



本项目是一个面向开发者的 API 平台,提供 API 接口供开发者调用。用户通过注册登录,可以开通接口调用权限,并可以浏览和调用接口。每次调用都会进行统计,用户可以根据统计数据进行分析和优化。管理员可以发布接口、下线接口、接入接口,并可视化接口的调用情况和数据。本项目侧重于后端,涉及多种编程技巧和架构设计层面的知识。
思考
后端项目现在有 backend、interface,为什么不在一个工程呢?
因为平台可以接入任何人开发的接口,不一定是同一个团队或者公司内部的项目。
接口调用次数的业务流程
需求:
- 用户每次调用接口成功,次数 + 1
- 给用户分配或者用户自主申请接口调用次数
业务流程:
- 用户调用接口(之前已完成)
- 修改数据库,调用次数 +1
实际上,整个接口调用次数加 1 的业务流程是嵌入在我们调用接口的业务流程中的。
首先用户在前端看到接口,然后他要开通接口获取调用次数,获取调用次数后发起调用。
在原有的调用接口成功基础上,再添加一个步骤,即在统计次数的位置进行记录。
设计库表
既然每次调用接口成功都要加 1 次数,那我们需要区分是哪个用户调用了哪个接口
根据需求分析,这是一个多对多的关系,一个用户可以调用多个接口,而一个接口也可以被多个用户调用。
设计一个新的表来存储用户和接口之间的关系,可称之为"用户调用接口关系表"。
-- 用户调用接口关系表
create table if not exists yuapi.`user_interface_info`
(
`id` bigint not null auto_increment comment '主键' primary key,
`userId` bigint not null comment '调用用户 id',
`interfaceInfoId` bigint not null comment '接口 id',
`totalNum` int default 0 not null comment '总调用次数',
`leftNum` int default 0 not null comment '剩余调用次数',
`status` int default 0 not null comment '0-正常,1-禁用',
`createTime` datetime default CURRENT_TIMESTAMP not null comment '创建时间',
`updateTime` datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
`isDelete` tinyint default 0 not null comment '是否删除(0-未删, 1-已删)'
) comment '用户调用接口关系';
总调用次数:指用户从第一次开通接口开始至今累计的调用次数。
剩余调用次数:指用户每次购买接口后剩余的可调用次数。
状态字段(status):决定是否允许其调用特定接口。
- 为了增加安全性,我们可以考虑为每个用户设置一个状态字段(status),来决定是否允许其调用特定接口。这样,如果用户触发了某些规则或违反了规定,我们可以将其状态设置为不允许调用该接口。通过添加一个状态字段,我们可以灵活地管理用户对接口的访问权限。例如,当用户违反规则时,我们可以限制其对某些接口的调用,而对其他接口仍然保持开放。这个状态字段可以帮助我们实现精确的接口访问控制。
💡 不建议将调用时间直接写入数据库
如果每个用户每次调用接口都要在数据库中新增一条数据,那么数据库表可能会变得非常庞大。建议使用日志来存储这些调用信息,可以将其记录在文件中,使用类似 ELK 等工具进行日志存储和分析。
OK创建表~~~
mybatisX 插件生成代码
表创建完成之后,现在去生成增删改查代码;
鼠标右键 user_interface_info 表 → MybatisX-Generator。
模块路径选择当前路径即可,它会生成到 src/main/java 下
点击 Next 点击 Finish
多了一个 generator包,代码都生成在这里。
给实体对象中的 isDelete 加上 @TableLogic,表示是逻辑删除的字段。
迁移生成的代码
把 UserInterfaceInfo.java 拖到entity包下。
把 UserInterfaceInfoMapper.java 拖到mapper包下。
把 UserInterfaceInfoServiceImpl.java 拖到impl包下。
把 UserInterfaceInfoService.java 拖到service包下。
迁移完了,把generator包删除,鼠标右键generator包 → Delete。
然后我们再写一下 controller,复制 InterfaceInfoController.java;
粘贴到controller包下,并重命名为 UserInterfaceInfoController。
按[Ctrl+R]替换,把 interfaceInfo 替换成userInterfaceInfo。
把 InterfaceInfo 替换成UserInterfaceInfo。
修改代码逻辑
为了确保用户每次调用接口成功时次数加一,而不是随意增加某个接口的调用次数,我们应该将增加调用次数的逻辑放在接口调用成功的业务逻辑之后。这样可以保证接口调用的准确性和安全性,防止滥用和不当操作
💡有按用户限制 QPS 的思路吗?
既然我们已经能够统计用户调用接口的次数,我们再统计用户调用接口的调用时间,然后根据用户在某一个时间段内的调用次数来限制。
例如,我们可以每隔一秒统计一次用户的接口调用次数,如果用户在这一秒内的调用次数超过了某个设定的频率,那么我们就给他禁用接口调用。
UserInterfaceInfoAddRequest
管理员要去给用户开通内的接口调用关系,接口调用次数的话,需要填写什么呢?
- 用户 id,知道哪个用户开通
- 接口 id
- 总调用次数
- 剩余调用次数
- 状态,状态默认是正常(所以可以不用填)
UserInterfaceInfoQueryRequest
管理员会根据哪些字段查询用户和接口的调用关系呢?
- id,根据 id 查询,但次数可能比较少,保留一下
- 用户 id,查某个用户开通哪些接口的调用权限
- 接口 id,这个接口有哪些用户调用
- 总调用次数,可以留着,一般是用范围查询
- 剩余调用次数
- 状态,常用的查询的状态
UserInterfaceInfoUpdateRequest
管理员会去修改用户接口调用关系的哪些内容呢?
- id,更新必须指定一条数据
- 用户 id(不会改这个,都给用户开通,再改用户就不合理了)
- 总调用次数
- 剩余调用次数
- 状态
实现用户调用成功次数加一
我们之前校验用户是否有权限调用,都直接写在了模拟接口项目里。
调用成功之后我们要做的事情是什么?
就是去调用我们的 userInterfaceInfoService.save,把这条调用记录添加到数据库中
或者调用 updateUserInterfaceInfo 在原有的调用次数的统计之上再加一。
有两种情况:
- 第一种情况是用户没有这个调用次数记录,那么我们需要创建一条新的记录。
- 第二种情况是用户已经有了调用次数记录,我们需要在现有的次数基础上加 1。
现在我们要开发调用次数加一的功能。之前的updateUserInterfaceInfo方法是以管理员的视角去更新调用次数记录,但并没有包含调用次数加一的逻辑,所以我们需要在这里进行开发。4
在 UserInterfaceInfoService 中补充次数加一的功能
并实现
@Override
public boolean invokeCount(long interfaceInfoId, long userId) {
// 判断(其实这里还应该校验存不存在,这里就不用校验了,因为它不存在,也更新不到那条记录)
if (interfaceInfoId <= 0 || userId <= 0) {
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
// 使用 UpdateWrapper 对象来构建更新条件
UpdateWrapper<UserInterfaceInfo> updateWrapper = new UpdateWrapper<>();
// 在 updateWrapper 中设置了两个条件:interfaceInfoId 等于给定的 interfaceInfoId 和 userId 等于给定的 userId。
updateWrapper.eq("interfaceInfoId", interfaceInfoId);
updateWrapper.eq("userId", userId);
// setSql 方法用于设置要更新的 SQL 语句。这里通过 SQL 表达式实现了两个字段的更新操作:
// leftNum=leftNum-1和totalNum=totalNum+1。意思是将leftNum字段减一,totalNum字段加一。
updateWrapper.setSql("leftNum = leftNum - 1, totalNum = totalNum + 1");
// 最后,调用update方法执行更新操作,并返回更新是否成功的结果
return this.update(updateWrapper);
}
在这里需要注意的是,由于用户可能会瞬间调用大量接口次数,为了避免统计出错,需要涉及到事务和锁的知识。在这种情况下,如果我们是在分布式环境中运行的,那么可能需要使用分布式锁来保证数据的一致性。
存在问题
现在的需求是在用户调用每个接口成功后,需要调用invokeCount方法,来给当前接口的调用次数加 1。
但是这样做可能会带来一个问题:如果每个方法调用成功后,返回结果之前都要调用一次invokeCount方法,会显得非常繁琐。
解决方案1:AOP
我们可以使用 AOP(面向切面编程)来实现这个功能。AOP 允许我们在原有业务逻辑的基础上,增加额外的操作,而不需要改动原有代码。
具体来说,我们可以通过 AOP 切面、拦截器或者过滤器来实现这个统计次数的逻辑。在接口调用成功后,AOP 切面或拦截器可以自动触发调用次数加 1 的方法,从而实现统一的统计功能。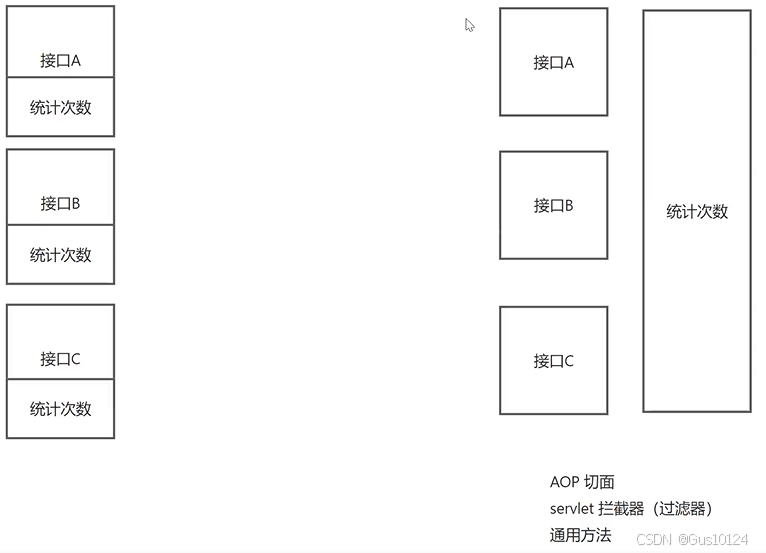
AOP 切面是我们推荐的方案,它可以将统计次数的逻辑从业务逻辑中解耦出来,并实现统一的处理。在学习 AOP 切面的过程中,也要重点学习 Spring 的核心特性之一。
AOP 切面的缺点:只存在于单个项目中,如果每个团队都要开发自己的模拟接口,那么都要写一个切面。
考虑到我们的项目架构,我们希望实现一种通用的统计方案,可以统一处理所有项目的接口调用情况。因此,我们决定采用网关来实现这个功能。
架构图: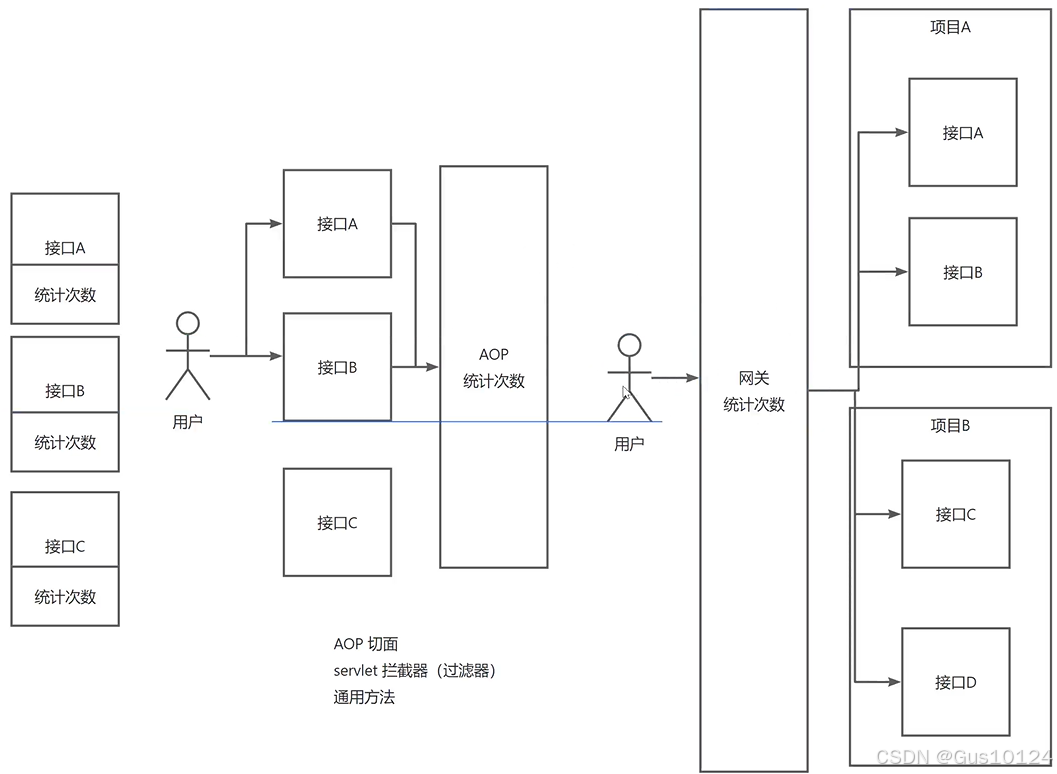
将统计次数的功能再抽出来一层。我们可以将统计次数的逻辑放在一个公共的位置,无论哪个模拟接口被调用,都会经过这个统一的统计次数逻辑。
通过这种设计,我们实现了一个统一的网关来处理不同项目的请求,用户和开发者都不需要关心具体的细节,简化了操作,提高了系统的可用性和可维护性。
网关
网关的应用场景
路由:路由实际上就像一个中转站,类似于我们的路由器。
- 假设用户要访问某个接口 A,但用户不需要直接调用接口 A,而是通过我们的网关统一接收用户的请求。网关记录了用户调用的接口,并将其转发到对应的项目和接口进行处理,有点类似于前台接待。
- 路由在这里起到了转发的作用。举个例子,假设我们有接口 A 和接口 B,网关会记录这些信息,并根据用户访问的地址和参数,将请求转发到对应的接口(服务器/集群)。这种转发过程就叫做路由。
参考文档:The After Route Predicate Factory。
统一鉴权:判断用户是否有权限进行操作,无论访问什么接口,都统一判断权限,不用重复写
- 之前的鉴权逻辑写在 interface 这个项目中的方法里,用于判断用户是否有权限进行操作。但是如果每个方法都要单独写鉴权逻辑,显然是不可行的。所以将鉴权逻辑和统计次数一样,抽取出来放到网关里面。
- 在网关中,鉴权的重点是实现统一鉴权。无论用户要访问哪个接口,网关都会统一判断权限,不需要重复编写鉴权逻辑。网关的作用在很多方面都是强调统一性,将重复的逻辑进行抽象和集中。
统一处理跨域:网关统一处理跨域,不用在每个项目里单独处理
参考文档:Global CORS Configuration。
统一业务处理:把一些每个项目中都要做的通用逻辑放到上层(网关),统一处理,比如本项目的次数统计。
- 项目中可能存在一些通用的逻辑,比如统计调用次数和鉴权等。如果把这些逻辑写在每个项目的方法里,就会导致重复代码和维护困难。
- 为了避免重复的代码,将这些统一的业务逻辑放到网关层面进行处理。让项目中的方法更加清晰、简洁,同时也避免了重复劳动。
访问控制:黑白名单,比如限制 DDOS IP
- 访问控制,实际上也是一种权限控制机制。它与鉴权有一些区别。鉴权通常指授权,即判断用户是否有访问某种资源的权限。而黑白名单则主要用于判断每个用户是否可以访问特定资源,它是一种与业务逻辑独立的控制方式。
- 举个例子,如果有人恶意刷我们的流量,进行 DDOS 攻击,我们可以将这些恶意 IP 加入黑名单,限制它们的访问。这样,这些 IP 就无法访问我们的服务,从而保护了我们的接口和服务不受恶意攻击。
发布控制:灰度发布,比如上线新接口,先给新接口分配 20% 的流量,老接口 80%,再慢慢调整比重。
- 举个例子,假设团队开发了一个名为项目 A 的接口 A,现在我们要对接口 A 进行升级,推出一个新版本的接口 A-V2。但我们并不确定新版本是否稳定可靠,所以我们想先让一部分用户试用这个新接口。我们可以将流量按照比例划分,比如 80% 的流量继续访问旧版本的接口 A,而 20% 的流量则引导到新版本的接口 A-V2。这样就实现了灰度测试的效果。然后我们会观察 V2 的表现,如果测试没有问题,我们可以逐步增加流量比例,比如 50%、70%、80%,直到 100%。最后,当我们确认新版本的接口稳定可靠时,就可以完全替换掉旧版本,下线接口 A。
- 这个流量分配的过程就是发布控制,而它通常是在网关层进行。因为网关是整个流量的入口,所以它可以担当请求流量分配的角色。
参考文档:The Weight Route Predicate Factory。
流量染色:给请求(流量)添加一些标识。通常通过设置请求头来实现。
举个例子。假设现在有一个用户要访问我的接口。但是有一个问题,我希望用户不能绕过网关直接调用我的接口,我想要防止这种情况发生。那么我应该如何防止绕过网关呢?
- 一个方法是要确定请求的来源。我们可以为用户通过网关来的请求打上一个标识,比如添加一个请求头 source=gateway。只要经过网关的请求,网关就会给它打上 source=gateway 的标识。接口 A 就可以根据这个请求头来判断,如果请求没有 source=gateway 这个标识,就直接拒绝掉它。这就是流量染色的一种应用。流量染色还有其他应用,比如区分用户的来源,这和鉴权是不同的概念,属于不同的应用场景。
- 另外一个常见的应用是用于排查用户调用接口时出现的问题。我们为每个用户的每次调用都打上一个唯一的 traceid,这是分布式链路追踪的概念。通过这个 traceid,当出现问题时,下游服务可以根据 traceid 追踪到具体的请求,从而逐层排查问题。这也是流量染色的作用之一。
参考文档:TheAddRequestHeaderGatewayFilterFactory。
💡 用户怎么绕过网关?
用户只要知道服务器的 IP 地址,尤其你的服务又在外网上公开时,用户就可以直接绕过网关进行访问。这种情况下,我们不能让这些接口直接对外暴露,而需要网关来隐藏这些接口信息。
统一接口保护:涉及多种方式,例如限制请求信息、数据脱敏、降级、限流、超时时间等措施,强调了统一的管理。
- 对于接口保护,我们可以通过网关统一限制请求的大小,确保接收到的请求在合理的范围内,避免恶意请求或者大量请求对后端服务造成不必要的负担。
限制请求参考文档:requestheadersize-gatewayfilter-factory
- 有些接口原本会在响应头中返回服务器的 IP 地址等敏感信息,但通过网关的操作,我们可以将这些敏感信息抹掉或删除,保护服务器的隐私和安全。
信息脱敏参考文档:the-removerequestheader-gatewayfilter-factory
- 另一个重要的保护机制是降级。当接口调用失败或接口下线时,我们可以采取降级逻辑,比如向用户提示接口已下线,或引导用户访问其他功能,从而确保用户始终能够得到有意义的响应。
降级(熔断)参考文档:fallback-headers
- 限流也是接口保护的重要手段。通过限制用户每分钟或每秒钟访问接口的次数,可以避免过多的请求对服务器造成压力。
限流参考文档:the-requestratelimiter-gatewayfilter-factory
- 设置超时时间也是保护服务器的一种方式,当接口调用时长超过设定时间,强制中断请求,保证服务器的稳定性。
超时时间参考文档:http-timeouts-configuration
网关的分类
- 全局网关(接入层网关):主要功能是负载均衡,将大量的请求平均分摊到系统中的多台机器上。它通常不涉及过多的业务逻辑,而更注重处理请求日志等任务。
- 业务网关(微服务网关):更多地关注业务逻辑,例如统计次数、鉴权等,同时也会负责转发请求到具体的业务处理单元
技术选型
Kong 是专门为 API 服务提供的网关。但是不推荐使用 Kong 的原因是,它有商业版本和免费版本,而免费版本可能会有一些限制。
Nginx 是比较推荐的全局网关,也称为接入层网关。Nginx 可以部署前端和后端,还能提供文件访问服务等多种功能,非常灵活。我们甚至可以在 Nginx 中编写业务逻辑,但是并不推荐这样做,因为它并不像 Spring Cloud Gateway 那样方便。
Spring Cloud Gateway ,取代了 Zuul。Zuul 的架构设计有一些问题,例如并发量有限。而 Spring Cloud Gateway 则使用了 NIO 和多路复用等技术,底层采用了 native 和 react 模型,因此性能更高。最大优点是它允许我们使用 Java 代码来编写逻辑。
Spring Cloud Gateway
访问:
核心概念
路由:用于根据请求的网址进行转发
断言:一组规则、条件,用来确定如何转发路由
过滤器:对请求进行一系列的处理,比如添加请求头、添加请求参数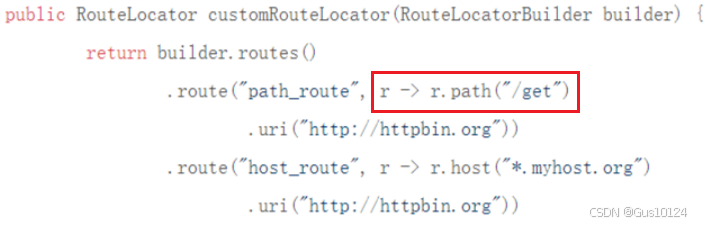
在这里我们定义的是一个匹配器,或者更明确地说,在 Spring Cloud Gateway 中它被称为"断言"。
两种配置方式:
-
配置式(方便、规范,推荐)
-
编程式(灵活、相对麻烦)
如何配置这个路由、过滤器和断言呢?Spring Cloud Gateway 提供了两种方式。第一种方式是配置式或者叫声明式配置,就是在 application.yml文件中写配置(推荐)。
它的配置式分为两种,一种是简单的参数,像下图这样(推荐):
spring:
cloud:
gateway:
routes:
- id: after_route
uri: https://example.org
predicates:
- After=2017-01-20T17:42:47.789-07:00[America/Denver]
- spring.cloud.gateway.routes: 这是配置路由的属性。
- - id: after_route: 这是路由的唯一标识符,用于区分不同的路由。
- uri: https://example.org: 这是路由将请求转发到的目标 URI,即请求经过此路由后将被转发到 https://example.org 这个地址。
- predicates: 这是断言的配置属性,用于定义请求是否满足路由条件。
- - Cookie=mycookie,mycookievalue: 这是一个断言条件,它指定了请求必须具有名为 mycookie 的 Cookie,且其值必须为 mycookievalue,才能匹配这个路由。
通过这个配置,当满足请求带有特定mycookie 的 Cookie 并且其值为mycookievalue时,请求将被路由到https://example.org这个目标 URI。
请求流程
- 客户端发起请求
- Handler Mapping:根据断言,去将请求转发到对应的路由
- Web Handler:处理请求(一层层经过过滤器)
- 实际调用服务
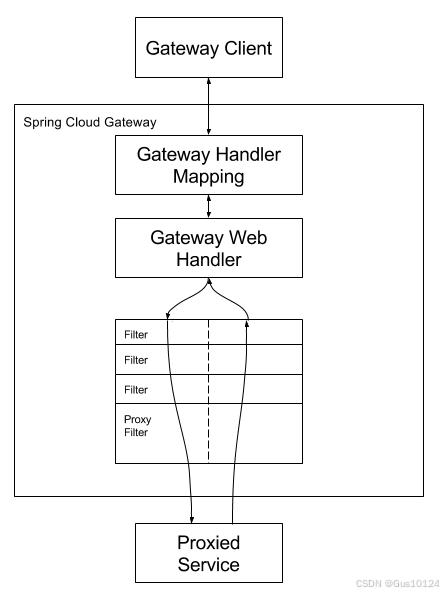
断言:
- After 在 xx 时间之后
- Before 在 xx 时间之前
- Between 在 xx 时间之间
- 请求类别
- 请求头(包含 Cookie)
- 查询参数
- 客户端地址
- 权重
过滤器:
基本功能:对请求头、请求参数、响应头的增删改查。
- 添加请求头
- 添加请求参数
- 添加响应头
- 降级
- 限流
- 重试


















 4650
4650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










