







问题导读
1.MapReduce是如何执行任务的?
2.Mapper任务是怎样的一个过程?
3.Reduce是如何执行任务的?
4.键值对是如何编号的?
5.实例,如何计算没见最高气温?
分析MapReduce执行过程
MapReduce运行的时候,会通过Mapper运行的任务读取HDFS中的数据文件,然后调用自己的方法,处理数据,最后输出。Reducer任务会接收Mapper任务输出的数据,作为自己的输入数据,调用自己的方法,最后输出到HDFS的文件中。整个流程如图: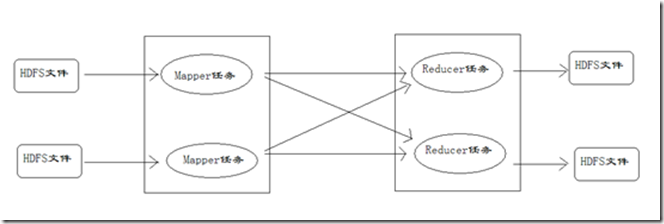
Mapper任务的执行过程详解
每个Mapper任务是一个java进程,它会读取HDFS中的文件,解析成很多的键值对,经过我们覆盖的map方法处理后,转换为很多的键值对再输出。整个Mapper任务的处理过程又可以分为以下几个阶段,如图所示。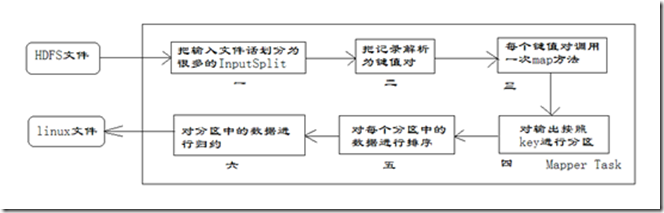
在上图中,把Mapper任务的运行过程分为六个阶段。
-
第一阶段是把输入文件按照一定的标准分片(InputSplit),每个输入片的大小是固定的。默认情况下,输入片(InputSplit)的大小与数据块(Block)的大小是相同的。如果数据块(Block)的大小是默认值64MB,输入文件有两个,一个是32MB,一个是72MB。那么小的文件是一个输入片,大文件会分为两个数据块,那么是两个输入片。一共产生三个输入片。每一个输入片由一个Mapper进程处理。这里的三个输入片,会有三个Mapper进程处理。
-
第二阶段是对输入片中的记录按照一定的规则解析成键值对。有个默认规则是把每一行文本内容解析成键值对。“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
-
第三阶段是调用Mapper类中的map方法。第二阶段中解析出来的每一个键值对,调用一次map方法。如果有1000个键值对,就会调用1000次map方法。每一次调用map方法会输出零个或者多个键值对。
-
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。比较是基于键进行的。比如我们的键表示省份(如北京、上海、山东等),那么就可以按照不同省份进行分区,同一个省份的键值对划分到一个区中。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务。
-
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到本地的linux文件中。
-
第六阶段是对数据进行归约处理,也就是reduce处理。键相等的键值对会调用一次reduce方法。经过这一阶段,数据量会减少。归约后的数据输出到本地的linxu文件中。本阶段默认是没有的,需要用户自己增加这一阶段的代码。
Reducer任务的执行过程详解
每个Reducer任务是一个java进程。Reducer任务接收Mapper任务的输出,归约处理后写入到HDFS中,可以分为如下图所示的几个阶段。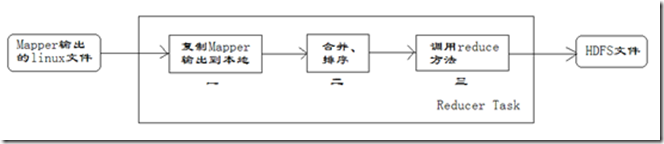
-
第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
-
第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
-
第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中。
在整个MapReduce程序的开发过程中,我们最大的工作量是覆盖map函数和覆盖reduce函数。
键值对的编号
在对Mapper任务、Reducer任务的分析过程中,会看到很多阶段都出现了键值对,读者容易混淆,所以这里对键值对进行编号,方便大家理解键值对的变化情况,如下图所示。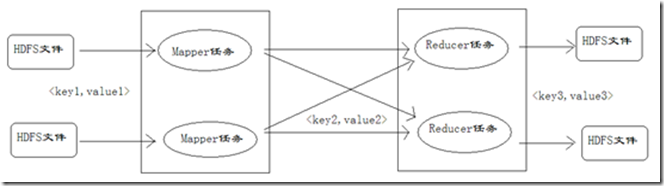
在上图中,对于Mapper任务输入的键值对,定义为key1和value1。在map方法中处理后,输出的键值对,定义为key2和value2。reduce方法接收key2和value2,处理后,输出key3和value3。在下文讨论键值对时,可能把key1和value1简写为<k1,v1>,key2和value2简写为<k2,v2>,key3和value3简写为<k3,v3>。
以上内容来自:http://www.superwu.cn/2013/08/21/530/
-----------------------分------------------割----------------线-------------------------
例子:求每年最高气温
在HDFS中的根目录下有以下文件格式: /input.txt
[Plain Text] 纯文本查看 复制代码
| 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
|
比如:2010012325表示在2010年01月23日的气温为25度。现在要求使用MapReduce,计算每一年出现过的最大气温。
在写代码之前,先确保正确的导入了相关的jar包。我使用的是maven,可以到http://mvnrepository.com去搜索这几个artifactId。
此程序需要以Hadoop文件作为输入文件,以Hadoop文件作为输出文件,因此需要用到文件系统,于是需要引入hadoop-hdfs包;我们需要向Map-Reduce集群提交任务,需要用到Map-Reduce的客户端,于是需要导入hadoop-mapreduce-client-jobclient包;另外,在处理数据的时候会用到一些hadoop的数据类型例如IntWritable和Text等,因此需要导入hadoop-common包。于是运行此程序所需要的相关依赖有以下几个:
[XML] 纯文本查看 复制代码
| 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 |
|
包导好了后, 设计代码如下:
[Java] 纯文本查看 复制代码
| 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050 051 052 053 054 055 056 057 058 059 060 061 062 063 064 065 066 067 068 069 070 071 072 073 074 075 076 077 078 079 080 081 082 083 084 085 086 087 088 089 090 091 092 093 094 095 096 097 098 099 100 101 102 103 104 105 |
|
上面代码中,注意Mapper类的泛型不是java的基本类型,而是Hadoop的数据类型Text、IntWritable。我们可以简单的等价为java的类String、int。
代码中Mapper类的泛型依次是<k1,v1,k2,v2>。map方法的第二个形参是行文本内容,是我们关心的。核心代码是把行文本内容按照空格拆分,把每行数据中“年”和“气温”提取出来,其中“年”作为新的键,“温度”作为新的值,写入到上下文context中。在这里,因为每一年有多行数据,因此每一行都会输出一个<年份, 气温>键值对。
下面是控制台打印结果:
[Plain Text] 纯文本查看 复制代码
| 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
|
执行结果: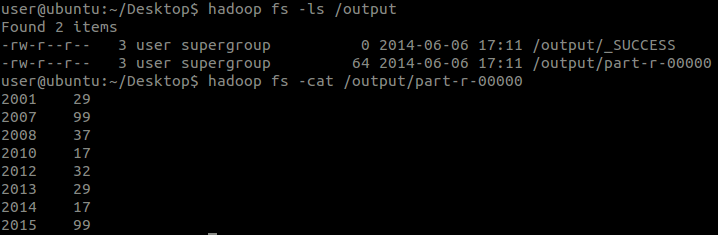
对分析的验证
从打印的日志中可以看出:
-
Mapper的输入数据(k1,v1)格式是:默认的按行分的键值对<0, 2010012325>,<11, 2012010123>...
-
Reducer的输入数据格式是:把相同的键合并后的键值对:<2001, [12, 32, 25...]>,<2007, [20, 34, 30...]>...
-
Reducer的输出数(k3,v3)据格式是:经自己在Reducer中写出的格式:<2001, 32>,<2007, 34>...
其中,由于输入数据太小,Map过程的第1阶段这里不能证明。但事实上是这样的。
结论中第一点验证了Map过程的第2阶段:“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
另外,通过Reduce的几行
[Plain Text] 纯文本查看 复制代码
| 1 2 3 4 5 6 7 8 |
|
可以证实Map过程的第4阶段:先分区,然后对每个分区都执行一次Reduce(Map过程第6阶段)。
对于Mapper的输出,前文中提到:如果没有Reduce过程,Mapper的输出会直接写入文件。于是我们把Reduce方法去掉(注释掉第95行即可)。
再执行,下面是控制台打印结果:
[Plain Text] 纯文本查看 复制代码
| 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
|
再来看看执行结果: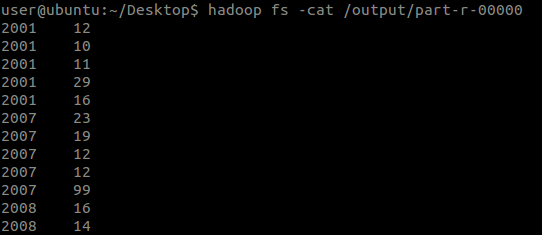
结果还有很多行,没有截图了。
由于没有执行Reduce操作,因此这个就是Mapper输出的中间文件的内容了。
从打印的日志可以看出:
-
Mapper的输出数据(k2, v2)格式是:经自己在Mapper中写出的格式:<2010, 25>,<2012, 23>...
从这个结果中可以看出,原数据文件中的每一行确实都有一行输出,那么Map过程的第3阶段就证实了。
从这个结果中还可以看出,“年份”已经不是输入给Mapper的顺序了,这也说明了在Map过程中也按照Key执行了排序操作,即Map过程的第5阶段。

















&spm=1001.2101.3001.5002&articleId=100578316&d=1&t=3&u=72ec8e734bf34316b39a37c305a898b4)
 2035
2035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










