




 本文探讨了最大似然估计(MLE)与最大后验概率(MAP)的区别,指出MAP在数据有限时结合先验知识更可靠。随着数据增加,MAP趋近于MLE。当面临计算下溢问题时,通常在对数空间中进行计算。若先验概率遵循高斯分布,等价于L2正则化;若遵循拉普拉斯分布,则对应L1正则化。
本文探讨了最大似然估计(MLE)与最大后验概率(MAP)的区别,指出MAP在数据有限时结合先验知识更可靠。随着数据增加,MAP趋近于MLE。当面临计算下溢问题时,通常在对数空间中进行计算。若先验概率遵循高斯分布,等价于L2正则化;若遵循拉普拉斯分布,则对应L1正则化。
往期文章链接目录
MLE v.s. MAP
- MLE: learn parameters from data.
- MAP: add a prior (experience) into the model; more reliable if data is limited. As we have more and more data, the prior becomes less useful.
- As data increase, MAP → \rightarrow → MLE.
Notation: D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } D = \{(x_1, y_1), (x_2, y_2), ..., (x_n, y_n)\} D={(x1,y1),(x2,y2),...,(xn,yn)}
Framework:
- MLE: a r g m a x P ( D ∣ θ ) \mathop{\rm arg\,max} P(D \,|\, \theta) argmaxP(D∣θ)
- MAP: a r g m a x P ( θ ∣ D ) \mathop{\rm arg\,max} P(\theta \,|\, D) argmaxP(θ∣D)
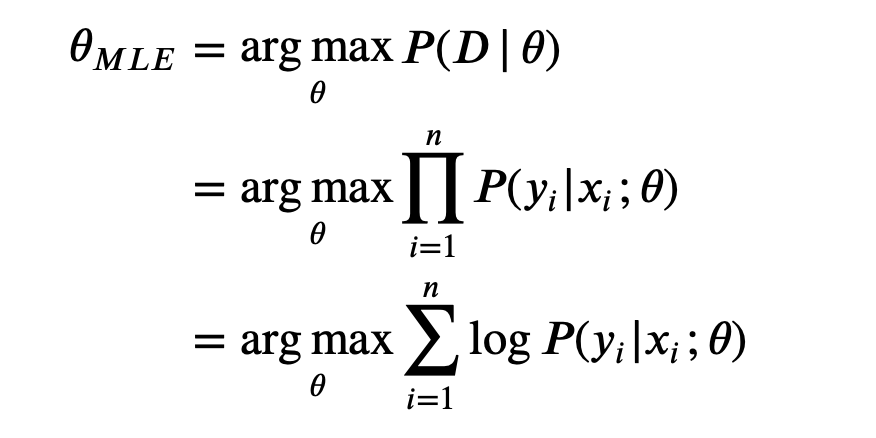
Note that taking a product of some numbers less than 1 would approaching 0 as the number of those numbers goes to infinity, it would be not practical to compute, because of computation underflow. Hence, we will instead work in the log space.
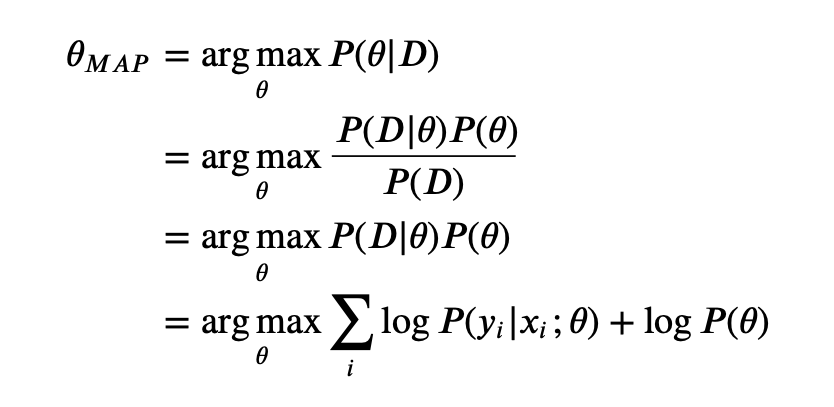
Comparing both MLE and MAP equation, the only thing differs is the inclusion of prior
P
(
θ
)
P(\theta)
P(θ) in MAP, otherwise they are identical. What it means is that, the likelihood is now weighted with some weight coming from the prior.
If the prior follows the normal distribution, then it is the same as adding a L 2 L2 L2 regularization.
We assume P ( θ ) ∼ N ( 0 , σ 2 ) P(\theta) \sim \mathcal{N}(0, \sigma^2) P(θ)∼N(0,σ2), then P ( x ) = 1 σ 2 π e x p ( − θ 2 2 σ 2 ) P(x) = \frac{1}{\sigma \sqrt {2\pi}}exp(-\frac{\theta^2}{2\sigma^2}) P(x)=σ2π1exp(−2σ2θ2)
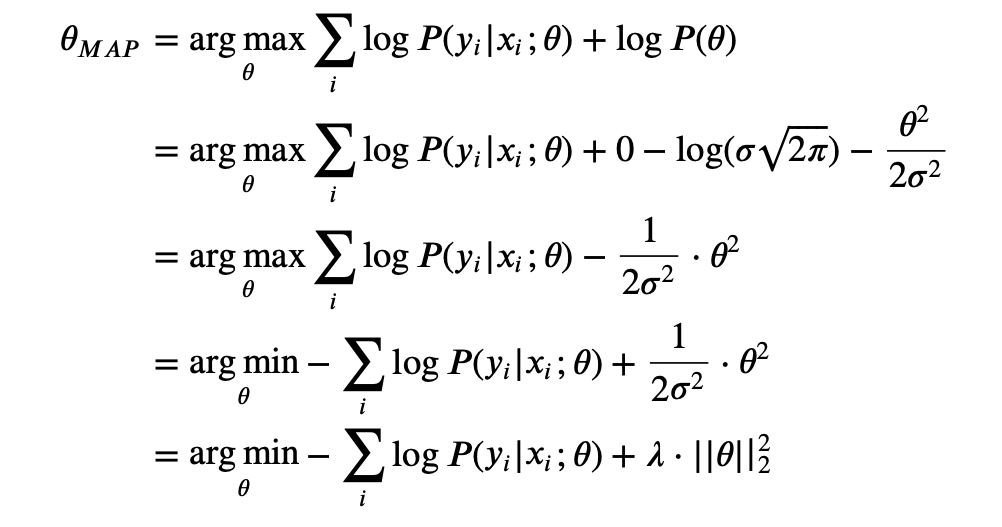
If the prior follows the Laplace distribution, then it is the same as adding a L 1 L1 L1 regularization.
We assume P ( θ ) ∼ L a p l a c e ( μ = 0 , b ) P(\theta) \sim Laplace \,(\mu=0, b) P(θ)∼Laplace(μ=0,b), then P ( θ ) = 1 2 b e x p ( − ∣ θ ∣ b ) P(\theta) = \frac{1}{2b}exp(-\frac{|\theta|}{b}) P(θ)=2b1exp(−b∣θ∣)
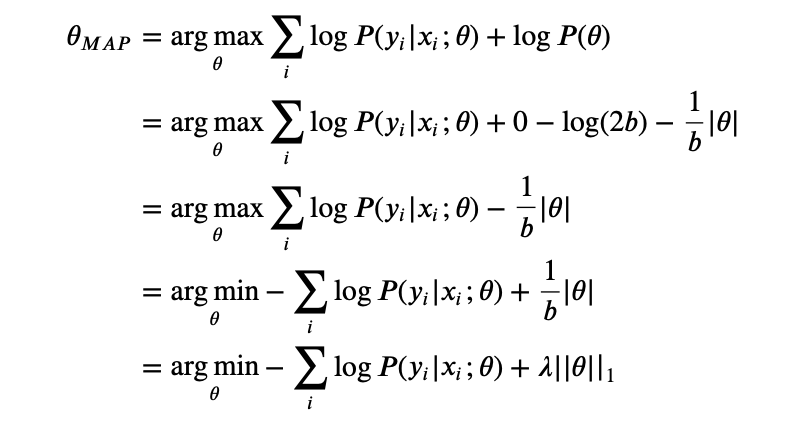


















 2469
2469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










