




 本文详细介绍了Hadoop分布式文件系统HDFS的基础知识,包括HDFS的概述、数据存储模式、副本策略和机架感知。讲解了HDFS的读写流程,列举了常用命令如cat、ls、mkdir等,并展示了如何通过HDFSAPI进行基础编程,如创建、删除文件,上传、下载文件等操作。此外,还提到了安全模式和Eclipse环境的配置。
本文详细介绍了Hadoop分布式文件系统HDFS的基础知识,包括HDFS的概述、数据存储模式、副本策略和机架感知。讲解了HDFS的读写流程,列举了常用命令如cat、ls、mkdir等,并展示了如何通过HDFSAPI进行基础编程,如创建、删除文件,上传、下载文件等操作。此外,还提到了安全模式和Eclipse环境的配置。
HDFS常用命令及基础编程
JunLeon——go big or go home

目录
前言:
HDFS是Hadoop的分布式文件系统,旨在运行在商品硬件上。它与现有的分布式文件系统有很多相似之处。但是与其他分布式文件系统的区别是显着的。HDFS 具有高度容错性,旨在部署在低成本硬件上。HDFS 提供对应用程序数据的高吞吐量访问,适用具有大型数据集的应用程序。HDFS 放宽了一些 POSIX 要求,以启用对文件系统数据的流式访问。HDFS 最初是作为 Apache Nutch 网络搜索引擎项目的基础设施而构建的。HDFS 是 Apache Hadoop Core 项目的一部分。
一、HDFS概述
1、什么是HDFS?
HDFS(Hadoop Distributed File System)分布式文件系统。是Hadoop平台的数据存储系统,大多用于存储大型的离线数据。
HDFS 具有主/从架构。HDFS 集群由单个 NameNode 组成,NameNode 是一个主服务器,用于管理文件系统命名空间并管理客户端对文件的访问。此外,还有许多 DataNode,通常集群中的每个节点一个,用于管理连接到它们运行的节点的存储。HDFS 公开了一个文件系统命名空间,并允许将用户数据存储在文件中。在内部,文件被分成一个或多个块,这些块存储在一组 DataNode 中。NameNode 执行文件系统命名空间操作,如打开、关闭和重命名文件和目录。它还确定块到 DataNode 的映射。DataNode 负责处理来自文件系统客户端的读写请求。DataNode 还执行块的创建、删除等操作。
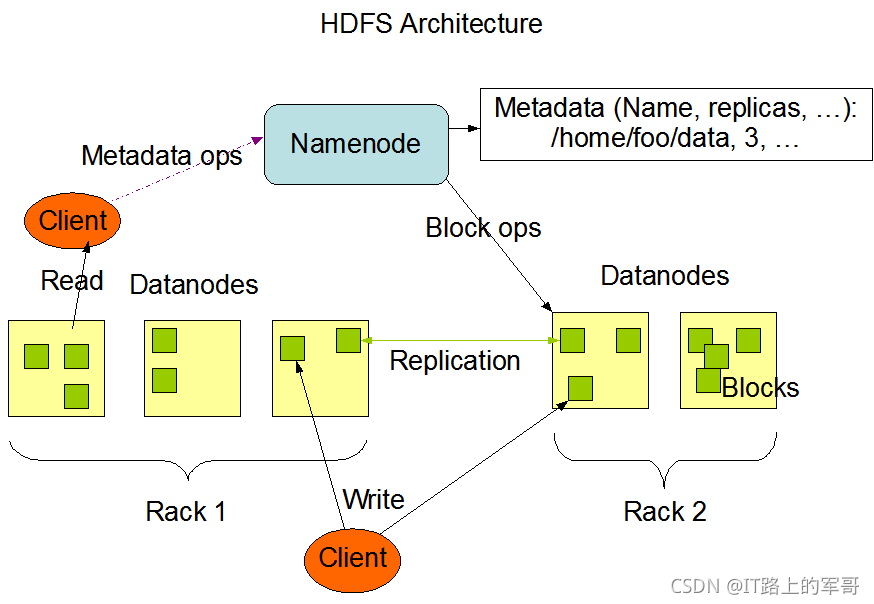
HDFS的Master/Slave架构主要由HDFS Client、NameNode、DataNode和Secondary NameNode四个部分组成,各组件介绍如下:
HDFS Clent:HDFS的客户端,与NameNode交互的程序,职责或功能如下:
(1)文件切分:在上传文件至HDFS的时候,Client会将文件分切成一个个的Block上传;
(2)与NameNode交互,可以获取文件的位置信息(存在哪个节点上);
(3)Client可以通过一些命令来访问HDFS,比如增删改查操作;
(4)Client通过一些命令来管理HDFS,比如将NameNode格式化。
NameNode:就是master,负责管理DataNode和管理HDFS的相关信息:
(1)管理HDFS的名称空间;
(2)管理副本的策略;
(3)管理数据块(Block)的映射信息;
(4)处理客户端的读写请求。
Secondary NameNode:并非是NameNode的热备。当NameNode挂掉的时候,它并不会立即替换NameNode并提供服务。
(1)辅助NameNode,分担其工作量,比如定期合并FsImage和Edits,并将合并后的FsImage.checkPoint推送给NameNode;
(2)在紧急情况下可以辅助恢复NameNode。
DataNode:就是slave,NameNode下达指令,DataNode执行实际的操作:
(1)存储实际的数据块;
(2)执行数据块的读/写操作。
2、HDFS数据存储模式——数据块(block)
HDFS主要以数据块(block)的模式对数据进行存储。
在Hadoop2.0以前,默认数据块大小为64Mb;Hadoop2.0以后版本默认数据块大小为128Mb。 block大小可以通过配置参数(dfs.blocksize)来设置。
采用数据块的模式存储数据的优点:
支持大规模文件存储:一个很大的文件可以被拆分为若干文件块,不同的文件块可以被分发到不同的节点上。因此一个文件的大小不会受单个节点的存储容量的限制。
简化系统设置:首先,简化存储管理,因为文件大小是固定的,这样就很容易算出一个节点可以存放多少文件块。其次,简化元数据的管理,元数据不需要和文件块一起存储。
适合数据备份:每个文件块都可以冗余地存储到多个节点上
3、HDFS的副本存放策略及机架感知
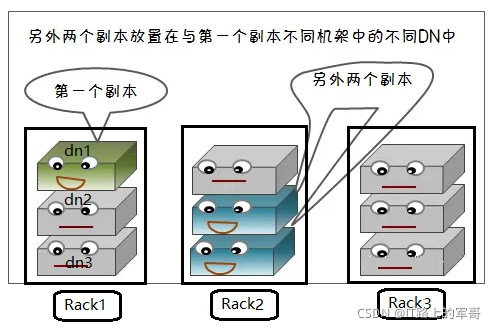
HDFS文件系统中,默认的副本存放数量为3,在写入数据是会自动的进行备份,副本数量可在hdfs-site.xml中(dfs.replication)来设置。
(1)副本存放策略:
1、第一个副本存储在本机(本地节点),这里所说的本地节点是相对于客户端来说的,也就是说某一个用户正在用一个客户端来向HDFS中写数据,如果该客户端上有数据节点,那么就应该最优先考虑把正在写入的数据的一个副本保存在这个客户端的数据节点上,它即被看做是本地节点。
2、第二个副本块存跟本机不同机架内的任意服务器节点。
3、第三个副本块存与第二个副本所在节点同一机架最近的另一个节点上。
作用:保证对该block所属文件的访问能够优先在本rack下找到,如果整个rack发生了异常,也可以在另外的rack上找到该block的副本。这样足够的高效,并且同时做到了数据的容错。这种策略设置可以将副本均匀分布在集群中,有利于当组件失效的情况下的均匀负载。
(2)机架感知:
通常,大型Hadoop集群会分布在很多机架上。在这种情况下,
1.希望不同节点之间的通信能够尽量发生在同一个机架之内,而不是跨机架。
2.为了提高容错能力,名称节点会尽可能把数据块的副本放到多个机架上。
综合考虑这两点的基础上Hadoop设计了机架感知功能
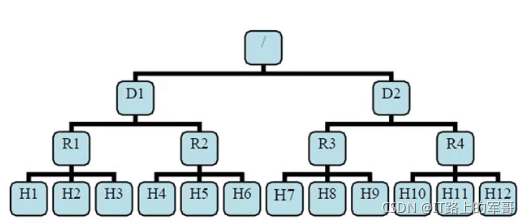
有了机架感知。NameNode就能够画出上图所看到的的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。
则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的parent是D1。这些rackid信息能够通过topology.script.file.name配置。有了这些rackid信息就能够计算出随意两台datanode之间的距离。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode4、HDFS的读写过程
(1)读流程:
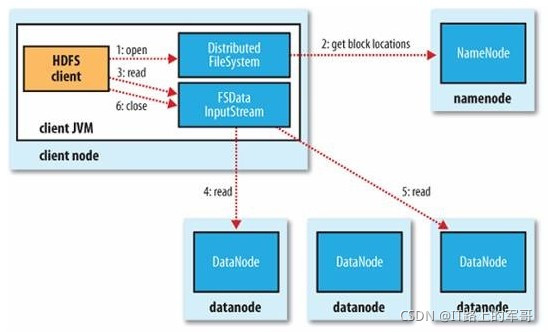
读详细步骤:
1、client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
2、就近挑选一台datanode服务器,请求建立输入流 。
3、DataNode向输入流中中写数据,以packet为单位来校验。
4、关闭输入流
(2)写流程:
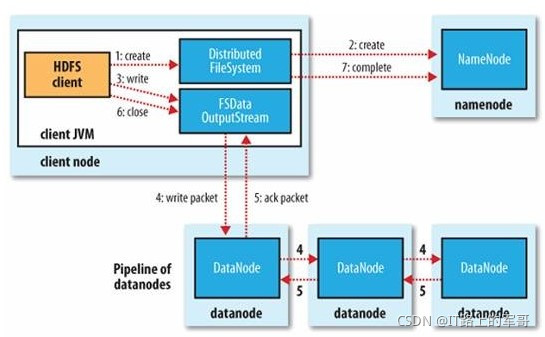
写详细步骤:
1、客户端向NameNode发出写文件请求。
2、检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。
(注:WAL,write ahead log,先写Log,再写内存,因为EditLog记录的是最新的HDFS客户端执行所有的写操作。如果后续真实写操作失败了,由于在真实写操作之前,操作就被写入EditLog中了,故EditLog中仍会有记录)
3、client端按128MB的块切分文件。
4、client将NameNode返回的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和多个DataNode构成pipeline管道。
client向第一个DataNode写入一个packet,这个packet便会在pipeline里传给第二个、第三个…DataNode。
在pipeline反方向上,逐个发送ack(命令正确应答),最终由pipeline中第一个DataNode节点将ack发送给client。
5、写完数据,关闭输输出流.
6、发送完成信号给NameNode。




















HDFS常用命令及HDFS API基础编程&spm=1001.2101.3001.5002&articleId=120837274&d=1&t=3&u=d55f0c3bf3e74674afa113ca52bc30b4)

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












