



📝 本篇文章主要是讲解并查集以及图的存储结构
🚀 如果阅读完本文后对图的相关算法感兴趣,可查阅博客:【C++】数据结构之图的相关算法-CSDN博客
目录
1 并查集
在说明一些图的基本概念与实现之前,我们先来了解一下并查集这个数据结构,以便于为后面图相关算法的实现提供一些基础知识。
1.1 并查集的基本概念
并查集是描述数据之间集合关系的一种抽象数据结构。在最开始时,所有的元素都各自属于一个单独的集合,然后当满足某种条件时,会按照某种规律将两个单独集合进行合并成一个大集合;在合并过程中会反复使用查询某元素归属于哪个集合的运算。像这样的,用于描述多个元素集合之间关系的数据结构,就是并查集。
例如,有这么一个场景:如果 A 是 B 的好友,B 是 C 的好友,那么 A、B、C 就同属于一个朋友圈,同样的 D、E、F 也是一个朋友圈。如果我们要查出一共有多少个朋友圈我们就可以使用并查集这个数据结构。我们可以将每一个朋友圈看作是一个独立的集合,查看两个人是否同属于一个朋友圈,就是看他们是否同属于一个集合。
1.2 并查集的结构
1.2.1 逻辑结构
处于并查集中的元素,我们一般都会给每个元素一个编号,便于存储,一般是从 0 开始。并查集的逻辑结构其实一个由多棵树构成的森林:
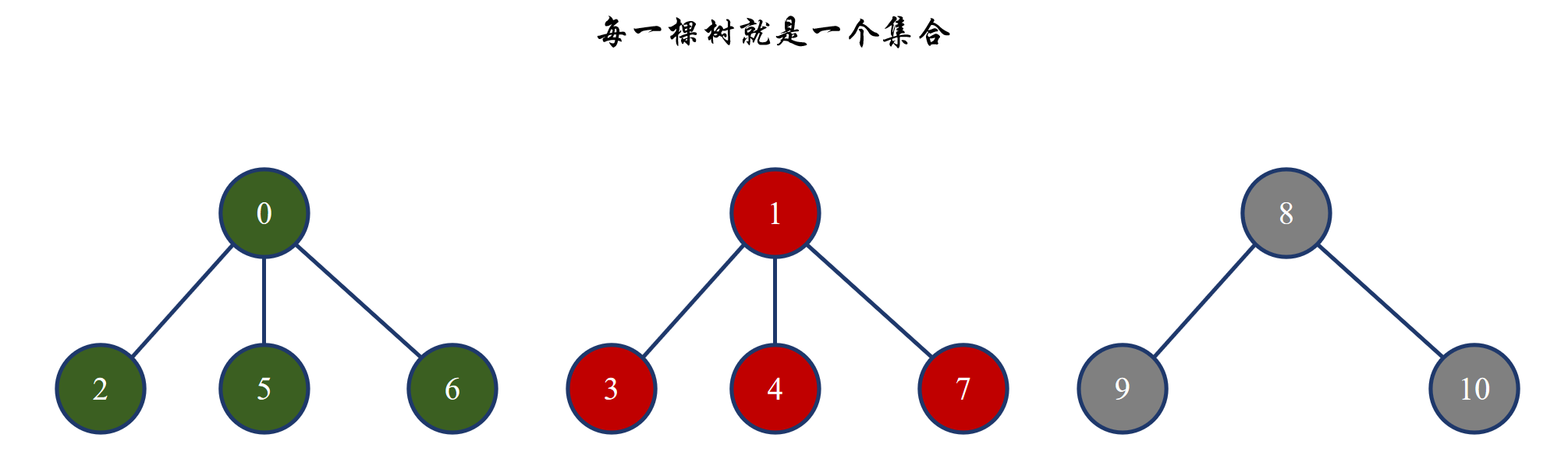
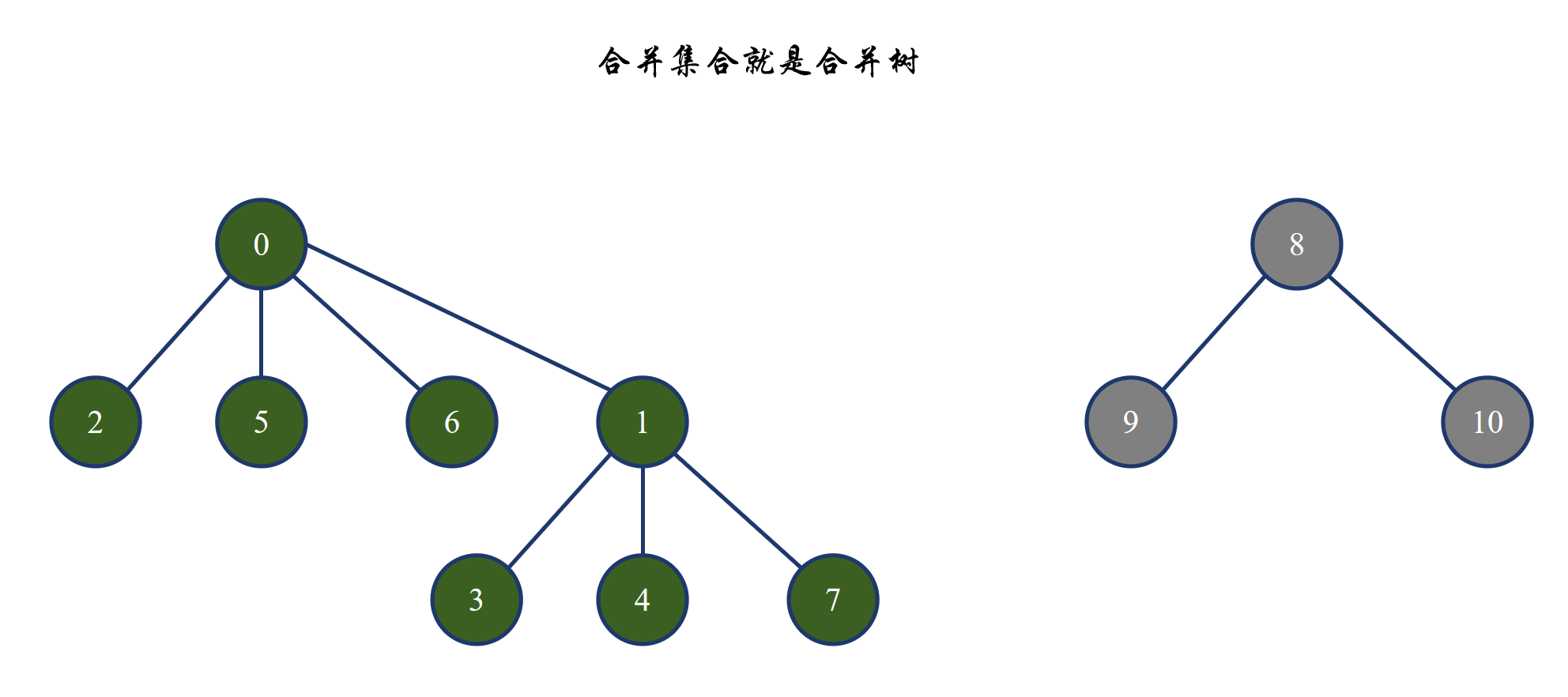
后面进行合并时,其实就是让一棵树的根成为另一棵树的孩子:
1.2.2 物理存储结构
虽然并查集的逻辑结构是一个森林,但是我们在存储并查集时,依然是采用线性结构,比如 vector,这一点跟堆很像,而且在并查集中我们采用的并不是像以前的树一样采用孩子表示法,而是采用双亲表示法。
在并查集中,如果一个元素为整个集合的根节点,那么该元素对应编号位置的数组元素就为 -1,否则该元素对应编号位置的数组元素就表示该元素的根节点编号。根据该设计思想,所以整个并查集的实现步骤为:
(1)利用数组下标对并查集中的每个元素进行编号,一般是按照插入顺序来定;
(2)由于刚开始每个元素都是一个独立的集合,也就是每个元素都是自己集合的根节点,所以最开始数组所有元素都为 -1;
(3)对两个集合 A、B 进行合并时,假设将 B 集合合并到 A,那么就将 B 编号位置的数组元素直接加到 A 编号位置的数组元素上,然后将 B 编号位置的数组元素改为 A 的编号。
按照这个步骤,上面两张图的物理存储结构为:
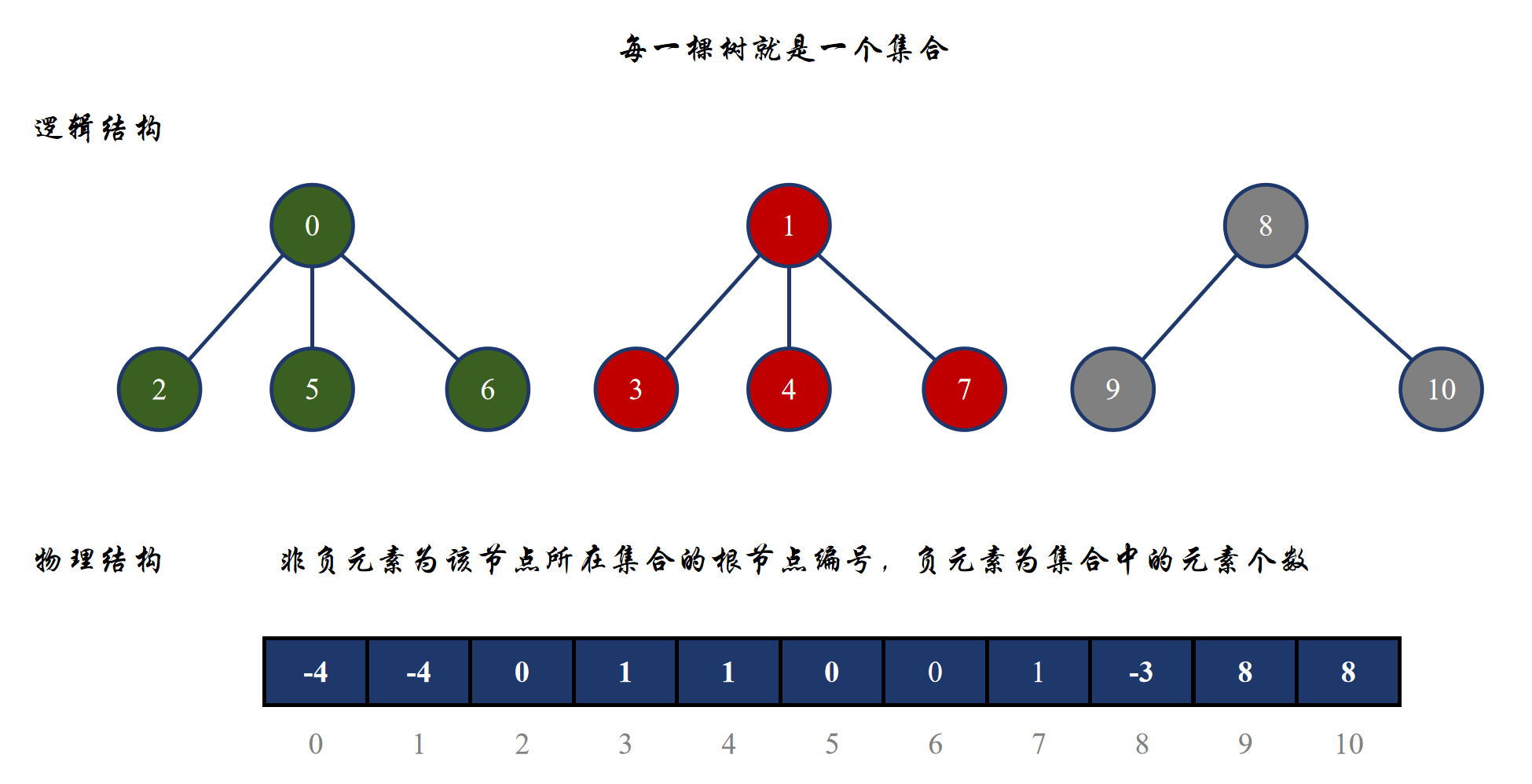
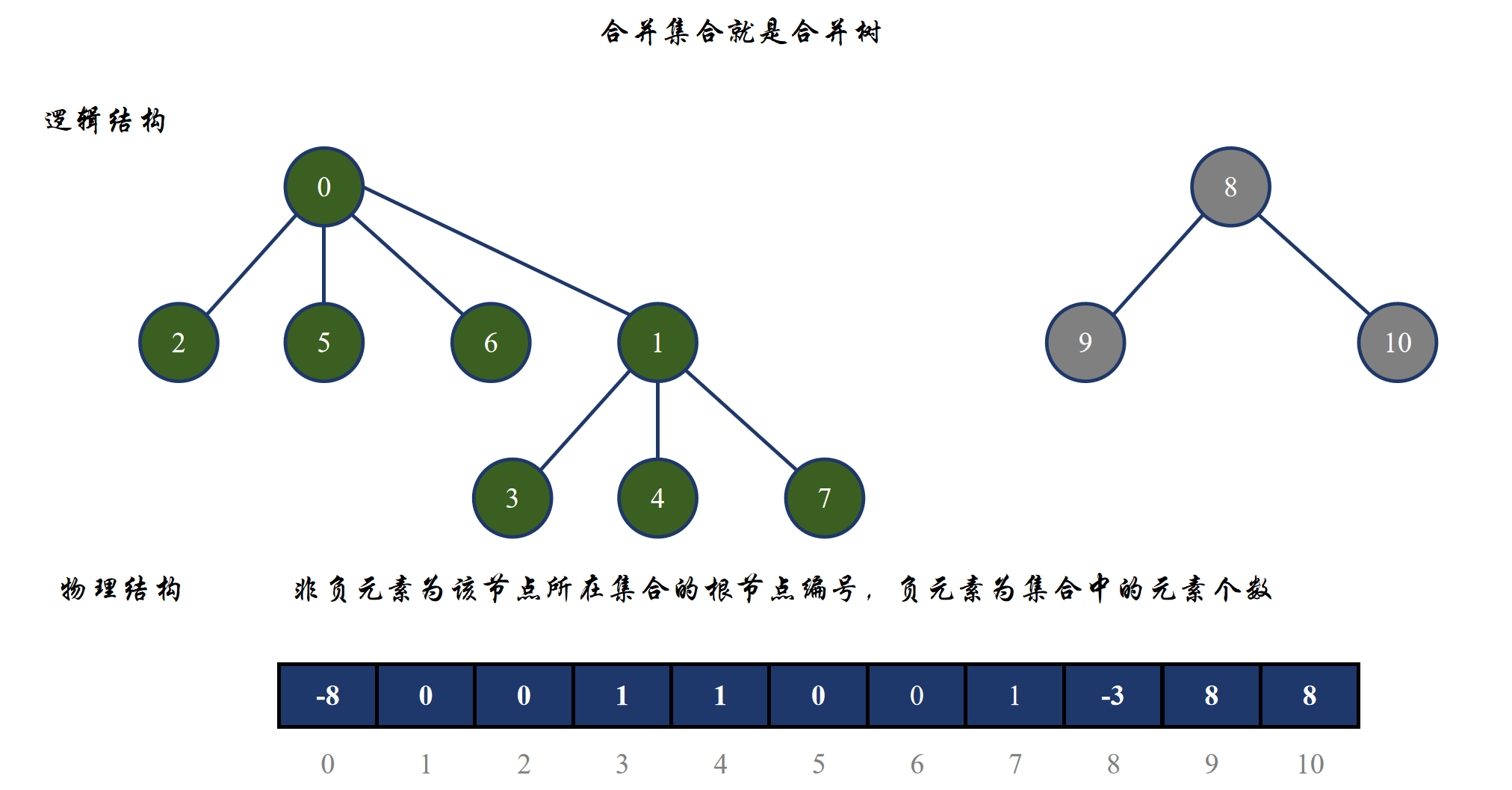
所以为什么刚开始要将所有数组元素设置为 -1 呢?这样就可以直接区分一个集合的根节点与孩子节点了,如果元素为负数,那么该编号节点就是整个集合的根节点,如果是非负元素,那就是该节点的双亲节点;而且根节点数组元素的绝对值就是整个集合的元素个数。
所以根据上面的结构,我们可以得到以下结论:
(1) 查找元素属于哪个集合:沿着祖先一直向上寻找,知道寻找到根。在存储结构中,如果一个下标位置的数组元素非负,那就沿着非负元素向上寻找,知道知道负数位置,那么该负数位置的下标即为该结合的根所在的编号。
(2) 查找两个元素是否位于同一个集合:就是两个元素的根是否是同一个。
(3) 集合的个数:数组中负元素的个数。
(4) 合并集合:假设将 B 合并到 A 集合,找到 A、B 两个所在的根 roota 与 rootb,将 rootb 的数组元素值加到 roota 中,将 rootb 的数组元素值改为 roota。
1.3 并查集的实现
按照上面的物理结构以及得到的结论,我们就可以将并查集类写为(这里我们假设提前利用数组下标对元素进行了编号):
//UnionFindSet.hpp
#pragma once
#include <iostream>
#include <vector>
//实现并查集
class UnionFindSet
{
public:
UnionFindSet(size_t size)
:_ufs(size, -1)
{}
//给出一个元素的编号index,找到其根的编号
int FindRoot(int index)
{
int root = index;
while (_ufs[root] >= 0)
{
root = _ufs[root];
}
//进行路径压缩,将 index 所有双亲的双亲都变为 root
int parent = 0;
if (_ufs[index] >= 0)
{
parent = _ufs[index];
_ufs[index] = root;
index = parent;
}
return root;
}
//合并两个集合
bool Union(int x1, int x2)
{
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
//如果两个在一个集合,那就不用合并了
if (root1 == root2)
return false;
//如果不在一个集合,那就是元素个数少的向元素个数多的合并
if (abs(_ufs[root1]) < abs(_ufs[root2]))
std::swap(root1, root2);
//将 root2 合并到 root1
_ufs[root1] += _ufs[root2];
_ufs[root2] = root1;
return true;
}
//查看集合的个数
size_t SetCount()
{
size_t n = 0;
for (auto& x : _ufs)
{
if (x < 0)
++n;
}
return n;
}
private:
std::vector<int> _ufs;
};
//Main.cc
#include <iostream>
#include "UnionFindSet.hpp"
int main()
{
UnionFindSet ufs(10);
ufs.Union(0, 6);
ufs.Union(0, 7);
ufs.Union(0, 8);
ufs.Union(1, 4);
ufs.Union(4, 9);
ufs.Union(0, 1);
ufs.Union(2, 3);
ufs.Union(2, 5);
std::cout << ufs.SetCount() << std::endl;
return 0;
}在并查集中我们使用了两个优化策略:路径压缩与按秩合并。因为影响并查集查找集合的效率,不在于树的宽度,而在于树的高度(因为查找在哪个集合其实是去查找其所在树的根节点)。
路径压缩
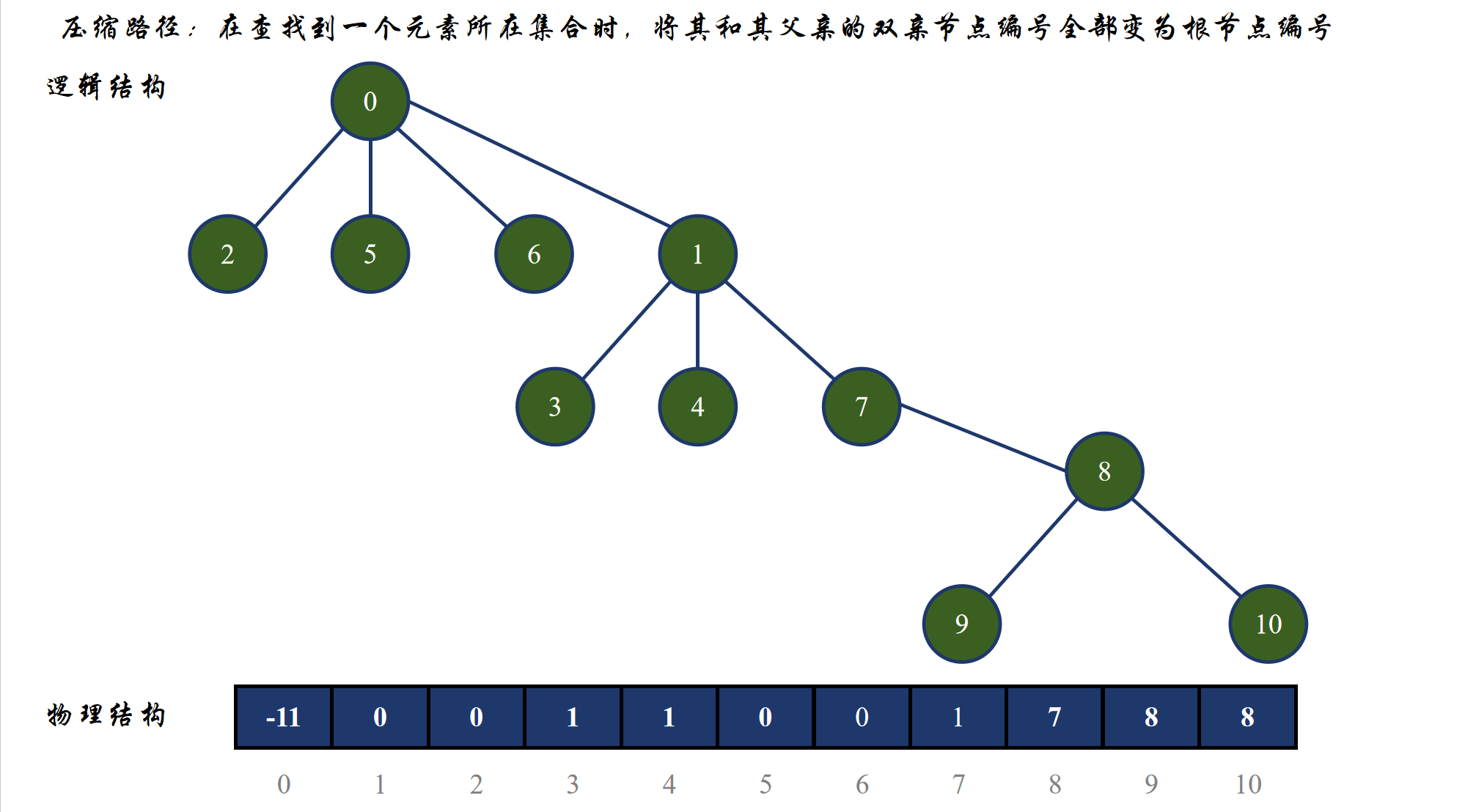
上面这个图就展示我们为什么要进行路径压缩,因为当一棵树,也就是一个集合的层数很深时,查找到根就需要查找很多次。比如上面那张图查找 9,需要跳转 4 次才可以找到根,那么如果当数据特别多时,整棵树的高度变成了百万级别,那么效率就会很低。所以我们需要进行路径压缩来将整棵树压扁(这里以查找上图的 9 编号元素为例):
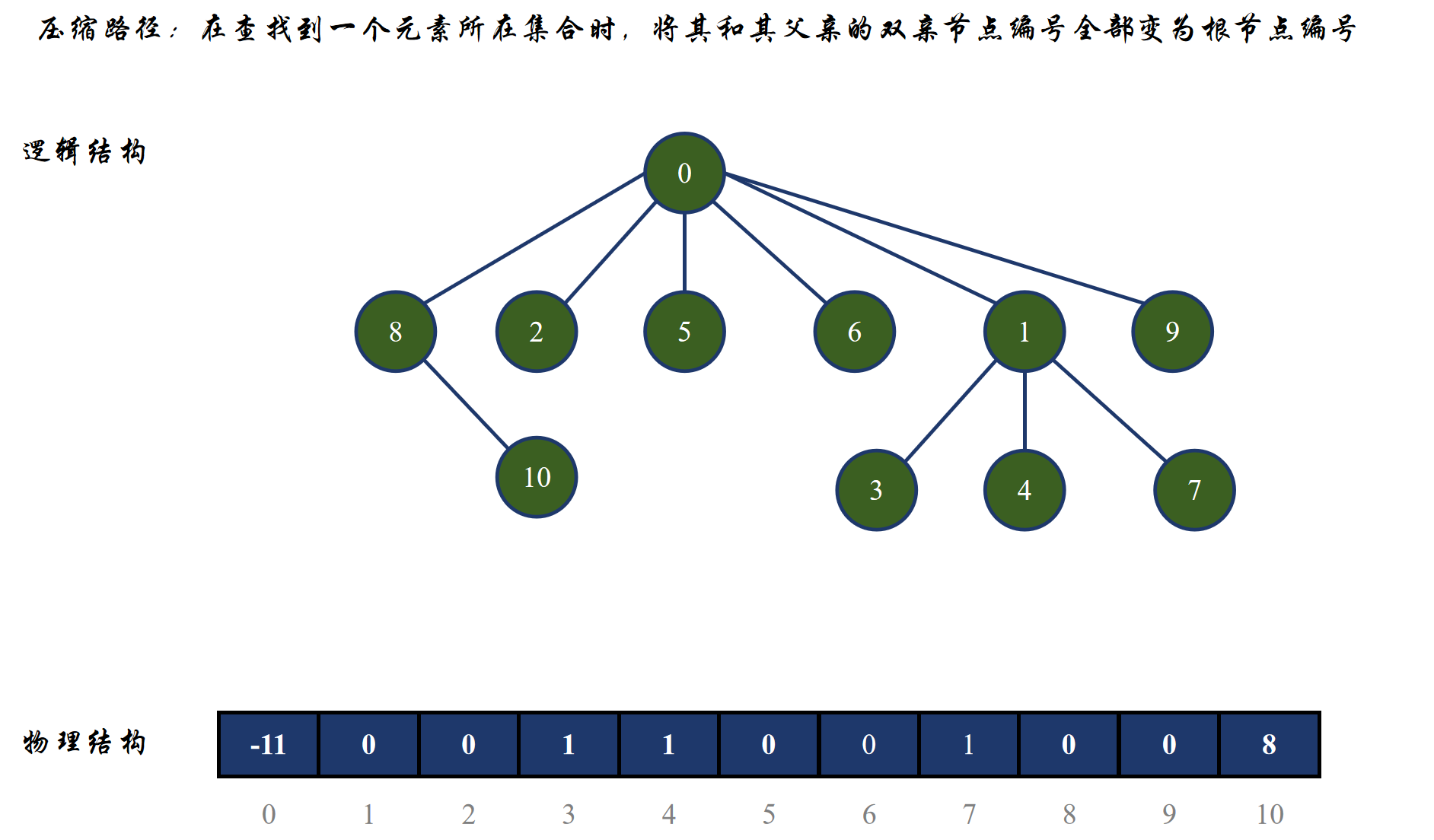
按秩合并
这种情况就更好理解了,合并一次,那么被合并的那个集合的所有元素查找集合时就会多查找一层。将元素少的集合合并到元素多的集合,就保证了元素少集合查找时多一层,而不是元素多集合多一层。
1.4 并查集的应用
了解了并查集,在遇到集合合并或者查找时的问题使用并查集就会轻松很多。
1.4.1 省份数量
leetcode 链接:547. 省份数量 - 力扣(LeetCode)
题目描述
有
n个城市,其中一些彼此相连,另一些没有相连。如果城市a与城市b直接相连,且城市b与城市c直接相连,那么城市a与城市c间接相连。省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个
n x n的矩阵isConnected,其中isConnected[i][j] = 1表示第i个城市和第j个城市直接相连,而isConnected[i][j] = 0表示二者不直接相连。返回矩阵中 省份 的数量。
示例 1:
输入:isConnected = [[1,1,0],[1,1,0],[0,0,1]] 输出:2示例 2:
输入:isConnected = [[1,0,0],[0,1,0],[0,0,1]] 输出:3提示:
1 <= n <= 200n == isConnected.lengthn == isConnected[i].lengthisConnected[i][j]为1或0isConnected[i][i] == 1isConnected[i][j] == isConnected[j][i]
题目解析
该题目会给你一个 n * n 的矩阵,也就是 vector<vector<int>>,一个位置 (i, j) 如果为1,代表 i, j 两个城市直接相连,此时如果 j 再与 k 直接相连,那么 i, k 是属于间接相连,但是不管直接还是间接相连,他们都是相连的城市,只要城市之间是相连的,那么他们就属于同一个省份。该问题让你返回对应省份的数量。
算法解析
该题目就很适合使用并查集数据结构实现。我们可以将每一个省份看作是一个独立的集合,如果 isConnected[i][j] == 1,那么我们就将 i, j 加入同一个集合,最终集合的数量就是省份的数量。
代码实现
借助并查集数据结构实现
class UnionFindSet
{
public:
UnionFindSet(size_t size)
:_ufs(size, -1)
{}
//给出一个元素的编号index,找到其根的编号
int FindRoot(int index)
{
int root = index;
while (_ufs[root] >= 0)
{
root = _ufs[root];
}
//进行路径压缩,将 index 所有双亲的双亲都变为 root
int parent = 0;
if (_ufs[index] >= 0)
{
parent = _ufs[index];
_ufs[index] = root;
index = parent;
}
return root;
}
//合并两个集合
bool Union(int x1, int x2)
{
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
//如果两个在一个集合,那就不用合并了
if (root1 == root2)
return false;
//如果不在一个集合,那就是元素个数少的向元素个数多的合并
if (abs(_ufs[root1]) < abs(_ufs[root2]))
std::swap(root1, root2);
//将 root2 合并到 root1
_ufs[root1] += _ufs[root2];
_ufs[root2] = root1;
return true;
}
//查看集合的个数
size_t SetCount()
{
size_t n = 0;
for (auto& x : _ufs)
{
if (x < 0)
++n;
}
return n;
}
private:
std::vector<int> _ufs;
};
class Solution
{
public:
int findCircleNum(vector<vector<int>>& isConnected)
{
int n = isConnected.size();
UnionFindSet ufs(n);
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
//如果他们直接相连就加入同一个集合
if (isConnected[i][j] == 1)
{
ufs.Union(i, j);
}
}
}
return ufs.SetCount();
}
};使用并查集思想实现
其实我们没必要真的实现一个并查集数据结构,可以使用并查集的思想,创建 n 个初始值为 -1 的 vector,然后写一个 FindRoot 的 lambda 匿名函数就可以实现这个问题了。
class Solution
{
public:
int findCircleNum(vector<vector<int>>& isConnected)
{
int n = isConnected.size();
vector<int> ufs(n, -1);
auto FindRoot = [&ufs](int index)->int{
int root = index;
while (ufs[root] >= 0)
{
root = ufs[root];
}
return root;
};
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
//如果他们直接相连就加入同一个集合
if (isConnected[i][j] == 1)
{
int root1 = FindRoot(i);
int root2 = FindRoot(j);
if (root1 != root2)
{
//i, j 不在同一个集合, 合并集合
ufs[root1] += ufs[root2];
ufs[root2] = root1;
}
}
}
}
int count = 0;
for (auto x : ufs)
{
if (x < 0) ++count;
}
return count;
}
};1.4.2 等式方程的可满足性
leetcode 链接:990. 等式方程的可满足性 - 力扣(LeetCode)
题目描述
给定一个由表示变量之间关系的字符串方程组成的数组,每个字符串方程
equations[i]的长度为4,并采用两种不同的形式之一:"a==b"或"a!=b"。在这里,a 和 b 是小写字母(不一定不同),表示单字母变量名。只有当可以将整数分配给变量名,以便满足所有给定的方程时才返回
true,否则返回false。
示例 1:
输入:["a==b","b!=a"] 输出:false 解释:如果我们指定,a = 1 且 b = 1,那么可以满足第一个方程,但无法满足第二个方程。没有办法分配变量同时满足这两个方程。示例 2:
输入:["b==a","a==b"] 输出:true 解释:我们可以指定 a = 1 且 b = 1 以满足满足这两个方程。示例 3:
输入:["a==b","b==c","a==c"] 输出:true示例 4:
输入:["a==b","b!=c","c==a"] 输出:false示例 5:
输入:["c==c","b==d","x!=z"] 输出:true提示:
1 <= equations.length <= 500equations[i].length == 4equations[i][0]和equations[i][3]是小写字母equations[i][1]要么是'=',要么是'!'equations[i][2]是'='
题目解析
这道题目就是给你几个 == 或者 != 的表达式,判断是否有相悖的表达式,如果有就返回 false,没有就返回 true。比如 ["a==b", "b==c", "c!=a", "x!=z"],因为 a == b,b==c,所以应该 a==c,但是 c!=a,与 c==a 相悖,所以应该返回 false。注意 x!=z 是正确的,因为前面并没有 x==z。
算法解析
因为 == 具有可传递性,也就是如果 a==b,b==c,那么 a==c。所有我们可以利用这一特性,将所有相等的元素看作是一个集合,如果后面遇到 !=,而且左右两边的字母同属于 == 这个集合,我们就可以说是相悖的。
所以我们需要先遍历一遍 equations,将所有 == 两边的字母加入同一个集合,再遍历一遍 equations,查找 != 两边的字母,如果在同一个集合,那就返回 false。需要注意的一点是,我们必须要遍历两次,第一次必须将所有 == 两边的字母加入集合,不能边加入集合边判断 != 两边的字母是否在同一个集合,因为可能出现这种情况:["a!=b", "a==b", "b==c"],这样也属于相悖的表达式,但是我们一边加入集合一边检查是检查不出来的。
代码实现
class Solution
{
public:
bool equationsPossible(vector<string>& equations)
{
//将 == 看作是在一个集合中,如果 != 的两个在同一个集合, 那就说明是相悖的
vector<int> ufs(26, -1);
auto FindRoot = [&ufs](int index){
int root = index;
while (ufs[root] >= 0)
{
root = ufs[root];
}
return root;
};
//1. 先要将所有的 == 的加入同一集合
for (auto& str : equations)
{
int root1 = FindRoot(str[0] - 'a');
int root2 = FindRoot(str[3] - 'a');
if (str[1] == '=')
{
//加入同一集合
if (root1 != root2)
{
ufs[root1] += ufs[root2];
ufs[root2] = root1;
}
}
}
//2. 再判断不相等的是否在同一集合,如果在,返回 false
for (auto& str : equations)
{
int root1 = FindRoot(str[0] - 'a');
int root2 = FindRoot(str[3] - 'a');
if (str[1] == '!')
{
if (root1 == root2)
return false;
}
}
return true;
}
};2 图的基本概念
2.1 图的相关名词
- 图:图是由顶点集合以及顶点之间的关系,也就是边所组成的一种数据结构。其中,顶点集合通常写为 V={x|x ∈ 某个数据对象集},V 是顶点 Vertex 的简写;边的集合通常写为 E = {<x, y> | x, y ∈ V},E 是边 Edge 的简写。所以图经常写为 G = (V, E),G 是图 Graph 的简写。在图的每个边上可能
- 顶点和边:图中的各个节点称为顶点,顶点与顶点之间相连的通路成为边。如下图的圆形就是各个顶点,顶点与顶点之间的直线就是边。从下图可以看到,二叉树其实就是一种简单的图,只不过二叉树没有回路。
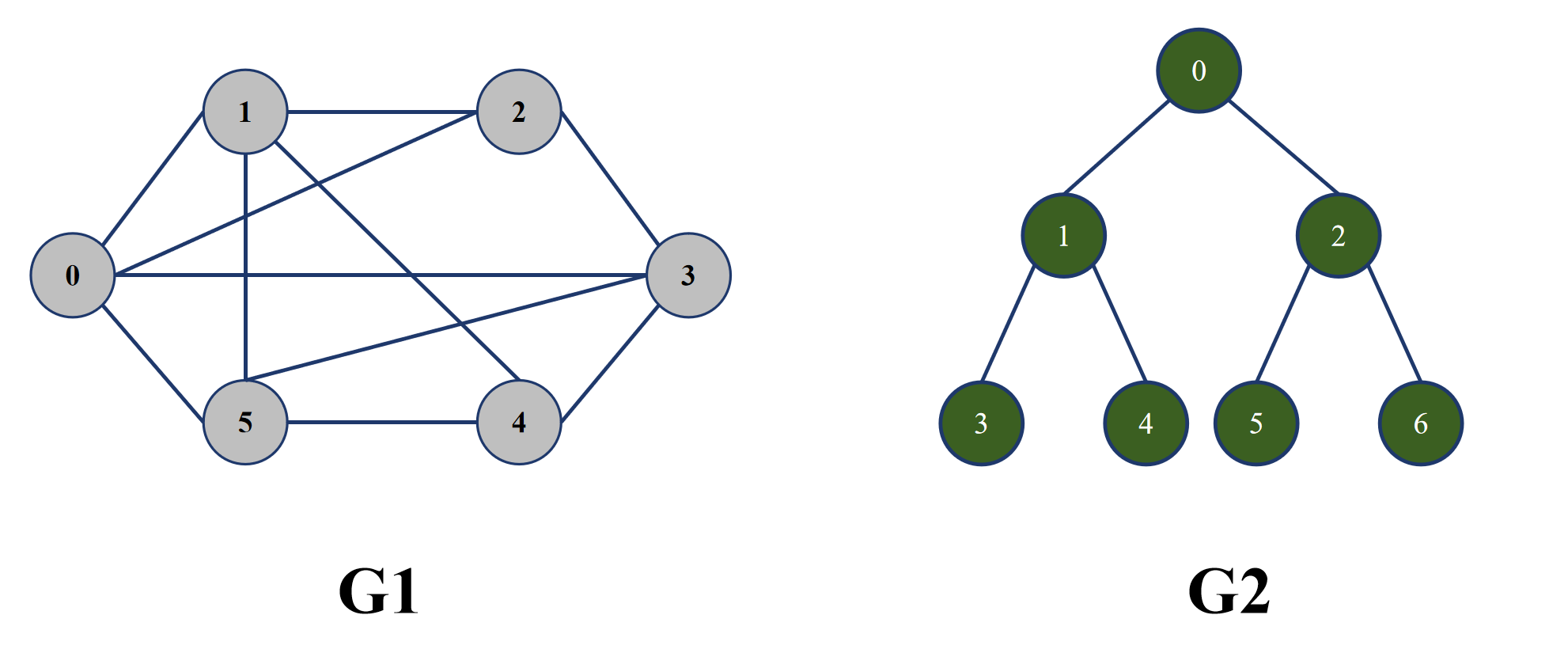
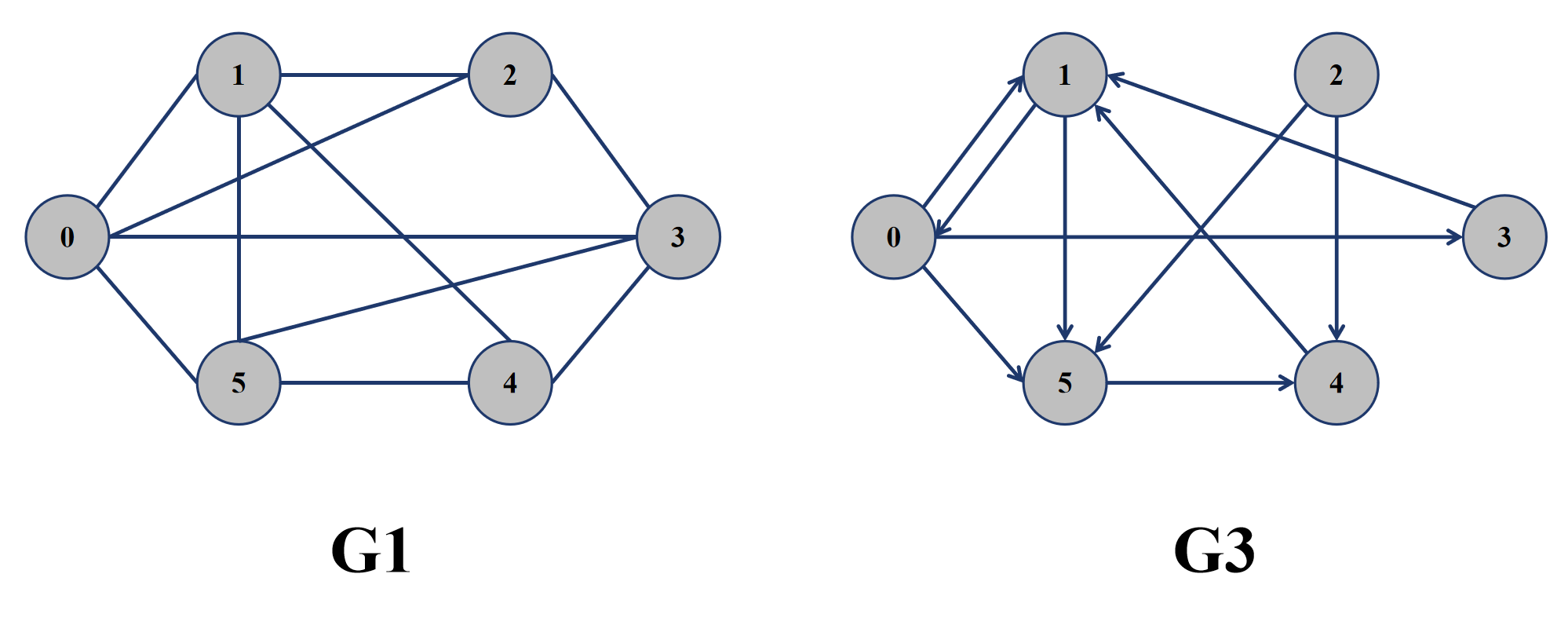
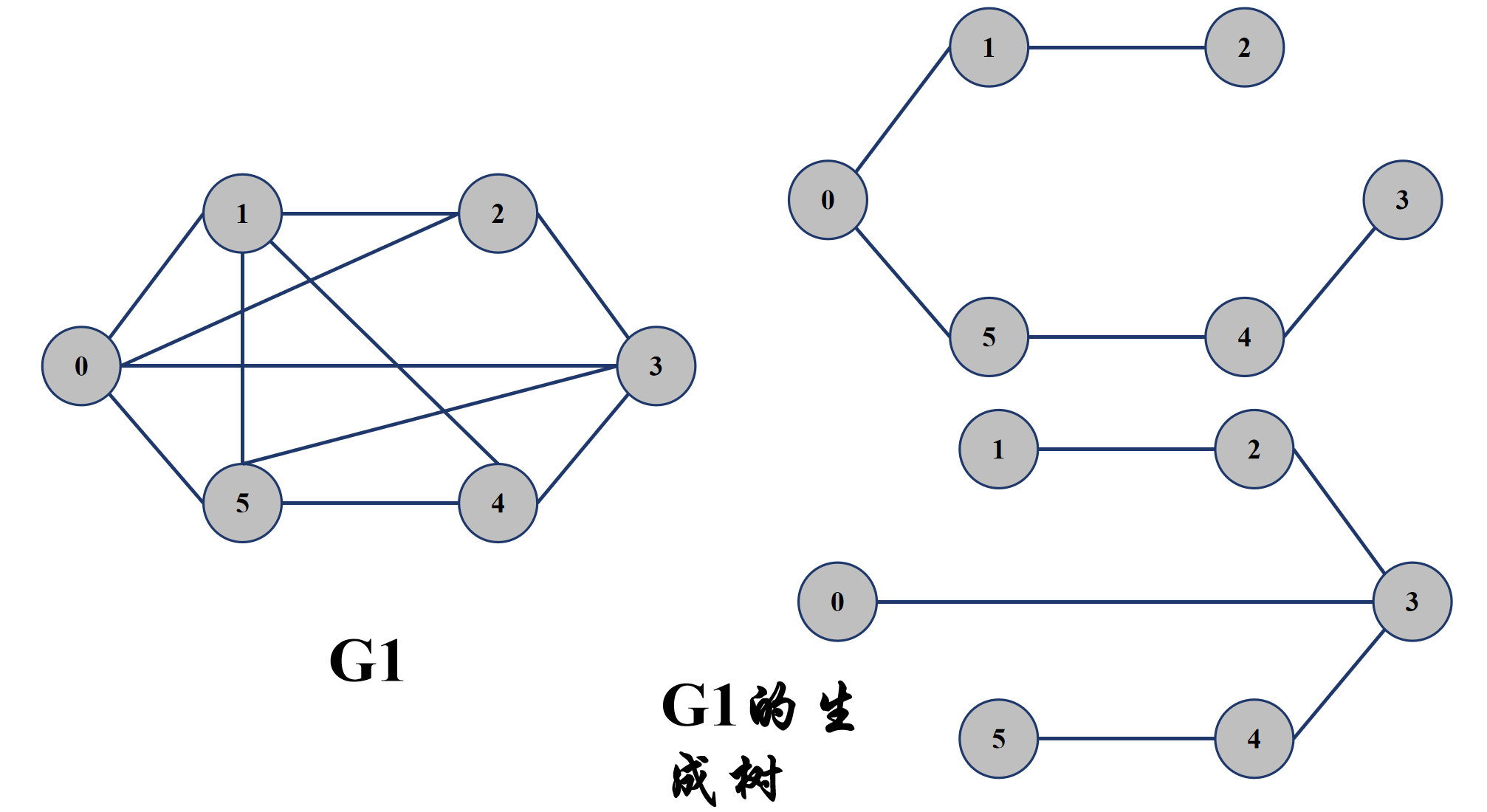
- 无向图与有向图:无向图是指顶点与顶点之间的顶点对,也就是一条边 (x, y) 没有顺序,即 (x, y) = (y, x);有向图是指顶点与顶点之间的顶点对,也就是一条边是有顺序的,比如 <x, y> 表示从 x 顶点到 y 顶点的一条边,而 <y, x> 表示从 y 顶点到 x 顶点的一条边,<x ,y> != <y, x>,一个顶点对 (x, y) 为 <x, y> 和 <y, x>。比如下图中,G1 就为无向图,G3 为有向图。
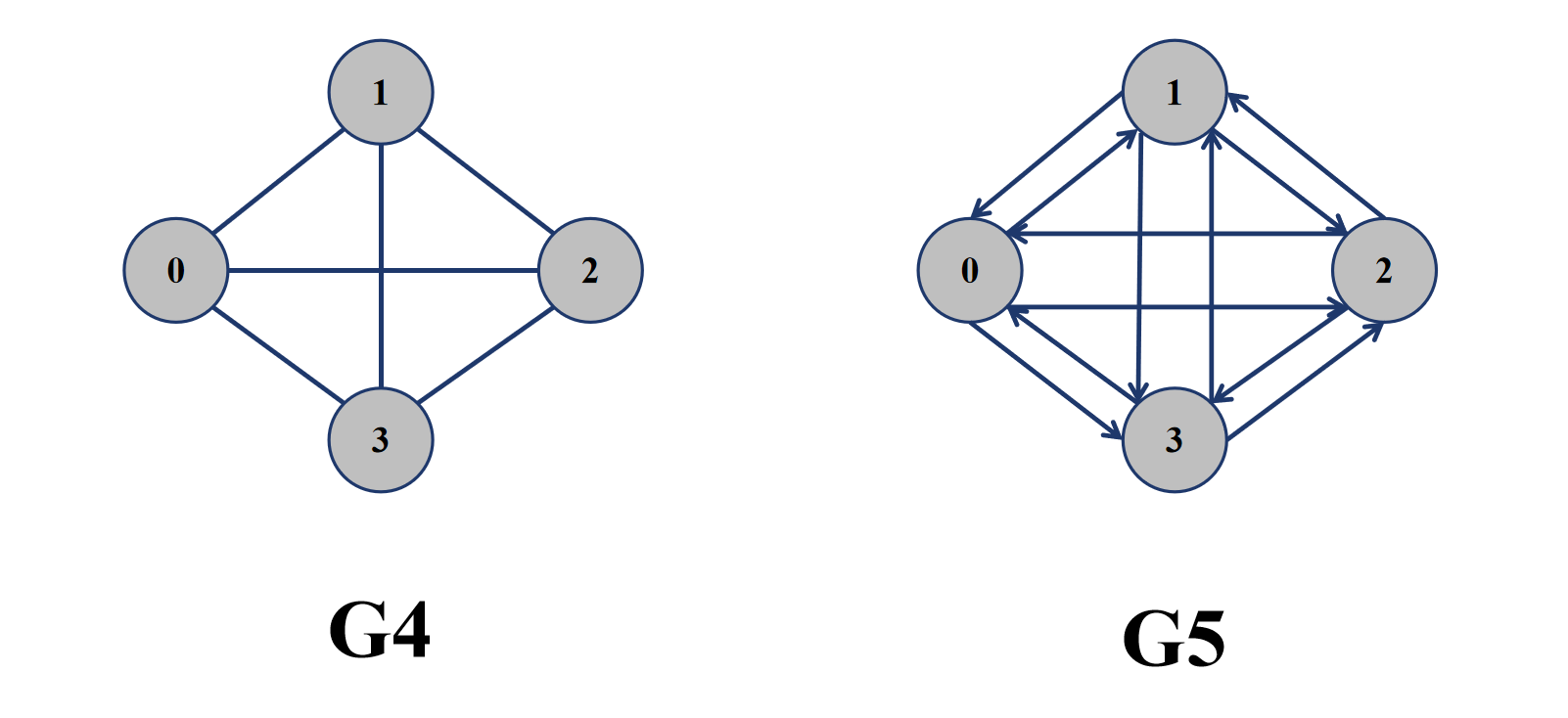
- 完全图:完全图分为完全无向图与完全有向图。在 n 个顶点完全无向图中,共有 [n * (n - 1)] / 2 条边,即任意两个顶点之间有且仅有一条边,第一个顶点与其余顶点之间各有一条边,所以是 n - 1 条边,第二个顶点除去与第一个顶点之间的那条边,与其余顶点之间各有一条边,所以是 n - 2 条边,以此类推,最终边的条数是一个等差数列求和,即∑(n + n - 1 + ... + 1) = [n * (n -1)] / 2;在 n 个顶点的完全有向图中,共有 n * (n-1) 条边,即任意两个顶点之间都有两条方向相反的边,任意一个顶点与其余顶点之间都有一条边,所以每个顶点指向出去的边都有 n - 1 条,所以是 n * (n - 1) 条边。
- 邻接顶点:在无向图中,如果两个顶点 x, y 之间有一条边 (x, y),那么就称 x, y 这两个顶点互为邻接顶点,称这条边 (x, y) 依附于顶点 x 和 y;在有向图中,如果 u, v 两个顶点之间有一条边 <u, v>,那么就称 u 邻接到 v,顶点 v 邻接自 u,边 <u, v> 与顶点 u,v 相关联。
- 顶点的度:顶点的度是指与顶点相连的边的条数,记为 deg(v)。在无向图中,顶点的度就是与其相连的边的条数,比如在完全无向图中,每个顶点的度都是 n - 1;在完全有向图中,顶点的度分为入度和出度。入度为以该顶点为终点的有向边,记为 indeg(v),出度为以该顶点为起点的边,记为 outdeg(v),有向图顶点的度就是入度与出度的和,即 deg(v) = indeg(v) + outdeg(v)。比如在完全有向图中,任意一个顶点的度都是 2 * (n - 1),入度为 (n - 1),出度为 (n - 1)。注意,在无向图中,顶点的度等于入度等于出度,即 deg(v) = indeg(v) + outdeg(v)。
- 路径:在图 G 中,若有从一组从顶点 Vi 出发到顶点 Vj 的边,那么就称从顶点 Vi 到 Vj 的顶点序列为 Vi 到 Vj 的路径。比如在图 G3 中,从顶点 0 到顶点 1 有三条路径,分别是 0 -> 1,0 -> 5 -> 4 ->1,0 -> 3 -> 1。
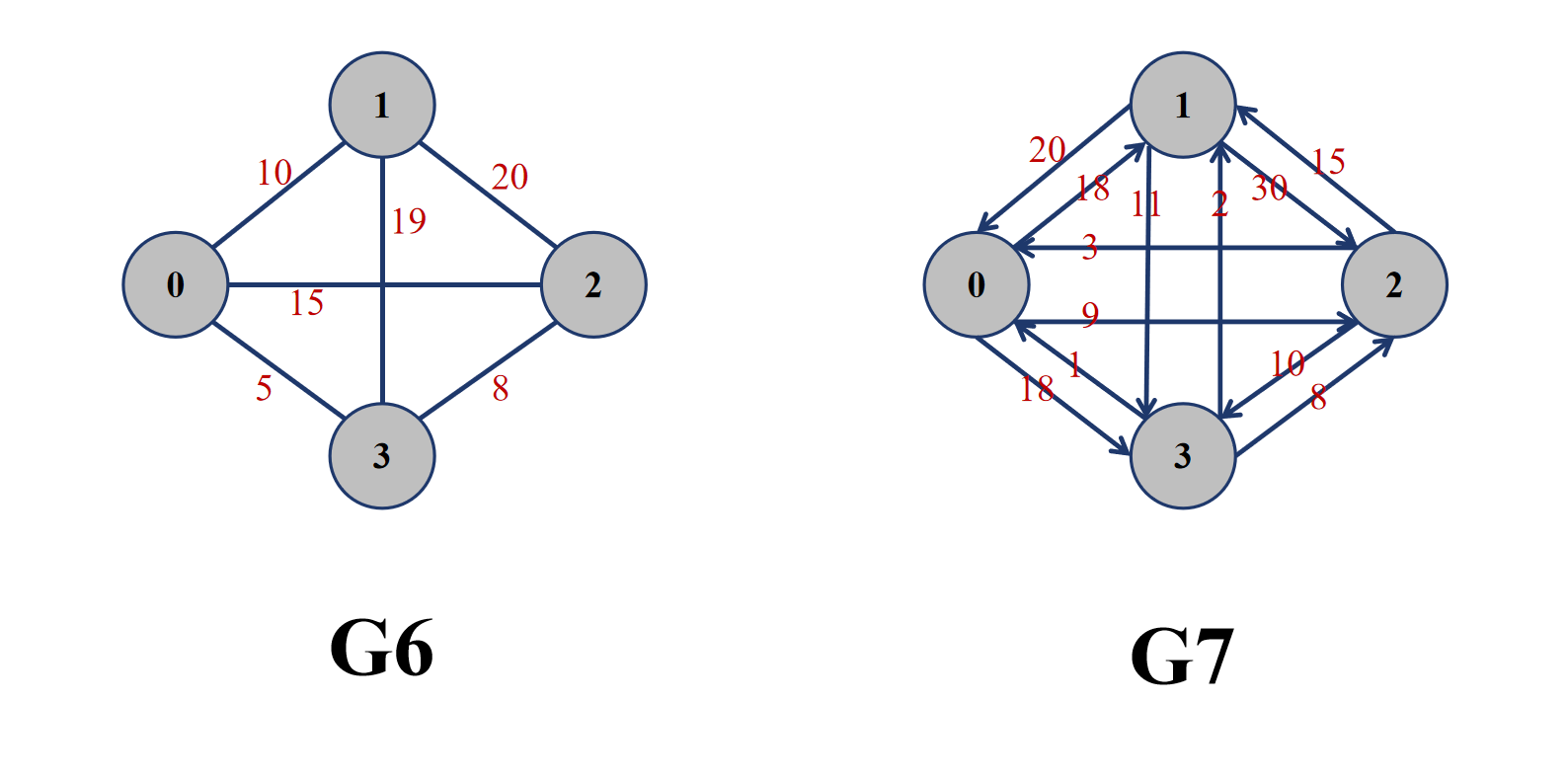
- 带权图与无权图:对于有向图或者无向图,如果边上具有一定的权值,那么就成为带权图,否则就称为无权图。对于无向带权图,边的权值是相同的;对于有向带权图,边 <x, y> 与 <y, x> 权值是可以不同的。
- 稠密图与稀疏图:稠密图与稀疏图是按照边的条数来分的。不管是无向图还是有向图,边数最多的图就是完全图,无向图最多是 [n * (n - 1)] / 2 条边,近似于 n^2 / 2,有向图最多是 n * (n - 1) 条边,近似于 n^2。所以当一个无向图的边数大致近似于 n^2/2 或者有向图的边数大致近似于 n^2 时,就成为稠密图,当边数远远小于最大边数时,就称为稀疏图。
- 路径长度:对于无权图,路径长度就是一条路径中边的长度;对于带权图,路径长度是一条路径中权值的和。
- 简单路径与回路:对于一条路径,如果路径上的顶点 V1、V2、V3 ... Vm 都不重复,称该路径为简单路径;如果一条路径的起点 V1 与终点 Vm 相同,那么该路径为回路。
- 子图:对于图 G = (V, E),如果 G1 = (V1, E1),其中 V1 是 V 的子集,E1 是 E 的子集,那么就称 G1 是 G 的子图。
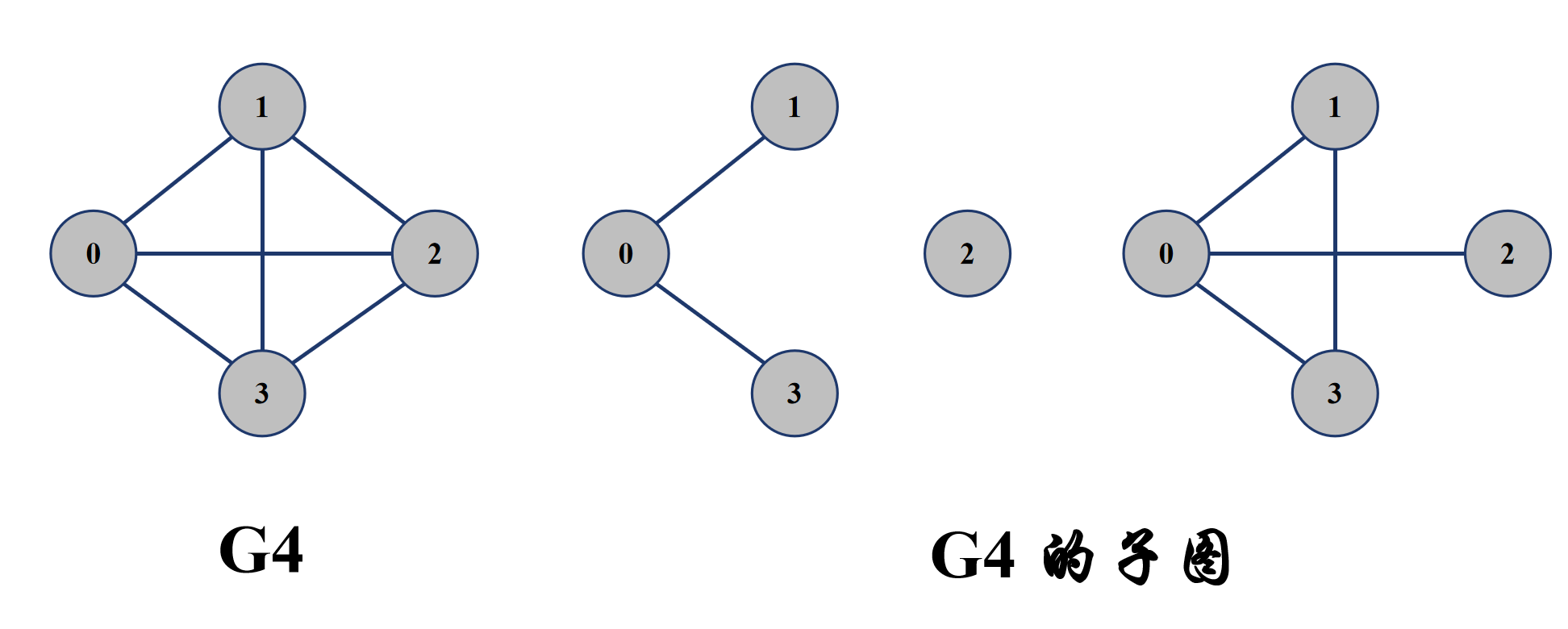
- 连通图:在无向图中,如果一对顶点 u,v 之间存在路径,那么就称 u,v 是连通的。如果对于任意一对顶点 u,v,都存在一条路径,即 u,v 是连通的,那么就称该无向图为连通图。
- 强连通图:在有向图中,对于任意一对顶点 u,v,如果存在从 u 到 v 的路径,也存在从 v 到 u 的路径,那么就称该有向图为强连通图。
- 生成树:一个连通图的最小连通子图称为该图的生成树。其中最小连通子图是指所需的边最少,所以对于 n 个顶点的连通图,其生成树的边数始终是 n - 1。
2.2 图的存储结构
图是顶点和边的集合,所以图的存储只需要存储顶点和边即可。顶点比较好存,但是边是顶点与顶点之间的关系,该如何存储呢?有两种存储的方法,一个是邻接矩阵,一个是邻接表。
2.2.1 邻接矩阵
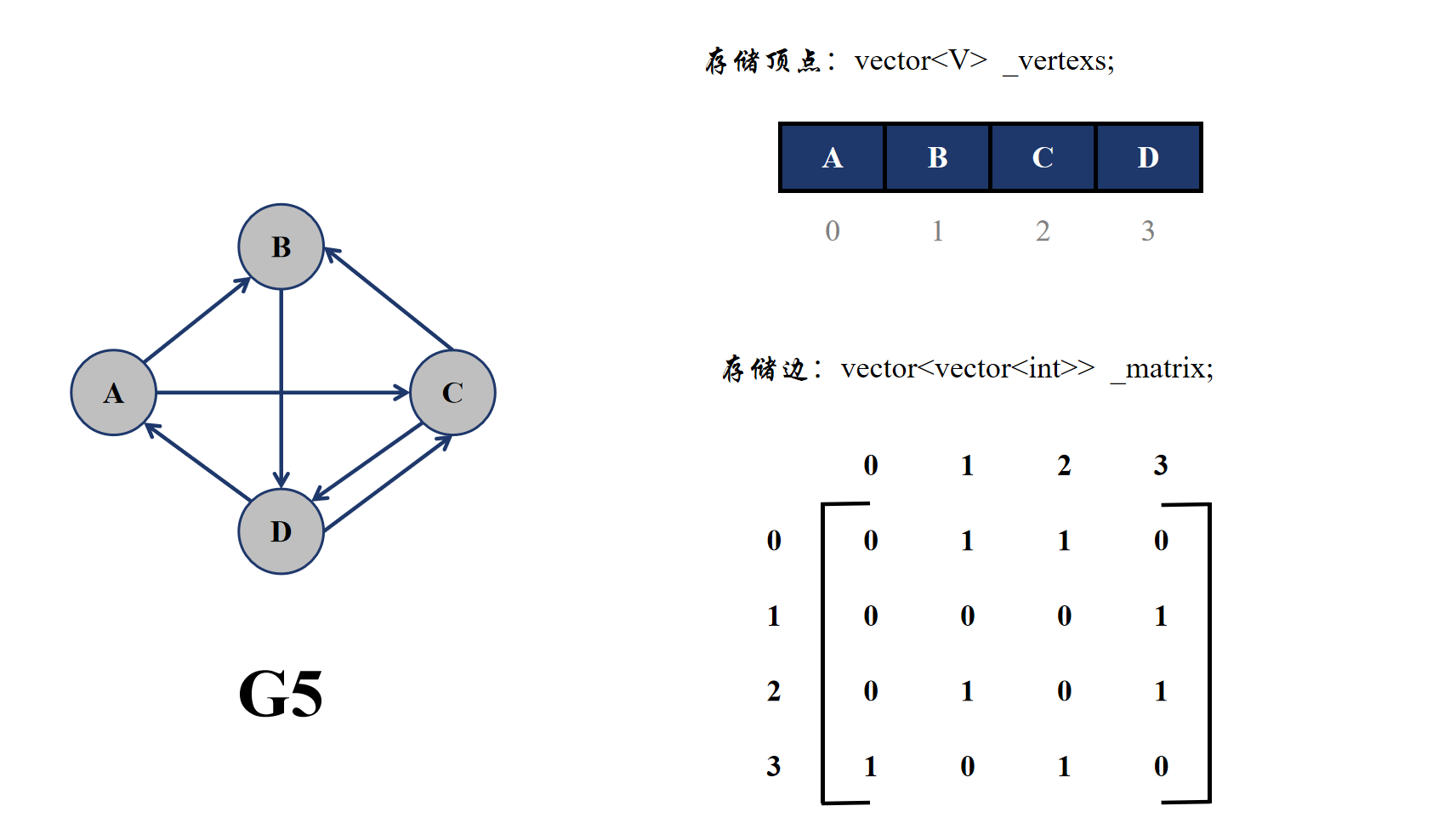
邻接矩阵的思想就是用一个矩阵来保存顶点与顶点之间的关系,即是否相连,也就是保存两个顶点之间是否有边。在无向图中,由于边没有方向,所以如果 u,v 两个顶点之间有边,那么 v,u 两个顶点之间也会有相同的边,所以无向图的邻接矩阵其实是一个对称矩阵,而有向图的边是有方向的,所以矩阵并不是一个对称矩阵。
在无权图中,一般使用 1 来代表两个顶点之间有边,用 0 代表两个顶点之间没边;在带权图中,如果权值为♾️(无穷大),一般代表的是没有边,其余值为两个顶点有边,而且数字为边的权值。
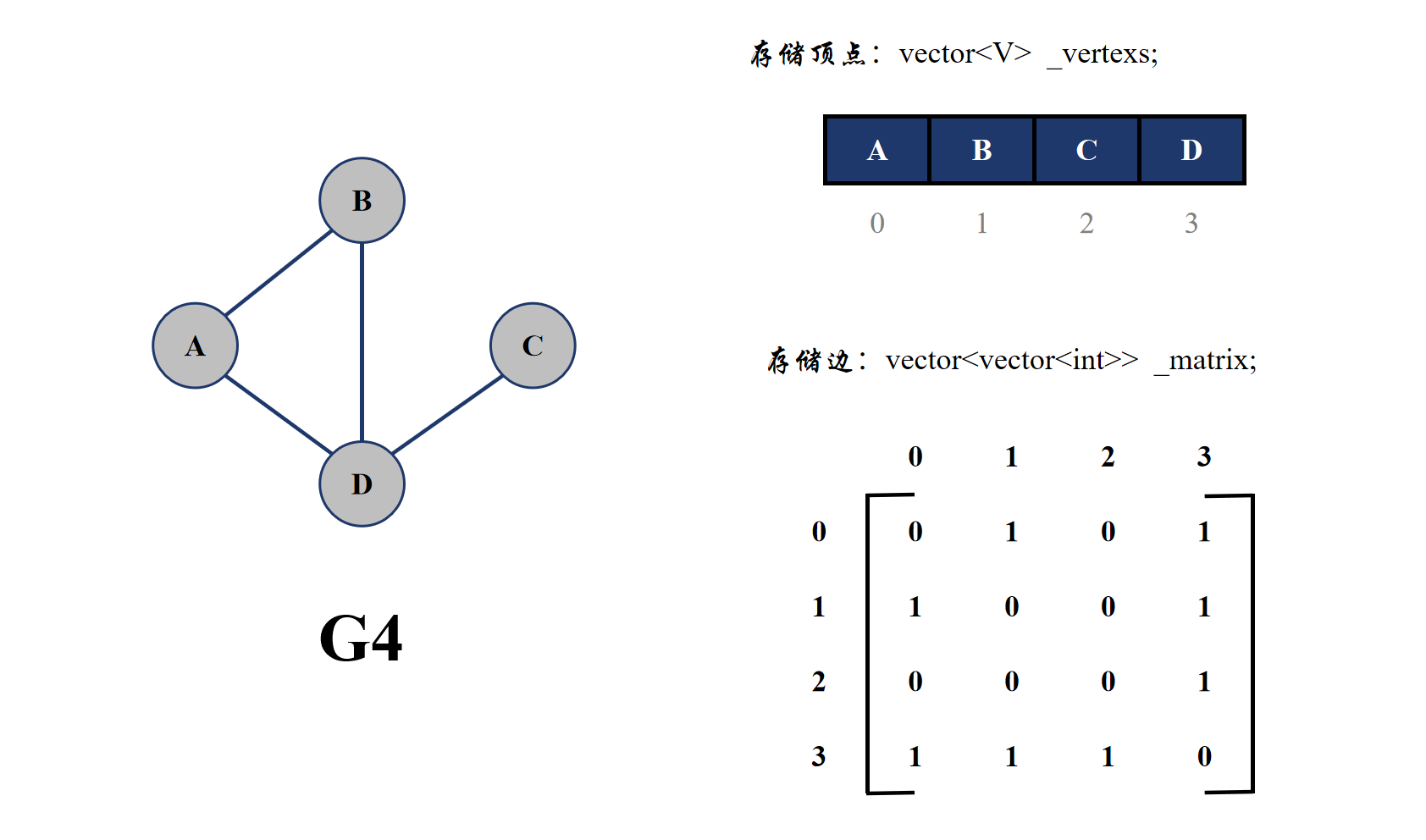
邻接矩阵的物理存储其实就是一个二维数组,一般用 vector<vector<int>> 来表示,而且会用下标来代表某个顶点的编号。
无权图
带权图
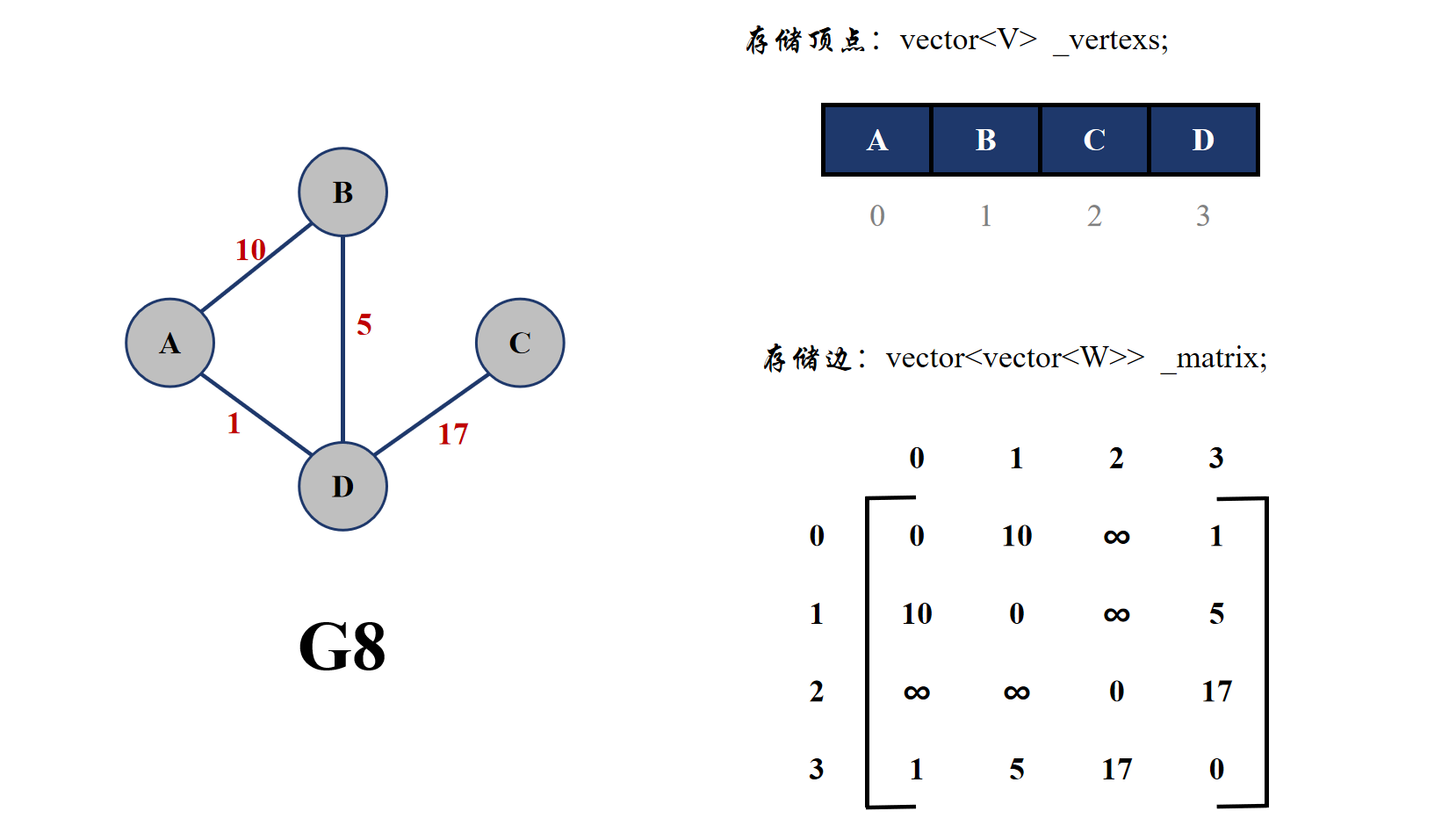
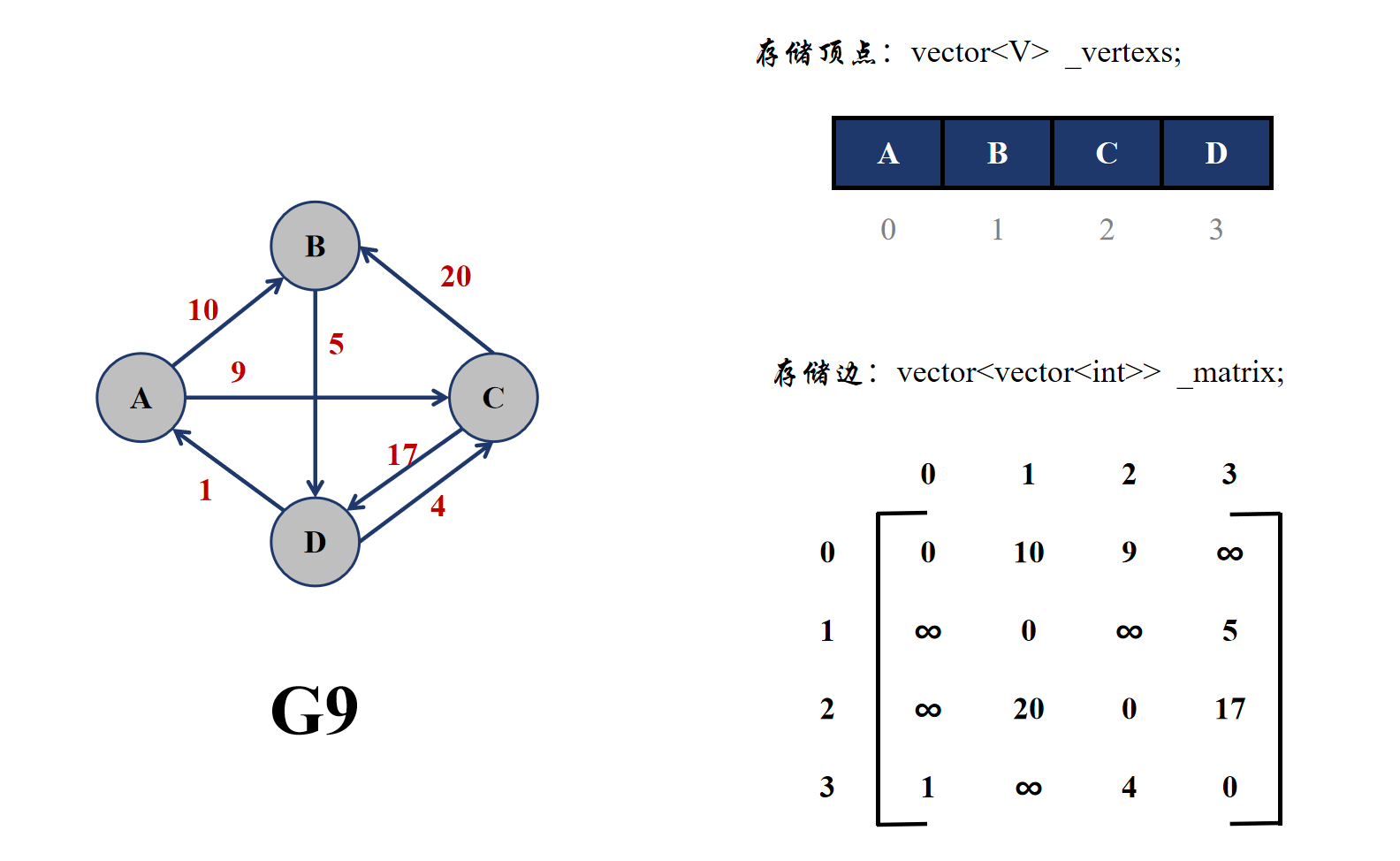
邻接矩阵的优点是能够快速查找到某两个顶点之间是否具有边,但是如果查找与一个顶点相连(有边)的所有顶点,对于无向图需要遍历完邻接矩阵中顶点编号的一行;但是对于有向图,需要遍历完顶点编号的一行与一列才可以找到。而且邻接矩阵适合存储稠密图,存储稀疏图会出现大量的 0 或者♾️,比较浪费空间。
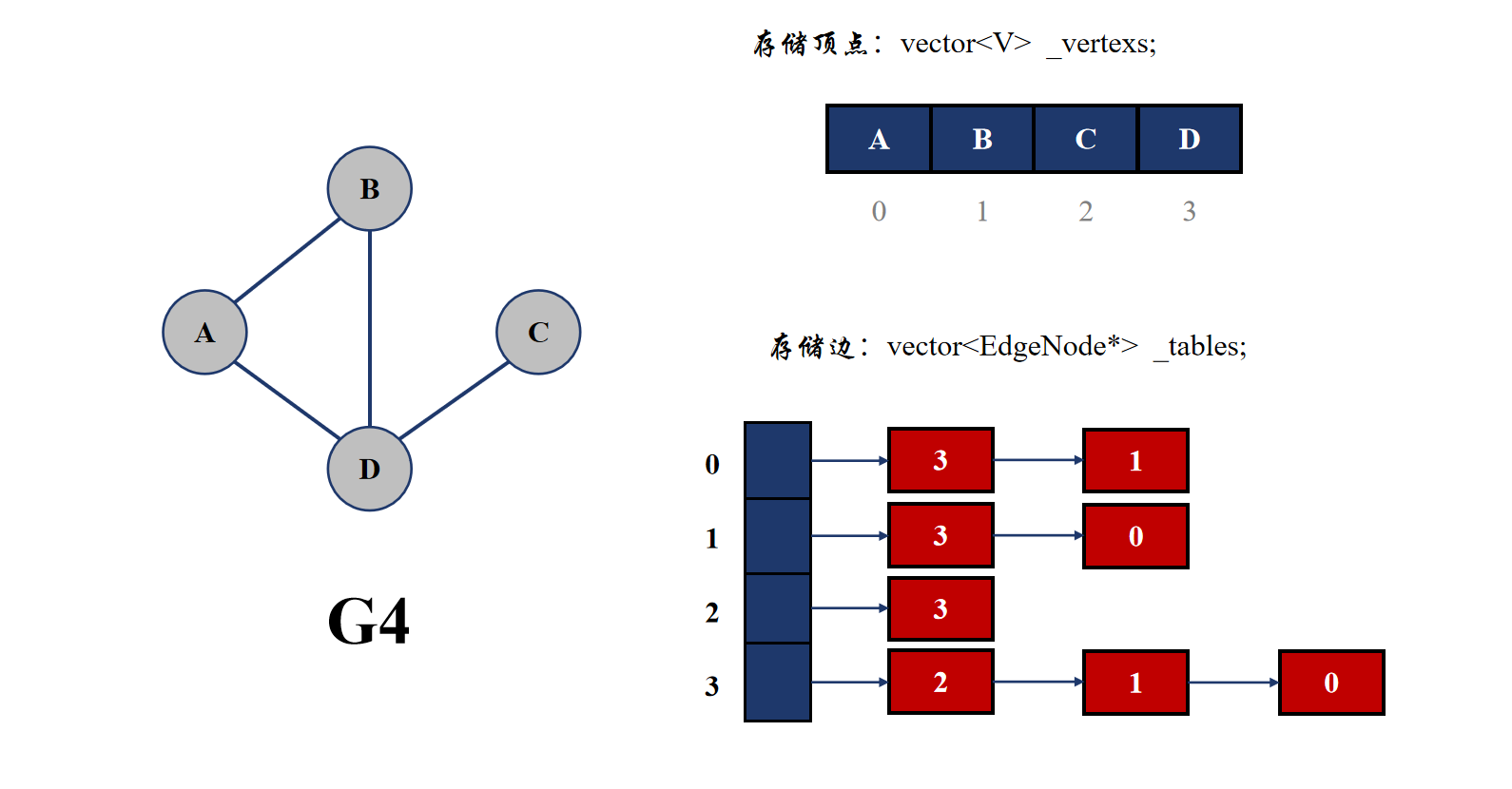
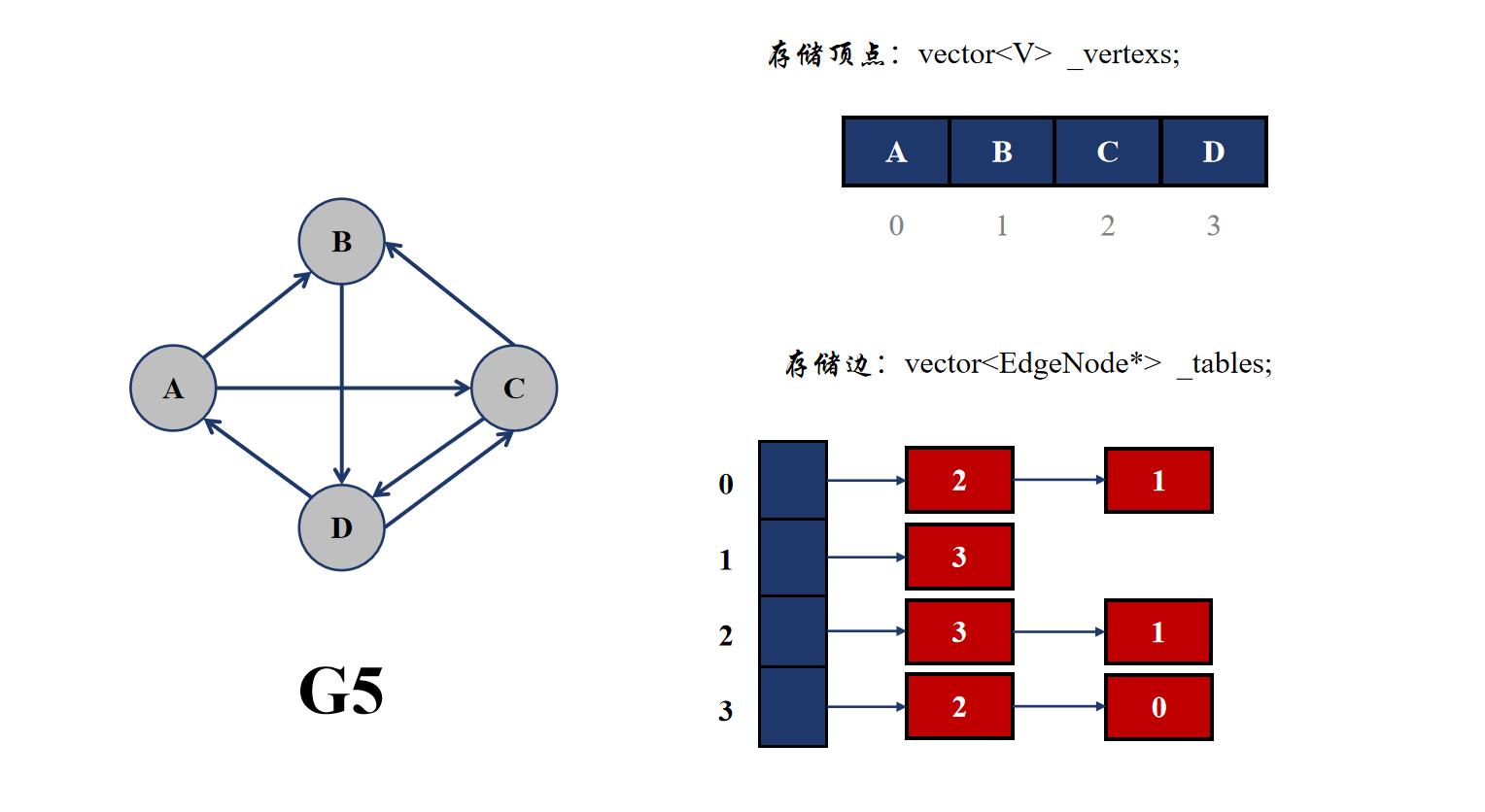
2.2.2 邻接表
邻接表依然使用数组来存储顶点,但是其是使用链表来存储与该顶点相连的边。具体来说,就是依然采用 vector 来存储顶点,但是边的存储使用的也是 vector,只不过存储边的 vector 里面的类型为 EdgeNode*,也就是用来连接与当前顶点相连顶点的编号。
无权图
带权图
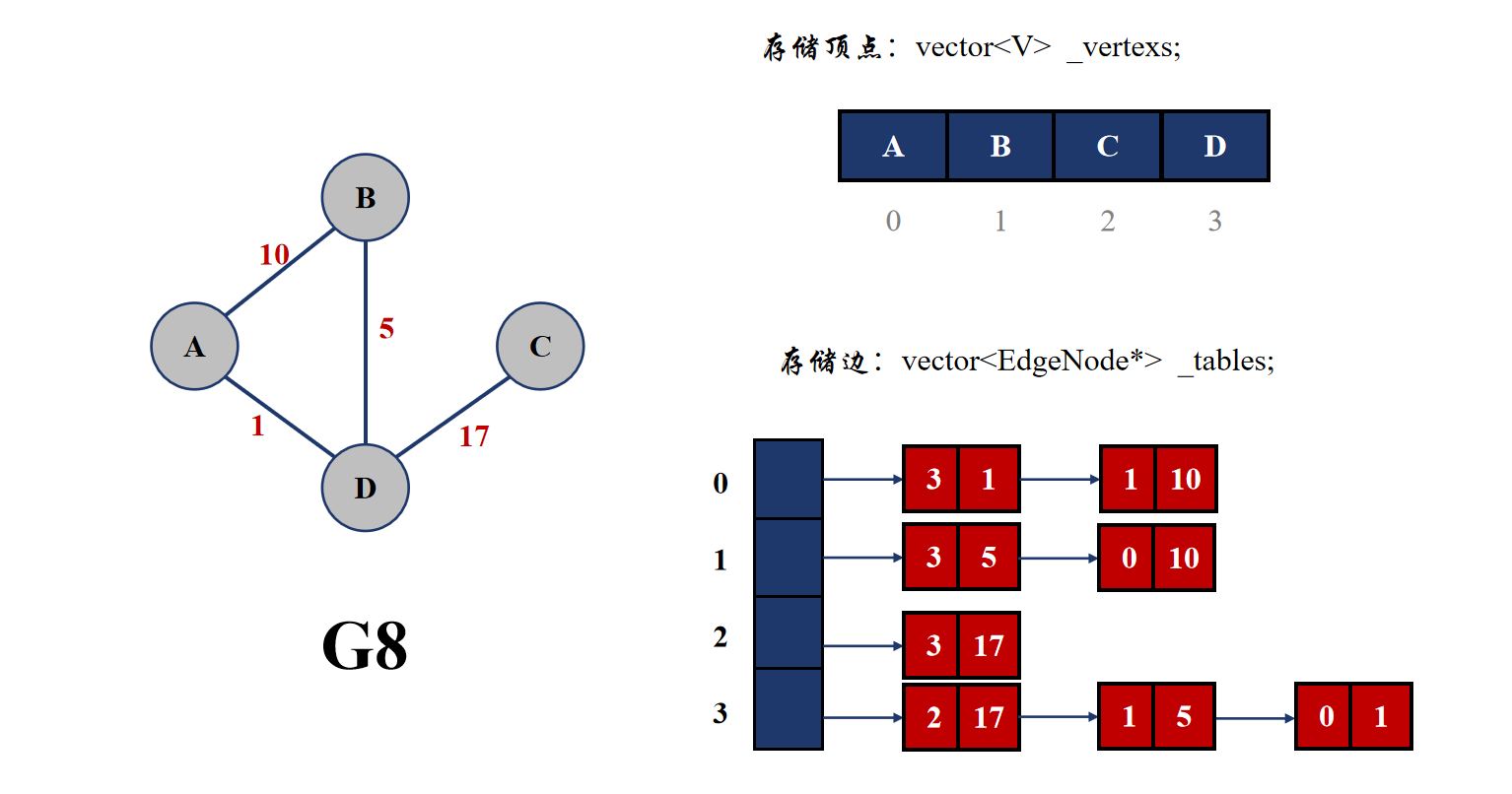
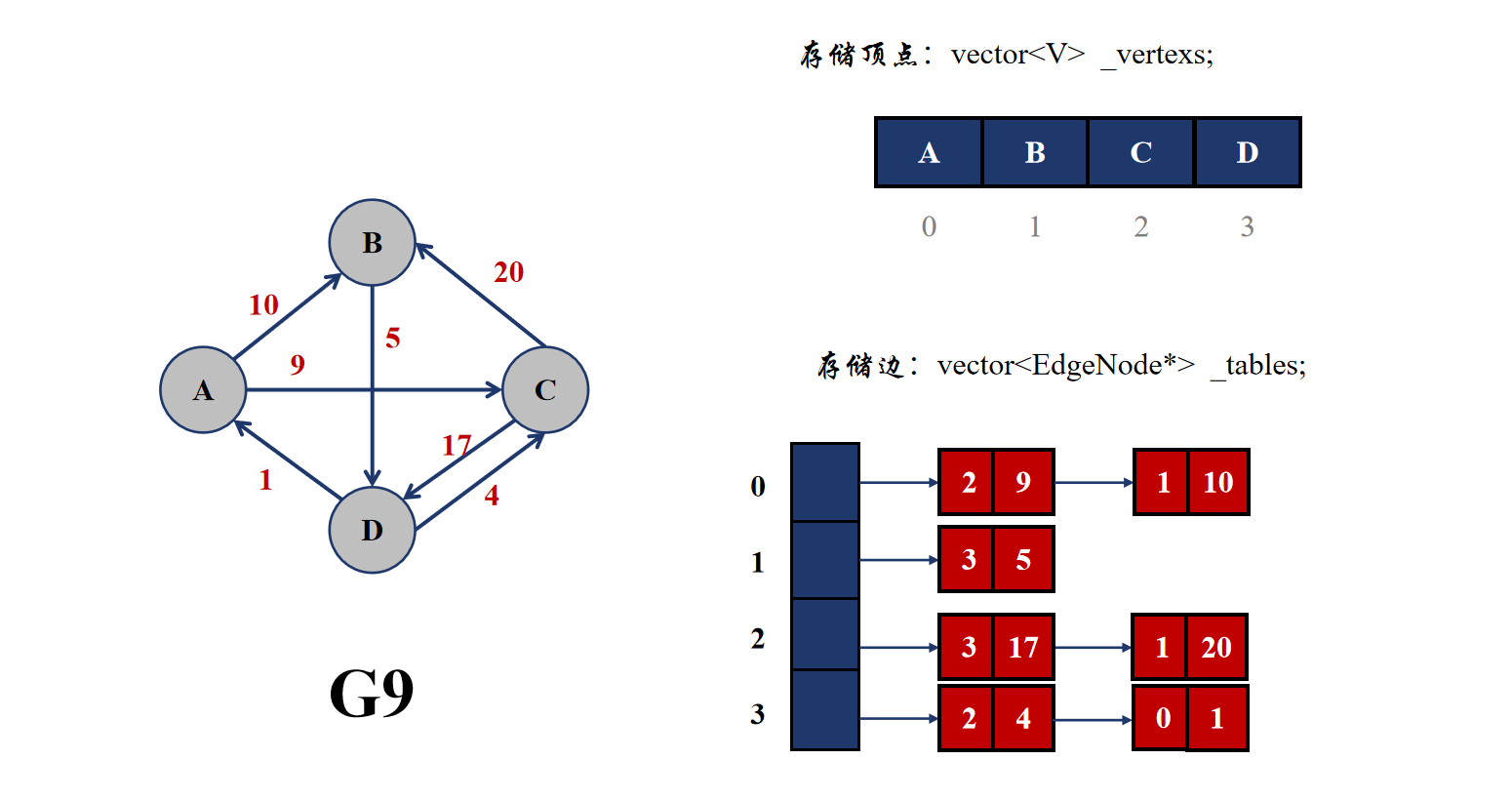
可以看到邻接表的表示方法其实与哈希桶很像,都是在 vector 里面保存指针。
邻接表查找与一个顶点相连的顶点很方便,只需要遍历一遍顶点编号的链表即可,但是查找两个顶点是否相连是不方便的,依然需要遍历查找。而且邻接表适合存储稀疏图,并不适合存储稠密图。
3 图存储结构的实现
3.1 邻接矩阵
对于邻接矩阵法存储图,一共会有四个模板参数,两个模板参数 V 和 W,V 表示顶点的类型,W 表示权值的类型,还有两个非类型模板参数,WAX_W 表示没有边时的权值大小,也就是邻接矩阵中的无穷大,这里用 INT_MAX 表示无穷大,Direction 非类型模板参数表示是否是有向图,为 false 时表示无向图,为 true 时表示是有向图。
#pragma once
#include <iostream>
#include <vector>
#include <string>
#include <map>
#include <stdexcept>
namespace Matrix
{
template<class V, class W, int MAX_W = INT_MAX, bool Direction = false>
class Graph
{
public:
Graph() = default; // 默认构造函数
Graph(const V* vertexs, size_t n)
{
//对图里面的成员进行初始化
_vertexs.reserve(n);
for (int i = 0; i < n; i++)
{
_vertexs.push_back(vertexs[i]);
_IndexMap[vertexs[i]] = i;
}
//再对邻接矩阵进行扩容
_matrix.resize(n);
for (auto& v : _matrix)
{
v.resize(n, MAX_W);
}
//这里也可以将邻接矩阵对角线变为0
//不变也没关系,因为不会用到的
for (int i = 0; i < n; i++)
{
_matrix[i][i] = 0;
}
}
size_t GetVertexIndex(const V& v)
{
if (_IndexMap.count(v))
{
return _IndexMap[v];
}
else
{
//没找到抛出异常
throw std::invalid_argument("the vertex is not exist!");
return -1;
}
}
bool AddEdge(const V& src, const V& dst, int weight)
{
//1. 先查找 src 与 dst 对应的下标
size_t srci = GetVertexIndex(src);
size_t dsti = GetVertexIndex(dst);
if (srci == -1 || dsti == -1)
{
return false;
}
//2. 向邻接矩阵中添加边
_matrix[srci][dsti] = weight;
//别忘记对无向图,要将 dsti 与 srci 也改为权值
if (!Direction)
{
_matrix[srci][dsti] = weight;
}
return true;
}
//打印函数
void Print()
{
// 打印顶点和下标映射关系
for (size_t i = 0; i < _vertexs.size(); ++i)
{
std::cout << _vertexs[i] << "-" << i << " ";
}
std::cout << std::endl << std::endl;
std::cout << " ";
for (size_t i = 0; i < _vertexs.size(); ++i)
{
std::cout << i << " ";
}
std::cout << std::endl;
// 打印矩阵
for (size_t i = 0; i < _matrix.size(); ++i)
{
std::cout << i << " ";
for (size_t j = 0; j < _matrix[i].size(); ++j)
{
if (_matrix[i][j] != MAX_W)
std::cout << _matrix[i][j] << " ";
else
std::cout << "#" << " ";
}
std::cout << std::endl;
}
std::cout << std::endl << std::endl;
// 打印所有的边
for (size_t i = 0; i < _matrix.size(); ++i)
{
for (size_t j = 0; j < _matrix[i].size(); ++j)
{
if (i < j && _matrix[i][j] != MAX_W)
{
std::cout << _vertexs[i] << "-" << _vertexs[j] << ":" <<
_matrix[i][j] << std::endl;
}
}
}
}
private:
std::vector<V> _vertexs; //顶点集合 -- 下标映射到顶点
std::map<V, size_t> _IndexMap; //顶点映射到下标
std::vector<std::vector<W>> _matrix; //邻接矩阵
};
void Test_Matrix()
{
Graph<char, int, INT_MAX, true> g("0123", 4);
g.AddEdge('0', '1', 1);
g.AddEdge('0', '3', 4);
g.AddEdge('1', '3', 2);
g.AddEdge('1', '2', 9);
g.AddEdge('2', '3', 8);
g.AddEdge('2', '1', 5);
g.AddEdge('2', '0', 3);
g.AddEdge('3', '2', 6);
g.Print();
}
}3.2 邻接表
邻接表与邻接矩阵的模板参数相同,只不过多了一个 EdgeNode 结构体来表示每条边,一共有三个成员,分别是 _dsti:相连的顶点编号,_weight:边的权值,_next:next 指针,指向下一个节点。
namespace Link_Table
{
template<class W>
struct EdgeNode
{
int _dsti;
W _weight;
EdgeNode<W>* _next;
EdgeNode(const W& w)
:_dsti(-1)
,_weight(w)
,_next(nullptr)
{}
};
template<class V, class W, int MAX_W = INT_MAX, bool Direction = false>
class Graph
{
using Edge = EdgeNode<W>;
public:
Graph() = default; // 默认构造函数
Graph(const V* vertexs, size_t n)
{
//对图里面的成员进行初始化
_vertexs.reserve(n);
for (int i = 0; i < n; i++)
{
_vertexs.push_back(vertexs[i]);
_IndexMap[vertexs[i]] = i;
}
//对邻接表进行扩容
_tables.resize(n, nullptr);
}
size_t GetVertexIndex(const V& v)
{
if (_IndexMap.count(v))
{
return _IndexMap[v];
}
else
{
//没找到抛出异常
throw std::invalid_argument("the vertex is not exist!");
return -1;
}
}
bool AddEdge(const V& src, const V& dst, int weight)
{
//1. 先查找 src 与 dst 对应的下标
size_t srci = GetVertexIndex(src);
size_t dsti = GetVertexIndex(dst);
if (srci == -1 || dsti == -1)
{
return false;
}
//2. 向邻接表中添加边
Edge* newedge = new Edge(weight);
newedge->_dsti = dsti;
//对对应编号的链表进行头插
newedge->_next = _tables[srci];
_tables[srci] = newedge;
//不要忘记对无向图 dsti 也插入 srci
if (!Direction)
{
Edge* dstedge = new Edge(weight);
dstedge->_dsti = srci;
//对对应编号的链表进行头插
dstedge->_next = _tables[dsti];
_tables[dsti] = dstedge;
}
return true;
}
private:
std::vector<V> _vertexs; //顶点集合 -- 下标映射到顶点
std::map<V, size_t> _IndexMap; //顶点映射到下标
std::vector<Edge*> _tables; //邻接表
};
void Test_LinkTable()
{
std::string a[] = { "张三", "李四", "王五", "赵六" };
Graph<std::string, int> g1(a, 4);
g1.AddEdge("张三", "李四", 100);
g1.AddEdge("张三", "王五", 200);
g1.AddEdge("王五", "赵六", 30);
}
}总结
本文主要围绕并查集和图这两类常见数据结构进行了基础介绍与实现。首先介绍了并查集的基本概念、核心思想以及查找、合并等基本操作,并对并查集的应用场景进行了简要说明。随后对图这一数据结构进行了概念讲解,包括顶点、边、无向图、有向图、带权图等基本组成,并分别使用邻接矩阵和邻接表两种方式对图进行了实现。为后面学习图的遍历、最小生成树和最短路径等进阶算法可以提供借鉴。


















 2187
2187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










