



聊《Codex 实战:简历项目怎么讲清楚》之前,先说一句实在的:别急着背概念,先看它在真实项目里到底解决什么问题。
摘要
本文概述文章目标、核心观点和实践价值。
前阵子带团队重构一个订单履约模块,我试着把 Codex 接进我们的 CI/CD 流水线,目标是让它在代码评审阶段自动拦截低级错误,并辅助生成单元测试。很多人问我:“这玩意儿真的能写生产代码吗?”
我的回答很直接:别把它当“自动修电脑的大师”,把它当成一个“读过你全部文档但有点缺乏常识的初级工程师”。
如果你想在面试或者简历里把这个项目讲清楚,千万别只堆砌“用了 AI”这种虚词。HR 和技术面试官更关心的是:你如何控制风险?出了线上问题怎么快速回滚?你是怎么界定 AI 生成代码的边界的?
这篇复盘,我不聊那些炫技的 Agentic 工作流,只聊最接地气的——在一个真实的 Java 微服务架构里,怎么安全地用 Codex 提效,以及怎么把这个过程包装成你的核心竞争力。
目录
- Codex 的定位:不是替代,是增强
- 项目上下文理解:喂给 AI 的“饲料”质量决定产出
- 代码修改流程:小步快跑,人工介入
- 测试与验证:用自动化构建信任
- 团队使用建议:建立规范而非禁止
- 总结:如何在简历里讲好这个故事?
Codex 的定位:不是替代,是增强
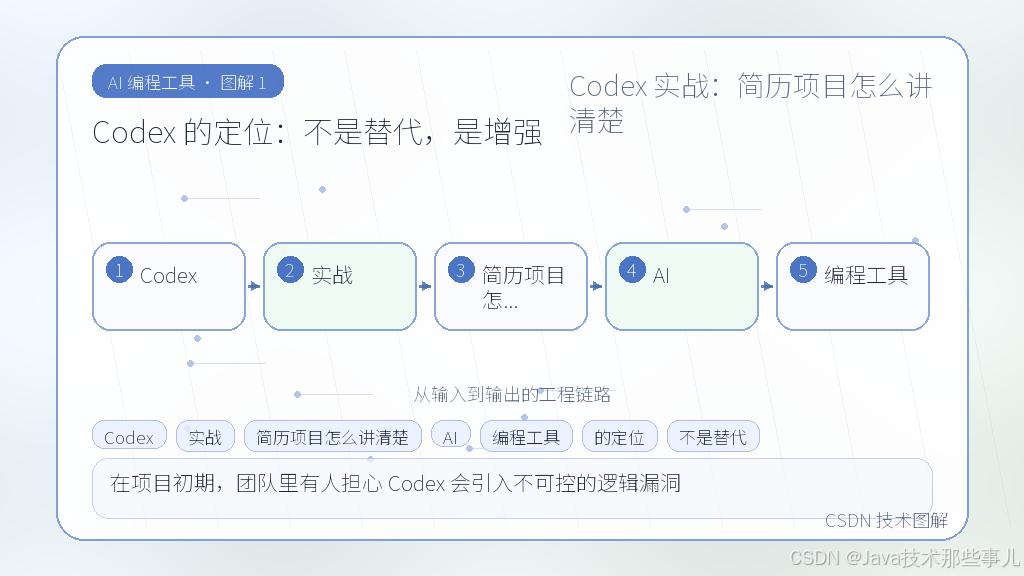
在项目初期,团队里有人担心 Codex 会引入不可控的逻辑漏洞。其实,Codex 的核心价值不在于“写出完美的业务逻辑”,而在于“消除样板代码”和“提供备选方案”。
在我的实际落地中,我们给它划定了三条红线:
1. 严禁直接处理敏感数据:所有涉及 PII(个人身份信息)的代码片段,必须脱敏后输入。
2. 严禁生成核心支付逻辑:支付链路必须由 Senior Dev 手写并 Review。
3. 生成的代码必须通过静态扫描:SonarQube 的 Gate 是硬性门槛,AI 生成的代码如果复杂度超标,直接打回。
这样定位之后,Codex 就变成了一个高效的“结对编程伙伴”,而不是一个黑盒。
项目上下文理解:喂给 AI 的“饲料”质量决定产出

很多开发者抱怨 Codex 生成的代码“不知所云”,问题往往出在 Context 上。它不像人类同事那样能脑补上下文,它需要你提供尽可能多的结构信息。
我们在项目中采用了分层注入策略。对于一个简单的订单查询接口,我不会直接把整个项目丢进去,而是做了如下处理:
首先,提取核心 Domain Model。比如 Order 类、User 类,以及相关的枚举状态。
其次,提供相关的 Repository 接口定义。
最后,给出一个类似的、已测试通过的 Controller 示例作为 Few-Shot 样例。
// 提供给 Codex 的上下文片段示例
public class OrderService {
// 假设这是已有的接口定义
public interface OrderRepository extends JpaRepository<Order, Long> {
List<Order> findByUserIdAndStatus(Long userId, Status status);
}
// 这是一个成功的样例,让 AI 模仿这种风格
@Transactional(readOnly = true)
public List<OrderDto> getOrdersByUser(Long userId) {
List<Order> orders = orderRepository.findByUserIdAndStatus(userId, Status.PENDING);
return orders.stream()
.map(OrderMapper::toDto)
.collect(Collectors.toList());
}
}当你给 Codex 提供这样的结构化上下文时,它生成的代码类型匹配度会从 60% 提升到 90% 以上。这也是我在面试中常提到的点:“我擅长通过 Prompt Engineering 和 Context Management 来降低 AI 的幻觉率。”

代码修改流程:小步快跑,人工介入
在实战中,我推荐采用 “Diff Review -> Apply” 的模式,而不是让 AI 直接 Commit。
每次修改,我会让 Codex 生成一段具体的 Method 实现,然后我自己进行人工 Diff 审查。重点关注以下三点:
1. 异常处理是否遗漏:AI 经常会忽略非受检异常。
2. 事务边界是否正确:特别是在嵌套调用时,AI 容易搞错 Propagation 级别。
3. 依赖注入是否混乱:确保它没有随意创建新的 Bean 实例。
如果发现不合理的地方,我会直接在 IDE 里修正,并把修正后的代码作为新的 Context 再次询问 Codex。这种迭代过程,往往比一次性让 AI 写完整个模块要可靠得多。
测试与验证:用自动化构建信任
AI 生成的代码,哪怕看起来再完美,也必须经过测试验证。我们利用 Codex 强大的测试生成能力,为每个新写的 Service 方法自动生成 JUnit 5 + Mockito 的单元测试。
但这只是第一步。真正的难点在于 Mock 数据的合理性。
我们会编写一个 Data Generator 脚本,让 Codex 基于真实的生产日志分布,生成符合正态分布的 Mock 数据。例如,订单金额通常集中在 100-500 元之间,偶尔有大额订单。用这种数据去跑测试,才能发现潜在的精度丢失或溢出问题。
此外,我们引入了混沌工程插件,随机注入网络延迟和数据库超时,观察 AI 生成的容错代码是否能在压力下正常工作。这一步至关重要,因为它模拟了真实线上环境的复杂性。
团队使用建议:建立规范而非禁止
对于技术负责人来说,最大的挑战不是“怎么用”,而是“怎么管”。
1. 代码所有权清晰化:在 Git Blame 中,AI 生成的代码虽然由机器产出,但 Reviewer 和 Author 必须是人。建议在 commit message 中标注 [AI-Assisted],并在 Code Review 中重点检查。
2. 知识库隔离:不同团队有不同的编码规范。我们建立了团队内部的 Codex 配置集,确保生成的代码符合团队风格,而不是通用的“教科书风格”。
3. 定期复盘:每月进行一次“AI 错误案例分享会”。把 Codex 犯过的典型错误(如空指针、逻辑死循环)整理成 CheckList,反哺给团队的 Code Review 规范。
总结:如何在简历里讲好这个故事?
回到最初的问题,如何在简历或面试中阐述这个项目?
不要说:“我使用了 Codex 提高了代码生成速度。” 这句话太苍白。
你要这样说:
> “在订单履约模块重构中,我主导引入了 AI 辅助编程工作流。通过构建结构化的上下文注入机制,将样板代码生成效率提升了 40%。同时,建立了‘AI 生成-静态扫描-混沌测试’的三层质量防线,确保了线上零故障引入。更重要的是,我制定了一套团队内的 AI 代码审查规范,平衡了创新效率与技术债务风险。”
这才是面试官想听到的:你有思考,有流程,有风险意识,并且带来了可量化的结果。
Codex 只是一个工具,真正值钱的是你驾驭工具、控制风险、并将其融入工程体系的能力。希望这篇实战复盘,能帮你理清思路,在下一个项目中玩得转,讲得清。
资料展示
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。
如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。



















 4516
4516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










