




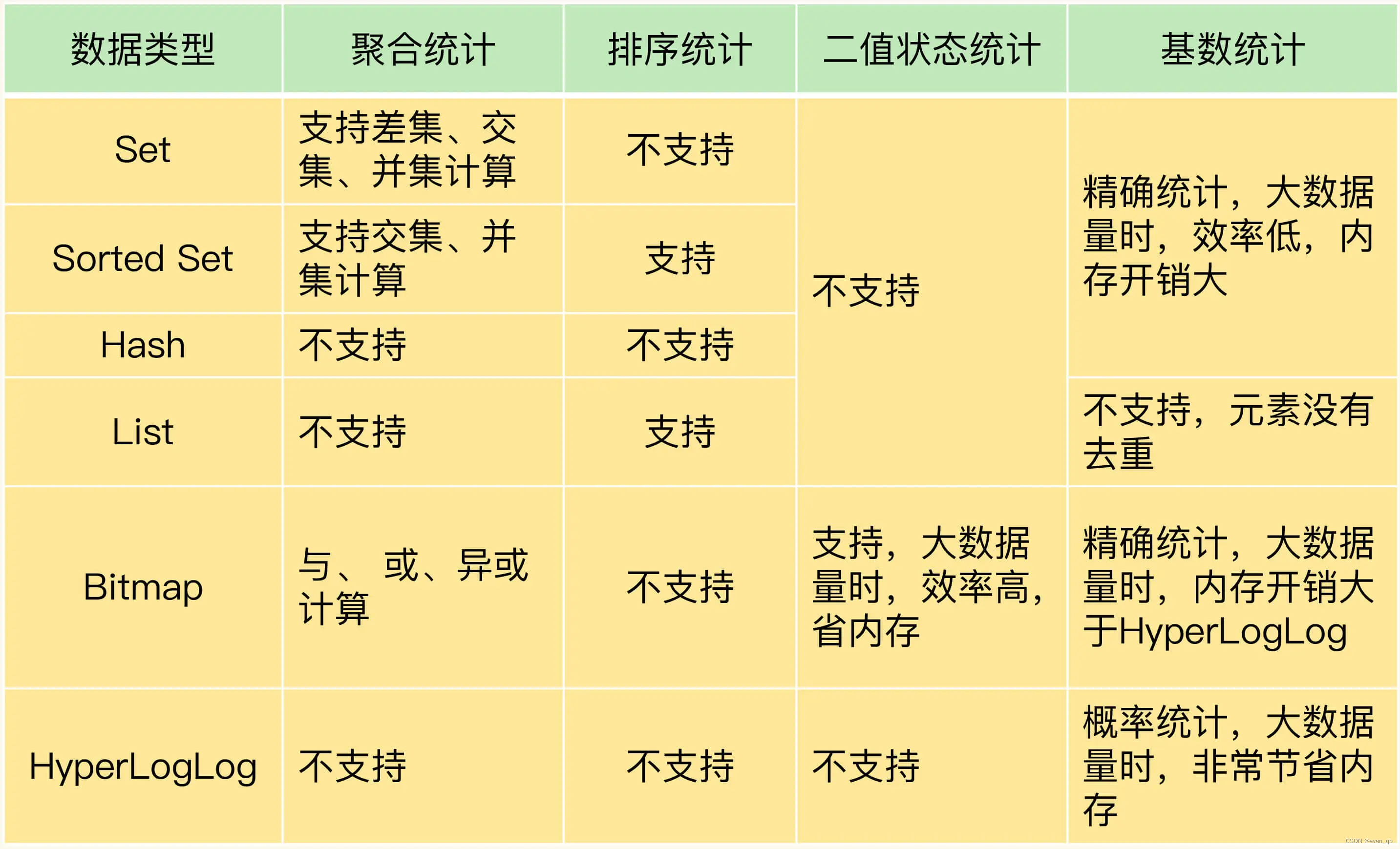
1. 常见功能介绍
聚合统计
使用list集合的差集、并集来统计
排序统计
SortedSet(ZSet)统计,再利用分页列出权重高的元素
二值状态统计
BitMap存储,获取并统计
SETBIT uid:sign:3000:202008 2 1
GETBIT uid:sign:3000:202008 2 统计8月份签到情况
BITCOUNT uid:sign:3000:202008基数统计
数据量小的时候可以用Set或hash
数据量大的时候可以HyperLogLog
PFADD page1:uv user1 user2 user3 user4 user5
PFCOUNT page1:uv注意:HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。这也就意味着,你使用 HyperLogLog 统计的 UV 是 100 万,但实际的 UV 可能是 101 万。虽然误差率不算大,但是,如果你需要精确统计结果的话,最好还是继续用 Set 或 Hash 类型。
2. 一个键值数据库应该包含什么?
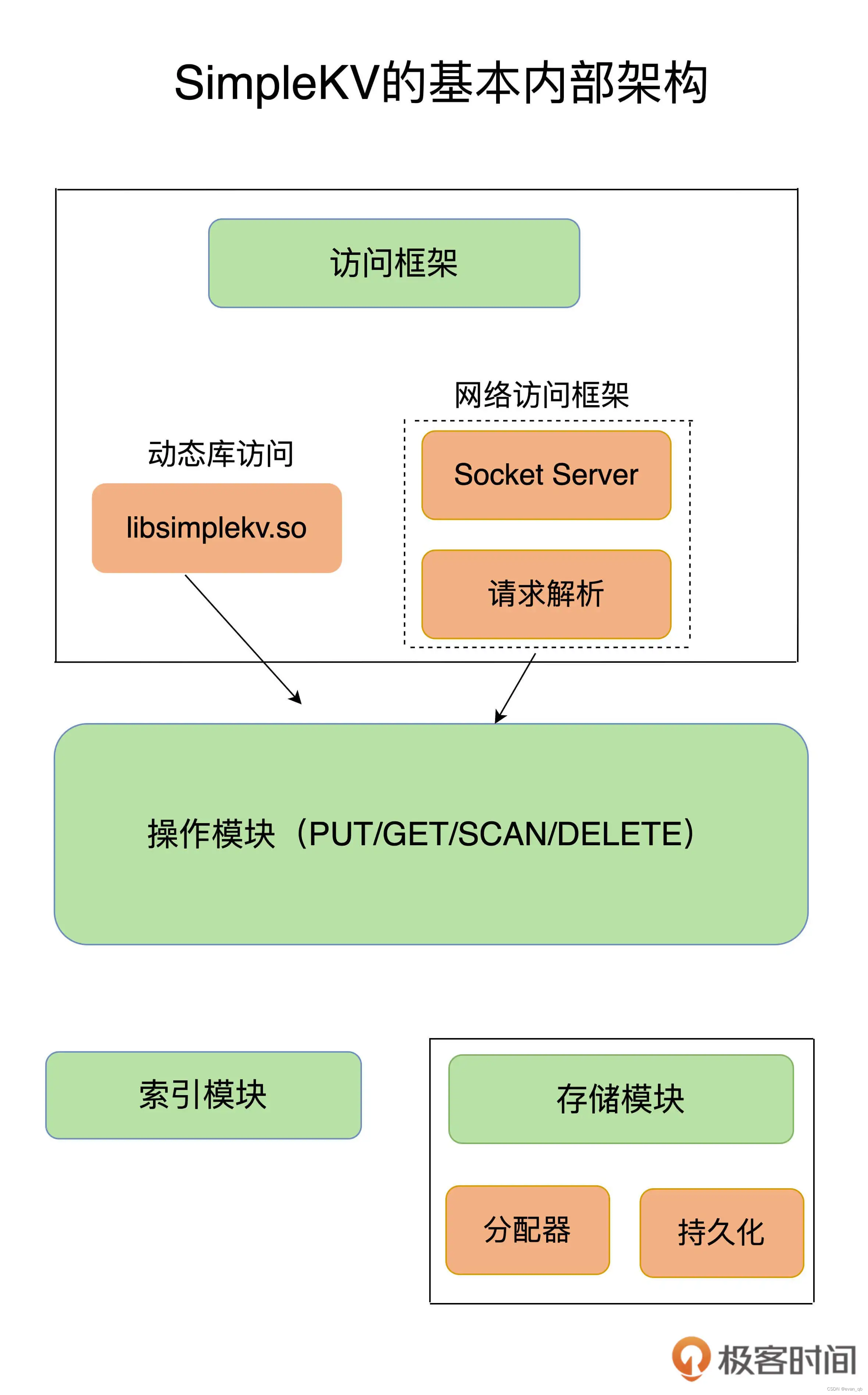
Redis 主要通过网络框架进行访问,而不再是动态库了,这也使得 Redis 可以作为一个基础性的网络服务进行访问,扩大了 Redis 的应用范围。
Redis 的持久化模块能支持两种方式:日志(AOF)和快照(RDB),这两种持久化方式具有不同的优劣势,影响到 Redis 的访问性能和可靠性。
Redis 支持高可靠集群和高可扩展集群,因此,Redis 中包含了相应的集群功能支撑模块。
3. redis常见的数据结构
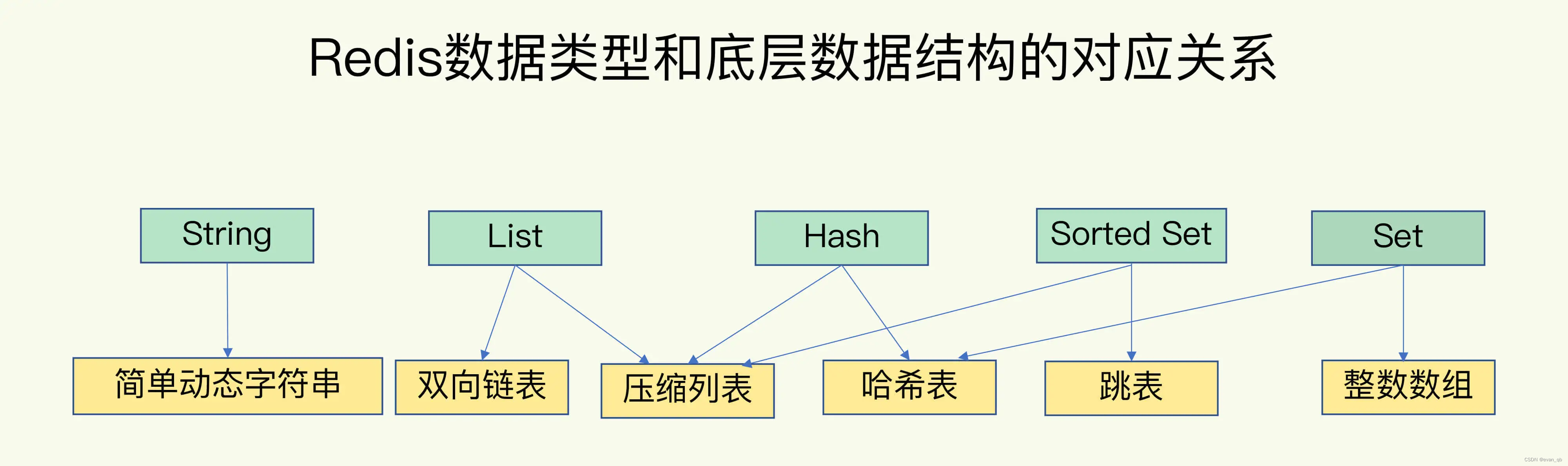
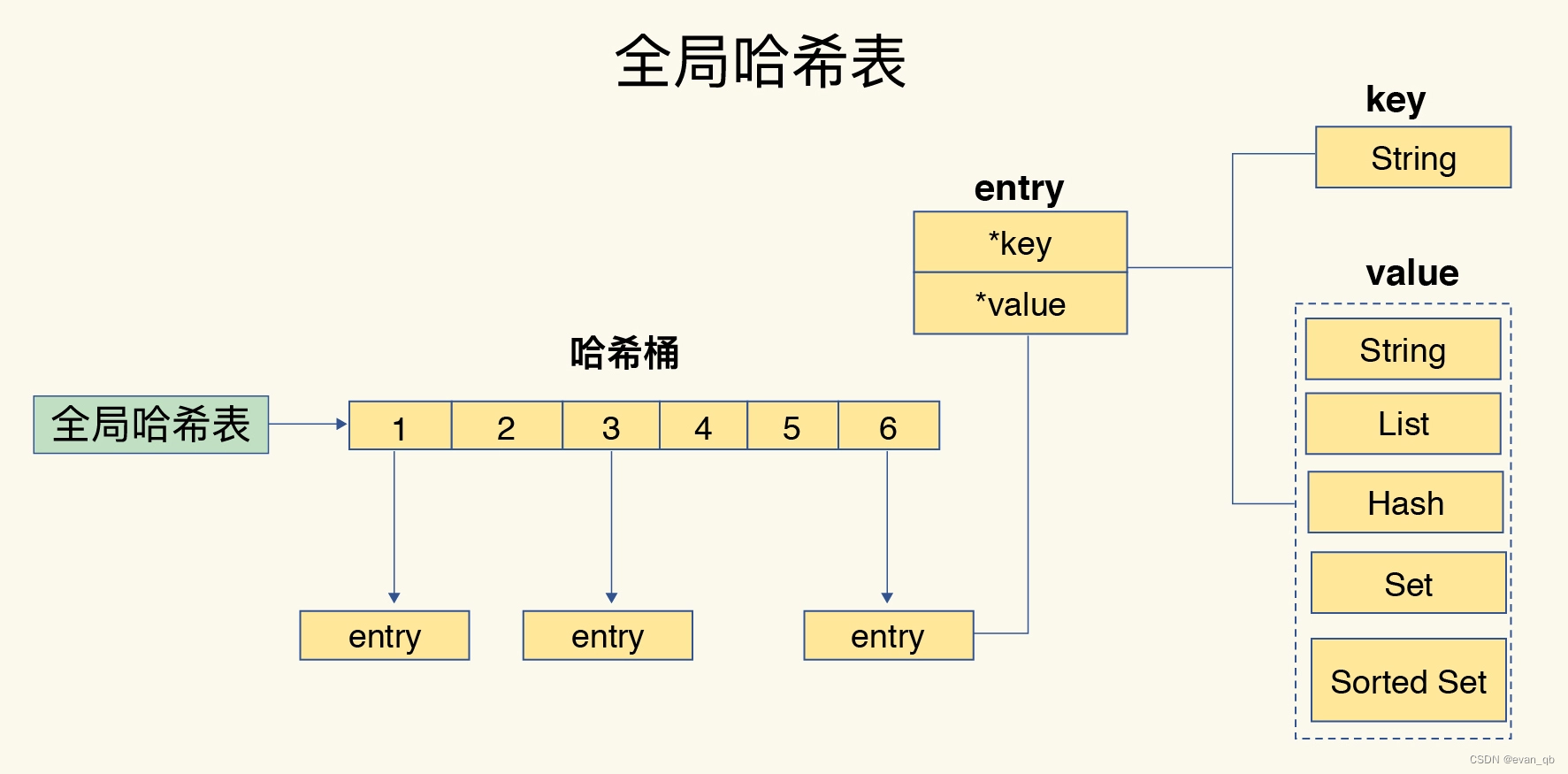
redis渐进式rehash
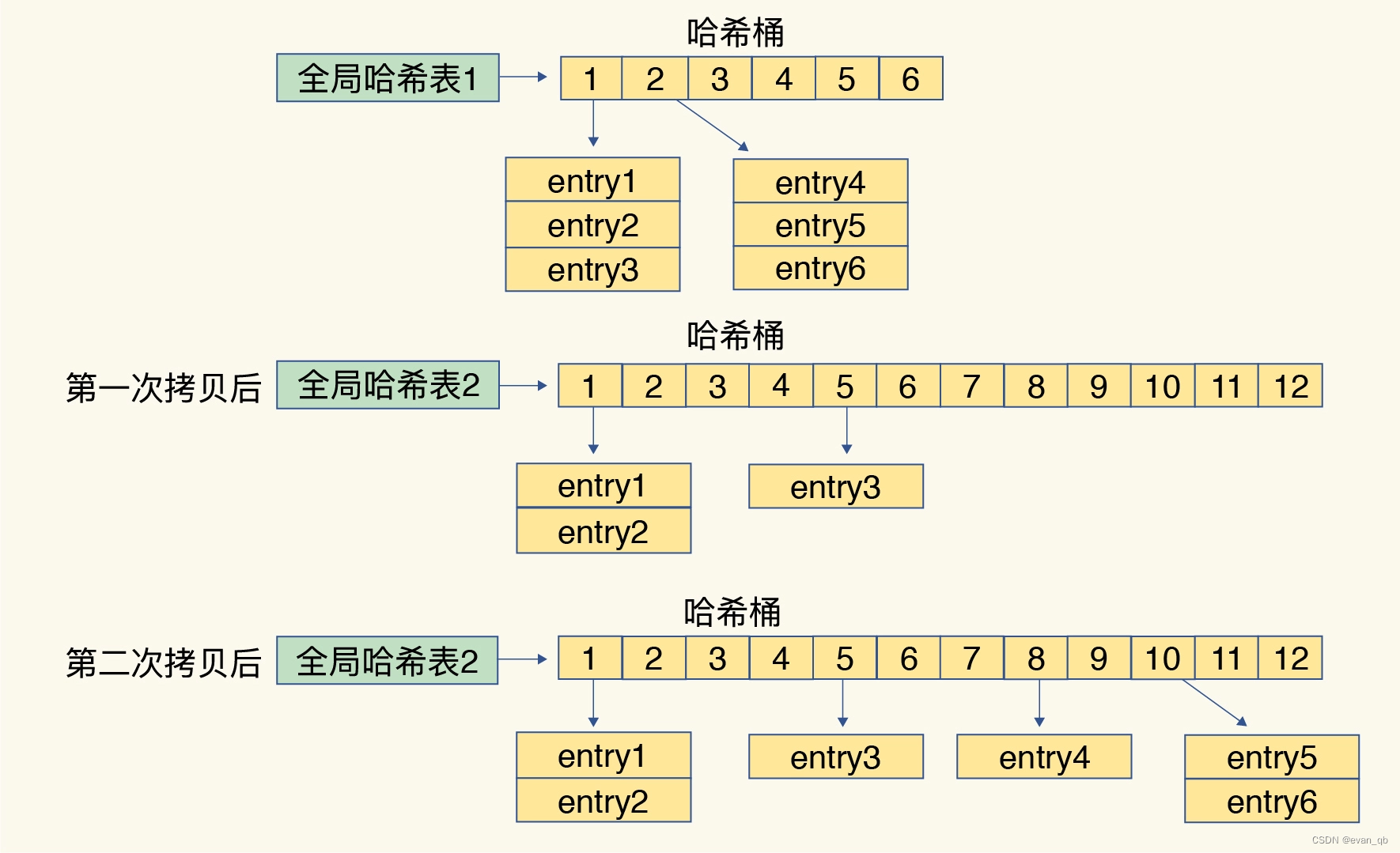
压缩列表

zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数
第一个元素和最后一个元素复杂度为O(1),其他为O(N)
跳表
在链表的基础上加了多级索引
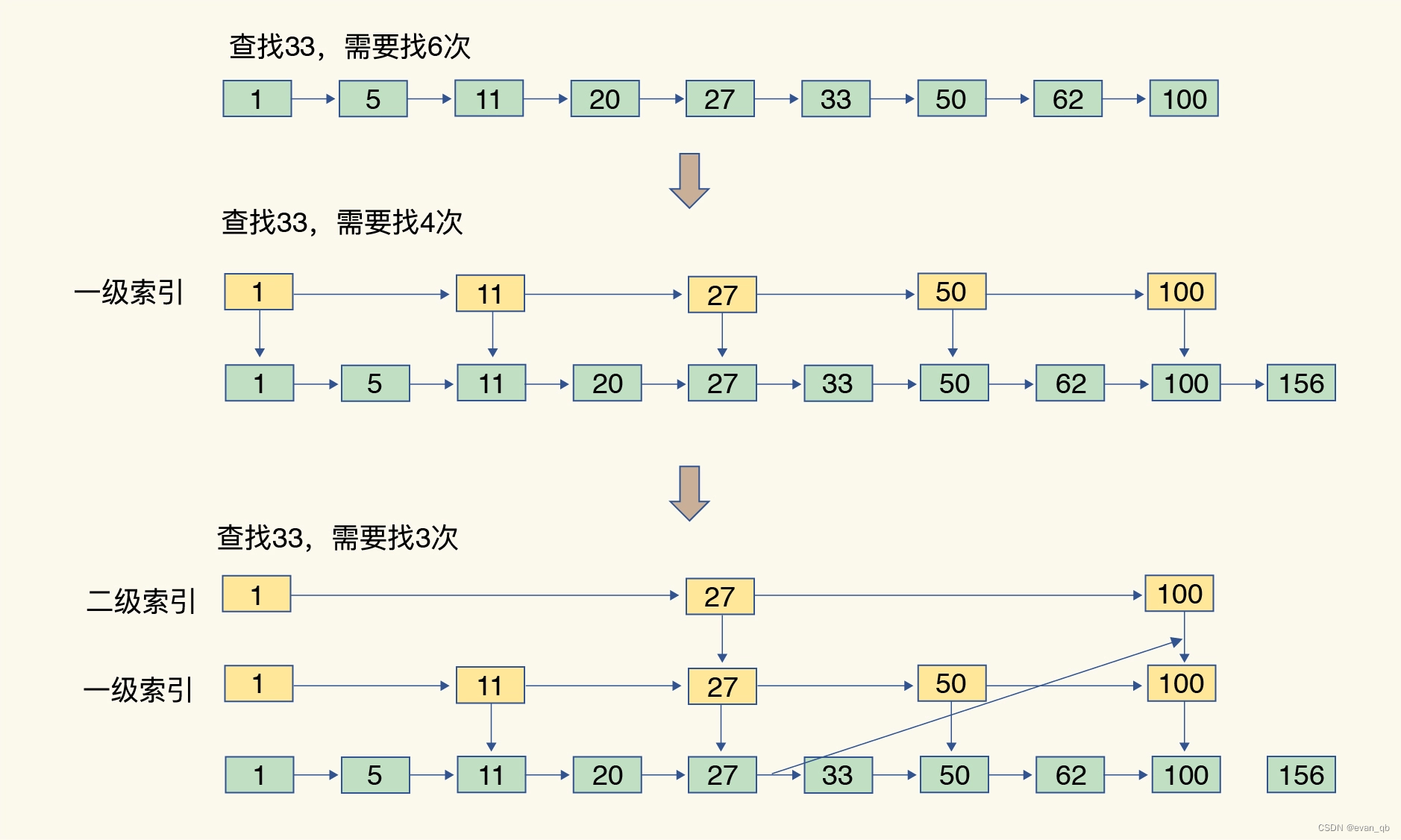
查找复杂度为O(logN)
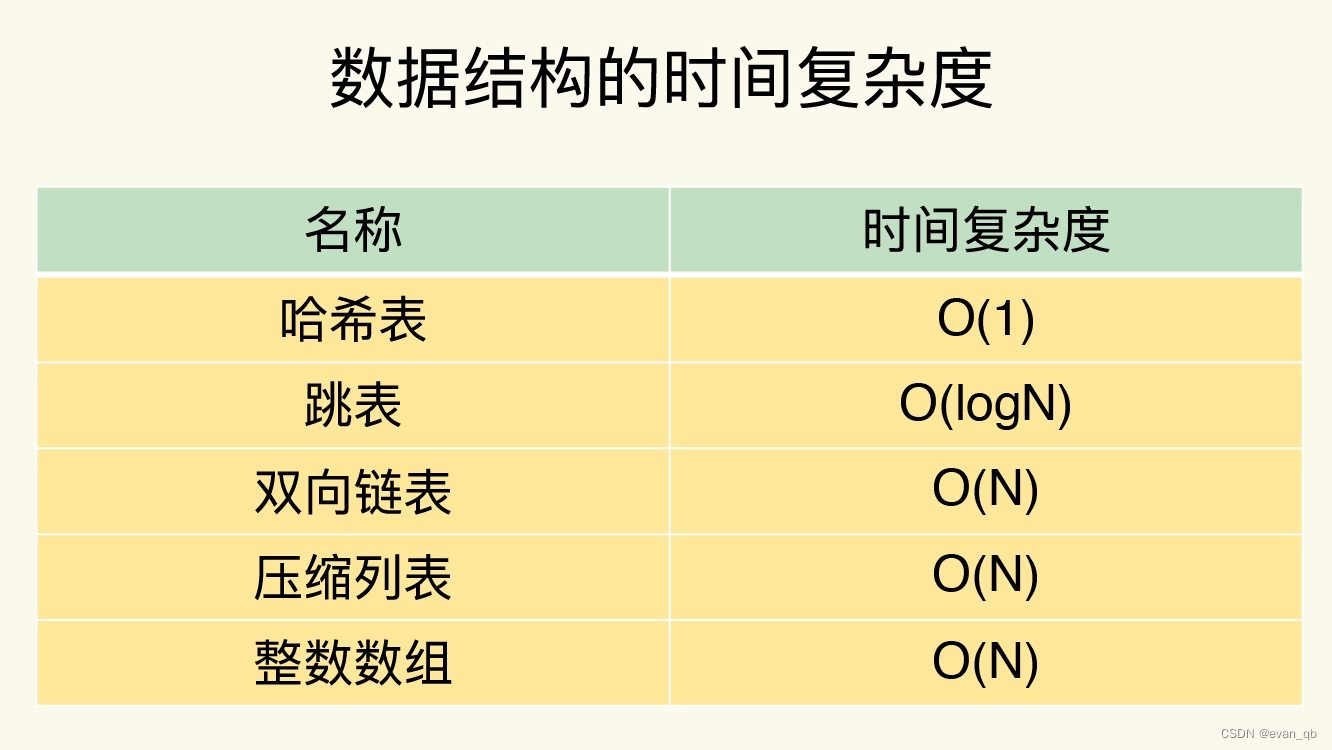
思考
整数数组和压缩列表在查找时间复杂度方面并没有很大的优势,那为什么 Redis 还会把它们作为底层数据结构呢?
1、内存利用率,数组和压缩列表都是非常紧凑的数据结构,它比链表占用的内存要更少。Redis是内存数据库,大量数据存到内存中,此时需要做尽可能的优化,提高内存的利用率。
2、数组对CPU高速缓存支持更友好,所以Redis在设计时,集合数据元素较少情况下,默认采用内存紧凑排列的




















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










