



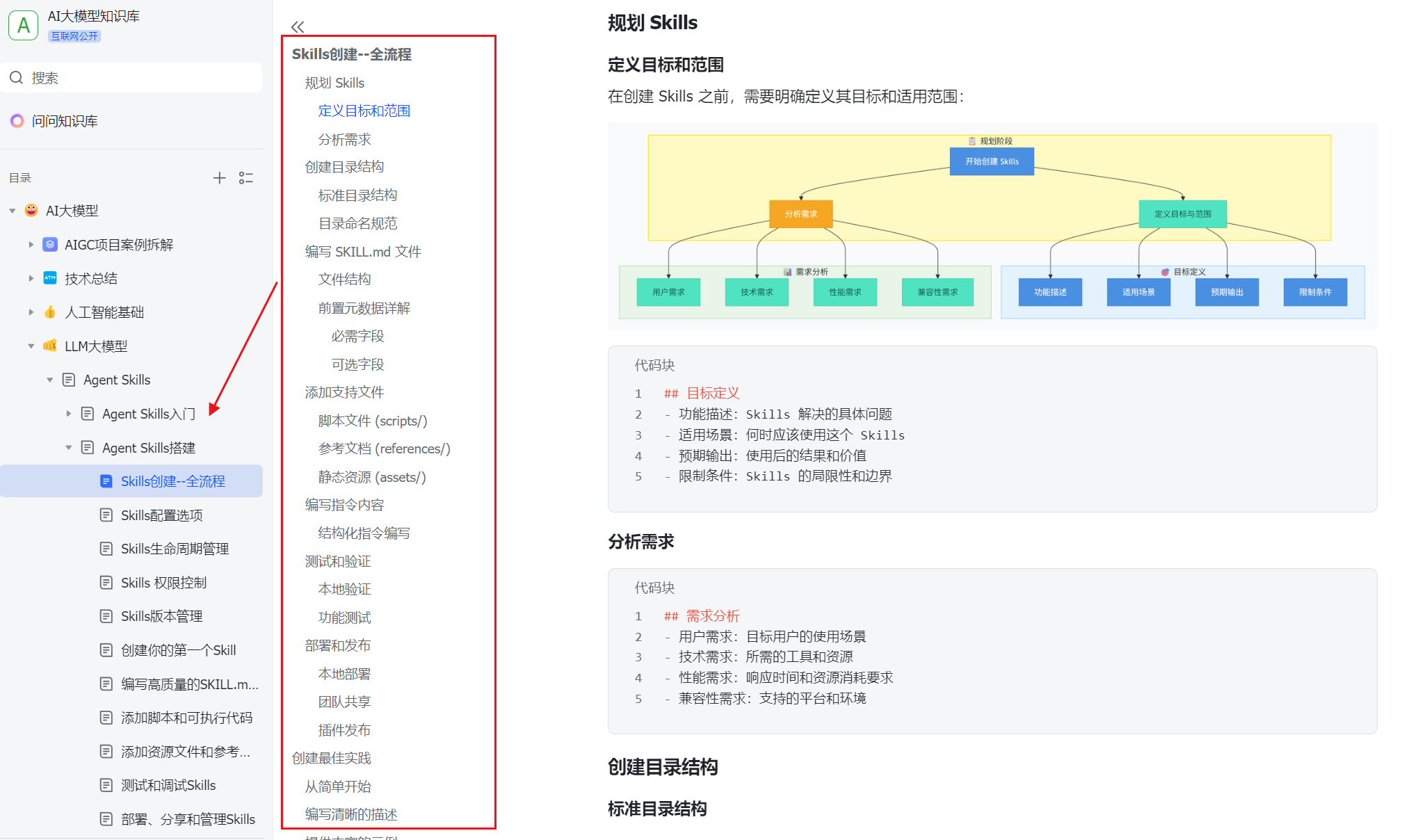
聊《大数据转大模型:用小项目验证核心能力》之前,先说一句实在的:别急着背概念,先看它在真实项目里到底解决什么问题。
摘要
本文概述文章目标、核心观点和实践价值。
去年这时候,我还陷在 Hive SQL 调优和 Spark 数据清洗的循环里,看着大模型风口兴起,心里其实挺慌的。很多人觉得转 AI 就是去学 Python、调参、跑 Transformer,但对于我们这种搞了几年数仓、ETL 的数据工程师来说,这种理解太浅了。
大模型(LLM)并不是凭空产生智慧的魔法,它更像是一个极度依赖高质量语料的“超级阅读者”。而我们的老本行——数据治理、清洗、结构化,恰恰是大模型落地中最脏、最累、也最容易被忽视的环节。
我花了一段时间复盘自己的转型路径,发现真正卡住很多人的不是模型本身,而是数据管道。今天不谈虚的概念,我就结合一个具体的 RAG(检索增强生成)小项目,聊聊数据工程师如何用最熟悉的技能树,撬开 AI 的大门。
目录
- 大数据与大模型的交叉点
- 数据治理:不仅仅是去重
- 向量数据库:换个思路看存储
- RAG 数据管道:用 ETL 的思维重构
- 落地项目:简历里该怎么写?
- 总结
大数据与大模型的交叉点
很多数据工程师有一个误区:认为大模型是算法工程师的事,我只负责把数据喂进去就行。
大错特错。在传统 BI 报表中,如果数据源有个 NULL,我们可以用 COALESCE 填个默认值,报表照样出,业务方可能都看不出来。但在 LLM 的应用中,如果向量检索返回了错误、过时或逻辑冲突的片段,模型会一本正经地胡说八道(幻觉),而且用户根本不知道来源是哪里。
这就是交叉点:确定性 vs 概率性。
传统大数据追求 ACID,追求绝对准确;大模型应用追求召回率、相关性,容忍一定的噪声,但要求上下文窗口内的信息必须高度聚焦且无冲突。作为数据工程师,你的核心价值在于构建一条能够处理非结构化数据、并保证语义一致性的管道。
数据治理:不仅仅是去重
在准备 RAG 数据集时,传统的“去重”完全不够用。
我之前的项目里,直接拿公司 Wiki 和历史文档做向量化,结果模型回答经常前后矛盾,或者引用了一篇已经废止的制度文件。原因很简单:原始文本中充满了冗余、格式混乱、以及版本迭代留下的废弃内容。
这里有个具体的取舍建议:不要试图清洗所有数据,而是清洗“高频访问”数据。
1. 元数据增强:给每一段文本打上标签(时间、部门、状态)。这和你以前打宽表标签是一样的道理。
2. 分段策略(Chunking):这是最关键的技术细节。直接按字符切割是新手常犯的错误。好的分段应该基于语义边界(如句子、段落),并保留重叠窗口(Overlap)。
* 坑点:Overlap 设置太小会导致上下文断裂,太大则浪费 Token 且增加检索噪声。我们通常设置为段落长度的 10%-15%。

向量数据库:换个思路看存储
以前我们用 ClickHouse 或 Doris 做 OLAP 查询,现在向量数据库(如 Milvus, Faiss, 甚至 PGVector)成了新宠。
虽然底层原理不同(余弦相似度 vs 精确匹配),但架构思维是相通的。你需要关注的是索引效率和元数据过滤。
在实际项目中,我强烈建议采用“混合检索”策略。不要只靠向量相似度,要结合关键词(BM25)和元数据过滤。
- 向量:找意思相近的内容。
- 关键词:找精确匹配的术语(如特定的产品型号、合同编号)。
- 元数据:限制时间范围(只看最近一年的文档)或部门权限。
这就像我们在数仓里既要做聚合分析,又要做精细化的权限隔离。向量库只是存储介质,真正的逻辑在于如何组合这些信号来精确定位知识。
RAG 数据管道:用 ETL 的思维重构
这是我最想强调的部分。RAG 的核心不是模型,是 Data Pipeline。
你可以把它看作一个 ETL 过程:
1. Extract:从各类文档(PDF, Word, Markdown)中提取文本。难点在于解析图片中的表格和复杂排版,这里推荐用 Unstructured 或 LangChain 的内置 loaders,但要手动 post-process。
2. Transform:清洗文本、分块、生成 Embedding。
3. Load:写入向量数据库。
下面是一个简单的 Python 代码示例,展示了如何利用 langchain 和 chromadb 构建一个极简的分块与入库流程。注意其中的参数调整,这才是体现工程能力的地方。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
import os
def build_rag_index(texts):
"""
构建 RAG 索引的核心函数
:param texts: 原始文本列表
"""
# 1. 智能分块:递归分割,保留语义完整性
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 根据中文语境适当调整,英文通常 1000+
chunk_overlap=50, # 重叠部分防止语义切断
length_function=len, # 使用字符数而非 token 数做初步估算
add_start_index=True
)
documents = text_splitter.create_documents(texts)
# 2. 嵌入模型选择:本地部署用 BGE-m3 性价比极高
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-m3"
)
# 3. 持久化存储
persist_dir = "./chroma_db"
vectorstore = Chroma.from_documents(
documents,
embedding=embeddings,
persist_directory=persist_dir
)
print(f"Successfully indexed {len(documents)} chunks.")
return vectorstore
# 模拟数据加载
raw_data = ["这是第一段测试文本...", "这是第二段关于向量搜索的原理..."]
db = build_rag_index(raw_data)
这段代码看起来简单,但背后的陷阱很多。比如 chunk_overlap 的大小直接影响检索的连贯性;嵌入模型的选择决定了语义对齐的效果。对于数据工程师来说,调试这些超参数比写 SQL 更考验直觉。
落地项目:简历里该怎么写?
很多兄弟转型失败,是因为简历上还写着“精通 Hive SQL”,却对向量检索一无所知。
我在面试或内推时,看到一个具体的 RAG 系统搭建经历,远比空喊“熟悉 LLM 原理”有用。建议你做一个端到端的小项目,比如“企业内部知识库问答助手”。
项目亮点建议:
1. 对比实验:在文章中展示不同 Chunk Size 对回答准确率的影响。这体现了你的工程量化思维。
2. 脏数据处理:专门写一节讲讲你是如何处理 PDF 扫描件乱码、HTML 标签残留的。这是数据工程师的强项,也是纯算法同学容易忽略的。
3. 评估体系:引入 RAGAS 或简单的人工评估,衡量检索召回率(Recall@K)和生成相关性。
不要只说“我用了 LangChain”,要说“我通过优化文本分块策略和混合检索机制,将幻觉率降低了 X%”。
总结
从大数据转大模型,不是抛弃过去,而是升级武器库。
你不需要成为算法科学家,你只需要成为懂 AI 的数据架构师。大模型时代的本质,依然是数据的流动与价值挖掘。只要你能解决非结构化数据的清洗、索引和高效检索问题,你就已经在 AI 浪潮中站稳了脚跟。
起步不用大,从一个小的、可复现的 RAG 数据管道做起,验证你的核心能力。当你能自信地说“我能保证喂给模型的数据是干净、结构化且可追溯的”时候,你就已经准备好进入这个新时代了。
资料展示
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。
如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。



















 1690
1690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










