




 本文深入探讨了KMP、BoyerMoore及散列指纹法等字符串匹配算法,包括算法原理、实现细节与性能对比,旨在帮助读者理解并掌握各种算法的特点与应用场景。
本文深入探讨了KMP、BoyerMoore及散列指纹法等字符串匹配算法,包括算法原理、实现细节与性能对比,旨在帮助读者理解并掌握各种算法的特点与应用场景。
1 KMP算法
1.1 next方法
1.1.1 PMT
1.1.1.1 PMT含义
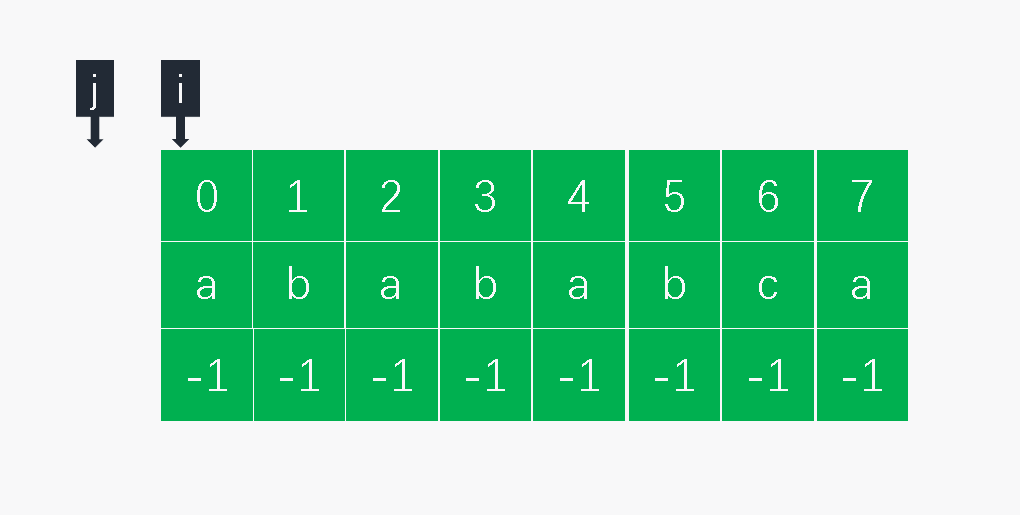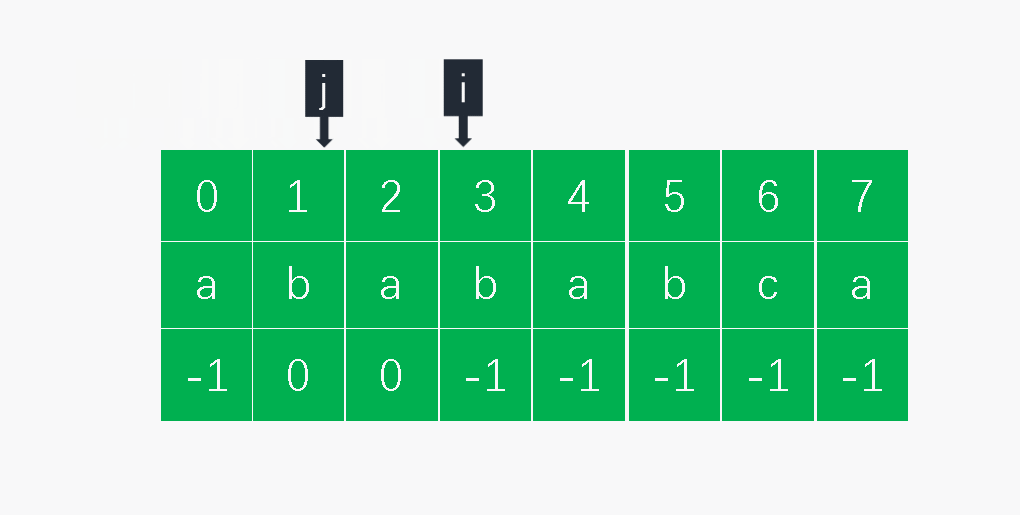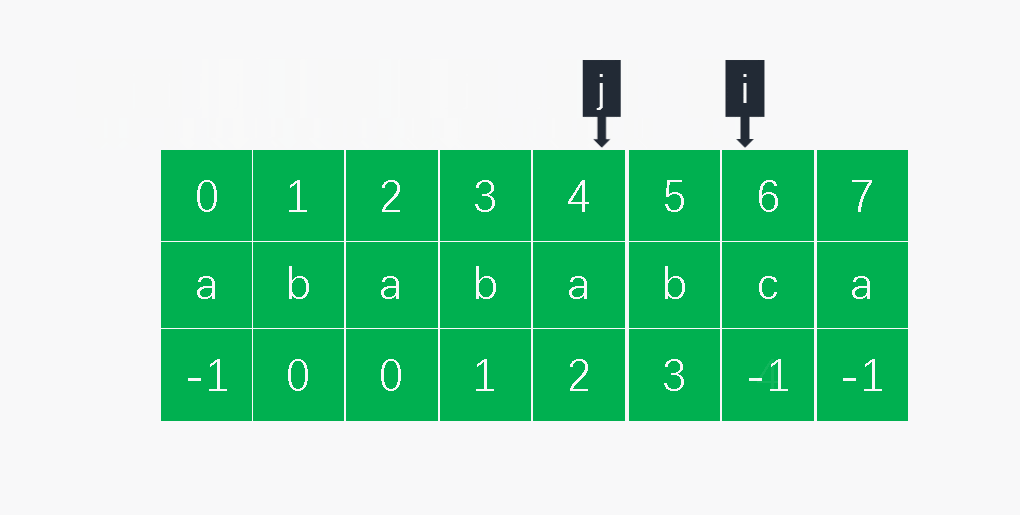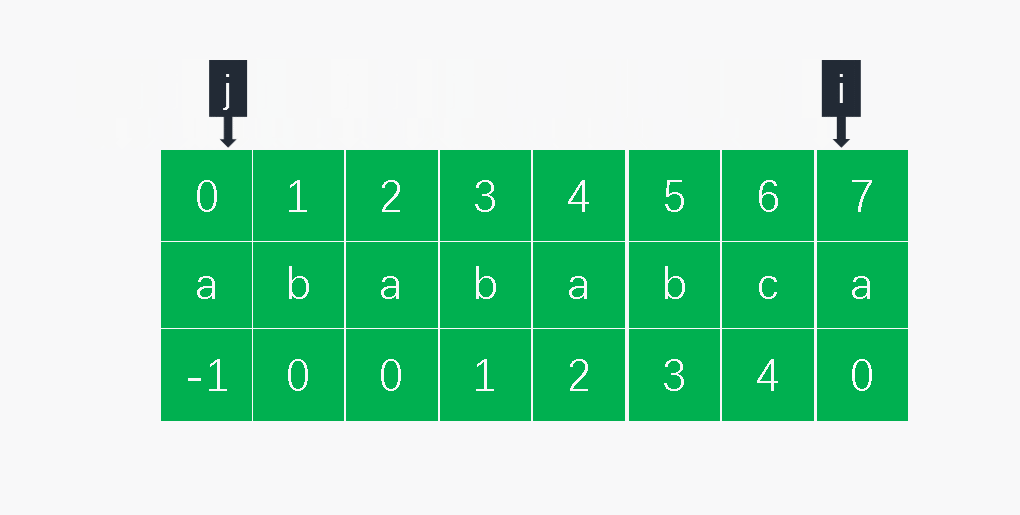
KMP算法中关键部分是弄清楚next数组的含义和作用,next数组即部分匹配表(PMT),如下面就是字符串’abababca’的PMT:
| 字符 | a | b | a | b | a | b | c | a |
|---|---|---|---|---|---|---|---|---|
| id | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| pmt | 0 | 0 | 1 | 2 | 3 | 4 | 0 | 1 |
首先说一些简单的基础概念:
- 前缀:对于字符串AB来说,A和B皆为AB的非空子字符串,其中A称为前缀。如’abcab’中,‘a’,‘ab’,‘abc’,'abca’都是前缀(字符串自身不是自身的前缀);
- 后缀:对于字符串AB来说,A和B皆为AB的非空子字符串,其中B称为前缀。如’abcab’中,‘b’,‘ab’,‘cab’,'bcab’都是后缀(字符串自身不是自身的后缀);
- 前缀集合:字符串AB所有前缀的集合。如’abcab’的前缀集合为{‘a’,‘ab’,‘abc’,‘abca’};
- 后缀集合:字符串AB所有后缀的集合。如’abcab’的前缀集合为{‘b’,‘ab’,‘cab’,‘bcab’};
PM中的值是字符串的前缀集合和后缀集合交集中最长元素的长度。例如对于字符串’abcab’的前后缀集合的交集为{‘ab’},则PMT中对应的值为2。
PMT中计算每个为止对应的值是计算当前字符之前(含当前字符)的所有字符组成的子字符串的前后缀集合交集中最长元素的长度,即对于
s
0
s
1
.
.
.
s
n
s_0s_1...s_n
s0s1...sn字符串,位置
i
i
i处的值为子字符串
s
0
.
.
.
s
i
s_0...s_i
s0...si的PMT值。
但是在实际使用时会将PMT右移一格即next数组,为了变成方便第0位的值设为-1:
| 字符 | a | b | a | b | a | b | c | a |
|---|---|---|---|---|---|---|---|---|
| id | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| pmt | 0 | 0 | 1 | 2 | 3 | 4 | 0 | 1 |
| next | -1 | 0 | 0 | 1 | 2 | 3 | 4 | 0 |
1.1.1.2 PMT生成
def get_next(pat):
i = 0
j = -1
next = (len(pat)) * [-1]
while i < len(next) - 1:
if j == -1 or pat[i] == pat[j]:
i += 1
j += 1
next[i] = j
else:
j = next[j]
return next
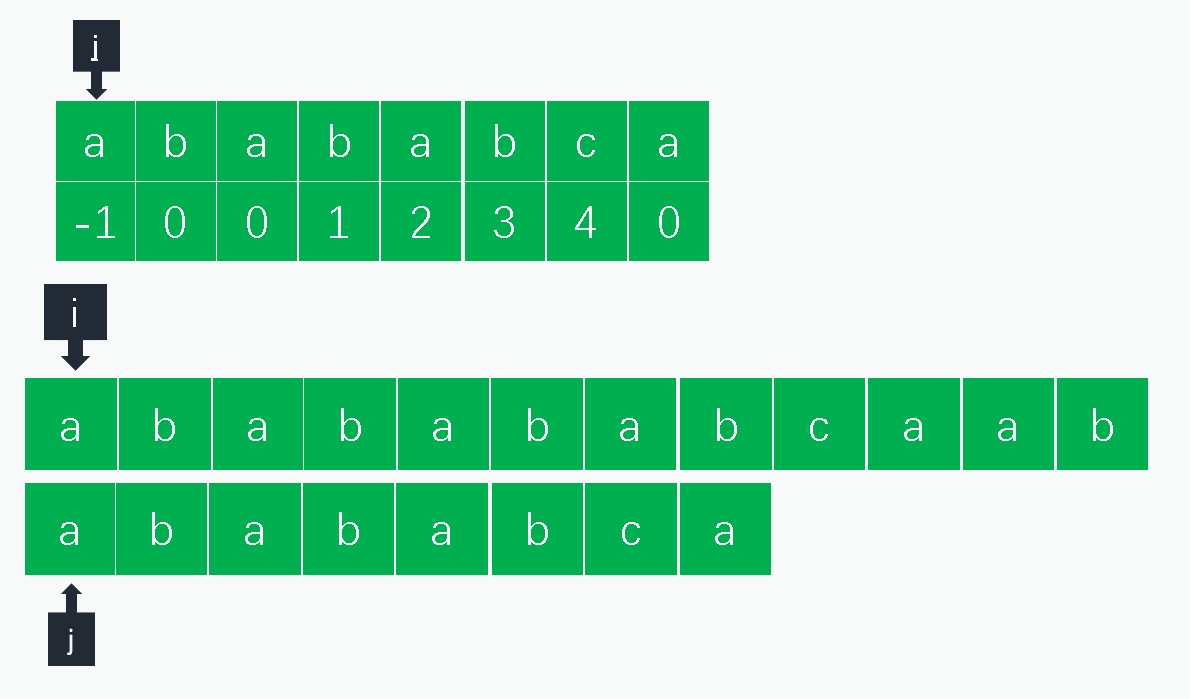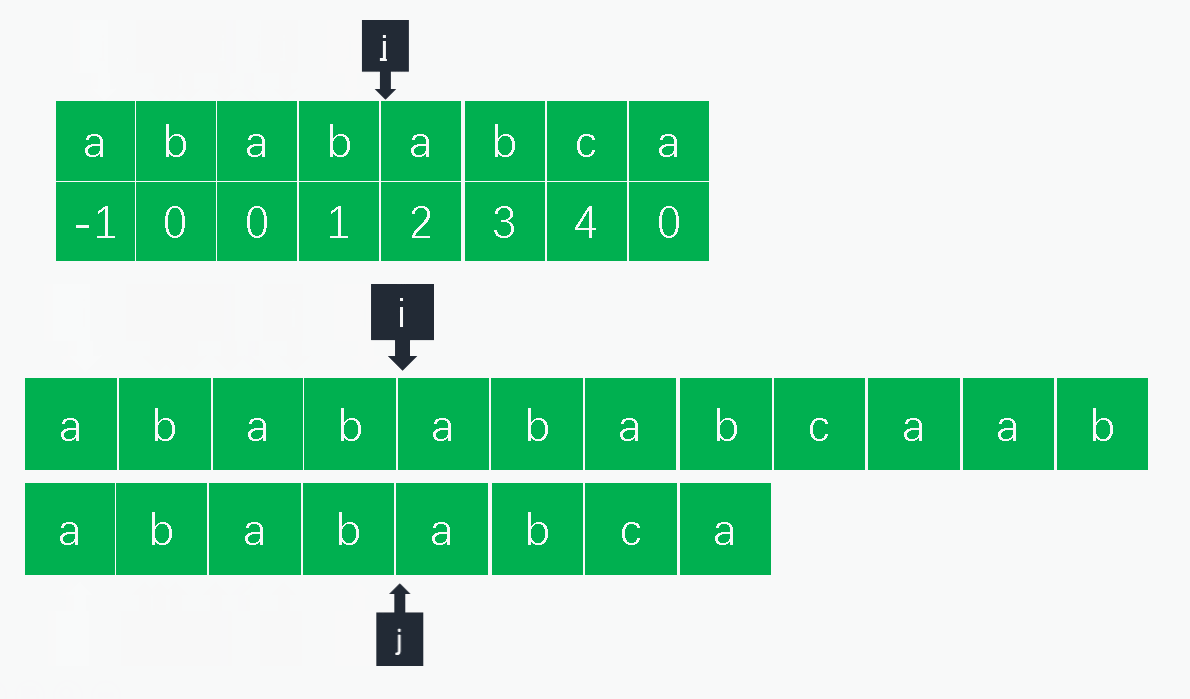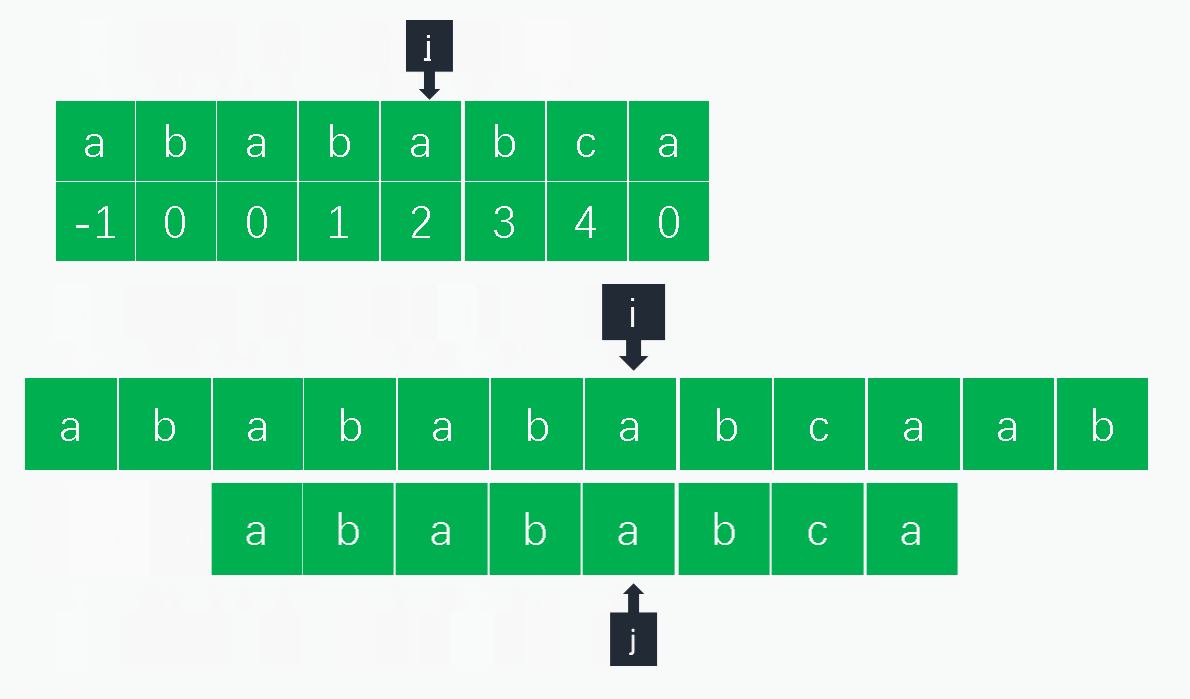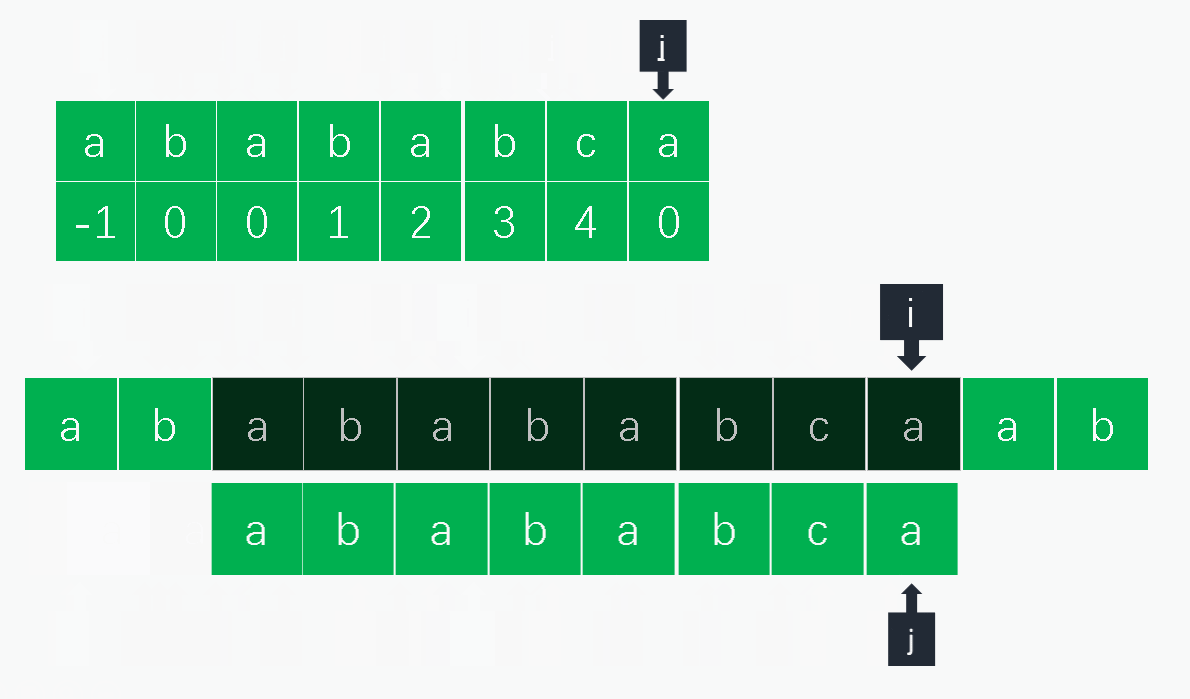
1.1.2 KMP算法
1.2.1 原理
KMP算法的实际利用next数组避免重复检查已经匹配的字符。字符串匹配无非分为当前字符匹配和当前字符失配,搜索字符串为 s 0 . . . s n s_0...s_n s0...sn,模式字符串为 p 0 . . . p m p_0...p_m p0...pm,二者的索引分别为 i , j i,j i,j:
- 匹配:匹配则同时增加模式字符串和查找字符串的索引 i , j i,j i,j匹配下一组字符;
- 失配:当前失配则意味着 s i − j . . . s i − 1 = p 0 . . . p j − 1 s_{i - j}...s_{i - 1} = p_0...p_{j-1} si−j...si−1=p0...pj−1,也就是说 s i − j . . . s i − 1 s_{i-j}...s_{i-1} si−j...si−1的后缀和 p 0 . . . p j − 1 p_0...p_{j-1} p0...pj−1的前缀匹配的长度为 n e x t [ j ] next[j] next[j],则只需将模式字符串的索引 j j j调整到 n e x t [ j ] next[j] next[j]即可,另外可以看到这里 n e x t [ j ] next[j] next[j]中的值我们实际需要的是 p m t [ j − 1 ] pmt[j-1] pmt[j−1],这也是将pmt右移一位的原因。
1.2.2 实现
def kmp(txt, pat):
next = get_next(pat)
i = 0
j = 0
while i < len(txt) and j < len(pat):
if j == -1 or txt[i] == pat[j]:
i += 1
j += 1
else:
j = next[j]
if j == len(pat):
return i - j
else:
return -1
1.2 DFA实现KMP
1.2.1 DFA
1.2.1.1 DFA(确定性有限状态自动机)
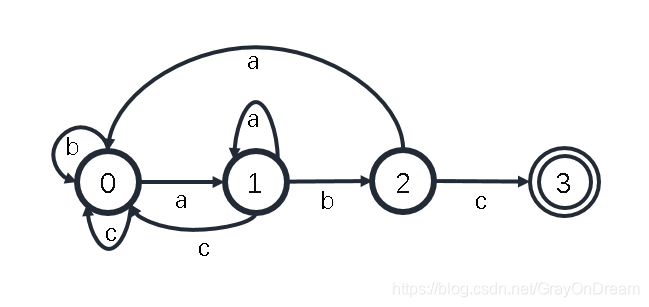
DFA是一个能实现状态转移的自动机。对于一个给定的属于该自动机的状态和一个属于该自动机字母表的字符,它都能根据事先给定的转移函数转移到下一个状态(这个状态可以是先前那个状态)。一般在自动机中圆圈表示状态,箭头表示状态转移,箭头上的内容便是引发状态转移的输入,DFA还有一个使用圆环表示的接受状态表示状态机接受状态。如下图为一个简单的DFA(每个确定状态,确定的输入对应着确定的下一状态)。
1.2.1.2 KMP DFA
字符串匹配问题可以看作一个确定性有限状态机,因为每个状态都是确定的,比如字符串"ababac"对应的状态机如下图:
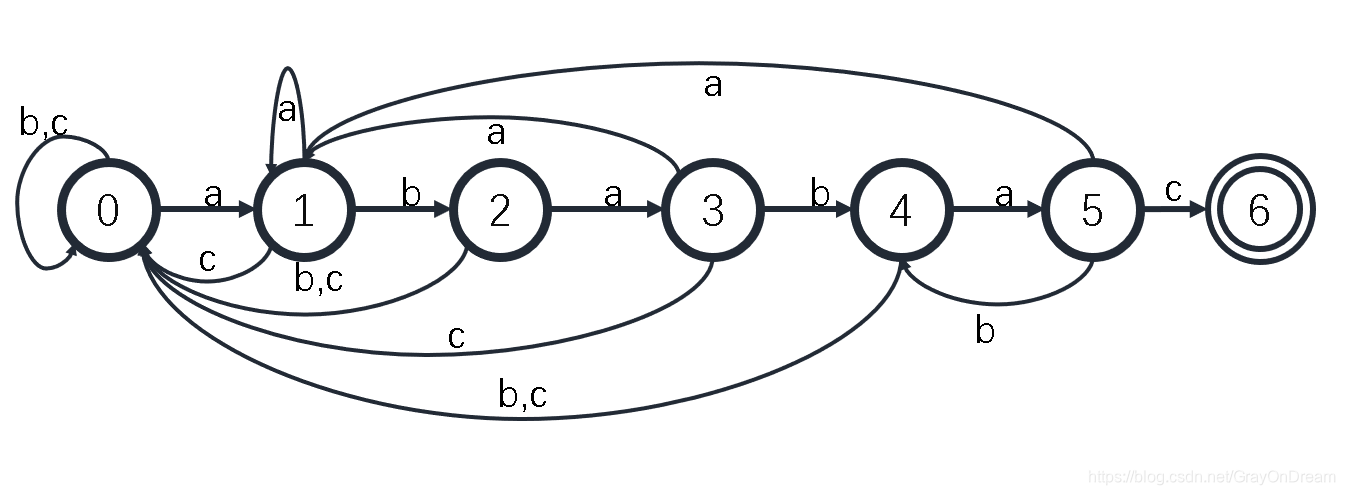
其对应的状态转移为:
| a | b | a | b | a | c | |
|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | |
| a | 1 | 1 | 3 | 1 | 5 | 1 |
| b | 0 | 2 | 0 | 4 | 0 | 4 |
| c | 0 | 0 | 0 | 0 | 0 | 6 |
1.2.2 实现
这部分主要分为两部分:
dfa[ord(pat[j])][j] = j + 1匹配成功进入下一个状态;dfa[c][j] = dfa[c][i]匹配失败进入重启状态。这里的 i i i记录的就是上一次匹配字符所对应的状态。
i i i用来记录前缀和后缀相同的位置, p 0 . . . p i = p j − i . . . p j p_0...p_i=p_{j-i}...p_j p0...pi=pj−i...pj。
def create_dfa(pat):
pat_len = len(pat)
r = 256
dfa = [[0 for i in range(pat_len)] for j in range(r)]
dfa[ord(pat[0])][0] = 1
i = 0
j = 1
while j < pat_len:
for c in range(r):
dfa[c][j] = dfa[c][i]
dfa[ord(pat[j])][j] = j + 1
i = dfa[ord(pat[j])][i]
j += 1
return dfa
1.2.2 KMP
1.2.2.1 DFA KMP
由于DFA本身提供了匹配失败和成功时的状态转移,所以只需要按照DFA进行状态转移即可。
1.2.2.2 实现
def search(txt, pat, dfa):
i = 0
j = 0
n = len(txt)
m = len(pat)
while i < n and j < m:
j = dfa[ord(txt[i])][j]
i += 1
if j == m:
return i - m
return n
2 BoyerMoore算法
2.1 算法原理
不同于KMP算法从左向右匹配BoyerMoore算法采用从右向左匹配的策略进行模式匹配。但是其基本的思路和KMP差不多都是指定匹配成功和匹配失败时进行跳转的位置以提高效率。
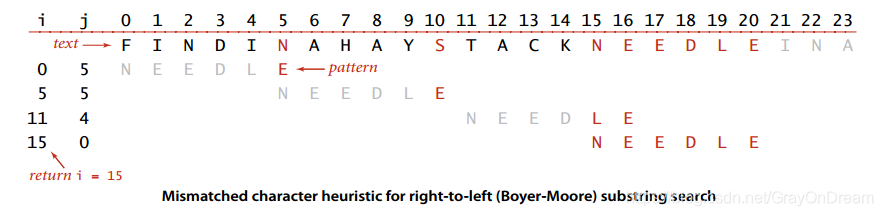
如上图中模式字符串中的E和文本中的N失配,下一步搜索只需要保证文本中的N和模式中的N匹配,因此不需要过多的搜索直接跳转到对应位置即可;下一步中S和E失配而S不在模式中,那么没必要将所有字符都匹配一遍直接跳转到下一次匹配即可;下一步E和E匹配,N和L失配,和之前一样将文本中的N和模式中的N匹配在进行搜索。
现在的问题是每次跳转多少,根据上面的过程每次匹配时肯定是文本中失配字符在模式字符中对应字符进行匹配,那么应该跳转到模式字符串中对应字符的哪个字符。由于当前算法是从右向左进行匹配因此选择选择从右向左第一个当前字符进行匹配即可。此时只需要一个额外的数组记录每个字符出现的最右位置即可,如’needle’出现的right数组为[N:0,E:5,L:4,D:3]。
整理下算法的过程,对于算法只有匹配和失配两种状况,处理好两种状况即可(文本中的索引为i,模式中的索引为j):
- 匹配:继续进行匹配直到搜索成功;
- 失配:
- 文本中的字符在模式中将模式右移j-right[txt[i]]个位置;
- 文本中的字符不在模式中:直接将模式跳转len(模式)个位置。
2.2 实现
获得right数组算法比较简单:
def get_right(pat, r=256):
right = [-1] * r
for i in range(len(pat)):
right[ord(pat[i])] = i
return right
下面的匹配算法skip就是失配时进行跳转的临时变量。
def boyemoore_search(txt, pat):
right = get_right(pat)
skip = 0
i = 0
while i <= len(txt) - len(pat):
skip = 0
j = len(pat) - 1
while j >= 0:
if pat[j] != txt[i + j]:
skip = j - right[ord(txt[i + j])]
if skip < 1:
skip = 1
break
j -= 1
if skip == 0:
return i
i += skip
return len(txt)
3 散列指纹法
长度为
M
M
M的字符串对应着一个
R
R
R进制的
M
M
M位数,对每次匹配的模式串进行编码即可,关键是设计好散列函数降低冲突和高效。具体过程如下图所示,这里选择的编码为10进制:

3.1 散列计算
3.1.1 Horner算法
散列计算可以采用秦九韶算法(Horner算法)。Horner法则:
对于一个
n
n
n次多项式:
f
(
x
)
=
a
n
x
n
+
a
n
−
1
x
n
−
1
+
.
.
.
+
a
1
x
+
a
0
f(x)=a_nx^n+a_{n-1}x^{n-1}+...+a_1x+a_0
f(x)=anxn+an−1xn−1+...+a1x+a0
直接计算代价比较高,利用horner法则则可以搞笑的计算,将f(x)写成:
f
(
x
)
=
(
.
.
.
(
(
a
n
x
+
a
n
−
1
)
x
+
a
n
−
2
)
x
+
.
.
.
+
a
1
)
x
+
a
0
f(x)=(...((a_nx+a_{n-1})x+a_{n-2})x+...+a_1)x+a_0
f(x)=(...((anx+an−1)x+an−2)x+...+a1)x+a0
对于上式每次只计算括号内部的子问题即可。因为要计算散列肯定使用的是取余运算,假设给定
n
n
n需要计算
n
%
m
n\%m
n%m,对于r进制对应的数可以拆分为:
n
=
(
.
.
.
(
(
a
k
∗
r
+
a
k
−
1
)
∗
r
+
a
k
−
2
)
∗
r
+
.
.
.
+
a
1
)
∗
r
+
a
0
n=(...((a_k * r + a_{k-1}) * r + a_{k-2})* r + ...+a_1) * r + a_0
n=(...((ak∗r+ak−1)∗r+ak−2)∗r+...+a1)∗r+a0
比如对于1234的10进制
1234
=
(
(
1
×
10
+
2
)
×
10
+
3
)
×
10
+
4
1234=((1×10+2)×10+3)×10+4
1234=((1×10+2)×10+3)×10+4,同理将对字符串txt的编码就描述为
h
a
s
h
c
o
d
e
=
(
h
a
s
h
c
o
d
e
+
t
x
t
[
i
]
)
%
b
i
g
p
r
i
m
e
hash_code=(hash_code + txt[i]) \% bigprime
hashcode=(hashcode+txt[i])%bigprime
3.1.2 优化
即便horner算法很优秀了但是还是有优化的空间。因为是字符串匹配因此当前匹配的字符串和下一次匹配的子字符串一定存在
m
−
1
m-1
m−1 个交集
m
m
m为模式长度,即对于模式
p
p
p,字符串s,当前索引为
i
i
i:
s
=
s
i
.
.
.
s
i
+
m
s=s_i...s_{i + m}
s=si...si+m
其对应的编码为:
x
i
=
t
i
r
m
−
1
+
.
.
.
+
t
i
+
m
−
1
r
0
x_i=t_ir^{m-1}+...+t_{i+m-1}r^0
xi=tirm−1+...+ti+m−1r0
则相应的下一个子串的编码为:
x
i
+
1
=
(
x
i
−
t
i
r
m
−
1
)
×
r
+
t
i
+
m
x_{i+1}=(x_i-t_ir^{m-1})×r+t_{i+m}
xi+1=(xi−tirm−1)×r+ti+m
这样就可以利用上一个子串的散列值计算下一个子串的散列值。
3.2 获取大素数
参考Rabin算法,不多说。
3.3 算法
由于是使用散列函数因此即便hashcode相同也无法保证字符串相同,不同字符串匹配方式对应不同的算法。
3.3.1 蒙特卡洛
不比较,蒙特卡洛方法的正确性取决于散列计算时的大素数的值,如果素数越大则出错的概率越低,加入大素数大约为 1 0 2 0 10^20 1020则错误的概率为 1 0 − 20 10^{-20} 10−20几乎不可能,素数越大越正确。
3.3.2 拉斯维加斯算法
简单的匹配。
3.4 实现
3.4.1 获取大素数
# 检测大整数是否是素数,如果是素数,就返回True,否则返回False
def rabin_miller(num):
s = num - 1
t = 0
while s % 2 == 0:
s = s // 2
t += 1
for trials in range(5):
a = random.randrange(2, num - 1)
v = pow(a, s, num)
if v != 1:
i = 0
while v != (num - 1):
if i == t - 1:
return False
else:
i = i + 1
v = (v ** 2) % num
return True
def is_prime(num):
# 排除0,1和负数
if num < 2:
return False
# 创建小素数的列表,可以大幅加快速度
# 如果是小素数,那么直接返回true
small_primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151, 157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229, 233, 239, 241, 251, 257, 263, 269, 271, 277, 281, 283, 293, 307, 311, 313, 317, 331, 337, 347, 349, 353, 359, 367, 373, 379, 383, 389, 397, 401, 409, 419, 421, 431, 433, 439, 443, 449, 457, 461, 463, 467, 479, 487, 491, 499, 503, 509, 521, 523, 541, 547, 557, 563, 569, 571, 577, 587, 593, 599, 601, 607, 613, 617, 619, 631, 641, 643, 647, 653, 659, 661, 673, 677, 683, 691, 701, 709, 719, 727, 733, 739, 743, 751, 757, 761, 769, 773, 787, 797, 809, 811, 821, 823, 827, 829, 839, 853, 857, 859, 863, 877, 881, 883, 887, 907, 911, 919, 929, 937, 941, 947, 953, 967, 971, 977, 983, 991, 997]
if num in small_primes:
return True
# 如果大数是这些小素数的倍数,那么就是合数,返回false
for prime in small_primes:
if num % prime == 0:
return False
# 如果这样没有分辨出来,就一定是大整数,那么就调用rabin算法
return rabin_miller(num)
# 得到大整数,默认位数为1024
def get_prime(key_size=1024):
while True:
num = random.randrange(2**(key_size-1), 2**key_size)
if is_prime(num):
return num
3.4.2 hash code
def hash(line, big_prime, r=256):
hcode = 0
for i in range(0, len(line)):
hcode = (r * hcode + ord(line[i])) % big_prime
return hcode
3.4.3 算法
为了加速这里使用的是已经计算好的大素数。
def long_random_prime():
return 121461810980405772771175611270843884000507802617010592057054218483258626678101103820926110565823269240433607391822175172403272239136199088141179467742900111960579379552996372680978058346702525397940161911461633009865733654996981492831594146175519276801093888903332607532190216271689437619073359758499365149323
def alwayes_matched(txt, pat):
return True
def check_matched(txt, pat):
print(txt, pat)
return txt == pat
def rabinkarp(txt, pat, is_matched_func, r=256):
big_prime = long_random_prime()
txt_code = hash(txt[0:len(pat)], big_prime, r)
pat_code = hash(pat, big_prime, r)
if txt_code == pat_code and is_matched_func(txt, pat):
return 0 #pat == txt
rm = 1
for i in range(1, len(pat)):
rm = (r * rm) % big_prime
for i in range(len(pat), len(txt)):
txt_code = (txt_code + big_prime - rm * ord(txt[i - len(pat)]) % big_prime) % big_prime
txt_code = (txt_code * r + ord(txt[i])) % big_prime
if pat_code == txt_code and is_matched_func(txt[i - len(pat) + 1:i + 1], pat):
return i - len(pat) + 1
return len(txt)
def rabinkarp_m(txt, pat):
'''
@brief 蒙特卡洛方法
'''
return rabinkarp(txt, pat, alwayes_matched)
def rabinkarp_l(txt, pat):
'''
@brief 拉斯维加斯算法
'''
return rabinkarp(txt, pat, check_matched)
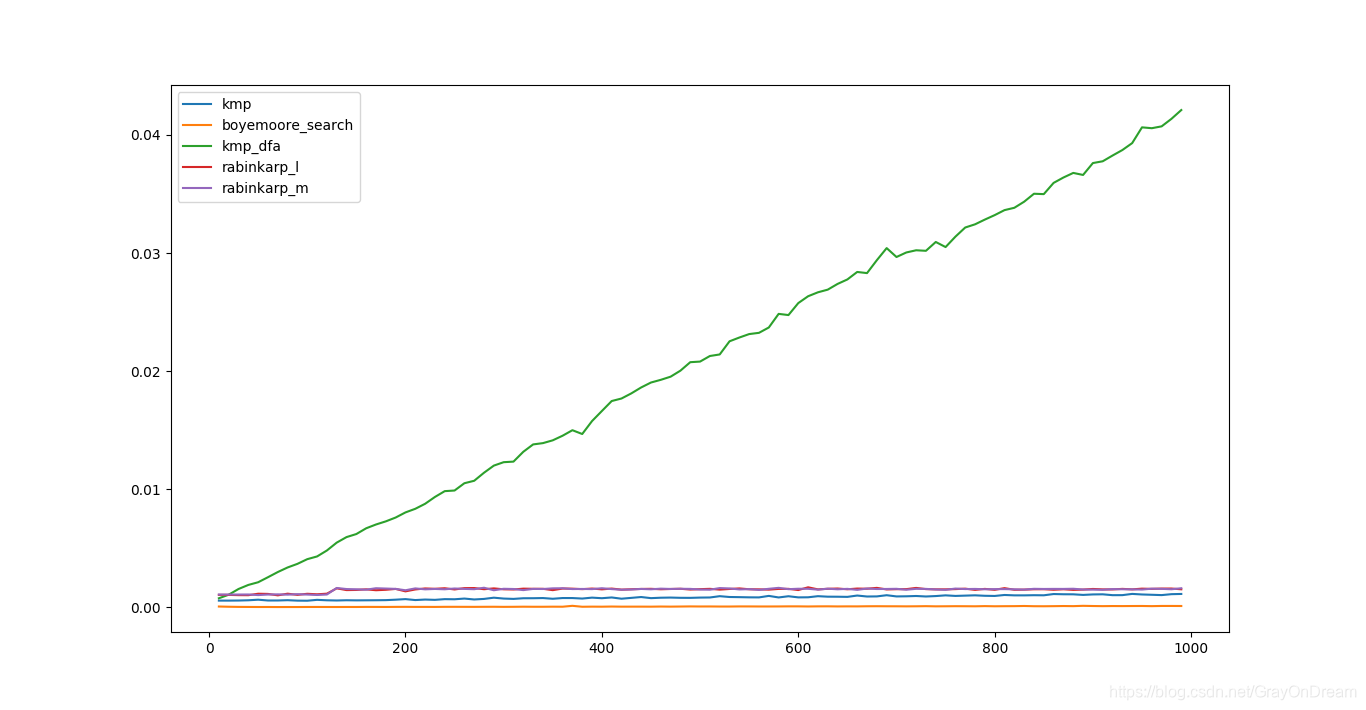
4 性能比较
4.1 性能对比
横坐标是子串长度。
4.2 算法复杂度
| 算法 | 最欢情况操作数 | 一般情况操作数 | 是否回退 | 正确性 | 额外空间需求 |
|---|---|---|---|---|---|
| 暴力搜索 | MN | 1.1N | 是 | 是 | 1 |
| KMPDFA | 2N | 1.1N | 否 | 是 | MR |
| KMPNext | 3N | 1.1N | 否 | 是 | M |
| Boyer-Moore | MN | N/M | 是 | 是 | R |
| Rabin-Karp蒙特卡洛 | 7N | 7N | 否 | 是(一定概率下) | 1 |
| Rabin-Karp拉斯维加斯 | 7N(一定概率下) | 7N | 是 | 是 | 1 |


















 3210
3210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










