





企业做 Agent 试点,第一阶段通常推进得很快。接一个大模型,挂几个工具,补一批业务知识,再做一个对话入口,团队很快就能看到效果。
麻烦往往出现在进入生产之后。
一个任务执行到一半中断了,第二天能不能接着跑?不同部门的数据和记忆怎么隔开?智能体调用高风险工具时,谁来审批?出了问题以后,能不能还原当时的上下文、工具输入、执行结果和责任边界?
这些问题靠单个应用临时补配置,很难长期撑住。企业级 Agent 需要一层运行时,把身份、技能、工具、状态、权限、审计和工作区统一管起来。接下来一段时间,Agent 平台的重点会从“能不能调用模型”,转向“能不能稳定、安全、可治理地运行”。
一个正在变得清晰的方向,是以文件系统为导向来组织智能体。
将智能体放到目录树里
很多 Agent 系统早期会把提示词放在代码里,把知识文件放在对象存储里,把工具权限放在数据库里,把运行状态放在缓存或任务表里。开发时看起来灵活,运维和审计时就会变得很散。
一个智能体到底由哪些内容组成、谁改过、当前版本是什么、能调用哪些系统,往往要跨好几处地方查。团队规模一大,这种分散会变成持续负担。
以文件系统为导向的做法更直接。一个智能体就是一棵目录树:
某个智能体/
├─ 身份与行为说明
├─ 模型与连接配置
├─ 工具声明
├─ 技能与知识文件
├─ 子智能体
├─ 运行记忆
└─ 历史产出
目录结构本身承载智能体的定义。新增能力,就是放入新的工具或技能文件;调整行为,就修改身份说明;迁移环境,可以连同目录一起打包、审阅、复制和回滚。
这类设计的价值不只在开发效率上。对企业来说,智能体从一段临时上下文,变成了一份可读、可查、可版本管理的资产。技术团队能维护,安全团队能审查,合规团队也能知道它到底能做什么。
企业场景不能只做“一个智能体一个目录”
个人工具或小团队场景里,一个智能体对应一个目录已经足够。企业内部的情况要复杂得多。
一个平台可能同时服务多个机构、多个部门、多个岗位。每个用户可能拥有自己的智能体,每个智能体又有不同的技能、记忆、工具权限和历史产出。如果所有内容仍然挤在一层目录里,隔离边界会很快变得模糊。
企业级架构更适合把工作空间组织成多层结构:
企业工作空间
└── 机构 / 租户
├── 用户 A
│ ├── 智能体 1
│ │ ├── 身份说明
│ │ ├── 技能与知识
│ │ ├── 记忆与产出
│ │ └── 工具权限
│ └── 智能体 2
└── 用户 B
└── 智能体 3
这层结构解决的是企业最关心的隔离问题。机构之间的数据不能互相可见,用户之间的记忆不能被随意共享,不同智能体的工具、知识和产出也要分开管理。对金融、政企、医疗、国央企等场景来说,逻辑隔离还不够,部分机构可能需要独立存储卷、独立密钥,甚至独立部署环境。
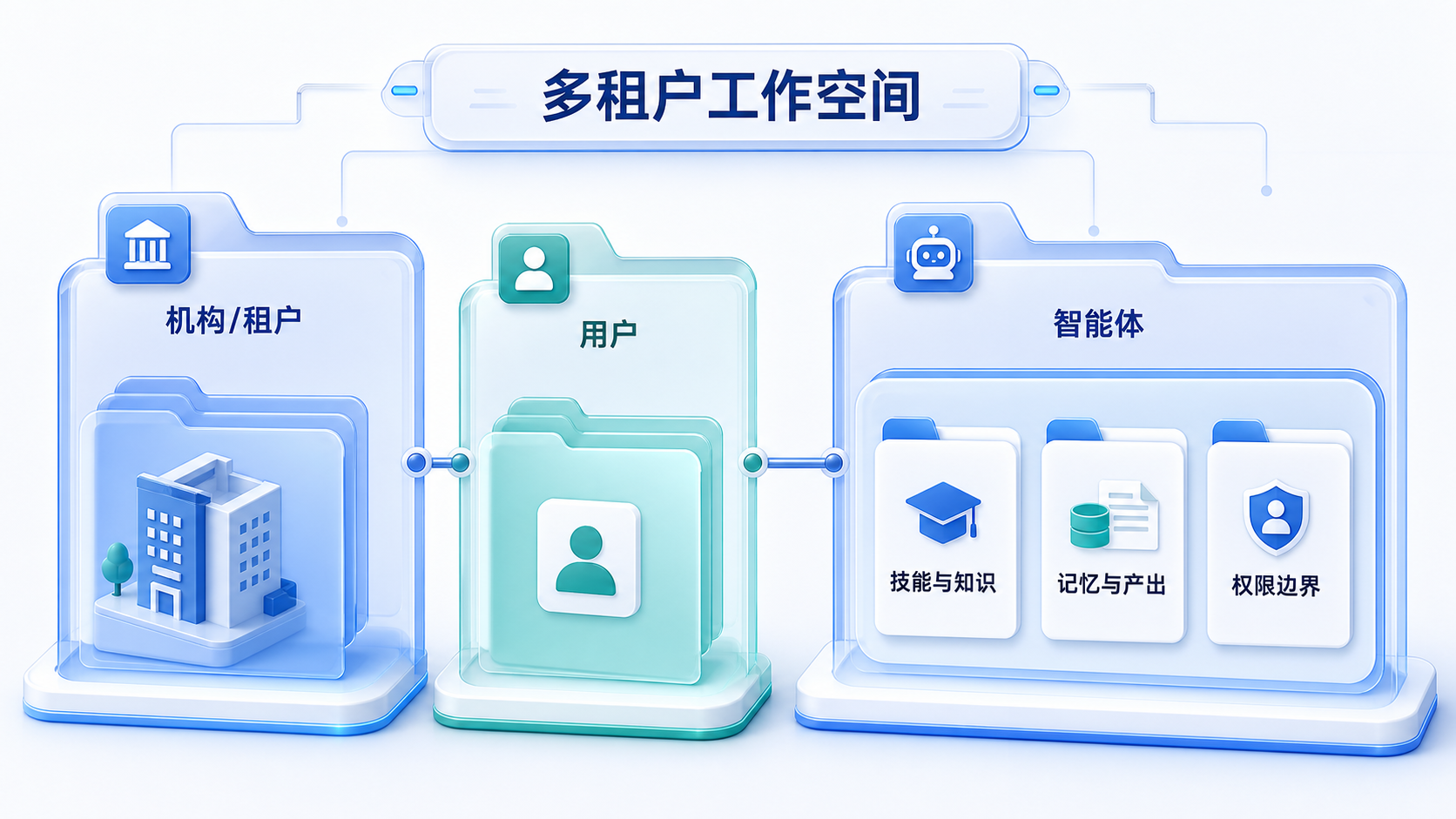
多租户不是后期加一列 tenant_id 就能解决的问题。它会影响请求路由、上下文加载、文件读写、工具授权、审计记录和资源配额。架构一开始没有把这层关系放进去,后面补起来会很重。
每一次请求,都要找到正确的工作区
Agent 平台接到一次请求后,不能只看用户输入了什么。它要先确认这次请求属于哪个机构、哪个用户、哪个智能体、哪段会话,以及适用哪套策略。
一个更稳的流程大致是这样:
用户请求
↓
治理层校验身份、权限、策略
↓
运行时定位机构 / 用户 / 智能体 / 会话
↓
加载身份说明、技能文件、历史上下文和工具权限
↓
执行智能体主循环
↓
写回产出、进度、审计记录
这个流程看起来普通,但它决定了平台能否承载大量用户同时使用。每次运行都按身份信息定位到对应工作区,智能体不需要长期占着某个进程。进程可以随用随起,任务结束后释放资源;状态留在文件系统和持久存储里。
对企业平台来说,这比“每个智能体长期占着一个运行环境”更容易扩展,也更容易恢复。扩容时增加运行进程即可,升级时替换进程即可,故障后也能从持久层恢复上下文和任务进度。
状态要从进程里拿出来
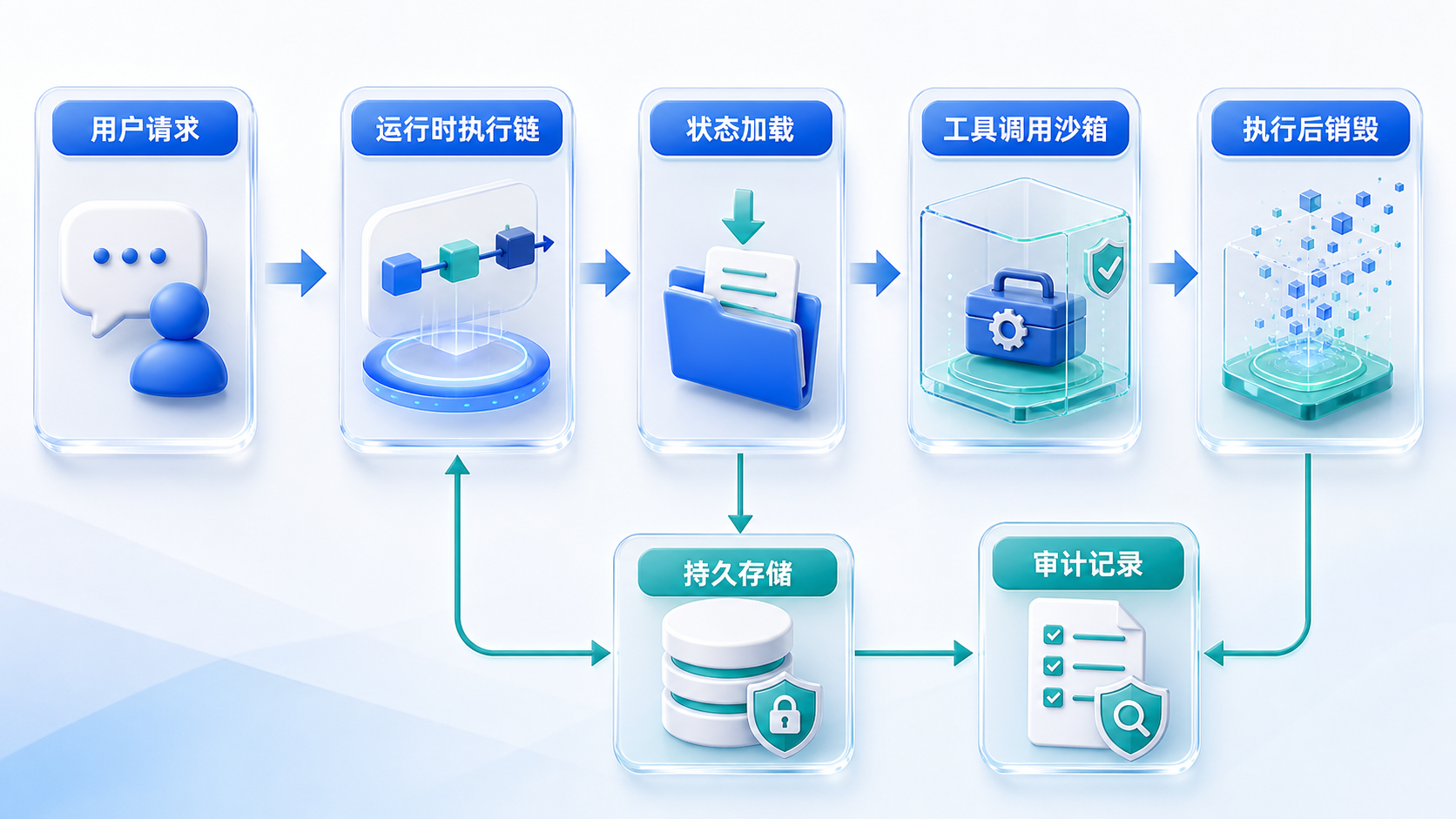
Agent 的很多生产问题都和状态有关。长任务执行到一半,进程重启了怎么办;模型调用失败,是否能重试;平台滚动升级时,会话会不会丢;用户第二天回来,能不能接上昨天的任务。
如果状态绑在进程里,这些问题都会变成运维负担。更合理的方式,是把状态放到客户可控的持久层。
智能体运行进程
↕
文件系统:身份、技能、知识、工作区产出
↕
持久存储:会话上下文、运行存档、续跑信息
↕
审计存储:工具调用、审批记录、结果回放
这样,每一次 Agent 运行都可以被看作一次独立计算:加载上下文,执行任务,写回结果。进程只是计算单元,不承担长期记忆。
这个设计会让很多运维动作变得简单。扩容时可以增加运行进程,升级时可以替换进程,故障后可以从持久层恢复。对合规要求高的企业来说,状态和审计记录留在自己的基础设施里,也更符合数据主权和内控要求。
这里还要注意会话记录的写入方式。生产环境里,审计记录不适合反复覆盖。更稳的方式是按追加方式记录每一次交互、工具调用、审批结果和产出摘要。出现争议时,平台可以按时间顺序回放当时发生了什么,避免只剩一个被更新过的最终状态。
沙箱应该落在工具调用上
Agent 风险较高的时刻,往往发生在动手阶段:执行命令、读取文件、访问内网接口、写入业务系统、触发自动化流程。模型生成一段文本本身风险有限,工具调用才需要严格隔离。
在多租户场景里,为每个智能体长期准备一个独立沙箱,资源开销会很高。智能体数量、用户数量、会话数量一上来,常驻隔离环境会拖慢部署和扩容。
更适合企业平台的方式,是工具调用级沙箱:
多租户运行时
├─ 工具调用 A → 临时沙箱 → 销毁
├─ 工具调用 B → 临时沙箱 → 销毁
└─ 工具调用 C → 临时沙箱 → 销毁
运行时负责上下文组装、策略判断和任务调度。只有当智能体要执行高风险动作时,才进入操作系统级隔离环境。调用完成后,沙箱销毁,结果写回。
这种粒度更贴近企业真实风险点。该隔离的时候隔离,该释放的时候释放,既控制资源成本,也方便对每次工具调用做权限校验、输入输出留痕和失败回收。
工具调用级沙箱还可以和授权策略配合。低风险的查询类工具可以直接放行,高风险写操作可以要求审批,涉及文件写入、命令执行、外部系统变更的动作可以进入更严格的隔离策略。这样一来,企业不用把所有能力一刀切地关掉,也不会让智能体在关键系统里裸跑。
治理能力要进入运行时
企业 Agent 进入生产后,平台每天都要处理类似问题:
- 哪些用户可以调用哪些智能体;
- 哪些工具可以直接执行,哪些要人工审批;
- 哪些数据可以进入模型上下文;
- 工具执行失败后是否需要回滚;
- 输出内容是否要经过安全检查;
- 审计时能否回放完整链路。
如果这些能力散落在各个业务系统里,后期会形成很多套规则。一个部门一套审批,一个应用一套审计,一个团队一套工具权限,平台很难统一管理。
更稳的做法,是把权限、审批、审计、隔离、回滚这些能力放进运行时和托管平台。业务团队负责定义智能体和业务流程,平台负责守住执行边界。
这一步容易被低估。很多团队会先把 Agent 做成一个应用,等业务跑起来以后再补治理。到了这个阶段,工具已经接了很多,数据入口也打开了不少,再回头整理权限、审计、沙箱和审批链路,改造成本会明显上升。
FinClaw 会成为企业的AI基础设施
公有云上的 Agent 框架适合云原生团队。托管工作流、连接器、沙箱、观测平台都已经准备好,开发者可以很快把智能体上线。
但很多企业的约束不同。数据不能出域,模型部署在内网,业务系统运行在专有云或信创环境,部分场景还要求离线运行。对这些组织来说,Agent 运行在哪里,数据沉淀在哪里,权限由谁控制,审计记录能否长期持有,往往比功能清单更重要。
FinClaw 的定位就在这里。它面向企业自有基础设施,提供多租户智能体运行时;ChatKit Middleware 负责治理、托管、多通道接入和全平台会话管理。两者配合后,企业可以把 Agent 的运行、状态、工具调用和审计记录放在自己的边界内管理。
可以把两者关系理解为:
ChatKit Middleware
治理 / 托管 / 多通道 / 会话管理
↓
FinClaw
多租户智能体运行时
↓
文件系统 / 持久存储 / 工具调用级沙箱
FinClaw 采用 Rust 构建,可以交付为单个可执行文件,部署依赖少。它可以运行在企业数据中心、专有云、隔离内网,作为独立运行时使用,也可以嵌入到更大的智能体平台里。
这种形态适合那些希望建设 Agent 平台,但又不能把数据和执行环境交给外部公有云的企业。
Agent落地会回到运行时工程
企业级 Agent 下一阶段不会只比模型接入数量,也不会只比工具列表有多长。会拉开差距的,是运行时能不能把智能体稳定地跑起来、隔离起来、治理起来。
以文件系统为导向的架构,把智能体变成可管理的工作空间;多租户目录树解决机构、用户和智能体之间的隔离;状态外置让会话可以恢复、任务可以续跑、进程可以替换;工具调用级沙箱把安全边界放到风险发生的位置。
FinClaw 沿着这条路线,把智能体运行时落在企业自有基础设施里。对监管行业、政企客户、信创环境和离线场景来说,这种架构更贴近真实约束。
Agent 从试点走向生产,要回答的问题会越来越具体:能不能长期运行,能不能审计,能不能隔离,能不能在企业自己的边界里被持续管理。


















 3145
3145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










