




 本文介绍了一种使用机器学习,特别是深度学习技术,来破解彩色数学验证码的方法。通过识别图片、训练Keras模型,然后进行验证,展示了从数据准备到模型应用的全过程。
本文介绍了一种使用机器学习,特别是深度学习技术,来破解彩色数学验证码的方法。通过识别图片、训练Keras模型,然后进行验证,展示了从数据准备到模型应用的全过程。
背景
机器学习,即Machine Learning,属于AI范畴,是深度学习的父集。 通过如何用机器学习(ML)在15分钟内破解图片验证码的一篇文章,看到了solving-captchas-code-examples项目。作者通过神经网络训练简单的model来破解了形如下图的图片验证码:

正文
根据该example,打算拿来练练手。当然不能止步于示例中的简单验证码,随手打开了几个网页,搜集了下如图所示的彩色的图片验证码:
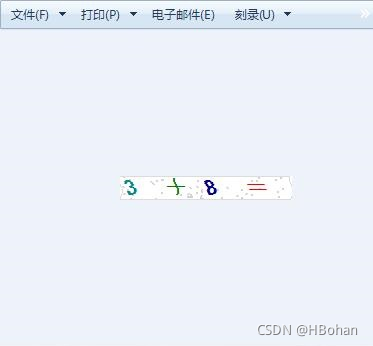
选定了上述的带数学算数的图形验证码,接下来开始上路了。 大致的思路是:识别图片->训练模型(model)->生产验证
一、识别图片
这个识别图片不是OCR的意思,是相当于你教会计算机去认识图片中的数字。 比如,你拿一张写着数字1的图片,然后告诉计算机,这是数字1。
这些基础数据,是作为下一步训练模型的基础的,大家都知道,时下人工智能里,训练个好的模型至关重要。我曾一度认为,源代码是否暴露或者开源已无关紧要,但是经过了大数据的神经网络模型,才是真正的’核心源码’。
所以,我们要获取的验证码图片的基础数据当然越多越好。这里我的初衷是简单实验一下,也不是打造一个专业的破解系统,所以通过爬虫简单保存了二三十张图片,并按照图片内容手动重命名:

接下来,按照各个基础数据图片的文件名,识别、拆分图片中的各个字符,来分类。这里没有照搬example中的代码,通过循环各个图片,来拆分图片并分类存储:
def main(counts, captcha_image_file):
# 结果输出dir
OUTPUT_FOLDER = './result'
# 基础数据dir
captcha_image_files = glob.glob(os.path.join( './subject/' , "*" ))
filename = os.path.basename(captcha_image_file)
captcha_correct_text = os.path.splitext(filename)[ 0 ]
# 加载图像并将其转换成灰度级
image = cv2.imread(captcha_image_file)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 在图像周围添加一些填充物
gray = cv2.copyMakeBorder(gray, 1 , 1 , 1 , 1 , cv2.BORDER_REPLICATE)
# 阈值图像(转换为纯黑色和白色)
# threshold: 输入图像,阈值,输出图像的最大值,阈值的类型,目标图像
# 转换第一次,有浅色情况所以下面转第二次
thresh = cv2.threshold(gray, 200 , 255 , cv2.THRESH_TOZERO)[ 1 ]
# 将图片转为黑白
thresh = cv2.threshold(thresh, 0 , 255 , cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[ 1 ]
# 找到图像的轮廓(连续像素块)
contours = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# OpenCV版本适应
contours = contours[ 0 ] if imutils.is_cv2() else contours[ 1 ]
letter_image_regions = []
# 遍历轮廓,并提取字母
for contour in contours:
# 获取包含轮廓的矩形
(x, y, w, h) = cv2.boundingRect(contour)
# 比较轮廓的宽度和高度来检测字母
if w / h > 1.25 :
# 轮廓太宽,把它分成两个字母区域
half_width = int (w / 2 )
letter_image_regions.append((x, y, half_width, h))
letter_image_regions.append((x + half_width, y, half_width, h)



















 9970
9970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










