



 大模型的价格已经打了下来。百万Token输入低至0.025元,部分开源模型直接免费。
大模型的价格已经打了下来。百万Token输入低至0.025元,部分开源模型直接免费。
按理说,开发者的调用成本应该大幅下降。但实际情况是,很多团队的月费不降反升。
原因就一个字:用量。Agent场景、长上下文、多轮对话,每次调用的Token量是两年前的几十倍。价格降了10倍,用量涨了20倍,账单反而更厚了。
选对模型是第一步,真正拉开差距的,是调用策略。
今天聊三个实操手段:缓存、路由、降级。
第一斧:缓存——别为重复内容重复付费
很多人没意识到一个事实:你的API调用里,有大量重复内容。
比如客服场景,用户问"退款流程是什么",这个问题的前缀、系统提示词、历史上下文,每天可能被重复发送上千次。每一份重复的Token,都在浪费钱。
语义缓存是解决这个问题最直接的方式。
核心思路:把之前请求过的输入和输出存下来,下次遇到相似输入时,直接返回缓存结果,跳过模型调用。
实测数据:在一个日均5000次调用的客服系统中,引入语义缓存后,缓存命中率稳定在35%到45%,月均成本直接降了40%。
几个落地建议:
缓存时间窗口根据业务设定,时效性强的数据设置短缓存(5-15分钟),通用知识类可以设长一些
相似度阈值不要设太高,0.85左右就能覆盖大部分重复请求,避免误匹配
注意区分用户隐私数据,涉及敏感信息的请求不建议缓存
第二斧:路由——不同任务用不同模型
缓存能解决重复调用的问题。但如果你每次都是全量调用模型,只是内容不同,缓存也帮不了你。
这时候就轮到智能路由出场了。
简单来说就是:根据任务的复杂度、实时性要求、成本预算,自动把请求分发到不同的模型上。
举个实际场景:
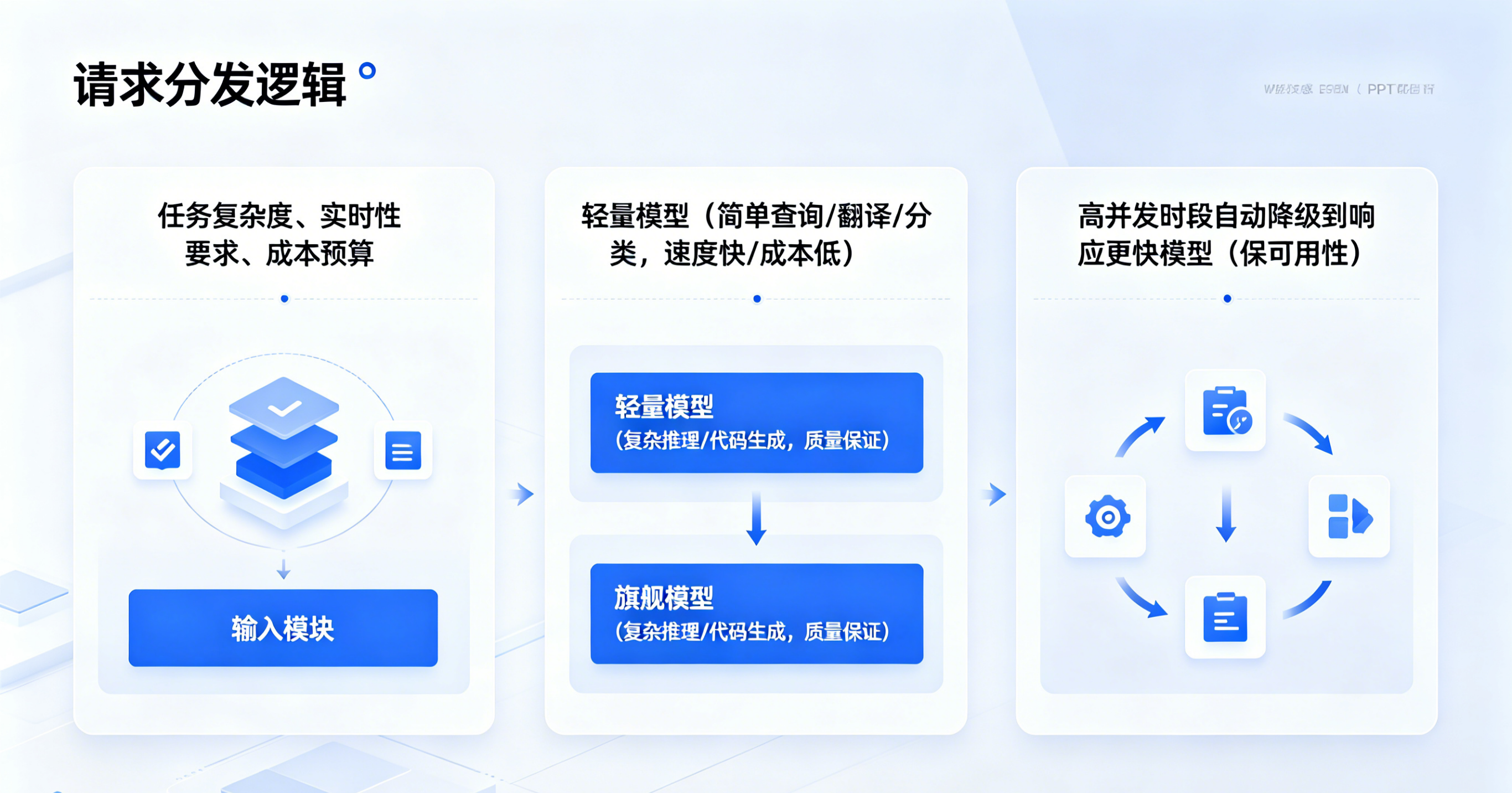 简单查询、翻译、分类 → 走轻量模型,速度快、成本低
简单查询、翻译、分类 → 走轻量模型,速度快、成本低
复杂推理、代码生成 → 走旗舰模型,质量有保证
高并发时段 → 自动降级到响应更快的模型,保可用性
这套路由逻辑如果自己做,需要写不少代码。但现在有不少现成的大模型API聚合平台已经把这些能力封装好了。
比如器灵模型广场,DeepSeek、Kimi、Qwen、GLM等主流模型都在一个入口,支持AI模型统一接口调用。你不需要挨个对接不同模型的SDK和计费体系,一个接口搞定。
当前全免费,特别适合拿来跑路由策略的对比测试。
第三斧:降级——关键时刻不能掉链子
缓存和路由解决的是"平时"的成本问题。但还有一种隐性成本很多人忽略了:故障成本。
模型服务不可用的时候,你的业务怎么办?
去年某段时间,某个头部大模型API连续宕机两小时。没有降级策略的团队,直接业务中断;有降级策略的,几秒内自动切到备用模型,用户甚至没感知到异常。
降级策略的核心设计:
主模型不可用时,自动切换到能力相近的备用模型
设置多级降级链:旗舰模型 → 同类平替模型 → 轻量模型(降质保可用)
关键业务设置超时熔断,避免排队堆积
如果你已经接入了多模型API切换能力,降级的实现成本会低很多。
器灵模型广场这类平台本身就是一个天然的降级池——里面200+模型API接入,一个接口,随时可以切。不需要提前跟每个供应商签约、充值、维护连接。
当你的路由策略检测到主模型响应变慢或报错时,直接把流量导到另一个模型上,整个过程对用户透明。
三板斧怎么组合?
实际落地的时候,三板斧不是单独用的,而是组合拳。
一个典型的请求处理链路:
请求进来,先查缓存 → 命中则直接返回,不调用模型
缓存未命中,进入路由层 → 根据任务类型和预算分发到对应模型
模型调用失败或超时 → 触发降级,切换到备用模型
成功返回结果 → 写入缓存,供后续请求复用
这套链路搭建好之后,效果是叠加的。缓存削掉了重复调用的费用,路由让每一分钱花在刀刃上,降级保证了极端情况下的可用性。
算一下账
假设你的业务当前月均调用100万次,平均每次2000 Token输入:
无优化方案:全部走旗舰模型,月成本约1200元
仅缓存优化:命中率40%,月成本降至约720元
缓存+路由:40%命中缓存,30%走轻量模型,月成本降至约420元
缓存+路由+降级:加上故障兜底,可用性从99%提升到99.9%,额外成本几乎为零
三板斧全上,成本降65%,可用性大幅提升。
这笔账,值不值,一目了然。
优化API调用成本这件事,说到底是一个思路:用更聪明的方式,用更少的资源,产出更高的价值。
模型会越来越便宜,但好的调用策略,永远稀缺。先把三板斧搭起来,比纠结选哪个模型重要得多。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










