




 本文详细介绍了Python内置的HTTP请求库urllib,包括urllib.parse的URL处理方法,如urlparse、urlunparse和urljoin,以及urlencode函数。接着讲解了urllib.request的urlopen用于打开URL,以及Request类用于添加headers进行伪装。还提到了urllib.error模块处理HTTPError和URLError异常。最后讨论了如何通过设置headers来避免因User-Agent问题导致的访问限制。
本文详细介绍了Python内置的HTTP请求库urllib,包括urllib.parse的URL处理方法,如urlparse、urlunparse和urljoin,以及urlencode函数。接着讲解了urllib.request的urlopen用于打开URL,以及Request类用于添加headers进行伪装。还提到了urllib.error模块处理HTTPError和URLError异常。最后讨论了如何通过设置headers来避免因User-Agent问题导致的访问限制。
urllib库
urllib库是Python内置的HTTP请求库,它包含4个模块:
1 urllib.parse 负责解析
一个工具模块,提供了许多URL处理方法,比如拆分、解析、合并等
2 urllib.request 负责请求
http请求模块,可以用来模拟发送请求。就好比在浏览器中输入网址然后回车一样,只需要给库方法传入URL以及额外的参数,就可以模拟实现这个过程
3.urllib.error 异常处理模块
如果出现请求错误,我们可以捕捉这些异常,然后进行重试或其他操作,保证程序不会意外终止
4. urllib.robotparser 负责robots.txt文件的解析
主要用来识别网站的robots.txt文件,然后判断哪些网站可以爬,哪些不可以
一.parse 模块
1.parse.urlparse():URL的抽取
import urllib.parse
url = 'https://www.baidu.com/s?ie=utf-8&tn=baidu&wd=%E7%BE%8E%E5%A5%B3#a'
result = urllib.parse.urlparse(url)
print(result)
# scheme:表示协议
# netloc:域名
# path:路径
# params:参数
# query:查询条件,一般都是get请求的url
# fragment:锚点,用于直接定位页面的下拉位置,跳转到网页的指定位置![]()
2.parse.urlunparse():URL的构造
urls = ('https','www.baidu.com','s','','ie=utf-8&tn=baidu&wd=%E7%BE%8E%E5%A5%B3','')
full_url = urllib.parse.urlunparse(urls)
print(full_url)![]()
3.parse.urljoin():URL的合并
将相对的地址组合成一个url,对于输入没有限制,开头必须是http://,否则将不组合前面。
import urllib.parse
url1 = "https://www.baidu.com/folder/main.html"
url2 = "test.html"
url = urllib.parse.urljoin(url1,url2)
print(url)
url3 = "/test.html"
url = urllib.parse.urljoin(url1,url3)
print(url)
url4 = "folder2/test"
url = urllib.parse.urljoin(url1,url4)
print(url)
url5 = "/folder2/test"
url = urllib.parse.urljoin(url1,url5)
print(url)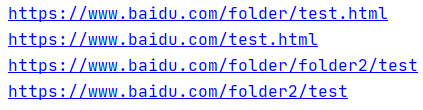
4. urlencode()序列化字典类型转换为请求类型(URL的编码格式)
params = {
'name' : 'germey',
'age' : 22
}
base_url = 'http://www.baidu.com?'
url = base_url + urllib.parse.urlencode(params)
print(url) ![]()
URL中,如果包含name age这种参数的时候,不会以键值对的形式出现,而是通过'&'字符连接两个键值对,而键值对的键与值之间直接用'='连接,整体是一个字符串 如上面的结果的显示一样,与原有的字符串可以合并成一个新的URL,所以当发起post的请求的时候,需要将字典的数据转变成URL形式的字符串
二.request模块
1. request.urlopen()
urlopen用来打开url,形式:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
url 资源url,data:携带的数据 ,timeout(超时时间)
返回一个对象;其中对于http及https的url会返回一个http.client.HTTPResponse对象;
import urllib.request
url = "http://www.baidu.com"
response = urllib.request.urlopen(url)
print(response)![]()
1.1 read() 返回服务器返回的原始数据并用decode 解码
import urllib.request
url = "http://www.baidu.com"
response = urllib.request.urlopen(url)
print(response.read().decode("utf-8"))
1.2 info()返回页面的元信息
1.3 getcode()页面的状态码
1.4 data 参数、
必须是字节流编码格式的内容,即bytes类型,当传递这个参数的时候请求就变成了post请求,默认是get方式
- GET - 从指定的资源请求数据。
- POST - 向指定的资源提交要被处理的数据
import urllib.parse
data = bytes(urllib.parse.urlencode({"hello":"world"}),encoding="utf-8")
#将用户信息封装在data中,用dytes转成二进制数组
response = urllib.request.urlopen("http://httpbin.org/post",data=data)
print(response.read().decode('utf-8'))上述过程可以理解为我们打算传递的是"hello":"world"的数据,但数据需要通过urlencode进行字典数据到URL编码格式数据的转换,在转成data数据指定(encoding="utf-8")的dytes格式,从而传递给urlopen向服务器发起post请求。上面http://httpbin.org/ 网站是测试 网站发送请求的过程;
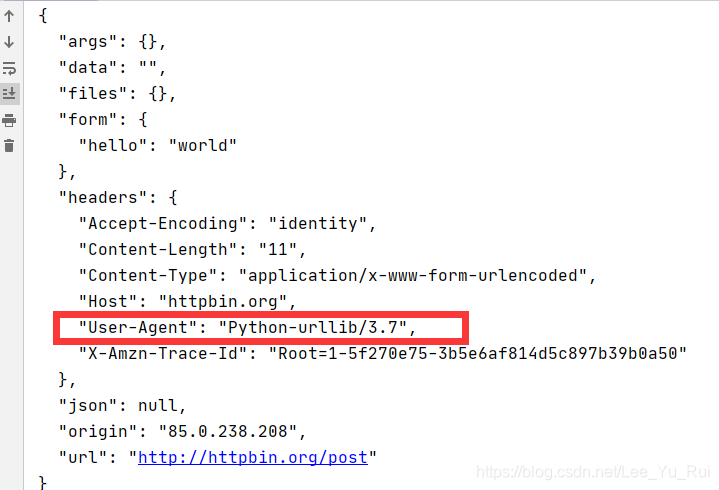
产生结果:发现User-Agent:是Python 也就是说,目前很诚实的告诉服务器这是Python在爬虫!!这不行啊,我们要做的是模拟浏览器的访问过程,如果这个地方显示的和真实浏览器不符,会使得大部分的网站认出你不是真的浏览器,所以拒绝接受访问,同样我们可以在网站测试get请求过程的响应
response = urllib.request.urlopen("http://douban.com")
print(response.read().decode('utf-8'))
去访问豆瓣,发现错误418,就是你被抓到了,不让你访问。不让你访问的原因就是,索然通过urlopen可以模拟访问的过程,但是响应或者说提交给服务器的身份信息并不和浏览器访问的完全一致,比如user-agent就不一样,所以查看urlopen( )函数的API,似乎这几个参数并不足以构建一个完整的请求
2. request.Request()
:加入headers等加入伪装的更好的信息,我们依然使用urlopen( )来发送这个请求,只是这次的参数不再是URL,而是一个Request类型的对象,本质就是不仅仅是有data还有一些浏览器的伪装信息等。
url = "http://httpbin.org/post"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
data = bytes(urllib.parse.urlencode({"name":"eric"}),encoding="utf-8")
req = urllib.request.Request(url = url, data=data,headers=headers,method = "POST")
response = urllib.request.urlopen(req)
print(response.read().decode("utf-8"))上述的过程是post请求,如果不需要post请求,可以省略data的参数信息,以下结果表明通过额外i装header信息成功进入豆瓣
url = "http://www.douban.com"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
req = urllib.request.Request(url = url, headers=headers)
response = urllib.request.urlopen(req)
print(response.read().decode("utf-8"))
3.urllib.error 异常处理模块
分为URLError和HTTPError
- URLError封装的错误信息一般是由网络引起的,包括url错误
- HTTPError封装的错误信息一般是服务器返回了错误状态码
URLError是OSERROR的子类,HTTPError是URLError的子类,注意:由于HTTPError是URLError的子类,所以捕获的时候HTTPError要放在URLError的上面
假如没有伪装前豆瓣的网站我们不能进去,如果不希望它因为错误中断爬取下一个网站就可以使用如下代码,通过结果可以知道原因,便于后期重新设置
from urllib import request,error
try:
response = request.urlopen('http://www.douban.com')
except error.HTTPError as e:
print("HTTPError",e.reason,e.code,e.headers,sep='\n')
except error.URLError as e:
print("URLError",e.reason)
except Exception as e:
print("others",e)
else:
print('Request.Sucessfully')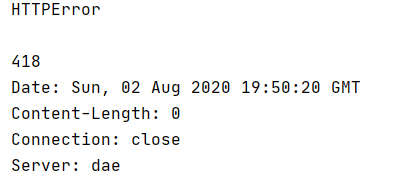



















 8644
8644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












