




词元
词元和嵌入是使用LLM的两个核心概念。
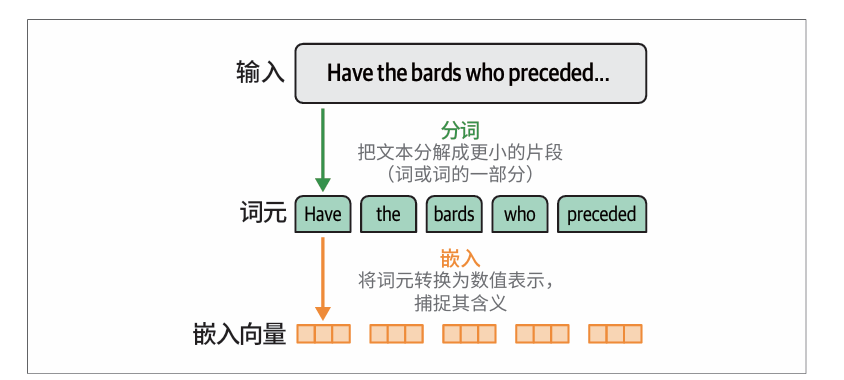
语言模型处理文本时会将其分成小块,称为词元。为了理解自然语言,语言模型需要将词元转换为数值表示,即嵌入向量。
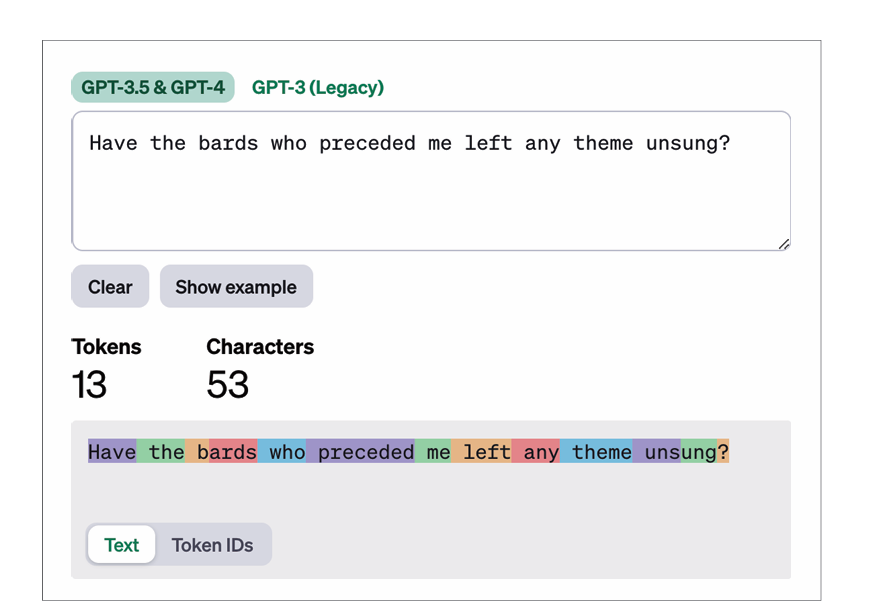
什么是语言模型?生成式LLM接收输入提示词并生成响应:

但在这之前它首先要通过分词器将其分解成片段
如GPT的分词效果是这样的:
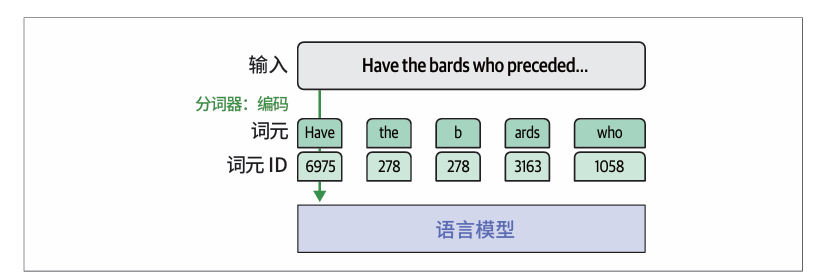
每个整数都是特定词元(字符、词或词的一部分)的唯一ID。这些ID是分词器内部的一张词元表的索引,该表包含了分词器能够识别的所有词元。
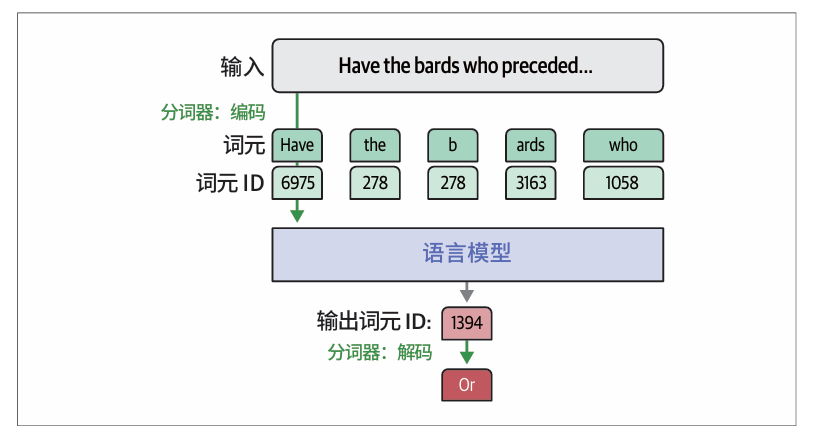
在上述例子中,模型生成了词元278(b),接着是词元3163(ards)。它们一起组成了 bards 这个词。就像输入端一样,我们需要分词器在输出端将词元ID转换为实际文本。我们使用分词器的decode方法来实现这一点。我们可以传入单个词元ID或它们的列表:
print(tokenizer.decode(278))
print(tokenizer.decode(3163))
print(tokenizer.decode([278, 3163]))
输出:
b
ards
bards
分词器
决定分词器如何分解输入提示词的因素主要有三个。
- 首先,在模型设计时,模型创建者会选择一种分词方法。流行的方法包括字节对编码(BPE,byte pair encoding,广泛用于 GPT 模型)和WordPiece(用于BERT模型)。这些方法的相似之处在于,它们都旨在找到一组尽可能高效的词元来表示文本数据集,但它们采用不同的方式实现这一目标。
- 其次,在选择方法之后,我们需要做出一些分词器设计选择,如词表大小和使用哪些特殊词元。
- 最后,分词器需要在特定数据集上进行训练,以建立能最好地表示该数据集的词表。即使我们设置相同的方法和参数,在英语文本数据集上训练的分词器也会与在代码数据集或多语言文本数据集上训练的分词器不同。
除了把输入文本处理成语言模型的输入外,分词器还负责处理语言模型的输出,将生成的词元ID转换为与之关联的输出词或词元:
分词方式
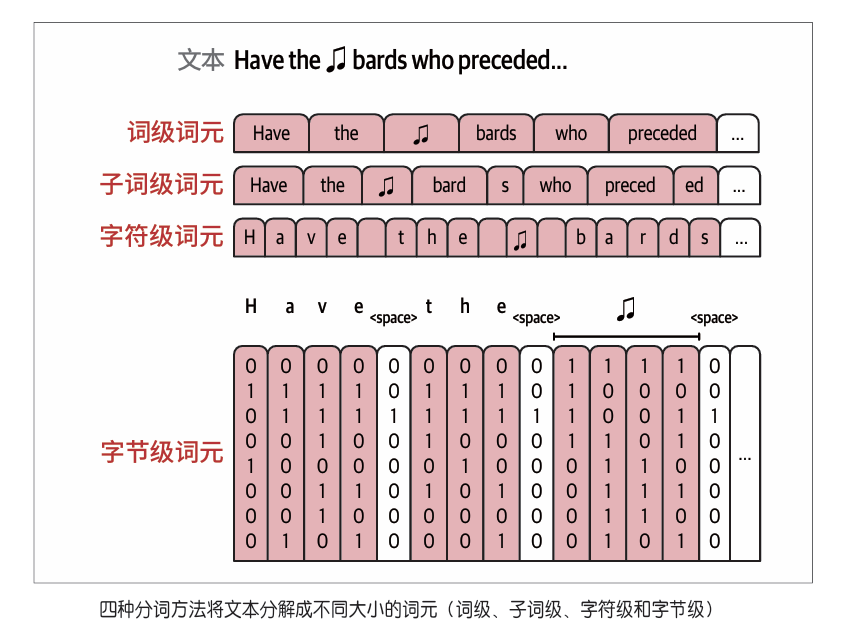
比较不同分词器
分词器中出现的词元是由三个主要因素决定的:分词方法、用于初始化分词器的参数和特殊词元,以及用于训练分词器的数据集。
我们使用多个分词器来编码以下文本:

由此,我们能够看到每个分词器是如何处理不同类型的词元的:
- 大小写
- 英语以外的语言
- 表情符号(emoji)
- 编程代码,包括关键字和经常用于缩进的空白字符(例如在Python等语言中)
- 数字
- 特殊词元。这类词元具有特定的作用,而不仅仅表示文本。它们包括表示文本开始或结束的词元(模型用结束词元来向系统表明已完成生成),以及我们随后将看到的其他功能性词元
1. BERT 基座模型(大小写不敏感)( 2018)
分词方法:WordPiece
词表大小:30 522

2. BERT 基座模型(大小写敏感)( 2018)
分词方法:WordPiece
词表大小:28 996

3. GPT-2(2019)
分词方法:BPE
词表大小:50 257

4. FLAN-T5(2022)
分词方法:SentencePiece
词表大小:32 100

5. GPT-4(2023)
分词方法:BPE
词表大小:略多于100 000

6. StarCoder2(2024)
分词方法:BPE
词表大小:49 152

7. Galactica
分词方法:BPE
词表大小:50 000

嵌入
嵌入的作用是用于捕捉语言中含义和模式的数值表示空间。
词元嵌入
分词器经过初始化和训练,就会在其关联的语言模型的训练过程中使用。这就是为什么预训练语言模型与其分词器绑定,在未经训练的情况下不能使用不同的分词器。
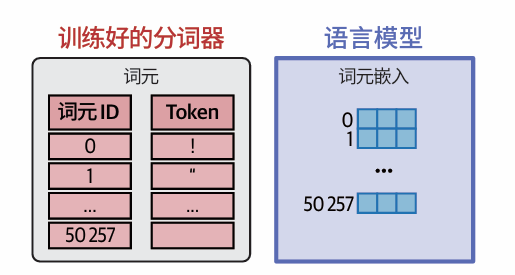
语言模型会创建与上下文相关(contextualized)的词嵌入
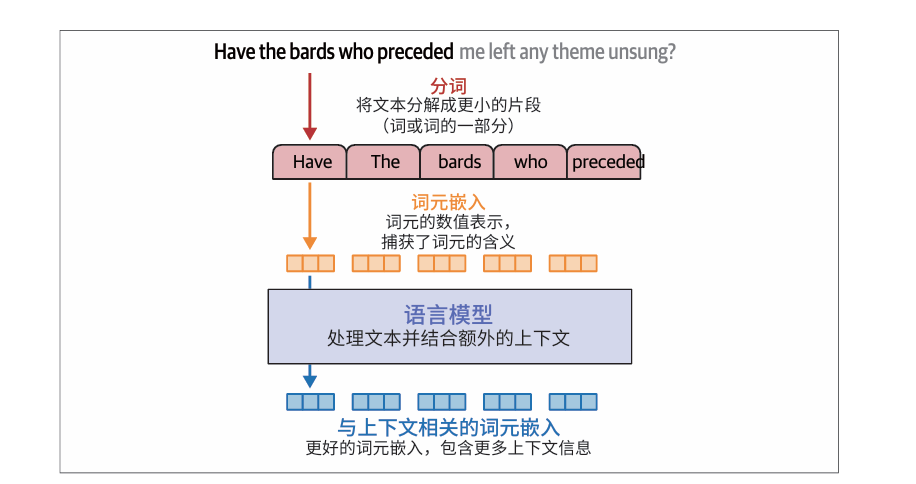
文本嵌入
虽然词元嵌入是LLM运作的关键,但许多LLM应用需要处理完整的句子、段落甚至文本文档,这催生了一些特殊的语言模型,它们能够生成文本嵌入——用单个向量来表示长度超过一个词元的文本片段。
除此之外还有很多LLM之外的很多嵌入方式,比如:
- word2vec 创建词嵌入
- 推荐系统中的嵌入
- …
总结:分词器设计中有三个主要决策点:分词器算法(如BPE、WordPiece、SentencePiece)、 分词参数(包括词表大小、特殊词元、大小写处理策略和不同语言的处理)以及用于训练分词器的数据集。
补充内容:专业词汇
词元嵌入(token embedding)
字节对编码(BPE,byte pair encoding,广泛用于 GPT 模型)
子词级分词(subword tokenization)
命名实体识别(named entity recognition,NER)
上下文相关(contextualized)



















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












