



最近在迭代“熙瑾会悟(离线转记)”项目的知识图谱模块时,踩了两个典型生产级问题:
1.多轮对话连续意图识别混乱(断层 / 跳转错误 / 多意图丢失)
2.知识图谱大规模渲染卡顿(节点多就卡、布局乱、交互失效)
这两个问题本质上其实是同一个矛盾:
系统既要“理解复杂对话”,又要“承载复杂结构展示”,最终通过“模型 + 状态机 + 图谱分层渲染”组合方案解决。
一、整体系统架构(核心升级图)
先看整体结构,这一版架构重点补充了“数据流转逻辑”,不只是模块划分。
系统架构图(知识图谱 + 多轮对话 + 可视化)
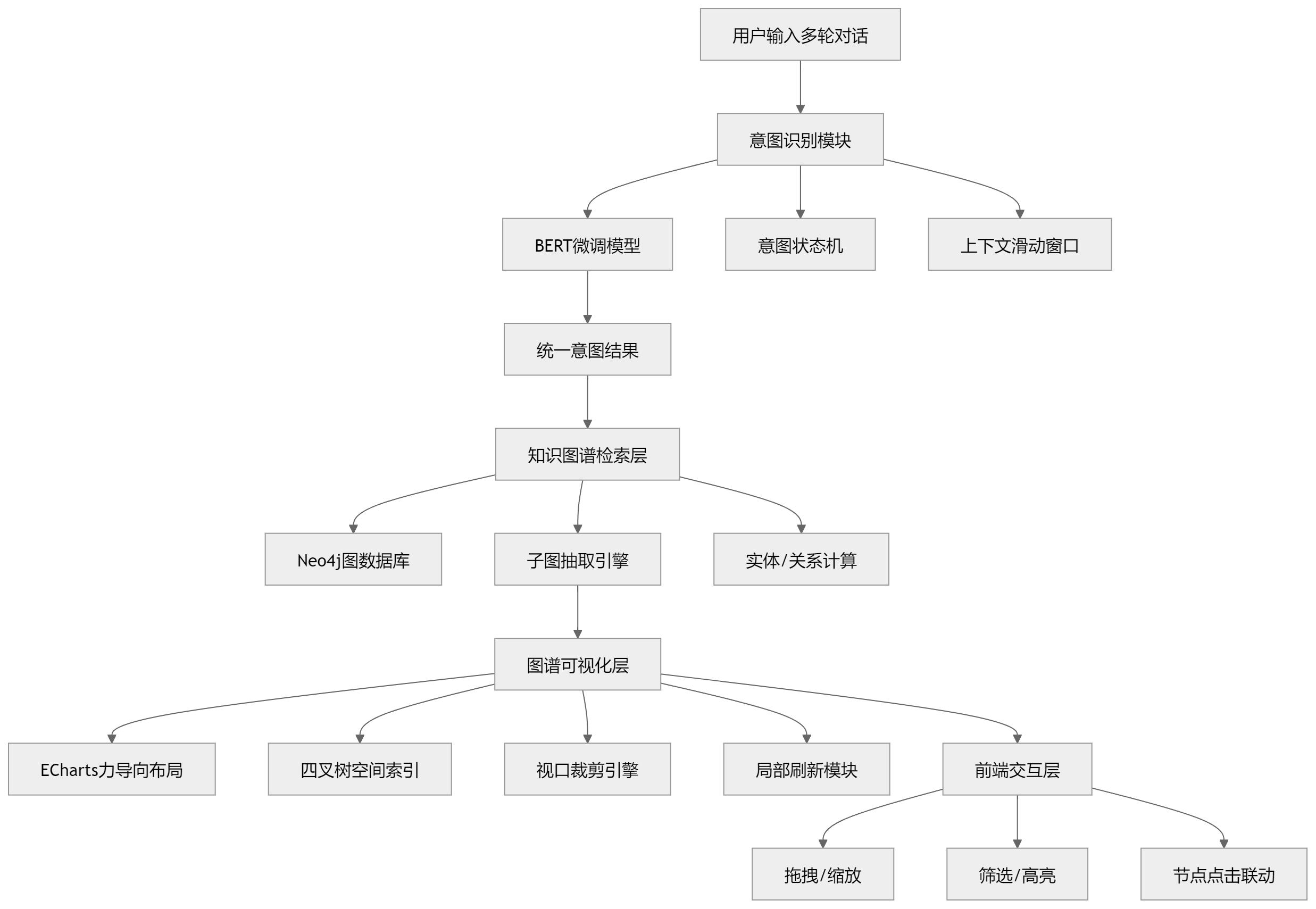
这里有个关键点是:
不是“请求→图谱展示”,而是“对话状态→图结构子集→局部渲染”
二、核心问题1:连续意图识别流程
在没有优化之前,线上经常出现一些很“诡异”的情况:
1.用户刚问完“这个事件是谁参与的”
2.下一句说“那他后来去了哪里”
3.系统却重新开始一个新查询
4.或者继续沿用旧意图,导致查询跑偏
还有更严重的:
一句话里同时包含两个意图
例如:“把这个事件的时间线整理一下,并导出相关人物” 系统只能识别成“时间线查询”,直接丢掉导出意图
多轮对话意图处理时序图
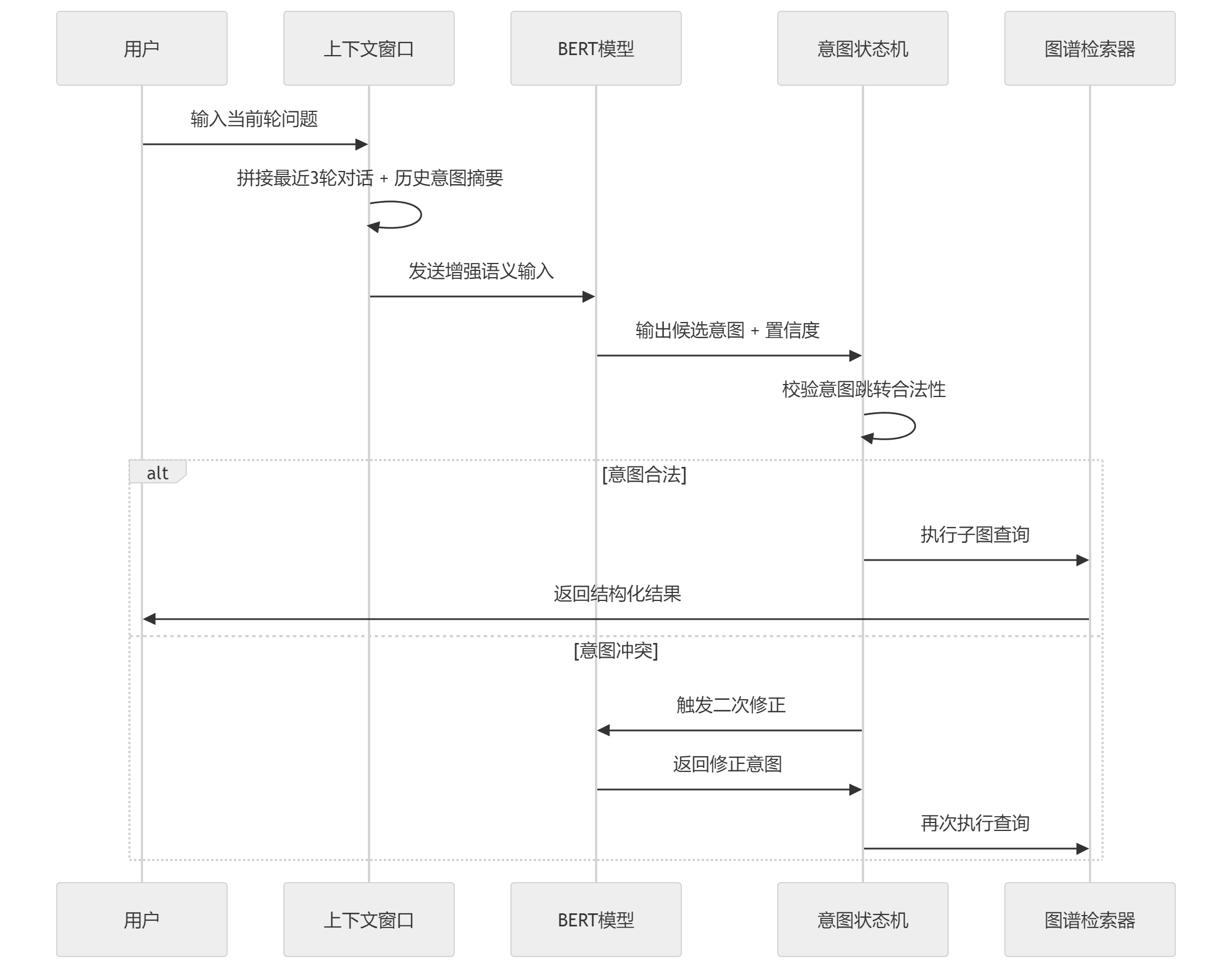
1)意图体系从“分类问题”改成“路径问题”
以前是:
输入 → 分类标签
现在变成:
输入 → 意图节点 → 状态迁移路径
也就是说:
意图不是一个结果,而是一个“状态节点”
2)上下文窗口不是简单拼接
不是直接把历史文本拼上去,而是做了压缩:
用户问题(原始)
模型意图(结构化)
检索结果摘要(token压缩)
避免上下文爆炸
3)状态机的作用不是“规则替代模型”
很多人容易误解,这里强调一下:
状态机不是替代模型,而是限制模型输出空间
比如:
查询类意图只能跳转到扩展查询
不能直接跳到导出
编辑类必须进入图谱编辑链路
三、核心问题2:知识图谱渲染优化
当图谱节点超过 200+ 后:
页面明显掉帧(尤其拖拽)
CPU 占用飙升
节点之间开始“乱吸附”
频繁触发 layout reflow
点击事件延迟明显
本质原因:
所有节点参与布局计算 + 全量重绘 + 无空间裁剪
图谱渲染优化架构
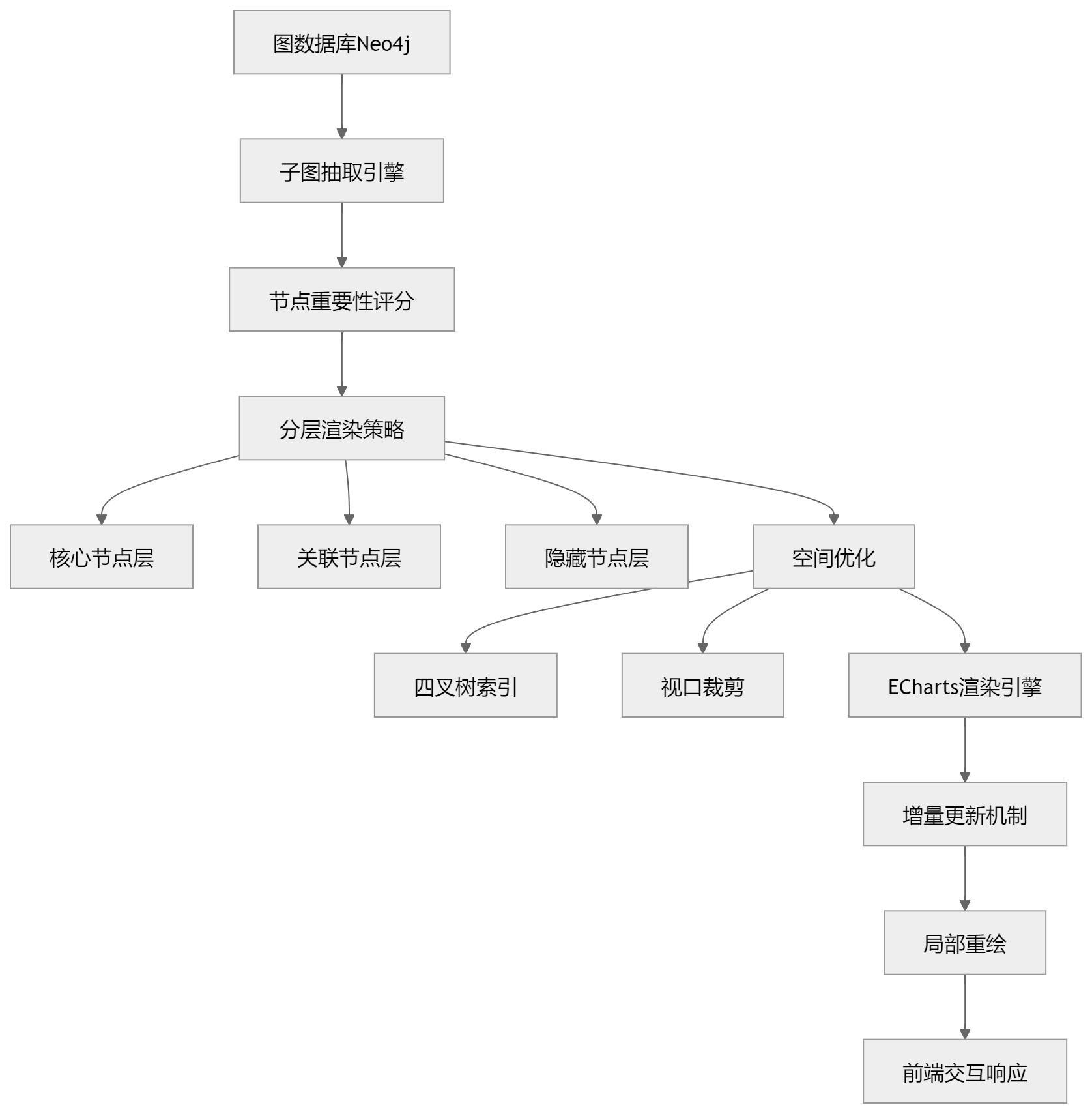
ECharts渲染优化示意图(非常关键)
优化前
所有节点参与 layout
每次交互触发全量 reflow
DOM + canvas 双重压力
结果就是:
“节点越多 → 越卡 → 越重绘 → 更卡”
[所有节点全部渲染]
O--O--O--O--O
|\/|\/|\/|\/|
O--O--O--O--O
|\/|\/|\/|\/|
O--O--O--O--O
问题:
- 节点重叠
- CPU爆炸
- 无层级
- 全量重绘
优化后(分层 + 子图 + 裁剪)
现在变成三层过滤:
① 子图过滤
只保留当前语义相关节点
② 空间过滤
只渲染视口内节点
③ 状态过滤
只更新变化节点
[核心节点]
O
/ | \
O---- O ----O
[关联层] [弱隐藏层]
特点:
- 只展示1~2跳关系
- 非核心节点默认隐藏
- 按权重分层展示
关键优化点补充说明
1)四叉树不是“优化手段”,是“前置筛选器”
它的作用是:
在渲染前就把无关节点过滤掉
2)局部刷新不是“优化点”,而是“重构点”
以前:
改一个节点 → 全图重画
现在:
改节点 → diff更新
3)力导向布局必须“收敛控制”
新增逻辑:
达到稳定阈值后停止迭代
防止无限抖动计算
四、最终效果(优化后)
优化后变化比较明显:
多轮对话基本不会再“跑题”
用户追问链路稳定
图谱可以稳定展示 500+ 节点
缩放/拖拽流畅无明显延迟
低配设备不会再出现闪退
CPU占用整体下降约 40%
更重要的是:
用户终于能“顺着图看懂知识关系”,而不是“看一堆点”
五、最终总结
本次针对熙瑾会悟(离线转记)知识图谱模块的优化实践,重点解决了多轮对话场景下的连续意图识别混乱以及大规模图谱渲染性能瓶颈问题。通过引入BERT微调模型、意图状态机、上下文滑动窗口机制,以及子图提取、四叉树索引、视口裁剪和局部刷新等优化方案,显著提升了系统的语义理解能力和图谱交互体验。实践证明,知识图谱项目的落地不仅依赖模型能力,更依赖对业务场景的深度适配和工程化优化能力。


















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










