




继 01 大模型基础能力构建 之后,继续阅读该篇。
9 LangChain概述与架构
如果是java选手,学习过langchain4j,上手这部分内容应该很快。
先详细看看课程目标
- 建立对 LangChain 的整体认识,知道它是什么、解决什么问题、在 AI 应用开发里处于什么位置。
- 理解 LangChain 在 1.x 时代的产品边界、包结构、版本演进,以及它与 LangGraph、LangSmith、Deep Agents 的关系。
- 建立对 Model I/O、Chains、Memory、Retrieval、Tools/Agents、Callbacks 这六类教学视角的整体认知。
看完第9章建立认知,第10章实践进行熟悉。
1 Langchain简介
LangChain 是一个面向 LLM 应用开发的开源框架。它本身不是大模型,也不是数据库,更不是知识库平台;它更像一层“应用编排层”,负责把模型、提示词、外部知识、工具、记忆、输出解析、调试追踪等能力组织成一个完整、可维护、可扩展的 AI 应用。
Langchain是 用代码把大模型和外部世界连接起来的应用开发框架
Langchain在于把原本零散的东西组织起来,
- 不同厂商的大模型调用方式
- Prompt 与多角色消息
- 结构化输出与解析
- 检索增强生成(RAG)
- 工具调用、Agent、多步任务
- 记忆、会话状态、持久化
- 日志、追踪、调试、评估
直接调API可以,适合简单任务,但是做应用,框架就会越来越有价值。
如下图所示的对比,可以利用框架进一步抽象,隔离,进行统一编排,统一接入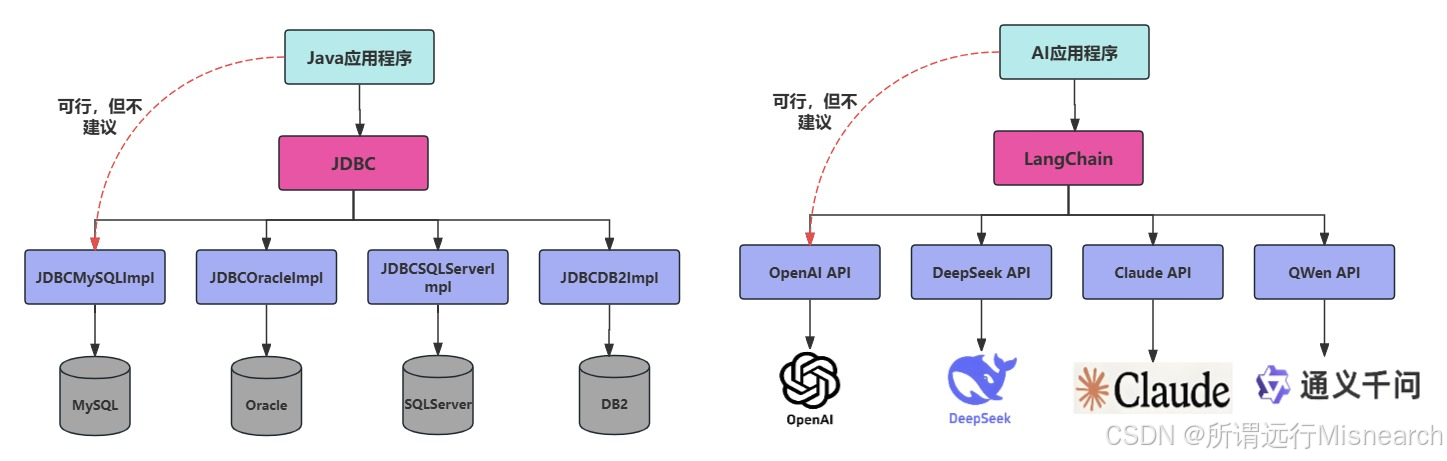
Coze/Dify等平台是低代码平台,受限于平台。
Langchain是代码框架或库,在 Python 或 JS 中以代码方式编排模型、工具、RAG、Agent
实际项目里可以先低代码验证,再代码化落地。
现在版本更稳定,1.x版本,学习入口更清晰,重点放在 create_agent、统一模型初始化、消息、工具、记忆、检索和可观测性上。
LangChain、LangGraph、LangSmith 的分工更明确:你更容易理解“什么时候用高层框架,什么时候用底层图编排,什么时候做调试与评估”
LangChain 的优势很明显,但它也不是银弹。学习时要同时看到它的“能做什么”和“不能替你做什么”。
优势:
- 统一模型接口,降低模型切换和多模型共存成本。
- 提供 Prompt、Message、Parser、Retriever、Tool、Agent 等常用抽象。
- 能把“单次调用”提升为“可维护流程”。
- 与 LangGraph、LangSmith、MCP 等生态衔接紧密,利于走向复杂应用。
- 资料多、案例多、社区活跃,适合建立体系化认知。
边界:
- 它不会替你设计业务逻辑,只是帮你更好地实现。
- 它不会替你训练模型,模型能力强弱仍取决于底层模型。
- 它不会替你存业务数据,向量库、数据库、对象存储仍要你自己选型。
- 它不会天然让效果变好,Prompt、知识质量、工具设计、评估流程依然是关键。
不足与槽点:
- 版本变化快:老教程里的类名、导入路径、写法,很可能在新版本里已经迁移。
- 抽象多,学习成本不低:初学时容易觉得“明明只是调个模型,为什么多了这么多概念”。
- 历史包袱真实存在:很多文章还在讲 LLMChain、ConversationChain、旧版 AgentExecutor,但新项目未必应照搬。
- 文档存在新旧并存现象:官方文档已经比早期稳定很多,但生态广,仍会碰到版本语境不一致的问题。
所以结论很明确:LangChain 适合做 AI 应用,但要用“工程框架”的心态去学,不要把它当成一个简单工具函数库。
2 LangChain定位
2.1 大模型开发体系分类
按照大模型相关工作,从底到顶的一个分类
- 基础模型层
- 模型定制层
- 应用开发层
LangChain 主要服务的,就是第三层:应用开发层。负责如何把模型能力变成一个能工作的应用系统。显然LangChain,LangGraph是服务编排层。
数据流:请求 自上而下(用户 → 服务/链 → 模型 → 存储),结果 自下而上返回用户;LangChain 处在 服务/编排层,串联 UI、模型与存储,而不是替代其中任一层。
2.3 使用场景
真实项目里,LangChain往往会承担下面几件事:
- 统一接模型
- 统一处理输入输出:用PromptTemplate、消息对象、输出解析器来规范请求与结果
- 组织固定流程
- 接入工具与外部系统
- 管理状态与记忆
- 做调试与评估
学习框架,掌握这套思维,再迁移到其他框架会快很多。
这里的简历看一下,
3 LangChain包与版本管理
3.1 版本演进:从链到Agent + 图 + 生态
- 第一阶段:0.0.x/0.1早期版本,特点是链优先
- 第二阶段:0.2,0.3阶段,开始重视生态拆分和工程边界
- 第三阶段:1.x阶段,重点变成精简主包,强化Agent,与LangGraph深度融合
2025年10月20日发布LangChainv1.0.0
3.2 当前官方产品线理解
官方讲一整套出产品线。
- LangChain:高层应用框架,快速构建,屏蔽大量底层细节
- LangGraph:低层图编排与运行时
- LangSmith:可观测性、评估、调试、部署平台,用来追踪、调试、评估和上线应用
- Deep Agents:开箱即用的复杂Agent方法,建立在Langchain/ LangGraph之上
3.3 0.x与1.x的核心差异
如下图所示:
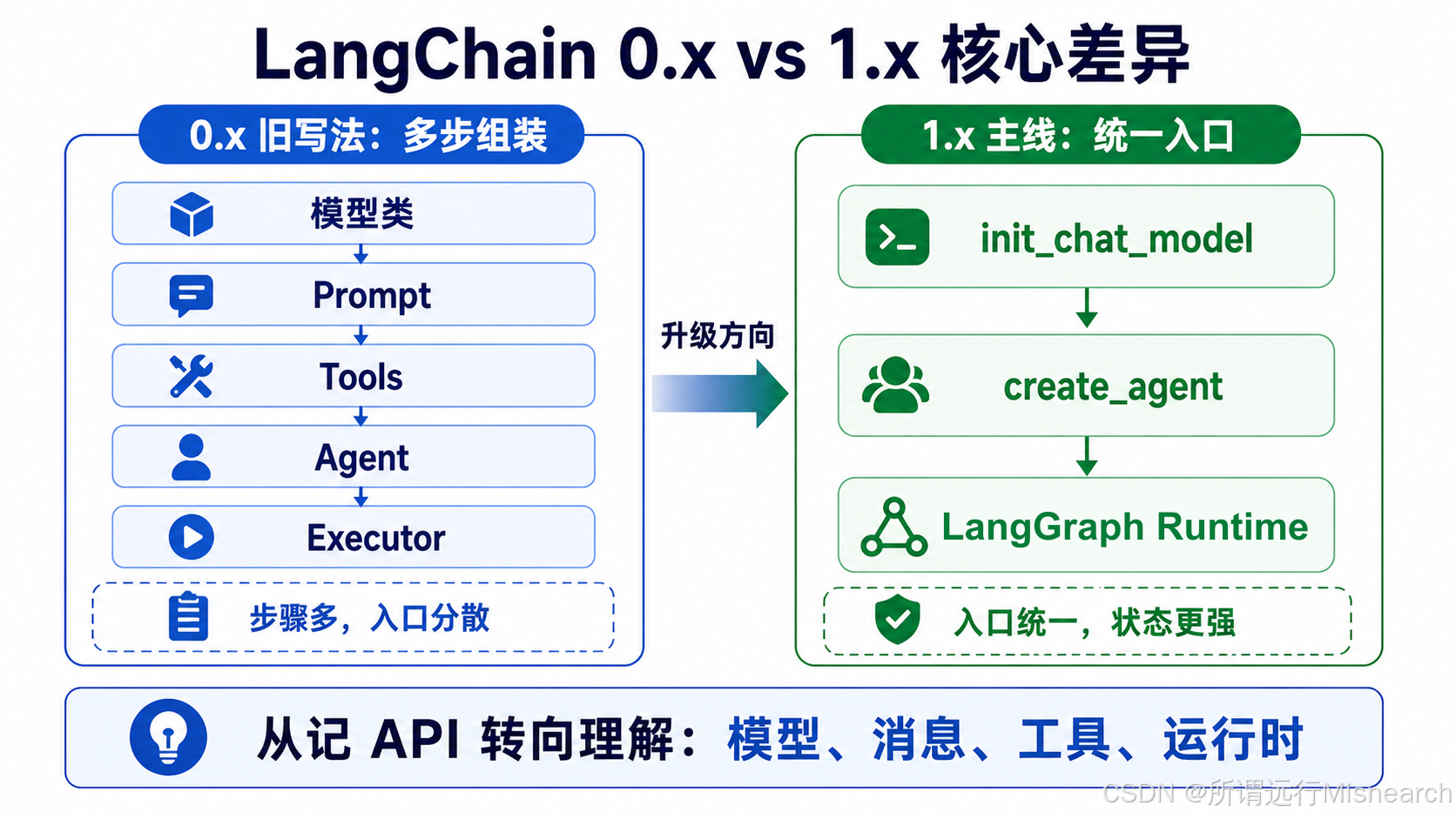
1.x更像精简主包 + 统一入口 + Agent建立在LangGraph之上
下面有一个0.x和1.x版本对比:
| 对比项 | 0.x写法 | 1.x写法 |
|---|---|---|
| Agent 创建 | 常见要手动组装Agent + Executor | 以create_agent为主入口 |
| 模型初始化 | 常见直接记忆具体类或旧导入路径 | 更强调统一入口,如init_chat_model |
| 主包内容 | langchain中内容很多,历史包袱重 | langchain主包被精简,只聚焦核心能力 |
| 旧能力去向 | LLMChain, 老Retriever等混在主包中 | 迁到langchain-classic |
| 底层运行时 | 以前很多人只感受到链 | 现在agent明前建立在langgraph之上 |
| python版本 | 老资料中常见3.8, 3.9 | 官方1.x要求python3.10 |
3.4 LangChain常见包
按照官方主线重新梳理
- langchain-core:核心抽象层,包含消息、Runnable、工具基础、Prompt 基础、模型接口等,是整个生态的底座
- langchain:高级应用框架主包,1.x中聚焦核心高层能力,如Agent,统一模型初始化,消息与工具等
- langchain-openai/ langchain-anthropic/langchain-allama:厂商/provider集成包,每个模型 厂商或平台通常有自己的独立集成包,便于独立版本管理。
- langchain-community:社区集成包,放置大量社区维护的集成,例如某些工具,loader, 向量库等。
- langchain-classic:旧版兼容包,
- langgraph:图编排与运行时,用于构建更复杂、可控、可持久化的Agentic workflow
- langsmith:调试、评估、Tracing SDK,对接LangSmith平台,常用语可观测性与实验评估
- langchain-text-splitters:文本切分组件,RAG常用,负责把 长文本拆分为合适片段。
- langchain-mcp-adpters:MCP适配包,用于在langchain/langgrpah应用中接入MCP工具
4 LangChain核心模块
4.1 全景图
下面这张图展示了完整知识体系,
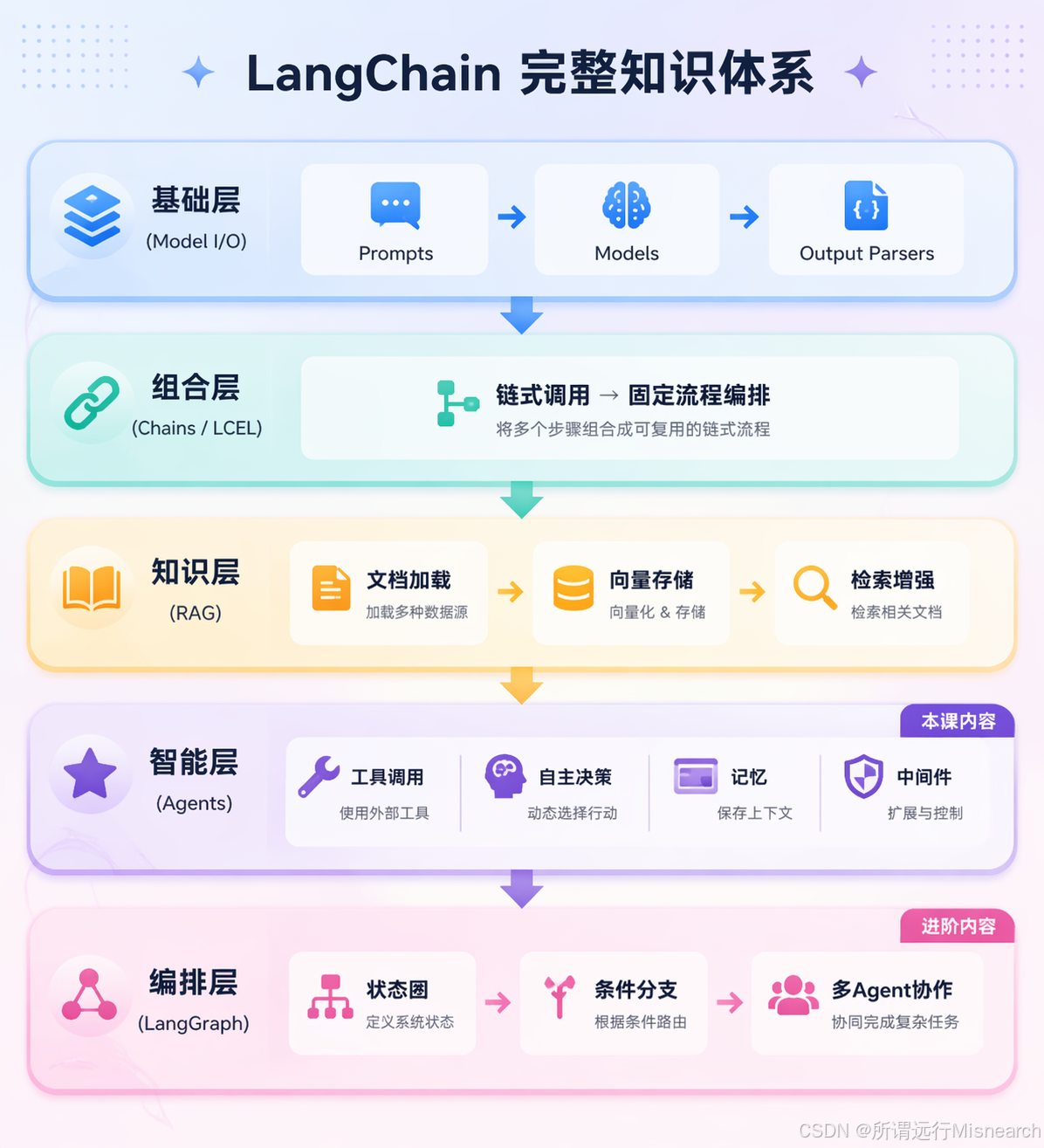
从这个视角看,LangChain 的核心模块其实是在回答六个问题:
- 怎么接模型:Model / Model I/O
- 怎么组织固定流程:Chains / LCEL
- 怎么记住上下文:Memory
- 怎么接外部知识:Retrieval / RAG
- 怎么让模型会做事:Tools / Agents
- 怎么观测与调试:Callbacks / LangSmith
4.2 Model I/O 模型输入输出
该部分是有关模型调用本身的一圈能力,解决的是输入怎么组织、模型怎么调、输出怎么拿的稳。
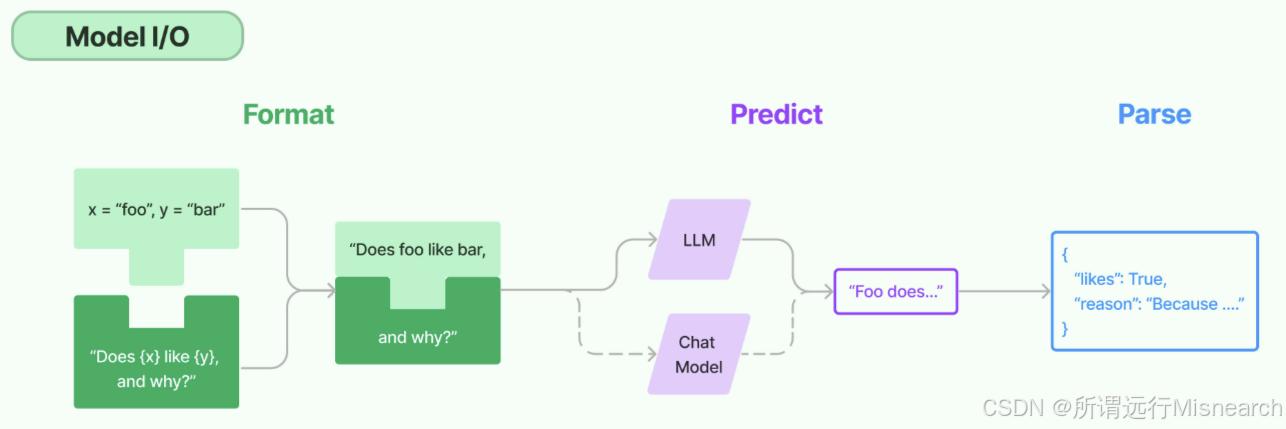
主要包含:
- Format:输入格式化,把原始输入组织成prompt或多角色消息
- Predict:模型调用,用统一接口调用不同厂商模型
- Parse:输出解析,把自然语言输出转成更稳定的结构化结果
4.3 Chains链:固定流程编排
Chain核心思想很简单:把多个步骤按固定顺序串起来。
链式思维仍然是LangChain的基础能力。
固定流程更适合Chain/LCEL。动态决策流程更适合Agent/Graph。
4.4 Memory记忆:记忆与上下文状态
Memory指的是应用如何“记住”过去发生过什么。注意,这里的记忆不是让模型变得更聪明,而是让系统在多轮交互中保留必要上下文。例如历史对话、用户偏好、会话状态、阶段性结果等。
在官方当前语境里,记忆通常会去分为Short-term Memory,和Long term memory。
4.5 Retrieval检索:检索与RAG
Retrieval模块解决的是模型不知道的知识从哪里来的问题。
是RAG的核心组成部分,负责从外部知识源中检索和当前问题相关的信息,再把检索结果交给模型辅助生成答案。
4.6 Tools/Agents:让模型不只是会说,还会做
4.6.1 Tool是什么
Tool本质上是一个可以被模型调用的外部能力
4.6.2 Agent是什么
则是在Tool之上再多一层,不是简单执行固定步骤,而是让模型根据当前任务自主决定下一步该做什么。
在1.x官方语境下,LangChain的Agent已经明确建立在LangGraph运行时之上,即使只是调用 create_agent,底层也不再只是一个松散的“工具循环”,而是带有状态、节点、流转、持久化能力的图式运行逻辑。
4.7 Callbacks回调:日志、调试与可观测性
一个可用的AI应用,不只是能跑,还要能看见他怎么跑。
现在官方更强调的是LangSmith + Tracing + Evaluation这一整套可观测性能力。
AI应用最难排查的问题,通常不是程序报错,而是为什么这次没检索到,为什么调了错误工具,为什么模型理解偏了,为什么这轮成本突然变高,为什么线上效果和本地不一致。
如果没有可观测性,很多问题只能猜。
4.8 六大模块总览
教学视图下的六大模块
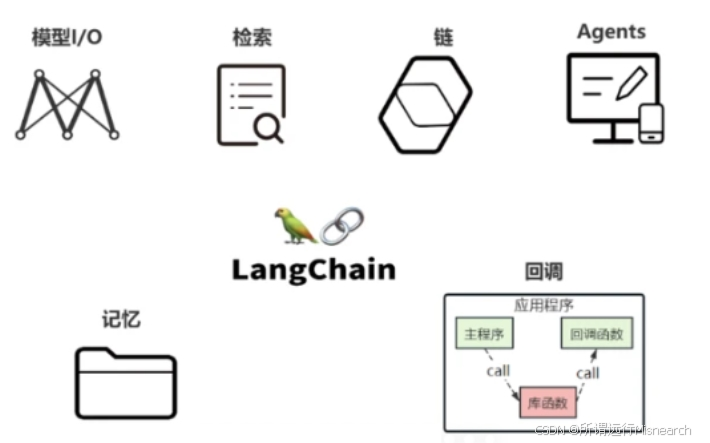
官方 1.x 文档中,你会看到这些能力被拆到 Agents、Models、Messages、Tools、Memory、Retrieval、Streaming、Structured Output、Middleware、Runtime、LangSmith 等更细的栏目里
进一步展开模块:
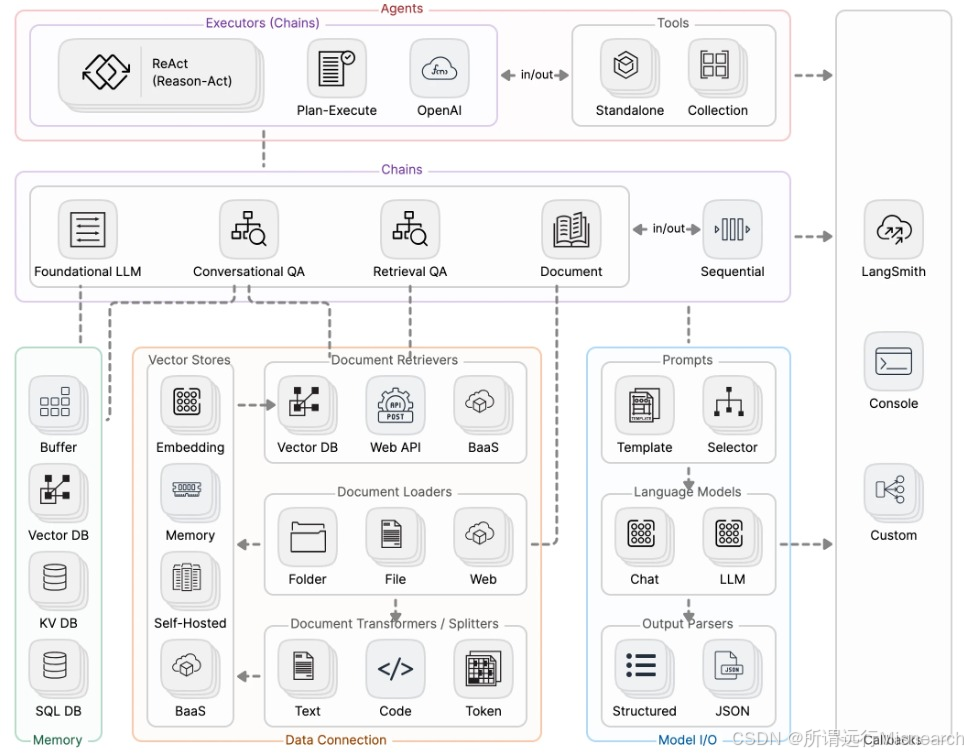
根据图的理解,理解LangChain做的不是某一件事,而是把模型调用、知识接入、流程编排、状态管理、工具执行、调试追踪这些原本分散的环节串成一个工程系统。
4.9 怎么记这套框架
章节思考题
为什么学习LangChain时要同时知道1.x,provider, Langgraph,
A : 1.x是当前主线,provider包负责具体模型接入,LangGraph承担复杂流程和Agent的底层编排
10 LangChain快速上手与HelloWorld
langchain中文文档链接
中文文档都是翻译更新的,可能慢于官方文档的更新速度
这里需要在新电脑按照之前配置环境配置好python3.10的虚拟环境。
这里还是解释一下pip和uv,
- pip:它是 Python 的官方包管理工具(全称 Pip Installs Packages)。开发者使用它来查找、下载、安装、升级和卸载 Python 第三方库和依赖包。例如,使用 pip install requests 就可以安装网络请求库13。
- uv:它是一个用 Rust 编写的、极其快速的 Python 包和项目管理器。你可以把它理解为 pip 的“超级替代品”。它的核心优势是速度极快(比传统 pip 快 10 到 100 倍),并且兼容 pip 的常用命令(如 uv pip install),同时还集成了虚拟环境管理等高级功能
1 LangChain环境与约定
1.1 支持的大模型与课程选用
langchain官方提供了完整的provider列表,将provider理解为封装好各个大模型的api提供者,只需要安装对应包 -》设置模型名称就可以切换各个大模型。
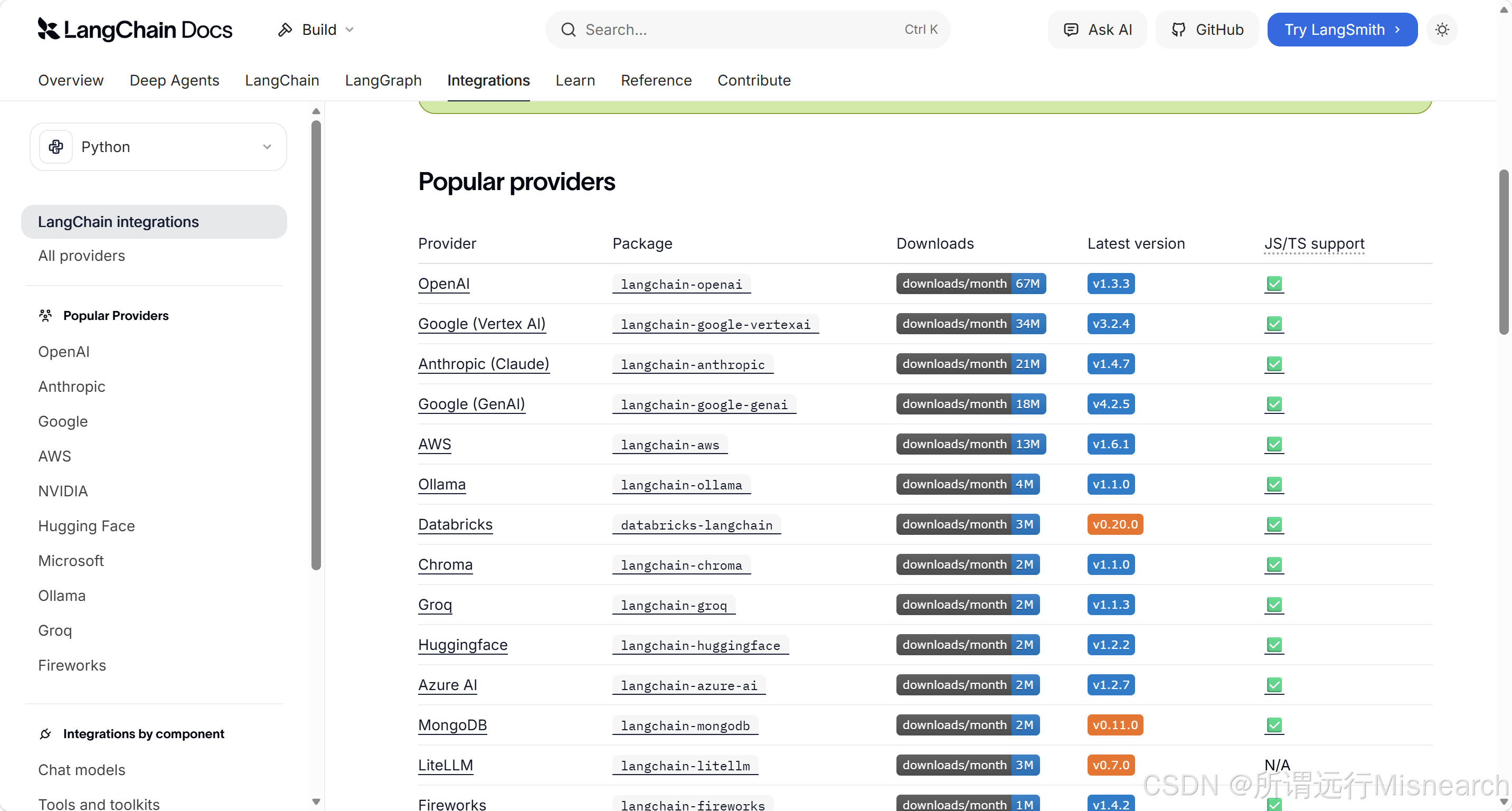
本课程选择阿里云百炼、千问,关键是理解怎么用langchain接模型。
1.2 python版本
langchain1.x推荐python3.10
1.3 运行案例前置注意事项
- 尽量在项目根目录运行案例
- 先配置.env,
2 常见大模型服务平台介绍
2.1 调用三件套
- API KEY
- 模型名
- Base URL
2.2 常见平台
3 安装依赖
将仓库拉到本地,安装依赖,之前已经弄好了。
3.3 验证安装
执行GetEnvInfo.py,检测环境,如图所示:
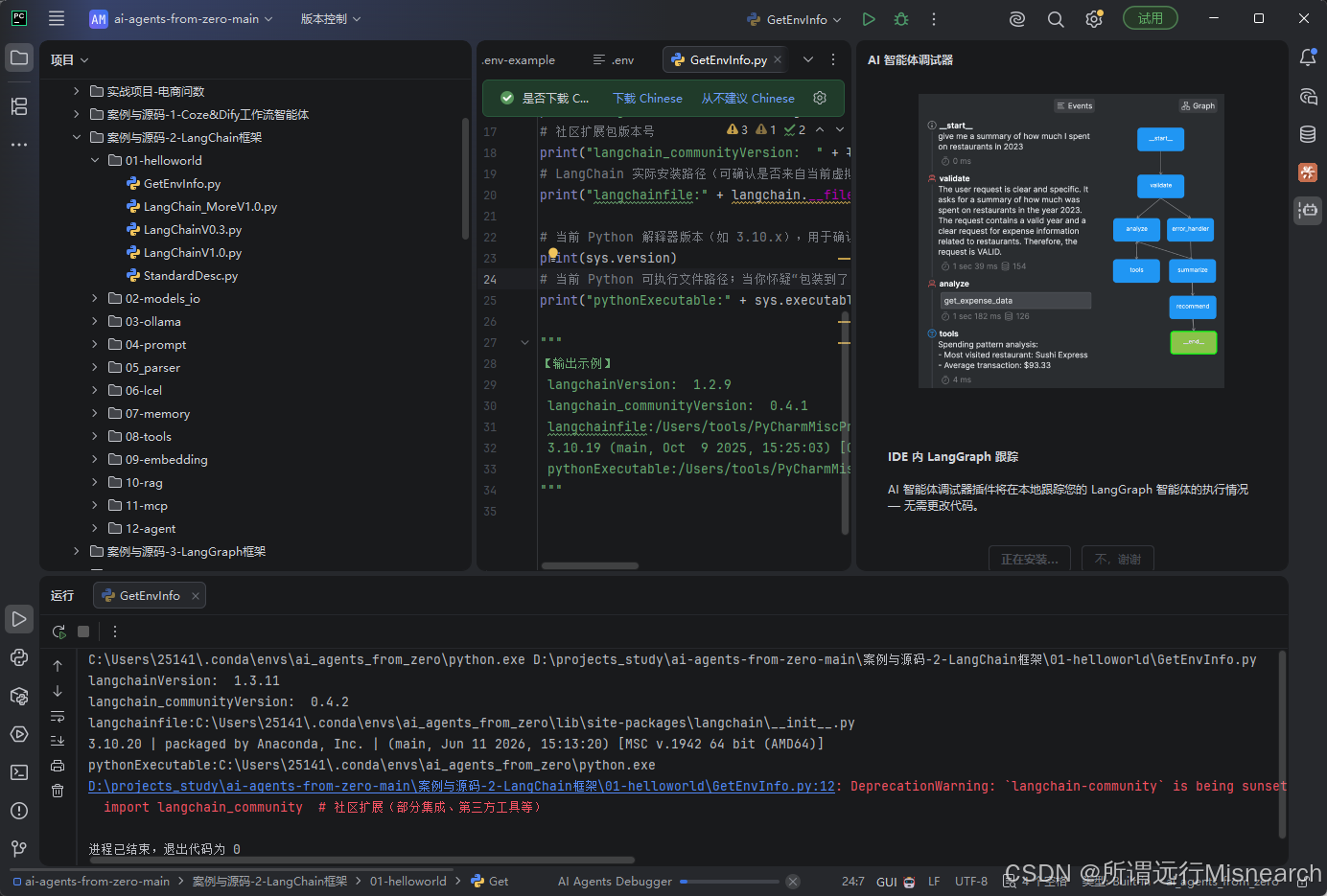
并下载了AI Agents Debugger插件,用于调试langgraph agent。
运行项目时要确保用的同一个python环境。
4 案例:基于百炼的HelloWorld
例如在百炼上找到:
- 模型名:qwen3.6-35b-a3b
- baseUrl:可以在对应模型下面找到OpenAI兼容,https://llm-55uiolr4hol9nlrx.cn-beijing.maas.aliyuncs.com/compatible-mode/v1
- api-key:在.env中声明了
4.2 HelloWorld的最小调用链路
最小链路流程:
准备三件套 → 初始化模型 → invoke("问题") → 读取 response.content
其中关键词:
- invoke:同步调用模型,返回一个消息对象
- .content:取出消息对象里的正文文本
4.3 示例代码
通过阅读代码,掌握这样的习惯,不将api-key硬编码到代码里,而是通过os.getenv()获取
查看langchain1.x写法
- 使用init_chat_model统一入口调用大模型,通过model_provider指定厂商
- 接国内平台(阿里百炼、通义等)时需显式写 model_provider=“openai”,否则会报错无法推断 provider。
- 调用三件套:API Key、模型名、Base URL;invoke(问题) 返回消息对象,.content 取正文。
其中invoke源码定义:
@override
def invoke(
self,
input: LanguageModelInput,
config: RunnableConfig | None = None,
*,
stop: list[str] | None = None,
**kwargs: Any,
) -> AIMessage:
invoke接收用户的输入和运行时配置,调用底层的大语言模型生成响应,并最终将其转换为标准的AIMessage对象返回。
- @Override是python3.12+引入的装饰器,明确表示该方法是对父类中invoke方法的重写
- input用户的输入,可以使字符串,消息列表等
- config:LangChain的运行时配置对象,用于控制执行行为
- stop:可选参数
核心执行与结果转换,嵌套的cast逻辑,从内向外执行以下操作:
# 1. 输入转换与生成请求
self.generate_prompt(
[self._convert_input(input)], # 将原始输入转换为模型能理解的格式
stop=stop, # 传入停止词
callbacks=config.get("callbacks"), # 提取配置中的回调处理器
tags=config.get("tags"), # 提取标签
metadata=config.get("metadata"), # 提取元数据
run_name=config.get("run_name"), # 提取运行名称
run_id=config.pop("run_id", None), # 提取并移除运行ID
**kwargs, # 其他额外参数
)
# generate_prompt 返回的是一个包含 generations 列表的 LLMResult 对象
# 2. 提取生成结果并转换类型
# .generations 获取了第一个批次中的第一个生成结果(ChatGeneration 对象)
cast("ChatGeneration", ...).message
# 从 ChatGeneration 对象中提取出底层的 message 属性
# 3. 最终类型转换
cast("AIMessage", ...)
# 确保最终返回的对象被明确标记为 AIMessage(AI 消息)类型
这段代码本质上是一个“适配器”。它将 LangChain 标准的 invoke 调用,转化为底层 generate_prompt 的调用,并且通过 config 实现了任务追踪、超时控制、日志记录等运行时控制712。最后,它把大模型返回的复杂嵌套结果(LLMResult -> ChatGeneration -> Message),剥离并强转为标准的 AIMessage,以便在 LangChain 的对话链(Chain)或 Agent 中继续流转
在openAI中的格式调用就是:
# Please install OpenAI SDK first: `pip3 install openai`
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get('DEEPSEEK_API_KEY'),
base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}}
)
print(response.choices[0].message.content)
可以发现langchain的invoke就是封装了的,可以理解为response.choices[0].message就是langchaininvoke得到的AIMessage,然后可以通过.content拿到正文,如下图所示:
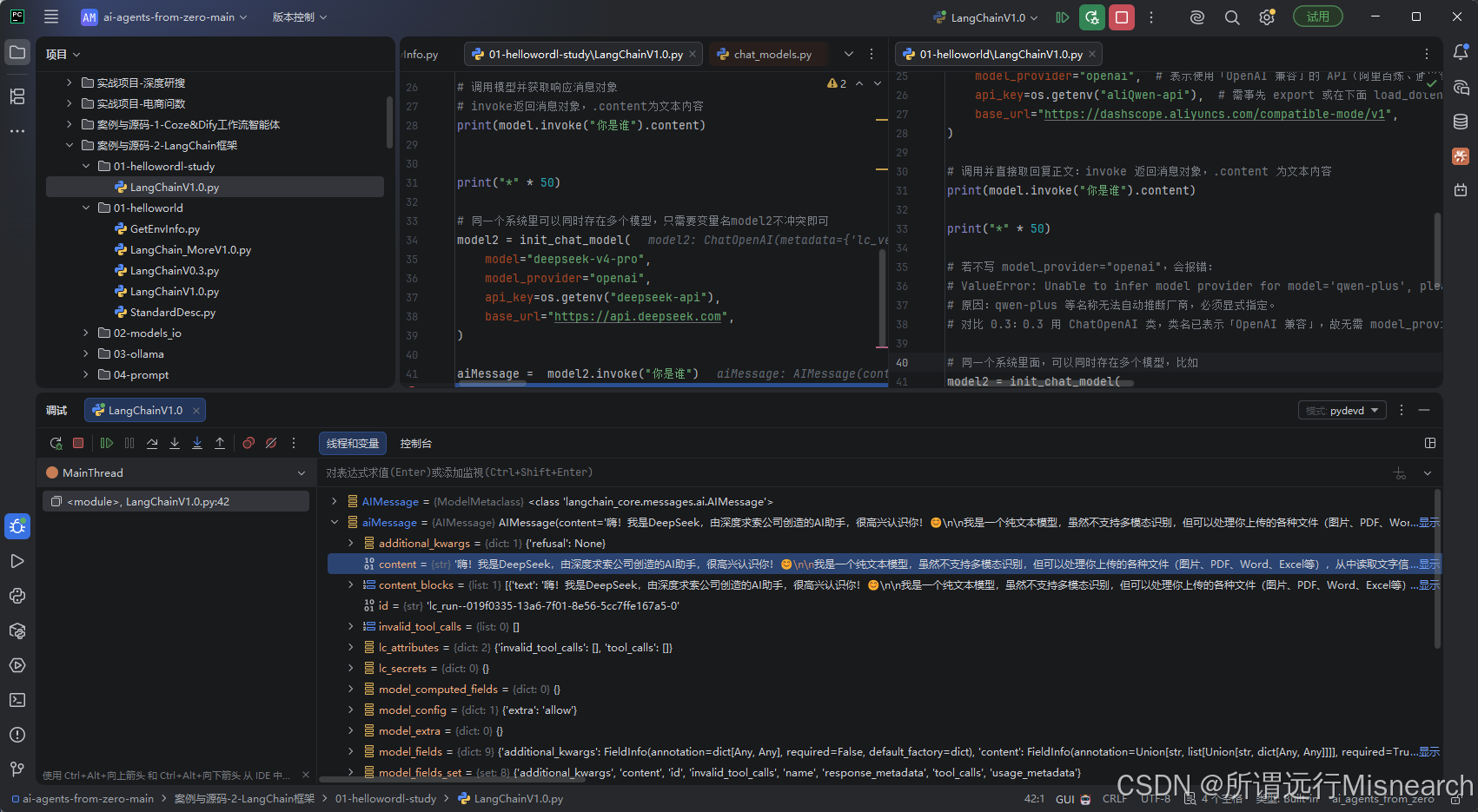
通过init_chat_model统一入口,不需要再为每个模型厂商记一套不同的初始化方式,而是先记住同一套调用骨架,通过参数切换不同模型和provider
4.4 0.3与1.0写法差异
0.3 / 经典写法的思路是:
- 直接从具体集成包导入类,例如 ChatOpenAI
- 类名本身就带有“我是按哪种协议接入”的语义
- 代码非常直观,但不同厂商、不同类名会让项目越写越散
1.x 的思路是:
- 用 init_chat_model 作为统一入口
- 通过 model、model_provider、api_key、base_url 等参数描述“我要接谁”
- 同一套代码骨架更容易迁移、统一与维护
5 多模型共存
5.1 多模型共存场景
存在不同模型的需求
5.2 调用三件套
5.3 多模型共存示例代码
记住就是多个模型使用变量名进行区分。
6 实战:企业级封装与流式输出
6.1 从HelloWorld到项目写法
真实项目里还要那么些就有问题了,因此要了解企业级封装和流式输出。
6.2 invoke()与stream()的区别
invoke()就是一次性返回完整结果。适合简单问答,后台处理,不需要实时展示中间输出的场景。
stream()就是变生成边返回。适合命令行实时输出,聊天界面打字机效果,长文本生成,用户等待体验更敏感的场景。
示例:
for chunk in model.stream("请介绍一下LangGraph"):
print(chunk.content, end="")
6.3 示例代码
下面是自己按照langchain1.0版本风格写的封装初始化代码
"""
【案例】标准/工程化写法,用LangChain调用大模型invoke或者stream
将初始化模型封装成函数便于复用
用.env存密钥
logging打日志
try/except区分错误
运行前记得在项目根目录配置.env中的api_key
这里直接看LangChainV1.0风格的写法
"""
# 导入环境
import os
import logging
from unittest import loader
from dotenv import load_dotenv
from langchain.chat_models import init_chat_model
from langchain_core.exceptions import LangChainException
load_dotenv(encoding="utf-8")
# 日志配置
_log_level = os.getenv("LOG_LEVEL", "INFO").upper()
logging.basicConfig(
level=getattr(logging, _log_level, logging.INFO),
format="%(asctime)s - %(levelname)s - %(message)s",
)
logger = logging.getLogger(__name__)
# LLM客户端初始化,封装为函数,便于多处复用
def init_llm_client():
"""
肯定是返回初始化好的模型实例
"""
api_key = os.getenv("deepseek-api")
if not api_key:
raise ValueError("环境变量DEEPSEEK_API_KEY未配置,请检查.env文件")
return init_chat_model(
model="deepseek-v4-pro",
model_provider="openai",
api_key=api_key,
base_url="https://api.deepseek.com",
)
# 主逻辑:invoke或者stream两种调用方式
def main():
"""
主函数:封装核心逻辑,符合python工程化规范
"""
try:
model = init_llm_client()
logger.info("LLM客户端初始化成功")
# invoke方式
question = "你是谁"
response = model.invoke(question)
logger.info(f"问题:{question}")
logger.info(f"回答:{response.content}")
# stream流式,边生成边输出
print("============下面是流式输出=============")
print("*" * 50)
for chunk in model.stream(question):
print(chunk.content, end="")
print()
except ValueError as e:
logger.error(f"配置错误:{str(e)}")
except LangChainException as e:
logger.error(f"模型调用失败: {str(e)}")
except Exception as e:
logger.error(f"未知错误:{str(e)}")
# 注意不要开代理,否则无法正常访问API端点
if __name__ == "__main__":
main()
上述示例:
- 把模型初始化封装为函数,避免到处重复写配置
- 显式检查环境变量
- 使用日志,这个很重要,
- 区分异常类型,便于排查问题
- 同时演示invoke和stream()
思考题
真实项目里还要处理配置校验、日志、异常、超时、重试、流式输出和敏感信息隐藏
接下来学习11,13,14,掌握完整的输入-》模型-》输出
第11章:Model I/O与模型接入
掌握Modell I/O模块中的输入提示Promot, 调用模型Model, 输出解析Parser三件套
掌握LangChain里最常见的模型分类,标准化参数,返回值结构
1 Model I/O 简介
1.1 定义
该模块关心的是模型的输入、调用和输出。
- Format(输入格式化):把原始业务输入整理成模型更容易理解的形式,例如 Prompt 模板、多角色消息、变量填充等。
- Predict(模型调用):通过 LangChain 的统一接口调用不同模型提供商,例如 OpenAI、DeepSeek、阿里百炼、Ollama 等。
- Parse(输出解析):把模型返回的自然语言结果转成更稳定、程序更好处理的形式,例如字符串、JSON、结构化对象等。
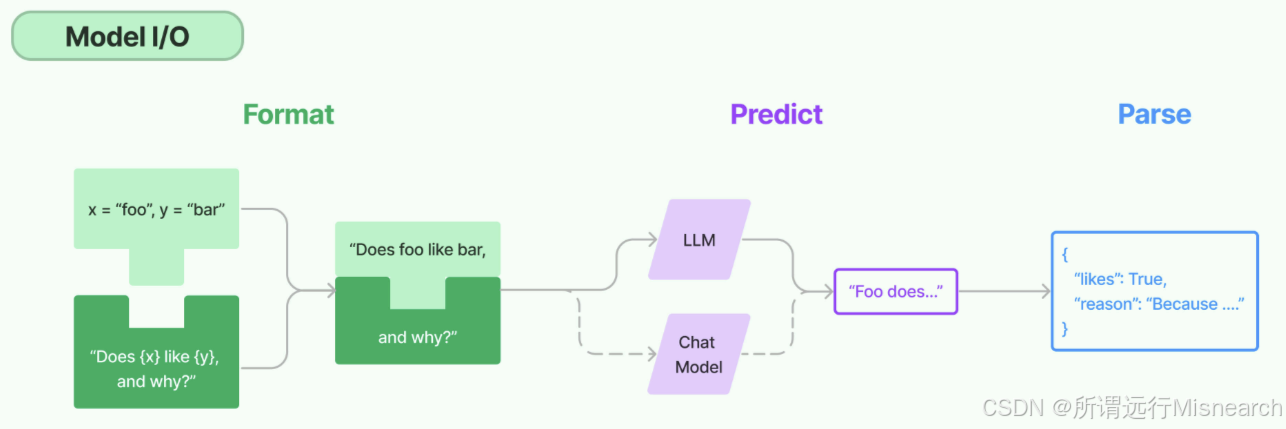
1.2 为什么需要Model I/O
真实项目里,还是需要Model I/O进行解决
2 LangChain模型分类、参数与返回
讲解模型调用Predict,弄清楚:
- LangChain中到底有哪些模型类型
- 调模型时常见参数是什么
- 调完模型后,返回的到底是什么
2.1 先分清:模型本身,模型提供商,LangChain模型对象
这个很好理解

2.2 LangChain常见模型分类
这里再次回顾LangChain框架是什么,是为了开发LLM应用程序设计的开源框架。
所以LangChain不提供模型权重本身,提供的是如何接这些模型的统一抽象。
LangChain的核心价值与能力体现在:
- 模块化的组件结构,这在第4章讲了一个概览,有一个印象
- 解决原生API调用的痛点
- 强大的生态与扩展能力
覆盖了AI应用从开发、测试到部署的完整生命周期。
LangChain中实际开发过程中最常用的是聊天对话模型,用于多轮对话、系统角色、用户消息等场景。
最常碰到的三类:
- LLM
- ChatModel
- Embeddings
后面的Prompt, Message, Tools, Agent, Memory本质大多都建立在ChatModel的消息交互之上。
2.3 LLM和Chat Model区别
在LangChain中,LLM和ChatModel,接口思维不一样,
- LLM更像给一段文本,让模型补全或生成下一段
- CahtModel更像给一段对话上下文,让模型按角色回复。
LLM风格就是提供prompt = "这是什么"
而ChatModel风格如下:
messages = [
{"role": "system", "content": "你是一个技术助教"},
{"role": "user", "content": "请用一句话解释什么是 LangChain"},
]
2.4 为什么Embedding放在这里
是向量模型
2.5 常用模型参数
LangChain对聊天模型定义了一批标准化参数,名称在不用写发下基本一致
掌握参数:
- model
- model_provider
- api_key
- base_url
- temperature
- max_tokens最大生成长度
- timeout超时时间,请求最长等多久
- max_retries 失败重试次数
- stop停止词,生成到某些位置时强制停止
在项目里最先调temperature 和max_tokens
2.6 Token, max_tokens与计费的关系
用量统计通常都以token数为单位
也有token可视化工具
2.7 参数的选择
根据业务场景选:
- 客服问答 / 规则回答 / 翻译:temperature 往往设低一些,例如 0~0.3
- 知识问答 / 通用助手:可设在 0.2~0.7
- 文案、创意写作、头脑风暴:可适当更高,例如 0.8~1.2
max_tokens 的使用也一样:
如果只是简短问答,可以限制小一点,避免无意义长回答
如果是总结、分析、长文输出,可以适当放大
但有一点要始终记住:
参数只是调味料,底层模型能力、Prompt 设计、上下文质量,通常比单纯调 temperature 更重要。
2.8 基本案例
temperature取值范围在0-2
"""
理解模型参数与返回对象结构
temperature影响输出随机性
max_tokens控制返回长度涉及到成本
使用api_key为deepseek_api
"""
import os
from langchain.chat_models import init_chat_model
from dotenv import load_dotenv
load_dotenv(encoding="utf-8")
# 实例化设置常用参数
model = init_chat_model(
model="deepseek-v4-flash",
model_provider="openai",
api_key=os.getenv("deepseek-api"),
base_url="https://api.deepseek.com",
temperature=0.7, # 0~1,越高越随机;此处略高便于看到多次输出差异
# max_tokens=256, # 可选:限制单次回复长度
)
print(model.invoke("写一句关于春天的词,14字以内"))
print(type(model))
print(type(model.invoke("写一个关于春天的词,14字以内").content))
print(type(model.invoke("写一句关于春天的词,14字以内")))
通过上述案例理解模型和返回的类型
2.9 调用后的返回信息
将init_chat_modle理解为模型客户端对象,invoke()返回的是<class 'langchain_core.messages.ai.AIMessage'>
2.10 AIMessage上常见字段
掌握字段:
- content
- response_metadata,厂商返回的原始元数据,用于看模型名、finish_reason, token_usage等
- usage_metadata,这是langchain统一整理后的用量信息,看input/output/total tokens
- tool_calls工具调用信息
- additional_kwargs厂商扩展字段
所以可以看到一个典型的AiMessage:
AIMessage(
content='《鹧鸪天·春》\n一篙绿涨江南岸,…', # 用户可见回复
response_metadata={
'token_usage': {
'prompt_tokens': 14,
'completion_tokens': 109,
'total_tokens': 123,
...
},
'model_name': 'deepseek-v4-flash',
'finish_reason': 'stop',
...
},
usage_metadata={
'input_tokens': 14,
'output_tokens': 109,
'total_tokens': 123,
...
},
tool_calls=[],
...
)
如图加深理解:
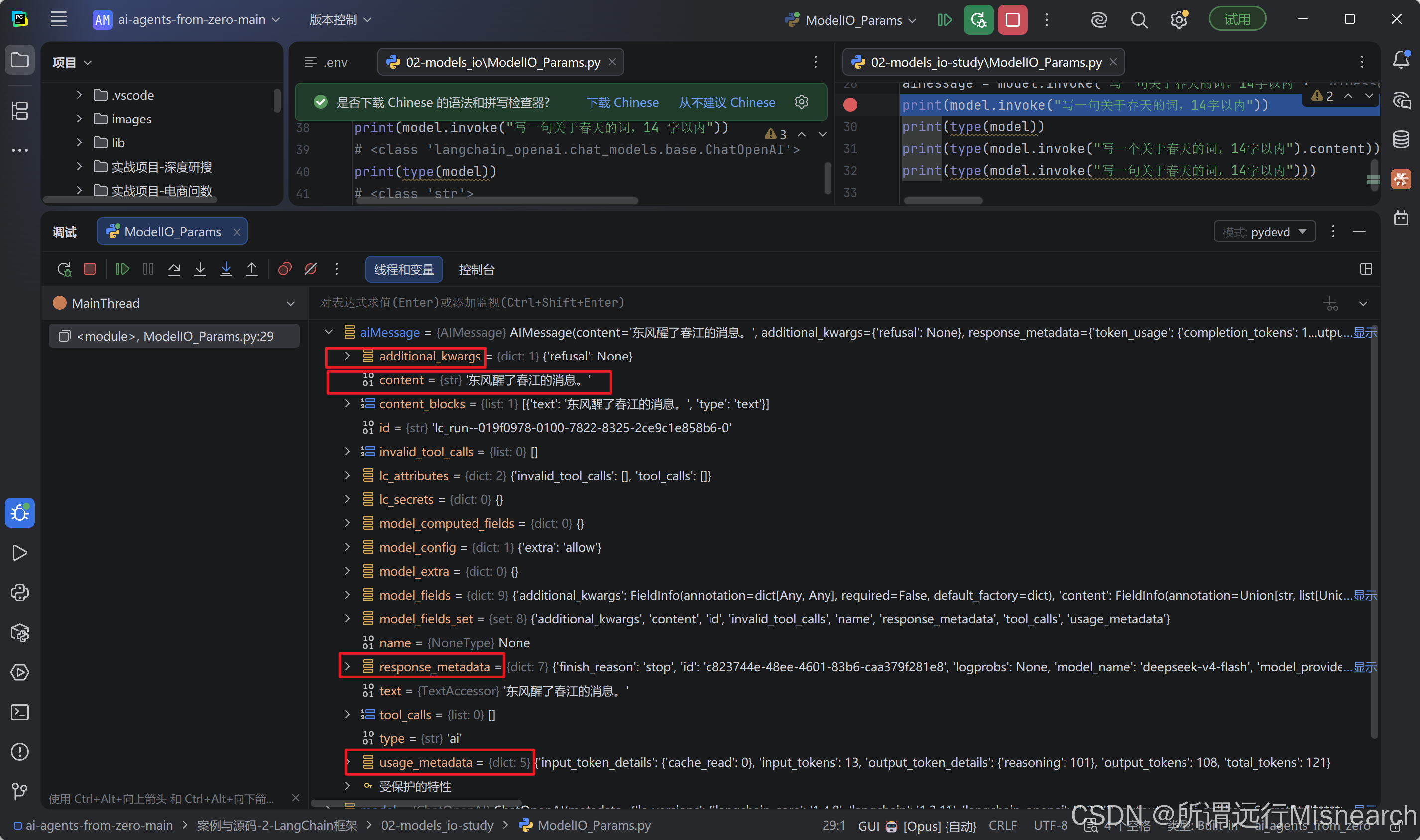
所以看content, response_metadata, usage_metadata
2.11 Messages的作用
ChatModel的输入输出,本质上都是消息Message
例如SystemMessage, HumanMessage, AIMessage, ToolMessage
Prompt只是输入的一种组织方式,Message才是更底层的统一表达
3 接入大模型
怎么把不同模型接进来
3.1 三种常见接入思路
从SDK, provider,到使用init_chat_model
3.2 接入OpenAI及兼容接口
3.2.2 openai.OpenAI与ChatOpenAI的区别
oepnai.OpenAI是官方的pythonSDK,langchain_openai.ChatOpenAI是LangChain生态
显然使用ChatOpenAI方便后续使用
3.2.6 真实项目建议
3.3 接入DeepSeek
3.3.1 常见接法
- 通过OpenAI兼容接口接入
- 通过langchain-deepseek原生provider接入
原生的更贴近deepseek自身集成,某些特性表达更自然
3.3.3 用init_chat_model接入
两种方法
- 按照OpenAI兼容接口接
- 使用deepseek provider包
3.4 接入通义千问
也是同样的方式,兼容接口或原生路线
3.7 模型对象拿到后还要关注什么
模型初始化之后,一个chat Model通常还会继续承担下面这些能力:
- 普通调用
- 流式输出
- 结构化输出with_structured_output(schema)
- 绑定工具model.bind_tools(tools)
- 放入链路
这里的模型也是核心组件
3.8 调用配置与运行时信息
除了初始化时传入的模型参数,LangChain每次调用还需要传入config,这是给LangChain运行时看的信息。
常见配置项:
- tags,给本次调用打标签,用于区分rag, agent, demo等不同链路
- metadata,记录额外上下文
- callback,挂接回调处理器
- configurable,运行时切换配置
示例:
response = model.invoke(
"用一句话解释 LangChain 的作用",
config={
"tags": ["model-io", "demo"],
"metadata": {"course": "ai-agents-from-zero"},
},
)
如果后面接入LangSmith,这些tags和metadata会很有用,因为可以在追踪记录里快速筛选某一类调用
还有一种更进阶的用法是运行时切换模型。例如先创建一个可配置的模型对象,再在调用时指定具体模型。
config更偏运行时管理和观测。
第12章 Ollama本地部署与调用
这一章先跳过
第13章 提示词语消息模板
掌握LangChain中与输入组织最相关的三块内容:消息类型Message,模型调用方式invoke, stream,提示词模板PromptTemplate, ChatPromptTemplate。
理解本章全部案例。从模型需要吃进什么,理解提示词模板。
1 Prompt简介
对应了Model I/O中的输入格式化format和模型调用predict
将之前了解的提示词工程,应用到本章就是代码实现版。
将之前提到的角色、任务、上下文、输入、输出和约束,理解在LangChain中以什么形态存在的。
1.1 定义
提示词,从自然语言到带有角色的,再到代码可复用、可维护、可协作,从而把输入写成模板,把会变化的部分改为占位符,这就是从随手提问走向工程化输入管理。
因此Prompt需要把模型输入组织清楚
随着项目复杂度提高,Prompt会从一个字符串逐步演化为多角色消息 + 模板 + 占位符 + 外部配置文件。
1.2 Prompt作用
将输入组织清楚
下面这些真实开发场景,都离不开本章内容:
- 智能客服:需要系统提示词规定语气、身份和拒答策略。
- 企业知识库问答:需要把“检索出来的上下文 + 用户问题”组合成一条清晰提示。
- 多轮聊天:需要把历史对话插回当前输入,而不是每轮都从头问。
- 结构化输出:需要提前在 Prompt 里写清楚输出格式要求,方便后面交给解析器处理(通过提示词就一定能保证按照结构化方式输出吗)。
- 团队协作与 A/B 测试:需要把 Prompt 模板从代码里抽出来,放到 JSON / YAML 中做版本管理。(例如java项目中使用nacos进行统一配置——AI版天机学堂)
模型能力决定上限,Prompt 设计决定你能不能稳定接近这个上限。
1.3 本章在项目中的位置
分为4类:
- invoke,模型调用方式,invoke, stream,batch及异步版本
- prompt_templates,文本模板,
- chat_prompt_tempalte,对话模板
- load_external,外部文件加载
2 调用大模型的入参类型
调用模型可以有多种输入形态
2.1 入参形态总览
- str
- PromptTemplate.format()后的字符串
- 消息对象列表
- (role, content)元组列表
- 字典列表
回顾python的基础知识,元组有序不可变,字典大括号。
示例:
"""
多种输入类型
invoke可以接受消息对象列表
(role, content)元组
{"role": "...", "content": "..."}字典
这样写都是表达这次输入由哪些角色、哪些内容组成,LangChain会在内部转成统一消息表示
可以使用Message类写法
"""
import asyncio
import os
from dotenv import load_dotenv
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage, SystemMessage
load_dotenv()
model = init_chat_model(
model="deepseek-v4-flash",
model_provider="openai",
api_key=os.getenv("deepseek-api"),
base_url="https://api.deepseek.com",
)
def demo_message_objects():
"""推荐,显式Message对象,角色与字段最清晰"""
message = [
SystemMessage(content="你是一个专业的数学助手,回答要简短。"), # 列表
HumanMessage(content="你好,你是谁?"),
]
resp = model.invoke(message)
print(type(resp), resp.content[:80] if resp.content else "")
def demo_tuple_list():
"""元组列表:与 ChatPromptTemplate.from_messages 的写法一致。"""
messages = [
("system", "你是一个专业的数学助手,回答要简短。"),
("human", "你好,你是谁?"),
]
resp = model.invoke(messages)
print(type(resp), resp.content[:80] if resp.content else "")
def demo_dict_list():
"""字典列表:与 OpenAI Chat Completions 等 API 的请求体形状接近。"""
messages = [
{"role": "system", "content": "你是一个专业的数学助手,回答要简短。"},
{"role": "user", "content": "你好,你是谁?"},
]
resp = model.invoke(messages)
print(type(resp), resp.content[:80] if resp.content else "")
async def demo_ainvoke_tuple():
"""异步调用同样支持元组简写。"""
resp = await model.ainvoke([(
"user", "用一句话说明什么是素数。"
)])
if __name__ == "__main__":
print("--- Message 对象列表 ---")
demo_message_objects()
print("--- 元组列表 ---")
demo_tuple_list()
print("--- 字典列表 ---")
demo_dict_list()
print("--- ainvoke + 元组 ---")
asyncio.run(demo_ainvoke_tuple())
回顾python中的异步编程语法async与await
- async def: 这是python定义异步函数协程的语法,告诉python解释器,这个函数内部包含需要等待的I/O操作,在等待期间可以释放控制权去执行其他任务。
- await,用于挂起当前协程的执行,等待model.ainvoke()这个异步操作完成并获取返回结果。LangChain中,ainvoke是同步方法invoke的异步版本,专门用于异步环境
2.3 写法二:模板 + 占位符
示例:
from langchain_core.prompts import PromptTemplate
template = PromptTemplate.from_template(
"用不超过 50 字介绍:{topic} 是什么?"
)
prompt_str = template.format(topic="LangChain")
resp = model.invoke(prompt_str)
print(resp.content)
2.4 写法三:多角色消息列表
构建消息类型列表,可以简化为列表,例如HumanMessage就是"user",SystemMessage可以为"system",Langchain会转换的。
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
messages = [
SystemMessage(content="你是只回答技术问题的助手,回答要简短。"),
HumanMessage(content="什么是 LangChain?"),
# 多轮示例:
# AIMessage(content="LangChain 是用于编排 LLM 应用的框架……"),
# HumanMessage(content="它和直接调 API 有什么区别?"),
]
resp = model.invoke(messages)
print(resp.content)
在实际项目里,这种写法特别常见,
- 系统提示词放在SystemMessage
- 用户问题放在HumanMessage
- 历史回复可放在AIMessage
- 工具执行结果后续可用ToolMessage
后续做多轮对话,Agent, RAG,这种消息列表思维会反复用到。
还有就是ChatPromptValue,链式编排里更常见。
直接构造对象然后转换,ChatPromptValue ->调用to_message()
2.4 写法四:元组列表与字典列表
2.6 Java生态中的多角色
多角色消息并不是某个框架的语法技巧,而是现代聊天模型交互的一种通用抽象。
3 入参的消息类型
知道每种消息类型代表什么
3.1 四类核心消息
- SystemMessage
- HumanMessage
- AIMessage,模型回复消息,保存上一轮回复,支持多轮上下文
- ToolMessage,工具执行结果,
3.3 ToolMessage什么时候会出现
ToolMessage不会在普通问答里频繁出现,更常见于函数调用,工具调用,Agent编排场景
简单示例:
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage, ToolMessage
messages = [
SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="你好,请你介绍一下你自己"),
AIMessage(content="我是一名人工智能助手,请问您有什么想问的吗?"),
ToolMessage(
content='{"population": 21540000, "area": "16410平方公里"}',
tool_call_id="call_abc123",
),
]
print(messages)
4 调用大模型的调用方式
LangChain 聊天模型常见的调用方式有四类:普通调用、流式调用、批量调用,以及它们各自的异步版本。
例如:
- invoke/ainvoke:一次发一条
- stream/astream:一边生成一边返回
- batch/abatch:一次发很多条
4.1 普通调用invoke/ ainvoke
- invoke:同步调用,最常用,适合单轮问答与脚本演示。
- ainvoke:异步调用,适合异步 Web 服务、并发任务和高吞吐场景。
实际项目中选择:
- 命令行脚本,教学示例,简单后台任务,优先invoke
- FastAPI, 异步服务,并发请求,优先ainvoke
- 本地开源模型也适用
这里了解ainvoke,
ainvoke是invoke的异步版本,等待模型返回时不会阻塞事件循环。- 它适合异步 Web 服务、并发任务和需要同时处理多条请求的场景。
- 返回结果类型通常仍是
AIMessage;只是调用方式从“直接返回”变成了“await后返回”。
示例:
resp = await model.ainvoke("解释一下你是谁")
if __name__ == "__main__":
asyncio.run(main())
4.2 流式调用
即:
- stream,同步流式输出
- astream,异步流式输出
流式的最大价值不是“更快算完”,而是更快把正在生成的内容展示给用户。在聊天机器人、报告生成、代码生成等场景里,用户体验会明显更好。
示例:
messages = [
SystemMessage(content="你叫小问,是一个乐于助人的AI助手"),
HumanMessage(content="你是谁")
]
for chunk in model.stream(messages):
print(chunk.content, end="", flush=True)
print()
异步流式,返回的是异步生成器,因此必须用asynch for遍历,循环的每一块通常仍是AIMessageChunk
示例:
# ---------- 3. 异步流式调用(在 async 函数中)----------
async def async_stream_call():
# astream(messages) 返回的是「异步生成器」,不是 await 一个整体结果
response = model.astream(messages)
print(f"响应类型:{type(response)}") # <class 'async_generator'>
# 必须用 async for 遍历异步生成器,不能用普通 for
async for chunk in response:
print(chunk.content, end="", flush=True)
print("\n")



















 1829
1829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












