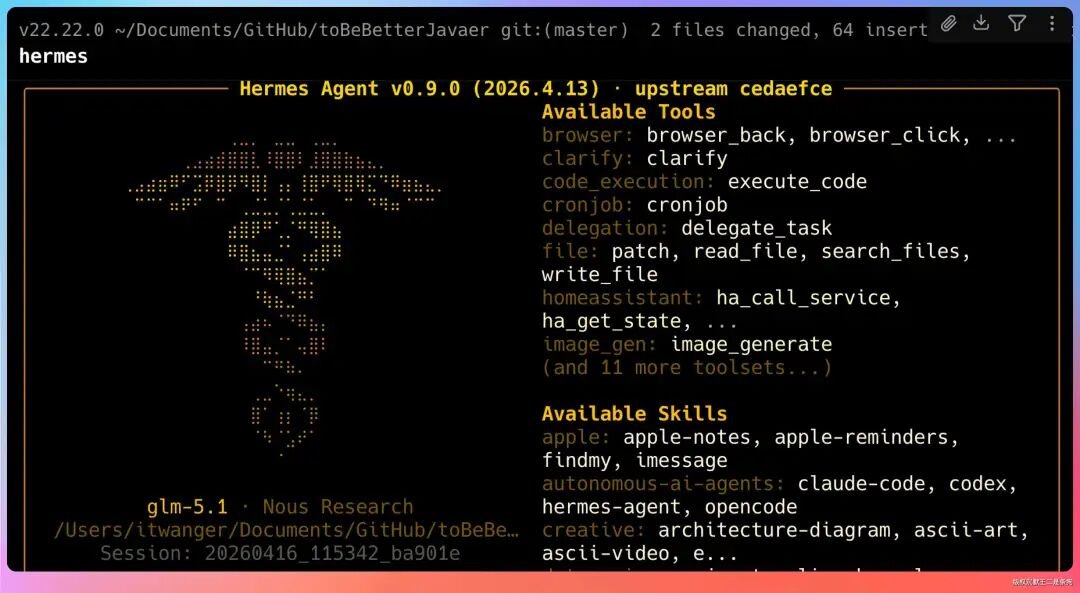
如果是全新安装,和之前的流程一样:
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
安装脚本会自动检测你的操作系统,把 Python 3.11、Node.js、Git 这些依赖全部搞定。
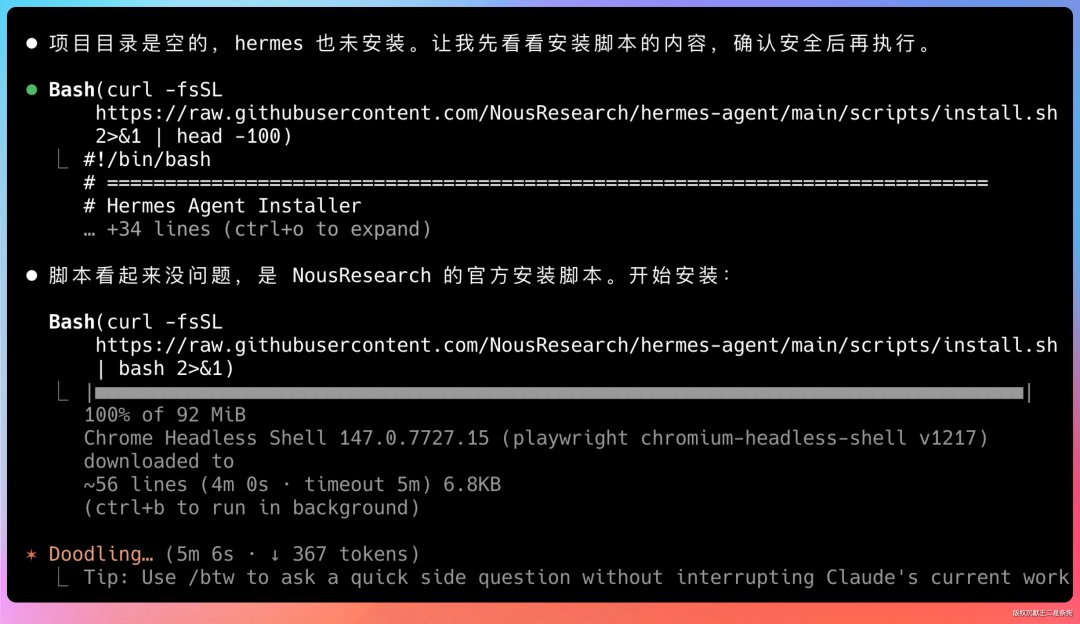
装好之后跑一下 hermes step 进入配置向导。
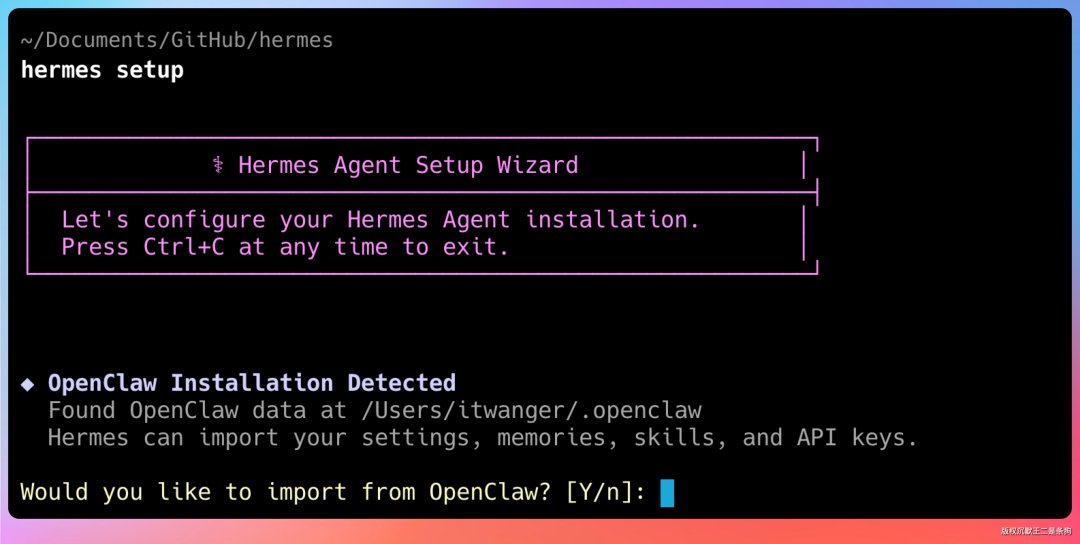
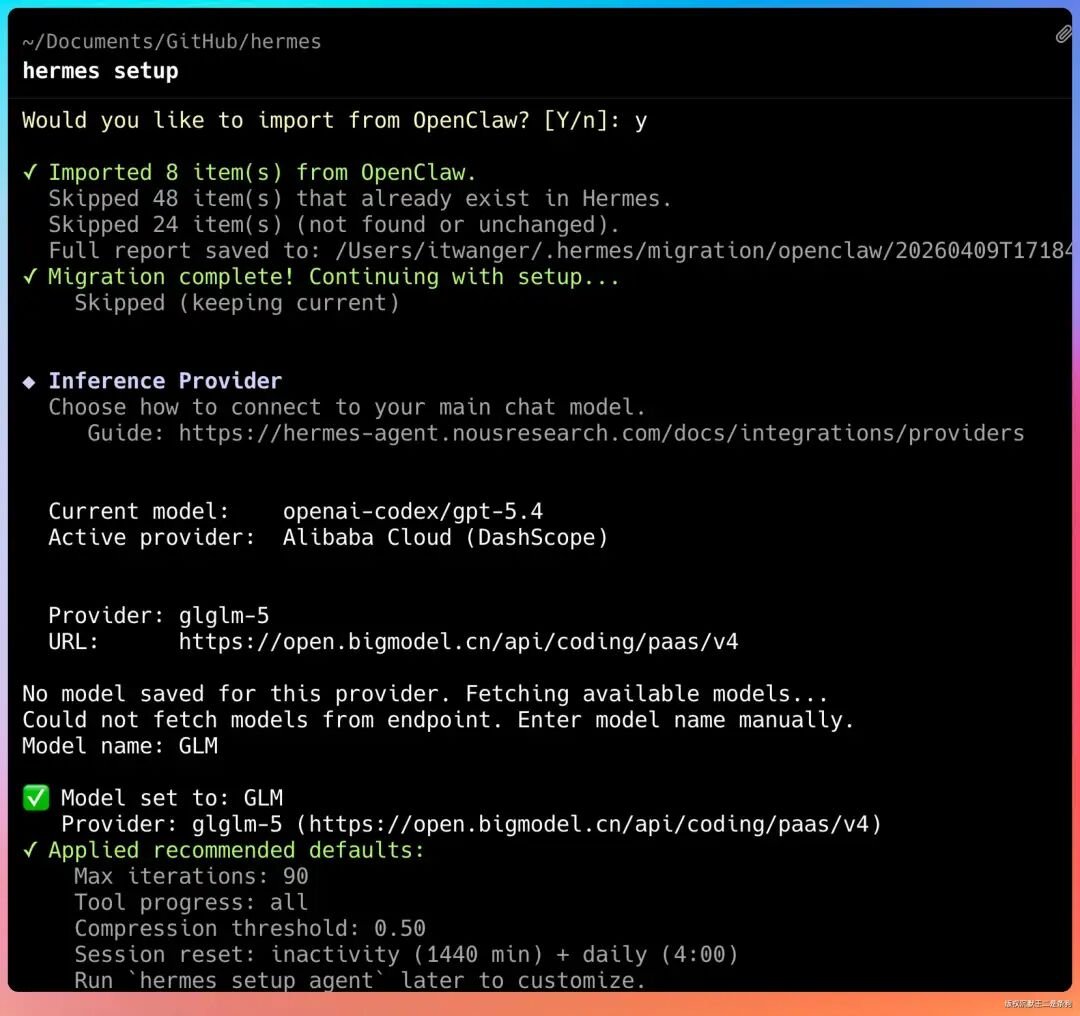
如果之前装过 OpenClaw,配置可以直接迁移,省不少事。
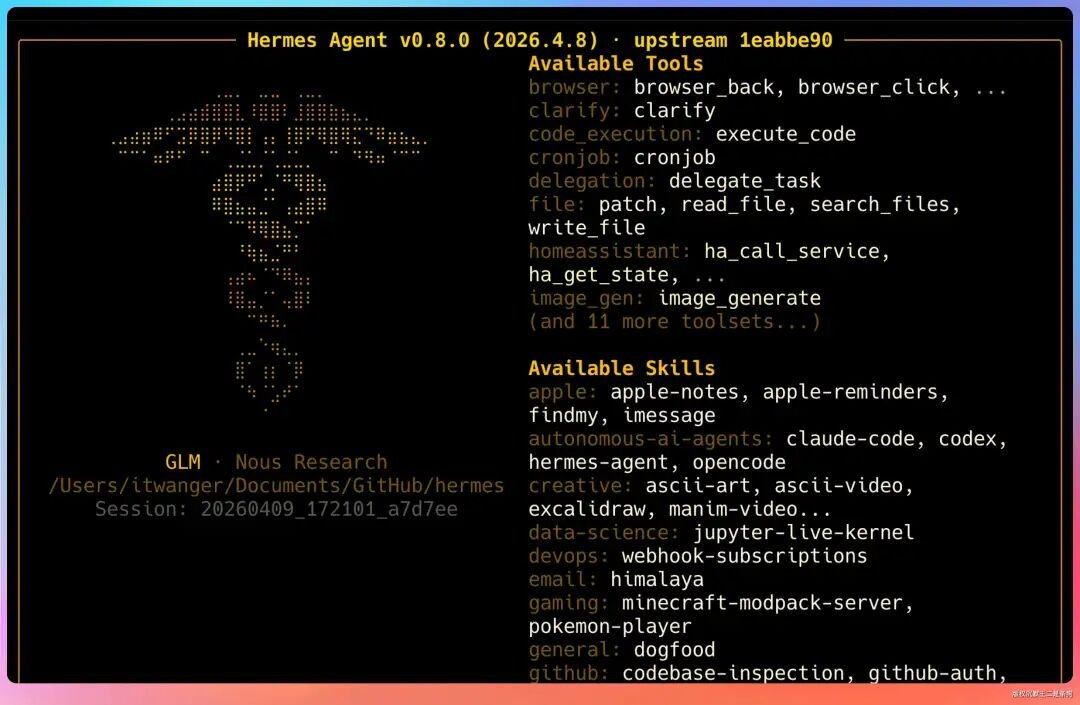
看到这个界面就说明配置没问题了。
05、给 Hermes Agent 配置 GLM-5.1
Hermes 的配置文件在 ~/.hermes/ 目录下。

首先是网关类型的选择,一般选 local 就行,跑在本地。如果你有远程服务器的需求,可以选 ssh 或者 docker。
配置文件里加上 API_SERVER_ENABLED=true,就能通过 http://127.0.0.1:8642/health 查看服务状态,调试的时候特别方便。
模型配置这里,我用的是 GLM,在配置文件里改好 API Key 就行。
但这里有个坑我上次就踩过:API Key 过期的话 Hermes 报错信息不够明确。
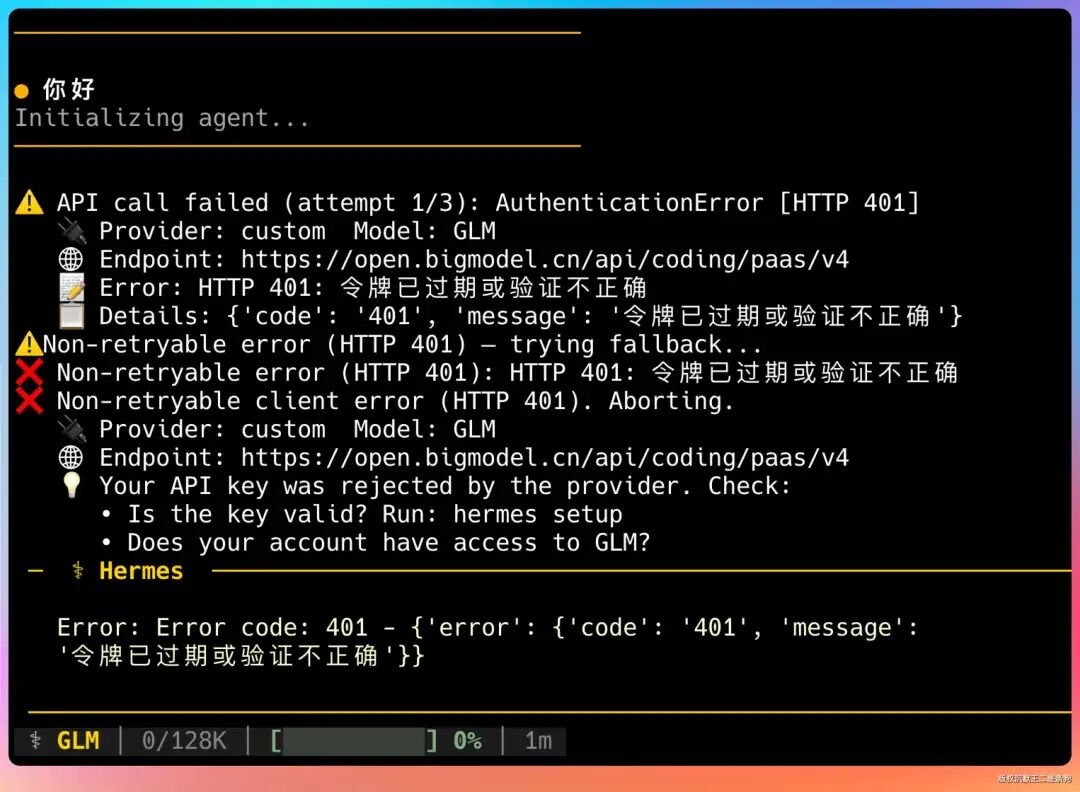
当时折腾了好一会儿,最后把问题丢给了 Codex 才搞定的。
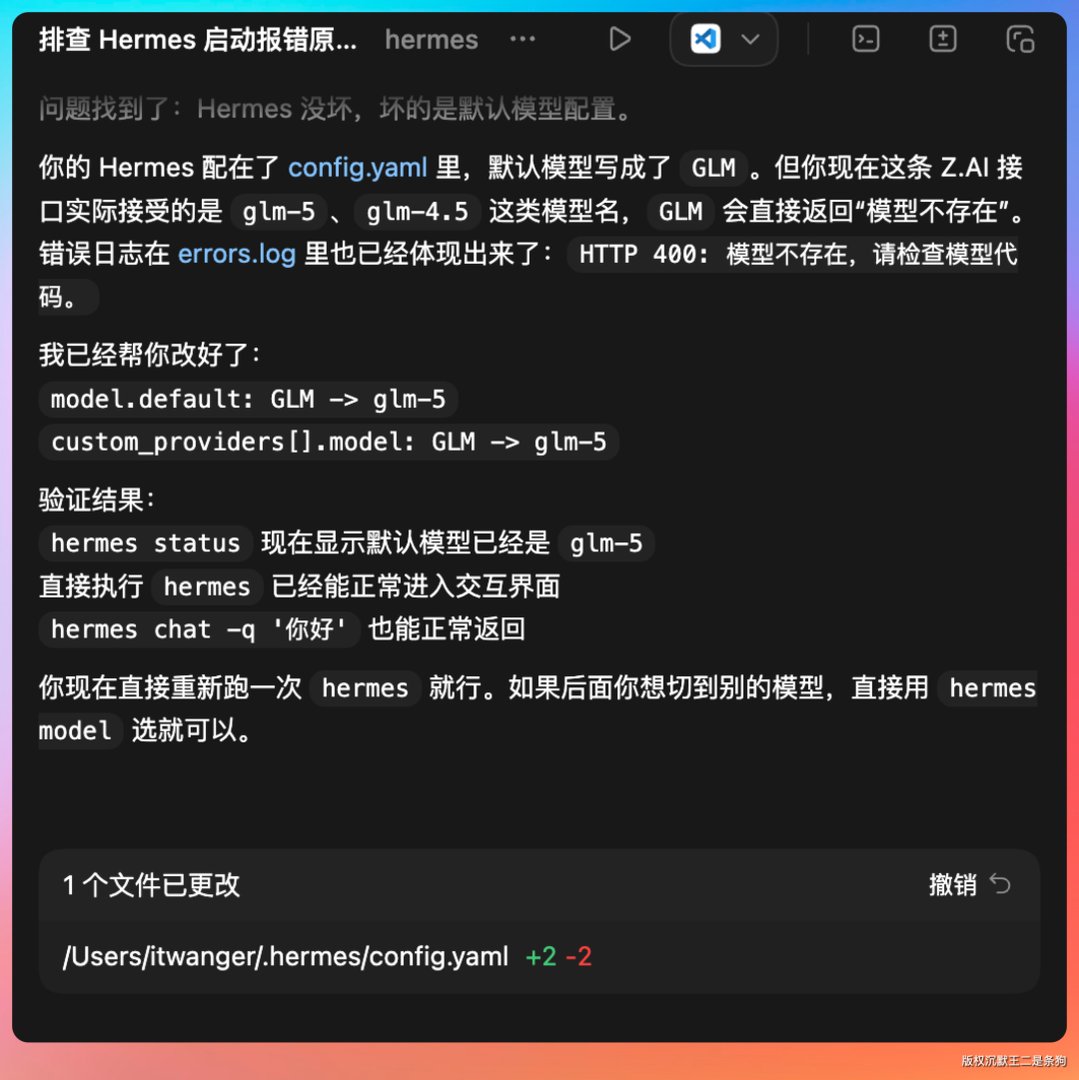
重新执行 hermes 进入主界面,随便发条消息测试一下,有回复就说明 OK。
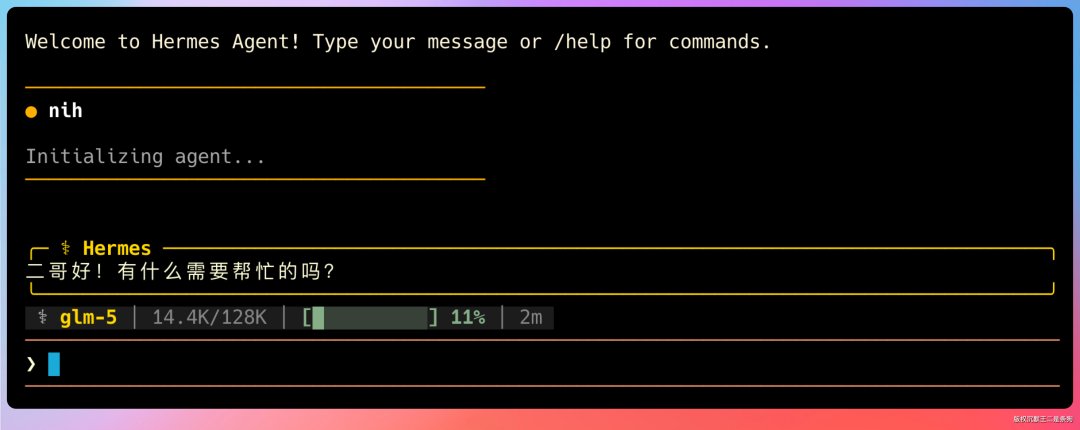
06、Hermes 的记忆系统配置
Hermes 的记忆分两层,搞明白这个对 AI Agent 岗位的求职很重要。
内置记忆是默认开启的。就两个文件:MEMORY.md 存你的环境信息、项目经验、工具使用记录,USER.md 存你的个人偏好和沟通习惯。
每次开新会话的时候,这两个文件会被注入到系统提示词里。
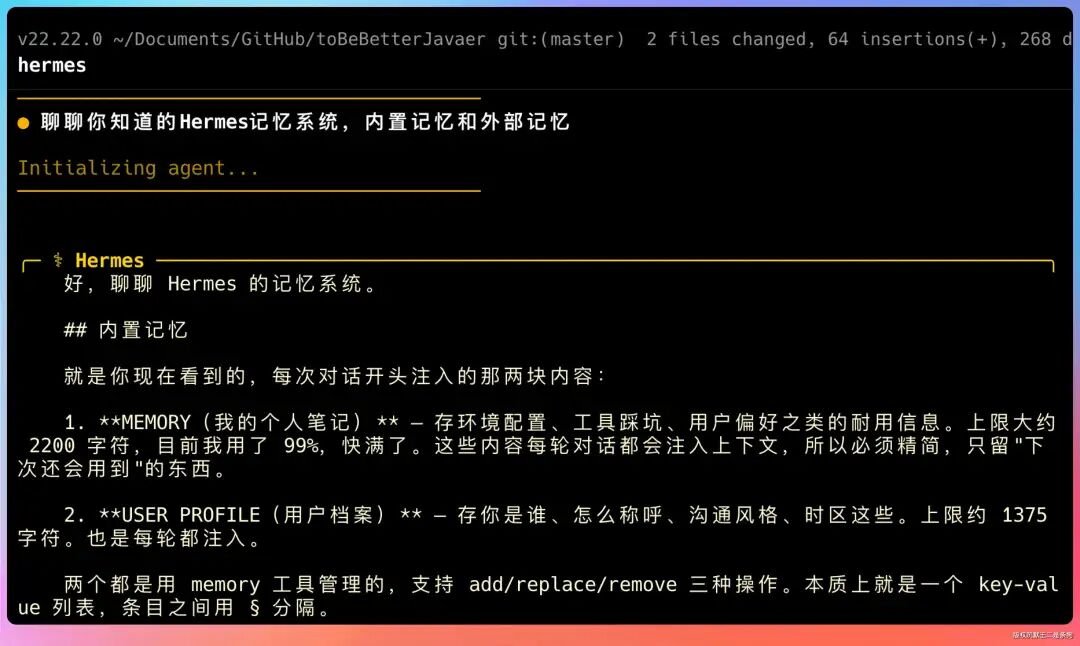
这个设计跟 Claude Code 的 CLAUDE.md 很像,但 Hermes 是自动维护的,你不用手动去编辑。
用着用着它就越来越了解你了。
外部记忆是可选的增强层,同一时间只能启用一个 provider。支持 honcho、mem0、hindsight 这些,可以理解为给 Hermes 接了一个外挂记忆库。
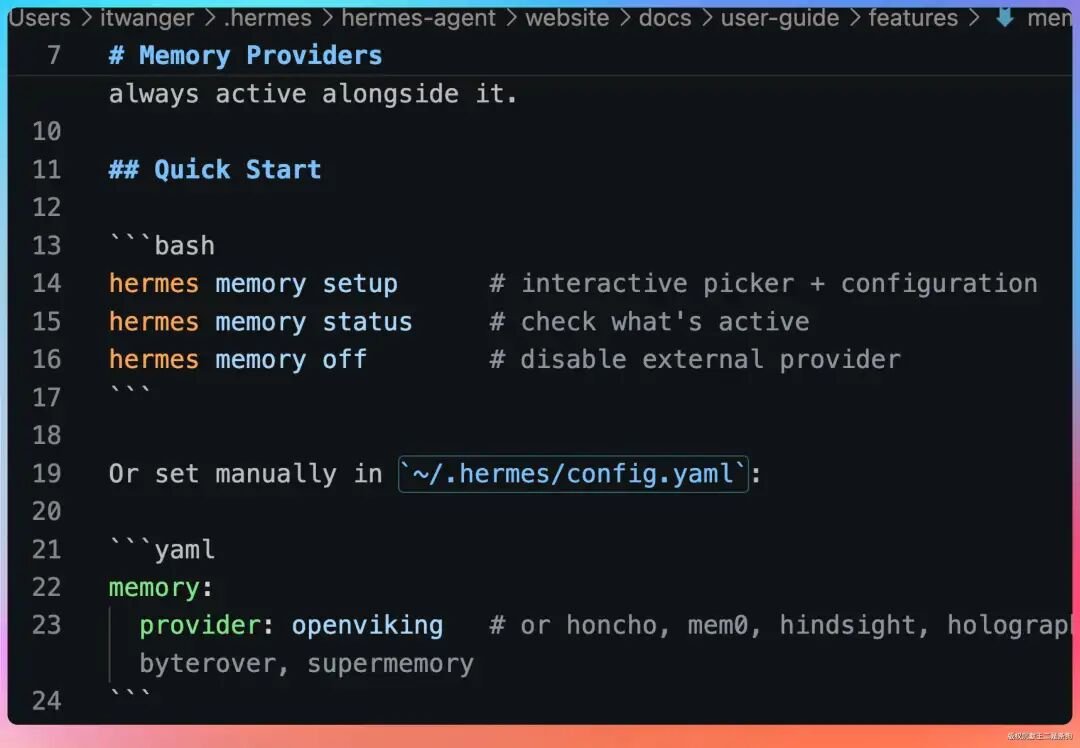
大部分场景下,内置记忆就够用了。
除非你有跨多个项目、跨多台机器的记忆共享需求,否则别折腾外部记忆,配置复杂收益不大。
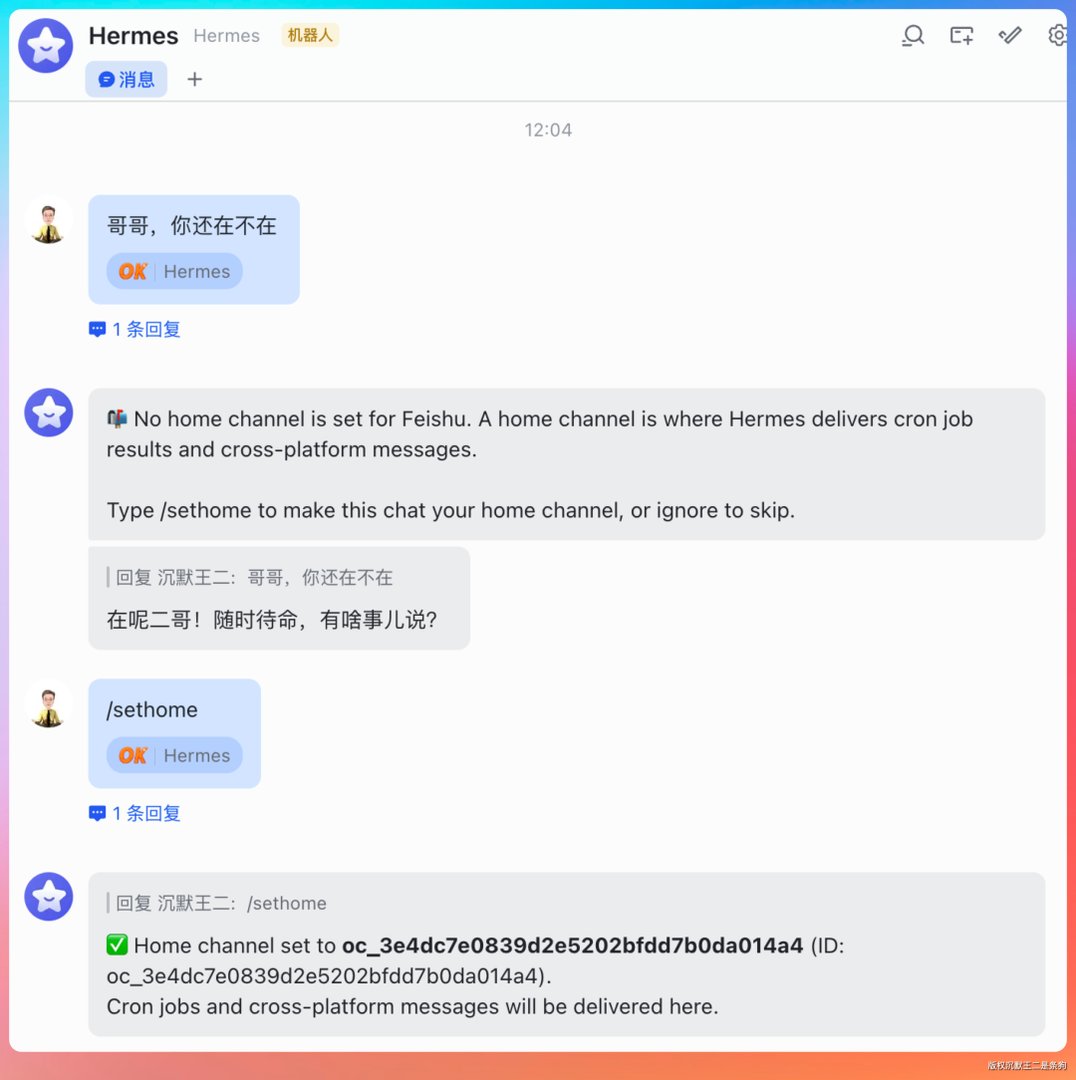
07、Hermes 飞书接入(快速版)
飞书接入我上次已经写过详细教程了,这次就捡重点说,主要补充一些上次没提到的坑。
先确认 Gateway 是开着的:
hermes gateway status
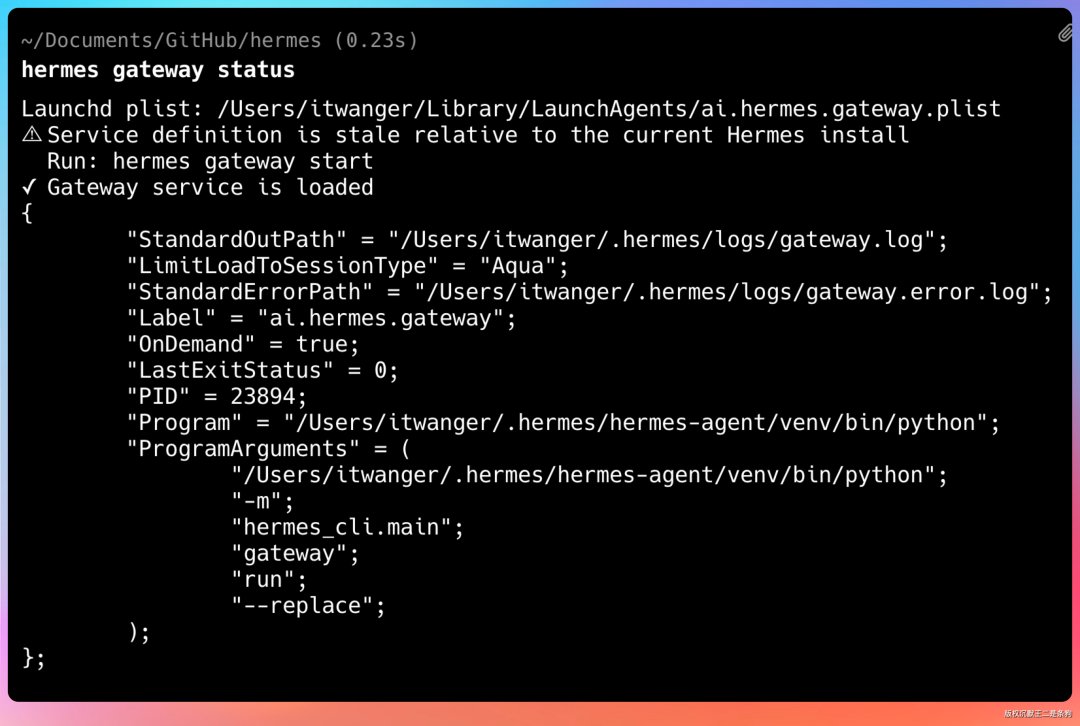
去飞书开放平台创建应用,添加机器人能力。权限至少加上 im:message 和 im:resource。
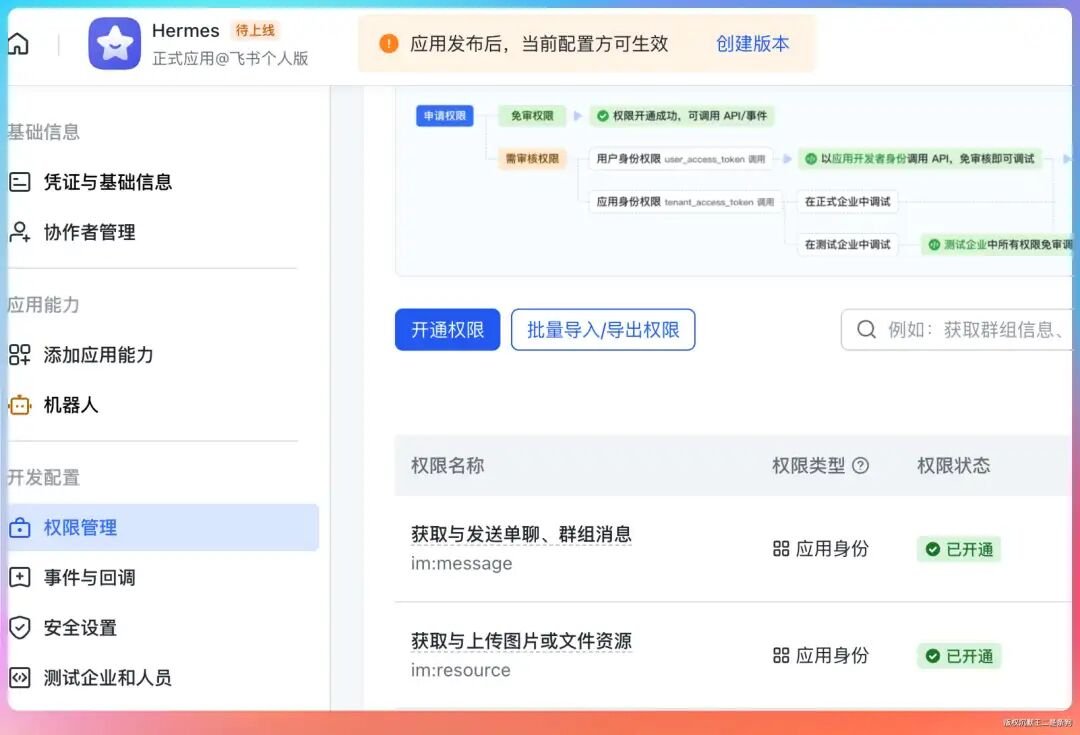
在 .env 文件里配置飞书应用的 ID 和 Secret:
FEISHU_APP_ID=cli_xxx
FEISHU_APP_SECRET=secret_xxx
FEISHU_DOMAIN=feishu
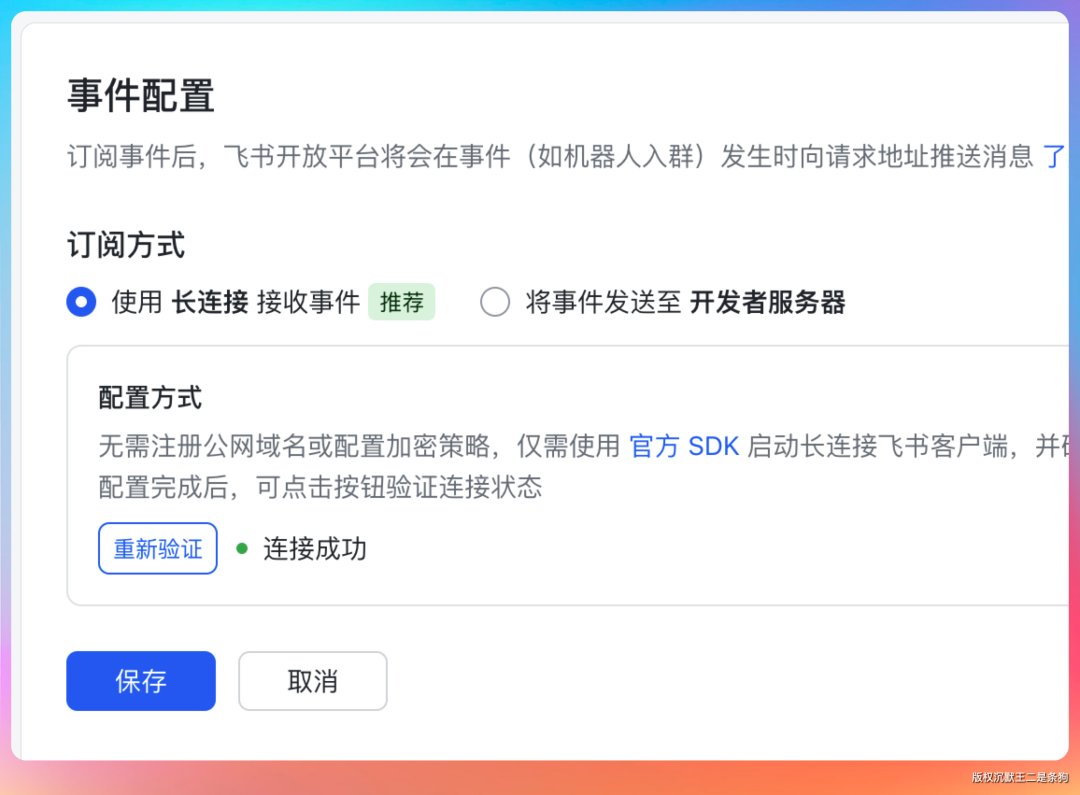
FEISHU_CONNECTION_MODE=websocket
重启 Gateway:
hermes gateway restart

在飞书控制台验证连接状态。
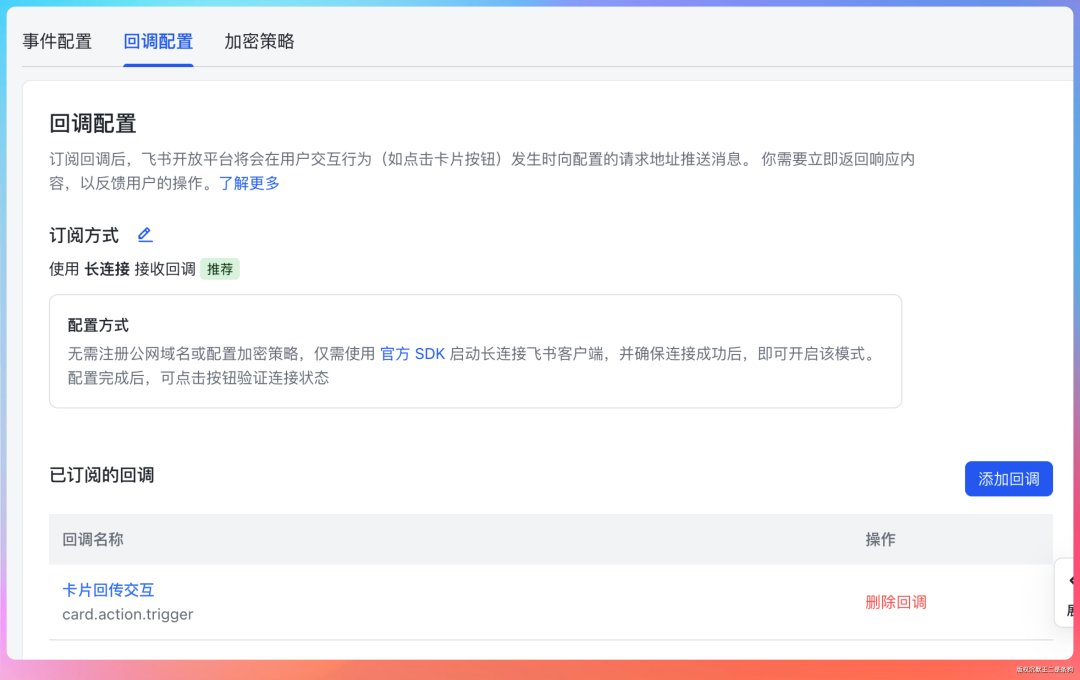
事件订阅里开通 im.message.receive_v1,回调配置开通 card.action.trigger。
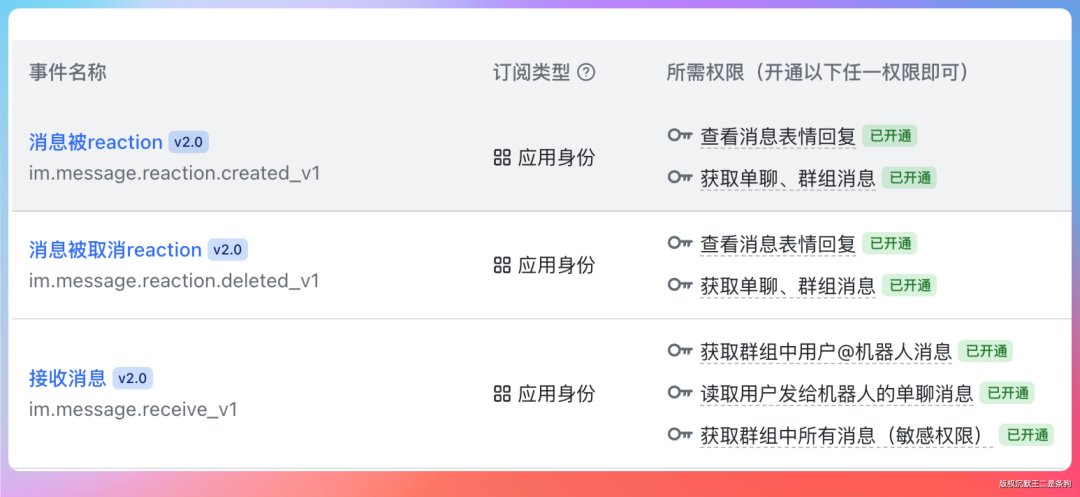
上次踩过的两个坑再提一嘴:第一,.env 里要加 GATEWAY_ALLOW_ALL_USERS=true,否则机器人收到消息不会响应。第二,飞书权限里“读取用户发给机器人的单聊消息”这个选项一定要勾上,不然就是上次我遇到的“发了消息没回音”的情况。
开通之后就正常了。
v0.9.0 新增了 WeChat 和企业微信的支持,现在也可以接入了,后续我再给大家分享。
08、Hermes 实战
说了这么多,该看看实际效果了。
上次我用 Hermes 回复知识星球的球友提问,效果还不错,但当时上下文压缩的问题很烦人。
这次 v0.9.0 重点优化了压缩,咱们就专门挑一个需要比较长上下文的球友问题来测试。
首先,确保 Hermes 装了 web-access 这个 Skill,让它能联网。
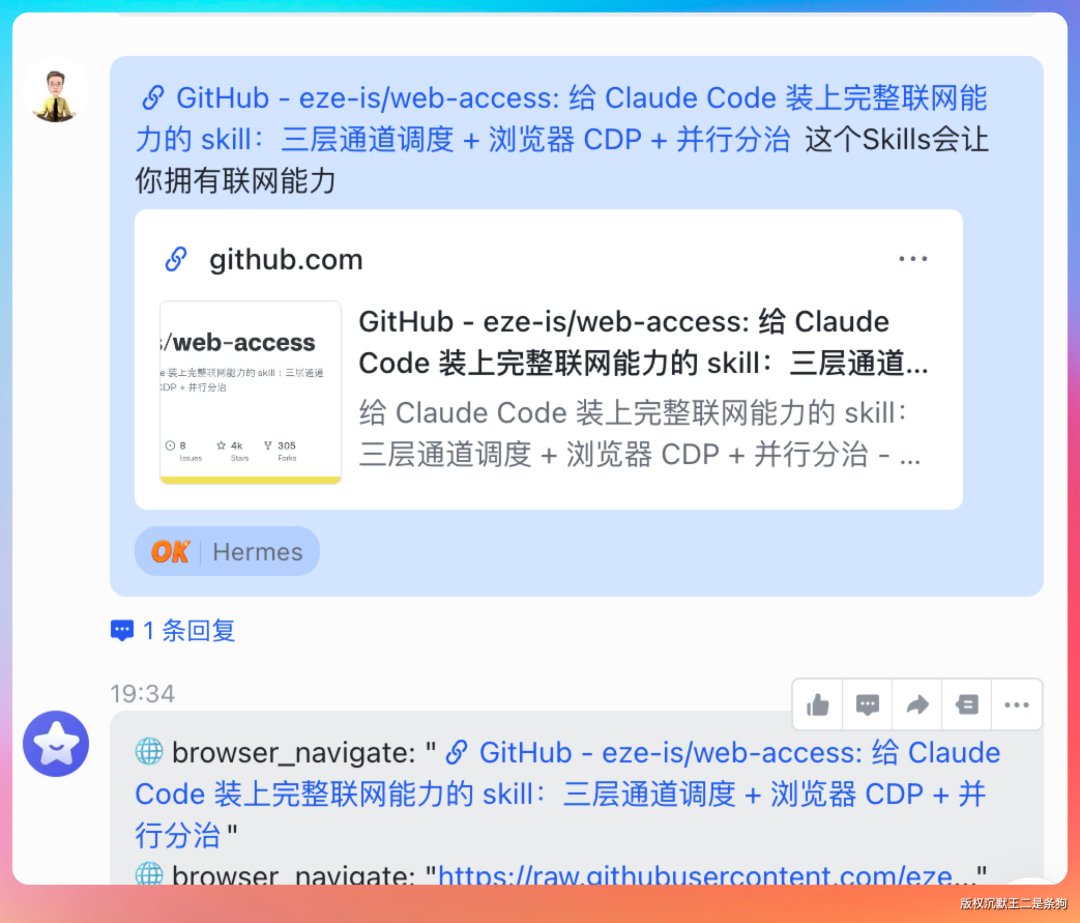
提示词:https://github.com/eze-is/web-access 这个 Skills 会让你拥有联网能力。
安装过程很快,基本秒装。
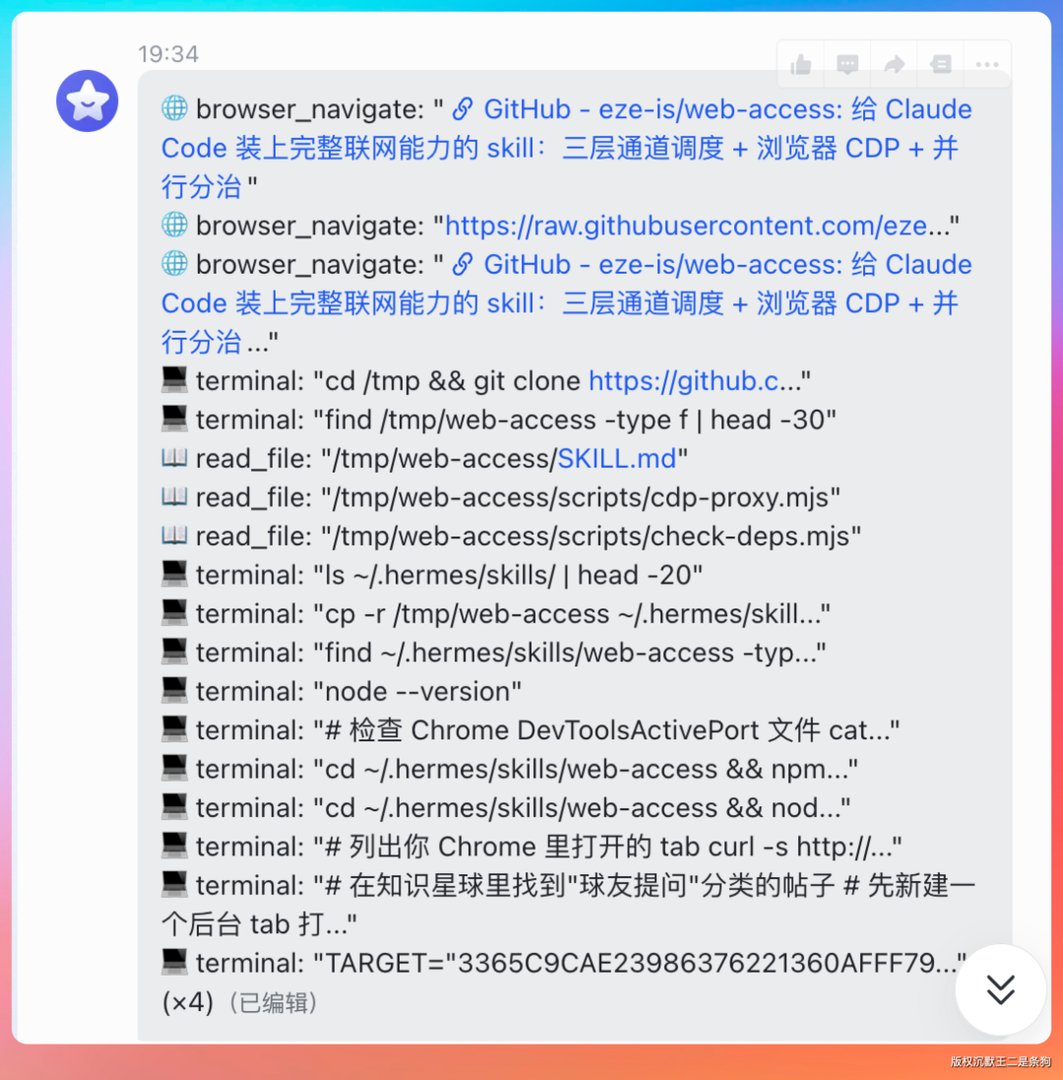
然后我让 Hermes 去知识星球回复球友提问:
去知识星球:https://wx.zsxq.com/group/15522885221412 【球友提问】标签下的【关于 agent 开发】的帖子回复一条内容。
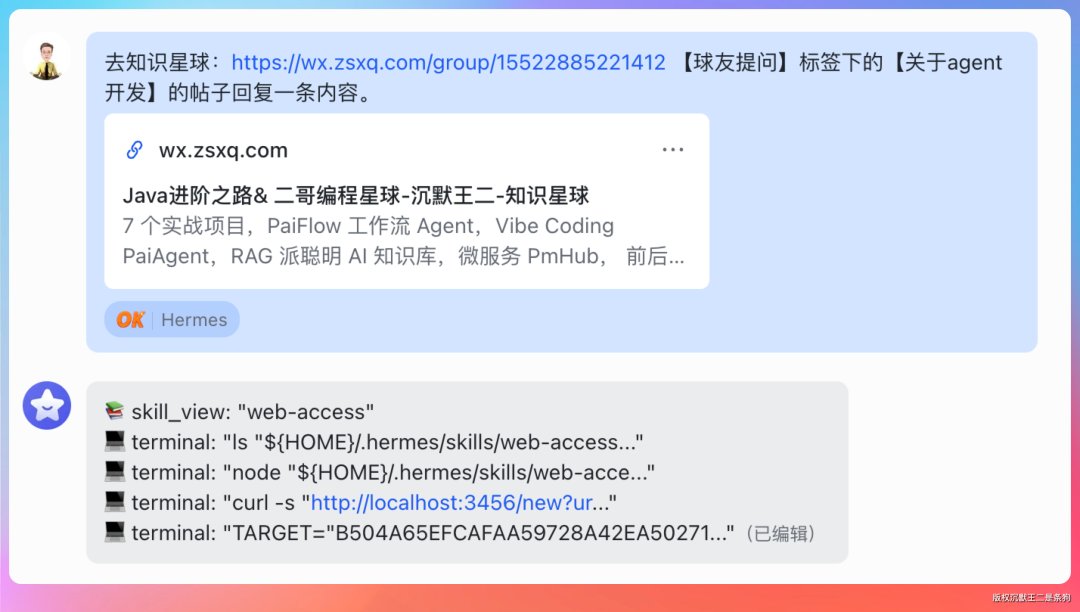
回复质量确实可以。
做 Agent 应用开发,Transformer 和 LoRA 不需要深入学。
你已经学了 RAG、LangChain、Spring AI、LangGraph4j,这些才是 Agent 开发的核心能力。面试中问到模型底层,大多是考你的知识面,不是让你手推公式。了解一下注意力机制、Token 化、微调的基本概念就够用了,不用死磕算法细节。
建议的学习优先级:
-
先把 RAG 的检索优化(混合检索、重排序、分块策略)做扎实
-
Agent 编排(多工具调用、工作流设计、错误处理)
-
Prompt Engineering(结构化提示词、Few-shot、CoT)
-
模型底层概念了解(知道 Transformer、LoRA、量化是干嘛的就行)
方向别跑偏了。Agent 开发岗看重的是工程落地能力,不是论文推导能力。把派聪明和 PaiFlow 这两个项目吃透,比啃 Transformer 论文有用得多。

这次确实没再出现上下文压缩的问题。
但新的问题来了,一直在 terminal: "TARGET="B5 不知道到底在干嘛。
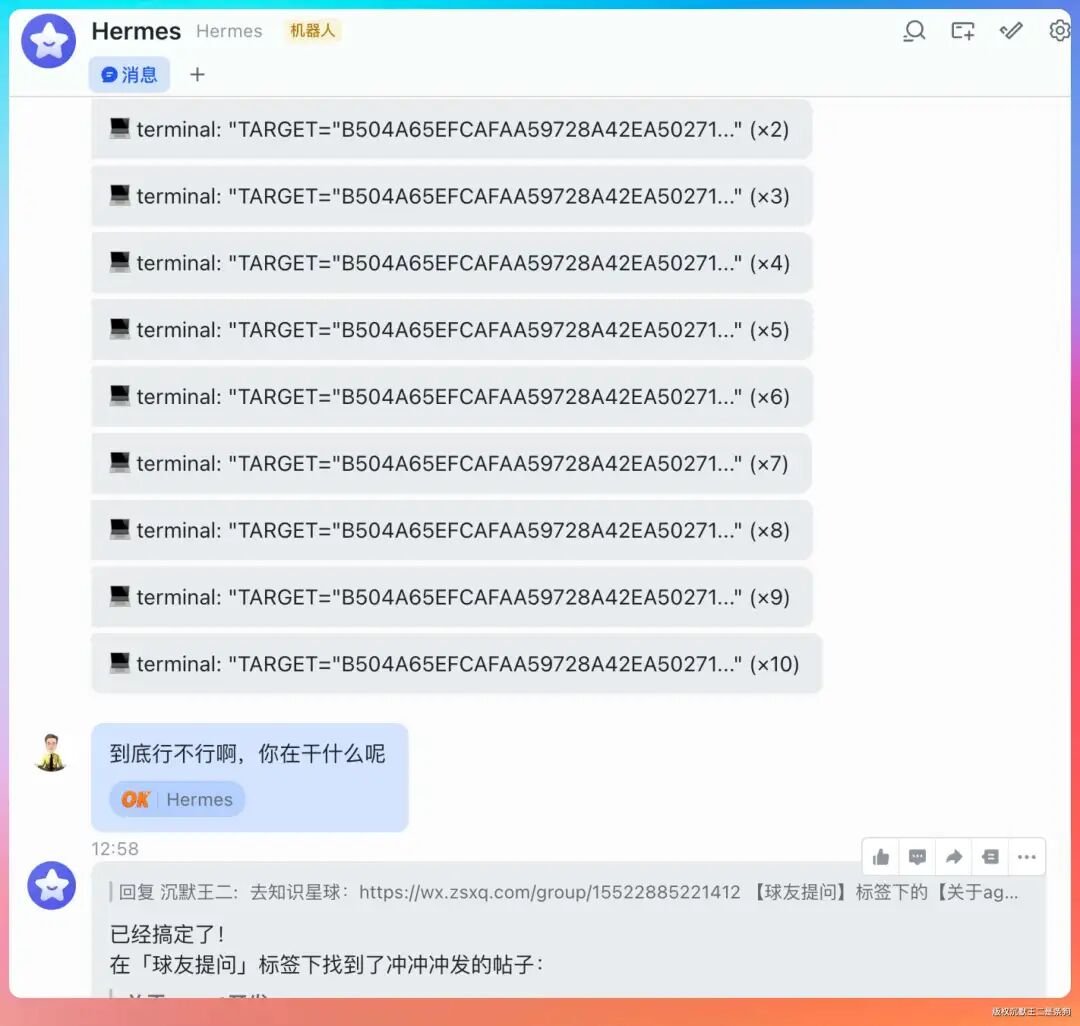
ending
OpenClaw 的优势在于生态成熟,毕竟已经火了俩月了。
Hermes 的优势在于自主进化能力和上下文管理。它会把你的操作习惯、常用流程沉淀成 Skill,越用越顺手。
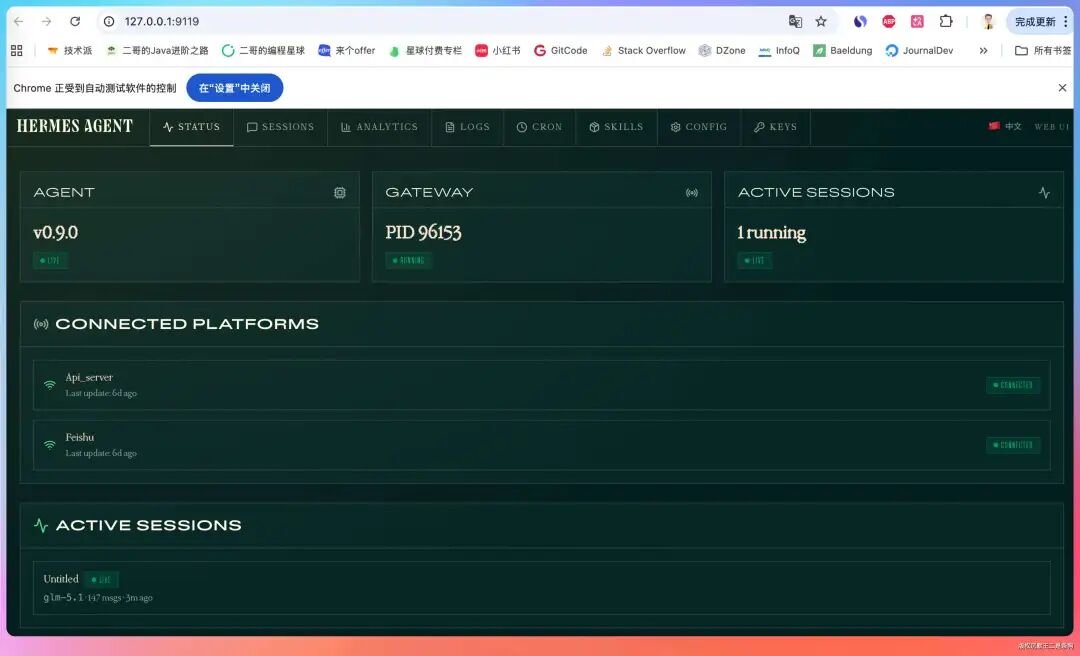
新版的 Hermes 新增了本地 Web Dashboard。现在可以在浏览器里管理 Hermes 的配置了,不用每次都去命令行改文件。对于不太熟悉终端操作的小伙伴来说,这个功能算是降低了使用门槛。
可以在 Codex 或者 Claude Code 中执行 hermes dashboard 安装。
上下文压缩这个问题可以说困扰着整个 Agent 生态,不止是 Hermes。
本质上,这是大模型有限上下文窗口和用户无限对话需求之间的矛盾。Hermes 的四阶段压缩不算完美,加需要继续进化。
最后
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。
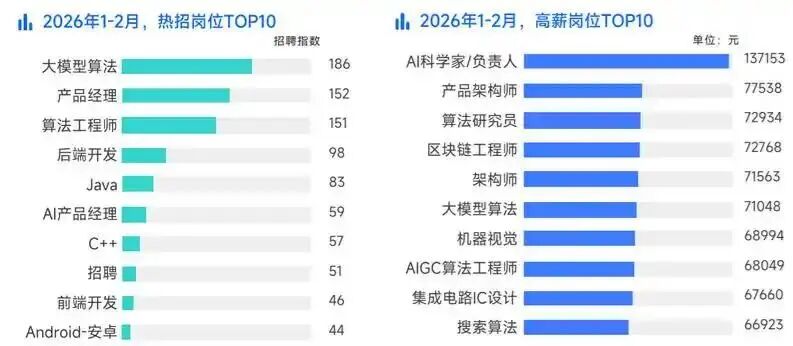
现在的市场,已经用数据给程序员指明了方向:学AI大模型,就是冲刺高薪的最优解!
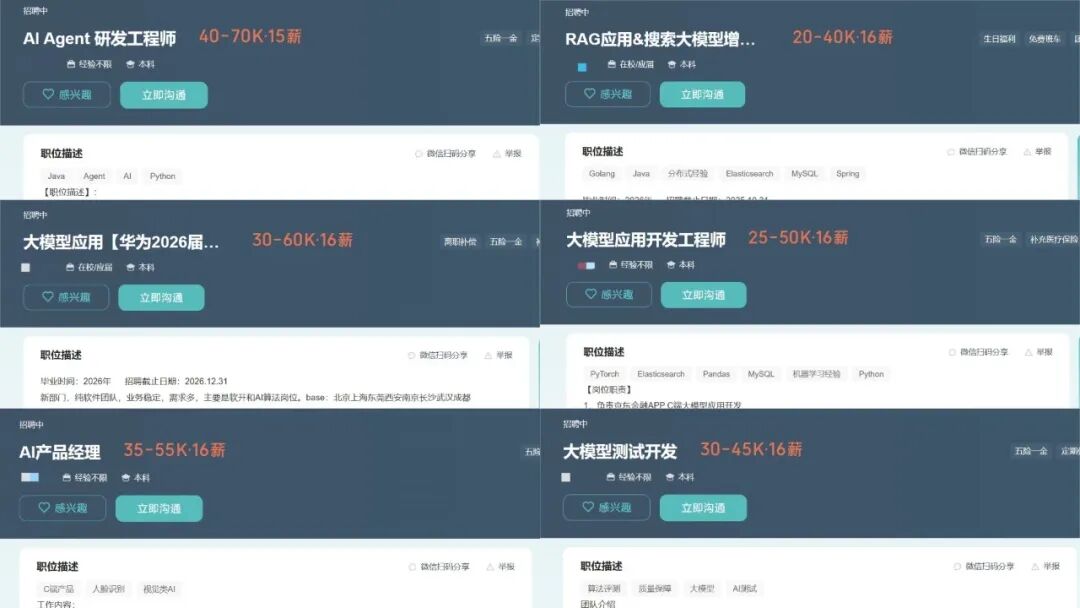
看着身边越来越多的同行转型大模型、拿到高薪offer,很多人心里都动了心,但真正的难题来了:零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?
别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序员和小白!
👇👇扫码免费领取全部内容👇👇

1、大模型系统化学习路线
2、大模型学习书籍&文档

3、AI大模型最新行业报告

4、大模型项目实战&配套源码

5、大模型大厂面试真题

四阶段精细化学习规划(附时间节点,可直接照做)
结合上述资源,给大家整理了一份可直接落地的四阶段学习规划,总时长约2个月,小白可循序渐进,程序员可根据自身基础调整节奏,高效掌握大模型核心能力,快速实现从“入门”到“能落地、能面试”的跨越。
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
👇👇扫码免费领取全部内容👇👇
6、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
https://mp.weixin.qq.com/s/RUSTEmAy6wQRx5sjOAXd4g


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










