



聊《Agentic AI:把学习路线变成作品集》之前,先说一句实在的:别急着背概念,先看它在真实项目里到底解决什么问题。
摘要
本文概述文章目标、核心观点和实践价值。
**摘要**
Agentic 架构不是把 Prompt 写长就能跑通的魔法,而是状态机、工具路由与容错策略的组合工程。本文从开发者视角拆解 Agentic 系统的真实构造过程,不聊虚的概念,直接给出能在 GitHub 仓库里复现、在面试时能讲透的实践路径。重点聚焦如何把“自主执行”抽象为可展示的成果,附代码示例与避坑清单,帮助技术人把学习笔记转化为有分量的项目履历。
**目录**
---
Agentic 的定义
很多人对 Agentic 的第一反应是“能自己调工具的智能体”。这个理解没全错,但停留在表层。Chatbot 的本质是上下文窗口里的模式匹配,而 Agentic 的核心是**循环执行与状态演进**。它不再是一次问答,而是一段有起点、有分支、有终点的计算流。
做作品集的时候,很多开发者习惯用 Streamlit 搭个聊天框,塞进 LangChain 的 `create_react_agent` 就交差。这种 Demo 在本地跑得欢,一旦遇到外部服务超时或工具参数格式错误,立刻卡死。我在上一家公司的数据中台项目里吃过亏:起初让 Agent 直接连数据库查数,结果它把 `DROP TABLE` 当成了自然语言建议执行了半分钟才触发熔断。后来我们做了明确区分——底层是工具链(Toolchain),上层才是调度器(Orchestrator)。Agent 只是路由器,真正干活的是经过校验的函数集合。
简历里怎么体现这个认知?不要只放一张聊天截图。把你的架构图画清楚:请求进来后,先经过意图分类,再分发到对应的执行子图,最后汇总结果。把“它只会问不会做”和“它能按规则完成多步操作”之间的工程差异讲出来,比堆砌框架名称有用得多。
自主性边界
自主性是个伪命题,除非你给它画上红线。我在做自动化运维辅助时,团队内部定过三条铁律:读操作默认放行,写操作必须二次确认,高危命令走审批队列。这不是为了限制能力,而是为了控制爆炸半径。
Agent 的“自主”应该体现在**路径选择**上,而不是**权限范围**上。比如同一个查询任务,它可以自行决定先用 Elasticsearch 还是 MySQL,但如果涉及修改配置或触发生产发布,必须落入人工节点。面试时常被问到“你的 Agent 能做到全自动吗”,我的标准回答是:全自动只在沙箱环境成立,生产环境永远保留降级通道。
作品集里可以放一份 `policy.yaml` 或权限矩阵文档,列出每个工具的 `scope`、`timeout`、`retry_count` 和 `approval_required`。评审者看到你能主动管理边界,就知道你不是在拼凑玩具,而是在设计系统。
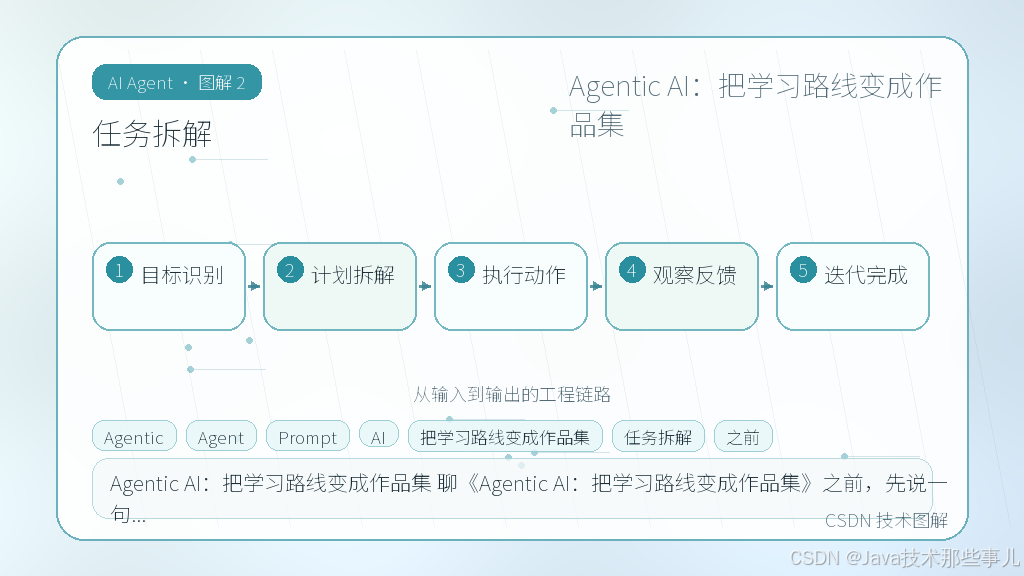
任务拆解
单体 Prompt 处理复杂任务一定会崩。真实的工程做法是把大请求压碎成原子步骤,并用显式状态流转来串联。ReAct 模式适合快速原型,但进入可维护阶段后,图结构(DAG)或有限状态机更靠谱。
下面这段是我在项目里常用的简易拆解与执行骨架,去掉了框架依赖,只保留核心逻辑,方便你移植或改造:
import json
from typing import List, Dict, Any
class TaskPlanner:
def __init__(self, llm_proxy, tool_registry: Dict[str, callable]):
self.llm = llm_proxy
self.tools = tool_registry
self.trace_log = []
def plan_steps(self, query: str) -> List[Dict]:
"""将自然语言请求拆分为结构化步骤"""
prompt = (
f"请将以下需求拆分为可独立执行的步骤。\n"
f"需求: {query}\n"
f"可用工具: {list(self.tools.keys())}\n"
f"返回 JSON 数组,每项包含 {{'step_id', 'tool_name', 'params'}}。"
)
raw = self.llm.call(prompt)

return json.loads(raw)
def run(self, steps: List[Dict]) -> Dict[str, Any]:
"""顺序执行并收集追踪数据"""
results = {}
for step in steps:
tool_fn = self.tools.get(step["tool_name"])
if not tool_fn:
self.trace_log.append(f"MISSING_TOOL: {step['tool_name']}")
continue
try:
res = tool_fn(**step["params"])
results[step["step_id"]] = {"status": "ok", "data": res}
self.trace_log.append(f"STEP_{step['step_id']}: OK | cost={res.get('latency')}ms")
except Exception as e:
results[step["step_id"]] = {"status": "fail", "error": str(e)}
self.trace_log.append(f"STEP_{step['step_id']}: FAIL | {e}")
# 此处可接入重试或回退逻辑
return {"plan": steps, "results": results, "trace": self.trace_log}这段代码没有炫技,但把三个关键动作钉死了:**输入结构化、工具路由、执行留痕**。放在仓库里,配合一段演示视频,说明你是怎么处理参数缺失、网络抖动或工具返回格式不一致的,比单纯贴官方教程强十倍。作品集不要怕暴露复杂度,反而要主动写出你如何处理失败分支。
可观测性
Agent 跑飞的时候,最缺的不是算力,是轨迹。我之前有个项目在压测时发现某个子图反复重试导致 Token 消耗飙升,全靠手动打点才知道是哪个 HTTP 客户端卡在了 TLS 握手阶段。后来我们把 TraceID 贯穿整个生命周期,每个工具调用都带上唯一标识,输出标准化 JSON 日志。
工程实践上,不需要一上来就上复杂的 APM。先在代码里埋几个锚点:计划生成时间、单步耗时、Token 使用量、工具调用次数。把这些指标导出到本地文件或轻量级看板,运行时一目了然。作品集里务必附上运行时的日志片段或 Grafana 截图,并在 README 里写明“某次异常中断的排查路径”。面试官问起可观测性,你能直接拿出具体字段和设计理由,信任感会大幅提升。
安全约束
自主执行最怕的就是越权。我在做财务数据同步 Agent 时,强制所有外部请求走代理层,剥离原始 URL,替换硬编码凭证为环境变量注入,并且对工具参数做白名单校验。SQL 拼接一律改用预编译,Shell 命令禁止直接透传用户输入。
安全不是事后补的补丁,是架构初期的默认选项。你可以写一份简单的威胁模型文档,列出可能的攻击面(如 Prompt 注入、工具滥用、凭据泄露)以及对应的拦截策略。仓库里放一个 `security.md`,记录你在开发过程中做过的安全决策。这部分内容往往被初学者忽略,但它恰恰是区分“玩具项目”和“工程作品”的分水岭。
总结
Agentic AI 的学习曲线不在 API 调用,而在系统思维的建立。从聊天界面走向自主执行,意味着你要同时当好产品经理、架构师和运维人员。作品集的价值不在于你用了哪个最新框架,而在于你能否清晰交代:任务怎么切、状态怎么存、失败怎么兜、权限怎么控。
推荐的学习顺序:先跑通单工具链 → 引入显式状态流转 → 补充日志与指标 → 加上安全代理与审批节点 → 最后封装成可复用的工作流引擎。每一步都在积累可展示的资产。把运行脚本、配置文件、测试用例和故障复盘全部扔进仓库,保持 README 诚实。当你能指着图表说清楚“这一步为什么卡住、我怎么修好的”,你就已经跨过了 Agentic 工程的门槛。
目录
- 总结

资料展示
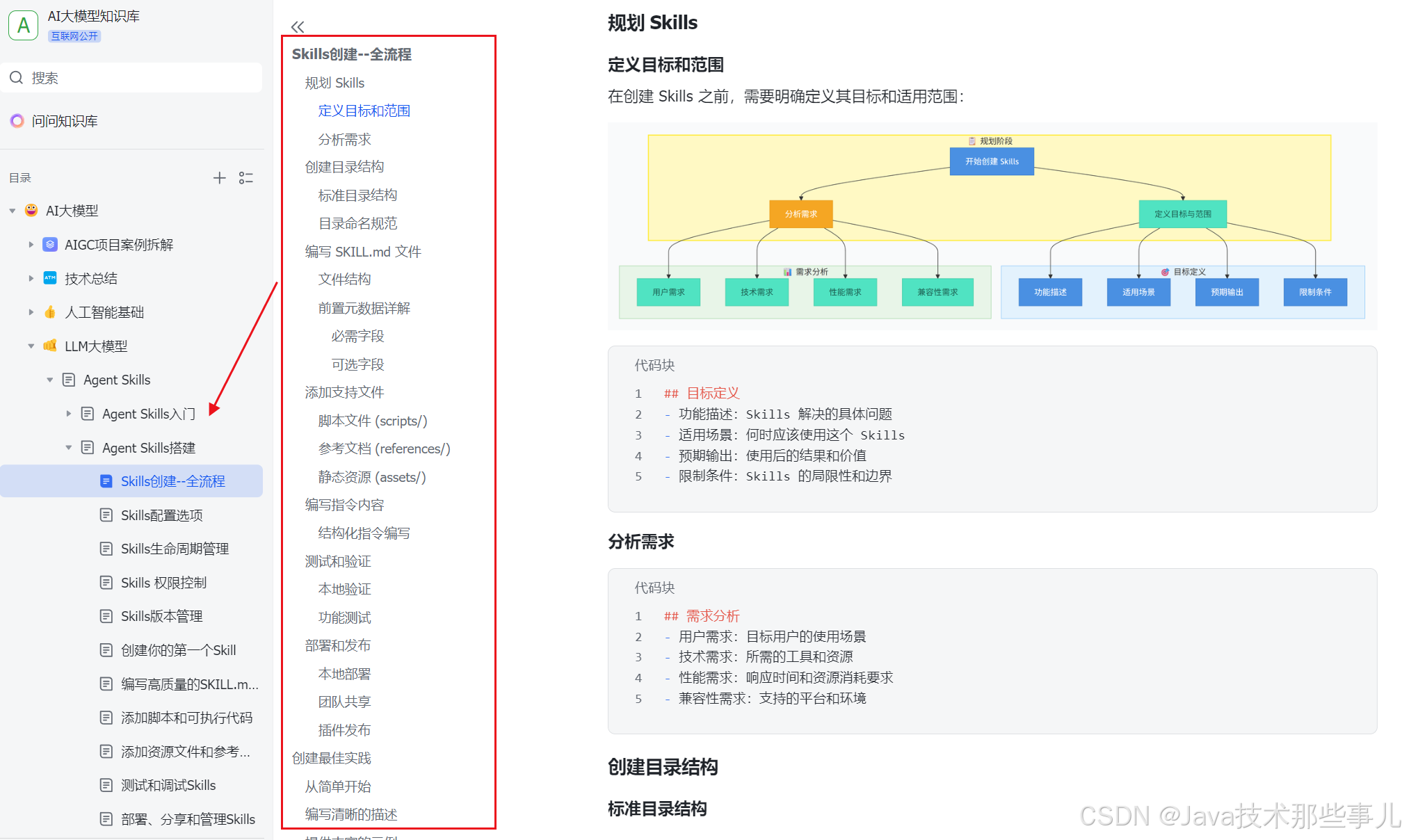
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。
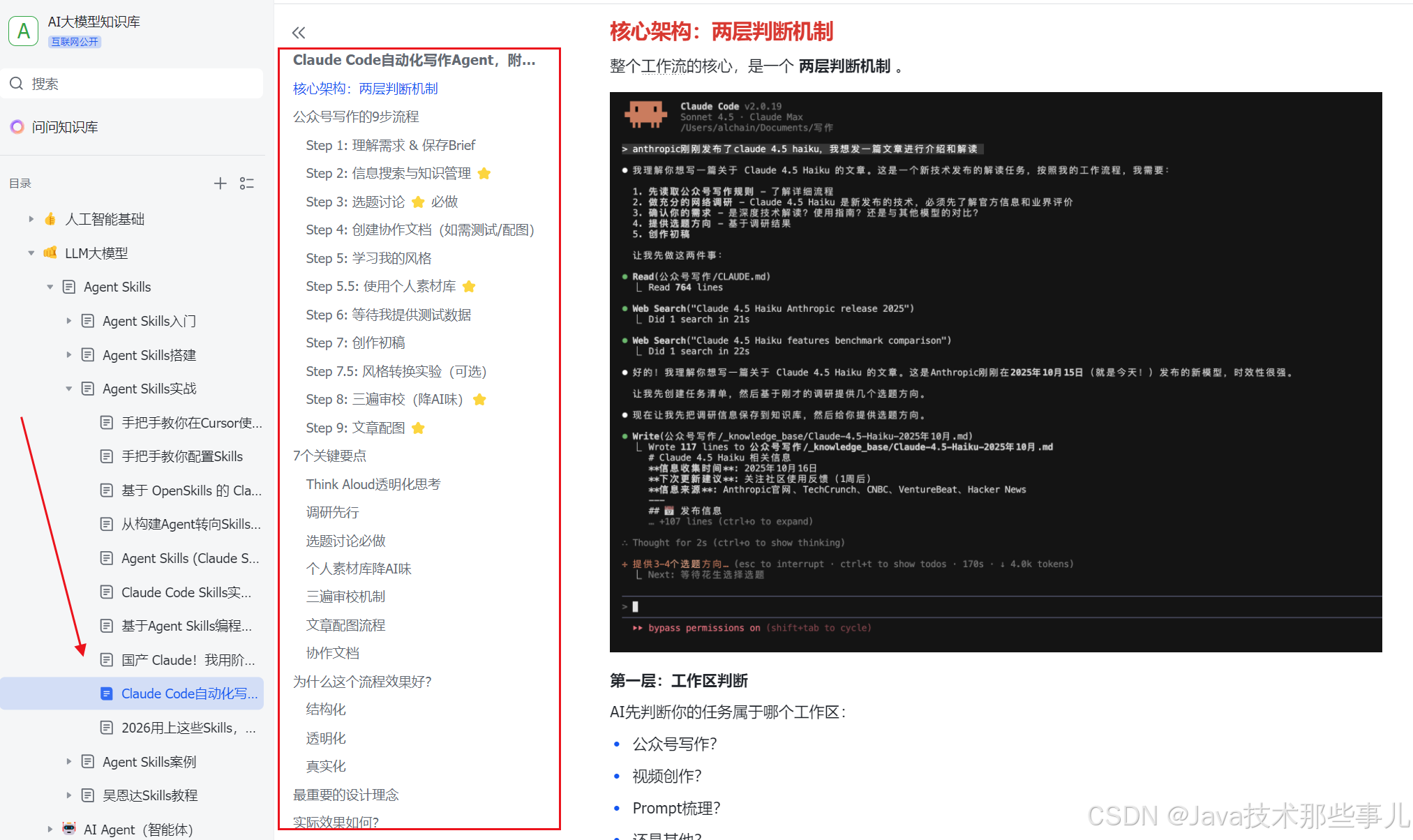
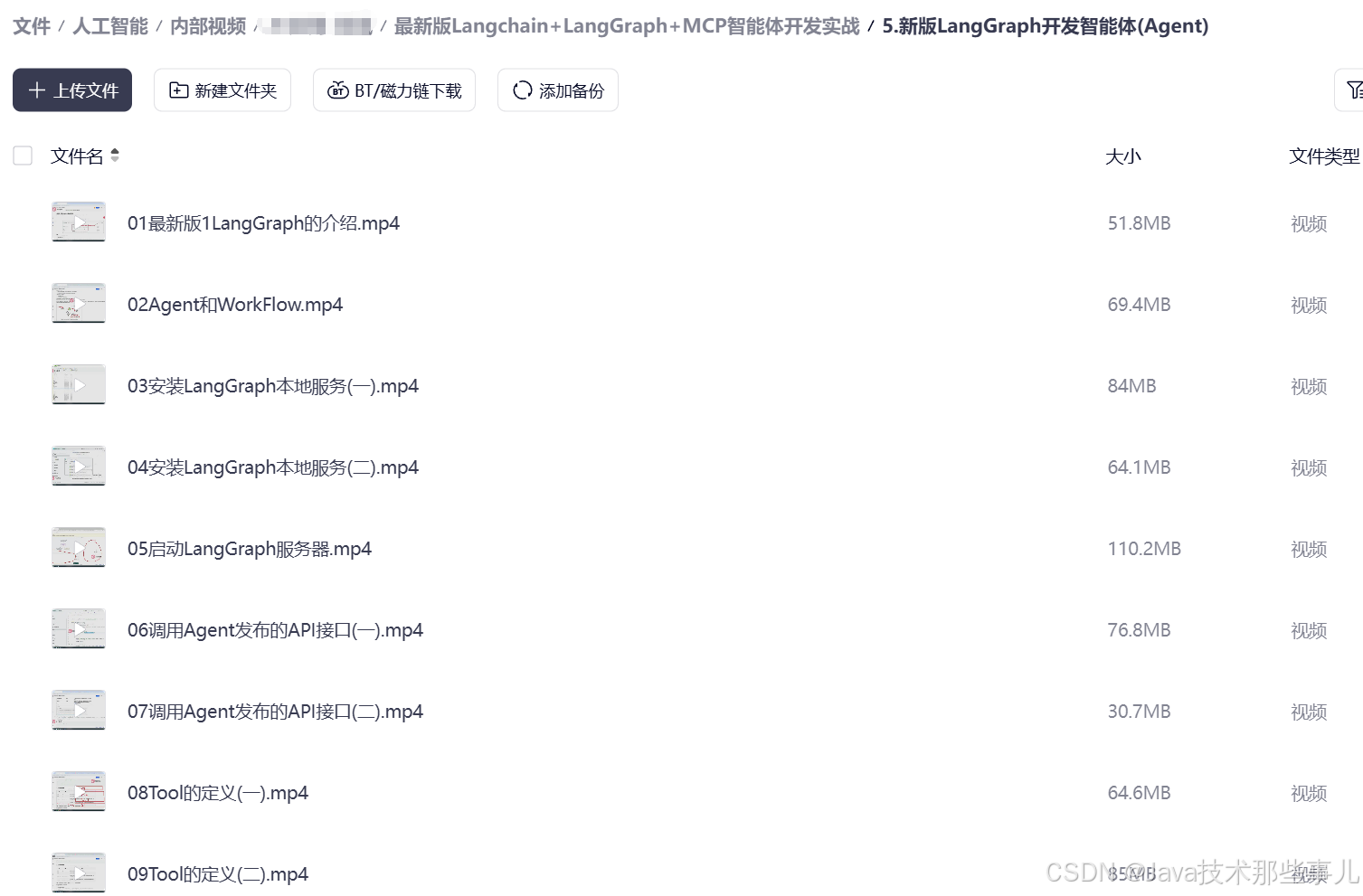
如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。



















 790
790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










