





什么是 Protobuf?
Protobuf(Protocol Buffers)是 Google 开发的一种高效的结构化数据序列化工具,可用于数据存储、通信协议等场景。相比 JSON/XML,它的优势是:
- 体积更小:二进制编码,数据压缩率高;
- 解析更快:无需解析字符串,效率是 JSON 的 5-10 倍;
- 跨语言兼容:支持 C++、Python、Java 等多种语言;
- 可扩展性强:新增字段不影响旧版本解析。
一、环境搭建(Ubuntu 系统)
- 安装依赖工具
sudo apt update
sudo apt install -y build-essential autoconf libtool pkg-config
- 安装 Protobuf 编译器和 C++ 库
推荐从源码编译(版本较新,兼容性更好):
# 下载源码(以 3.20.3 为例,可替换为最新版本)
wget https://github.com/protocolbuffers/protobuf/releases/download/v3.20.3/protobuf-all-3.20.3.tar.gz
# 解压并编译
tar -zxvf protobuf-all-3.20.3.tar.gz
cd protobuf-3.20.3
./configure --prefix=/usr/local # 安装到系统目录
make -j4 # 4线程加速编译
sudo make install
sudo ldconfig # 刷新动态链接库
# 验证安装(输出版本号即成功)
protoc --version # 应显示:libprotoc 3.20.3
二、Protobuf 核心语法(proto3)
Protobuf 通过 .proto 文件定义数据结构,语法简洁,核心要素如下:
- 基础结构
protobuf
syntax = "proto3"; // 声明使用 proto3 语法(必须第一行)
package example; // 命名空间,避免类名冲突
// 定义消息(数据结构)
message 消息名 {
类型 字段名 = 标签号; // 标签号:1~53,不可重复,用于二进制编码
}
-
常用类型对应表
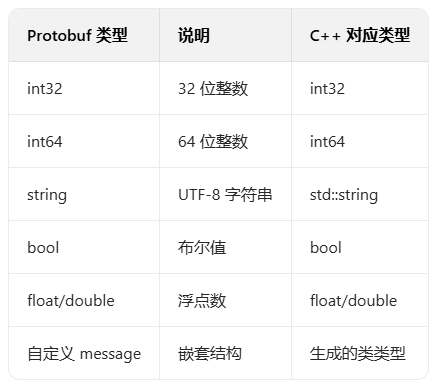
-
字段修饰符
- repeated:字段可重复(类似 C++ 的 vector);
- (默认)optional:字段可存在或不存在,未设置时用默认值(如 0、空字符串)。
- 示例:定义一个 Person 消息
创建 person.proto 文件:
syntax = "proto3";
package example; // 生成 C++ 代码时会转为 namespace example
// 人员信息
message Person {
int32 id = 1; // 标签号 1
string name = 2; // 标签号 2
string email = 3; // 标签号 3
bool is_student = 4; // 标签号 4
}
// 人员列表(包含多个 Person)
message PersonList {
repeated Person persons = 1; // repeated 表示列表
}
三、编译 .proto 文件生成 C++ 代码
使用 protoc 编译器将 .proto 转为 C++ 代码:
# 命令格式:protoc --cpp_out=输出目录 文件名.proto
protoc --cpp_out=. person.proto # 输出到当前目录
执行后生成两个文件:
- person.pb.h:头文件,包含类定义(example::Person、example::PersonList);
- person.pb.cc:源文件,包含类的实现代码(无需手动修改)。
四、C++ 代码编写(序列化与反序列化)
- 核心操作流程
- 序列化:将内存中的对象转为二进制数据(用于存储 / 传输);
- 反序列化:将二进制数据解析为内存中的对象(用于读取)。
- 示例代码
创建 main.cpp:
#include <iostream>
#include <fstream>
#include <string>
#include "person.pb.h"
using namespace example;
int main() {
GOOGLE_PROTOBUF_VERIFY_VERSION;
// 1. 序列化:写入文件(关键:写完后关闭流)
Person person1;
person1.set_id(1001);
person1.set_name("Alice");
person1.set_email("alice@example.com");
person1.set_is_student(true);
Person person2;
person2.set_id(1002);
person2.set_name("Bob");
person2.set_email("bob@example.com");
person2.set_is_student(false);
PersonList person_list;
*person_list.add_persons() = person1;
*person_list.add_persons() = person2;
// 序列化:打开文件并写入,写完后关闭流(避免流占用导致后续读取失败)
std::fstream output("person_data.bin", std::ios::out | std::ios::binary);
if (!person_list.SerializeToOstream(&output)) {
std::cerr << "序列化失败!" << std::endl;
return -1;
}
output.close(); // 关键:关闭输出流,释放文件资源
std::cout << "序列化成功,数据已写入 person_data.bin" << std::endl;
// 2. 反序列化:重新打开文件读取(关键:用新的输入流,从开头读取)
PersonList new_person_list;
// 重新打开文件,模式为“读+二进制”,确保流位置在文件开头
std::fstream input("person_data.bin", std::ios::in | std::ios::binary);
if (!input.is_open()) { // 新增:检查文件是否成功打开
std::cerr << "无法打开文件 person_data.bin!" << std::endl;
return -1;
}
if (!new_person_list.ParseFromIstream(&input)) {
std::cerr << "反序列化失败!" << std::endl;
input.close();
return -1;
}
input.close(); // 关闭输入流
// 3. 打印数据(确保循环逻辑正确)
std::cout << "\n反序列化后的数据:" << std::endl;
// 用 persons_size() 获取列表长度,循环遍历
for (int i = 0; i < new_person_list.persons_size(); ++i) {
const Person& p = new_person_list.persons(i);
std::cout << "ID: " << p.id()
<< ", Name: " << p.name()
<< ", Email: " << p.email()
<< ", Is Student: " << (p.is_student() ? "Yes" : "No")
<< std::endl;
}
google::protobuf::ShutdownProtobufLibrary();
return 0;
}
五、编译与运行
- 编译代码
使用 g++ 编译,需链接 Protobuf 库:
g++ main.cpp person.pb.cc -o proto_demo `pkg-config --cflags --libs protobuf`
- 说明:pkg-config --cflags --libs protobuf 自动引入 Protobuf 的头文件和库路径。
- 运行程序
./proto_demo
成功输出:





















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












